
Cet article fait partie de
la Chronique de l'architecture logicielle , une série d'articles sur l'architecture logicielle. J'y écris ce que j'ai appris sur l'architecture logicielle, ce que j'en pense et comment j'utilise les connaissances. Le contenu de cet article peut avoir plus de sens si vous lisez les articles précédents de la série.
Après avoir obtenu mon diplôme universitaire, j'ai commencé à travailler en tant que professeur de lycée, mais il y a quelques années, j'ai arrêté de travailler et suis allé chez les développeurs de logiciels à temps plein.
Depuis lors, j'ai toujours ressenti le besoin de récupérer le temps «perdu» et de le découvrir le plus rapidement possible. Par conséquent, j'ai commencé à m'impliquer un peu dans les expériences, à lire et à écrire beaucoup, en accordant une attention particulière à la conception et à l'architecture du logiciel. C'est pourquoi j'écris ces articles pour m'aider dans mes études.
Dans les derniers articles, j'ai parlé de nombreux concepts et principes que j'ai appris, et un peu comment je raisonne à leur sujet. Mais je les imagine comme des fragments d'un grand puzzle.
Cet article explique comment j'ai rassemblé tous ces fragments. Je pense que je devrais leur donner un nom, donc je les appellerai
architecture explicite . De plus, tous ces concepts sont
«testés au combat» et sont utilisés en production sur des plateformes hautement fiables. L'un d'eux est une plateforme de commerce électronique SaaS avec des milliers de boutiques en ligne à travers le monde, l'autre est une plateforme de trading opérant dans deux pays avec un bus de messages qui traite plus de 20 millions de messages par mois.
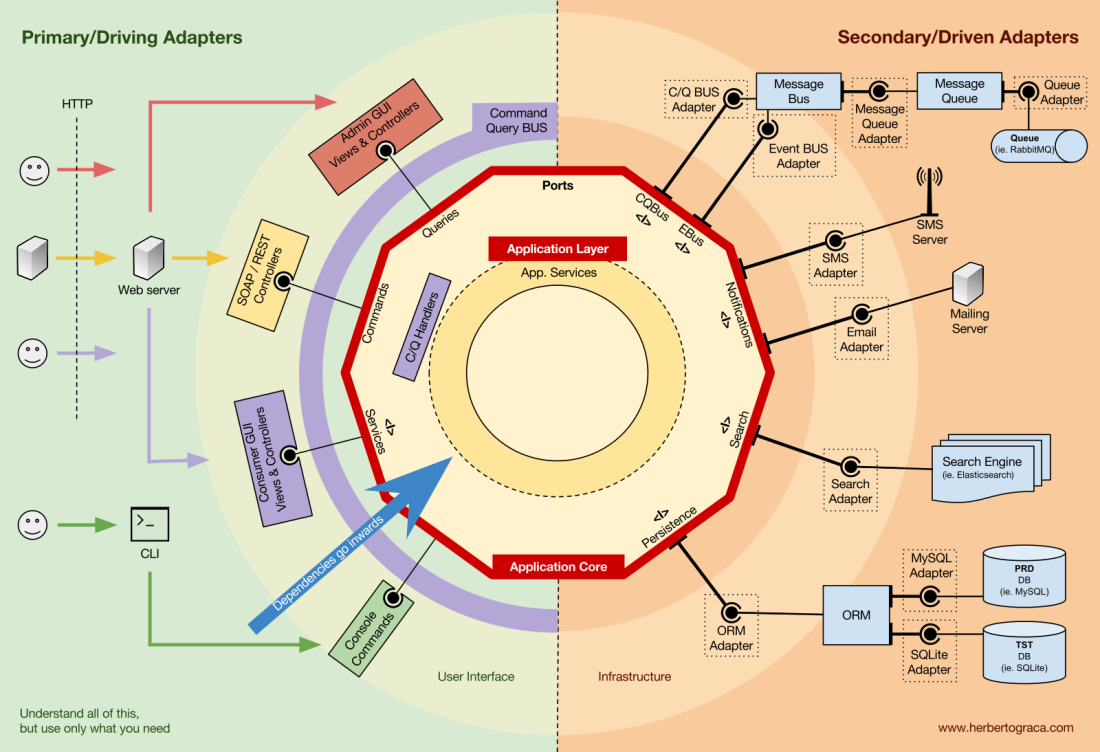
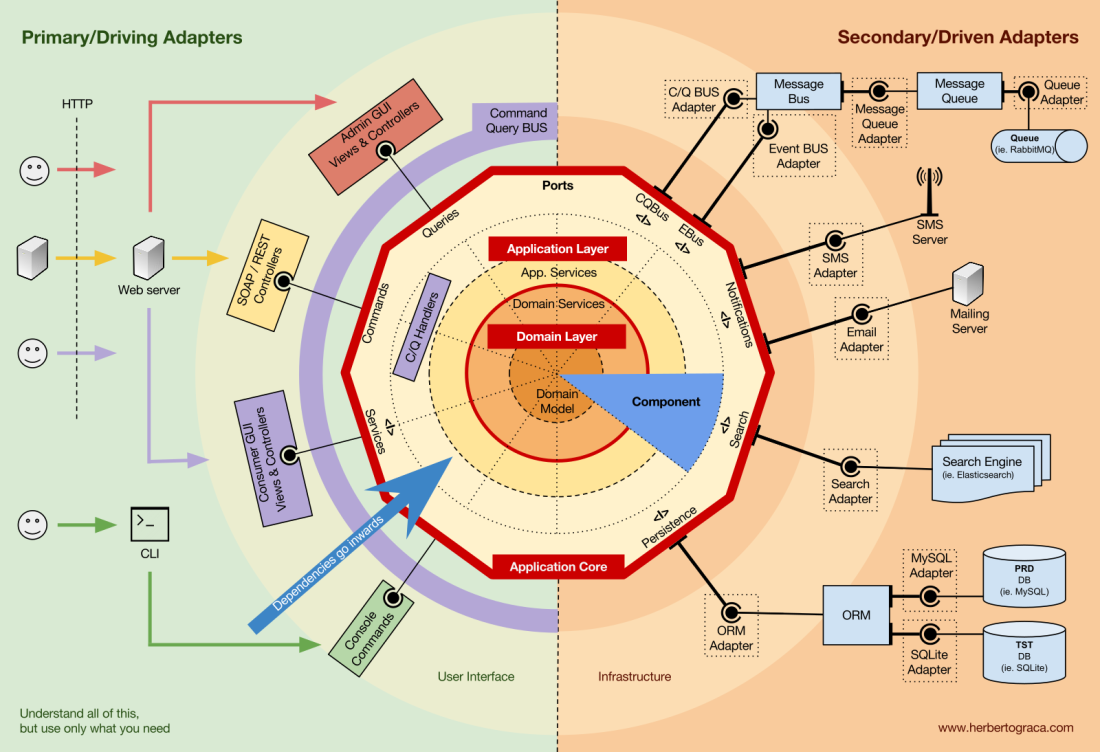
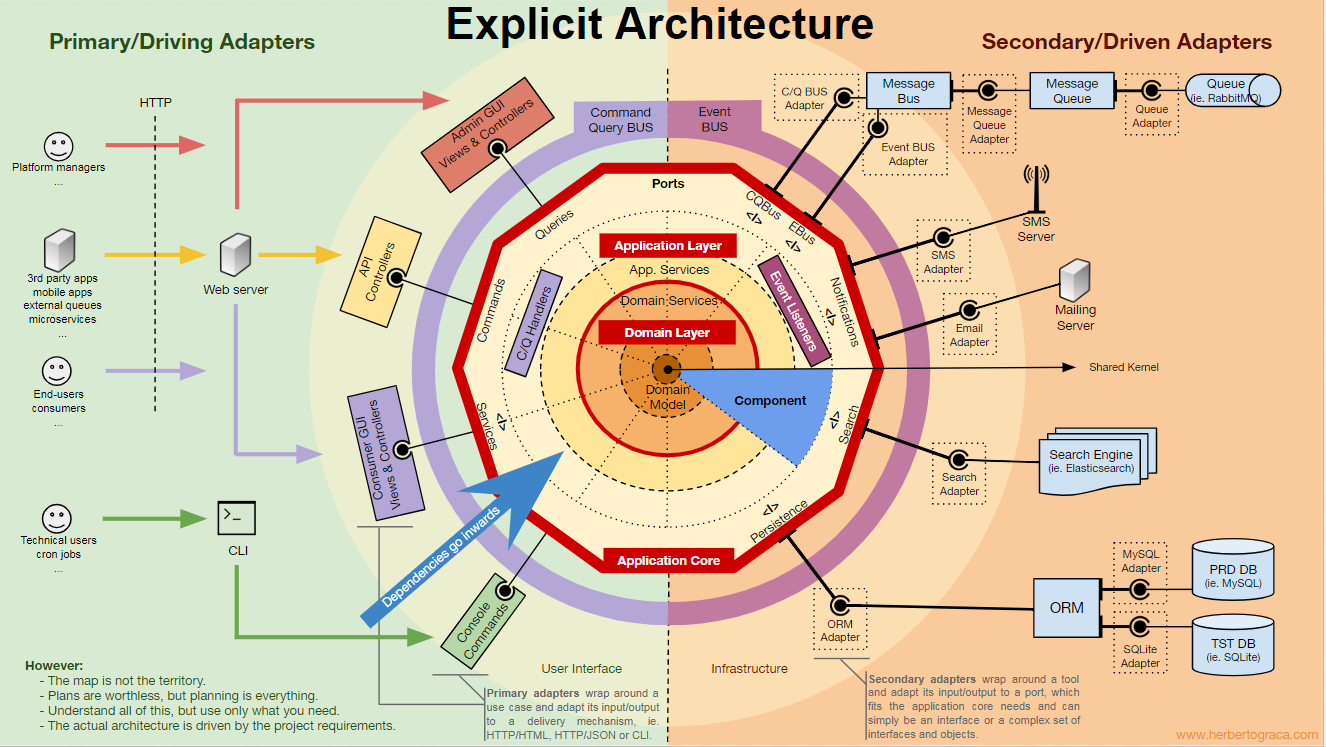
Blocs fondamentaux du système
Commençons par
rappeler les architectures
EBI et
Ports & Adapters . Les deux séparent clairement le code interne et externe de l'application, ainsi que les adaptateurs pour connecter le code interne et externe.
De plus, l'architecture des
ports et adaptateurs définit explicitement les trois blocs de code fondamentaux du système:
- Cela vous permet d'exécuter l' interface utilisateur , quel que soit son type.
- Logique métier système ou cœur d'application . Il est utilisé par l'interface utilisateur pour effectuer des transactions réelles.
- Le code d' infrastructure qui relie le cœur de notre application à des outils tels que la base de données, le moteur de recherche ou les API tierces.
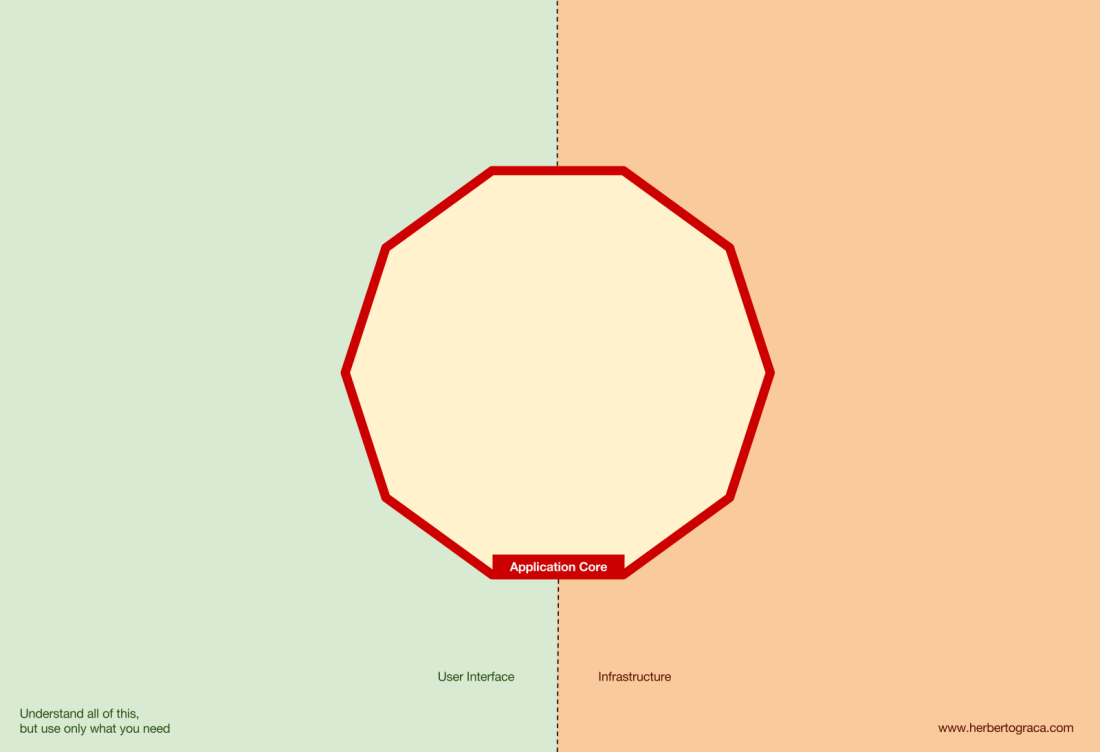
Le cœur de l'application est la chose la plus importante à penser. Ce code vous permet d'effectuer des actions réelles dans le système, c'est-à-dire, c'est notre application. Plusieurs interfaces utilisateur (une application Web progressive, une application mobile, une CLI, une API, etc.) peuvent fonctionner avec, tout fonctionne sur un cœur.
Comme vous pouvez l'imaginer, un flux d'exécution typique passe du code de l'interface utilisateur au cœur de l'application au code d'infrastructure, puis au cœur de l'application et, enfin, la réponse est fournie à l'interface utilisateur.

Les outils
Loin du code du noyau le plus important, il existe encore des outils que l'application utilise. Par exemple, le moteur de base de données, le moteur de recherche, le serveur Web et la console CLI (bien que les deux derniers soient également des mécanismes de livraison).
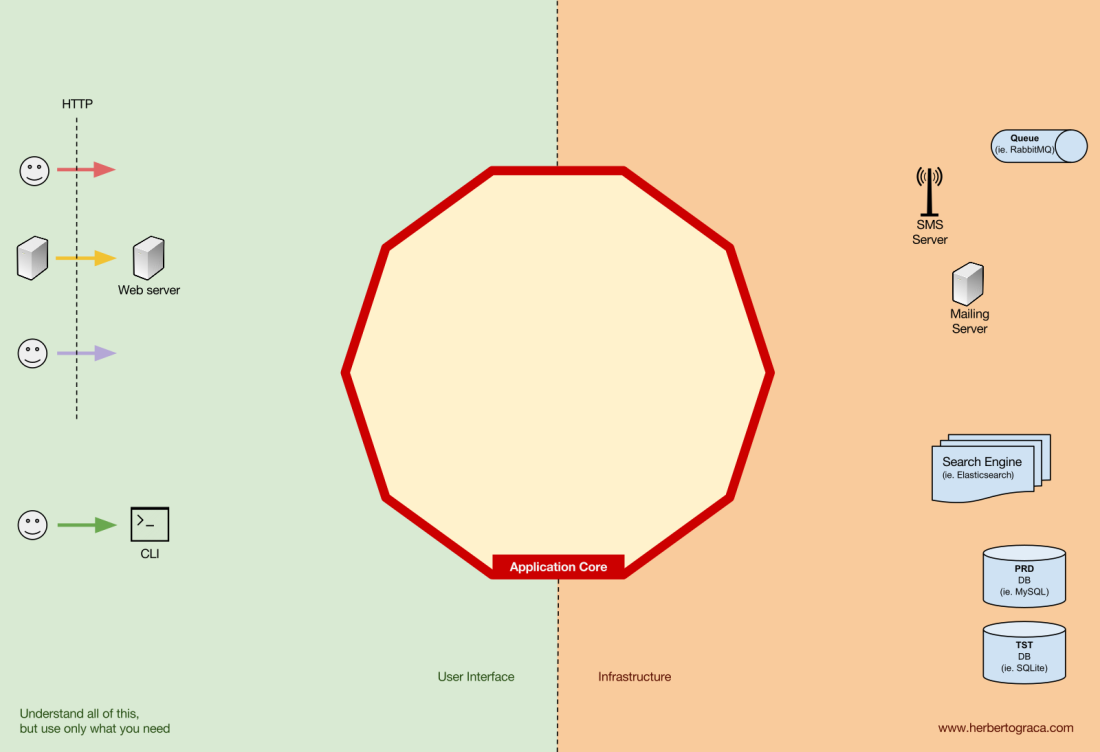
Il semble étrange de placer la console CLI dans la même section thématique que le SGBD, car ils ont un objectif différent. Mais en fait, les deux sont des outils utilisés par l'application. La principale différence est que la console CLI et le serveur Web
indiquent à l'application de faire quelque chose , le noyau SGBD, au contraire,
reçoit des commandes de l'application . Il s'agit d'une différence très importante, car elle affecte considérablement la façon dont nous écrivons du code pour connecter ces outils au cœur de l'application.
Connecter les outils et les mécanismes de livraison au cœur de l'application
Les blocs d'outils de connexion de code au cœur de l'application sont appelés adaptateurs (
architecture des ports et adaptateurs ). Ils permettent à la logique métier d'interagir avec un outil spécifique et vice versa.
Les adaptateurs qui indiquent à l'application de faire quelque chose sont appelés
adaptateurs principaux ou de contrôle , tandis que les adaptateurs qui indiquent à l'application de faire quelque chose sont appelés
adaptateurs secondaires ou gérés .
Ports
Cependant, ces
adaptateurs ne sont pas créés par hasard, mais pour correspondre à un point d'entrée spécifique dans le noyau de l'application, le
port . Un port n'est
rien de plus qu'une spécification de la façon dont l'outil peut utiliser le cœur de l'application ou vice versa. Dans la plupart des langues et dans sa forme la plus simple, ce port sera une interface, mais en fait il peut être composé de plusieurs interfaces et DTO.
Il est important de noter que les
ports (interfaces) sont à l'intérieur de la logique métier et que les adaptateurs sont à l'extérieur. Pour que ce modèle fonctionne correctement, il est extrêmement important de créer des ports conformément aux besoins du cœur de l'application, et pas seulement de reproduire les API de l'outil.
Adaptateurs primaires ou de contrôle
Les adaptateurs principaux ou de contrôle
s'enroulent autour d'un port et l'utilisent pour indiquer au noyau de l'application quoi faire.
Ils transforment toutes les données du mécanisme de livraison en appels de méthode dans le cœur de l'application.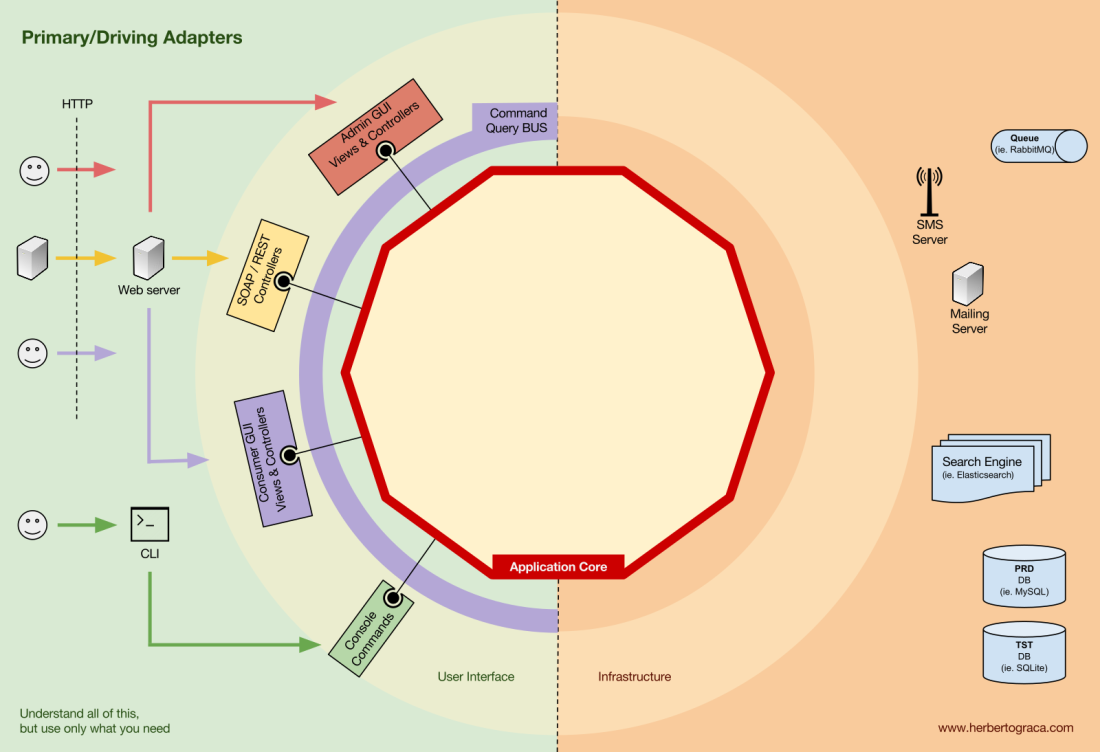
En d'autres termes, nos adaptateurs de contrôle sont des contrôleurs ou des commandes de console, ils sont intégrés dans leur constructeur avec un objet dont la classe implémente l'interface (port) requise par une commande de contrôleur ou de console.
Dans un exemple plus spécifique, le port peut être l'interface de service ou l'interface de référentiel requise par le contrôleur. Une implémentation spécifique d'un service, d'un référentiel ou d'une demande est ensuite implémentée et utilisée dans le contrôleur.
De plus, le port peut être un bus de commande ou une interface de bus de requête. Dans ce cas, une implémentation spécifique du bus de commande ou de requête est entrée dans le contrôleur, qui crée ensuite une commande ou une requête et la transmet au bus correspondant.
Adaptateurs secondaires ou gérés
Contrairement aux adaptateurs de contrôle qui entourent un port, les
adaptateurs gérés implémentent un port, une interface, puis entrent dans le cœur de l'application où le port est requis (avec le type).

Par exemple, nous avons une application native qui doit enregistrer des données. Nous créons une interface de persistance avec une méthode d'
enregistrement d'un tableau de données et une méthode de
suppression d'une ligne dans une table par son ID. Désormais, partout où l'application doit enregistrer ou supprimer des données, nous aurons besoin dans le constructeur d'un objet qui implémente l'interface de persistance que nous avons définie.
Créez maintenant un adaptateur spécifique à MySQL qui implémentera cette interface. Il aura des méthodes pour enregistrer le tableau et supprimer la ligne dans le tableau, et nous l'introduirons partout où l'interface de persistance est requise.
Si à un moment donné, nous décidons de changer le fournisseur de base de données, par exemple, pour PostgreSQL ou MongoDB, nous avons juste besoin de créer un nouvel adaptateur qui implémente l'interface de persistance spécifique à PostgreSQL et d'introduire un nouvel adaptateur au lieu de l'ancien.
Inversion de contrôle
Une caractéristique de ce modèle est que les adaptateurs dépendent d'un outil spécifique et d'un port spécifique (en implémentant une interface). Mais notre logique métier ne dépend que du port (interface), qui est conçu pour répondre aux besoins de la logique métier et ne dépend pas d'un adaptateur ou d'un outil spécifique.
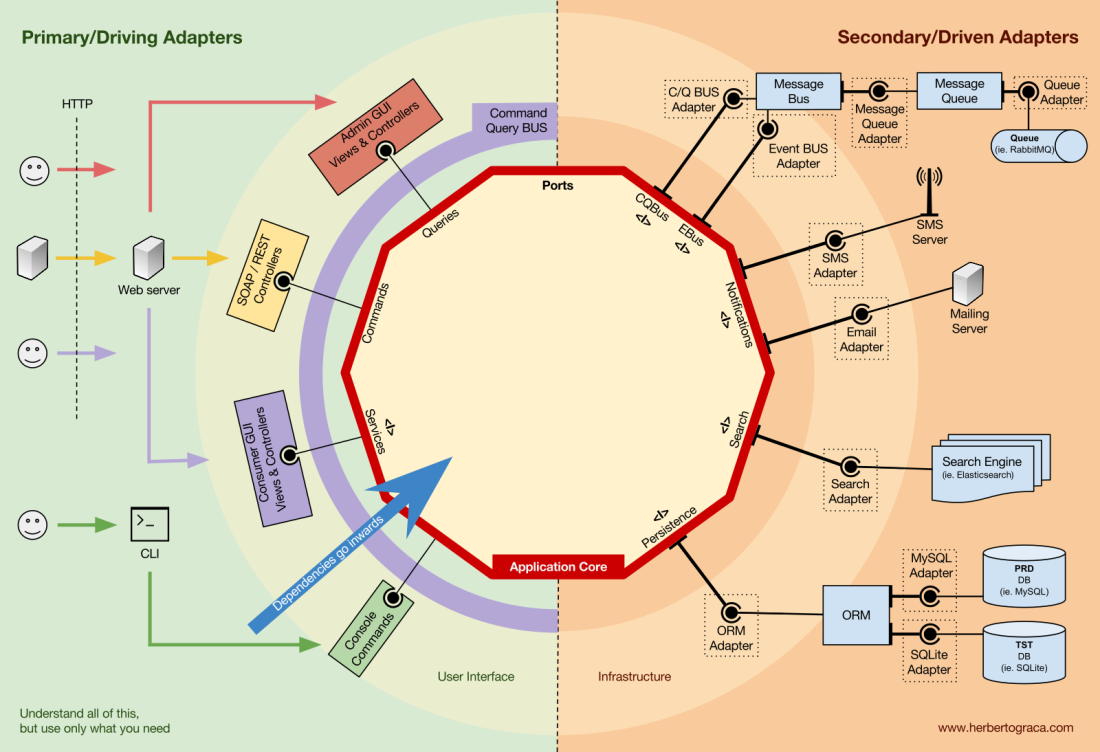
Cela signifie que les dépendances sont dirigées vers le centre, c'est-à-dire qu'il y a une
inversion du principe de contrôle au niveau architectural .
Bien que, encore une fois,
il est impératif que les ports soient créés conformément aux besoins du cœur de l'application, et non pas simplement imitent les API de l'outil .
Organisation du cœur d'application
L'architecture Onion récupère les couches DDD et les intègre dans l'
architecture du
port et de l'adaptateur . Ces niveaux sont conçus pour mettre de l'ordre dans la logique métier, à l'intérieur de l '«hexagone» des ports et des adaptateurs. Comme précédemment, la direction des dépendances est vers le centre.
Couche d'application (couche d'application)
Les cas d'utilisation sont des processus qui peuvent être lancés dans le noyau par une ou plusieurs interfaces utilisateur. Par exemple, un CMS peut avoir une interface utilisateur pour les utilisateurs réguliers, une autre interface utilisateur indépendante pour les administrateurs CMS, une autre CLI et une API Web. Ces interfaces utilisateur (applications) peuvent déclencher des cas d'utilisation uniques ou courants.
Les cas d'utilisation sont définis au niveau de l'application - le premier niveau de DDD et l'architecture Onion.
Cette couche contient des services d'application (et leurs interfaces) en tant qu'objets de première classe, et contient également des interfaces de port et d'adaptateur (ports), qui incluent des interfaces ORM, des interfaces de moteur de recherche, des interfaces de messagerie, etc. Dans le cas où nous utilisons le bus de commande et / ou le bus de requête, à ce niveau sont les gestionnaires de commande et de requête correspondants.
Les services d'application et / ou les gestionnaires de commandes contiennent la logique de déploiement d'un cas d'utilisation, un processus métier. En règle générale, leur rôle est le suivant:
- utiliser le référentiel pour rechercher une ou plusieurs entités;
- demander à ces entités d'exécuter une logique de domaine;
- et utiliser le stockage pour réenregistrer les entités, enregistrant efficacement les modifications des données.
Les gestionnaires de commandes peuvent être utilisés de deux manières:
- Ils peuvent contenir une logique pour exécuter un cas d'utilisation;
- Ils peuvent être utilisés comme de simples parties d'une connexion dans notre architecture qui reçoivent une commande et invoquent simplement la logique qui existe dans le service d'application.
L'approche à utiliser dépend du contexte, par exemple:
- Nous avons déjà des services d'application et maintenant le bus de commande est ajouté?
- Le bus de commandes vous permet-il de spécifier une classe / méthode en tant que gestionnaire, ou avez-vous besoin d'étendre ou d'implémenter des classes ou des interfaces existantes?
Cette couche contient également des
événements d'application déclencheurs qui représentent certains résultats d'un cas d'utilisation. Ces événements déclenchent une logique qui est un effet secondaire d'un cas d'utilisation, comme l'envoi d'e-mails, la notification d'une API tierce, l'envoi d'une notification push ou même le lancement d'un autre cas d'utilisation appartenant à un autre composant de l'application.
Au niveau du domaine
Plus à l'intérieur, il y a un niveau de domaine. Les objets de ce niveau contiennent des données et une logique de gestion de ces données, qui sont spécifiques au domaine lui-même et sont indépendantes des processus métier qui déclenchent cette logique. Ils sont indépendants et ignorent complètement le niveau d'application.
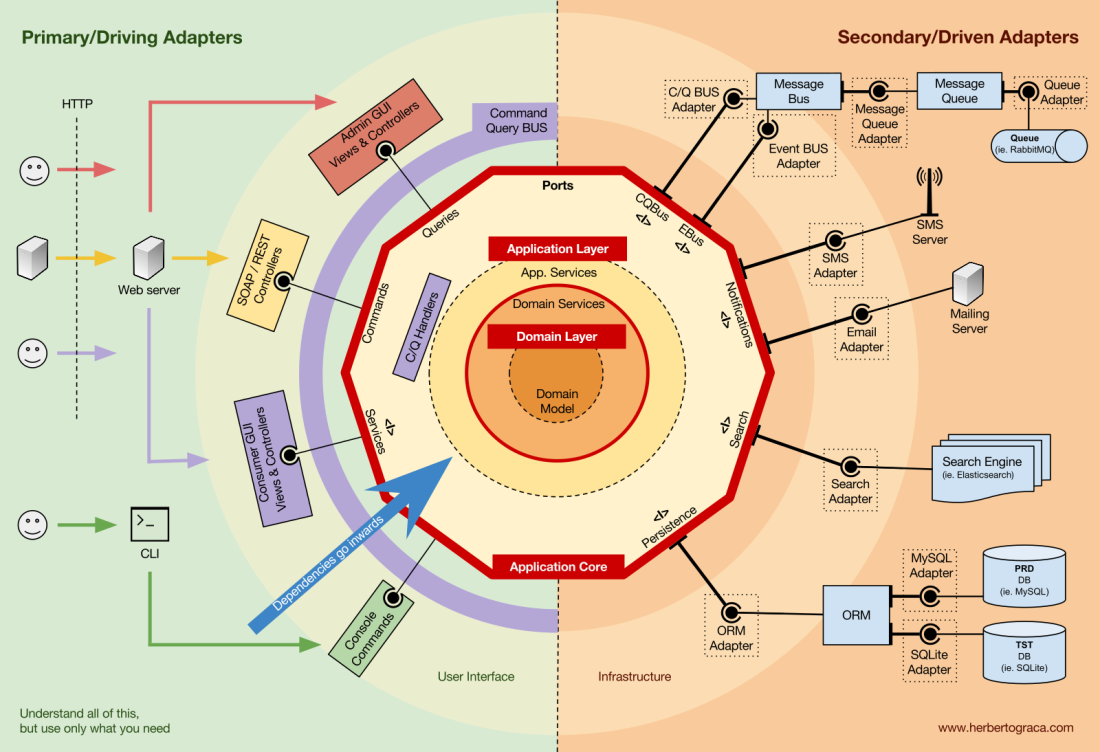
Services de domaine
Comme je l'ai mentionné ci-dessus, le rôle du service d'application:
- utiliser le référentiel pour rechercher une ou plusieurs entités;
- demander à ces entités d'exécuter une logique de domaine;
- et utiliser le stockage pour réenregistrer les entités, enregistrant efficacement les modifications des données.
Mais parfois, nous rencontrons une logique de domaine, qui comprend diverses entités du même type ou de types différents, et cette logique de domaine n'appartient pas aux entités elles-mêmes, c'est-à-dire que la logique n'est pas leur responsabilité directe.
Par conséquent, notre première réaction peut être de placer cette logique en dehors des entités dans le service d'application. Cependant, cela signifie que dans d'autres cas, la logique du domaine ne sera pas réutilisée: la logique du domaine doit rester en dehors du niveau de l'application!
La solution consiste à créer un service de domaine dont le rôle est d'obtenir un ensemble d'entités et d'exécuter une logique métier sur celles-ci. Un service de domaine appartient à un niveau de domaine et ne sait donc rien des classes au niveau de l'application, telles que les services d'application ou les référentiels. D'autre part, il peut utiliser d'autres services de domaine et, bien sûr, des objets de modèle de domaine.
Modèle de domaine
Au centre se trouve le modèle de domaine. Il ne dépend de rien en dehors de ce cercle et contient des objets métier qui représentent quelque chose dans le domaine. Des exemples de tels objets sont, tout d'abord, les entités, ainsi que les objets de valeur, les énumérations et tous les objets utilisés dans le modèle de domaine.
Les événements de domaine vivent également dans le modèle de domaine. Lorsqu'un ensemble de données spécifique change, ces événements sont déclenchés, qui contiennent de nouvelles valeurs des propriétés modifiées. Ces événements sont idéaux, par exemple, pour une utilisation dans le module de sourcing d'événements.
Composants
Jusqu'à présent, nous avons isolé le code en couches, mais c'est une isolation du code trop détaillée. Il est tout aussi important de regarder l'image avec un aspect plus général. Nous parlons de diviser le code en sous-domaines et
contextes associés conformément aux idées de Robert Martin exprimées dans l'
architecture hurlante [c'est-à-dire que l'architecture devrait "crier" sur l'application elle-même, et non sur les cadres qu'elle utilise - env. trans.]. Ils parlent de l'organisation des packages par fonction ou composant, et non par couche, et Simon Brown l'a très bien expliqué dans son article
«Packages de composants et tests conformément à l'architecture» de son blog:
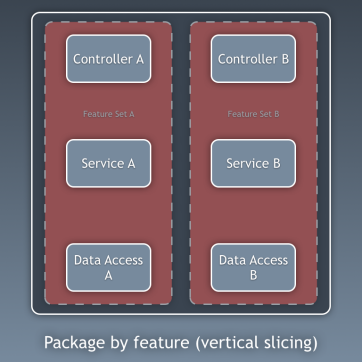
Je suis partisan de l'organisation des packages de composants et je souhaite changer sans vergogne le diagramme de Simon Brown comme suit:
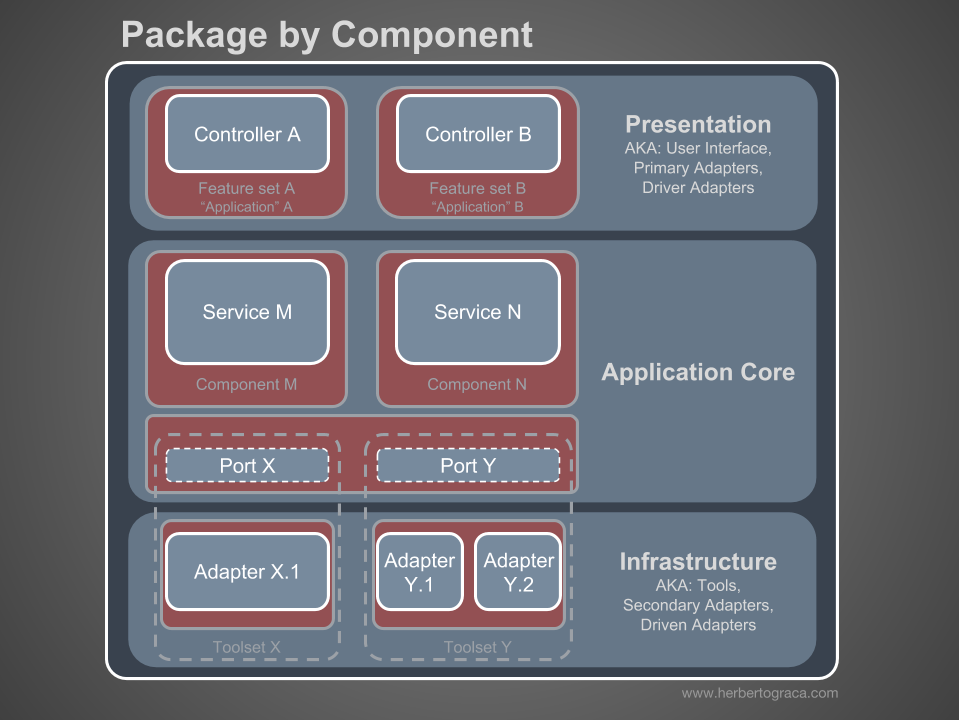
Ces sections du code sont transversales pour toutes les couches décrites précédemment, et ce sont les
composants de notre application. La facturation, l'utilisateur, la vérification ou le compte sont des exemples de composants, mais ils sont toujours associés à un domaine. Les contextes limités, tels que l'autorisation et / ou l'authentification, doivent être considérés comme des outils externes pour lesquels nous créons un adaptateur et nous cachons derrière un port.
Déconnexion des composants
Tout comme dans les unités de code à grain fin (classes, interfaces, traits, mixins, etc.), les grandes unités (composants) bénéficient d'un couplage faible et d'une connectivité étroite.
Pour séparer les classes, nous utilisons l'injection de dépendances, introduisant des dépendances dans la classe, plutôt que de les créer à l'intérieur de la classe, et inversant également les dépendances, rendant la classe dépendante des abstractions (interfaces et / ou classes abstraites) au lieu de classes spécifiques. Cela signifie que la classe dépendante ne sait rien de la classe spécifique qu'elle utilisera, elle n'a pas de référence au nom complet des classes dont elle dépend.
De même, dans les composants complètement déconnectés, chaque composant ne sait rien des autres composants. En d'autres termes, il n'a aucun lien vers un bloc de code à grain fin provenant d'un autre composant, même vers l'interface! Cela signifie que l'injection de dépendance et l'inversion de dépendance ne suffisent pas pour séparer les composants, nous aurons besoin d'une sorte de construction architecturale. Des événements, un tronc commun, une cohérence éventuelle et même un service de découverte peuvent être nécessaires!
Déclenchement de la logique dans d'autres composants
Lorsqu'un de nos composants (composant B) doit faire quelque chose à chaque fois que quelque chose d'autre se produit dans un autre composant (composant A), nous ne pouvons pas simplement appeler directement le composant A vers la classe / méthode du composant B, car alors A sera connecté à B.
Cependant, nous pouvons utiliser le gestionnaire d'événements pour distribuer l'événement d'application, qui sera remis à tout composant qui l'écoute, y compris B, et l'écouteur d'événement dans B déclenchera l'action souhaitée. Cela signifie que le composant A dépendra du gestionnaire d'événements, mais sera distinct du composant B.
Cependant, si l'événement lui-même "vit" dans A, cela signifie que B connaît l'existence de A et y est associé. Pour supprimer cette dépendance, nous pouvons créer une bibliothèque avec un ensemble de fonctionnalités du cœur de l'application qui seront partagées par tous les composants - un
cœur commun . Cela signifie que les deux composants dépendront du noyau commun, mais seront séparés l'un de l'autre. Un noyau commun contient des fonctionnalités telles que les événements d'application et de domaine, mais il peut également contenir des objets de spécification et tout ce qui a du sens à partager. En même temps, il doit être d'une taille minimale, car tout changement dans le noyau commun affectera tous les composants de l'application. De plus, si nous avons un système polyglotte, disons, un écosystème de microservices dans différentes langues, le noyau commun ne devrait pas dépendre de la langue pour que tous les composants le comprennent. Par exemple, au lieu d'un noyau commun avec une classe d'événements, il contiendra une description de l'événement (c'est-à-dire un nom, des propriétés, peut-être même des méthodes, bien qu'elles soient plus utiles dans l'objet de spécification) dans un langage universel comme JSON afin que tous les composants / microservices puissent l'interpréter et peut-être même générer automatiquement leurs propres implémentations spécifiques.
Cette approche fonctionne à la fois dans les applications monolithiques et distribuées, telles que les écosystèmes de microservices. Mais si les événements ne peuvent être délivrés que de manière asynchrone, cette approche n'est pas suffisante pour les contextes où la logique de déclenchement dans d'autres composants devrait fonctionner immédiatement! Ici, le composant A devra effectuer un appel HTTP direct au composant B. Dans ce cas, pour déconnecter les composants, nous avons besoin d'un service de découverte. La composante A lui demandera où envoyer la demande pour lancer l'action souhaitée. Sinon, faites une demande au service de découverte, qui la transmettra au service approprié et retournera finalement une réponse au demandeur.
Cette approche associe des composants à un service de découverte, mais ne les associe pas entre eux.Récupération de données à partir d'autres composants
Selon moi, le composant n'est pas autorisé à modifier des données qu'il ne «possède» pas, mais il peut demander et utiliser n'importe quelle donnée.Stockage de données partagé pour les composants
Si le composant doit utiliser des données appartenant à un autre composant (par exemple, le composant de facturation doit utiliser le nom du client qui appartient au composant de comptes), alors il contient l'objet de demande au stockage de données. Autrement dit, le composant de facturation peut connaître n'importe quel ensemble de données, mais doit utiliser des données en lecture seule d'autres pays.Stockage de données séparé pour le composant
Dans ce cas, le même modèle est appliqué, mais le niveau de stockage des données devient plus compliqué. La présence de composants avec leur propre entrepôt de données signifie que chaque entrepôt de données contient:- Un ensemble de données qu'un composant possède et peut changer, ce qui en fait la seule source de vérité;
- Un ensemble de données qui est une copie des données d'autres composants qu'il ne peut pas modifier par lui-même, mais qui est nécessaire pour la fonctionnalité du composant. Ces données doivent être mises à jour chaque fois qu'elles changent dans le composant propriétaire.
Chaque composant créera une copie locale des données dont il a besoin à partir d'autres composants, qui sera utilisée au besoin. Lorsque les données changent dans le composant auquel elles appartiennent, ce composant propriétaire déclenche un événement de domaine qui entraîne des modifications de données. Les composants contenant une copie de ces données écouteront cet événement de domaine et mettront à jour leur copie locale en conséquence.Contrôle du flux
Comme je l'ai dit ci-dessus, le flux de contrôle va de l'utilisateur au cœur de l'application, aux outils d'infrastructure, puis à nouveau au cœur de l'application - et retourne à l'utilisateur. Mais comment fonctionnent exactement les classes ensemble? Qui dépend de qui? Comment les composons-nous?Comme Oncle Bob, dans mon article sur l'architecture propre, je vais essayer d'expliquer le flux de la gestion des schémas UMLish ...Sans bus de commande / demande
Si nous n'utilisons pas le bus de commande, les contrôleurs dépendront du service d'application ou de l'objet de requête.[Supplément 18/11/2017] J'ai complètement ignoré le DTO, que j'utilise pour renvoyer les données de la demande, alors je l'ai ajouté maintenant. Merci à MorphineAdministered , qui a indiqué un espace. Dans le diagramme ci-dessus, nous utilisons l'interface pour le service d'application, bien que nous puissions dire qu'elle n'est pas vraiment nécessaire, car le service d'application fait partie de notre code d'application. Mais nous ne voulons pas changer la mise en œuvre, bien que nous puissions procéder à une refactorisation complète. L'objet Query contient une requête optimisée qui renvoie simplement des données brutes qui seront affichées à l'utilisateur. Ces données sont renvoyées au DTO, qui est intégré dans le ViewModel. Ce ViewModel peut avoir une sorte de logique de vue et sera utilisé pour remplir la vue.D'un autre côté, le service d'application contient une logique de cas d'utilisation qui se déclenche lorsque nous voulons faire quelque chose sur le système, et pas seulement afficher certaines données. Le service d'application dépend des référentiels qui renvoient des entités qui contiennent la logique qui doit être lancée. Il peut également dépendre du service de domaine pour coordonner le processus de domaine sur plusieurs entités, mais c'est un cas rare.Après avoir analysé le cas d'utilisation, le service d'application peut informer l'ensemble du système qu'un cas d'utilisation s'est produit, puis il dépendra du répartiteur d'événements pour déclencher l'événement.Il est intéressant de noter que nous hébergeons des interfaces à la fois sur le moteur de persistance et les référentiels. Cela peut sembler redondant, mais ils servent à différentes fins:
L'objet Query contient une requête optimisée qui renvoie simplement des données brutes qui seront affichées à l'utilisateur. Ces données sont renvoyées au DTO, qui est intégré dans le ViewModel. Ce ViewModel peut avoir une sorte de logique de vue et sera utilisé pour remplir la vue.D'un autre côté, le service d'application contient une logique de cas d'utilisation qui se déclenche lorsque nous voulons faire quelque chose sur le système, et pas seulement afficher certaines données. Le service d'application dépend des référentiels qui renvoient des entités qui contiennent la logique qui doit être lancée. Il peut également dépendre du service de domaine pour coordonner le processus de domaine sur plusieurs entités, mais c'est un cas rare.Après avoir analysé le cas d'utilisation, le service d'application peut informer l'ensemble du système qu'un cas d'utilisation s'est produit, puis il dépendra du répartiteur d'événements pour déclencher l'événement.Il est intéressant de noter que nous hébergeons des interfaces à la fois sur le moteur de persistance et les référentiels. Cela peut sembler redondant, mais ils servent à différentes fins:- L'interface de persistance est une couche d'abstraction sur ORM, afin que nous puissions échanger ORM sans changer le cœur de l'application.
- persistence-. , MySQL MongoDB. persistence- , ORM, . , , , , , , MongoDB SQL.
C /
Si notre application utilise le bus de commande / requête, le schéma reste quasiment le même, sauf que le contrôleur dépend désormais du bus, ainsi que des commandes ou requêtes. Une instance d'une commande ou d'une demande est créée ici et transmise au bus, qui trouvera le gestionnaire approprié pour recevoir et traiter la commande.Dans le diagramme ci-dessous, le gestionnaire de commandes utilise le service d'application. Mais ce n'est pas toujours nécessaire, car dans la plupart des cas, le gestionnaire contiendra toute la logique du cas d'utilisation. Tout ce que nous devons faire est d'extraire la logique du gestionnaire dans un service d'application distinct si nous devons réutiliser la même logique dans un autre gestionnaire.[Supplément 18/11/2017] J'ai complètement ignoré le DTO, que j'utilise pour renvoyer les données de la demande, alors je l'ai ajouté maintenant. Je vous remercieMorphineAdministered , qui indiquait un espace. Vous avez peut-être remarqué qu'il n'y a pas de dépendances entre le bus, la commande, la demande et les gestionnaires. En fait, ils n'ont pas besoin de se connaître pour assurer une bonne séparation. La méthode de direction du bus vers un gestionnaire spécifique pour le traitement d'une commande ou d'une demande est configurée dans une configuration simple. Dans les deux cas, toutes les flèches - dépendances qui traversent la limite du noyau de l'application - pointent vers l'intérieur. Comme expliqué précédemment, c'est la règle fondamentale des ports et adaptateurs, de l'oignon et de l'architecture propre.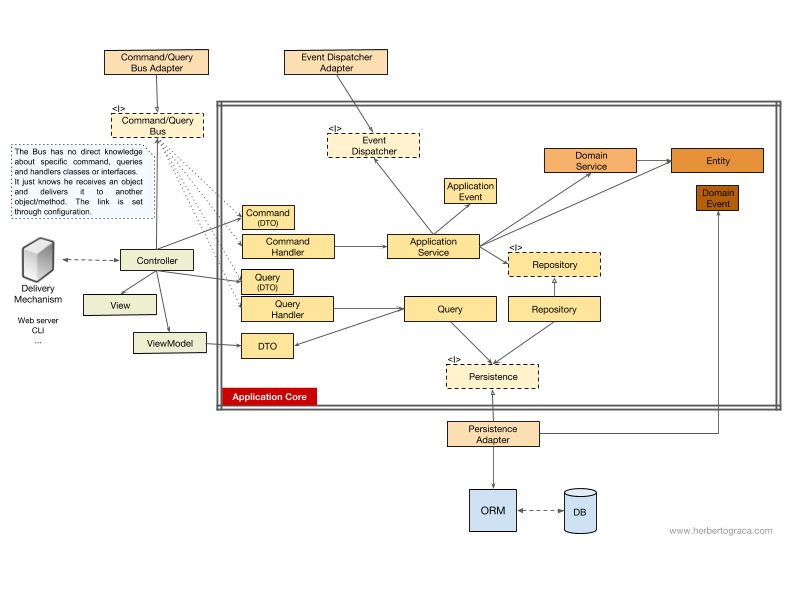

Conclusion
Comme toujours, l'objectif est d'obtenir une base de code déconnectée avec une connectivité élevée, dans laquelle vous pouvez facilement, rapidement et en toute sécurité apporter des modifications.Les plans sont inutiles, mais la planification est tout. - Eisenhower
Cette infographie est une carte conceptuelle. La connaissance et la compréhension de tous ces concepts vous aident à planifier une architecture saine et une application viable.Cependant:Une carte n'est pas un territoire. - Alfred Korzybsky
En d'autres termes, ce ne sont que des recommandations! Une application est un territoire, une réalité, un cas d'utilisation spécifique où nous devons appliquer nos connaissances, et cela détermine à quoi ressemblera la vraie architecture!Nous devons comprendre tous ces modèles, mais nous devons également toujours penser et comprendre ce dont notre application a besoin, jusqu'où nous pouvons aller pour la séparation et la connectivité. Cette décision dépend de nombreux facteurs, allant des exigences fonctionnelles du projet, au calendrier de développement de l'application, à sa durée de vie, à l'expérience de l'équipe de développement, etc.C'est comme ça que j'imagine tout ça pour moi.Ces idées sont discutées plus en détail dans l'article suivant: "Plus que de simples couches concentriques . "