Institut de technologie du Massachusetts. Cours magistral # 6.858. "Sécurité des systèmes informatiques." Nikolai Zeldovich, James Mickens. 2014 année
Computer Systems Security est un cours sur le développement et la mise en œuvre de systèmes informatiques sécurisés. Les conférences couvrent les modèles de menace, les attaques qui compromettent la sécurité et les techniques de sécurité basées sur des travaux scientifiques récents. Les sujets incluent la sécurité du système d'exploitation (OS), les fonctionnalités, la gestion du flux d'informations, la sécurité des langues, les protocoles réseau, la sécurité matérielle et la sécurité des applications Web.
Cours 1: «Introduction: modèles de menace»
Partie 1 /
Partie 2 /
Partie 3Conférence 2: «Contrôle des attaques de pirates»
Partie 1 /
Partie 2 /
Partie 3Conférence 3: «Débordements de tampon: exploits et protection»
Partie 1 /
Partie 2 /
Partie 3Conférence 4: «Séparation des privilèges»
Partie 1 /
Partie 2 /
Partie 3Conférence 5: «D'où viennent les systèmes de sécurité?»
Partie 1 /
Partie 2Conférence 6: «Opportunités»
Partie 1 /
Partie 2 /
Partie 3Conférence 7: «Native Client Sandbox»
Partie 1 /
Partie 2 /
Partie 3Conférence 8: «Modèle de sécurité réseau»
Partie 1 /
Partie 2 /
Partie 3Conférence 9: «Sécurité des applications Web»,
partie 1 /
partie 2 /
partie 3Conférence 10: «Exécution symbolique»
Partie 1 /
Partie 2 /
Partie 3Conférence 11: «Ur / Web Programming Language»
Partie 1 /
Partie 2 /
Partie 3Conférence 12: Sécurité du réseau,
partie 1 /
partie 2 /
partie 3Conférence 13: «Protocoles réseau»,
partie 1 /
partie 2 /
partie 3 Donc, aujourd'hui, nous allons parler de Kerberos, un protocole cryptographiquement sécurisé conçu pour l'authentification mutuelle des ordinateurs et des applications sur le réseau. Il s'agit d'un protocole permettant d'authentifier le client et le serveur avant d'établir une connexion entre eux.
Alors maintenant, enfin, nous allons utiliser la cryptographie, contrairement à la dernière conférence, où nous avons examiné la sécurisation en utilisant uniquement les numéros de séquence TCP SYN.

Parlons donc de Kerberos. Qu'est-ce qui essaie de supporter ce protocole? Il a été créé dans notre institut il y a 25 ou 30 ans dans le cadre du projet Athena pour assurer l'interaction de plusieurs ordinateurs serveurs et de plusieurs ordinateurs clients.
Imaginez que vous ayez un serveur de fichiers quelque part. Il s'agit peut-être d'un serveur de messagerie connecté au réseau ou d'autres services réseau, tels que des imprimantes. Et tout cela est simplement connecté à un réseau et non à des processus sur un ordinateur.

La condition préalable à la création d'Athena et Kerberos était que vous disposiez d'une machine pour le partage simultané, où tout était un processus distinct, et tout le monde pouvait simplement se connecter au même système et y stocker leurs fichiers. Par conséquent, les développeurs voulaient créer un système distribué plus pratique.
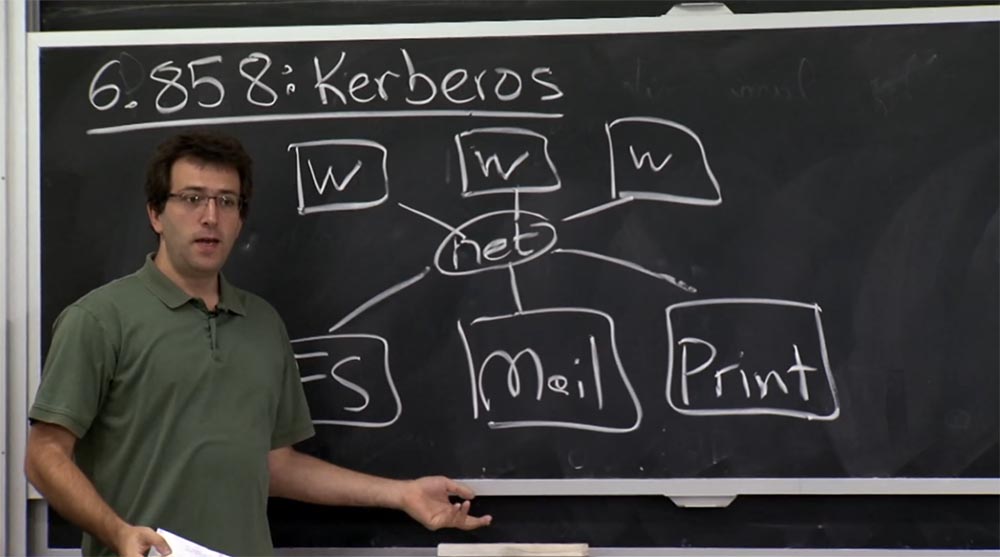
Ainsi, cela signifiait que vous auriez ces serveurs d'un côté et un tas de postes de travail de l'autre côté que les utilisateurs utiliseraient eux-mêmes et sur lesquels les applications s'exécuteraient. Ces postes de travail se connectent à ces serveurs et stockent les fichiers utilisateur, reçoivent leur courrier, etc.
Le problème qu'ils voulaient résoudre était de savoir comment authentifier les utilisateurs qui utilisent ces postes de travail pour tous ces différents ordinateurs côté serveur, sans avoir à faire confiance au réseau et à vérifier son exactitude. C'était à tous égards une exigence de conception raisonnable. Je dois mentionner qu'à cette époque, l'alternative à Kerberos était l'équipe de connexion R, discutée dans la dernière conférence, ce qui semblait être un mauvais plan, car ils utilisent simplement leurs adresses IP pour authentifier les utilisateurs.
Kerberos a connu un certain succès, il est en fait toujours utilisé sur le réseau MIT et est l'épine dorsale du serveur Active Directory de Microsoft. Presque tous les produits basés sur Microsoft Windows Server utilisent Kerberos sous une forme ou une autre.
Mais ce protocole a été développé il y a 25 ou 30 ans, et depuis lors, des changements ont été nécessaires, car les gens comprennent aujourd'hui beaucoup plus la sécurité. Ainsi, la version actuelle de Kerberos est sensiblement différente à bien des égards de la version décrite dans les documents de cette conférence. Nous examinerons quelles hypothèses particulières ne sont pas assez bonnes aujourd'hui et ce qui n'allait pas dans la première version. Cela est inévitable pour le premier protocole qui a vraiment utilisé la cryptographie pour authentifier les participants du réseau dans un système complet.
Dans tous les cas, le schéma représenté sur la carte est une sorte d'installation pour créer Kerberos. Il est intéressant de savoir quel est le modèle de confiance. Par conséquent, une structure supplémentaire est introduite dans notre schéma - le serveur Kerberos, situé ici sur le côté.
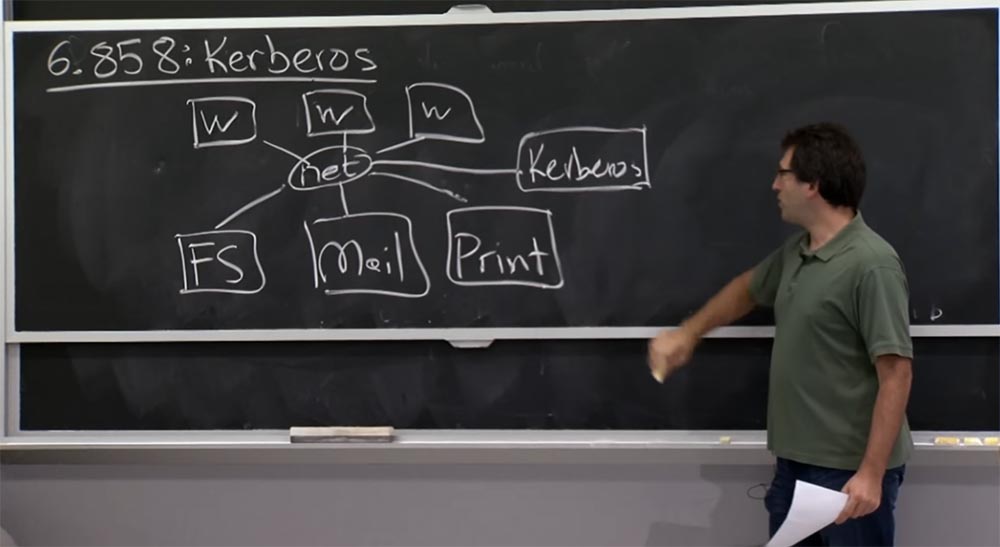
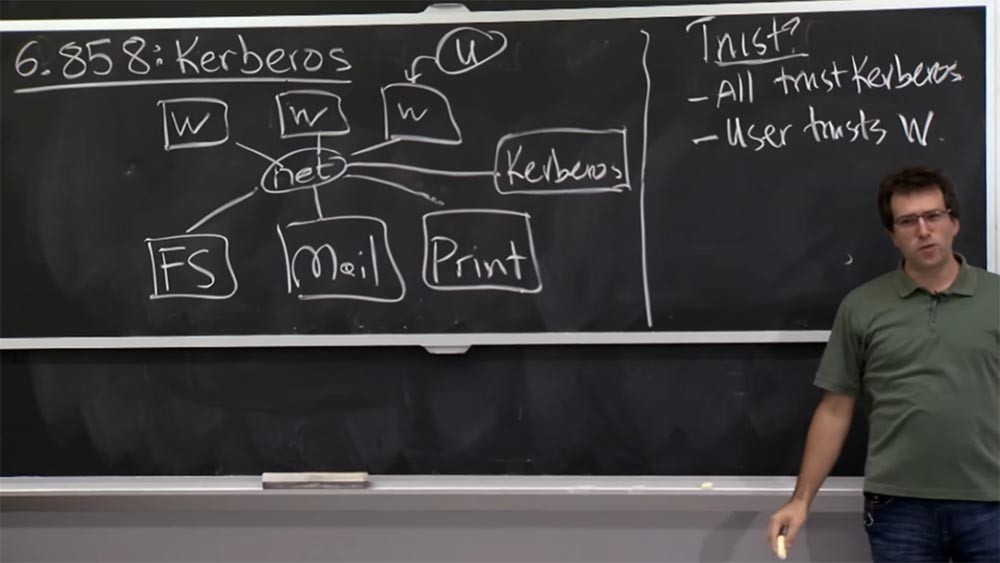
Ainsi, notre troisième modèle est en quelque sorte basé sur le fait que le réseau n'est pas fiable, comme nous l'avons mentionné dans la dernière conférence. À qui devons-nous faire confiance dans ce programme Kerberos? Bien sûr, tous les participants au réseau doivent faire confiance au serveur Kerberos. Ainsi, les créateurs du système ont suggéré à un moment donné que le serveur Kerberos serait responsable de toutes les vérifications de l'authentification réseau sous une forme ou une autre. Que pouvons-nous faire d'autre sur ce réseau en qui vous pouvez avoir confiance?
Étudiant: les utilisateurs peuvent faire confiance à leurs propres machines.
Professeur: oui, c'est un bon argument. Il y a des utilisateurs ici que je n'ai pas dessinés. Mais ces gars-là utilisent une sorte de poste de travail, et en fait, dans Kerberos, il est très important que l'utilisateur fasse confiance à son poste de travail. Que se passe-t-il si vous ne faites pas confiance à votre poste de travail? Parce que si l'utilisateur ne fait pas confiance au poste de travail, vous pouvez simplement "flairer" votre mot de passe et agir en votre nom.
 Étudiant:
Étudiant: un attaquant peut faire bien plus, par exemple, en apprenant votre ticket sur le serveur Kerberos.
Professeur: oui, exactement. Lorsque vous vous connectez, vous entrez votre mot de passe, ce qui est encore pire qu'un ticket. Donc en réalité, il y a un petit problème avec Kerberos si vous ne faites pas confiance au poste de travail. Si vous utilisez votre propre ordinateur portable, ce n'est pas si effrayant, mais la sécurité d'un ordinateur public est mise en doute. Nous examinerons ce qui peut mal tourner dans ce cas.
Étudiant: vous devez faire confiance aux administrateurs de serveur et être sûr qu'ils peuvent avoir un accès privilégié aux serveurs les uns des autres.
Professeur: Je pense que les machines elles-mêmes n'ont pas à se faire mutuellement confiance, par exemple, le serveur de messagerie n'a pas à faire confiance au serveur d'impression ou au serveur de fichiers.
Étudiant: ne faites pas confiance, mais avez la possibilité d'accéder à un serveur auquel l'accès via un autre serveur n'est pas pris en charge.
Professeur: oui, c'est vrai. Si vous établissez une relation de confiance entre le serveur de messagerie et le serveur d'impression, mais donnez simplement au serveur de messagerie l'accès à vos fichiers sur le serveur de fichiers pour plus de commodité, cela peut être abusé. Vous devez donc être prudent lorsque vous introduisez ici des niveaux de confiance supplémentaires ou des approbations redondantes.
Quoi d'autre importe ici? Les serveurs devraient-ils en quelque sorte faire confiance aux utilisateurs ou aux postes de travail? Je suppose que non. L'objectif global de Kerberos était que le serveur a priori ne devrait pas connaître tous ces utilisateurs ou postes de travail, ni savoir comment les authentifier, jusqu'à ce que ces utilisateurs puissent prouver de manière cryptographique qu'ils sont des utilisateurs légitimes et doivent avoir accès à leurs données ou quelque chose plus que le serveur ne gère.
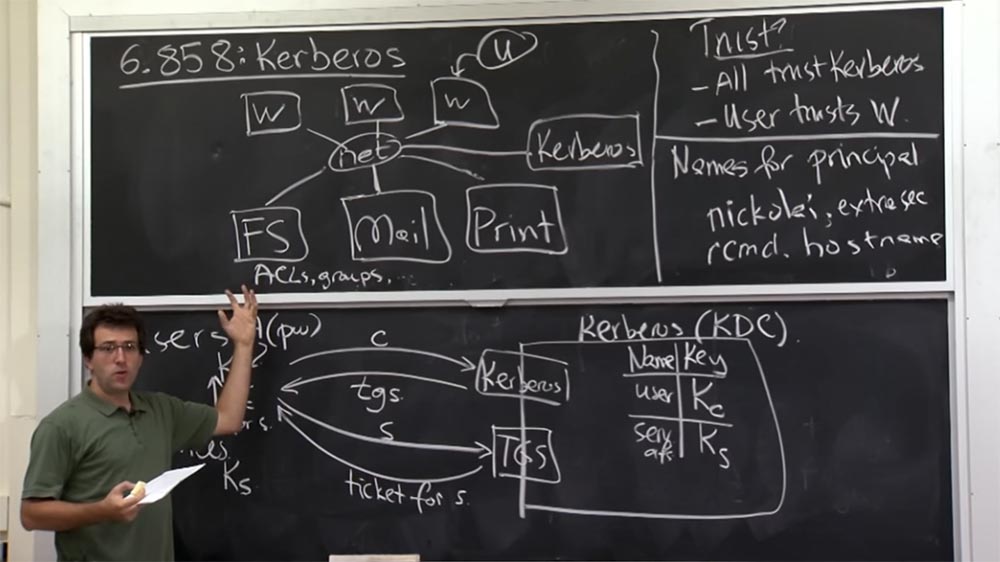
Voyons comment Kerberos fonctionne et quelle est son architecture générale. Dessinons un serveur Kerberos à plus grande échelle. De nos jours, il s'appelle KDC - Key Distribution Center, ou Key Providing Center. Quelque part, il existe des utilisateurs et des services auxquels vous pouvez vous connecter. Le plan est que le serveur Kerberos sera responsable du stockage de la clé partagée pour la communication entre le serveur Kerberos et chaque entité informatique dans le monde qui l'entoure. Ainsi, si l'utilisateur possède une sorte de clé client Kc, le serveur Kerberos se souvient de cette clé et la stocke quelque part à l'intérieur de lui-même. De la même manière, la clé Ks d'un service ne sera connue que de ce service lui-même, du serveur Kerberos et de personne d'autre. Ainsi, vous pouvez le considérer comme une utilisation courante des mots de passe lorsque vous connaissez le mot de passe et que Kerberos le connaît, mais que personne d'autre ne le connaît.

Voilà comment vous allez vous prouver que "je suis le même gars". Bien sûr, le serveur Kerberos devra garder une trace de qui possède cette clé, il devrait donc avoir une table dans laquelle les noms d'utilisateur et les noms de service, par exemple, serv afs (il s'agit d'un serveur de fichiers), et les clés qui leur correspondent seront stockées.
Dans le même temps, KDC est responsable du stockage d'une table géante, pas très grande en termes de nombre d'octets, mais très volumineuse en nombre d'enregistrements, car elle prend en compte toute entité informatique vivant dans le réseau MIT que le serveur Kerberos devrait connaître. Ainsi, nous avons deux types d'interface.

Le matériel de cours n'en parle pas assez clairement, c'est-à-dire que l'existence de ces 2 interfaces est simplement implicite. En fait, il y a vraiment deux interfaces pour une machine. L'un d'eux s'appelle Kerberos et le second est TGS, Ticket Granting Service ou Ticket Service.
En fait, en fin de compte, ce ne sont que deux façons de parler de la même chose, et le protocole n'est que légèrement différent pour ces deux choses. Par conséquent, initialement, lorsqu'un utilisateur se connecte, il «parle» avec l'interface supérieure, Kerberos, et lui envoie son nom de client C, cela peut être votre nom d'utilisateur sur le réseau universitaire Athena.
Le serveur répond à cette demande avec un ticket tgs ou des informations de ticket, nous discuterons un peu plus tard des détails de ces informations. Ensuite, lorsque vous voulez discuter avec un service, vous devez d'abord aller sur l'interface TGS et lui dire: "Je me suis déjà connecté via l'interface Kerberos et maintenant je veux parler au serveur S, qui me fournira un certain service."
Vous parlez donc à TGS du serveur auquel vous souhaitez parler, après quoi il vous reviendra quelque chose comme un ticket pour parler au serveur S. Ensuite, vous pourrez enfin parler au serveur dont vous avez besoin en utilisant le ticket reçu pour le serveur S.
Il s'agit d'une sorte de plan de haut niveau. Alors pourquoi 2 interfaces sont-elles utilisées ici? Beaucoup de questions peuvent être posées à ce sujet. Dans le cas du serveur Ks, ce service sera probablement stocké sur disque. Et qu'advient-il de ce Kc côté utilisateur? D'où vient ce Kc à Kerberos?
 Étudiant:
Étudiant: ce Kc doit être dans la base de données, dans la table du serveur KDC.
Professeur: oui, eh bien, la clé C est ici dans le tableau, dans cette gigantesque base de données. Mais il doit également être connu de l'utilisateur, car l'utilisateur doit prouver qu'il est un utilisateur.
Etudiant: est-ce une fonction unidirectionnelle qui nécessite alors un mot de passe?
Professeur: oui, ils ont en fait un plan si intelligent, où Kc est obtenu en hachant le mot de passe de l'utilisateur ou une sorte de fonction de génération de clés, il existe plusieurs méthodes différentes pour cela. Mais en gros, nous prenons le mot de passe, le convertissons d'une manière ou d'une autre et obtenons cette clé Kc. Cela semble donc être un bon moyen.
Mais pourquoi avons-nous besoin de deux protocoles? Après tout, vous pouvez imaginer que vous demandez simplement un ticket directement à partir de la première interface Kerberos, en lui disant: "hé, je veux un ticket pour ce nom particulier!", Il vous renverra le ticket, et vous pouvez le décrypter en utilisant Kc.
Étudiant: peut-être ne veut-il pas que l'utilisateur ressaisisse son mot de passe à chaque fois qu'il souhaite accéder à un autre service?
Professeur: vrai, la raison de la différence entre les deux interfaces est que depuis la première interface toutes les réponses sont retournées cryptées avec votre clé Kc, et les créateurs de Kerberos s'inquiétaient de la possibilité de conserver ce Kc pendant une longue période. Parce que soit vous devez demander à l'utilisateur de saisir le mot de passe à chaque fois, ce qui est juste ennuyeux, soit il «reste» constamment dans la mémoire. Fondamentalement, cela équivaut à un simple mot de passe utilisateur, car une personne disposant d'un accès Kc peut conserver l'accès aux fichiers de l'utilisateur jusqu'à ce que l'utilisateur modifie son mot de passe, voire plus. Plus tard, nous examinerons cette question plus en détail.
La fuite de cette clé Kc est donc une chose très dangereuse. Ainsi, l'intérêt d'utiliser la première puis la deuxième interface pour toutes les requêtes suivantes est que vous pouvez réellement oublier Kc dès que vous déchiffrez la réponse de l'interface TGS du serveur Kerberos. Désormais, même en cas de fuite de clé, la fonctionnalité dépendra du ticket reçu. Donc, dans le pire des cas, quelqu'un aura accès à votre compte pendant quelques heures, et non pour une durée illimitée. C'est la raison d'un tel schéma avec deux chemins d'accès aux mêmes ressources.
Donc, avant de nous plonger dans la mécanique de l'apparence réelle de ces protocoles sur le réseau, parlons un peu de l'aspect des noms Kerberos. Dans un sens, Kerberos peut être considéré comme un registre de noms. Il est responsable de l'affichage de ces clés cryptographiques sous forme de noms en minuscules. C'est le type d'opération fondamental que Kerberos effectue. Vous verrez dans la prochaine conférence pourquoi nous avons besoin d'une fonction similaire. Il peut être implémenté différemment de Kerberos, mais il est fondamentalement très important d'avoir une chose similaire dans presque tous les systèmes de sécurité distribués. Voyons donc comment Kerberos gère les noms.
Kerberos a quelque chose comme des appels système pour chaque entité informatique dans la base de données des membres du réseau, et la forme principale de ces données est juste une chaîne. Vous pouvez donc avoir des noms de base sous une forme comme nickolai, par exemple. Il s'agit de la chaîne de nom.

C'est le paramètre principal dans une zone de Kerberos, en fait c'est la chose qui se trouve dans la colonne de gauche de la table KDC. Et il existe également des paramètres supplémentaires pris en charge par le protocole. Je pourrais, par exemple, entrer un autre nom comme nickolai.extra sec, qui serait utilisé en plus du nom nickolai pour accéder aux ressources qui ont besoin d'une sécurité supplémentaire. Alors peut-être que j'aurai un mot de passe pour des choses vraiment sûres et un autre mot de passe pour mon compte régulier.
Kerberos a mentionné cet aspect. Par conséquent, on peut se demander - d'où vient l'impact? Le service Kerberos mappe des noms pour vous à certaines clés, mais comment savoir quel nom demander ou quel nom attendre en réponse lorsque vous parlez à un ordinateur? Autrement dit, je demande quels noms apparaissent en dehors du serveur Kerberos, ou où exactement ces noms d'utilisateurs apparaissent-ils? Avez-vous des idées?
Étudiant: vous pouvez probablement demander des noms d'utilisateur au serveur MIT.
Professeur: oui, bien sûr. Voici comment vous pouvez lister ces choses. De plus, les utilisateurs les saisissent simplement lorsqu'ils se connectent, d'où ils viennent. Les noms d'utilisateur apparaissent-ils ailleurs? Doivent-ils apparaître ailleurs?
Etudiant: il est possible que l'accès utilisateur soit indiqué dans les listes des différents services.
Professeur: oui, c'est un point vraiment important, non? Le but de Kerberos est de simplement mapper les clés aux noms. Mais cela ne vous dit pas à quoi ce nom devrait avoir accès.
En fait, la façon dont les applications utilisent généralement Kerberos est que l'un de ces serveurs utilise Kerberos pour déterminer le nom en minuscule auquel il parle. Lorsque le serveur de messagerie reçoit une connexion d'un poste de travail, il reçoit un ticket Kerberos, ce qui prouve que cet utilisateur est Nikolai. Après cela, le serveur de messagerie recherche en interne à quoi cet utilisateur a accès. Le serveur de fichiers fait de même.
Ainsi, à l'intérieur de tous ces serveurs, il y a des listes de contrôle d'accès, éventuellement des listes de groupes ou d'autres choses qui effectuent une autorisation. Kerberos fournit donc une authentification qui vous montre à qui vous parlez. Le service lui-même est responsable de la mise en œuvre de cette partie de l'autorisation, qui décide du niveau d'accès que vous devriez avoir en fonction de votre nom d'utilisateur. Nous avons donc compris où les noms d'utilisateur apparaissent. Il existe d'autres noms de base pris en charge par Kerberos pour interagir avec les services.
Selon les documents de cours, les services ressemblent à ceci: rcmd.hostname. La raison pour laquelle vous avez besoin d'un nom pour l'un de ces services est que vous souhaitez, par exemple, lors de la connexion à un serveur de fichiers, effectuer une authentification mutuelle. Cela signifie que dans cette procédure, non seulement le serveur de destination découvre qui je suis, mais moi, l'utilisateur ou le poste de travail, je m'assure que je parle au bon serveur de fichiers, et non à un faux serveur de fichiers qui a truqué le mien fichiers. Parce que, peut-être, je veux regarder le fichier avec mes notes et l'envoyer au registraire. Par conséquent, il serait dommage qu'un autre serveur de fichiers puisse agir comme le bon serveur et me fournir le mauvais fichier d'évaluation.
Par conséquent, les services ont également besoin de leur propre nom et les postes de travail doivent savoir quel nom je m'attends à voir lorsque je me connecte au service.
En règle générale, à un certain niveau, cela vient de l'utilisateur. Ainsi, par exemple, si je tape ssh.foo, cela signifie que je dois m'attendre à ce qu'un nom principal Kerberos comme rcmd.foo apparaisse à l'autre extrémité de cette connexion. Et si quelqu'un d'autre est là, le client SSH doit se déconnecter et ne pas me permettre de me connecter, car alors je serai induit en erreur et commencerai à parler à une autre machine.
Cela soulève une question intéressante. Quand peut-on réutiliser des noms dans Kerberos? Par exemple, vous avez tous des comptes dans le système de l'institut Athena. Lorsque vous serez diplômé, le MIT peut-il détruire votre entrée de base de données et permettre à quelqu'un d'autre d'enregistrer le même nom d'utilisateur? Serait-ce une bonne idée?
Etudiant: mais pas seulement la base de données Kerberos, mais aussi les services ont une liste de noms d'utilisateurs?
Professeur: oui, car ces noms sont en fait juste représentés par des entrées de chaîne quelque part dans l'ACL sur un serveur de fichiers ou de messagerie. Si nous supprimons votre entrée dans la base de données du serveur Kerberos, cela ne signifie pas que votre entrée a complètement disparu. Ces entrées sont indépendantes de la version.
Par exemple, un enregistrement indique qu'Alice a accès à un casier Athena. , , - , Kerberos. , , .
, Kerberos , Kerberos . , , , .
. , , , , , . , , , - . , . , , .
, . , , , TGS.

, , Kerberos, «». : s , IP – addr, time stump, life, , , Kc,s, . .

.
, Kerberos «». Ac , IP- , , . , . K,s, , Kerberos Ks. , .
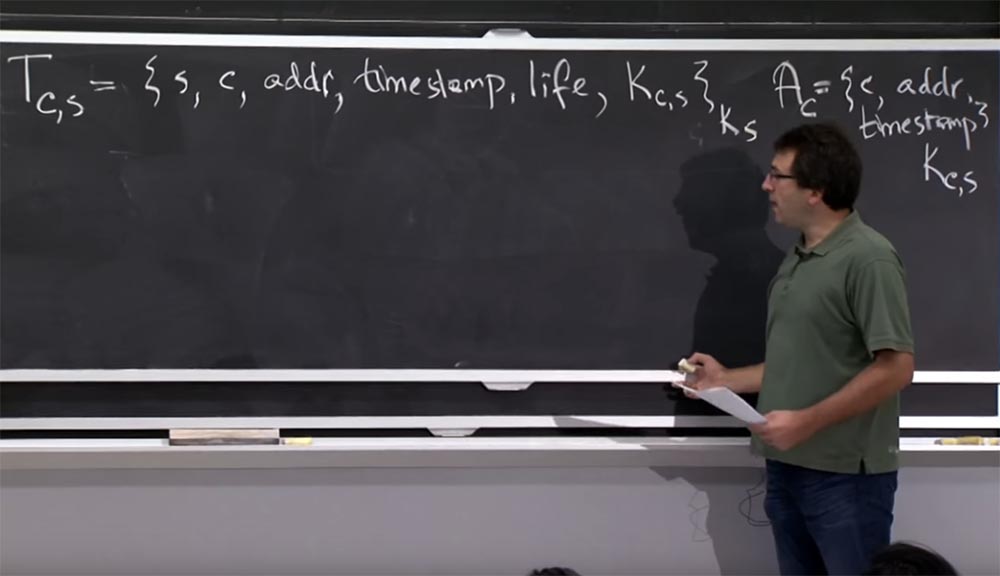
, , Kerberos TGS. , , Kerberos, , . : C, , S, TGS. .
Tc,s, Ks, , Ks, , Kc. .
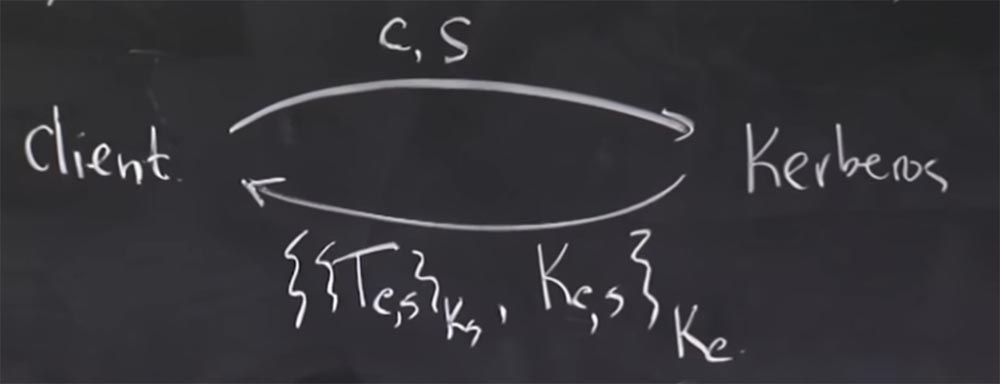
. , Kerberos ? , ?
: , , , Kc.
: , , Kerberos , . : «, , . , , , Kc». , .
, , , Kerberos, Kerberos , . , , - Kerberos, , .
: …
: , , Kerberos, ? , ? , , , , , , , , , .

«», , , , , . , , . . Kerberos, , . , , .
: ? , …
: , . , Kerberos , . , , - , , , . 30 , .
Kerberos 5 : , — . , , , , .
Kerberos 4 , , , . , . , , .
, , , . , . — K,s - ? K,s T,s. K,s?
27:10
MIT « ». 13: « », 2.
Merci de rester avec nous. ? Vous voulez voir des matériaux plus intéressants? Soutenez-nous en passant une commande ou en le recommandant à vos amis, une
réduction de 30% pour les utilisateurs Habr sur un analogue unique de serveurs d'entrée de gamme que nous avons inventés pour vous: Toute la vérité sur VPS (KVM) E5-2650 v4 (6 cœurs) 10 Go DDR4 240 Go SSD 1 Gbps à partir de 20 $ ou comment diviser le serveur? (les options sont disponibles avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).
VPS (KVM) E5-2650 v4 (6 cœurs) 10 Go DDR4 240 Go SSD 1 Gbit / s jusqu'en décembre gratuitement en payant pour une période de six mois, vous pouvez commander
ici .
Dell R730xd 2 ? Nous avons seulement
2 x Intel Dodeca-Core Xeon E5-2650v4 128 Go DDR4 6x480 Go SSD 1 Gbps 100 TV à partir de 249 $ aux Pays-Bas et aux États-Unis! Pour en savoir plus sur la
création d'un bâtiment d'infrastructure. classe utilisant des serveurs Dell R730xd E5-2650 v4 coûtant 9 000 euros pour un sou?