Bonjour à tous! Récemment, il a été nécessaire d'écrire du code pour implémenter la segmentation d'image en utilisant la méthode k-means (anglais k-means). Eh bien, la première chose que Google fait est d'aider. J'ai trouvé beaucoup d'informations, comme d'un point de vue mathématique (toutes sortes de gribouillis mathématiques complexes là-bas, vous comprendrez ce que l'enfer y est écrit), ainsi que certaines implémentations logicielles qui sont sur Internet en anglais. Ces codes sont certainement beaux - sans aucun doute, mais l'essence de l'idée est difficile à saisir. D'une manière ou d'une autre, tout est compliqué, confus, et pourtant, à la main, à la main, vous n'écrirez pas le code, vous ne comprendrez rien. Dans cet article, je veux montrer une mise en œuvre simple, non productive, mais, je l'espère, compréhensible de ce merveilleux algorithme. D'accord, allons-y!
Alors, qu'est-ce que le clustering en termes de nos perceptions? Permettez-moi de vous donner un exemple, disons qu'il y a une belle photo avec des fleurs du chalet de votre grand-mère.

La question est: pour déterminer combien de zones sur cette photo sont remplies d'environ la même couleur. Eh bien, ce n’est pas du tout difficile: des pétales blancs - un, des centres jaunes - deux (je ne suis pas biologiste, je ne sais pas comment on les appelle), trois verts. Ces sections sont appelées clusters. Un cluster est une combinaison de données ayant des caractéristiques communes (couleur, position, etc.). Le processus de détermination et de placement de chaque composant des données dans de tels clusters - sections est appelé clustering.
Il existe de nombreux algorithmes de clustering, mais le plus simple d'entre eux est k-medium, qui sera discuté plus tard. K-means est un algorithme simple et efficace, facile à mettre en œuvre à l'aide d'une méthode logicielle. Les données que nous distribuerons en grappes sont des pixels. Comme vous le savez, un pixel de couleur a trois composants - rouge, vert et bleu. L'imposition de ces composants crée ainsi une palette de couleurs existantes.
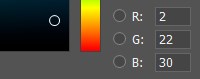
Dans la mémoire de l'ordinateur, chaque composante de couleur est caractérisée par un nombre compris entre 0 et 255. Autrement dit, en combinant différentes valeurs de rouge, vert et bleu, nous obtenons une palette de couleurs à l'écran.
En utilisant des pixels comme exemple, nous implémentons notre algorithme. K-means est un algorithme itératif, c'est-à-dire qu'il donnera le résultat correct, après un certain nombre de répétitions de certains calculs mathématiques.
Algorithme
- Vous devez savoir à l'avance de combien de clusters vous avez besoin pour distribuer les données. C'est un inconvénient important de cette méthode, mais ce problème est résolu par des implémentations améliorées de l'algorithme, mais cela, comme on dit, est une histoire complètement différente.
- Nous devons choisir les centres initiaux de nos grappes. Comment? Oui au hasard. Pourquoi? Pour que vous puissiez accrocher chaque pixel au centre du cluster. Le centre est comme le roi, autour duquel ses sujets sont rassemblés - les pixels. C'est la «distance» du centre au pixel qui détermine à qui chaque pixel obéira.
- Nous calculons la distance de chaque centre à chaque pixel. Cette distance est considérée comme la distance euclidienne entre les points dans l'espace, et dans notre cas, comme la distance entre les trois composantes de couleur:
$$ affiche $$ \ sqrt {(R_ {2} -R_ {1}) ^ 2 + (G_ {2} -G_ {1}) ^ 2 + (B_ {2} -B_ {1}) ^ 2} . $$ afficher $$
Nous calculons la distance du premier pixel à chaque centre et déterminons la plus petite distance entre ce pixel et les centres. Pour le centre, dont la distance est la plus petite, nous recalculons les coordonnées comme moyenne arithmétique entre chaque composante du pixel - le roi et le pixel - du sujet. Notre centre se déplace dans l'espace selon les calculs. - Après avoir recompté tous les centres, nous distribuons les pixels en grappes, en comparant la distance de chaque pixel aux centres. Un pixel est placé dans un cluster, au centre duquel il est plus proche que les autres centres.
- Tout recommence, tant que les pixels restent dans les mêmes grappes. Souvent, cela peut ne pas se produire, car avec une grande quantité de données, les centres se déplacent dans un petit rayon et les pixels le long des bords des clusters sautent dans l'un ou l'autre cluster. Pour ce faire, déterminez le nombre maximal d'itérations.
Implémentation
Je vais implémenter ce projet en C ++. Le premier fichier est «k_means.h», dans lequel j'ai défini les principaux types de données, les constantes et la classe principale pour travailler - «K_means».
Pour caractériser chaque pixel, créez une structure qui se compose de trois composants de pixel, pour lesquels j'ai choisi le type double pour des calculs plus précis, et défini également quelques constantes pour que le programme fonctionne:
const int KK = 10;
K_means se classe:
class K_means { private: std::vector<rgb> pixcel; int q_klaster; int k_pixcel; std::vector<rgb> centr; void identify_centers(); inline double compute(rgb k1, rgb k2) { return sqrt(pow((k1.r - k2.r),2) + pow((k1.g - k2.g), 2) + pow((k1.b - k2.b), 2)); } inline double compute_s(double a, double b) { return (a + b) / 2; }; public: K_means() : q_klaster(0), k_pixcel(0) {}; K_means(int n, rgb *mas, int n_klaster); K_means(int n_klaster, std::istream & os); void clustering(std::ostream & os); void print()const; ~K_means(); friend std::ostream & operator<<(std::ostream & os, const K_means & k); };
Passons en revue les composants de la classe:
vectorpixcel - un vecteur pour les pixels;
q_klaster - nombre de clusters;
k_pixcel - nombre de pixels;
vectorcentr - un vecteur pour regrouper les centres, le nombre d'éléments qu'il contient est déterminé par q_klaster;
identifier_centers () - une méthode pour sélectionner aléatoirement les centres initiaux parmi les pixels d'entrée;
compute () et compute_s () sont des méthodes intégrées pour calculer la distance entre les pixels et les centres de recalcul, respectivement;
trois constructeurs: le premier par défaut, le second pour initialiser les pixels du tableau, le troisième pour initialiser les pixels d'un fichier texte (dans mon implémentation, le fichier est d'abord accidentellement rempli de données, puis les pixels sont lus à partir de ce fichier pour que le programme fonctionne, pourquoi pas directement dans le vecteur - juste nécessaire dans mon cas);
clustering (std :: ostream & os) - méthode de clustering;
méthode et surcharge de l'instruction de sortie pour publier les résultats.
Implémentation de la méthode:
void K_means::identify_centers() { srand((unsigned)time(NULL)); rgb temp; rgb *mas = new rgb[q_klaster]; for (int i = 0; i < q_klaster; i++) { temp = pixcel[0 + rand() % k_pixcel]; for (int j = i; j < q_klaster; j++) { if (temp.r != mas[j].r && temp.g != mas[j].g && temp.b != mas[j].b) { mas[j] = temp; } else { i--; break; } } } for (int i = 0; i < q_klaster; i++) { centr.push_back(mas[i]); } delete []mas; }
Il s'agit d'une méthode pour sélectionner les centres de regroupement initiaux et les ajouter au vecteur central. Une vérification est effectuée pour répéter les centres et les remplacer dans ces cas.
K_means::K_means(int n, rgb * mas, int n_klaster) { for (int i = 0; i < n; i++) { pixcel.push_back(*(mas + i)); } q_klaster = n_klaster; k_pixcel = n; identify_centers(); }
Une implémentation de constructeur pour initialiser des pixels à partir d'un tableau.
K_means::K_means(int n_klaster, std::istream & os) : q_klaster(n_klaster) { rgb temp; while (os >> temp.r && os >> temp.g && os >> temp.b) { pixcel.push_back(temp); } k_pixcel = pixcel.size(); identify_centers(); }
Nous passons un objet d'entrée à ce constructeur pour pouvoir entrer des données à la fois du fichier et de la console.
void K_means::clustering(std::ostream & os) { os << "\n\n :" << std::endl; std::vector<int> check_1(k_pixcel, -1); std::vector<int> check_2(k_pixcel, -2); int iter = 0; while(true) { os << "\n\n---------------- №" << iter << " ----------------\n\n"; { for (int j = 0; j < k_pixcel; j++) { double *mas = new double[q_klaster]; for (int i = 0; i < q_klaster; i++) { *(mas + i) = compute(pixcel[j], centr[i]); os << " " << j << " #" << i << ": " << *(mas + i) << std::endl; } double min_dist = *mas; int m_k = 0; for (int i = 0; i < q_klaster; i++) { if (min_dist > *(mas + i)) { min_dist = *(mas + i); m_k = i; } } os << " #" << m_k << std::endl; os << " #" << m_k << ": "; centr[m_k].r = compute_s(pixcel[j].r, centr[m_k].r); centr[m_k].g = compute_s(pixcel[j].g, centr[m_k].g); centr[m_k].b = compute_s(pixcel[j].b, centr[m_k].b); os << centr[m_k].r << " " << centr[m_k].g << " " << centr[m_k].b << std::endl; delete[] mas; } int *mass = new int[k_pixcel]; os << "\n : "<< std::endl; for (int k = 0; k < k_pixcel; k++) { double *mas = new double[q_klaster]; for (int i = 0; i < q_klaster; i++) { *(mas + i) = compute(pixcel[k], centr[i]); os << " №" << k << " #" << i << ": " << *(mas + i) << std::endl; } double min_dist = *mas; int m_k = 0; for (int i = 0; i < q_klaster; i++) { if (min_dist > *(mas + i)) { min_dist = *(mas + i); m_k = i; } } mass[k] = m_k; os << " №" << k << " #" << m_k << std::endl; } os << "\n : \n"; for (int i = 0; i < k_pixcel; i++) { os << mass[i] << " "; check_1[i] = *(mass + i); } os << std::endl << std::endl; os << " : " << std::endl; int itr = KK + 1; for (int i = 0; i < q_klaster; i++) { os << " #" << i << std::endl; for (int j = 0; j < k_pixcel; j++) { if (mass[j] == i) { os << pixcel[j].r << " " << pixcel[j].g << " " << pixcel[j].b << std::endl; mass[j] = ++itr; } } } delete[] mass; os << " : \n" ; for (int i = 0; i < q_klaster; i++) { os << centr[i].r << " " << centr[i].g << " " << centr[i].b << " - #" << i << std::endl; } } iter++; if (check_1 == check_2 || iter >= max_iterations) { break; } check_2 = check_1; } os << "\n\n ." << std::endl; }
La principale méthode de clustering.
std::ostream & operator<<(std::ostream & os, const K_means & k) { os << " : " << std::endl; for (int i = 0; i < k.k_pixcel; i++) { os << k.pixcel[i].r << " " << k.pixcel[i].g << " " << k.pixcel[i].b << " - №" << i << std::endl; } os << std::endl << " : " << std::endl; for (int i = 0; i < k.q_klaster; i++) { os << k.centr[i].r << " " << k.centr[i].g << " " << k.centr[i].b << " - #" << i << std::endl; } os << "\n : " << k.q_klaster << std::endl; os << " : " << k.k_pixcel << std::endl; return os; }
La sortie des données initiales.
Exemple de sortie
Exemple de sortiePixels de départ:
255 140 50 - n ° 0
100 70 1 - n ° 1
150 20 200 - n ° 2
251 141 51 - n ° 3
104 69 3 - n ° 4
153 22 210 - n ° 5
252 138 54 - n ° 6
101 74 4 - n ° 7
Centres de regroupement initial aléatoires:
150 20 200 - # 0
104 69 3 - # 1
100 70 1 - # 2
Nombre de grappes: 3
Nombre de pixels: 8
Début du cluster:
Numéro d'itération 0
Distance entre le pixel 0 et le centre # 0: 218.918
Distance entre le pixel 0 et le centre # 1: 173,352
Distance entre le pixel 0 et le centre # 2: 176,992
Distance centrale minimale # 1
Recalculer le centre n ° 1: 179,5 104,5 26,5
Distance entre le pixel 1 et le centre # 0: 211.189
Distance entre le pixel 1 et le centre # 1: 90,3369
Distance entre le pixel 1 et le centre # 2: 0
Distance centrale minimale # 2
Recalculer le centre # 2: 100 70 1
Distance entre le pixel 2 et le centre # 0: 0
Distance entre le pixel 2 et le centre # 1: 195.225
Distance entre le pixel 2 et le centre # 2: 211.189
Distance centrale minimale # 0
Compter le centre # 0: 150 20 200
Distance entre le pixel 3 et le centre # 0: 216.894
Distance entre le pixel 3 et le centre # 1: 83,933
Distance entre le pixel 3 et le centre # 2: 174,19
Distance centrale minimale # 1
Compter le centre # 1: 215,25 122,75 38,75
Distance entre le pixel 4 et le centre # 0: 208.149
Distance entre le pixel 4 et le centre # 1: 128,622
Distance entre le pixel 4 et le centre # 2: 4,58258
Distance centrale minimale # 2
Compter le centre # 2: 102 69,5 2
Distance entre le pixel 5 et le centre # 0: 10.6301
Distance entre le pixel 5 et le centre # 1: 208,212
Distance entre le pixel 5 et le centre # 2: 219,366
Distance centrale minimale # 0
Recalculer le centre # 0: 151,5 21 205
Distance entre le pixel 6 et le centre # 0: 215.848
Distance entre le pixel 6 et le centre # 1: 42.6109
Distance entre le pixel 6 et le centre # 2: 172.905
Distance centrale minimale # 1
Recalculer le centre n ° 1: 233,625 130,375 46,375
Distance entre le pixel 7 et le centre # 0: 213.916
Distance entre le pixel 7 et le centre # 1: 150,21
Distance entre le pixel 7 et le centre # 2: 5.02494
Distance centrale minimale # 2
Recalculer le centre n ° 2: 101,5 71,75 3
Classons les pixels:
La distance entre le pixel n ° 0 et le centre # 0: 221.129
La distance entre le pixel n ° 0 et le centre n ° 1: 23,7207
La distance entre le pixel n ° 0 et le centre n ° 2: 174,44
Pixel # 0 le plus proche du centre # 1
La distance entre le pixel n ° 1 et le centre # 0: 216.031
La distance entre le pixel n ° 1 et le centre n ° 1: 153,492
La distance du pixel n ° 1 au centre n ° 2: 3.05164
Pixel # 1 le plus proche du centre # 2
La distance entre le pixel n ° 2 et le centre # 0: 5.31507
La distance entre le pixel n ° 2 et le centre n ° 1: 206,825
La distance entre le pixel n ° 2 et le centre n ° 2: 209,378
Pixel # 2 le plus proche du centre # 0
La distance entre le pixel numéro 3 et le centre # 0: 219.126
La distance entre le pixel n ° 3 et le centre n ° 1: 20,8847
La distance entre le pixel n ° 3 et le centre n ° 2: 171,609
Pixel # 3 le plus proche du centre # 1
La distance entre le pixel n ° 4 et le centre # 0: 212,989
La distance entre le pixel n ° 4 et le centre n ° 1: 149,836
La distance entre le pixel n ° 4 et le centre n ° 2: 3,71652
Pixel # 4 le plus proche du centre # 2
La distance entre le pixel n ° 5 et le centre # 0: 5.31507
La distance entre le pixel n ° 5 et le centre # 1: 212.176
La distance entre le pixel n ° 5 et le centre n ° 2: 219.035
Pixel # 5 le plus proche du centre # 0
La distance entre le pixel numéro 6 et le centre # 0: 215.848
La distance du pixel n ° 6 au centre # 1: 21.3054
La distance du pixel numéro 6 au centre # 2: 172.164
Pixel # 6 le plus proche du centre # 1
La distance du pixel n ° 7 au centre # 0: 213.916
La distance entre le pixel n ° 7 et le centre n ° 1: 150,21
La distance entre le pixel n ° 7 et le centre n ° 2: 2,51247
Pixel # 7 le plus proche du centre # 2
Un tableau de pixels et de centres correspondants:
1 2 0 1 2 0 1 2
Résultat du clustering:
Groupe # 0
150 20 200
153 22 210
Groupe # 1
255 140 50
251 141 51
252 138 54
Groupe # 2
100 70 1
104 69 3
101 74 4
Nouveaux centres:
151,5 21 205 - # 0
233,625 130,375 46,375 - # 1
101,5 71,75 3 - # 2
Numéro d'itération 1
Distance entre le pixel 0 et le centre # 0: 221.129
Distance entre le pixel 0 et le centre # 1: 23.7207
Distance entre le pixel 0 et le centre # 2: 174,44
Distance centrale minimale # 1
Compter le centre # 1: 244.313 135.188 48.1875
Distance entre le pixel 1 et le centre # 0: 216.031
Distance entre le pixel 1 et le centre # 1: 165.234
Distance entre le pixel 1 et le centre # 2: 3.05164
Distance centrale minimale # 2
Recalculer le centre n ° 2: 100,75 70,875 2
Distance entre le pixel 2 et le centre # 0: 5.31507
Distance entre le pixel 2 et le centre # 1: 212,627
Distance entre le pixel 2 et le centre # 2: 210,28
Distance centrale minimale # 0
Recalculer le centre # 0: 150,75 20,5 202,5
Distance entre le pixel 3 et le centre # 0: 217.997
Distance entre le pixel 3 et le centre # 1: 9.29613
Distance entre le pixel 3 et le centre # 2: 172.898
Distance centrale minimale # 1
Compter le centre # 1: 247.656 138.094 49.5938
Distance entre le pixel 4 et le centre # 0: 210.566
Distance entre le pixel 4 et le centre # 1: 166.078
Distance entre le pixel 4 et le centre # 2: 3.88306
Distance centrale minimale # 2
Comptage du centre n ° 2: 102,375 69,9375 2,5
Distance entre le pixel 5 et le centre # 0: 7.97261
Distance entre le pixel 5 et le centre # 1: 219.471
Distance entre le pixel 5 et le centre # 2: 218,9
Distance centrale minimale # 0
Compter le centre # 0: 151.875 21.25 206.25
Distance entre le pixel 6 et le centre # 0: 216.415
Distance entre le pixel 6 et le centre # 1: 6.18805
Distance entre le pixel 6 et le centre # 2: 172.257
Distance centrale minimale # 1
Recalculer le centre # 1: 249.828 138.047 51.7969
Distance entre le pixel 7 et le centre # 0: 215.118
Distance entre le pixel 7 et le centre # 1: 168,927
Distance entre le pixel 7 et le centre # 2: 4,54363
Distance centrale minimale # 2
Recalculer le centre n ° 2: 101,688 71,9688 3,25
Classons les pixels:
La distance du pixel n ° 0 au centre # 0: 221.699
La distance entre le pixel n ° 0 et le centre # 1: 5.81307
La distance entre le pixel n ° 0 et le centre n ° 2: 174,122
Pixel # 0 le plus proche du centre # 1
La distance entre le pixel n ° 1 et le centre # 0: 217.244
La distance entre le pixel n ° 1 et le centre n ° 1: 172,218
La distance entre le pixel n ° 1 et le centre n ° 2: 3,43309
Pixel # 1 le plus proche du centre # 2
La distance entre le pixel n ° 2 et le centre # 0: 6,64384
La distance du pixel n ° 2 au centre # 1: 214.161
La distance entre le pixel n ° 2 et le centre n ° 2: 209,154
Pixel # 2 le plus proche du centre # 0
La distance du pixel n ° 3 au centre # 0: 219.701
Distance entre le pixel # 3 et le centre # 1: 3,27555
La distance entre le pixel n ° 3 et le centre n ° 2: 171,288
Pixel # 3 le plus proche du centre # 1
La distance entre le pixel n ° 4 et le centre # 0: 214.202
La distance entre le pixel n ° 4 et le centre n ° 1: 168,566
La distance entre le pixel n ° 4 et le centre n ° 2: 3,777142
Pixel # 4 le plus proche du centre # 2
La distance entre le pixel n ° 5 et le centre # 0: 3,9863
La distance entre le pixel n ° 5 et le centre n ° 1: 218,794
La distance entre le pixel n ° 5 et le centre n ° 2: 218.805
Pixel # 5 le plus proche du centre # 0
La distance entre le pixel numéro 6 et le centre # 0: 216.415
La distance entre le pixel n ° 6 et le centre # 1: 3.09403
La distance entre le pixel n ° 6 et le centre n ° 2: 171,842
Pixel # 6 le plus proche du centre # 1
La distance du pixel n ° 7 au centre # 0: 215.118
La distance entre le pixel n ° 7 et le centre n ° 1: 168,927
La distance entre le pixel n ° 7 et le centre n ° 2: 2,27181
Pixel # 7 le plus proche du centre # 2
Un tableau de pixels et de centres correspondants:
1 2 0 1 2 0 1 2
Résultat du clustering:
Groupe # 0
150 20 200
153 22 210
Groupe # 1
255 140 50
251 141 51
252 138 54
Groupe # 2
100 70 1
104 69 3
101 74 4
Nouveaux centres:
151,875 21,25 206,25 - # 0
249.828 138.047 51.7969 - # 1
101,688 71,9688 3,25 - # 2
La fin du clustering.
Cet exemple est prévu à l'avance, les pixels sont sélectionnés spécifiquement pour la démonstration. Deux itérations suffisent pour que le programme regroupe les données en trois clusters. En regardant les centres des deux dernières itérations, vous pouvez voir qu'ils sont pratiquement restés en place.
Plus intéressants sont les cas de pixels générés aléatoirement. Ayant généré 50 points qui doivent être divisés en 10 grappes, j'ai obtenu 5 itérations. Ayant généré 50 points qui doivent être divisés en 3 clusters, j'ai obtenu les 100 itérations maximales autorisées. Vous pouvez remarquer que plus il y a de clusters, plus il est facile pour le programme de trouver les pixels les plus similaires et de les combiner en petits groupes, et vice versa - s'il y a peu de clusters et qu'il y a beaucoup de points, l'algorithme se termine souvent uniquement lorsque le nombre maximum d'itérations est dépassé, car certains pixels sautent constamment d'un cluster à l'autre. Cependant, la majeure partie est encore complètement déterminée dans leurs grappes.
Eh bien, vérifions maintenant le résultat du clustering. En prenant le résultat de certains clusters de l'exemple de 50 points pour 10 clusters, j'ai conduit le résultat de ces données dans Illustrator et c'est ce qui s'est passé:
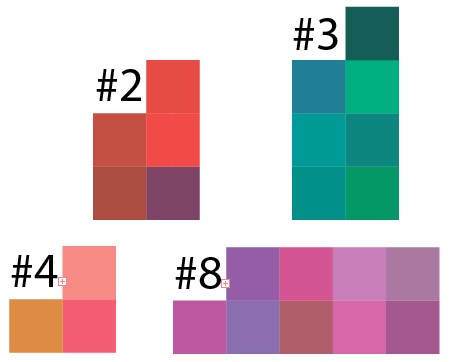
On peut voir que dans chaque groupe, toutes les nuances de couleur prévalent, et ici vous devez comprendre que les pixels ont été sélectionnés au hasard, l'analogue d'une telle image dans la vie réelle est une sorte d'image sur laquelle toutes les couleurs ont été accidentellement pulvérisées et il est difficile de sélectionner des zones de couleurs similaires.
Disons que nous avons une telle photo. Nous pouvons définir une île comme un seul cluster, mais avec une augmentation, nous voyons qu'elle se compose de différentes nuances de vert.

Et c'est le cluster 8, mais dans une version plus petite, le résultat est similaire:

La version complète du programme peut être consultée sur mon
GitHub .