Avant qu'un client puisse effectuer des transferts d'argent dans des paiements électroniques, il devra passer par une vérification. Il nous fournit ses données personnelles et télécharge des documents pour vérifier son identité et son adresse. Et nous vérifions s'ils répondent aux exigences de notre régulateur. Le flux des demandes de vérification est devenu de plus en plus, il nous est devenu difficile de traiter un tel flux de documents. Nous avions peur que la procédure prenne beaucoup de temps et dépasse toutes les conditions raisonnables pour les clients. Nous avons ensuite décidé de créer un système de vérification basé sur le deep learning.

Programme éducatif sur les régulateurs et leurs exigences
Pour émettre de la monnaie électronique, vous devez obtenir une licence de régulateur. Si vous ouvrez un système de paiement, par exemple en Russie, la Banque centrale de la Fédération de Russie deviendra votre régulateur. ePayments est un système de paiement anglais, notre régulateur est la Financial Conduct Authority (FCA), une autorité qui rend compte au Trésor britannique. FCA garantit que nous respectons la politique de lutte contre le blanchiment d'argent (AML), qui comprend l'ensemble des procédures Know Your Customer (KYC).
Selon KYC, nous nous engageons à vérifier qui est notre client et s'il est associé à des groupes socialement dangereux. Par conséquent, nous avons deux obligations:
- Identification et confirmation de l'identité du client.
- Réconciliation de ses données avec différentes listes: terroristes, personnes sous sanctions, membres du gouvernement et bien d'autres.
Chaque année, les exigences KYC deviennent plus strictes et plus détaillées. Début 2017, les clients ePayments pouvaient toujours recevoir des paiements ou effectuer des virements sans vérification. Maintenant, ce n'est plus possible tant qu'ils n'ont pas confirmé leur identité.
Vérification manuelle
Il y a quelques années, nous nous sommes débrouillés seuls. Les Russes ont envoyé une analyse de certaines pages du passeport pour confirmer leur identité, et une analyse du contrat de location, un reçu pour le paiement du logement et des services communaux pour confirmer l'adresse. Rappelez-vous les papiers du jeu, s'il vous plaît? Dans ce document, en tant qu'agent des douanes, vous vérifiez les documents par rapport aux exigences de plus en plus complexes du gouvernement. Notre service client y a joué tous les jours.

Les clients sont vérifiés à distance, sans visite au bureau. Pour accélérer la procédure, nous avons embauché de nouveaux employés, mais c'est une impasse. Puis l'idée est venue de confier une partie du travail du réseau neuronal. Si elle fait bien face à la reconnaissance faciale, alors elle fait face à nos tâches. D'un point de vue commercial, un système de vérification rapide devrait pouvoir:
- Classez un document. On nous envoie une carte d'identité et une confirmation de l'adresse de résidence. Le système doit répondre à ce qu'il a reçu à l'entrée: un passeport d'un citoyen de la Fédération de Russie, un contrat de location ou autre chose.
- Comparez le visage sur la photo et le document. Nous demandons aux clients d'envoyer des selfies avec une carte d'identité pour s'assurer qu'ils sont eux-mêmes enregistrés dans le système de paiement.
- Extraire du texte. Remplir des dizaines de champs à partir d'un smartphone n'est pas très pratique. C'est beaucoup plus facile si l'application a tout fait pour vous.
- Vérifiez les fichiers d'image pour le montage photo. Il ne faut pas oublier les escrocs qui veulent entrer frauduleusement dans le système.
En sortie, le système doit indiquer un certain niveau de confiance envers le client: élevé, moyen ou faible. En nous concentrant sur une telle gradation, nous allons rapidement vérifier et ne pas irriter les clients avec des périodes prolongées.
Classificateur de documents
La tâche de ce module est de s'assurer que l'utilisateur envoie un document valide et donne une réponse qu'il a spécifiquement téléchargée: un passeport d'un citoyen du Kazakhstan, un contrat de location ou un reçu pour le paiement du logement et des services communaux.
Le classificateur reçoit les données d'entrée:
- Document photo ou numérisé
- Pays de résidence
- Type de document indiqué par le client (carte d'identité ou justificatif de domicile)
- Texte extrait (plus d'informations ci-dessous)
À la sortie, le classificateur rend compte de ce qu'il a reçu (passeport, permis de conduire, etc.) et de sa confiance dans la bonne réponse.

La solution fonctionne désormais sur l'architecture Wide Residual Network. Nous ne sommes pas venus vers elle tout de suite. La première version du système de vérification rapide a fonctionné sur la base de l'architecture à laquelle VGG nous a inspiré. Elle avait 2 problèmes évidents: un grand nombre de paramètres (environ 130 millions) et l'instabilité de la position du document. Plus il y a de paramètres, plus il est difficile de former un tel réseau de neurones - il généralise mal les connaissances. Le document sur la photographie doit être centré, sinon le classificateur devra être formé sur les échantillons dans lesquels il se trouve dans différentes parties de la photographie. En conséquence, nous avons abandonné VGG et avons décidé de passer à une architecture différente.
Residual Network (ResNet) était plus frais que VGG. Grâce aux
connexions sautées, vous pouvez créer un grand nombre de couches et atteindre une grande précision. ResNet ne dispose que d'environ 1 million de paramètres et elle était indifférente à la position du document. Peu importe où il se trouve dans l'image, la solution sur cette architecture a géré la classification.
Pendant que nous finalisions la solution avec un fichier, une nouvelle modification d'architecture, le Wide Residual Network (WRN), a été publiée. La principale différence avec ResNet est un recul en termes de profondeur. WRN a moins de couches, mais plus de filtres convolutionnels. Il s'agit maintenant de la meilleure architecture de réseau neuronal pour la plupart des tâches et notre solution y fonctionne.
Quelques solutions utiles
Problème numéro 1. Le classificateur devait être formé. Nous avons dû télécharger de nombreux passeports et permis de conduire russes, kazakhs et biélorusses. Mais, bien sûr, vous ne pouvez pas prendre de documents clients. Le réseau contient des échantillons, mais il y en a trop peu pour réussir la formation d'un réseau neuronal.
Solution. Notre service technique a généré un échantillon de plus de 8000 échantillons de chaque type. Nous créons un modèle de document et multiplions par de nombreux échantillons aléatoires. Ensuite, nous générons une position aléatoire du document dans l'espace par rapport à la caméra, en tenant compte de son modèle mathématique et de ses caractéristiques: distance focale, résolution matricielle, etc. Lors de la génération d'une photographie artificielle, une image aléatoire de l'ensemble de données fini est sélectionnée comme arrière-plan. Après cela, un document présentant des distorsions de perspective est placé sur l'image de manière aléatoire. Sur un tel échantillon, notre réseau de neurones était bien formé et parfaitement défini le document «en bataille». Les résultats se trouvent à la fin de l'article.
Problème numéro 2. Restriction banale sur les ressources informatiques et la mémoire. Cela n'a aucun sens de soumettre un réseau neuronal profond à l'entrée de grandes images. Et les photos de smartphones modernes ne sont que cela.
Solution. Avant d'appliquer à l'entrée, la photo est compressée à une taille d'environ 300x300 pixels. À partir de l'image de cette autorisation, on peut facilement distinguer un document d'identification d'un autre. Pour résoudre ce problème, nous pouvons utiliser l'architecture standard Wide ResNet.
Problème numéro 3. Avec des documents confirmant l'adresse de résidence, tout est plus compliqué. Le contrat de location ou le relevé bancaire ne peut être distingué que par le texte sur la feuille. Après avoir réduit la taille de l'image aux mêmes 300x300 pixels, tous ces documents ont la même apparence - comme une feuille A4 avec du texte illisible.
Solution. Pour classer des documents arbitraires, nous avons apporté des modifications à l'architecture du réseau neuronal lui-même. Une couche supplémentaire de neurones y est apparue, qui est connectée à la couche de sortie. Les neurones de cette couche d'entrée reçoivent une entrée vectorielle qui décrit le texte précédemment reconnu à l'aide du modèle
Bag-of-Words .
Tout d'abord, nous avons formé un réseau de neurones pour classer les documents d'identité. Nous avons utilisé les poids du réseau formé lors de l'initialisation d'un autre réseau avec une couche supplémentaire pour classer les documents arbitraires. Cette solution était très précise, mais la reconnaissance de texte prenait un certain temps. La différence de vitesse de traitement entre les différents modules et la précision de la classification est visible dans le tableau n ° 2.
Reconnaissance faciale
Comment tromper un système de paiement qui vérifie les documents? Vous pouvez emprunter le passeport de quelqu'un d'autre et vous inscrire en l'utilisant. Pour vous assurer que le client s'enregistre, nous vous demandons de prendre un selfie avec une carte d'identité. Et le module de reconnaissance devrait comparer le visage sur le document et le visage sur le selfie et répondre, c'est une personne ou deux différentes.
Comment comparer 2 visages si vous êtes une voiture et pensez comme une voiture? Transformez une photo en un ensemble de paramètres et comparez leurs valeurs entre elles. C'est ainsi que fonctionnent les réseaux de neurones qui reconnaissent les visages. Ils prennent une image et la transforment en un vecteur à 128 dimensions (par exemple). Lorsque vous soumettez une autre image de visage à l'entrée et leur demandez de comparer, le réseau neuronal transformera la deuxième face en vecteur et calculera la distance entre elles.
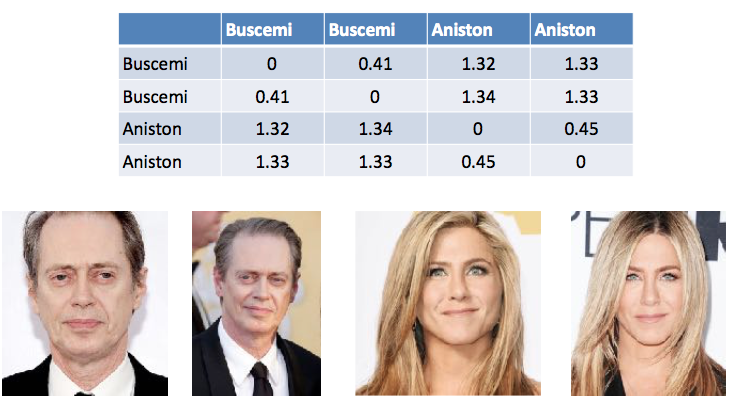 Tableau 1. Un exemple de calcul de la différence entre les vecteurs dans la reconnaissance faciale. Steve Buscemi se distingue de lui-même sur différentes photos par 0,44. Et de Jennifer Aniston - une moyenne de 1,33.
Tableau 1. Un exemple de calcul de la différence entre les vecteurs dans la reconnaissance faciale. Steve Buscemi se distingue de lui-même sur différentes photos par 0,44. Et de Jennifer Aniston - une moyenne de 1,33.Bien sûr, il existe des différences entre l'apparence d'une personne dans la vie et sur un passeport. Nous avons également sélectionné la distance entre les vecteurs et testé sur de vraies personnes pour obtenir un résultat. Dans tous les cas, la décision finale sera désormais prise par la personne, et un commentaire du système ne sera qu'une recommandation.
Reconnaissance de texte
Il y a des champs de texte sur les documents qui aident le classificateur à comprendre ce qui se trouve devant lui. Il sera pratique pour l'utilisateur que le texte du même passeport soit transféré automatiquement et ne doive pas être tapé manuellement, par qui et quand il a été émis. Pour ce faire, nous avons créé le module suivant - reconnaissance et extraction de texte.
Sur certains documents, par exemple, les nouveaux passeports de la Fédération de Russie, il y a une zone de lecture automatique (MRZ). Avec son aide, il est facile de prendre des informations - il est facile de lire du texte noir sur fond blanc, ce qui est facile à reconnaître. De plus, MRZ a un format bien connu, grâce auquel il est plus facile d'obtenir les données nécessaires.

Si la tâche contient des documents avec MRZ, cela devient plus facile pour nous. L'ensemble du processus se situe dans le domaine de la vision par ordinateur. Si cette zone n'est pas là, après avoir reconnu le texte, vous devez résoudre un problème intéressant - comprendre, et quelles informations avons-nous reconnu? Par exemple, «15 mai 1999» est la date de naissance ou la date d'émission? À ce stade, vous pouvez également faire une erreur. MRZ est bon car il est uniquement décodé. Nous savons toujours quelles informations et dans quelle partie de la MRZ rechercher. C'est très pratique pour nous. Mais MRZ n'était pas sur le document le plus populaire avec lequel le réseau travaillera - le passeport de la Fédération de Russie.
Pour la reconnaissance de texte, nous avions besoin d'une solution très efficace. Le texte devra être supprimé de l'image prise par l'appareil photo du téléphone et non par les photographes les plus professionnels. Nous avons testé Google Tesseract et plusieurs solutions payantes. Rien ne s'est produit - soit cela a mal fonctionné, soit c'était excessivement cher. En conséquence, nous avons commencé à développer notre propre solution. Nous terminons maintenant ses tests. La solution montre des résultats décents - vous pouvez les lire ci-dessous. Nous parlerons du module de vérification du montage photo un peu plus tard, lorsqu'il y aura des résultats de recherche précis sur des échantillons de test et sur la «bataille».
Résultat
Le système est actuellement testé sur le segment des demandes de vérification en provenance de Russie. Le segment est déterminé par échantillonnage aléatoire, les résultats sont enregistrés et comparés aux décisions de l'opérateur du service client pour un client particulier.
| Pays | Type de classificateur | Précision | Temps de travail, s |
| La russie | Carte d'identité | 99,96% | 0,41 |
| La russie | Document personnalisé | 98,62% | 6,89 |
| Kazakhstan | Carte d'identité | 99,51% | 0,47 |
| Kazakhstan | Document personnalisé | 97,25% | 7,66 |
| Biélorussie | Carte d'identité | 98,63% | 0,46 |
| Biélorussie | Document personnalisé | 98,63% | 9,66 |
Tableau 2. L'exactitude du classificateur de documents (la classification correcte du document par rapport à l'évaluation de l'opérateur).L'un des grands avantages de l'apprentissage automatique est que le réseau neuronal apprend vraiment et fait moins d'erreurs. Bientôt, nous terminerons les tests sur le segment et lancerons le système de vérification en mode «combat». 30% des demandes de vérification proviennent de paiements électroniques de Russie, du Kazakhstan et de Biélorussie. Selon nos estimations, le lancement contribuera à réduire la charge du ministère client de 20 à 25%. À l'avenir, la solution pourra être étendue aux pays européens.
Vous cherchez un emploi?
Nous recherchons des employés pour travailler dans un bureau à Saint-Pétersbourg. Si vous êtes intéressé par un projet international avec un large bassin de tâches ambitieuses, nous vous attendons. Nous n'avons pas assez de gens qui n'ont pas peur de les réaliser. Vous trouverez ci-dessous des liens vers les offres d'emploi sur hh.ru.