L'apprentissage automatique vous permet de rendre le service beaucoup plus pratique pour les utilisateurs. Ce n'est pas si difficile de commencer à mettre en œuvre des recommandations, les premiers résultats peuvent être obtenus même sans avoir une infrastructure établie, l'essentiel est de commencer. Et seulement alors pour construire un système à grande échelle. C'est ainsi que tout a commencé sur Booking.com. Et ce qu'il en est résulté, quelles approches sont maintenant utilisées, comment les modèles sont introduits dans la production, lesquels surveiller, Viktor Bilyk a déclaré à HighLoad ++ Siberia. Les erreurs et problèmes possibles n'ont pas été laissés derrière le rapport, cela aidera quelqu'un à contourner les hauts-fonds et quelqu'un proposera de nouvelles idées.
 À propos de l'orateur:
À propos de l'orateur: Victor Bilyk introduit des produits d'apprentissage automatique dans les opérations commerciales de Booking.com.
Tout d'abord, voyons où Booking.com utilise l'apprentissage automatique dans quels produits.
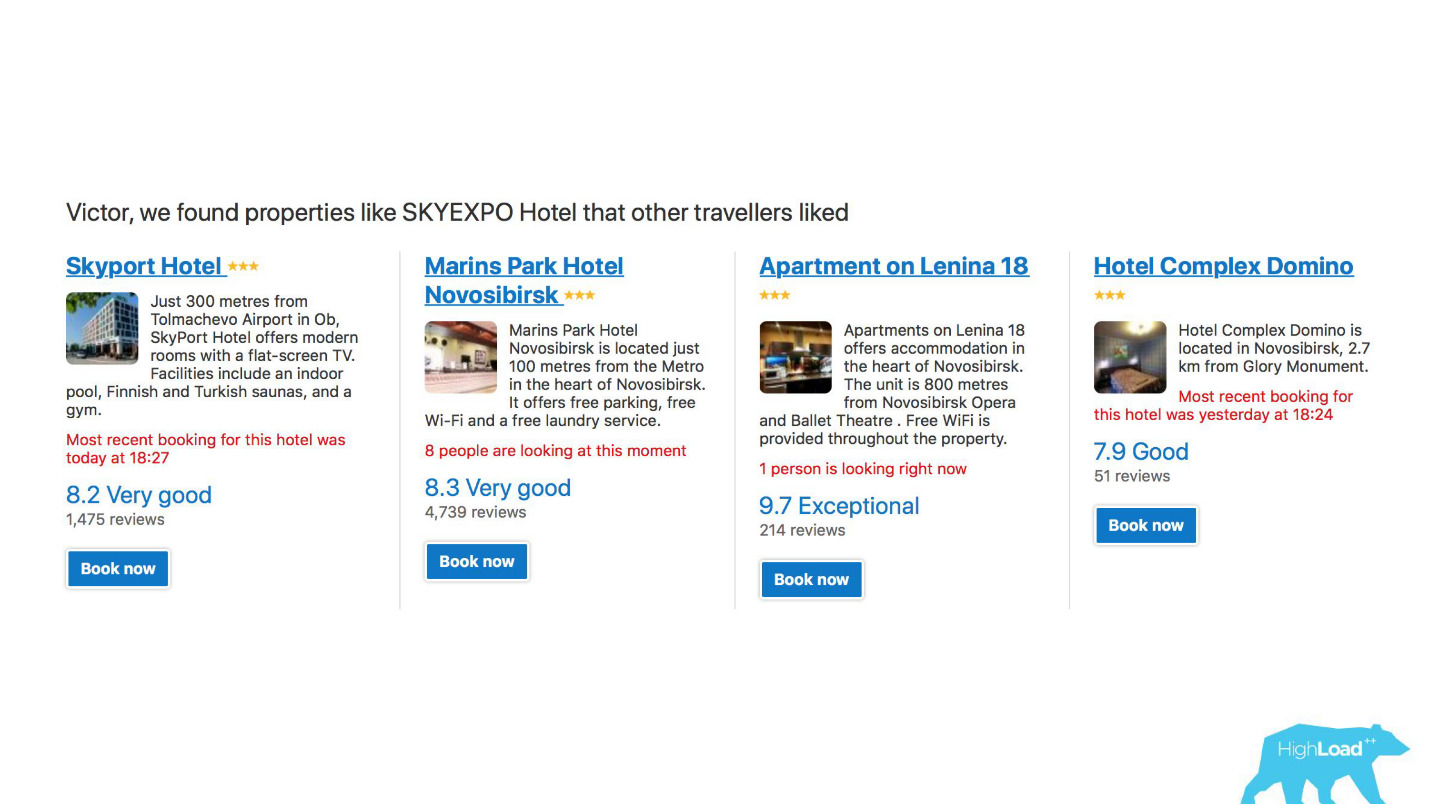
Premièrement, il s'agit d'un grand nombre de systèmes de recommandation pour les hôtels, les destinations, les dates et à différents points de l'entonnoir de vente et dans différents contextes. Par exemple, nous essayons de deviner où vous irez lorsque vous n'avez rien saisi dans la ligne de recherche.

Ceci est une capture d'écran dans mon compte, et je visiterai certainement deux de ces domaines cette année.
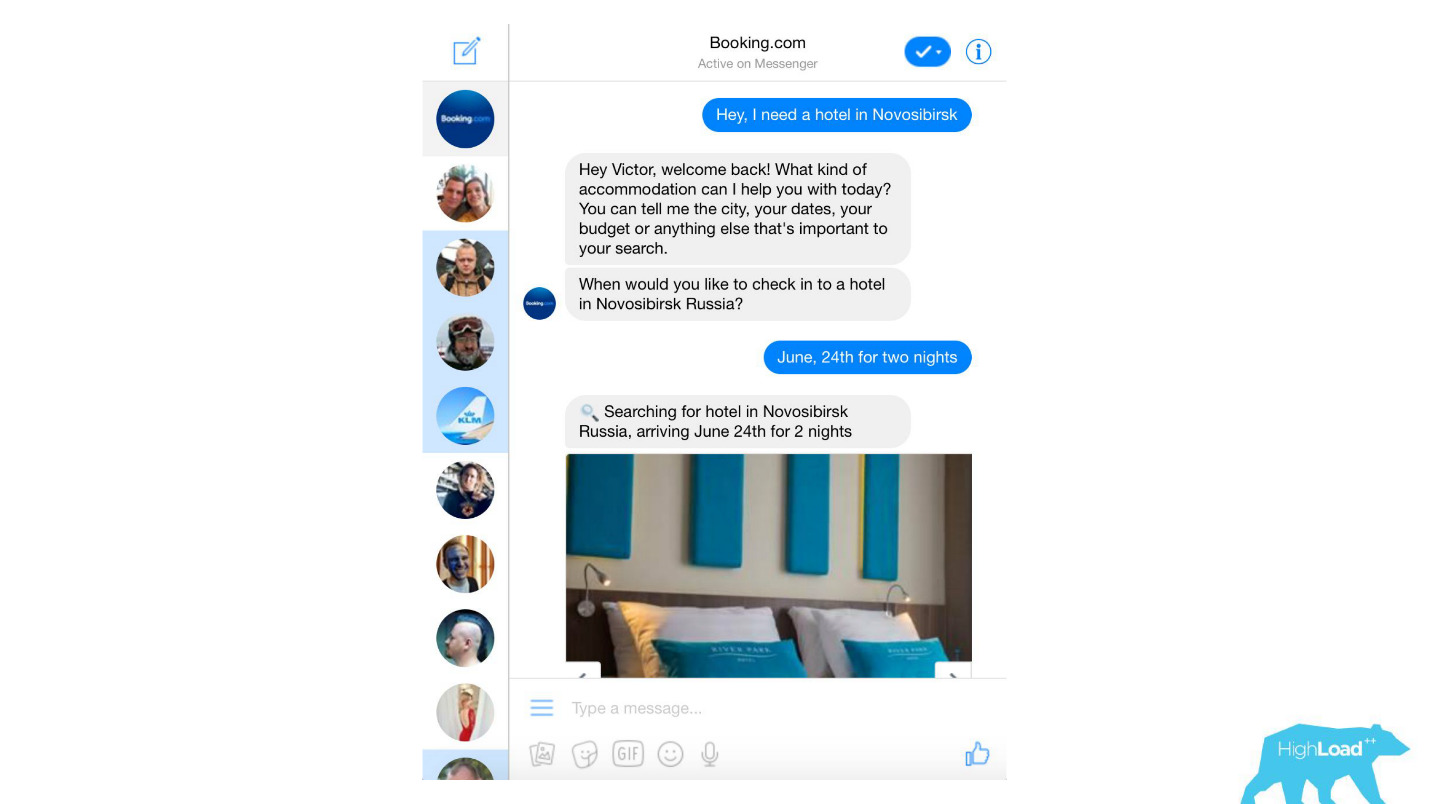
Nous traitons presque tous les messages texte des clients, des filtres anti-spam banaux aux produits sophistiqués comme Assistant et ChatToBook, qui utilisent des modèles pour déterminer les intentions et reconnaître les entités. En outre, il existe des modèles qui ne sont pas si visibles, par exemple, la détection de fraude.
Nous analysons les avis. Les mannequins nous disent pourquoi les gens vont, disons, à Berlin.
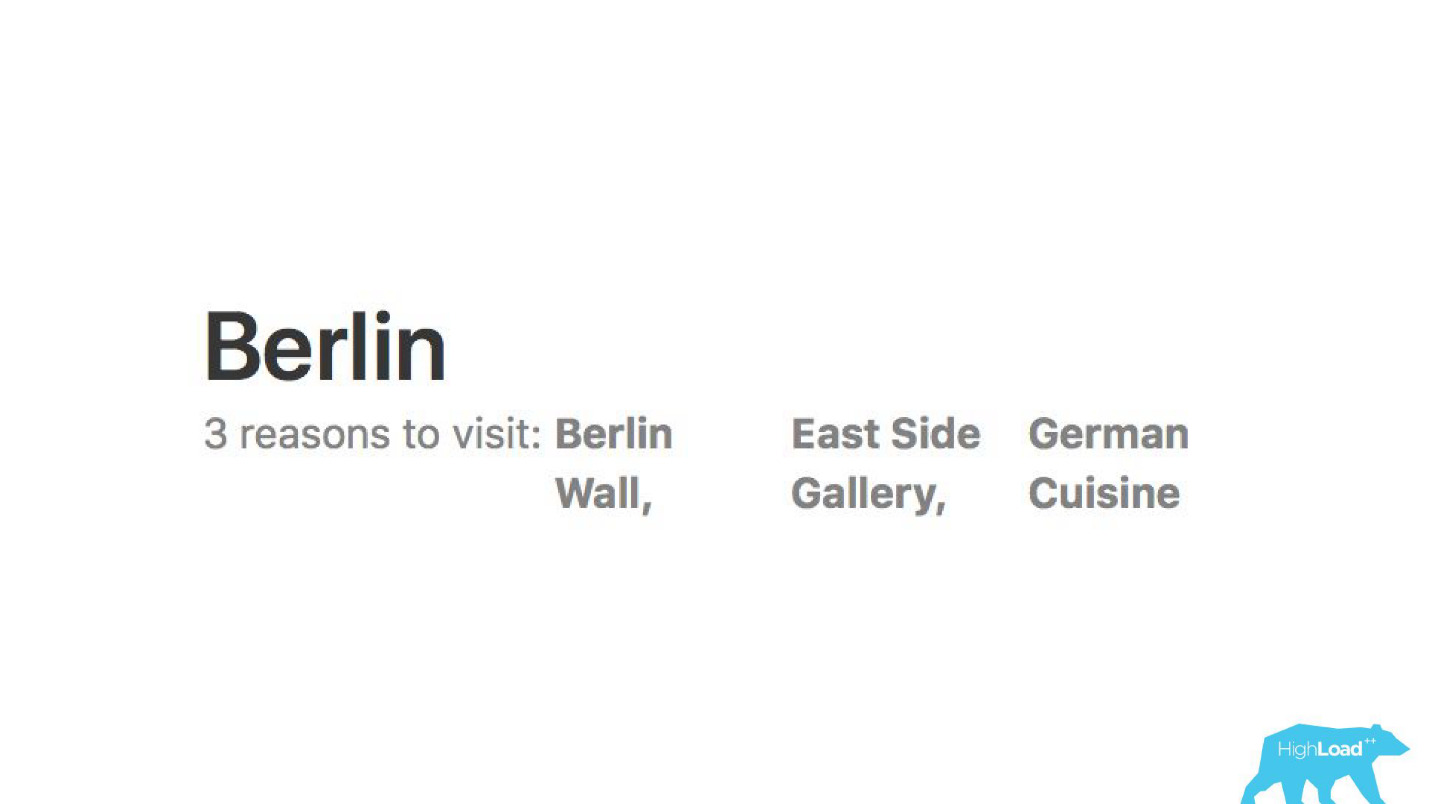
À l'aide de modèles d'apprentissage automatique, il est analysé pourquoi l'hôtel est loué afin que vous n'ayez pas à lire vous-même des milliers d'avis.
À certains endroits de notre interface, presque chaque pièce est liée aux prédictions de certains modèles. Par exemple, nous essayons ici de prédire quand l'hôtel sera complet.
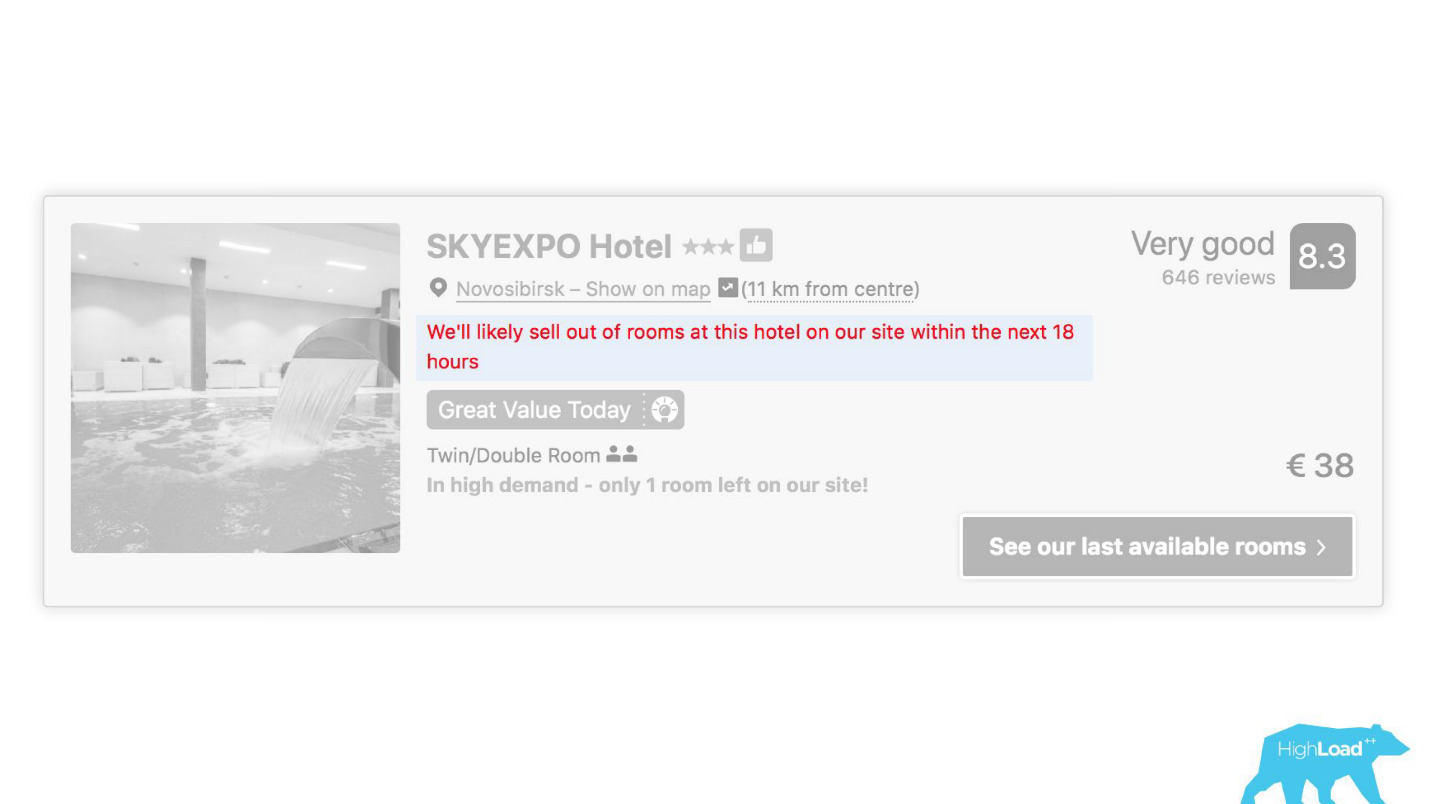
Nous nous retrouvons souvent bien - après 19 heures, la dernière chambre est déjà réservée.
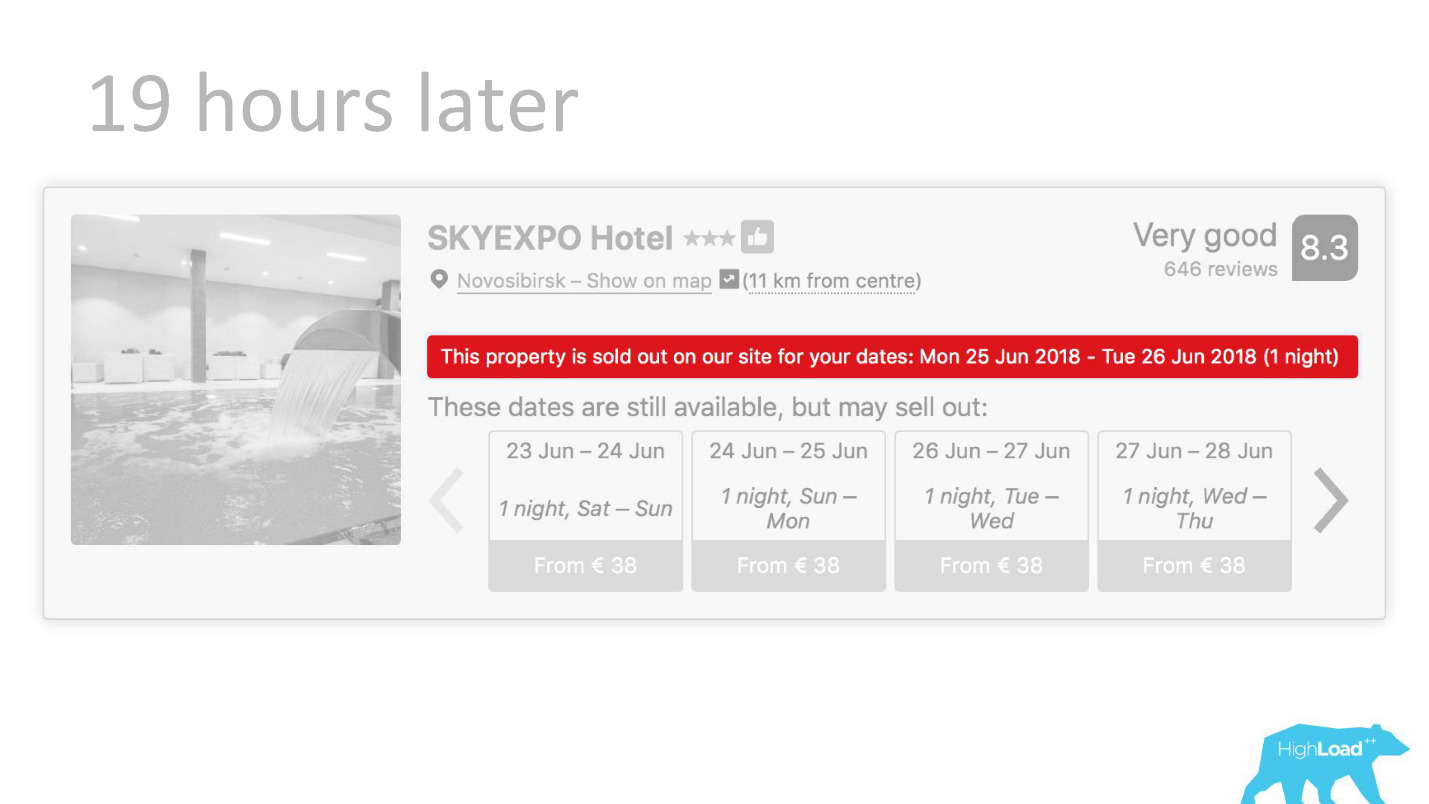
Ou, par exemple, - le badge "Offre favorable". Ici, nous essayons de formaliser le subjectif: qu'est-ce qu'une offre si avantageuse. Comment comprendre que les prix fixés par l'hôtel pour ces dates sont bons? Après tout, cela, en plus du prix, dépend de nombreux facteurs, tels que des services supplémentaires, et souvent même de raisons externes, si, par exemple, la Coupe du monde ou une grande conférence technique se tient dans cette ville maintenant.
Début de la mise en œuvre
Revenons en arrière il y a quelques années, en 2015. Certains des produits dont j'ai parlé existent déjà. De plus, le système dont je vais parler aujourd'hui ne l'est pas encore. Comment s'est déroulée la mise en œuvre à ce moment-là? Franchement, les choses n'étaient pas très. Le fait est que nous avons eu un énorme problème, dont une partie technique et une partie organisationnelle.
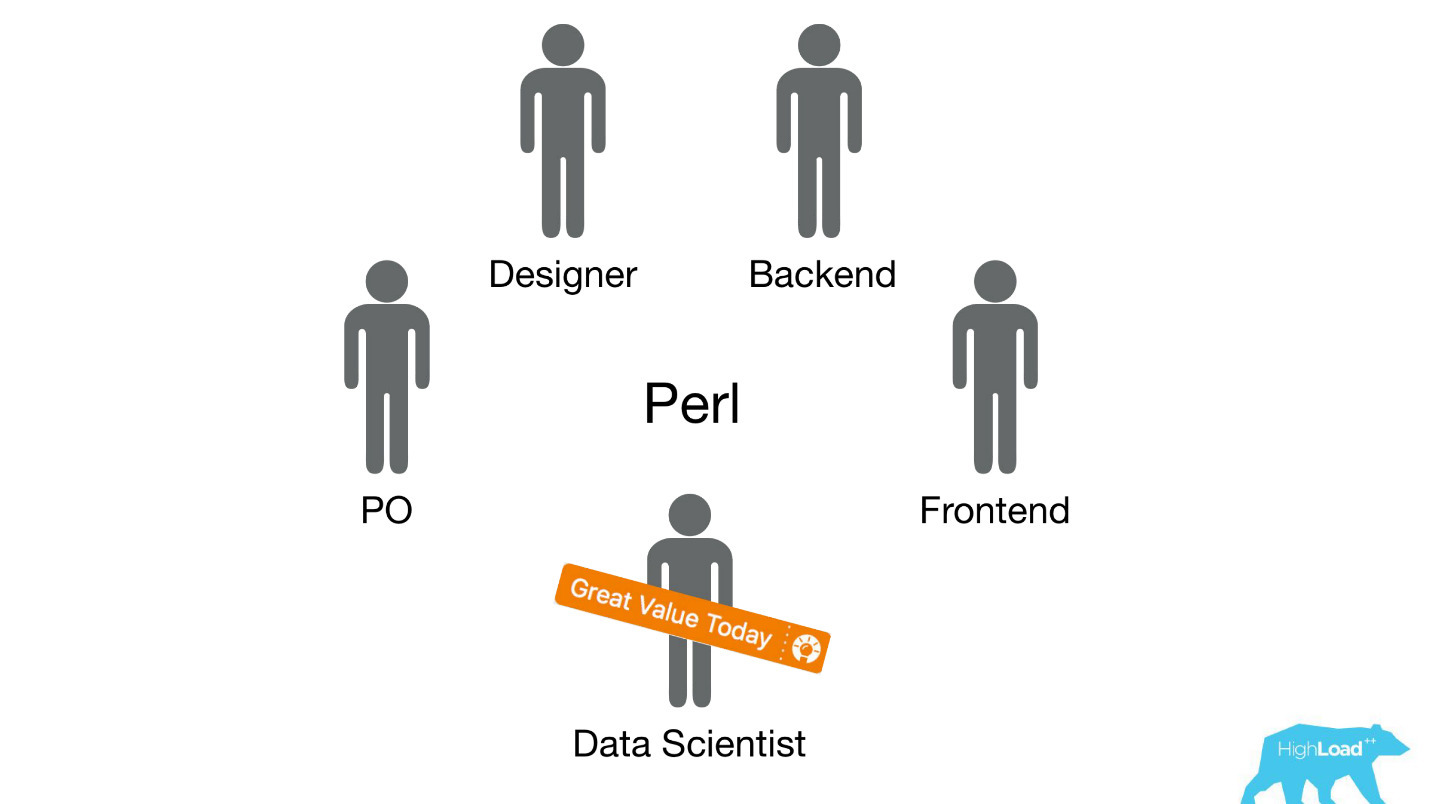
Nous avons envoyé des scientifiques des données à des équipes interfonctionnelles existantes qui travaillent sur un problème d'utilisateur spécifique et nous nous attendions à ce qu'elles améliorent le produit d'une manière ou d'une autre.
Le plus souvent, ces pièces du produit ont été construites sur la pile Perl. Il y a un problème évident avec Perl - il n'est pas conçu pour un calcul intensif, et notre backend est déjà chargé avec d'autres choses. De plus, le développement de systèmes sérieux qui résoudraient ce problème n'a pas pu être priorisé au sein de l'équipe, car l'équipe se concentre sur la résolution d'un problème utilisateur et non sur la résolution d'un problème utilisateur à l'aide du machine learning. Par conséquent, le Product Owner (PO) serait très opposé à cela.
Voyons comment cela s'est produit alors.
Il n'y avait que deux options - je le sais à coup sûr, car à l'époque je travaillais dans une telle équipe et aidais les Data Scientists à amener leurs premiers modèles au combat.
La première option a été la
matérialisation des prédictions . Supposons qu'il existe un modèle très simple avec seulement deux fonctionnalités:
- pays où se trouve le visiteur;
- la ville dans laquelle il recherche un hôtel.
Nous devons prédire la probabilité d'un événement. Nous venons de faire exploser tous les vecteurs d'entrée: disons, 100 000 villes, 200 pays - un total de 20 millions de lignes dans MySQL. Cela ressemble à une option entièrement fonctionnelle pour la sortie de certains petits systèmes de classement ou d'autres modèles simples à la production.

Une autre option consiste à
intégrer les prédictions directement dans le code principal . Il y a de grandes limites - des centaines, voire des milliers de coefficients - c'est tout ce que nous pouvions nous permettre.

Évidemment, ni l'un ni l'autre ne vous permet de mettre en évidence au moins une sorte de modèle complexe en production. Cela a limité le centre de données et les succès qu'ils ont pu obtenir en améliorant les produits. De toute évidence, ce problème devait être résolu d'une manière ou d'une autre.
Service de prédiction
La première chose que nous avons faite a été un service de prédiction. Probablement, l'architecture la plus simple jamais montrée sur Habré et HighLoad ++ est inférieure.
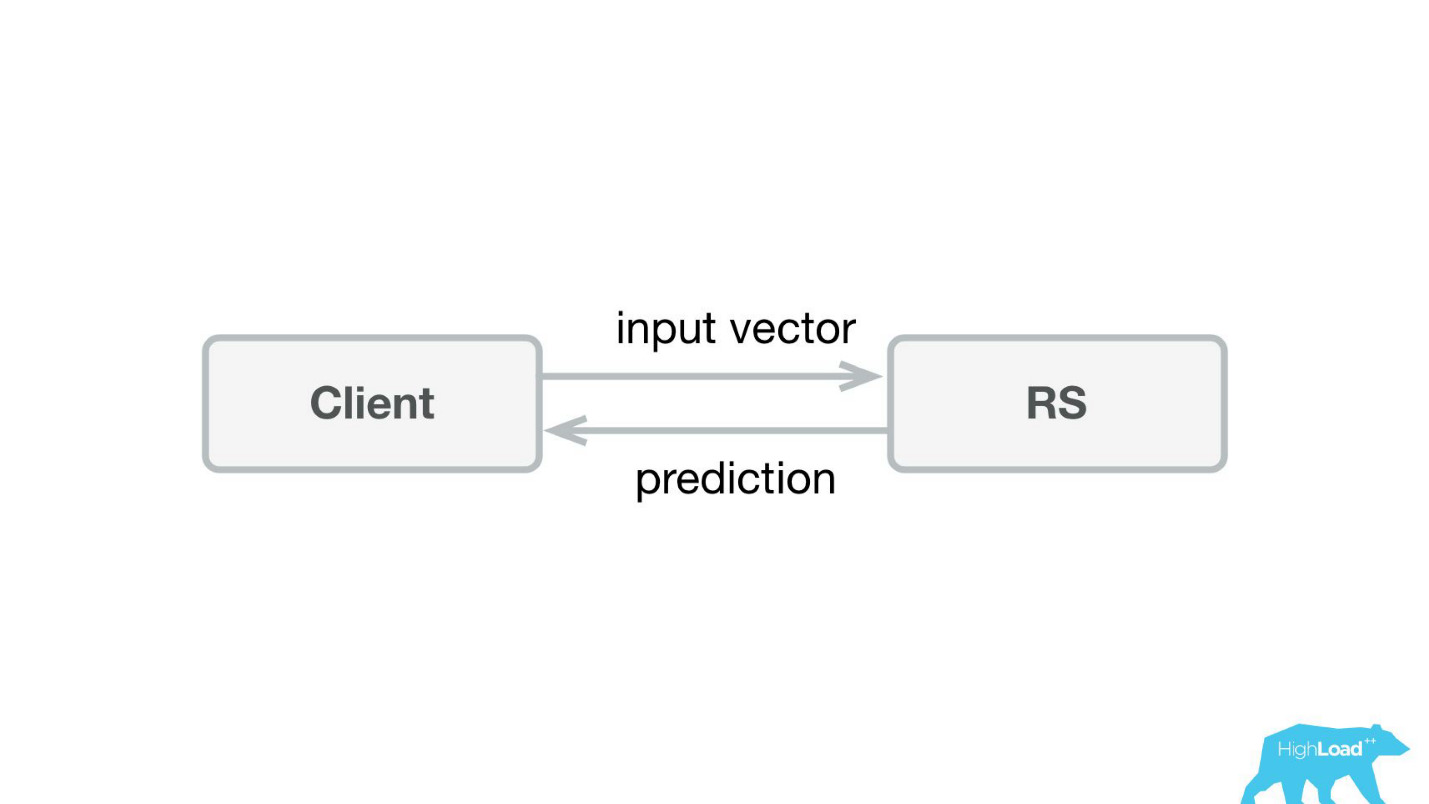
Nous avons écrit une petite application dans Scala + Akka + Spray qui a simplement pris les vecteurs entrants et renvoyé la prédiction. En fait, je suis un peu rusé - le système était un peu plus compliqué, car nous devions en quelque sorte le surveiller et le déployer. En réalité, tout ressemblait à ceci:
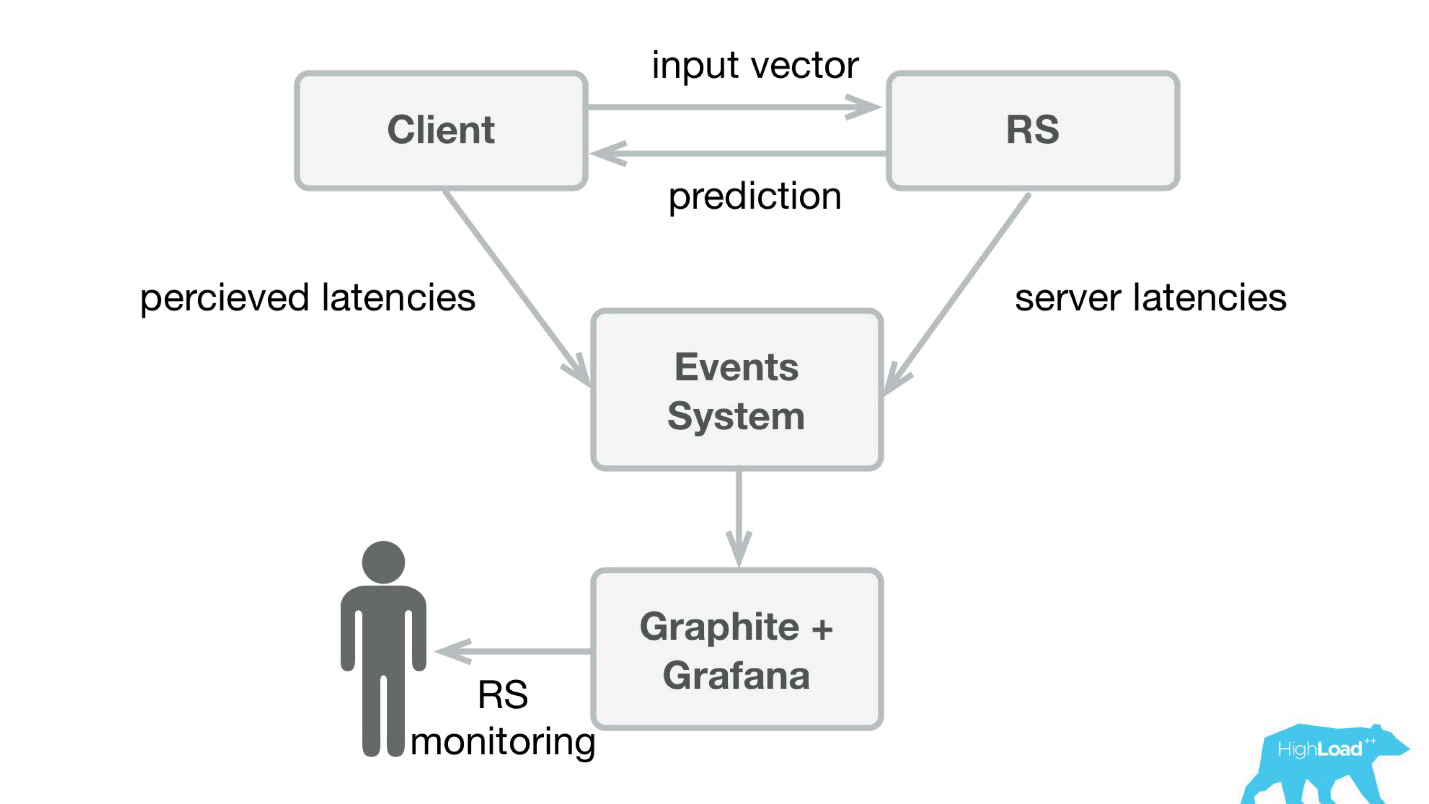
Booking.com a un système d'événements - quelque chose comme un magazine pour tous les systèmes. Il est très facile d'y écrire et ce flux est très simple à rediriger. Au début, nous devions envoyer des données de télémétrie client à Graphite et Grafana avec des latences perçues et des informations détaillées du côté serveur.

Nous avons créé des bibliothèques clientes simples pour Perl - avons caché tout le RPC dans un appel local, y avons placé plusieurs modèles et le service a commencé à décoller. Vendre un tel produit était assez simple, car nous avons eu l'occasion
d'introduire des modèles plus complexes et de passer beaucoup moins de temps .
Les scientifiques des données ont commencé à travailler avec beaucoup moins de restrictions et, dans certains cas, le travail des backders a été réduit à une seule ligne.
Prédictions des produits
Mais revenons brièvement à la façon dont nous avons utilisé ces prédictions dans le produit.
Il existe un modèle qui fait des prédictions basées sur des faits connus. Sur la base de cette prédiction, nous modifions en quelque sorte l'interface utilisateur. Bien sûr, ce n'est pas le seul scénario d'utilisation de l'apprentissage automatique dans notre entreprise, mais assez courant.
Quel est le problème du lancement de telles fonctionnalités? Le fait est que ce sont deux choses dans une bouteille: un modèle et un changement dans l'interface utilisateur. Il est très difficile de séparer les effets des deux.
Imaginez le lancement de l'insigne «Offre favorable» dans le cadre d'une expérience AB. S'il ne décolle pas - il n'y a pas de changement statistiquement significatif dans les métriques cibles - on ne sait pas quel est le problème: un badge incompréhensible, petit et discret ou un mauvais modèle.
De plus, les modèles peuvent se dégrader, et il peut y avoir plusieurs raisons à cela. Ce qui a fonctionné hier ne fonctionne pas nécessairement aujourd'hui. De plus, nous sommes constamment en mode démarrage à froid, connectant constamment de nouvelles villes et hôtels, des gens de nouvelles villes viennent à nous. Nous devons en quelque sorte comprendre que le modèle se généralise toujours bien dans ces parties de l'espace entrant.

Le cas le plus probablement le plus récemment connu de dégradation du modèle a été l'histoire d'Alex. Très probablement, à la suite d'un recyclage, elle a commencé à comprendre des bruits aléatoires, comme une demande de rire, et a commencé à rire la nuit, effrayant les propriétaires.
Surveillance des prévisions
Afin de suivre les prédictions, nous avons légèrement modifié notre système (schéma ci-dessous). De la même manière, à partir du système d'événements, nous avons redirigé le flux vers Hadoop et commencé à enregistrer, en plus de tout ce que nous avons enregistré auparavant, tous les vecteurs d'entrée et toutes les prédictions faites par notre système. Ensuite, en utilisant Oozie, nous les avons agrégés dans MySQL et à partir de là, nous les avons montrés avec une petite application Web à ceux qui sont intéressés par une sorte de caractéristiques qualitatives des modèles.
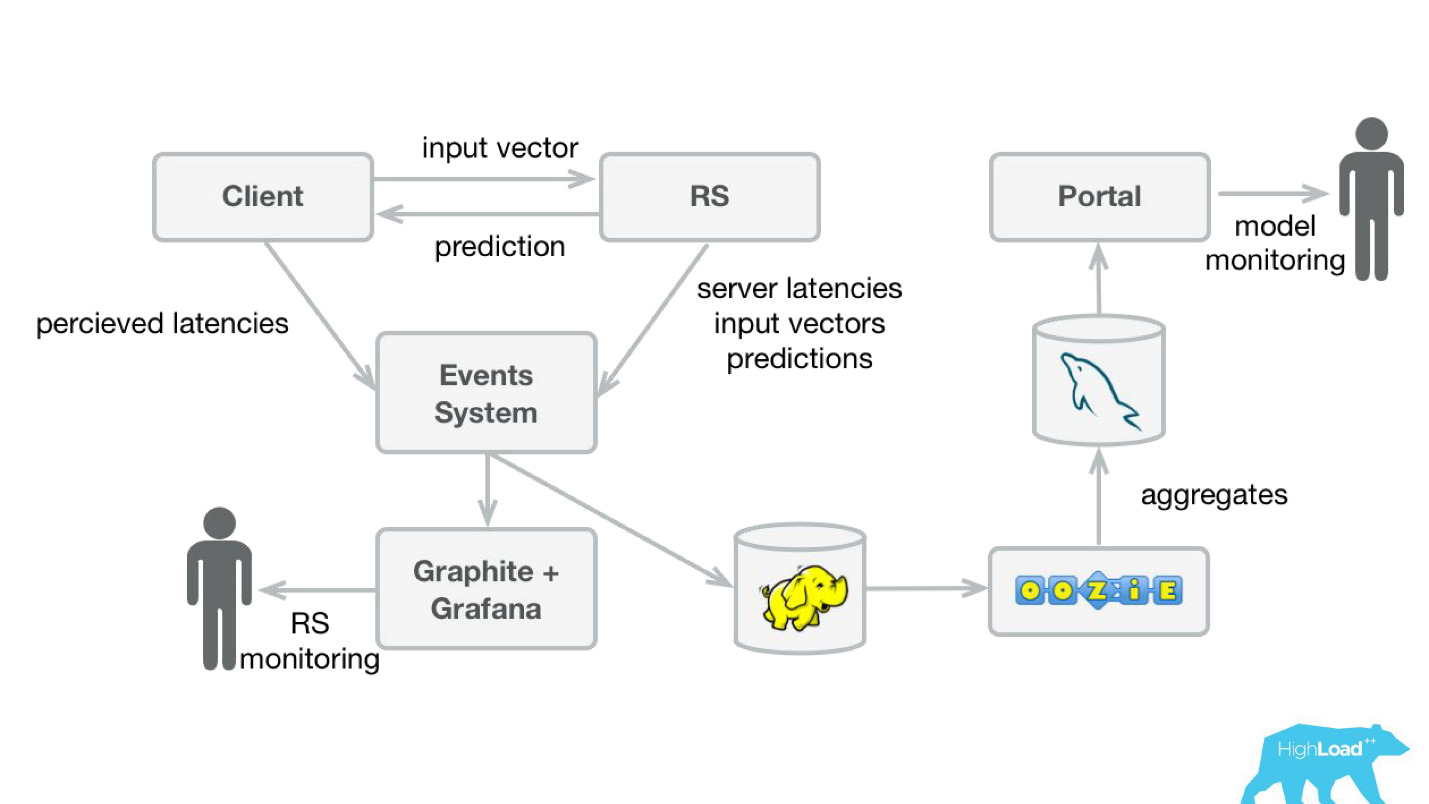
Cependant, il est important de savoir quoi montrer là-bas. Le fait est que dans notre cas, il est très difficile de calculer les métriques habituelles utilisées dans la formation des modèles, car souvent nous avons un énorme retard dans les étiquettes.
Considérez ceci comme un exemple. Nous voulons prédire si l'utilisateur part en vacances seul ou en famille. Nous avons besoin de cette prédiction lorsqu'une personne choisit un hôtel, mais nous ne pouvons découvrir la vérité qu'en un an. A peine parti en vacances, l'internaute recevra une invitation à laisser un avis, où il y aura entre autres une question de savoir s'il était seul ou avec sa famille.
Autrement dit, vous devez stocker quelque part toutes les prévisions faites au cours de l'année, et même pour pouvoir trouver rapidement des correspondances avec les étiquettes entrantes. Cela ressemblait à un investissement très sérieux, peut-être même lourd. Par conséquent, jusqu'à ce que nous résolvions ce problème, nous avons décidé de faire quelque chose de plus simple.
Ce «plus simple» s'est avéré n'être qu'un
histogramme des prédictions faites par le modèle.
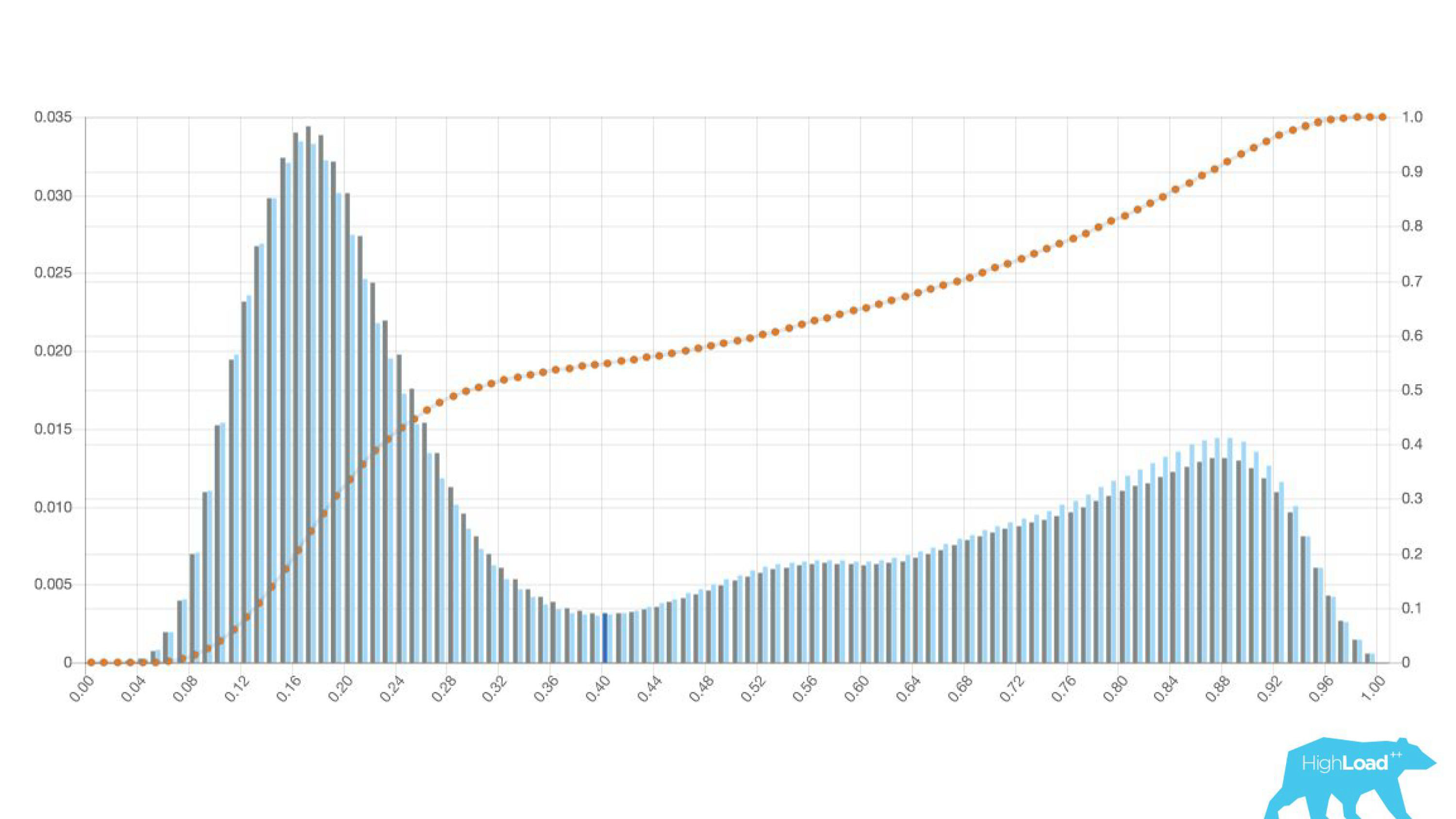
Ci-dessus sur le graphique est une régression logistique qui prédit si l'utilisateur changera la date de son voyage ou non. On peut voir qu'elle divise bien les utilisateurs en deux classes: à gauche, la colline est celle qui ne le fera pas; la colline à droite est celle qui le fait.
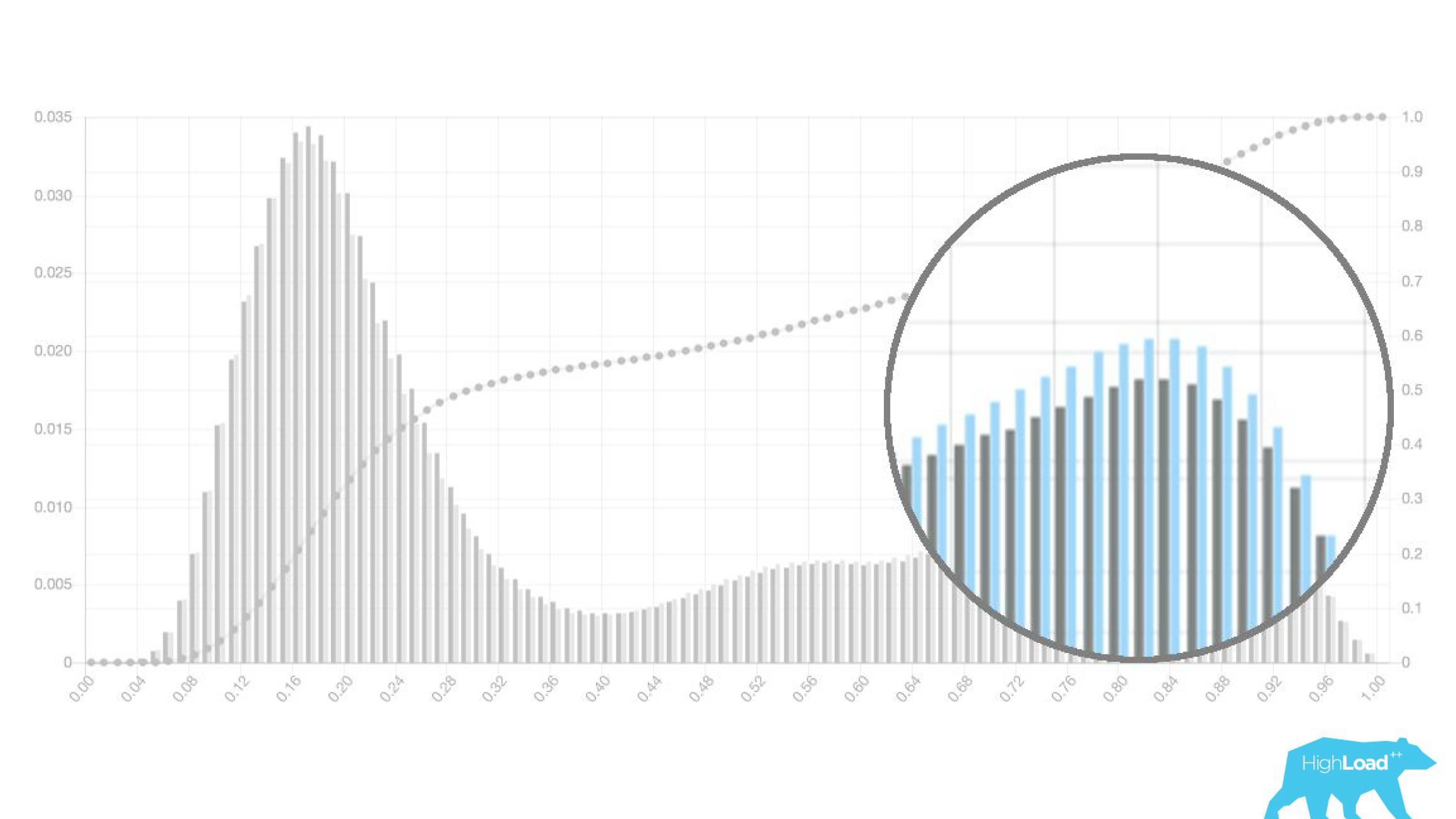
En fait, nous montrons même deux graphiques: un pour la période actuelle et l'autre pour le précédent. On voit clairement que cette semaine (il s'agit d'un graphique hebdomadaire) le modèle prédit un changement de dates un peu plus souvent. Il est difficile de dire avec certitude s'il s'agit de la saisonnalité ou de la même dégradation au fil du temps.
Cela a entraîné un changement dans le travail des datacientes, qui ont cessé d'engager d'autres personnes et ont commencé à itérer leurs modèles plus rapidement. Ils ont envoyé des modèles en production avec des ingénieurs back-end. Autrement dit, les vecteurs ont été collectés, le modèle a fait une prédiction, mais ces prédictions n'ont été utilisées d'aucune façon.
Dans le cas d'un badge, nous n'avons simplement rien montré, comme auparavant, mais collecté des statistiques. Cela nous a permis de ne pas perdre de temps à l'avance sur des projets ratés. Nous avons libéré du temps pour le front-end et les concepteurs pour d'autres expériences.
Tant que le centre de données n'est pas sûr que le modèle fonctionne comme il le souhaite, il n'implique tout simplement pas les autres dans ce processus.Il est intéressant de voir comment les graphiques changent dans différentes sections.
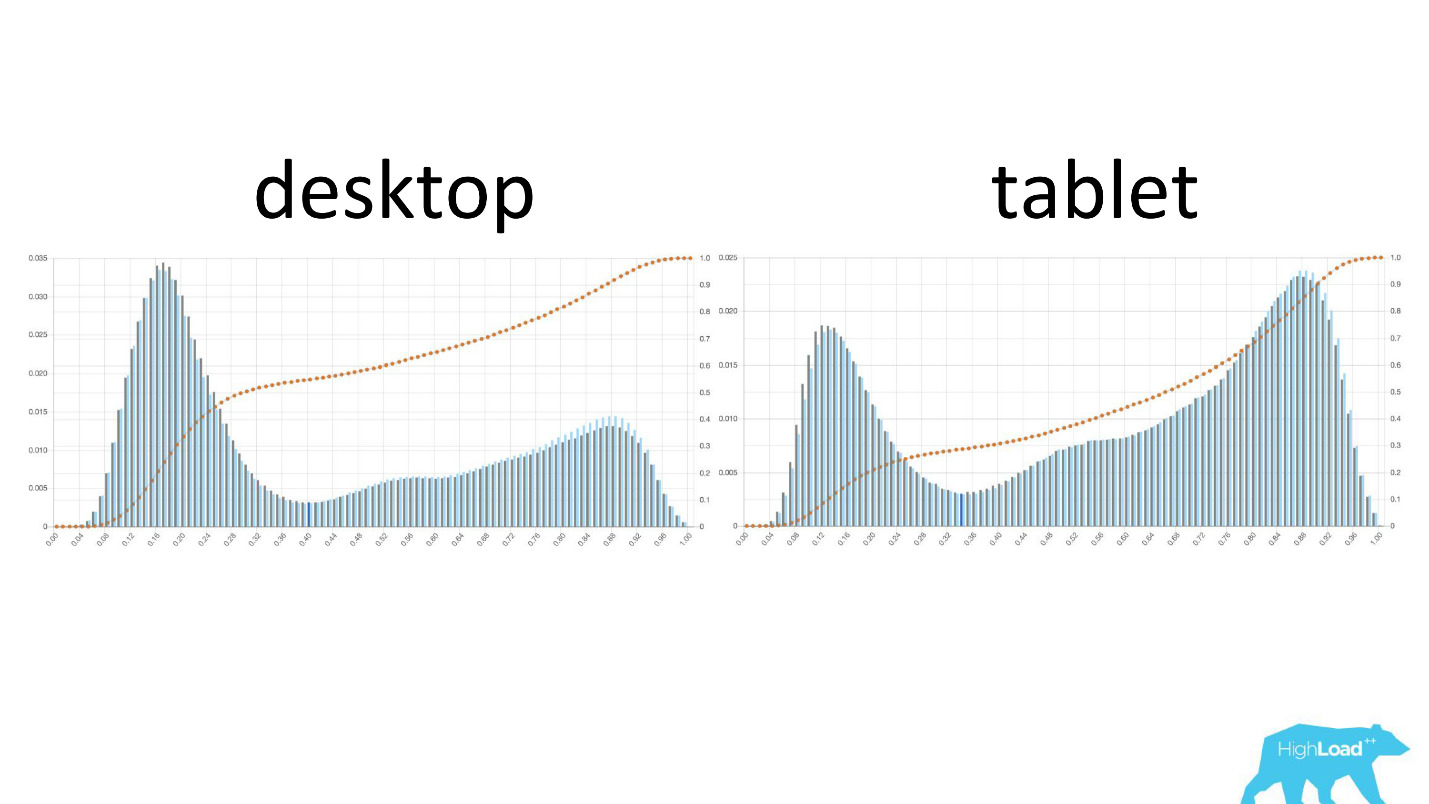
À gauche, la probabilité de changer les dates sur le bureau, à droite sur les tablettes. On voit clairement que sur les tablettes, le modèle prédit un changement de dates plus probable. Cela est probablement dû au fait que la tablette est souvent utilisée pour la planification des voyages et moins souvent pour les réservations.
Il est également intéressant de voir comment ces graphiques changent à mesure que les utilisateurs se déplacent dans l'entonnoir de vente.
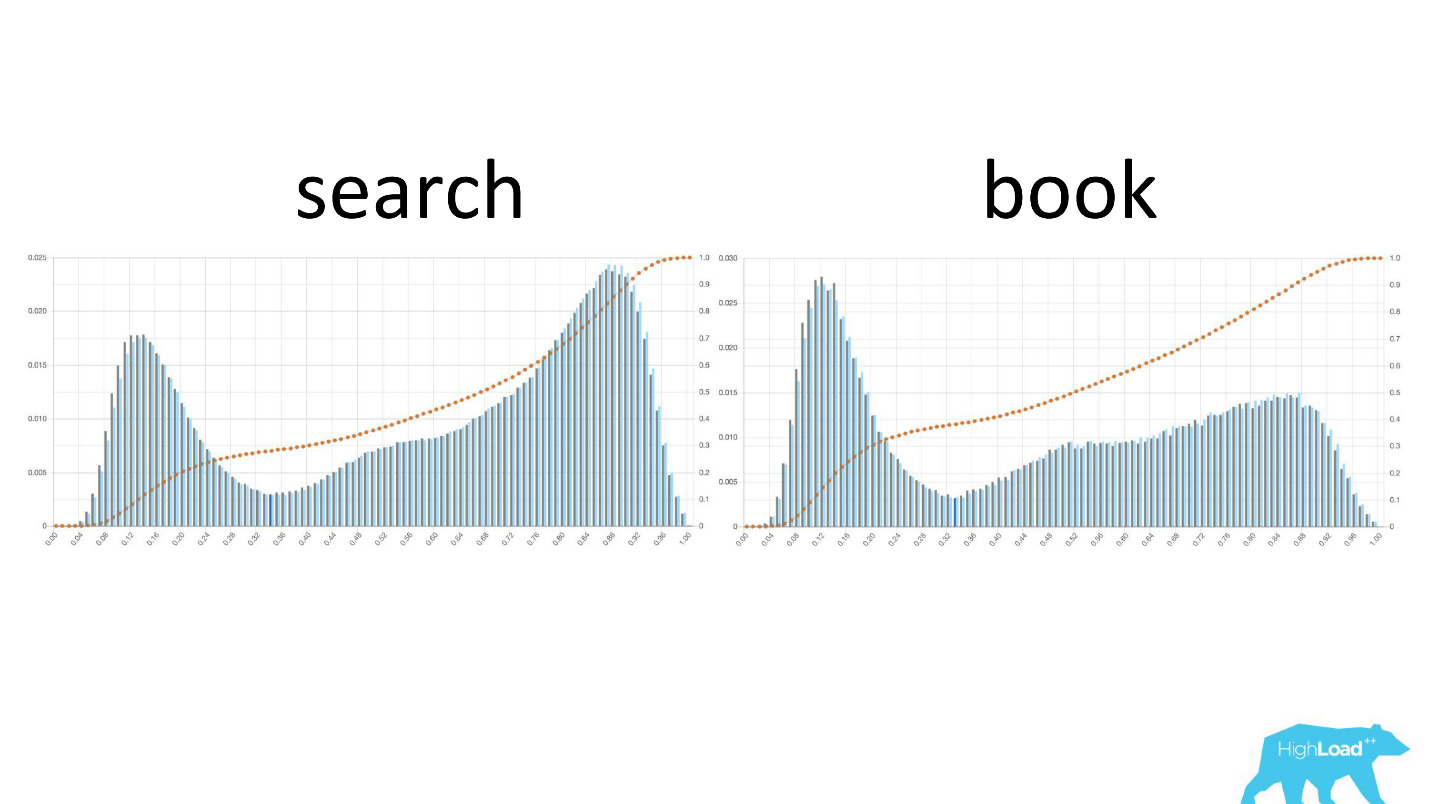
A gauche, la probabilité de changer les dates sur la page de recherche, à droite sur la première page de réservation. On peut voir qu'un nombre beaucoup plus important de personnes qui ont déjà décidé de leurs dates accèdent à la page de réservation.
Mais ce sont de bons graphismes. À quoi ressemblent les mauvais? De manières très différentes. Parfois, c'est juste du bruit, parfois c'est une énorme colline, ce qui signifie que le modèle ne peut pas séparer efficacement deux classes de prédictions.

Ce sont parfois d'énormes pics.
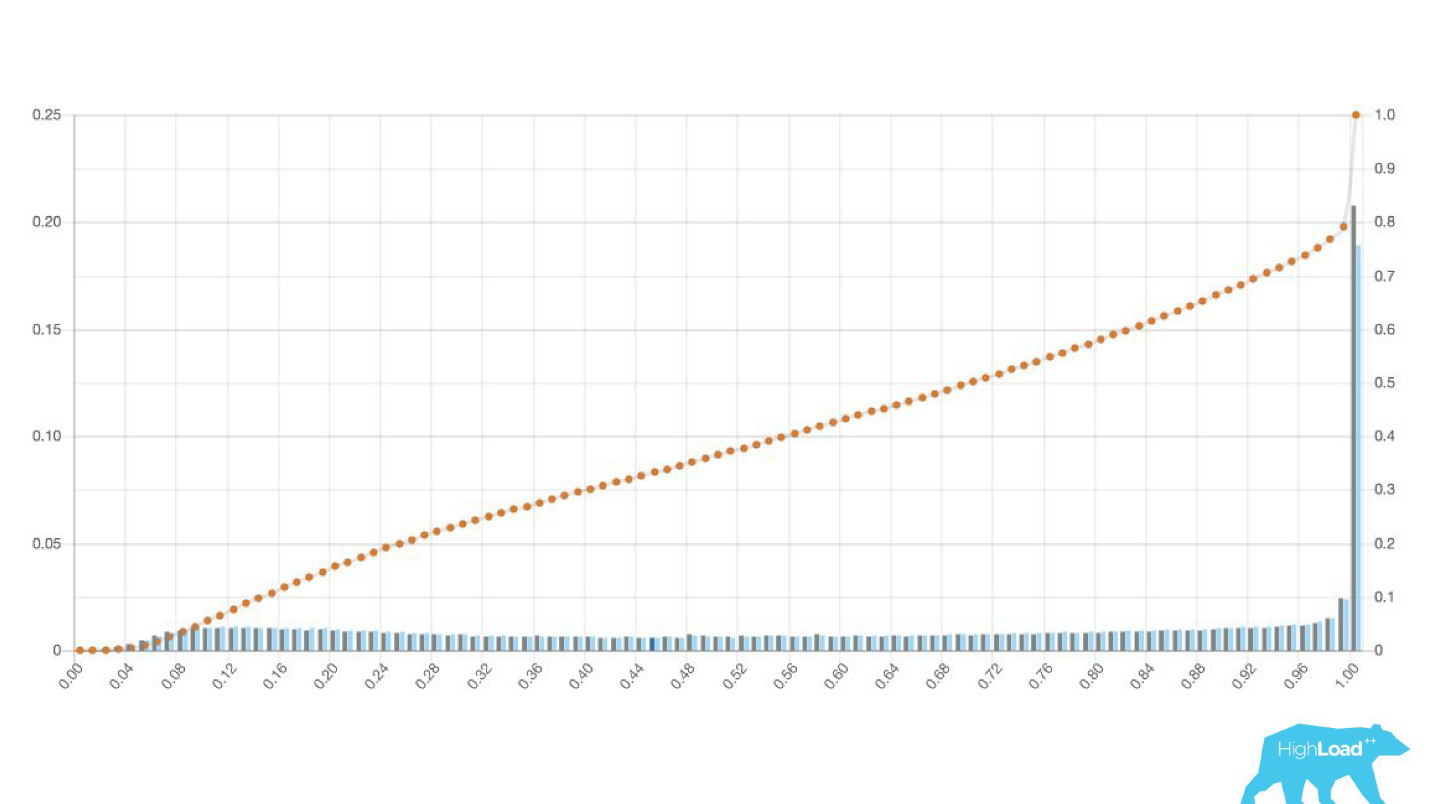
C'est aussi une régression logistique, et jusqu'à un certain point, il a montré une belle image avec deux collines, mais un matin, c'est devenu comme ça.
Afin de comprendre ce qui s'est passé à l'intérieur, vous devez comprendre comment la régression logistique est calculée.
Référence rapide
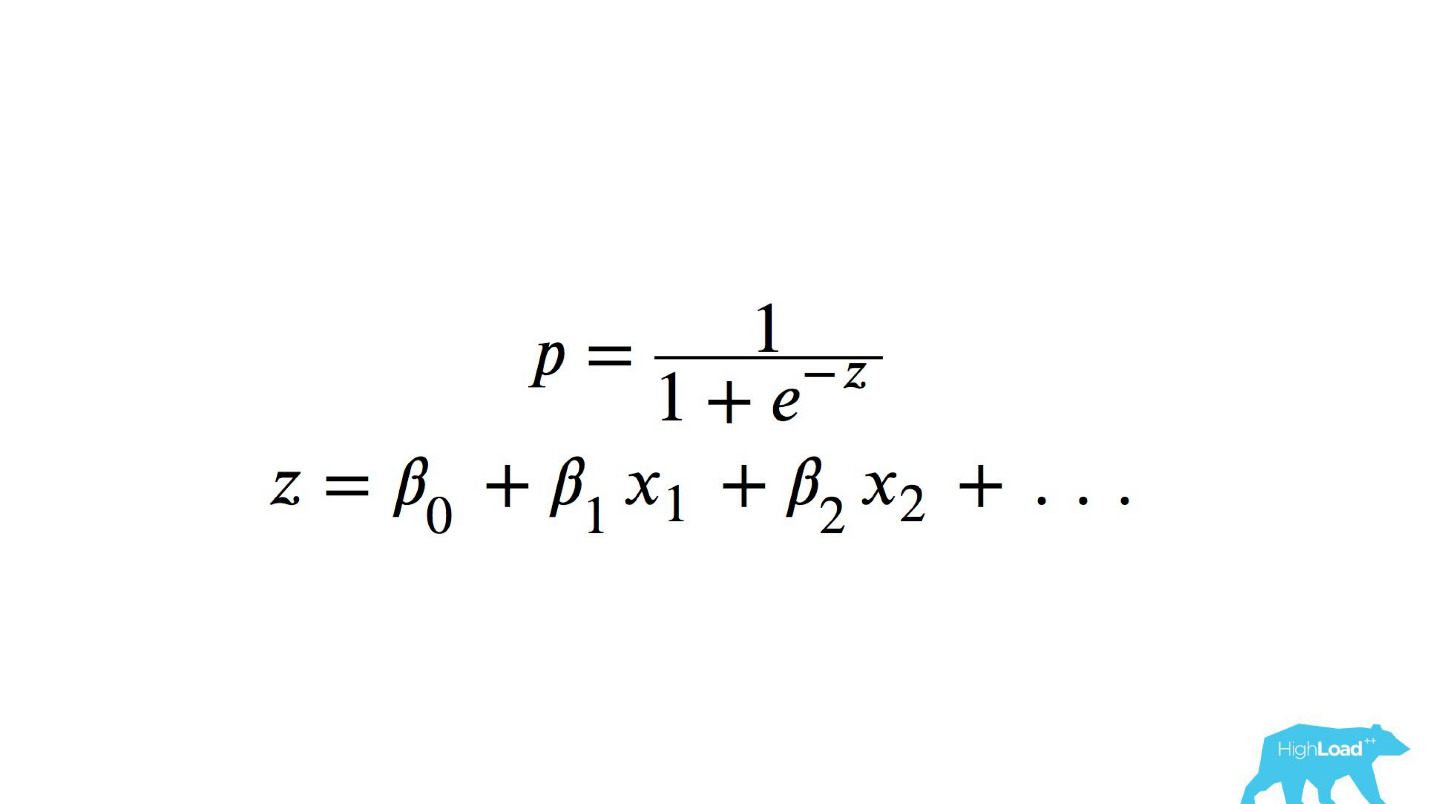
Il s'agit d'une fonction logistique du produit scalaire, où x
n sont quelques caractéristiques. L'une de ces caractéristiques était le prix d'une nuit d'hôtel (en euros).
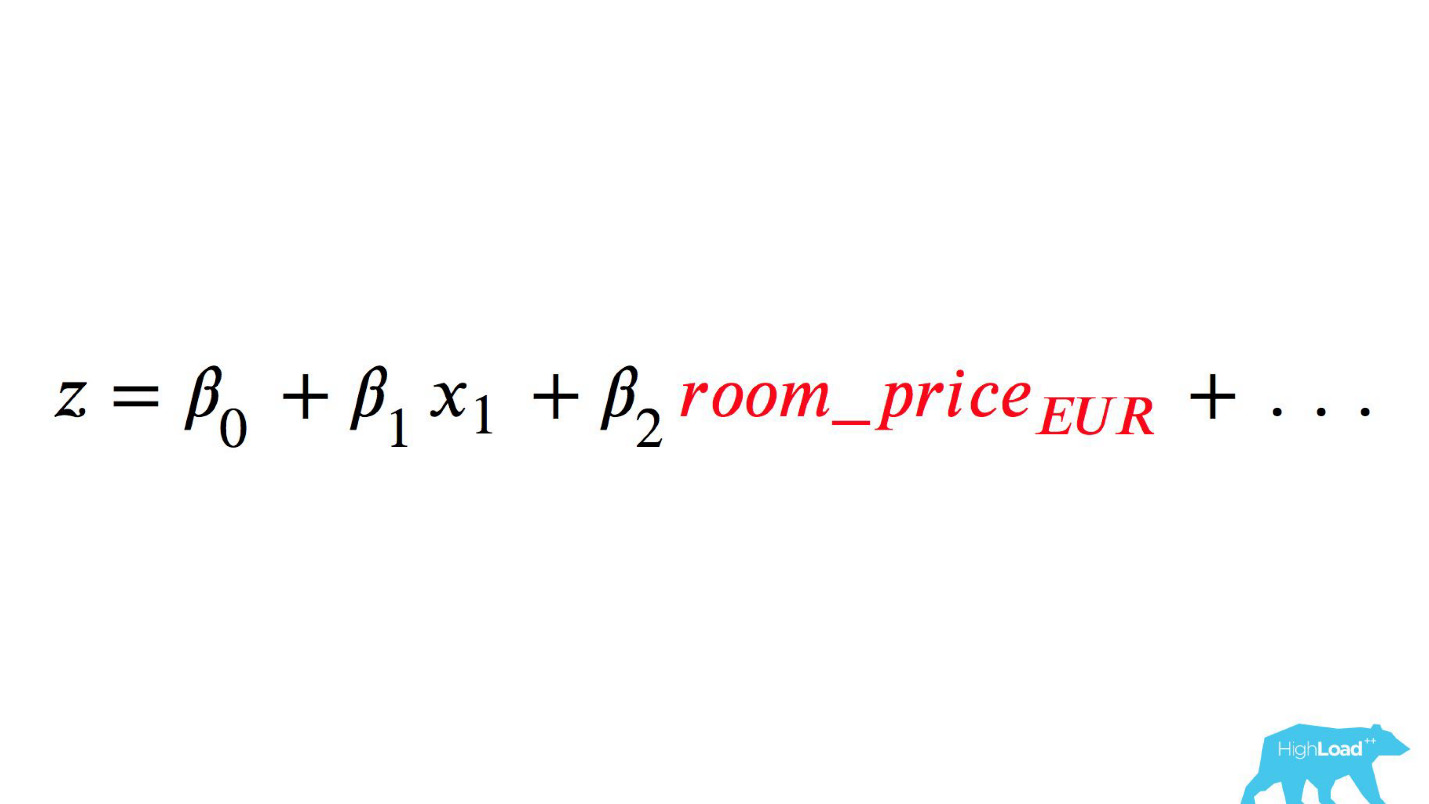
Appeler ce modèle serait quelque chose comme ceci:
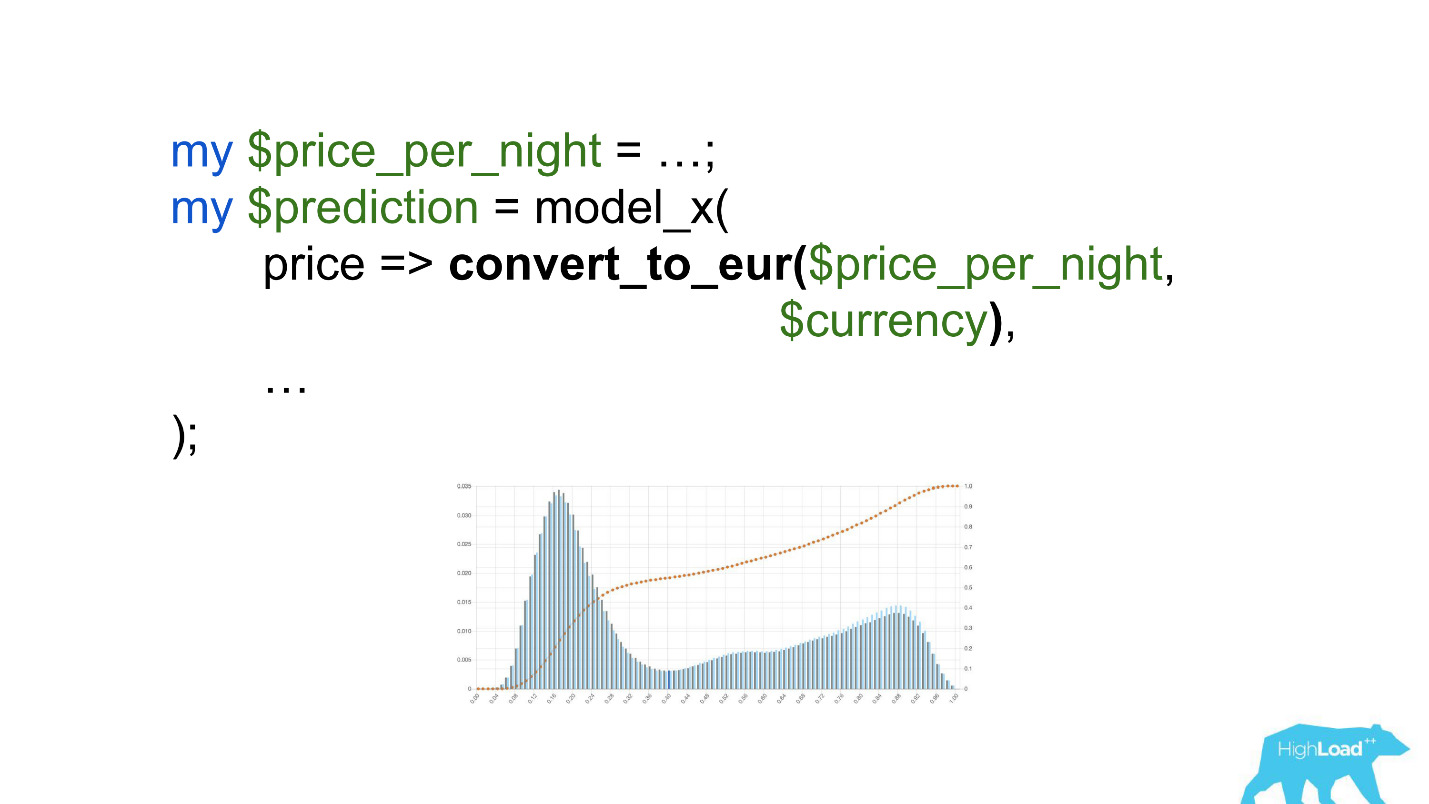
Faites attention à la sélection. Il fallait convertir le prix en euros, mais le développeur a oublié de le faire.
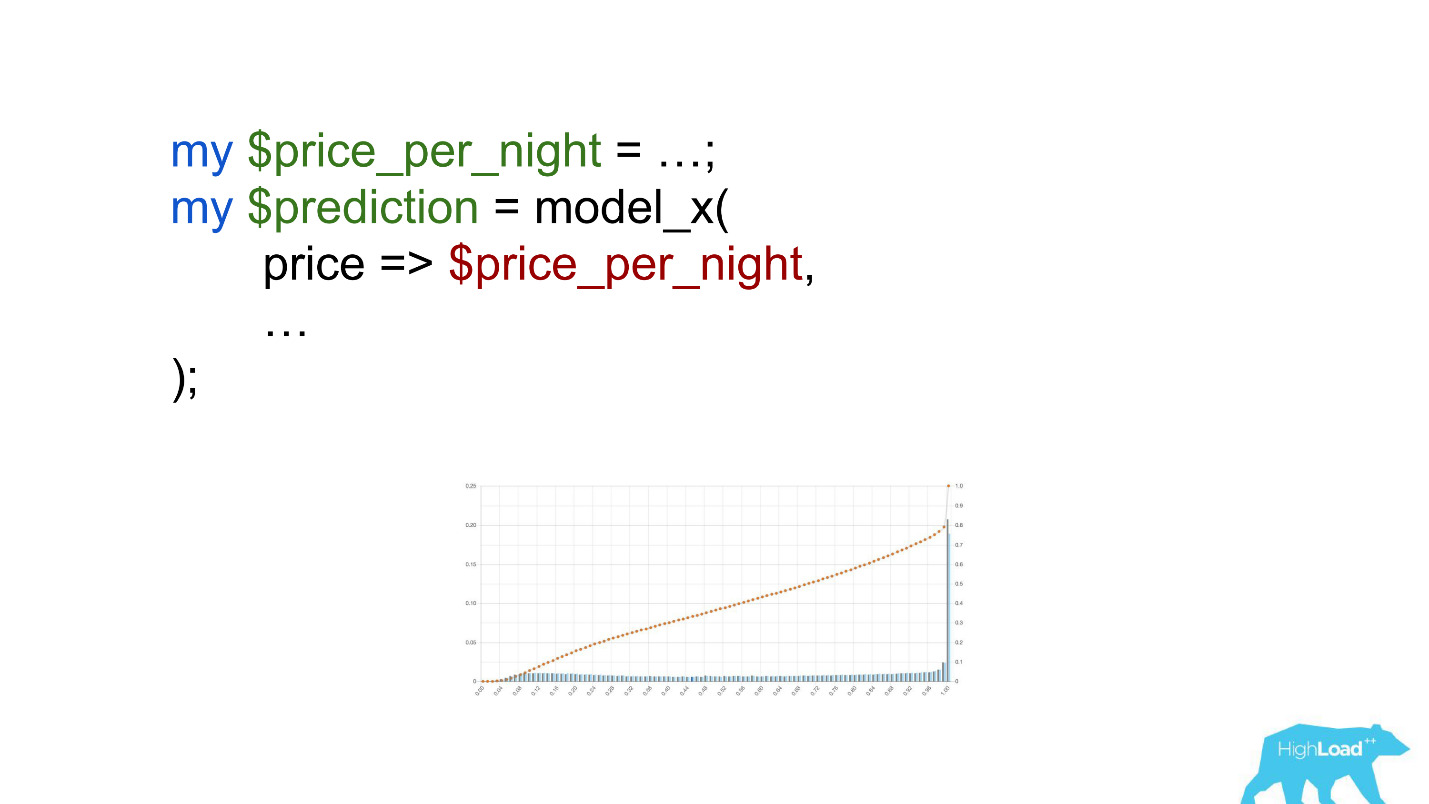
Des devises comme les roupies ou les roubles ont augmenté le produit scalaire à plusieurs reprises et ont donc forcé ce modèle à produire une valeur proche de l'unité, beaucoup plus souvent, que nous voyons sur le graphique.
Valeurs de seuil
Une autre caractéristique utile de ces histogrammes était la possibilité d'un choix conscient et optimal des valeurs de seuil.
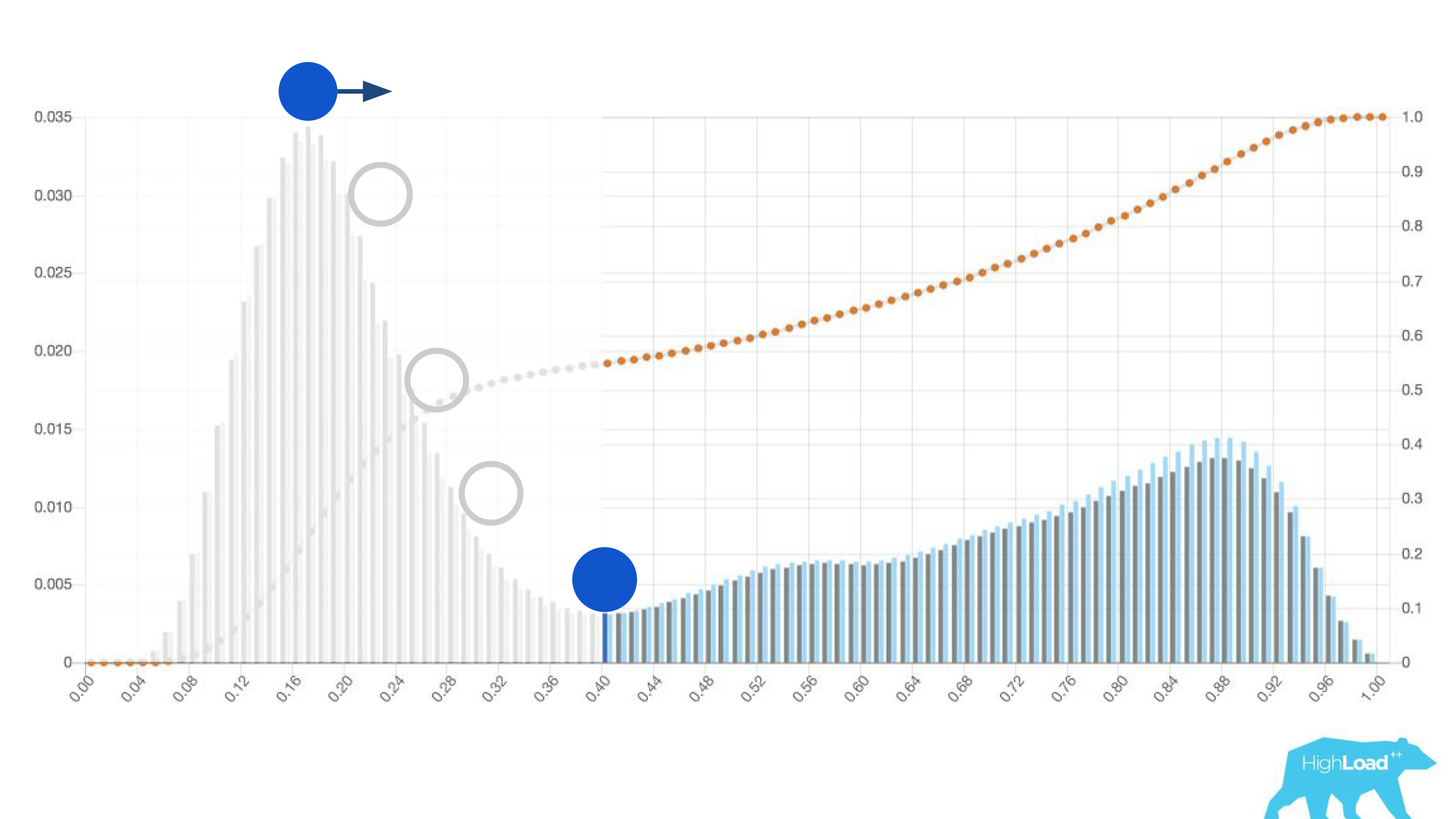
Si vous placez la balle sur la colline la plus haute de cet histogramme, poussez-la et imaginez où elle s'arrêtera, ce sera le point optimal pour la séparation des classes. Tout à droite est une classe, tout à gauche en est une autre.
Cependant, si vous commencez à déplacer ce point, vous pouvez obtenir des effets très intéressants. Supposons que nous voulons exécuter une expérience qui, si le modèle dit oui, modifie en quelque sorte l'interface utilisateur. Si vous déplacez ce point vers la droite, l'audience de notre expérience est réduite. Après tout, le nombre de personnes qui ont reçu cette prédiction est la zone sous la courbe. Cependant, dans la pratique, la précision des prévisions est beaucoup plus élevée. De même, s'il n'y a pas assez de puissance statique, vous pouvez augmenter l'audience de votre expérience, mais réduire la précision des prédictions.
En plus des prédictions elles-mêmes, nous avons commencé à surveiller les valeurs d'entrée dans les vecteurs.
Un encodage à chaud
La plupart des fonctionnalités de nos modèles les plus simples sont catégoriques. Cela signifie qu'il ne s'agit pas de chiffres, mais de certaines catégories: la ville d'où vient l'utilisateur ou la ville dans laquelle il recherche un hôtel. Nous utilisons un codage à chaud et transformons chacune des valeurs possibles en une unité dans un vecteur binaire. Comme au début, nous utilisions uniquement notre propre noyau informatique, il était facile d'identifier les situations où il n'y a pas de place pour la catégorie entrante dans le vecteur entrant, c'est-à-dire que le modèle n'a pas vu ces données pendant la formation.
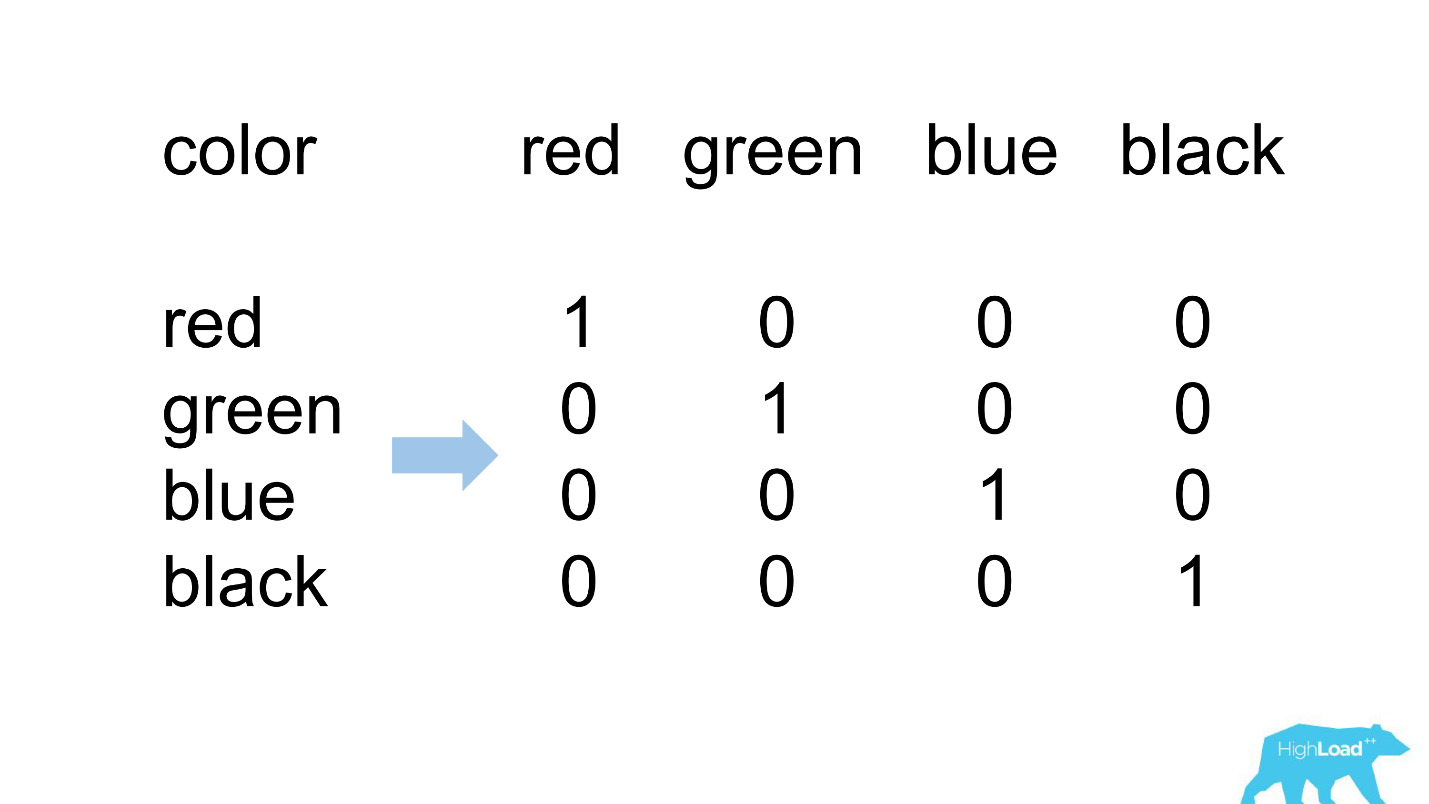
Voici à quoi cela ressemble habituellement.

destination_id - la ville dans laquelle l'utilisateur recherche un hôtel. Naturellement, le modèle n'a pas vu environ 5% des valeurs, car nous connectons constamment de nouvelles villes. visitor_cty_id = 23,32%, car les datacientists omettent parfois consciemment des villes moins communes.
Dans un mauvais cas, cela pourrait ressembler à ceci:

Immédiatement 3 propriétés, 100% des valeurs dont le modèle n'a jamais vu. Le plus souvent, cela se produit en raison de l'utilisation de formats autres que ceux utilisés dans la formation, ou simplement de fautes de frappe banales.
Maintenant, à l'aide de tableaux de bord, nous détectons et corrigeons ces situations très rapidement.
Vitrine d'apprentissage automatique
Parlons d'autres problèmes que nous avons résolus. Après avoir créé les bibliothèques clientes et la surveillance, le service a commencé à prendre de l'ampleur très rapidement. Nous avons été littéralement submergés d'applications de différentes parties de l'entreprise: «Connectons également ce modèle! Mettons à jour l'ancien! " Nous venons de coudre, en fait, tout nouveau développement s'est arrêté.
Nous sommes sortis de la situation en créant
un kiosque en libre-service pour les scientifiques des données . Maintenant, vous pouvez simplement accéder à notre portail, le même que nous avons utilisé au début uniquement pour la surveillance, et littéralement en cliquant sur le bouton charger le modèle en production. Dans quelques minutes, elle travaillera et fera des prédictions.
Il y avait encore un problème.
Booking.com compte environ 200 équipes informatiques. Comment faire savoir à l'équipe dans une partie complètement différente de l'entreprise qu'il existe un modèle qui pourrait les aider? Vous ne savez peut-être tout simplement pas qu'une telle équipe existe. Comment savoir quels modèles existent et comment les utiliser? Traditionnellement, les communications externes de nos équipes sont engagées en PO (Product Owner). Cela ne signifie pas que nous n'avons pas d'autres connexions horizontales, mais PO le fait plus que les autres. Mais il est évident qu'à une telle échelle, la communication individuelle ne se modifie pas. Vous devez y faire quelque chose.
Comment faciliter la communication?Nous avons soudain réalisé que le portail, que nous avons créé exclusivement pour la surveillance, commence progressivement à devenir une vitrine de l'apprentissage automatique au sein de notre entreprise.
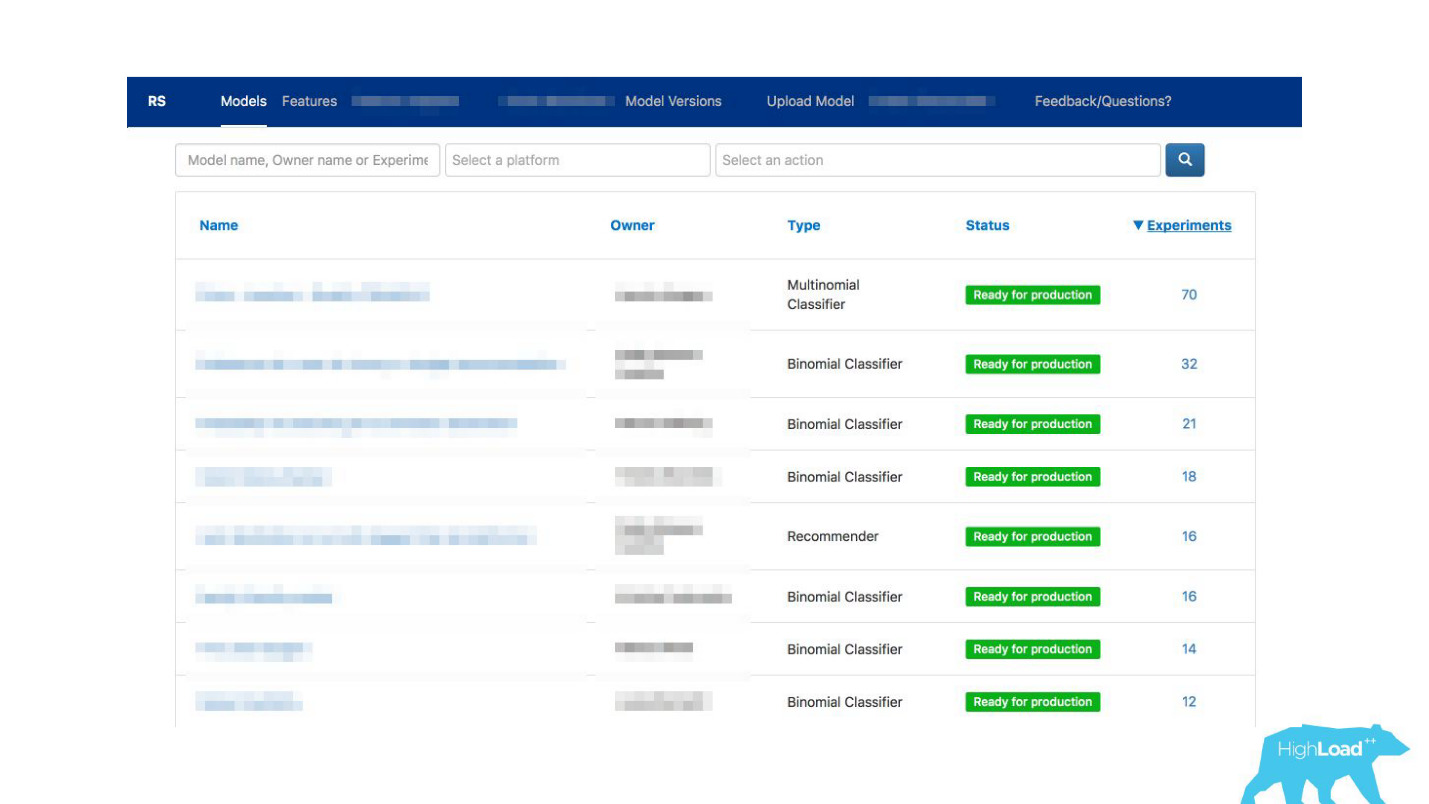
Nous avons permis aux datacientists de décrire leurs modèles en détail. Lorsqu'il y avait beaucoup de modèles, nous avons ajouté des étiquettes de sujet et de zone pour un regroupement pratique.
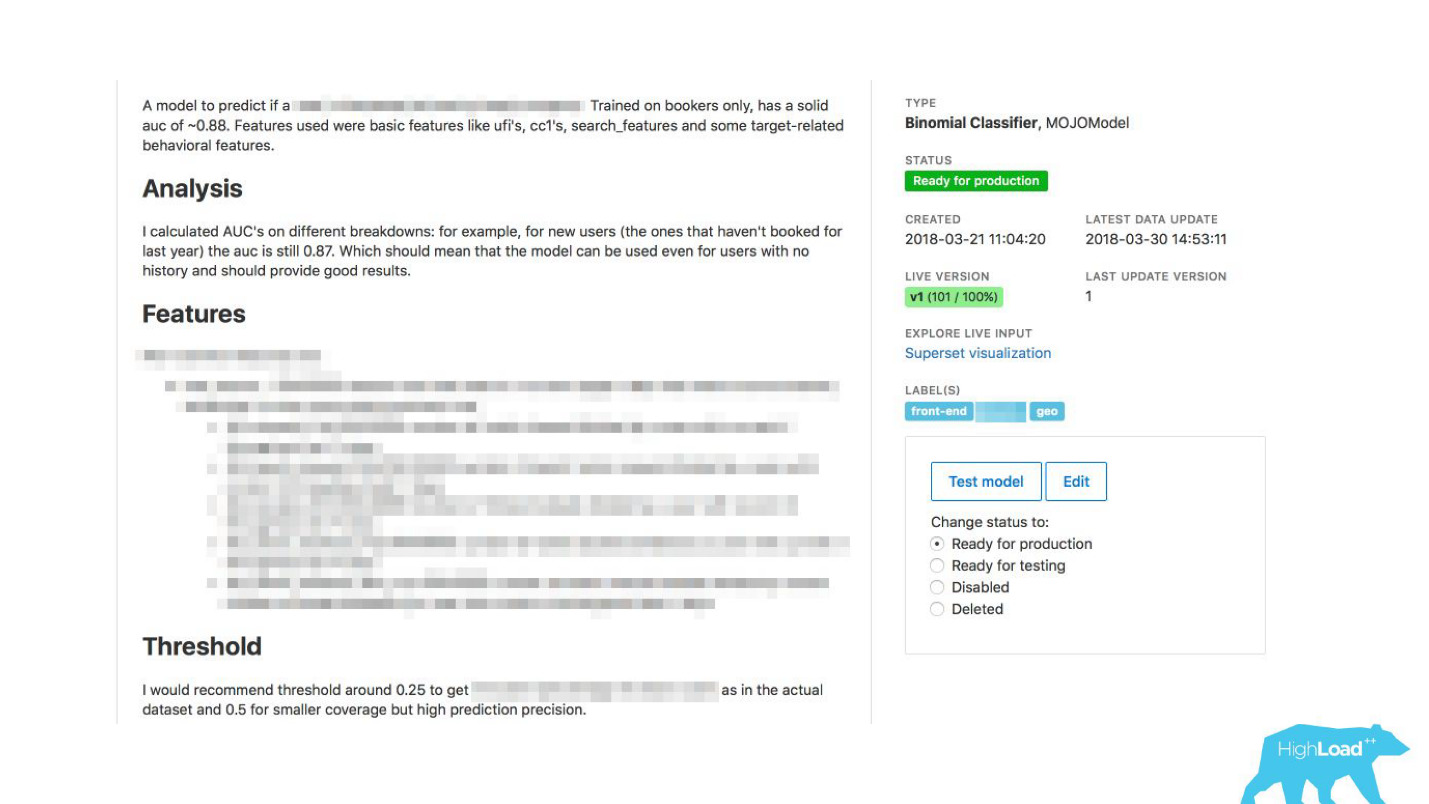
Nous avons lié notre outil à ExperimentTool. Il s'agit d'un produit au sein de notre entreprise qui fournit des expériences A / B et stocke toute l'histoire de l'expérimentation.

Maintenant, avec la description du modèle, vous pouvez également voir ce que les autres équipes ont fait avec ce modèle avant et avec succès. Cela a tout changé.
Sérieusement, cela a changé le fonctionnement de l'informatique, car même dans les situations où il n'y a pas de data scientist dans l'équipe, vous pouvez utiliser le machine learning.
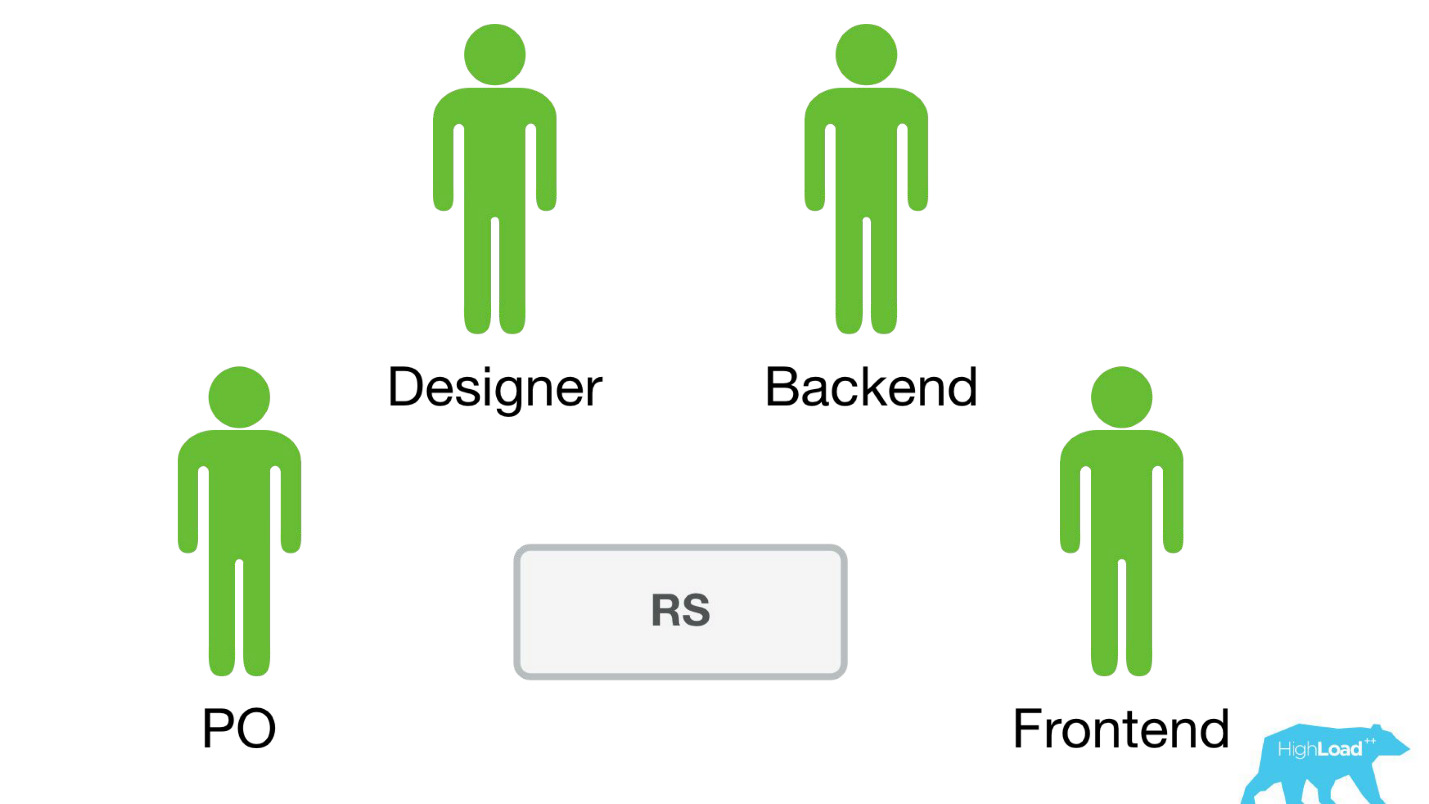
Par exemple, de nombreuses équipes l'utilisent lors de sessions de brainstorming. Lorsqu'ils proposent de nouvelles idées de produits, ils sélectionnent simplement les modèles qui leur conviennent et les utilisent. Rien de compliqué n'est nécessaire pour cela.
Qu'est-ce que cela a renversé pour nous? À l'heure actuelle, au pic, nous fournissons environ 200 000 prédictions par seconde, avec une latence inférieure à 20-30 ms, y compris l'aller-retour HTTP, et le placement de plus de 200 modèles.
Il peut sembler que c'était une promenade si facile dans le parc: nous avons fait un travail formidable, tout fonctionne, tout le monde est content!
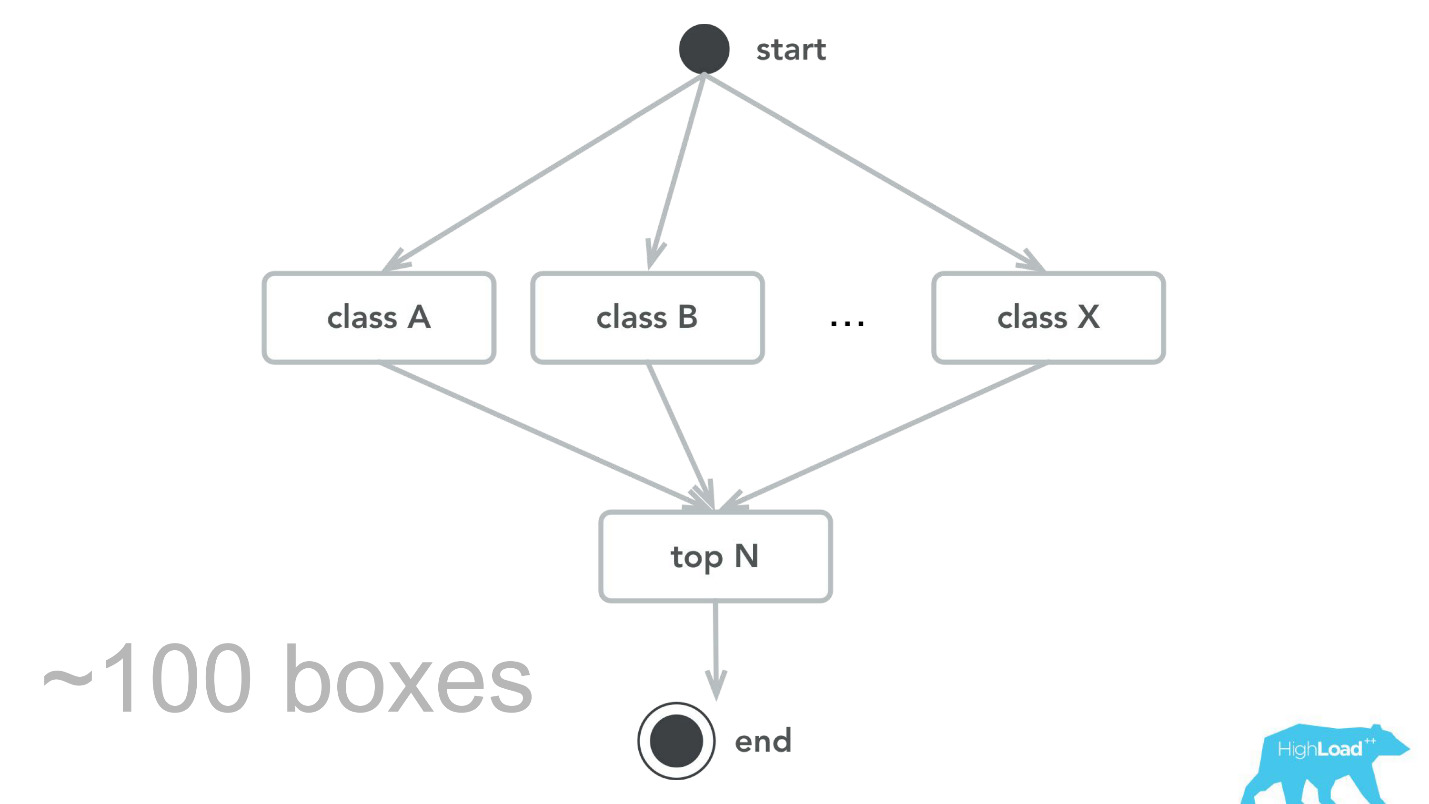
Bien sûr, cela ne se produit pas. Il y a eu des erreurs. Au tout début, par exemple, nous avons posé une petite bombe à retardement. Pour une raison quelconque, nous avons supposé que la plupart de nos modèles seront des systèmes de recommandation avec des vecteurs d'entrée lourds, et la pile Scala + Akka a été choisie précisément parce qu'il est très facile d'organiser des calculs parallèles avec son aide. Mais en réalité, le surcoût de toute cette parallélisation, pour la collecte ensemble, s'est avéré supérieur au gain possible. À un moment donné, nos 100 machines n'ont traité que 100 000 RPS et des pannes se sont produites avec des symptômes assez caractéristiques: l'utilisation du processeur est faible, mais des délais d'attente sont obtenus.
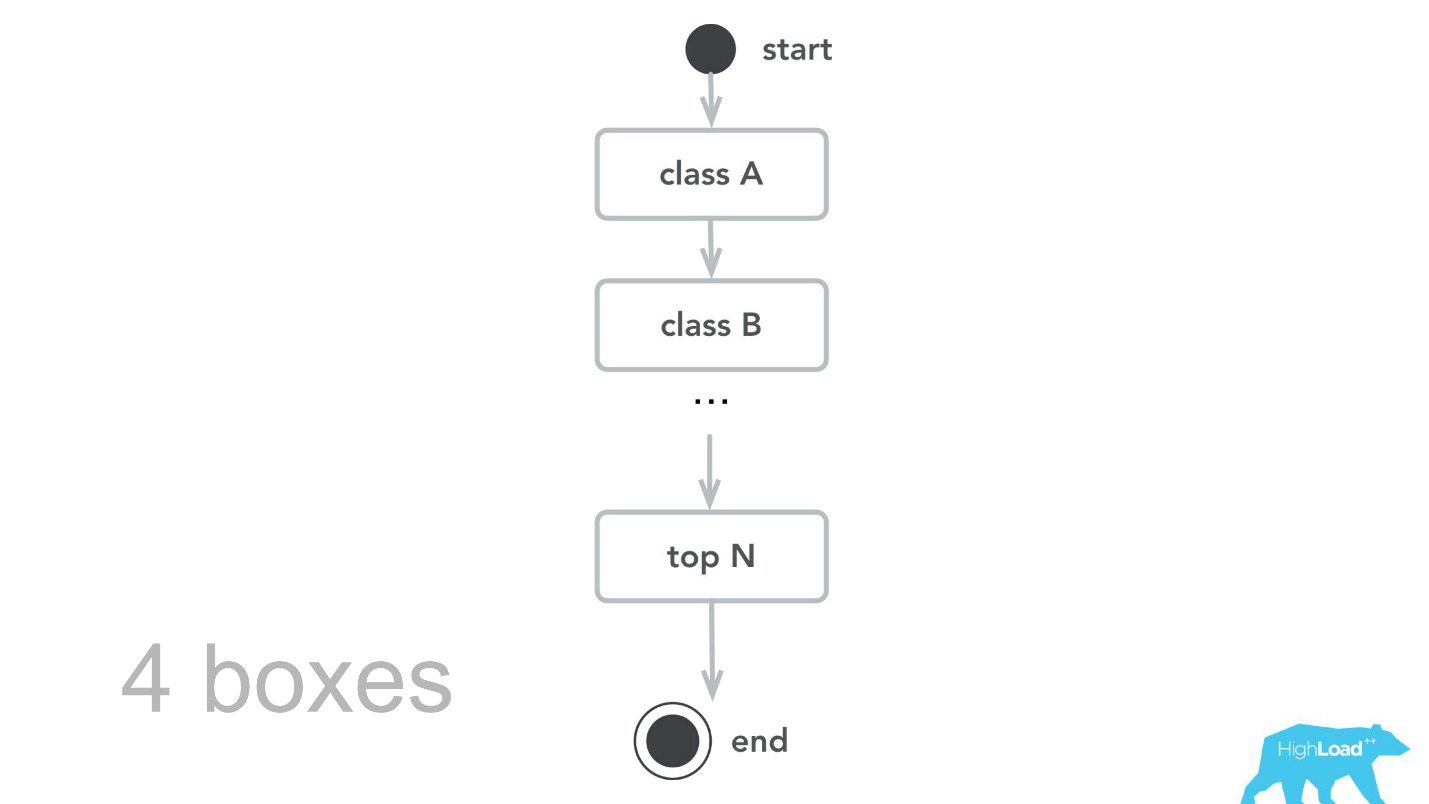
Ensuite, nous sommes revenus à notre cœur de calcul, avons revu, fait des benchmarks et, à la suite des tests de capacité, nous avons appris que pour le même trafic, nous n'avons besoin que de 4 machines. , , -, , , , 100 000 RPS 4 .
- , , . - , , , .
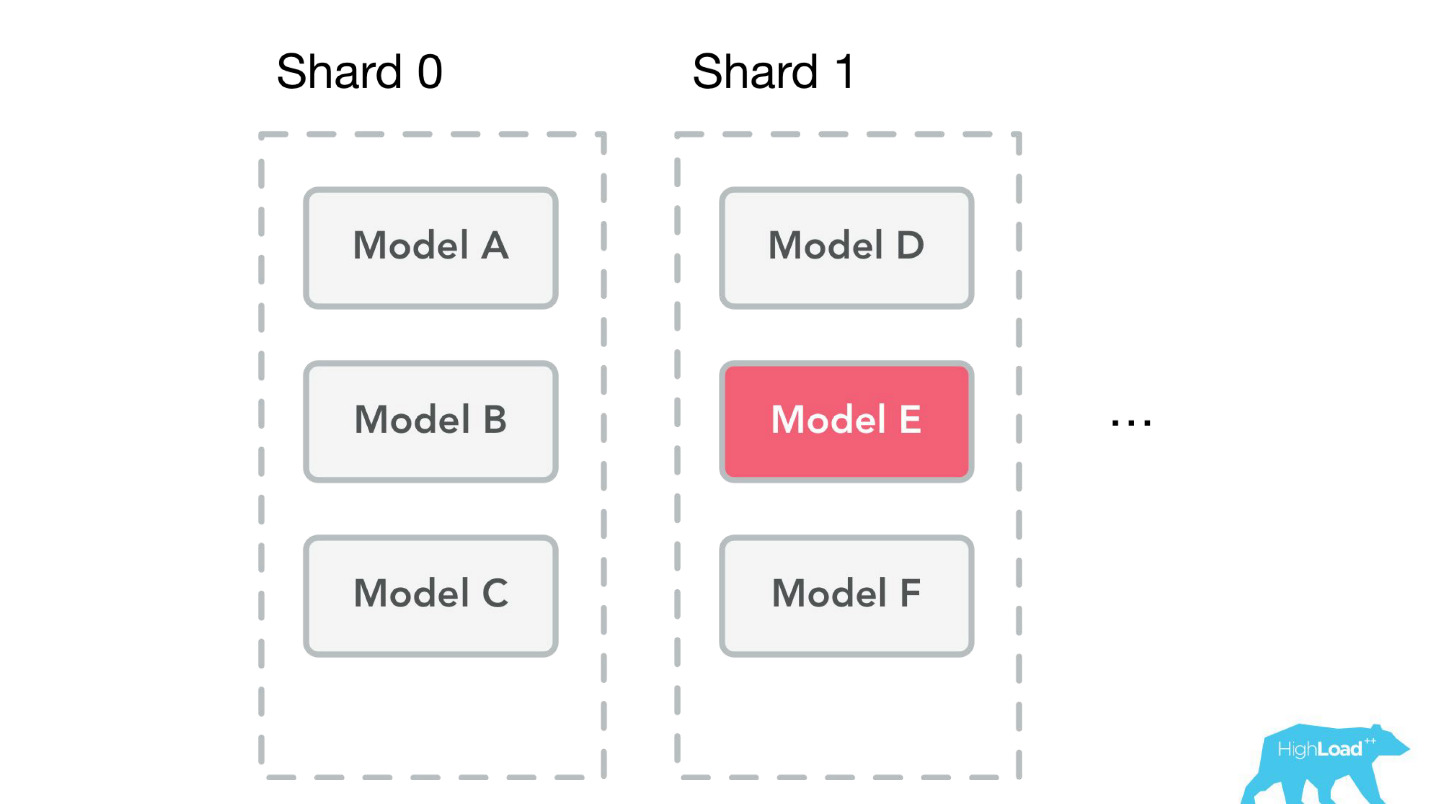
— , . , ID , . , 0.
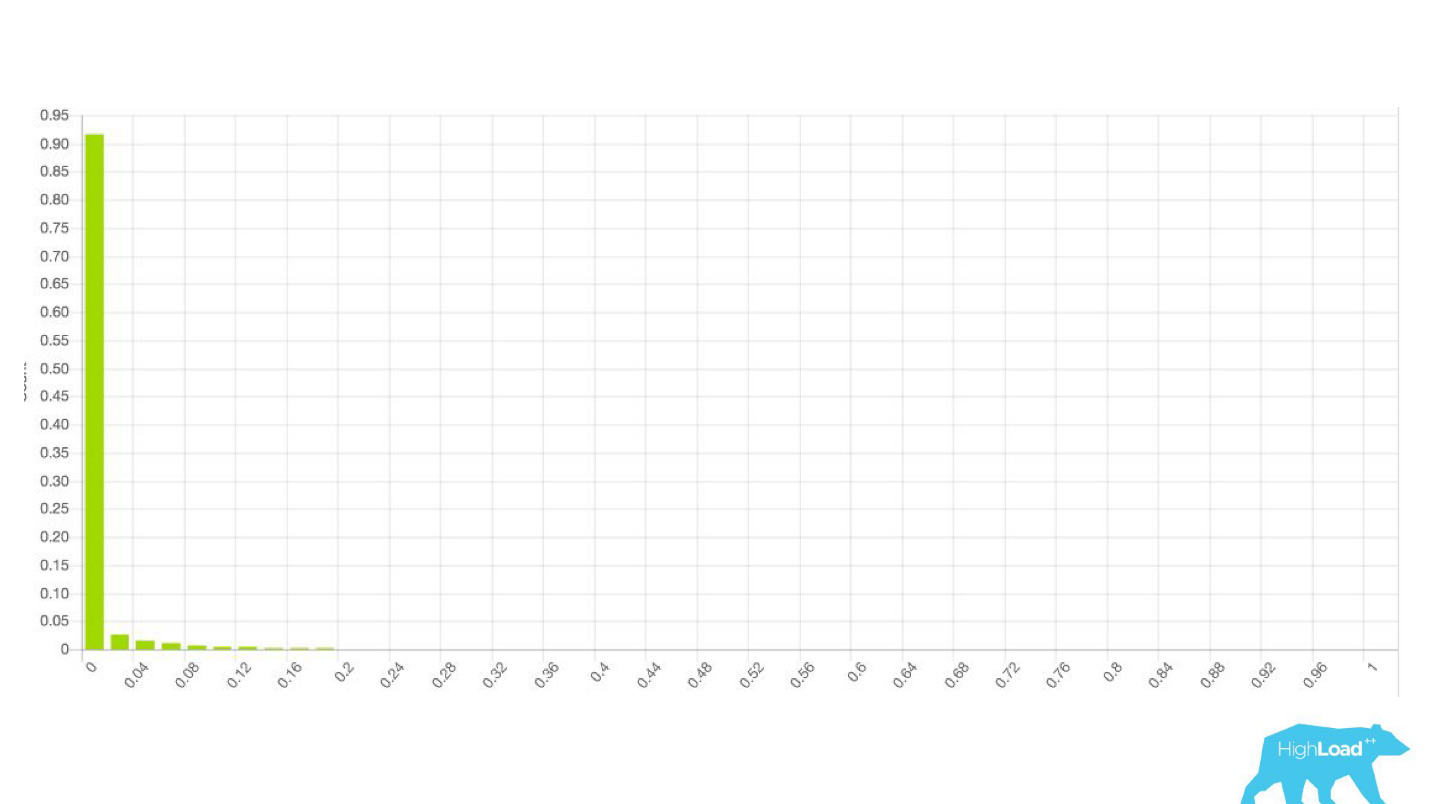
— , — .
, . , . , — , . , , , - .
, — ID . — 49-51%. , . , , . , .
Plans futurs
- , . Label based metrics, precision recall .
- More tools & integrations
, . , Perl Java, , , . Spark, .
- Reusable training pipelines
.
, -. , , , , ,
steaming — - , , .
. pipeline, , . , , .
. ,
, 50 , . , . , , .
Start small
, , Booking.com, , , — !
, , MySQL. , , . - . B . , , - — .
, ?
Monitor
— , -, .
— . — , . , , , . : , . , , , — !
Organization footprint
, . , . , .
(Don't) Follow our steps
- , , , . , - , . , . — , , ? , , , ?
, , !HighLoad++ 2018, 8 9 , 135 , . 9 - . , .