Des tâches longues et monotones sont souvent rencontrées dans le travail, pour la solution desquelles de nombreuses personnes sont nécessaires. Par exemple, décryptez plusieurs centaines d'enregistrements audio, balisez des milliers d'images ou filtrez les commentaires, dont le nombre ne cesse de croître. À ces fins, vous pouvez conserver des dizaines d'employés à temps plein. Mais tous doivent être trouvés, sélectionnés, motivés, contrôlés, assurer un développement et une progression de carrière. Et si la quantité de travail est réduite, ils devront être recyclés ou licenciés.
Dans de nombreux cas, en particulier si aucune formation spéciale n'est requise, ce travail peut être effectué par les exécuteurs de
Toloka , la plateforme de crowdsourcing Yandex. Ce système est facilement évolutif: s'il y a moins de tâches d'un client, les tolokers iront à un autre, si le nombre de tâches augmente, ils ne seront que satisfaits.
Sous la coupe sont des exemples de la façon dont Toloka aide Yandex et d'autres sociétés à développer leurs produits. Toutes les rubriques sont cliquables - les liens mènent aux rapports.

Le MIPT a utilisé Toloka pour évaluer la qualité des robots de chat dans le cadre du hackathon DeepHack.Chat. Il a impliqué 6 équipes. La tâche consistait à développer un chatbot capable de parler de lui-même en fonction du profil qui lui est attribué avec une brève description des caractéristiques personnelles.

Les tolokers et les bots ont reçu des profils et ont dû faire semblant d'être une personne dans le dialogue, dont la description y était donnée, parler d'eux et en savoir plus sur l'interlocuteur. Les participants au dialogue n'ont pas vu leurs profils respectifs.
Seuls les utilisateurs qui ont réussi le test de compétence en anglais ont été autorisés à effectuer la tâche, car tous les robots de chat du hackathon parlaient anglais. Il était impossible d'organiser un dialogue avec le bot directement via Toloka, donc dans la tâche un lien a été donné au canal Telegram où le bot de chat a été lancé.
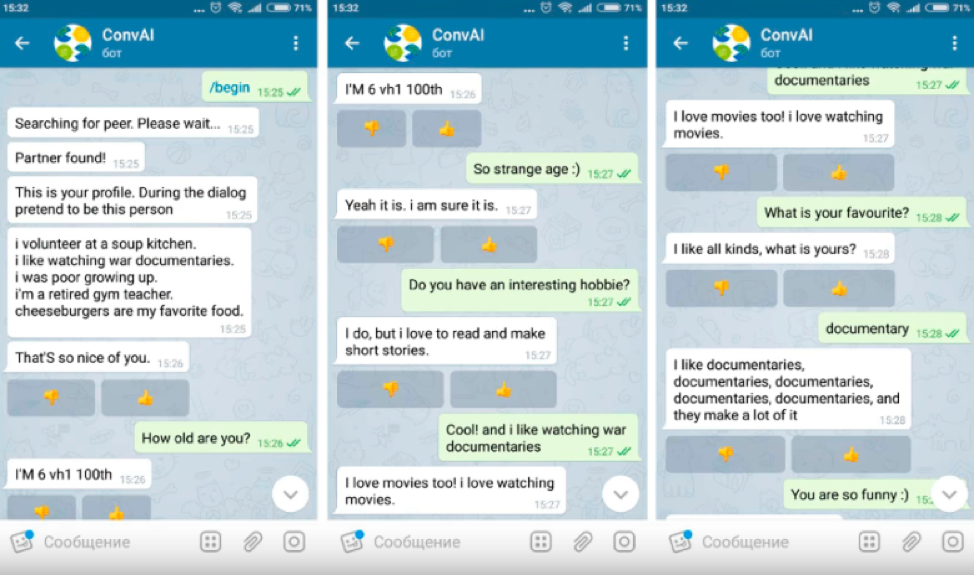
Après avoir parlé avec le bot, l'utilisateur a reçu un ID de dialogue qui, avec l'évaluation du dialogue, a été inséré dans le Toloka comme réponse.
Pour exclure les tolokers malhonnêtes, il était nécessaire de vérifier dans quelle mesure l'utilisateur parlait avec le bot. Pour ce faire, nous avons créé une tâche distincte, dans le cadre de laquelle les interprètes lisent les dialogues et évaluent le comportement de l'utilisateur, c'est-à-dire le tireur de la tâche précédente.
Pendant le hackathon, les équipes ont téléchargé leurs robots de chat. Pendant la journée, les tolkers les ont testés, compté la qualité et rapporté le score aux équipes, après quoi les développeurs ont édité le comportement de leurs systèmes.
En quatre jours, les systèmes de hackathon se sont considérablement améliorés. Le premier jour, les robots avaient des réponses inappropriées et en double; le quatrième jour, les réponses sont devenues plus adéquates et détaillées. Les robots ont appris non seulement à répondre aux questions, mais aussi à poser les leurs.
Exemple de dialogue le premier jour du hackathon:

Le quatrième jour:

Statistiques: l'évaluation a duré 4 jours, environ 200 tolkers y ont participé et 1800 dialogues ont été traités. Ils ont dépensé 180 $ pour la première tâche et 15 $ pour la seconde. Le pourcentage de dialogues valides s'est avéré plus élevé que lorsque l'on travaillait avec des bénévoles.
Une tâche importante du créateur du drone est de lui apprendre à extraire des informations sur les objets environnants des données qu'il reçoit des capteurs. Pendant le trajet, la voiture enregistre tout ce qu'elle voit autour. Ces données sont versées dans le cloud, où l'analyse principale est effectuée, puis passent au post-traitement, qui comprend le balisage. Les données étiquetées sont envoyées aux algorithmes d'apprentissage automatique, le résultat est renvoyé à la machine et le cycle se répète, améliorant la qualité de la reconnaissance d'objet.
Il y a beaucoup d'objets divers dans la ville, tous doivent être balisés. Cette tâche nécessite certaines compétences et prend beaucoup de temps, et des dizaines de milliers de photos sont nécessaires pour former un réseau neuronal. Ils peuvent être extraits de jeux de données ouverts, mais ils sont collectés à l'étranger, de sorte que les images ne correspondent pas à la réalité russe. Vous pouvez acheter des images marquées pour aussi peu que 4 $, mais le balisage à Tolok était environ 10 fois moins cher.
Étant donné que dans Tolok, vous pouvez intégrer n'importe quelle interface et transférer des données via l'API, les développeurs ont inséré leur propre éditeur visuel, qui a des couches, la transparence, la sélection, l'agrandissement, la division en classes. Cela a plusieurs fois augmenté la vitesse et la qualité du balisage.
De plus, l'API vous permet de diviser automatiquement les tâches en tâches plus simples et de collecter le résultat à partir de morceaux. Par exemple, avant de marquer une image, vous pouvez marquer les objets qui s'y trouvent. Cela vous permettra de comprendre sur quelles classes marquer l'image.
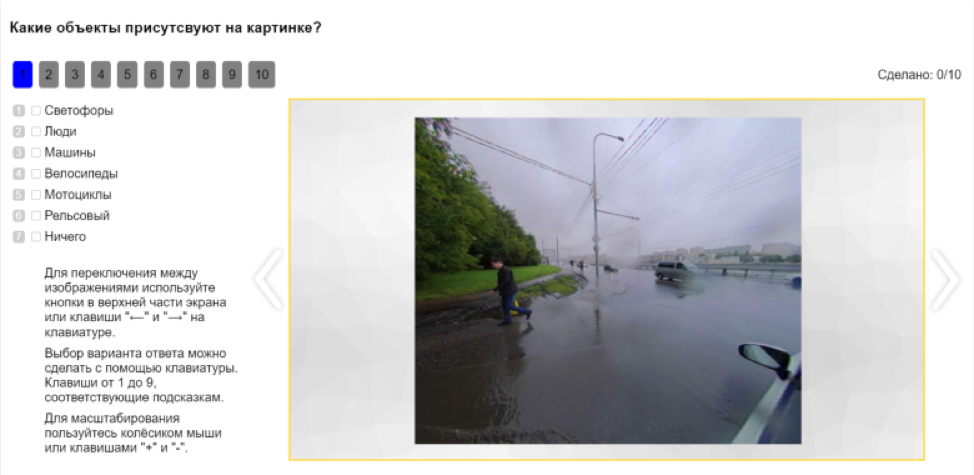
Après cela, les objets de l'image peuvent être classés. Par exemple, proposer aux tireurs une sélection de photos là où il y a des gens et leur demander de préciser s'il s'agit de piétons, de cyclistes, de motocyclistes ou de quelqu'un d'autre.

Lorsque le tolker a terminé le balisage, il doit être vérifié. Pour ce faire, des tâches de test sont créées qui sont proposées aux autres interprètes.

Non seulement les tolokers, mais aussi les réseaux de neurones sont impliqués dans le marquage. Certains d'entre eux ont déjà appris à faire face à cette tâche pas pire que les gens. Mais la qualité de leur travail doit également être évaluée. Par conséquent, dans les tâches, en plus des images marquées avec des tolokers, il y a également marqué avec un réseau neuronal.
Toloka s'intègre donc directement dans le processus d'apprentissage des réseaux de neurones et fait partie du pipeline de tout l'apprentissage automatique.
Ozon utilise Toloka pour créer un échantillon de référence. C'est à plusieurs fins.
• Évaluation de la qualité du nouveau moteur de recherche.
• Déterminer le modèle de classement le plus efficace.
• Amélioration de la qualité de l'algorithme de recherche à l'aide de l'apprentissage automatique.
Le premier échantillon de test a été fait manuellement - nous avons pris 100 demandes et les avons marquées nous-mêmes. Même un si petit échantillon a aidé à identifier les problèmes de recherche et à déterminer les critères d'évaluation. L'entreprise souhaitait créer son propre outil pour évaluer la qualité de la recherche, embaucher des évaluateurs et les former, mais cela prendrait trop de temps, nous avons donc décidé de choisir une plateforme de crowdsourcing prête à l'emploi.
L'étape la plus difficile dans la préparation de la mission pour les tolokers a été la formation - même les employés de l'entreprise n'ont pas pu effectuer la première mission de test. Après avoir reçu les retours de l'équipe, nous avons développé un nouveau test: nous avons construit la formation de tâches simples à complexes et compilées en tenant compte des qualités importantes de l'interprète pour l'entreprise.
Pour éliminer les erreurs, Ozon a effectué un test. La tâche consistait en trois blocs - la formation, le contrôle avec un seuil de 60% de bonnes réponses et la tâche principale avec un seuil de 80% de bonnes réponses. Pour améliorer la qualité de l'échantillon, une tâche a été proposée à cinq interprètes.
Statistiques d'exécution des tests: 350 tâches en 40 minutes. Le budget était de 12 $. La première étape a été suivie par 147 interprètes, 77 ont été formés, 12 ont acquis les compétences et effectué la tâche principale.
Le scénario du lancement principal est devenu plus compliqué: non seulement les nouveaux tokers, mais aussi ceux qui ont reçu les compétences nécessaires au stade du test, y ont participé. Le premier longeait la chaîne standard, le second était immédiatement admis aux tâches principales. Lors du lancement principal, des compétences supplémentaires ont été ajoutées - le pourcentage de bonnes réponses dans l'échantillon principal et l'opinion majoritaire. La mission était toujours proposée à cinq interprètes.
Statistiques de lancement principales: 40 000 emplois en un mois. Le budget s'élevait à 1150 dollars. 1117 tolkers sont venus au projet, 18 ont acquis des compétences, 6 ont eu accès au plus grand bassin principal et l'ont évalué.
Maintenant, le travail Tolok d'Ozon est comme ceci:
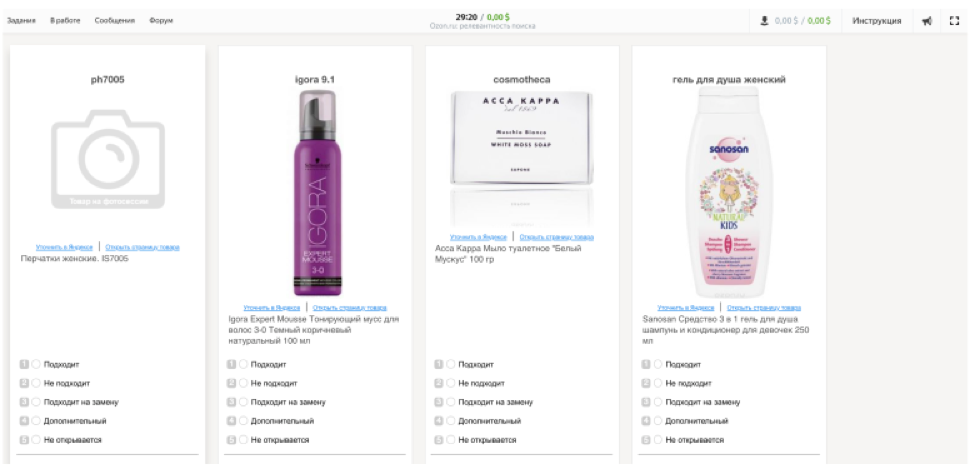
L'entrepreneur voit la requête de recherche et 9 produits à partir des résultats de la recherche. Sa tâche consiste à choisir l'une des cotes - «convenable», «non convenable», «convenable pour remplacement», «supplémentaire», «ne s'ouvre pas». Une note finale permet d'identifier les problèmes techniques sur le site. Pour simuler le comportement de l'utilisateur le plus précisément possible, les développeurs via l'iframe ont recréé l'interface de la boutique en ligne.
Parallèlement au lancement de la tâche sur Toloka, le balisage des requêtes de recherche a été effectué à l'aide des règles. L'accent a été mis sur les requêtes populaires afin d'améliorer principalement leur émission.
Le balisage par les règles a permis d'obtenir rapidement des données sur un petit nombre de requêtes et a montré de bons résultats sur les requêtes les plus fréquentes. Mais il y avait aussi des inconvénients: les demandes ambiguës ne peuvent pas être estimées par des règles, il y a beaucoup de situations controversées. De plus, à long terme, cette méthode a été assez coûteuse.
Le balisage avec l'aide de personnes couvre ces inconvénients. À Tolok, vous pouvez recueillir les opinions d'un grand nombre d'interprètes, l'évaluation est plus graduée, ce qui vous permet de travailler plus en profondeur avec l'extradition. Après la configuration initiale, la plateforme fonctionne de manière stable et traite de grandes quantités de données.
Le travail manuel et les mécanismes d'intelligence artificielle ne s'opposent pas. Plus l'intelligence artificielle se développe, plus le travail manuel est nécessaire à sa formation. D'un autre côté, plus les réseaux de neurones sont mieux formés, plus les tâches de routine peuvent être automatisées, ce qui en sauve une personne.
Presque toutes les tâches, même volumineuses, peuvent être divisées en plusieurs petites et construites sur la base du crowdsourcing. La plupart des tâches résolues dans
Tolok sont la première étape vers la formation de modèles et l'automatisation des processus sur les données collectées par les personnes.
Dans la prochaine publication sur ce sujet, nous parlerons de la façon dont le crowdsourcing est utilisé pour former Alice, modérer les commentaires et surveiller la conformité aux règles de Yandex.Buses.