
Une chose aussi romantique qu'un ciel étoilé et une chose aussi hardcore que l'optimisation de la consommation de mémoire par une application iOS peuvent bien aller de pair: cela vaut la peine d'essayer de pousser ce ciel étoilé dans une application AR, et la question de la même consommation se posera immédiatement.
Pour minimiser l'utilisation de la mémoire sera utile dans de nombreux autres cas. Donc, ce texte sur l'exemple d'un petit projet montre des méthodes d'optimisation qui peuvent être utiles dans des applications iOS complètement différentes (et pas seulement iOS-).
Le message a été préparé sur la base d'une transcription du rapport de
Conrad Filer de la conférence Mobius 2018 Piter. Nous attachons sa vidéo, puis une version texte à la première personne:
Heureux d'accueillir tout le monde! Je m'appelle Conrad Filer, et sous le nom spectaculaire de «Un million d'étoiles dans un iPhone», nous verrons comment vous pouvez réduire la taille de la mémoire occupée par votre application iOS. Coloré et en exemples.
Pourquoi optimiser?
Qu'est-ce qui nous encourage généralement à faire de l'optimisation, que souhaitons-nous exactement? Nous ne voulons pas cela:
Nous ne voulons pas que l'utilisateur attende. Autrement dit, la première raison est de
réduire le temps de démarrage .
Une autre raison est
d'améliorer la qualité .

Nous pouvons parler de la qualité des images, du son et même de l'IA. «AI optimisée» signifie que vous pouvez en faire plus - par exemple, calculer le jeu pour un plus grand nombre de mouvements en avant.
La troisième raison est très importante:
économiser la batterie . L'optimisation permet de décharger moins la batterie. Voici une comparaison intéressante, quoique du monde Android. Ici comparé Vulkan et OpenGL ES:

Le second est pire optimisé pour les plateformes mobiles. En observant la vitesse de consommation d'énergie de la batterie, vous pouvez voir que pour une image similaire, OpenGL ES a dépensé beaucoup plus de ressources que Vulkan.
Quel type d'optimisation peut aider ici? Par exemple, dans un jeu au tour par tour, lorsque l'utilisateur pense à son coup, vous pouvez réduire le FPS à zéro. Si vous avez un moteur 3D, il est tout à fait sage de tout désactiver pendant que l'utilisateur regarde simplement l'écran.
De plus, il y a des moments où, sans approche optimisée, vous ne pourrez pas implémenter l'une ou l'autre fonctionnalité avancée: elle ne sera tout simplement pas tirée.
Pas de fanatisme
Parlant d'optimisation, on ne peut que rappeler la thèse de Donald Knuth: «Il faut oublier la faible efficacité, disons, dans 97% des cas: l'optimisation prématurée est à l'origine de tous les maux. Bien que nous ne devrions pas abandonner nos capacités dans ces 3% critiques. "
Dans 97% des cas, nous ne devons pas nous soucier de l'efficacité, mais d'abord de la façon de rendre notre code compréhensible, sûr et testable. Nous développons toujours pour les appareils mobiles, et non pour les vaisseaux spatiaux. Les entreprises dans lesquelles nous travaillons ne devraient pas payer trop cher pour le support du code que nous avons écrit. De plus, le temps de travail du développeur a un coût, et si vous le dépensez pour optimiser quelque chose de non essentiel, vous dépensez l'argent de l'entreprise. Eh bien, le fait qu'un code bien optimisé ait tendance à être plus difficile à comprendre, vous pouvez le voir pour les exemples que je vais vous montrer aujourd'hui.
En général, hiérarchisez et optimisez de manière significative au besoin.
Les approches
Lorsque nous travaillons sur l'optimisation, nous surveillons généralement les performances (lecture: charge du processeur) ou la quantité de mémoire utilisée. Souvent, ces deux options entrent en conflit et vous devrez trouver un équilibre entre elles.
Dans le cas du processeur, nous pouvons réduire le nombre de cycles de processeur requis par nos opérations. Comme vous le savez, moins de cycles de processeur nous donnent moins de temps de chargement, moins de consommation de batterie, la capacité de fournir une meilleure qualité, etc.
Pour les développeurs iOS, Xcode Instruments dispose d'un outil Time Profiler pratique. Il vous permet de suivre le nombre de cycles CPU dépensés par différentes parties de votre application. Ce rapport ne concerne pas les outils, donc je ne vais pas entrer dans les détails maintenant, il y avait une bonne vidéo de la WWDC à ce sujet.
Vous pouvez choisir un autre objectif - l'optimisation pour la mémoire. Nous essaierons de nous assurer qu'au démarrage, notre application tient dans le plus petit nombre possible de cellules RAM. N'oubliez pas que les applications les plus volumineuses sont les premiers candidats à un arrêt forcé lors du nettoyage, que l'OS est obligé de réaliser. Par conséquent, cela affecte la durée pendant laquelle votre application reste en arrière-plan.
Il est également important que la ressource RAM pour différents appareils soit également différente. Par exemple, si vous décidez de développer pour Apple Watch, la mémoire est insuffisante, ce qui vous permet également d'optimiser.
Enfin, parfois une petite quantité de mémoire rend également le programme très rapide. Je vais vous donner un exemple. Voici les structures de différentes tailles en octets:

Element8 contient 8 octets, Element16 - 16, etc.

Nous allons créer des tableaux, un pour chacun de nos types de structures. La dimension de tous les tableaux est la même - 10 000 éléments. Chaque structure contient un nombre différent de champs (croissant); le champ n est le premier champ et, par conséquent, il est présent dans toutes les structures.
Essayons maintenant ce qui suit: pour chaque tableau, nous calculerons la somme de tous ses champs n. Autrement dit, à chaque fois, nous additionnerons le même nombre d'éléments (10 000 pièces). La seule différence est que pour chaque somme la variable n sera extraite de structures de tailles différentes. Nous voulons savoir si la sommation prend le même temps.
Le résultat est le suivant:
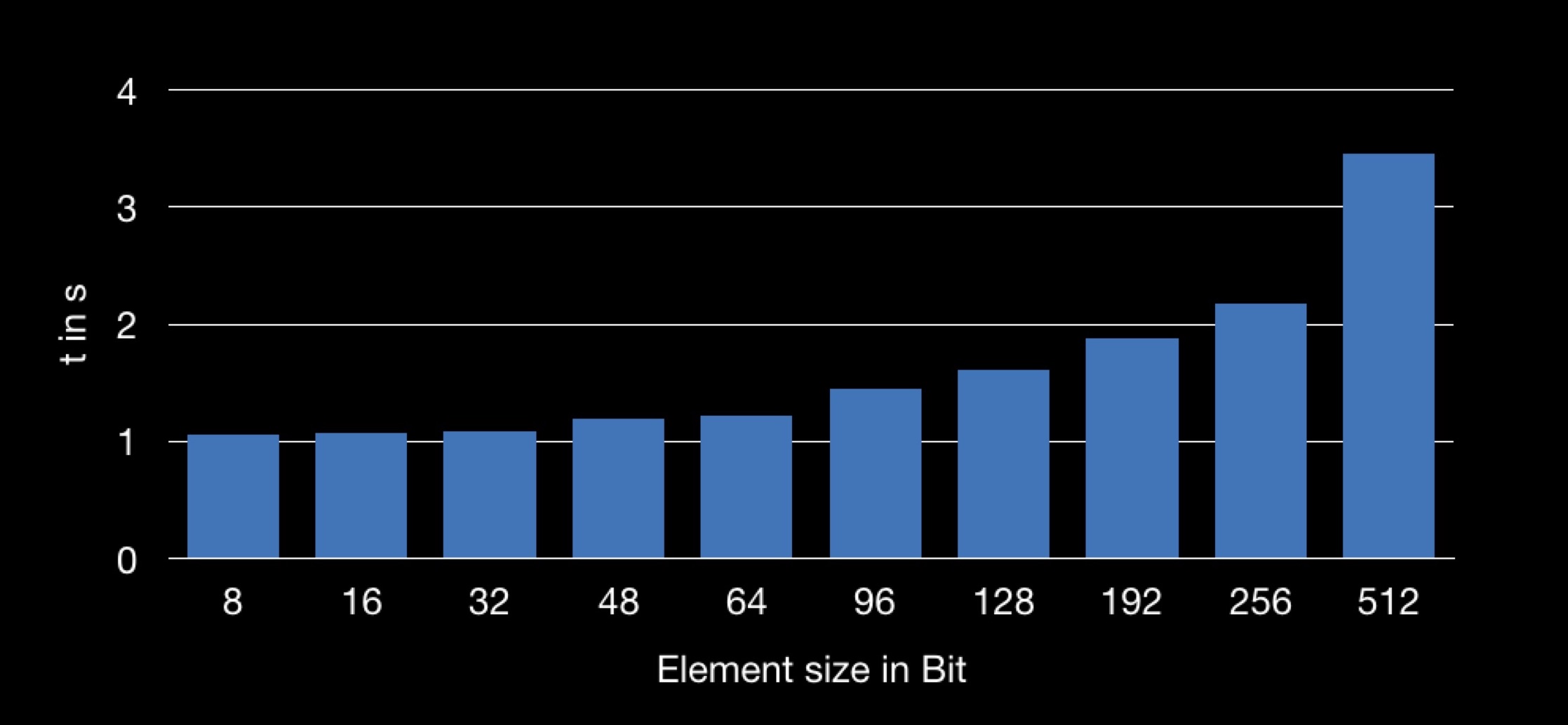
Le graphique montre la dépendance du temps de sommation à la taille de la structure utilisée dans le tableau. Il s'avère que l'obtention du champ n à partir d'une structure plus grande est plus longue, et donc l'opération de sommation prend plus de temps.
Beaucoup d'entre vous ont déjà compris pourquoi cela se produit.
Le processeur a des caches L1, L2 (parfois même L3 et L4). Le processeur accède à ce type de mémoire directement et rapidement.
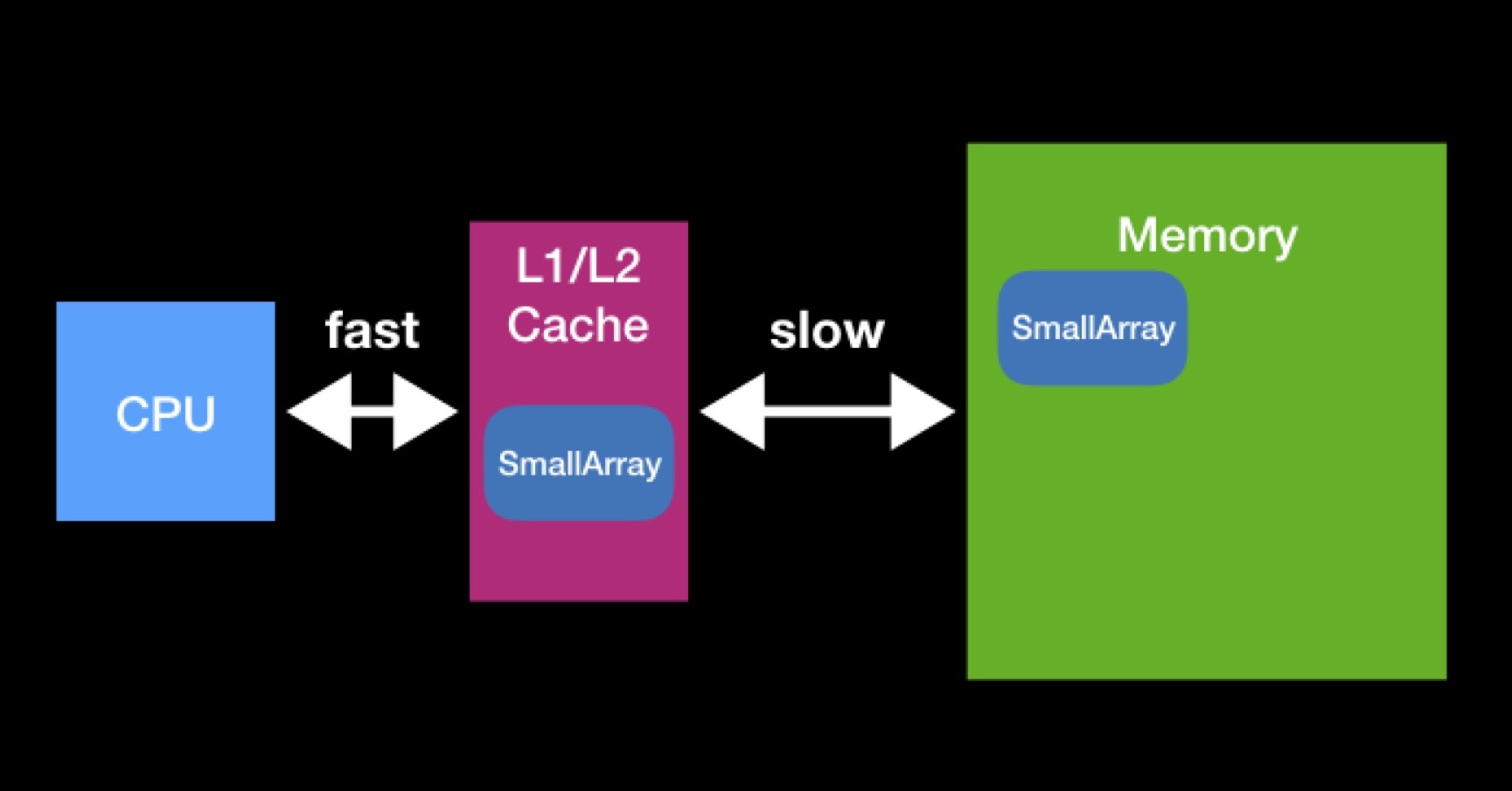
Des caches existent pour accélérer la réutilisation des données. Supposons que nous travaillons avec des tableaux. Si la baie requise par le processeur est déjà présente dans l'un des caches, elle était déjà requise par le processeur plus tôt. À ce moment, il les a demandés à la mémoire principale, les a placés dans le cache, a effectué toutes les opérations nécessaires avec eux, après quoi ces données sont restées mensongères (ils n'ont pas eu le temps d'effacer les autres).
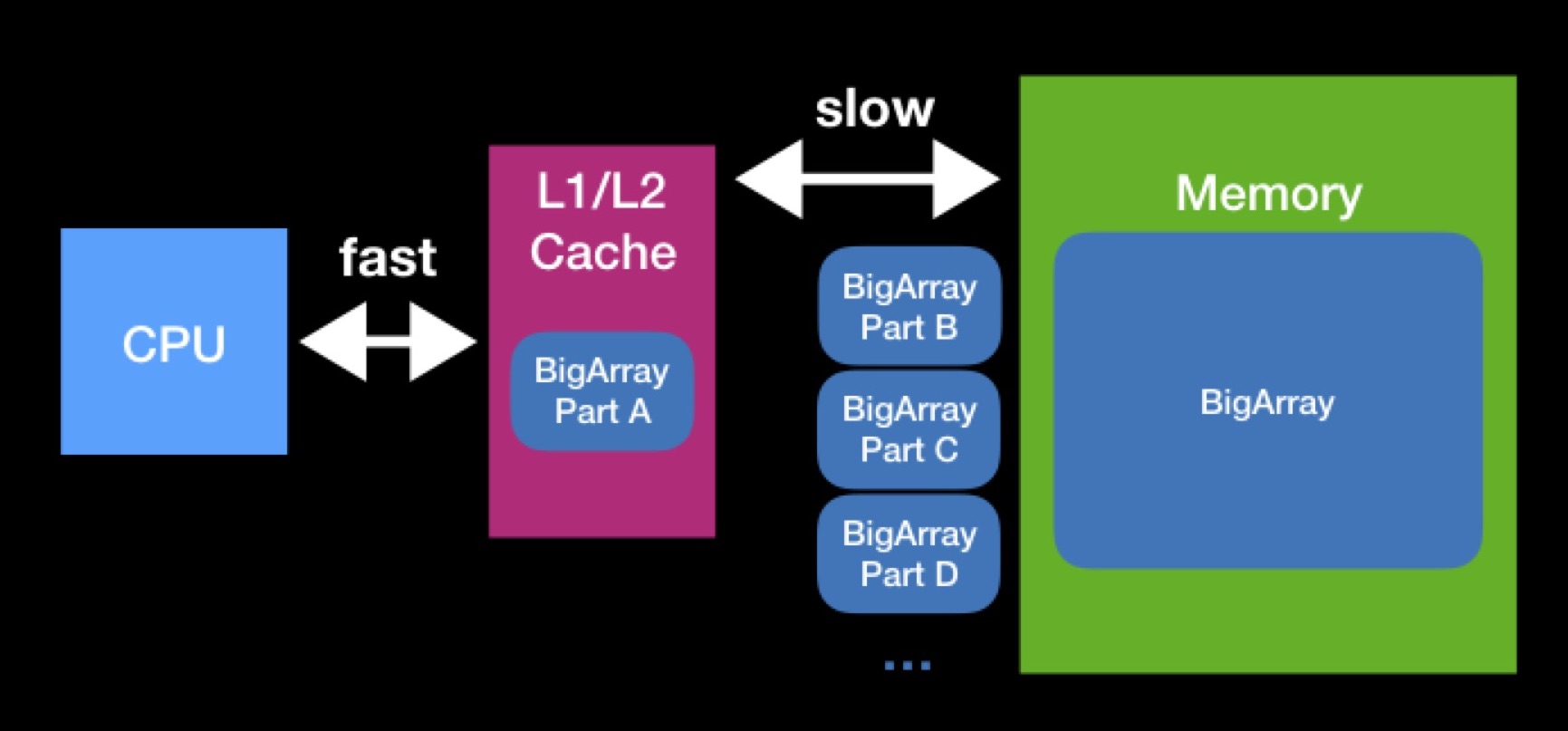
Les tailles des caches L1, L2 ne sont pas si grandes. La baie dont le processeur a besoin pour fonctionner peut être plus grande. Afin d'effectuer pleinement l'opération sur un tel tableau, nous devrons le décharger dans le cache en plusieurs parties et opérer sur ces parties une par une. En raison de demandes constantes à la mémoire principale, le traitement de notre baie prendra beaucoup plus de temps.
Lors de la programmation des structures de données, essayez de garder à l'esprit les caches. Il est possible qu'en réduisant la taille de votre structure de données, vous atteigniez sa capacité de cache réussie et accélérerez les opérations qui seront effectuées sur elle à l'avenir. L'interaction avec la mémoire principale a toujours été, est et restera probablement un facteur important de productivité - même lorsque vous écrivez sur Swift pour des appareils modernes hautes performances.
CPU vs RAM: initialisation paresseuse
Bien que dans certains cas, lorsque la mémoire utilisée est réduite, le programme commence à fonctionner plus rapidement, il existe des cas où ces deux mesures, au contraire, sont en conflit. Je vais donner un exemple avec le concept d'initialisation paresseuse.
Supposons que nous ayons une méthode makeHeavyObject () qui retourne un gros objet. Cette méthode initialise la variable lazilyCalculated.

Le modificateur paresseux définit la variable lazilyCalculated sur l'initialisation paresseuse. Cela signifie qu'une valeur ne lui sera affectée que lors du premier appel à celle-ci lors de l'exécution. C'est alors que la méthode makeHeavyObject () fonctionnera et que l'objet résultant sera assigné à la variable lazilyCalculated.
Quel est le plus ici? Dès le moment de l'initialisation (quoique plus tard, mais il sera exécuté), nous avons un objet situé en mémoire. Sa valeur est comptée, il est prêt à l'emploi - il suffit de faire une demande. Une autre chose est que notre objet est grand et dès l'instant de l'initialisation occupera en mémoire sa part du lion de cellules.
Vous pouvez aller dans l'autre sens - ne stockez pas du tout la valeur du champ:

Avec chaque lien vers le champ lazilyCalculated, la méthode makeHeavyObject () sera à nouveau exécutée. La valeur sera renvoyée au point de requête, alors qu'elle ne sera pas placée en mémoire. Comme vous pouvez le voir, le stockage d'une variable est facultatif.
Quoi de plus cher - pour stocker un grand objet en mémoire, mais pas pour perdre du temps CPU, ou pour appeler la méthode à chaque fois que nous avons besoin de notre champ, tout en économisant de la mémoire? Devriez-vous avoir une valeur prête à l'emploi ou la calculer à la volée? Ce genre de dilemme survient assez souvent, où que vous effectuiez vos calculs - sur un serveur distant ou sur votre machine locale, quel que soit le cache avec lequel vous devez travailler. Vous devez prendre une décision en fonction des limites du système dans ce cas particulier.
Cycle d'optimisation

Quoi que vous optimisiez, votre travail, en règle générale, sera construit sur le même algorithme. Tout d'abord, vous examinez le code, le profil / la mesure (dans Xcode en utilisant les outils appropriés), en essayant d'identifier ses goulots d'étranglement. Essentiellement, organisez les méthodes en fonction de leur durée d'exécution. Et puis regardez les premières lignes pour déterminer ce qu'il faut optimiser.
En choisissant un objet, vous vous fixez la tâche (ou, en parlant scientifiquement, vous émettez une hypothèse): en appliquant ces méthodes d'optimisation ou d'autres, vous pouvez accélérer le travail du morceau de code sélectionné.
Ensuite, vous essayez d'optimiser. Après chaque modification, vous examinez les indicateurs de performance, évaluant l'efficacité de la modification, combien vous avez réussi à avancer.
Tout comme dans un travail scientifique: spéculation, expérience, analyse des résultats. Vous passez ce cycle d'actions encore et encore. La pratique montre que le travail ainsi construit vous permet d'éliminer les botneks un par un.
Tests unitaires

En bref sur les tests unitaires: nous avons une fonction que nous testons, une entrée de données d'entrée et une sortie de données de sortie; en recevant une entrée en entrée, notre fonction doit toujours renvoyer une sortie, et aucune de nos optimisations ne doit violer cette propriété.
Les tests unitaires nous aident à suivre la panne. Si, en réponse à l'entrée, notre fonction a cessé de renvoyer la sortie, alors, directement ou indirectement, nous avons changé l'ancien mode de fonctionnement de notre fonction.
N'essayez même pas de commencer à optimiser si vous n'avez pas écrit une généreuse portion de tests unitaires dans votre code. Vous devriez pouvoir effectuer un test de régression. Si vous regardez GitHub my commits dans mon exemple d'application, que je vais poursuivre, vous pouvez voir que certaines de mes optimisations ont apporté des bogues avec elles.
Et maintenant, pour la partie amusante, passons aux étoiles.
Million d'étoiles
Il existe une grande (énorme) base de données décrivant un million d'étoiles. En plus, j'ai créé plusieurs applications. L’un d’eux utilise la réalité augmentée, en dessinant en temps réel des étoiles sur l’image de l’appareil photo du téléphone. Je vais maintenant le démontrer en action:
En l'absence de lumières de la ville, une personne peut distinguer jusqu'à 8 000 étoiles dans le ciel. J'aurais besoin d'environ 1,8 Mo pour stocker 8 000 enregistrements. En principe, acceptable. Mais je voulais ajouter ces étoiles qu'une personne peut voir à travers un télescope - il s'est avéré environ 120 000 étoiles (selon le soi-disant catalogue Hipparcos, désormais obsolète). Cela nécessitait déjà 27 Mo. Et parmi les catalogues modernes du domaine public, vous pouvez en trouver un qui comptera environ 2 500 000 étoiles. Une telle base de données occuperait déjà environ 560 Mo. Comme vous pouvez le voir, beaucoup de mémoire est déjà requise. Mais nous ne voulons pas seulement une base de données, mais une application basée sur elle, où il y aura ARKit, SceneKit et d'autres choses qui nécessitent également de la mémoire.
Que faire?
Nous optimiserons les étoiles.
Outil MemoryLayout
Vous pouvez évaluer la taille du programme dans son ensemble. Mais pour les travaux de bijouterie tels que l'optimisation, vous aurez besoin d'outils pour estimer la taille de chaque structure de données individuelle.
Swift vous permet de le faire très simplement - en utilisant des objets MemoryLayout <>. Vous déclarez un MemoryLayout <>, spécifiant la structure de données qui vous intéresse en tant que type générique. Maintenant, en vous référant aux propriétés de l'objet reçu, vous pouvez recevoir une variété d'informations utiles sur votre structure.

La propriété size nous donne le nombre d'octets occupés par une instance de la structure.
Maintenant sur la propriété stride. Vous avez peut-être remarqué que la taille du tableau, en règle générale, n'est pas égale à la somme des tailles de ses éléments constitutifs, mais la dépasse. De toute évidence, un peu «d'air» est laissé entre les éléments de la mémoire. Pour estimer la distance entre des éléments consécutifs dans un tableau adjacent, nous utilisons la propriété stride. Si vous le multipliez par le nombre d'éléments dans le tableau, vous obtenez sa taille.
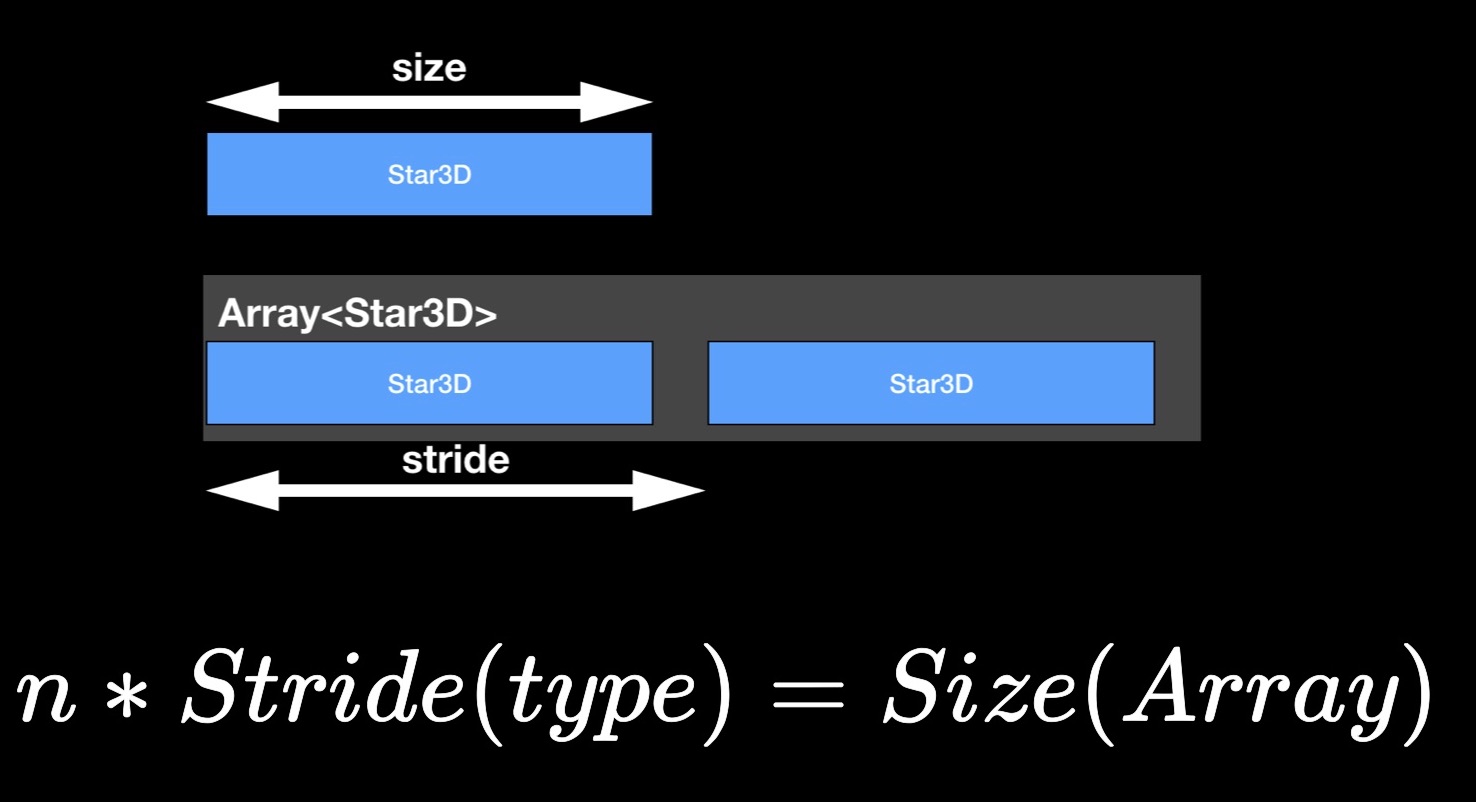
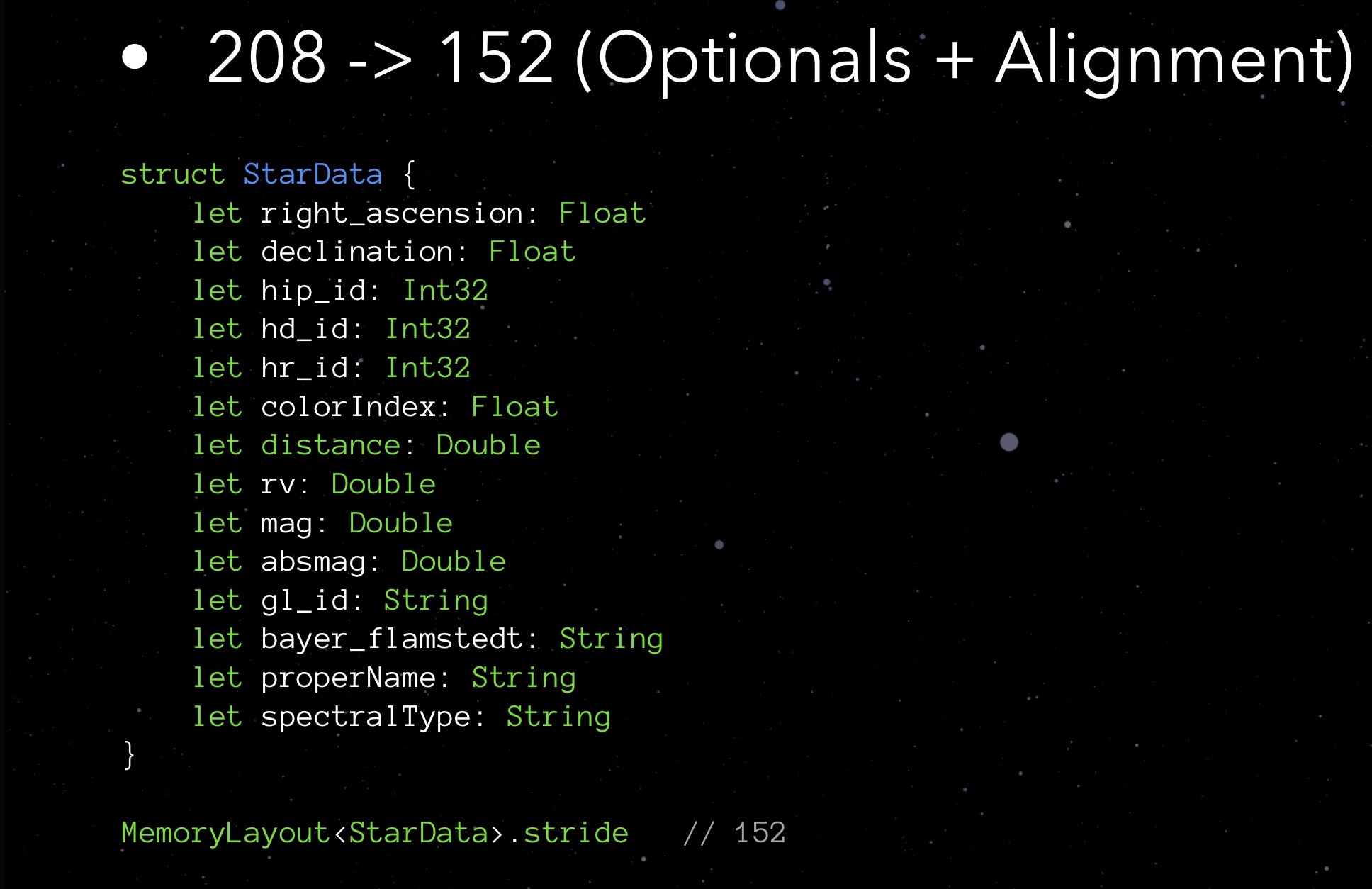
StarData, notre structure expérimentale, dans son état initial non optimisé:
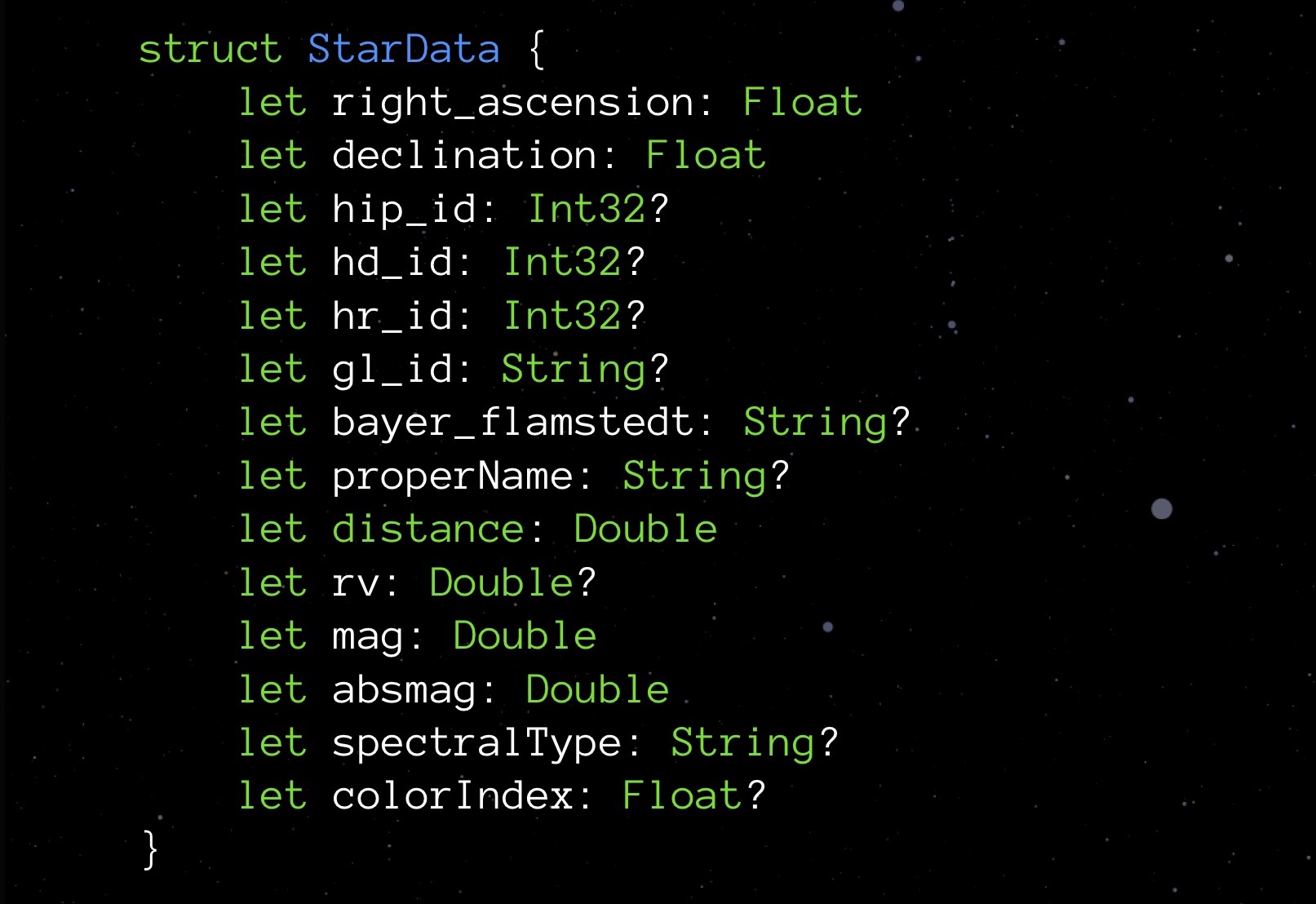
Voici une structure de données conçue pour stocker des données sur une étoile. Il n'est pas nécessaire de se pencher sur la signification de chacun de ces éléments. Il est plus important maintenant de faire attention aux types: variables flottantes stockant les coordonnées de l'étoile (en fait, latitude et longitude), plusieurs Int32 pour différents ID, chaîne pour stocker les noms et les noms de diverses classifications; il y a une distance, une couleur et quelques autres quantités nécessaires pour l'affichage correct d'une étoile.
Nous demandons la propriété stride:

À l'heure actuelle, notre structure pèse 208 octets. Un million de ces structures nécessiteront 250 Mo - c'est, comme vous le savez, c'est trop. Par conséquent, il est nécessaire d'optimiser.
Correct int
Le fait qu'il existe différentes variétés d'Int est expliqué dans les premières leçons de programmation. L'Int le plus familier pour nous dans Swift s'appelle Int8. Il occupe 8 bits (1 octet) et peut stocker des valeurs de -128 à 127 inclus. Il existe également d'autres Ints:
- Int16 d'une taille de 2 octets, la plage de valeurs va de -32 768 à 32 767;
- Int32 d'une taille de 4 octets, la plage de valeurs va de -2 147 483 648 à 2 147 483 647;
- Int64 (ou juste Int) a une taille de 8 octets, la plage de valeurs va de -9,223,372,036,854,775,808 à 9,223,372,036,854,775,807.
Probablement ceux d'entre vous qui étaient engagés dans le développement Web et qui s'occupaient de SQL y réfléchissent déjà. Mais oui, tout d'abord, choisissez l'Int optimal. Dans ce projet, avant même d'avoir pensé à l'optimisation, je me suis lancé dans une optimisation prématurée (ce qui, comme je viens de vous le dire, n'est pas nécessaire).
Regardons, par exemple, les champs avec ID. Nous savons que nous aurons environ un million d'étoiles - pas quelques dizaines de milliers, mais pas un milliard. Ainsi, pour de tels champs, il est préférable de choisir Int32. Ensuite, j'ai réalisé que 4 octets suffisent pour Float ici. Double occupera 8, chaîne de 24 chacun, ajoutez tout - il s'avère 152 octets. Si vous vous en souvenez, MemoryLayout nous a dit plus tôt que 208. Pourquoi? Nous devons creuser plus profondément.
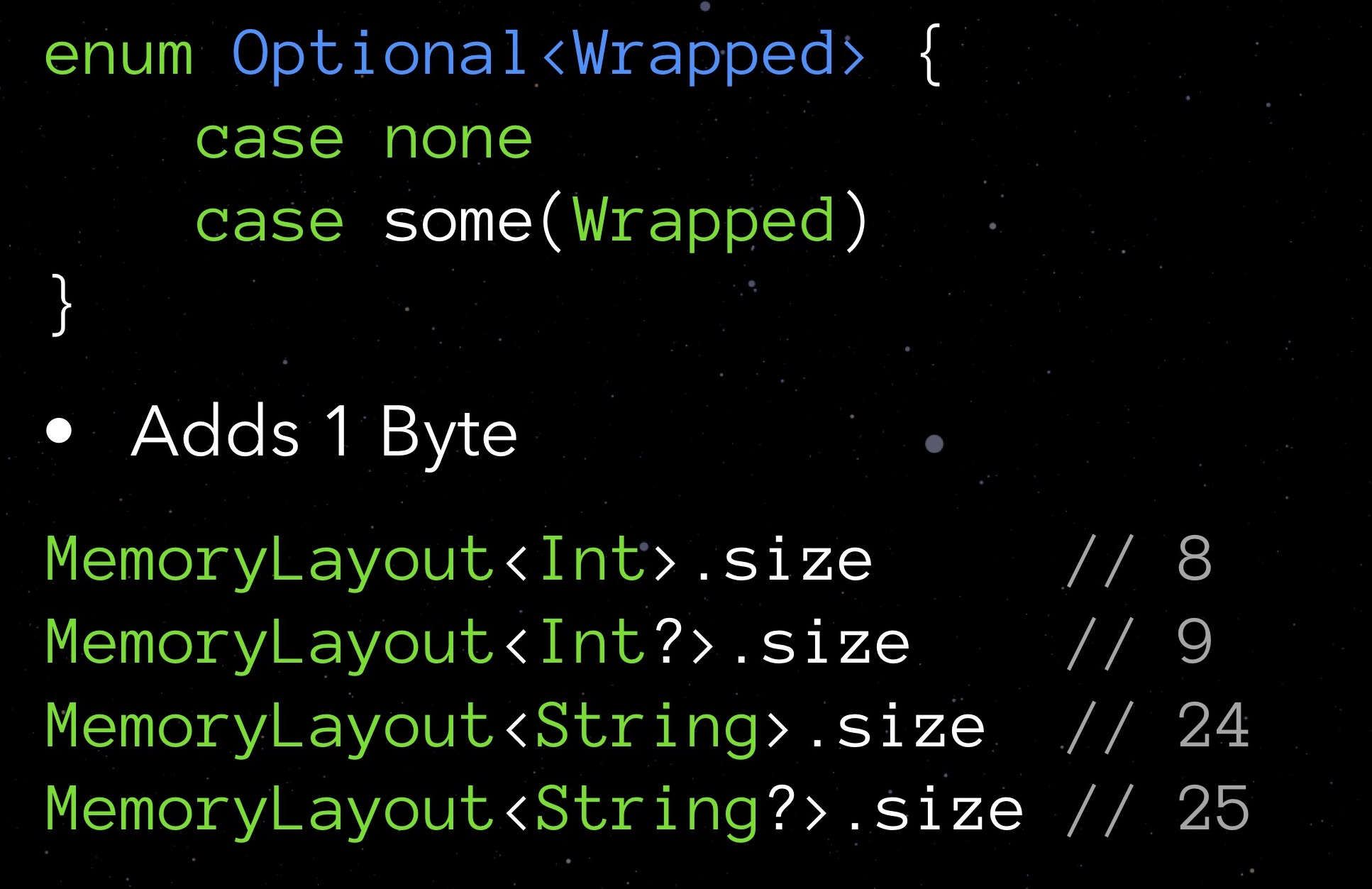
Tout d'abord, regardons Facultatif. Les types facultatifs diffèrent par le fait qu'en l'absence de valeur affectée, ils stockent zéro. Cela garantit la sécurité dans l'interaction avec les objets. Mais comme vous le savez, une telle mesure ne coûte pas cher: en demandant la propriété size de tout type facultatif, vous verrez qu'un tel type prend toujours un octet de plus. Nous payons pour la possibilité de vous inscrire au champ nul.
Nous ne voudrions pas dépenser un octet supplémentaire sur une variable. En même temps, nous aimons vraiment l'idée incarnée en option. Que proposer? Essayons de mettre en œuvre notre structure.
Choisissons une valeur qui peut raisonnablement être considérée comme «non valide» pour un champ donné, tout en convenant au type déclaré. Pour getHipId (Int32), il peut s'agir, par exemple, de la valeur "-1". Cela signifiera que notre champ n'est pas initialisé. Voici un tel vélo en option, qui se passe d'un octet supplémentaire sur zéro.
De toute évidence, avec une telle astuce, nous avons également une vulnérabilité potentielle. Pour nous protéger des erreurs, nous allons créer un getter pour le champ, qui gérera indépendamment notre nouvelle logique et vérifiera la validité du champ.

Un tel getter nous fait complètement abstraction de la complexité d'une solution inventée.
Tournez-vous vers nos StarData. Remplacez tous les types facultatifs par des types réguliers et voyez ce que la foulée montre:
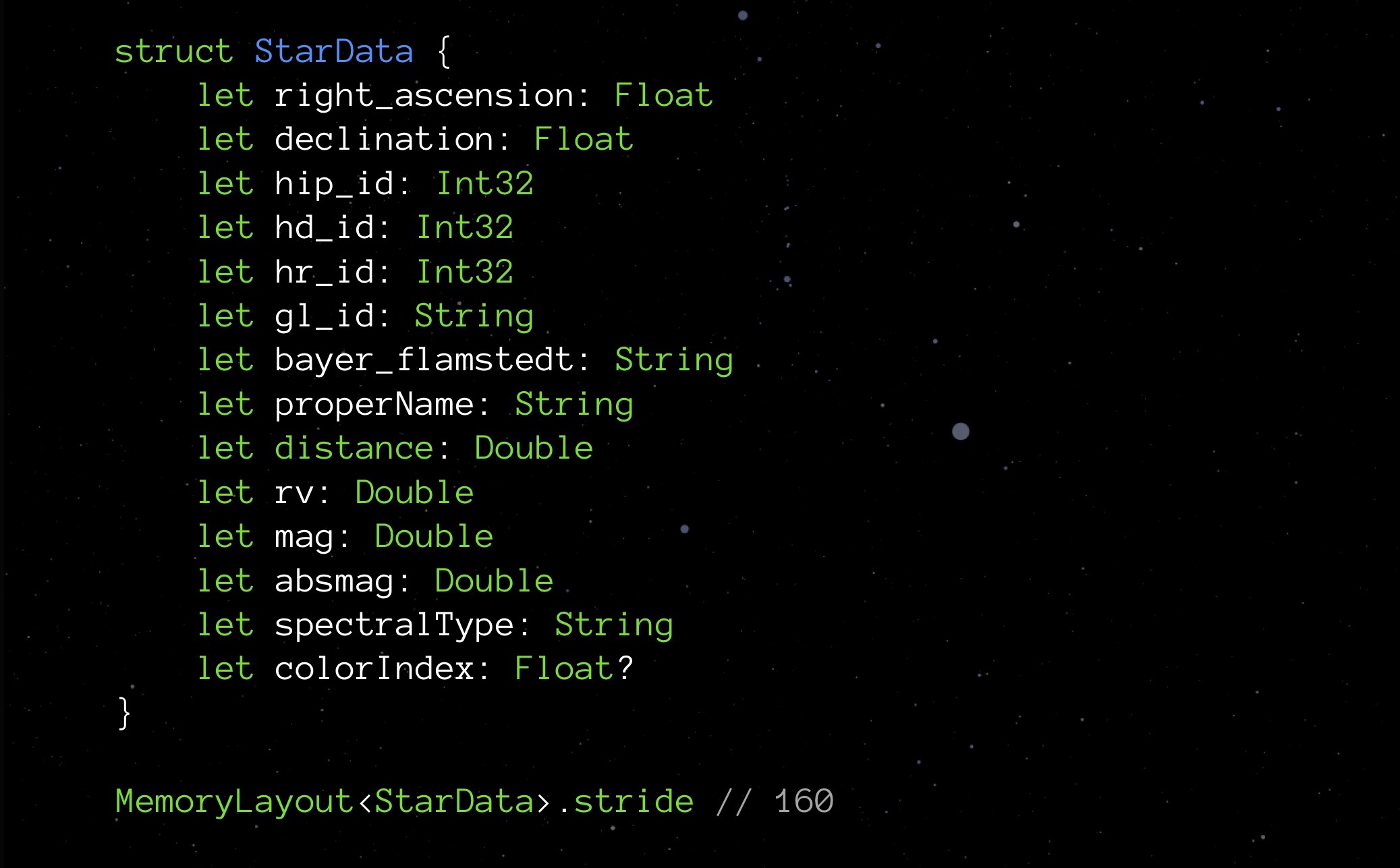
Il s'avère qu'en éliminant les options, nous avons économisé non pas 9 octets (un octet pour chacune des neuf options), mais jusqu'à 48. La surprise est agréable, mais j'aimerais savoir pourquoi cela s'est produit. Et c'est arrivé à cause de l'alignement des données en mémoire.
Alignement des données
Rappelons qu'avant Swift, nous écrivions dans Objective-C, et c'était basé sur C - et cette situation remonte également à C.
En plaçant des structures en mémoire, les processeurs modernes placent leurs éléments non pas dans un flux continu (pas «épaule contre épaule»), mais dans une grille amincie de façon inhomogène par des vides. C'est l'alignement des données. Il vous permet de simplifier et d'accélérer l'accès aux éléments de données nécessaires en mémoire.
Les règles d'alignement des données s'appliquent à chaque variable selon son type:
- une variable de type char peut commencer à partir des 1er, 2e, 3e, 4e, etc. octets, car il ne prend qu'un seul octet en soi;
- une variable courte prend 2 octets, elle peut donc commencer à partir du 2ème, 4ème, 6ème, 8ème, etc. un octet (c'est-à-dire de chaque octet pair);
- une variable de type float prend 4 octets, ce qui signifie qu'elle peut commencer tous les 4, 8, 12, 16, etc. un octet (c'est-à-dire tous les quatre octets);
- les variables de type Double et String occupent chacune 8 octets, elles peuvent donc commencer par les 8e, 16e, 24e, 32e, etc. octets
- etc.
Les objets MemoryLayout <> ont une propriété d'alignement qui renvoie la règle d'alignement correspondante pour le type spécifié.
Pourrions-nous appliquer la connaissance des règles d'alignement pour optimiser le code? Regardons un exemple. Il existe une structure utilisateur: pour firstName et lastName, nous utilisons une chaîne régulière, pour middleName - une chaîne facultative (l'utilisateur peut ne pas avoir un tel nom). En mémoire, une instance d'une telle structure sera placée comme suit:

Comme vous pouvez le voir, puisque le middleName facultatif prend 25 octets (au lieu de multiples de 8 24 octets), les règles d'alignement vous obligent à ignorer les 7 octets suivants et à dépenser 80 octets sur toute la structure. Ici, peu importe comment vous échangez des blocs avec des chaînes, il est impossible de compter sur un plus petit nombre d'octets.
Et maintenant un exemple d'alignement échoué:

BadAligned isHidden Bool (1 ), size Double (8 ), isInteractable bool (1 ) age Int ( 8 ). , , 32 .
— , .
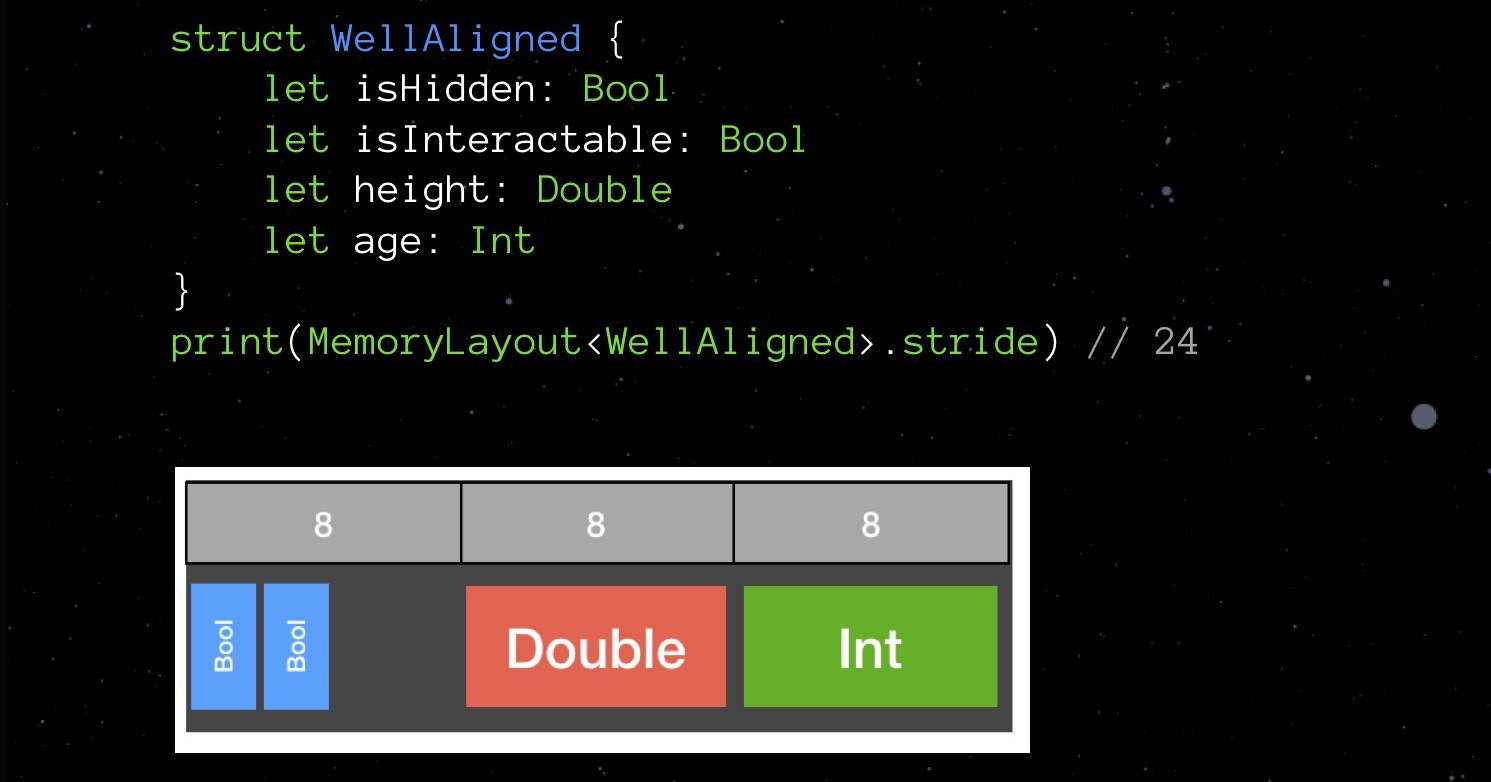
32 , 24. 25%.
, ? Swift C — . , , , . — - .
StarData. .
Float Int32, Double String. !
stride 152 . , , 208 152 .
? , . -, — - , .
, . : FPS, — .
StarData. « » — String, . : ! 146 «» , properName. gl_id — ID , 3801 , . bayer_flamstedt — — 3064- . spectralType — 4307-. , , 24 .
. . — Int16, , - — , -1.
StarData properName, gl_id, bayer_flamstedt spectralType , . -, . — :

— . private, .
, . . ; — , «-1».
. — .
, , . . unit- — , .
: stride 64 !
? , : Int16 .

. , StarData 208 56 . 500 , 130. !
. User - 20 , , . , . , « , »! . , — , , .
Swift
( ) . , , .
- . , .
Xcode. :

, xCode culprits.txt. .

, . 2 , . ?
, , . , Swift . ( , ) , , , . , 5 2 (!) .
«»: . . : .
. Swift.
,
GitHub . API-, . , ARkit. : 500 , Bluemix. , .
, , :
- . . , , , ?
- , unit-. , unit-. , . Unit- , .
- . , . , : — .
- . . , — , «» .
- RAM vs. CPU. . , .
Mobius — , 8-9 Mobius 2018 Moscow , . 1 , !