L'apprentissage renforcé (RL) est l'une des techniques d'apprentissage automatique les plus prometteuses qui est activement développée. Ici, l'agent IA reçoit une récompense positive pour les bonnes actions et une récompense négative pour les mauvaises. Cette méthode de
carotte et de bâton est simple et universelle. Avec cela, DeepMind a enseigné l'algorithme
DQN pour jouer à d'anciens jeux vidéo Atari et
AlphaGoZero pour jouer à l'ancien jeu Go. OpenAI a donc appris à l'algorithme
OpenAI-Five à jouer au jeu vidéo Dota moderne, et Google a appris aux mains robotiques à
capturer de nouveaux objets . Malgré le succès de RL, il existe encore de nombreux problèmes qui réduisent l'efficacité de cette technique.
Les algorithmes RL ont du
mal à travailler dans un environnement où l'agent reçoit rarement des commentaires. Mais c'est typique du monde réel. Par exemple, imaginez chercher votre fromage préféré dans un grand labyrinthe, comme un supermarché. Vous cherchez et cherchez un département avec des fromages, mais vous ne pouvez pas le trouver. Si à chaque pas vous n’obtenez ni «bâton» ni «carotte», alors il est impossible de dire si vous allez dans la bonne direction. En l'absence de récompense, qu'est-ce qui vous empêche de vous promener pour toujours? Rien que peut-être votre curiosité. Cela motive le passage au service d'épicerie, qui ne semble pas familier.
L'ouvrage scientifique,
«Curiosité épisodique grâce à l'accessibilité», est le résultat d'une collaboration entre
l'équipe de Google Brain ,
DeepMind, et
la Swiss Higher Technical School de Zurich . Nous proposons un nouveau modèle de récompense RL basé sur la mémoire épisodique. Elle ressemble à une curiosité qui vous permet d'explorer l'environnement. Étant donné que l'agent doit non seulement étudier l'environnement, mais également résoudre le problème initial, notre modèle ajoute un bonus à la récompense initialement clairsemée. La récompense combinée n'est plus rare, ce qui permet aux algorithmes RL standard d'en tirer des leçons. Ainsi, notre méthode de curiosité élargit la gamme des tâches qui peuvent être résolues en utilisant RL.
 Curiosité occasionnelle par l'accessibilité: des données d'observation sont ajoutées à la mémoire, la récompense est calculée en fonction de la distance entre l'observation actuelle et des observations similaires en mémoire. L'agent reçoit une plus grande récompense pour les observations qui ne sont pas encore présentées en mémoire.
Curiosité occasionnelle par l'accessibilité: des données d'observation sont ajoutées à la mémoire, la récompense est calculée en fonction de la distance entre l'observation actuelle et des observations similaires en mémoire. L'agent reçoit une plus grande récompense pour les observations qui ne sont pas encore présentées en mémoire.L'idée principale de la méthode est de stocker les observations de l'agent sur l'environnement dans la mémoire épisodique, ainsi que de récompenser l'agent pour la visualisation des observations non encore présentées en mémoire. «Manque de mémoire» est la définition de la nouveauté dans notre méthode. La recherche de telles observations signifie la recherche d'un étranger. Une telle envie de rechercher un étranger mènera l'agent IA vers de nouveaux endroits, empêchant ainsi l'errance dans un cercle, et l'aidera finalement à tomber sur la cible. Comme nous le verrons plus tard, notre libellé peut dissuader l'agent du comportement indésirable auquel sont soumis certains autres libellés. À notre grande surprise, ce comportement présente certaines similitudes avec ce qu'un profane appellerait «procrastination».
Curiosité antérieure
Bien qu'il y ait eu de nombreuses tentatives pour formuler la curiosité dans le passé
[1] [2] [3] [4] , dans cet article, nous nous concentrerons sur une approche naturelle et très populaire: la curiosité par la surprise basée sur les prévisions. Cette technique est décrite dans un article récent,
«Enquêter sur un environnement utilisant la curiosité en prédisant sous son propre contrôle» (généralement appelé ICM). Pour illustrer le lien entre surprise et curiosité, nous utilisons à nouveau l'analogie de trouver du fromage dans un supermarché.
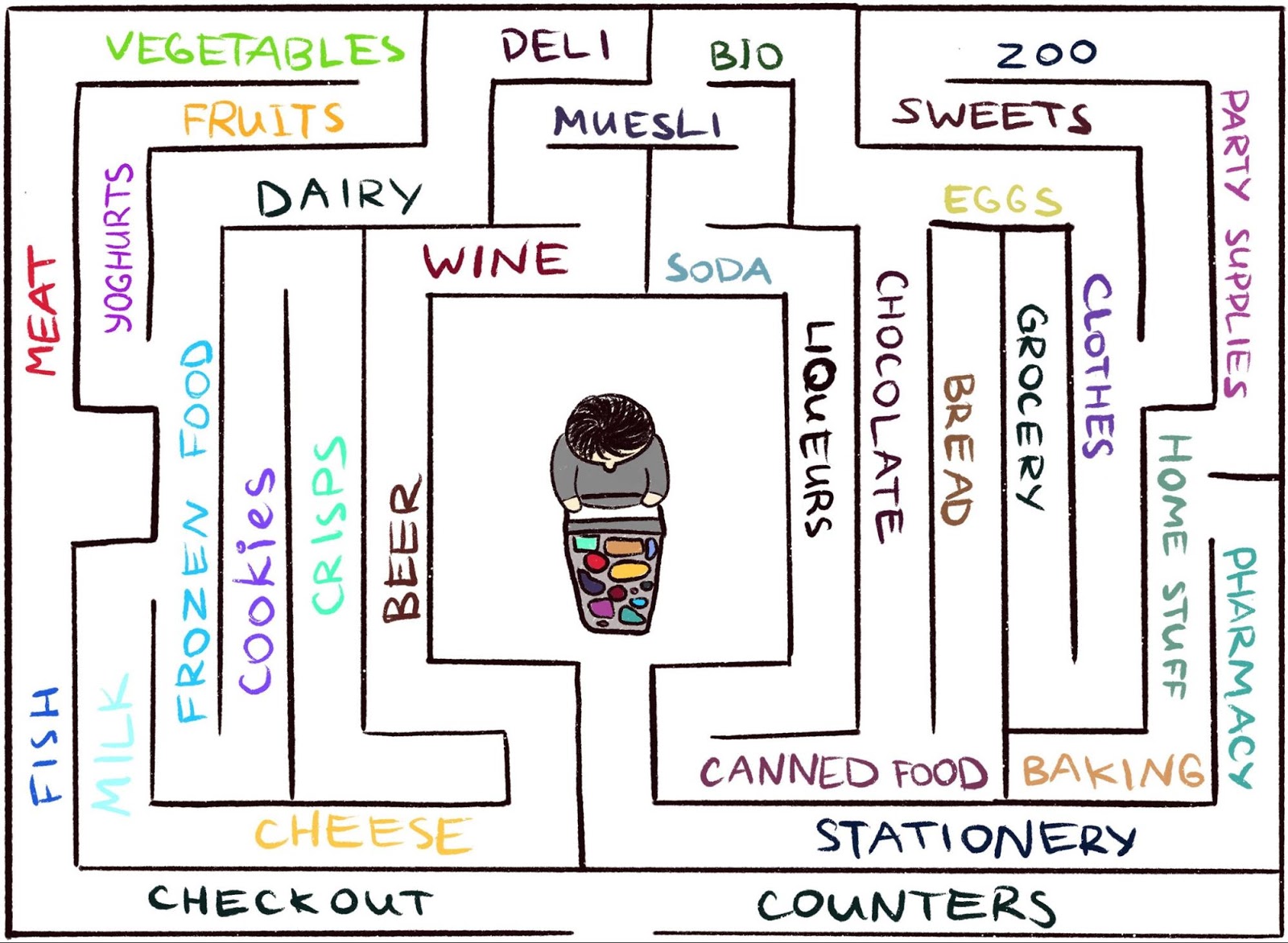 Illustration d' Indira Pasko , sous licence CC BY-NC-ND 4.0
Illustration d' Indira Pasko , sous licence CC BY-NC-ND 4.0En vous promenant dans le magasin, vous essayez de prédire l'avenir (
"Maintenant, je suis dans le rayon viande, donc je pense que le rayon du coin est le rayon poisson, ils sont généralement à proximité dans cette chaîne de supermarchés" ). Si la prévision est incorrecte, vous êtes surpris (
"En fait, il y a un département de légumes. Je ne m'y attendais pas!" ) - et de cette façon, vous obtenez une récompense. Cela augmente la motivation à l'avenir pour regarder à nouveau au coin de la rue, en explorant de nouveaux endroits uniquement pour vérifier que vos attentes sont vraies (et éventuellement tomber sur du fromage).
De même, la méthode ICM construit un modèle prédictif de la dynamique du monde et donne à l'agent une récompense si le modèle ne parvient pas à faire de bonnes prédictions - un marqueur de surprise ou de nouveauté. Veuillez noter que l'exploration de nouveaux endroits n'est pas directement articulée dans la curiosité de l'ICM. Pour la méthode ICM, y assister n'est qu'un moyen d'obtenir plus de «surprises» et ainsi maximiser votre récompense globale. Il s'avère que dans certains environnements, il peut y avoir d'autres façons de se surprendre, ce qui conduit à des résultats inattendus.
Un agent avec un système de curiosité basé sur la surprise se fige lorsqu'il rencontre un téléviseur. Animation de la vidéo de Deepak Patak , sous licence CC BY 2.0Le danger de la procrastination
Dans l'article
«A Large-Scale Study of Curiosity-Based Learning», les auteurs de la méthode ICM, avec les chercheurs d'OpenAI, montrent un danger caché de maximiser la surprise: les agents peuvent apprendre à se laisser aller à la procrastination au lieu de faire quelque chose d'utile pour la tâche. Pour comprendre pourquoi cela se produit, envisagez une expérience de pensée que les auteurs appellent le «problème du bruit de la télévision». Ici, l'agent est placé dans un labyrinthe avec la tâche de trouver un article très utile (comme «fromage» dans notre exemple). L'environnement a une télévision et l'agent a une télécommande. Le nombre de chaînes est limité (chaque chaîne a une transmission distincte) et chaque pression sur la télécommande fait passer le téléviseur sur une chaîne aléatoire. Comment un agent agira-t-il dans un tel environnement?
Si la curiosité se forme sur la base de la surprise, un changement de chaîne donnera plus de récompenses, car chaque changement est imprévisible et inattendu. Il est important de noter que même après un balayage cyclique de toutes les chaînes disponibles, une sélection aléatoire d'une chaîne garantit que chaque nouveau changement sera toujours inattendu - l'agent fait une prédiction qu'il affichera la télévision après avoir changé de chaîne, et très probablement les prévisions se révéleront incorrectes, ce qui surprendra. Il est important de noter que même si l'agent a déjà vu chaque transmission sur chaque canal, le changement est toujours imprévisible. Pour cette raison, l'agent, au lieu de chercher un article très utile, restera finalement devant le téléviseur - semblable à la procrastination. Comment changer la formulation de la curiosité pour éviter ce comportement?
Curiosité épisodique
Dans l'article
«Curiosité épisodique grâce à l'accessibilité», nous examinons un modèle de curiosité basé sur la mémoire épisodique qui est moins sujet au plaisir instantané. Pourquoi Si nous prenons l'exemple ci-dessus, après un certain temps de commutation de canaux, toutes les transmissions finiront par finir en mémoire. Ainsi, le téléviseur perdra de son attrait: même si l'ordre dans lequel les programmes apparaissent à l'écran est aléatoire et imprévisible, ils sont tous en mémoire! C'est la principale différence avec la méthode basée sur la surprise: notre méthode n'essaie même pas de prédire l'avenir, elle est difficile à prévoir (voire impossible). Au lieu de cela, l'agent examine le passé et vérifie s'il y a des observations dans la mémoire
comme celle en cours. Ainsi, notre agent n'est pas sujet aux plaisirs instantanés, ce qui donne un "bruit de télévision". L'agent devra aller explorer le monde en dehors du téléviseur pour obtenir plus de récompenses.
Mais comment décider si un agent voit la même chose qui est stockée en mémoire? La vérification exacte des correspondances est inutile: dans un environnement réel, un agent voit rarement la même chose deux fois. Par exemple, même si l'agent retourne dans la même pièce, il verra toujours cette pièce sous un angle différent.
Au lieu de vérifier les correspondances exactes, nous utilisons un
réseau neuronal profond qui est formé pour mesurer la similitude de deux expériences. Pour former ce réseau, il faut deviner à quel point les observations se sont produites dans le temps. La proximité dans le temps est un bon indicateur pour savoir si deux observations doivent être considérées comme faisant partie de la même. Un tel apprentissage conduit à un concept général de nouveauté par l'accessibilité, qui est illustré ci-dessous.
 Le graphique d'accessibilité définit la nouveauté. En pratique, ce graphique n'est pas disponible - par conséquent, nous formons l'approximateur de réseau neuronal pour estimer le nombre d'étapes entre les observations
Le graphique d'accessibilité définit la nouveauté. En pratique, ce graphique n'est pas disponible - par conséquent, nous formons l'approximateur de réseau neuronal pour estimer le nombre d'étapes entre les observationsRésultats expérimentaux
Pour comparer les performances de différentes approches pour décrire la curiosité, nous les avons testées dans deux environnements 3D visuellement riches:
ViZDoom et
DMLab . Dans ces conditions, l'agent s'est vu confier diverses tâches, telles que trouver une cible dans le labyrinthe, collecter les bons objets et éviter les mauvais. Dans l'environnement DMLab, l'agent est équipé par défaut d'un gadget fantastique comme un laser, mais si le gadget n'est pas nécessaire pour une tâche spécifique, l'agent ne peut pas l'utiliser librement. Fait intéressant, basé sur la surprise, l'agent ICM a utilisé le laser très souvent, même s'il était inutile de terminer la tâche! Comme dans le cas de la télévision, au lieu de chercher un objet de valeur dans le labyrinthe, il a préféré passer du temps à tirer sur les murs, car cela donnait beaucoup de récompenses sous forme de surprise. Théoriquement, le résultat d'une photo murale devrait être prévisible, mais en pratique, il est trop difficile à prévoir. Cela nécessite probablement une connaissance plus approfondie de la physique que celle dont dispose l'agent IA standard.

Contrairement à lui, notre agent maîtrise un comportement raisonnable pour étudier l'environnement. Cela s'est produit parce qu'il n'essaie pas de prédire le résultat de ses actions, mais cherche plutôt des observations qui sont «plus éloignées» de celles qui sont dans la mémoire épisodique. En d'autres termes, l'agent poursuit implicitement des objectifs qui nécessitent plus d'efforts qu'un simple coup de feu contre le mur.
Notre méthode démontre un comportement d'exploration environnementale intelligent.Il est intéressant d'observer comment notre approche de la récompense punit un agent s'exécutant dans un cercle, car après l'achèvement du premier cercle, l'agent ne rencontre pas de nouvelles observations et, par conséquent, ne reçoit aucune récompense:
Visualisation des récompenses: le rouge correspond à la récompense négative, le vert au positif. De gauche à droite: carte de récompense, carte avec emplacements en mémoire, vue à la première personneDans le même temps, notre méthode contribue à une bonne étude de l'environnement:
Visualisation des récompenses: le rouge correspond à la récompense négative, le vert au positif. De gauche à droite: carte de récompense, carte avec emplacements en mémoire, vue à la première personneNous espérons que nos travaux contribueront à une nouvelle vague de recherche qui dépasse le cadre de la technique de la surprise afin d'éduquer les agents sur des comportements plus intelligents. Pour une analyse approfondie de notre méthode, veuillez consulter la
préimpression du travail scientifique .
Remerciements:
Ce projet est le résultat d'une collaboration entre l'équipe de Google Brain, DeepMind, et la Swiss Higher Technical School de Zurich. Groupe de recherche principal: Nikolay Savinov, Anton Raichuk, Rafael Marinier, Damien Vincent, Mark Pollefeys, Timothy Lillirap et Sylvain Zheli. Nous remercions Olivier Pietkin, Carlos Riquelme, Charles Blundell et Sergey Levine d'avoir discuté de ce document. Nous remercions Indira Pasco pour son aide avec les illustrations.
Références à la littérature:
[1]
«L'étude de l'environnement basée sur le comptage avec des modèles de densité neuronale» , Georg Ostrovsky, Mark G. Bellemar, Aaron Van den Oord, Remy Munoz
[2]
«Environnements d'apprentissage basés sur le comptage
pour l'apprentissage en profondeur avec renforcement» , Khaoran Tan, Rain Huthuft, Davis Foot, Adam Knock, Xi Chen, Yan Duan, John Schulman, Philip de Turk, Peter Abbel
[3]
«Apprendre sans professeur pour localiser les objectifs d'une recherche à motivation interne», Alexander Pere, Sébastien Forestier, Olivier Sigot, Pierre-Yves Udaye
[4]
«VIME: l'intelligence pour maximiser les changements d'information», Rein Huthuft, Xi Chen, Yan Duan, John Schulman, Philippe de Turk, Peter Abbel