
Il n'y a probablement pas beaucoup d'utilisateurs sur Habr qui n'ont jamais entendu parler des
« archives Internet», un service qui recherche et stocke des données numériques importantes pour toute l'humanité, que ce soit des pages Web, des livres, des vidéos ou d'autres types d'informations. .
Qui gère l'archive en ligne lorsqu'elle est apparue et quelle est sa mission? Lisez à ce sujet dans l'aide d'aujourd'hui.
Pourquoi avons-nous besoin d'une «archive»?
C'est loin d'être un simple divertissement. La mission de l'organisation est l'accès universel à toutes les informations. Les archives Internet cherchent à lutter contre le monopole de la fourniture d'informations provenant à la fois des entreprises de télécommunications (Google, Facebook, etc.) et des États.
De plus, les «Archives» sont une organisation respectueuse des lois. Si la loi américaine exige la suppression d'informations, l'organisation le fait.
Les archives Internet sont également un outil pour les scientifiques, les agences de renseignement, les historiens (tels que les archéologues) et les représentants de nombreux autres domaines, sans parler des utilisateurs individuels.
Quand les «archives Internet» sont-elles apparues?
Le créateur des archives est American Brewster Cale, qui a créé Alexa Internet. Ses deux services sont devenus extrêmement populaires, ils fleurissent tous les deux maintenant.
Les archives Internet ont commencé à archiver des informations à partir de sites et à stocker des copies de pages Web depuis 1996. Le siège social de cette organisation à but non lucratif est situé à San Francisco, aux États-Unis.
Certes, pendant cinq ans, les données n'étaient pas accessibles au public - les données étaient stockées sur les serveurs d'archives, et c'est tout, seule l'administration du service pouvait voir les anciennes copies des sites. Depuis 2001, l'administration du service a décidé de donner accès aux données stockées à tous.
Au tout début, les «archives Internet» n'étaient qu'une archive Web, mais l'organisation a alors commencé à enregistrer des livres, des fichiers audio, des images animées et des logiciels. Désormais, "Internet Archive" sert de référentiel pour les photos et autres images de la NASA, les textes de l'Open Library, etc.
À quoi sert une organisation?
Des «archives» existent sur les dons volontaires - à la fois des organisations et des individus. Vous pouvez fournir une assistance dans les portefeuilles bitcoins, 1Archive1n2C579dMsAu3iC6tWzuQJz8dN. Ce portefeuille a d'ailleurs reçu 357,47245492 BTC pour toute son existence, ce qui représente environ 2,25 millions de dollars au taux de change actuel.
Comment fonctionne l'archive?
La plupart des employés sont employés dans des centres de numérisation de livres, effectuant un travail de routine mais laborieux. L'organisation possède trois centres de données situés en Californie, aux États-Unis. L'un est à San Francisco, le second à Redwood City, le troisième à Richmond. Afin d'éviter le risque de perte de données en cas de catastrophe naturelle ou d'autres catastrophes, l'Archive dispose de capacités inutilisées en Égypte et à Amsterdam.
«Des millions de personnes ont consacré beaucoup de temps et d'efforts à partager avec d'autres ce que nous savons sous la forme d'Internet. Nous voulons créer une bibliothèque pour cette nouvelle plateforme de publication », a déclaré Brewster Kahle, fondateur d'Internet Archive
Quelle est la taille des archives maintenant?
Les "archives Internet" ont plusieurs divisions, et celle qui recueille les informations des sites a son propre nom - Wayback Machine. Au moment de la rédaction de l '«enquête», les archives contenaient 339 milliards de pages Web enregistrées. En 2017, les «archives» ont
stocké 30 pétaoctets d'informations, soit environ 300 milliards de pages Web, 12 millions de livres, 4 millions d'enregistrements audio, 3,3 millions de vidéos, 1,5 million de photos et 170 000 distributions logicielles différentes. En un an à peine, le service a "pris du poids", désormais les "Archives" stockent 339 milliards de pages Web, 19 millions de livres, 4,5 millions de fichiers vidéo, 4,7 millions de fichiers audio, 3,2 millions d'images de toutes sortes, 381 mille distributions Logiciel.
Comment le stockage des données est-il organisé?
Les informations sont stockées sur des disques durs dans les «nœuds de données». Ce sont des serveurs, chacun contenant 36 disques durs (plus deux disques avec les systèmes d'exploitation). Les nœuds de données sont regroupés en tableaux de 10 machines et constituent un référentiel de cluster. En 2016, les «Archives» utilisaient des disques durs de 8 téraoctets, maintenant la situation est à peu près la même. Il s'avère qu'un nœud contient environ 288 téraoctets de données. En général, des disques durs d'autres tailles sont également utilisés: 2, 3 et 4 To.
En 2016, il y avait environ 20 000 disques durs. Les centres de données d'archives sont équipés de systèmes climatiques pour maintenir un microclimat aux caractéristiques constantes. Un stockage en cluster de 10 nœuds consomme environ 5 kW d'énergie.
La structure des archives Internet est une «bibliothèque» virtuelle, divisée en sections telles que livres, films, musique, etc. Pour chaque élément, une description est entrée dans le catalogue - il s'agit généralement du nom, du nom de l'auteur et des informations supplémentaires. D'un point de vue technique, les éléments sont structurés et résident dans des répertoires Linux.
La quantité totale de données stockées par les «archives» est de 22 PB, alors qu'il reste encore de la place pour 22 PB. «Parce que nous sommes paranoïaques», disent les représentants des services.

Regardez la capture d'écran du contenu du répertoire - il y a un fichier avec un nom se terminant par "_files.xml". Il s'agit d'un répertoire contenant des informations sur tous les fichiers du répertoire.
Qu'adviendra-t-il des données si un ou plusieurs serveurs tombent en panne?
Il ne se passera rien de terrible - les
données sont dupliquées . Dès qu'un nouvel élément apparaît dans la bibliothèque d'archives, il est immédiatement répliqué et placé sur différents disques durs sur différents serveurs. Le processus de "mise en miroir" du contenu permet de faire face à des problèmes tels que les pannes de courant et les plantages du système de fichiers.
Si le disque dur tombe en panne, il est remplacé par un nouveau. Grâce à la structure de données en miroir et redupliquée, le novice est immédiatement rempli de données qui étaient sur l'ancien disque dur en panne.
Le "Archive" dispose d'un système spécialisé qui surveille l'état du disque dur. Le jour où vous devez remplacer 6-7 disques défectueux.
Qu'est-ce qu'une machine Wayback?
Ce n'est là qu'un des services des "archives Internet", spécialisées dans la conservation des pages Web. Le service dispose de sa propre "araignée", qui examine régulièrement tous les sites disponibles sur le réseau et les stocke sur des serveurs spécialisés. Plus le site Web est populaire, plus le robot copie souvent son contenu. Si l'administrateur des ressources ne souhaite pas que les informations du site soient copiées par le bot, il suffit d'écrire une interdiction dans le fichier robots.txt.
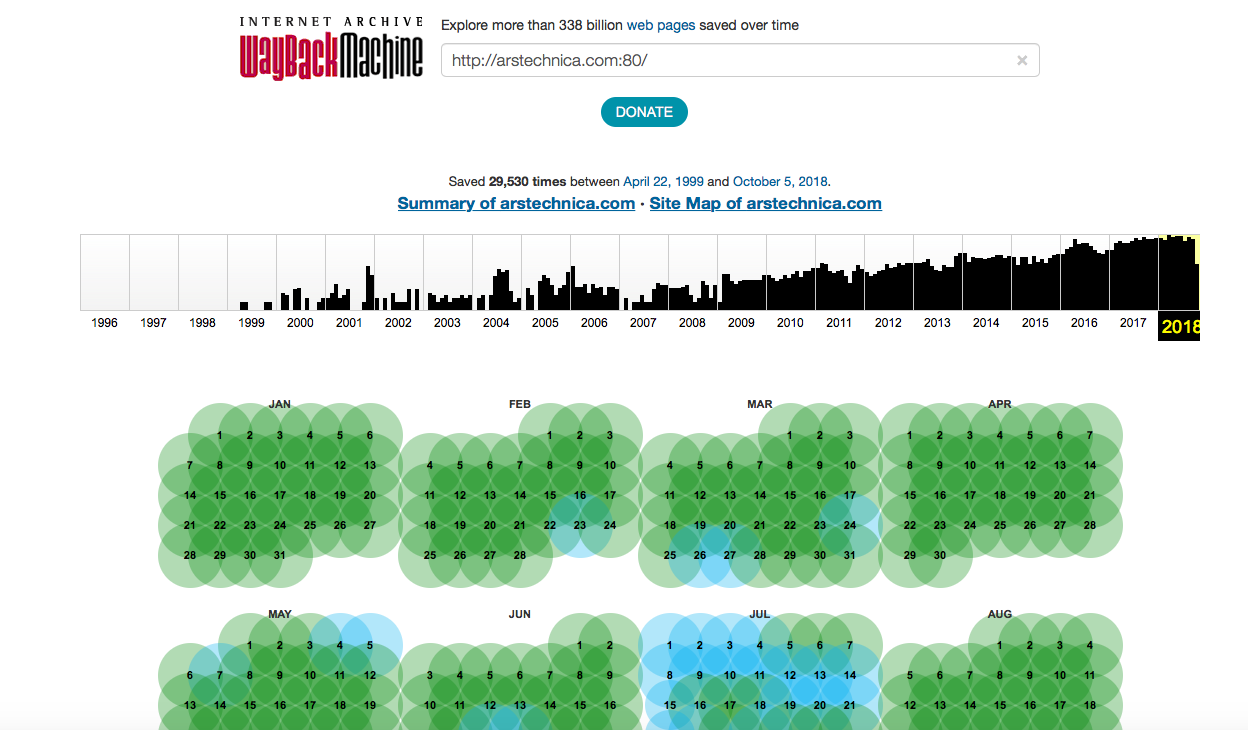 Les ressources populaires sont copiées souvent - presque quotidiennement. Wayback Machine indexe même les réseaux sociaux, dont Twitter, Facebook
Les ressources populaires sont copiées souvent - presque quotidiennement. Wayback Machine indexe même les réseaux sociaux, dont Twitter, Facebook
En 2017, Archive a
lancé le service Wayback Machine mis à jour , promettant un accès plus pratique aux pages Web enregistrées. Le service a été écrit sinon à partir de zéro, puis cool repensé. Désormais, il prend en charge un certain nombre de formats de fichiers qui, auparavant, n'étaient tout simplement pas enregistrés. Au cours de la même année, l'organisation a annoncé qu'environ 1 milliard de pages Web étaient stockées sur ses serveurs chaque semaine.
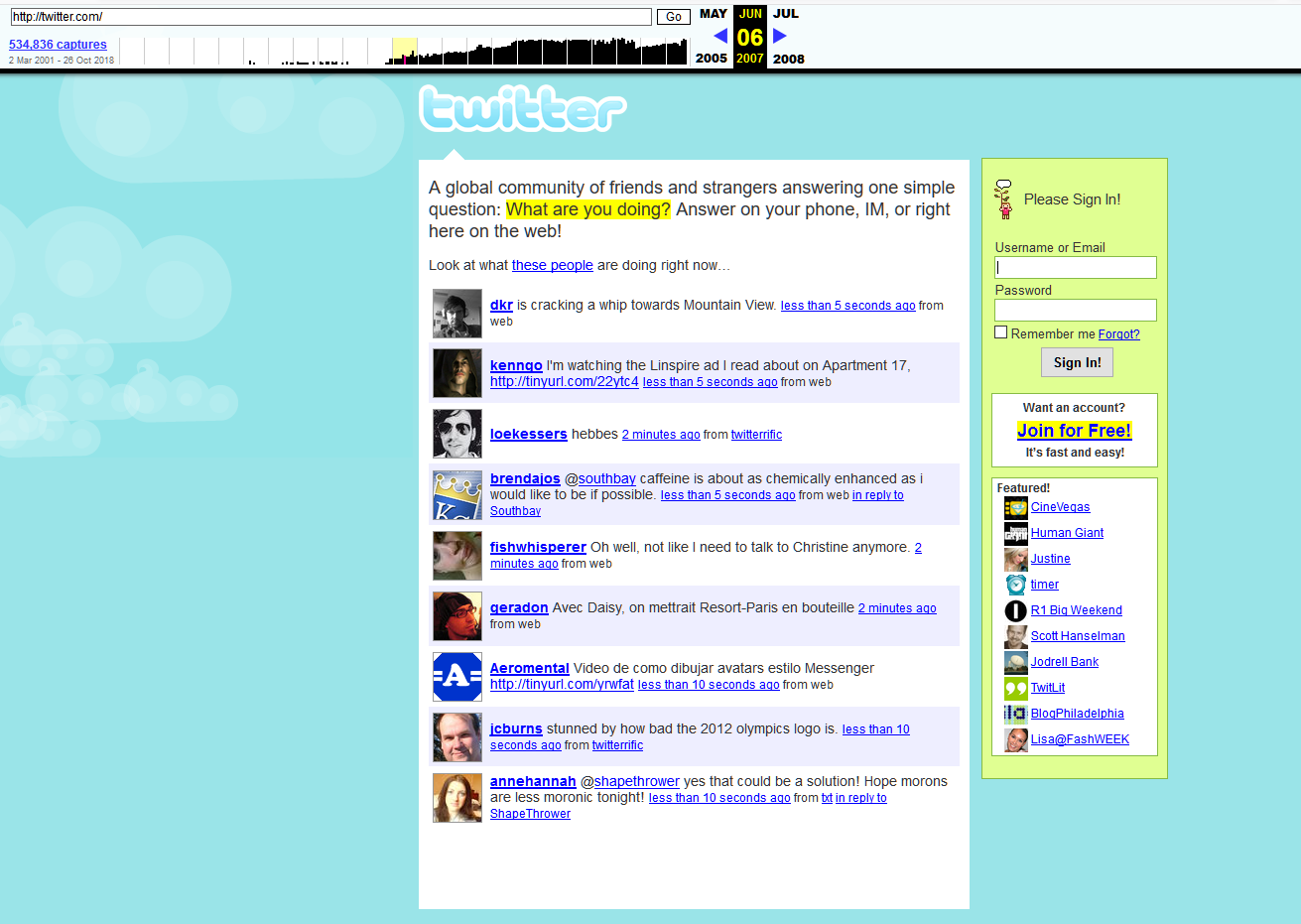 Voilà à quoi ressemblait Twitter en 2007
Voilà à quoi ressemblait Twitter en 2007Que peut-on trouver d'autre dans la base de données "Internet Archive"?
Livres. La collection de l'organisation est immense, elle comprend des livres numérisés, des éditions courantes et très rares. Les livres sont stockés non seulement en anglais, mais aussi dans de nombreuses autres langues. Les Archives ont des centres spécialisés pour numériser des livres, il y en a 33 au total, ils sont situés dans cinq pays à travers le monde.
Le personnel du centre numérise environ 1 000 livres par jour. La base de données des services contient des millions de publications, le travail sur leur numérisation est financé à la fois par des gens ordinaires et diverses organisations, y compris des bibliothèques et des fonds.
Depuis 2007, Internet Archive conserve des livres accessibles au public de Google Recherche de Livres dans sa base de données. Après le lancement, la base de livres s'est rapidement développée - en 2013, il y avait déjà plus de 900 000 livres enregistrés à partir du service Google.
L'un des services des «Archives» donne également accès à des livres entièrement ouverts, il y en a déjà plus d'un million. Ce service s'appelle Open Library.
Vidéo Le service stocke 4,5 millions de clips. Ils sont divisés par sujet et ont un objectif très différent. Les serveurs des «Archives» stockent des films, des documentaires, des enregistrements d'événements sportifs, des émissions de télévision et de nombreux autres supports.
En 2015, les «Archives» ont donné naissance à un projet d'envergure - la
numérisation des cassettes vidéo . Au début, il s'agissait d'environ 40 000 enregistrements provenant des archives de Marion Stokes, une femme qui, pendant des décennies, a enregistré des informations sur des enregistrements. Ensuite, d'autres cassettes vidéo ont été ajoutées, qui ont été envoyées aux «Archives» par les fans de l'idée de numériser des données importantes pour l'humanité.
Audio Comme pour la vidéo, les «archives» stockent également des fichiers audio, qui sont également divisés par sujet. L'an dernier, «Archive» a commencé à mettre en œuvre son nouveau projet - le décodage des enregistrements de gomme laque, le plus ancien format d'enregistrement audio. Le son a été conservé sur des plaques de gomme laque, une résine naturelle sécrétée par des vers femelles. Au total, les archives du
Great 78 Project contiennent plusieurs
centaines de milliers de documents .
Logiciel. Bien sûr, il est tout simplement impossible de stocker tous les logiciels créés par l'humanité, même pour les archives. Les serveurs stockent vintage - par exemple, des programmes pour Macintosh, des logiciels pour DOS et d'autres logiciels. En 2016, les employés des Archives ont publié plus de
1500 programmes pour Windows 3.1 , vous pouvez travailler directement dans le navigateur. En 2017, Internet Archive a publié une
archive logicielle pour le premier Macintosh .
Jeux Oui, l'archive donne accès à un grand nombre de jeux. Certains d'entre eux peuvent être lus dans l'environnement d'un émulateur de navigateur. Les jeux sont stockés très différemment, y compris
des consoles portables analogiques-numériques . Il existe des jeux pour
MS-DOS et
des jeux de console pour Atari et ColecoVision.

L'organisation a d'abord
publié les archives des anciens jeux en 2013. Nous parlons de titres il y a 30 à 40 ans, qui pouvaient être lus directement dans le navigateur. Ce sont des jeux pour les consoles Atari 2600 (1977), Atari 7800 (1986), ColecoVision (1982), Philips Videopac G7000 (1978) et Astrocade (1983). Le plus intéressant est qu'Internet Archive a permis de jouer en toute légalité. Maintenant, la collection compte
plus de 3400 jeux et continue de se reconstituer.