Salut habr.
Dans un projet où il était nécessaire de stocker et de traiter une liste dynamique assez grande, les testeurs ont commencé à se plaindre du manque de mémoire. Un moyen simple de résoudre le problème avec "peu de sang" en ajoutant une seule ligne de code est décrit ci-dessous. Le résultat dans l'image:
Comment cela fonctionne, a continué sous la coupe.
Prenons un exemple simple de «formation» - créez une classe DataItem contenant
des données
personnelles sur une personne, telles que son nom, son âge et son adresse.
class DataItem(object): def __init__(self, name, age, address): self.name = name self.age = age self.address = address
La question des "enfants" est de savoir combien un tel objet prend en mémoire?
Essayons la solution au front:
d1 = DataItem("Alex", 42, "-") print ("sys.getsizeof(d1):", sys.getsizeof(d1))
Nous obtenons une réponse de 56 octets. Cela semble un peu, assez satisfait.
Cependant, nous vérifions un autre objet dans lequel il y a plus de données:
d2 = DataItem("Boris", 24, "In the middle of nowhere") print ("sys.getsizeof(d2):", sys.getsizeof(d2))
La réponse est encore 56. À ce stade, nous comprenons que quelque chose ne se passe pas ici et que tout n'est pas aussi simple qu'il y paraît à première vue.
L'intuition ne nous fait pas défaut, et tout n'est vraiment pas si simple. Python est un langage très flexible avec une frappe dynamique, et pour son travail, il stocke beaucoup de données supplémentaires. Qui en eux-mêmes prennent beaucoup. À titre d'exemple, sys.getsizeof ("") renverra 33 - oui, jusqu'à 33 octets par ligne vide! Et sys.getsizeof (1) renverra 24 à 24 octets pour un entier (je demande aux programmeurs C de s'éloigner de l'écran et de ne pas lire plus loin, afin de ne pas perdre confiance dans le beau). Pour les éléments plus complexes, comme un dictionnaire, sys.getsizeof (dict ()) renverra 272 octets - et ceci pour un dictionnaire
vide . Je ne continuerai pas plus loin, j'espère que le principe est clair,
et les fabricants de RAM doivent également vendre leurs puces .
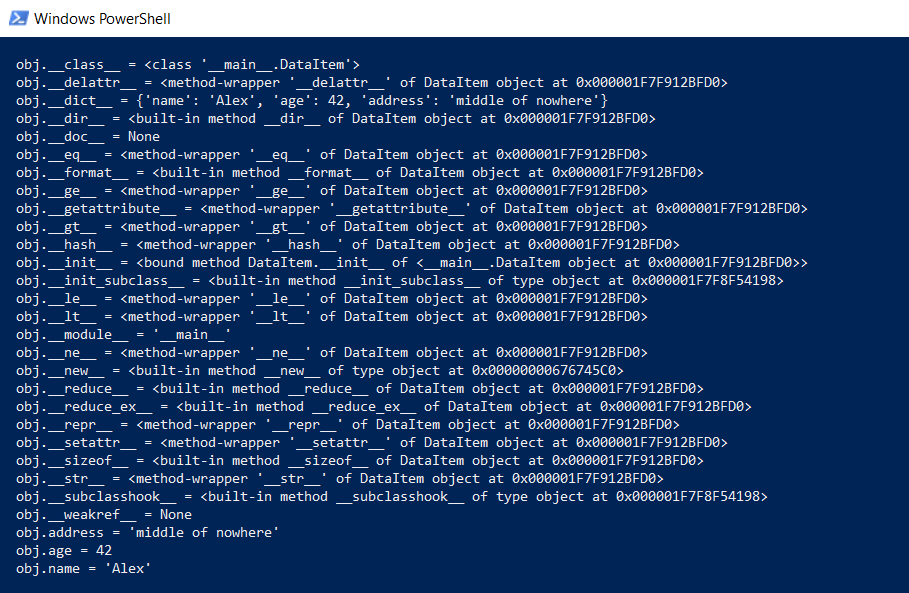
Mais revenons à notre classe DataItem et à la question "enfant". Combien de temps une telle classe prend-elle en mémoire? Pour commencer, nous affichons l'intégralité du contenu de la classe à un niveau inférieur:
def dump(obj): for attr in dir(obj): print(" obj.%s = %r" % (attr, getattr(obj, attr)))
Cette fonction montrera ce qui est caché «sous le capot» afin que toutes les fonctions Python (frappe, héritage et autres goodies) puissent fonctionner.
Le résultat est impressionnant:
Combien cela prend-il? Sur github, il y avait une fonction qui calcule la quantité réelle de données, appelant récursivement getsizeof pour tous les objets.
def get_size(obj, seen=None):
Nous l'essayons:
d1 = DataItem("Alex", 42, "-") print ("get_size(d1):", get_size(d1)) d2 = DataItem("Boris", 24, "In the middle of nowhere") print ("get_size(d2):", get_size(d2))
Nous obtenons respectivement 460 et 484 octets, ce qui ressemble davantage à la vérité.
Ayant cette fonction, un certain nombre d'expériences peuvent être effectuées. Par exemple, je me demande quelle quantité de données prendra si vous mettez les structures DataItem dans la liste. La fonction get_size ([d1]) retourne 532 octets - apparemment, c'est le "même" 460 + quelques frais généraux. Mais get_size ([d1, d2]) renverra 863 octets - moins de 460 + 484 séparément. Encore plus intéressant est le résultat pour get_size ([d1, d2, d1]) - nous obtenons 871 octets, juste un peu plus, c'est-à-dire Python est suffisamment intelligent pour ne pas allouer de mémoire pour le même objet une deuxième fois.
Passons maintenant à la deuxième partie de la question - est-il possible de réduire la consommation de mémoire? Oui tu peux. Python est un interpréteur, et nous pouvons étendre notre classe à tout moment, par exemple, ajouter un nouveau champ:
d1 = DataItem("Alex", 42, "-") print ("get_size(d1):", get_size(d1)) d1.weight = 66 print ("get_size(d1):", get_size(d1))
C'est très bien, mais si nous
n'avons pas besoin de cette fonctionnalité, nous pouvons forcer l'interpréteur à lister les objets de la classe en utilisant la directive __slots__:
class DataItem(object): __slots__ = ['name', 'age', 'address'] def __init__(self, name, age, address): self.name = name self.age = age self.address = address
Vous pouvez en lire plus dans la documentation (
RTFM ), qui dit que "__slots__ nous permet de déclarer explicitement les membres de données (comme les propriétés) et de refuser la création de __dict__ et __weakref__. L'espace économisé en utilisant __dict__
peut être important ".
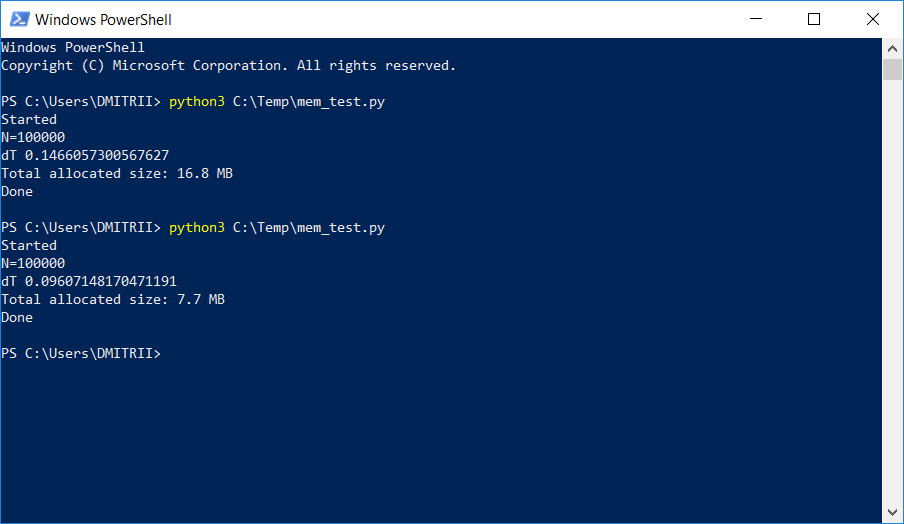
Vérifier: oui, vraiment significatif, get_size (d1) renvoie ... 64 octets au lieu de 460, c'est-à-dire 7 fois moins. En prime, les objets sont créés environ 20% plus rapidement (voir la première capture d'écran de l'article).
Hélas, avec une utilisation réelle, un tel gain de mémoire ne sera pas dû à d'autres frais généraux. Créons un tableau pour 100 000 en ajoutant simplement des éléments et voyons la consommation de mémoire:
data = [] for p in range(100000): data.append(DataItem("Alex", 42, "middle of nowhere")) snapshot = tracemalloc.take_snapshot() top_stats = snapshot.statistics('lineno') total = sum(stat.size for stat in top_stats) print("Total allocated size: %.1f MB" % (total / (1024*1024)))
Nous avons 16,8 Mo sans __slots__ et 6,9 Mo avec. Pas 7 fois bien sûr, mais quand même assez bien, étant donné que le changement de code était minime.
Maintenant sur les lacunes. L'activation de __slots__ interdit la création de tous les éléments, y compris __dict__, ce qui signifie, par exemple, qu'un tel code pour traduire la structure en json ne fonctionnera pas:
def toJSON(self): return json.dumps(self.__dict__)
Mais c'est facile à corriger, il suffit de générer votre dict par programme, en triant tous les éléments de la boucle:
def toJSON(self): data = dict() for var in self.__slots__: data[var] = getattr(self, var) return json.dumps(data)
Il sera également impossible d'ajouter dynamiquement de nouvelles variables à la classe, mais dans mon cas, cela n'était pas nécessaire.
Et le dernier test pour aujourd'hui. Il est intéressant de voir combien de mémoire prend tout le programme. Ajoutez une boucle sans fin à la fin du programme afin qu'il ne se ferme pas et voyez la consommation de mémoire dans le gestionnaire de tâches Windows.
Sans __slots__:
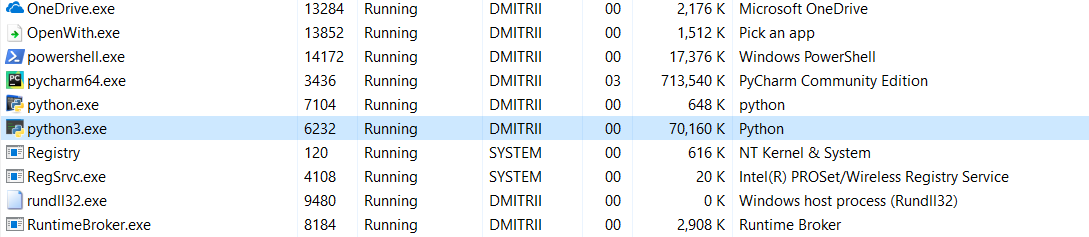
16,8 Mo sont en quelque sorte passés miraculeusement (édition - une explication du miracle ci-dessous) à 70 Mo (j'espère que les programmeurs C ne sont pas encore revenus à l'écran?).
Avec __slots__ activé:

6,9 Mo transformés en 27 Mo ... eh bien, après tout, nous avons économisé de la mémoire, 27 Mo au lieu de 70 n'est pas si mal pour le résultat de l'ajout d'une ligne de code.
Edit : dans les commentaires (merci à robert_ayrapetyan pour le test), ils ont suggéré que la bibliothèque de débogage tracemalloc occupe beaucoup de mémoire supplémentaire. Apparemment, il ajoute des éléments supplémentaires à
chaque objet créé. Si vous le désactivez, la consommation totale de mémoire sera bien moindre, la capture d'écran montre 2 options:
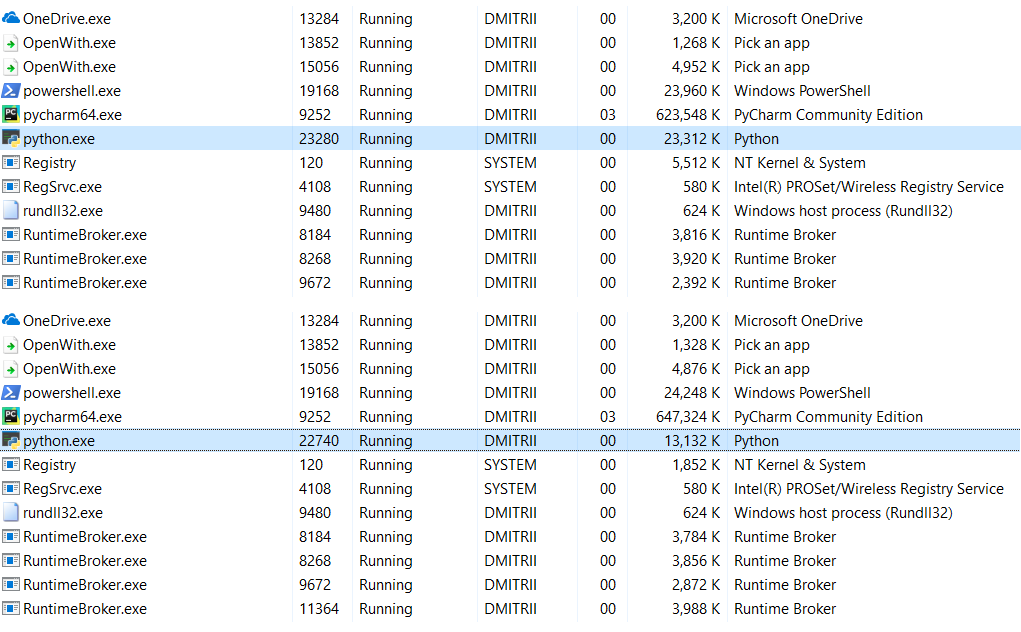
Que faire si vous avez besoin d'économiser encore plus de mémoire? Ceci est possible en utilisant la bibliothèque
numpy , qui vous permet de créer des structures de style C, mais dans mon cas, cela nécessiterait un raffinement plus approfondi du code, et la première méthode s'est avérée assez suffisante.
Il est étrange que l'utilisation de __slots__ n'ait jamais été examinée en détail sur Habré, j'espère que cet article comblera un peu cette lacune.
Au lieu d'une conclusion.
Cet article peut sembler anti-publicité de Python, mais ce n'est pas du tout le cas. Python est très fiable (vous devez essayer
très fort de supprimer un programme Python), un langage qui est facilement lisible et facile à écrire du code. Ces avantages l'emportent sur les inconvénients dans de nombreux cas, mais si vous avez besoin de performances et d'efficacité maximales, vous pouvez utiliser des bibliothèques comme numpy écrites en C ++ qui fonctionnent avec les données assez rapidement et efficacement.
Merci à tous pour votre attention et bon code :)