En expérimentant des améliorations pour le
modèle de prévision de
Guess.js , j'ai commencé à examiner de près l'apprentissage profond: les réseaux de neurones récurrents (RNN), en particulier les LSTM, en raison de leur
«efficacité déraisonnable» dans le domaine où Guess.js travaille. Dans le même temps, j'ai commencé à jouer avec les réseaux de neurones convolutifs (CNN), qui sont également souvent utilisés pour les séries chronologiques. Les CNN sont couramment utilisés pour classer, reconnaître et détecter des images.
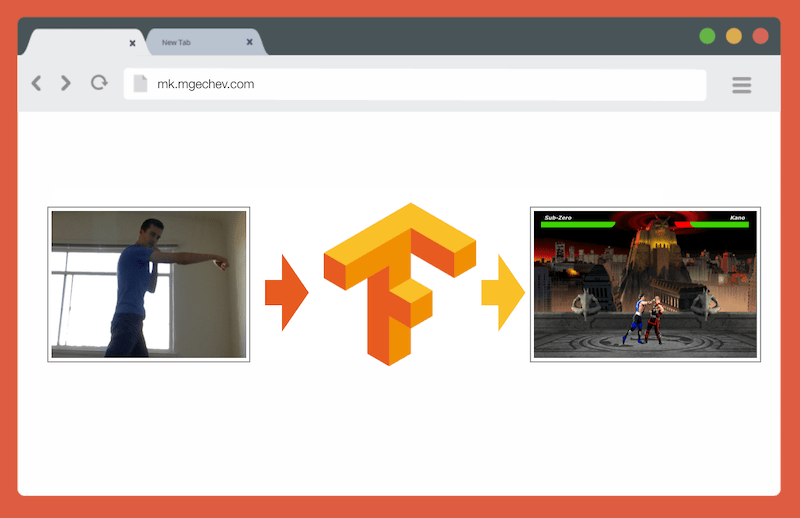 Gérer MK.js avec TensorFlow.js
Gérer MK.js avec TensorFlow.jsLe code source de cet article et MK.js sont sur mon GitHub . Je n'ai pas publié de jeu de données de formation, mais vous pouvez créer le vôtre et former le modèle comme décrit ci-dessous!
Après avoir joué avec CNN, je me suis souvenu d'une
expérience que j'avais menée il y a plusieurs années lorsque les développeurs de navigateurs ont publié l'API
getUserMedia . Dans celui-ci, la caméra de l'utilisateur a servi de contrôleur pour jouer au petit clone JavaScript de Mortal Kombat 3. Vous pouvez trouver ce jeu dans
le référentiel GitHub . Dans le cadre de l'expérience, j'ai implémenté un algorithme de positionnement de base qui classe l'image dans les classes suivantes:
- Poinçon gauche ou droit
- Coup de pied gauche ou droit
- Pas à gauche et à droite
- Squat
- Aucune de ces réponses
L'algorithme est si simple que je peux l'expliquer en quelques phrases:
L'algorithme photographie l'arrière-plan. Dès que l'utilisateur apparaît dans le cadre, l'algorithme calcule la différence entre l'arrière-plan et le cadre actuel avec l'utilisateur. Il détermine donc la position de la figure de l'utilisateur. L'étape suivante consiste à afficher le corps de l'utilisateur en blanc sur noir. Après cela, des histogrammes verticaux et horizontaux sont construits, sommant les valeurs pour chaque pixel. Sur la base de ce calcul, l'algorithme détermine la position actuelle du corps.
La vidéo montre comment fonctionne le programme. Code source de
GitHub .
Bien que le petit clone MK ait fonctionné avec succès, l'algorithme est loin d'être parfait. Un cadre avec un arrière-plan est requis. Pour un fonctionnement correct, l'arrière-plan doit être de la même couleur tout au long de l'exécution du programme. Une telle limitation signifie que les changements de lumière, d'ombre et d'autres choses interfèrent et donnent un résultat inexact. Enfin, l'algorithme ne reconnaît pas l'action; il classe uniquement le nouveau cadre comme la position du corps à partir d'un ensemble prédéfini.
Maintenant, grâce aux progrès de l'API Web, à savoir WebGL, j'ai décidé de revenir à cette tâche en appliquant TensorFlow.js.
Présentation
Dans cet article, je partagerai mon expérience dans la création d'un algorithme pour classer les positions du corps à l'aide de TensorFlow.js et MobileNet. Considérez les sujets suivants:
- Collecte de données d'entraînement pour la classification d'images
- Augmentation des données avec imgaug
- Transfert d'apprentissage avec MobileNet
- Classification binaire et classification N-primaire
- Formation au modèle de classification d'images TensorFlow.js dans Node.js et utilisation dans un navigateur
- Quelques mots sur la classification des actions avec LSTM
Dans cet article, nous allons réduire le problème de la détermination de la position du corps sur la base d'une image, contrairement à la reconnaissance des actions par une séquence d'images. Nous allons développer un modèle d'apprentissage en profondeur avec un enseignant qui, à partir de l'image de la webcam de l'utilisateur, détermine les mouvements d'une personne: coup de pied, jambe ou rien de tout cela.
À la fin de l'article, nous serons en mesure de construire un modèle pour jouer à
MK.js :

Pour une meilleure compréhension de l'article, le lecteur doit être familiarisé avec les concepts fondamentaux de la programmation et de JavaScript. Une compréhension de base de l'apprentissage en profondeur est également utile, mais pas nécessaire.
Collecte de données
La précision du modèle d'apprentissage en profondeur dépend fortement de la qualité des données. Nous devons nous efforcer de collecter un vaste ensemble de données, comme en production.
Notre modèle devrait être capable de reconnaître les coups de poing et les coups de pied. Cela signifie que nous devons collecter des images de trois catégories:
- Coups de pied
- Coups de pied
- Autre
Dans cette expérience, deux volontaires (
@lili_vs et
@gsamokovarov ) m'ont aidé à collecter des photos. Nous avons enregistré 5 vidéos QuickTime sur mon MacBook Pro, chacune contenant 2-4 coups de pied et 2-4 coups de pied.
Ensuite, nous utilisons ffmpeg pour extraire des images individuelles des vidéos et les enregistrer sous forme d'images
jpg :
ffmpeg -i video.mov $filename%03d.jpgPour exécuter la commande ci-dessus, vous devez d'abord
installer ffmpeg sur l'ordinateur.
Si nous voulons former le modèle, nous devons fournir les données d'entrée et les données de sortie correspondantes, mais à ce stade, nous n'avons qu'un tas d'images de trois personnes dans des poses différentes. Pour structurer les données, vous devez classer les cadres en trois catégories: coups de poing, coups de pied et autres. Pour chaque catégorie, un répertoire séparé est créé où toutes les images correspondantes sont déplacées.
Ainsi, dans chaque répertoire, il devrait y avoir environ 200 images similaires à celles ci-dessous:

Veuillez noter qu'il y aura beaucoup plus d'images dans le répertoire Others, car relativement peu d'images contiennent des photos de coups de poing et de pied, et dans les images restantes, les gens marchent, se retournent ou contrôlent la vidéo. Si nous avons trop d'images d'une classe, nous courons le risque d'enseigner le modèle biaisé vers cette classe particulière. Dans ce cas, lors de la classification d'une image ayant un impact, le réseau neuronal peut toujours déterminer la classe «Autre». Pour réduire ce biais, vous pouvez supprimer certaines photos du répertoire Others et entraîner le modèle sur un nombre égal d'images de chaque catégorie.
Pour plus de commodité, nous attribuons les numéros dans les catalogues de
1 à
190 , donc la première image sera
1.jpg , la seconde
2.jpg , etc.
Si nous formons le modèle à seulement 600 photographies prises dans le même environnement avec les mêmes personnes, nous n'atteindrons pas un niveau de précision très élevé. Pour tirer le meilleur parti de nos données, il est préférable de générer quelques échantillons supplémentaires à l'aide de l'augmentation des données.
Augmentation des données
L'augmentation des données est une technique qui augmente le nombre de points de données en synthétisant de nouveaux points à partir d'un ensemble existant. En règle générale, l'augmentation est utilisée pour augmenter la taille et la diversité de l'ensemble d'entraînement. Nous transférons les images originales vers le pipeline de transformations qui créent de nouvelles images. Vous ne pouvez pas aborder les transformations de manière trop agressive: seuls les autres coups de poing doivent être générés à partir d'un coup de poing.
Les transformations acceptables sont la rotation, l'inversion des couleurs, le flou, etc. Il existe d'excellents outils open source pour l'augmentation des données. Au moment d'écrire cet article en JavaScript, il n'y avait pas trop d'options, j'ai donc utilisé la bibliothèque implémentée en Python -
imgaug . Il dispose d'un ensemble d'agrandisseurs qui peuvent être appliqués de manière probabiliste.
Voici la logique d'augmentation des données pour cette expérience:
np.random.seed(44) ia.seed(44) def main(): for i in range(1, 191): draw_single_sequential_images(str(i), "others", "others-aug") for i in range(1, 191): draw_single_sequential_images(str(i), "hits", "hits-aug") for i in range(1, 191): draw_single_sequential_images(str(i), "kicks", "kicks-aug") def draw_single_sequential_images(filename, path, aug_path): image = misc.imresize(ndimage.imread(path + "/" + filename + ".jpg"), (56, 100)) sometimes = lambda aug: iaa.Sometimes(0.5, aug) seq = iaa.Sequential( [ iaa.Fliplr(0.5),
Ce script utilise la méthode
main avec trois boucles
for - une pour chaque catégorie d'image. Dans chaque itération, dans chacune des boucles, nous appelons la méthode
draw_single_sequential_images : le premier argument est le nom du fichier, le second est le chemin, le troisième est le répertoire où enregistrer le résultat.
Après cela, nous lisons l'image du disque et lui appliquons une série de transformations. J'ai documenté la plupart des transformations dans l'extrait de code ci-dessus, nous ne le répéterons donc pas.
Pour chaque image, 16 autres images sont créées. Voici un exemple de leur apparence:

Veuillez noter que dans le script ci-dessus, nous redimensionnons les images à
100x56 pixels. Nous le faisons pour réduire la quantité de données et, par conséquent, le nombre de calculs que notre modèle effectue pendant la formation et l'évaluation.
Construction de modèles
Maintenant, construisez un modèle pour la classification!
Puisque nous avons affaire à des images, nous utilisons un réseau neuronal convolutif (CNN). Cette architecture de réseau est connue pour convenir à la reconnaissance d'images, à la détection d'objets et à la classification.
Transfert d'apprentissage
L'image ci-dessous montre le populaire CNN VGG-16, utilisé pour classer les images.
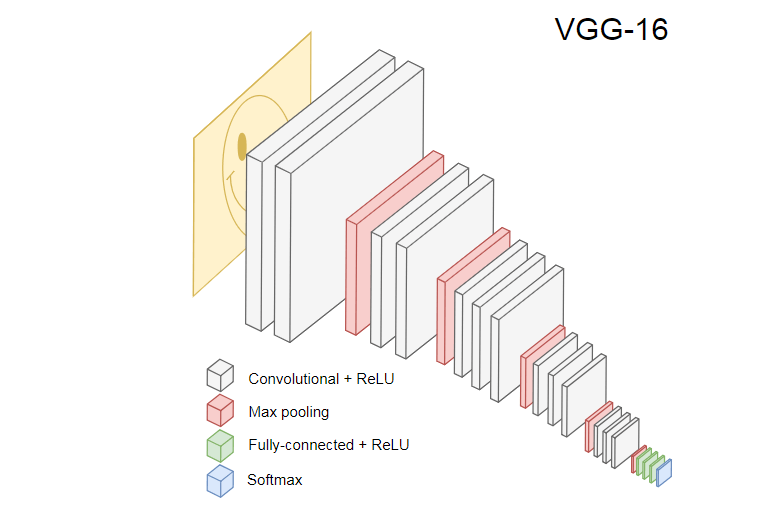
Le réseau neuronal VGG-16 reconnaît 1 000 classes d'images. Il a 16 couches (sans compter les couches de regroupement et de sortie). Un tel réseau multicouche est difficile à former en pratique. Cela nécessitera un grand ensemble de données et de nombreuses heures de formation.
Les couches masquées de CNN formés reconnaissent divers éléments d'images de l'ensemble d'apprentissage, en commençant par les bords, pour passer à des éléments plus complexes, tels que des formes, des objets individuels, etc. Un CNN formé dans le style de VGG-16 pour reconnaître un grand ensemble d'images doit avoir des couches cachées qui ont appris beaucoup de fonctionnalités de l'ensemble d'entraînement. Ces fonctionnalités seront communes à la plupart des images et, par conséquent, réutilisées dans différentes tâches.
Le transfert d'apprentissage vous permet de réutiliser un réseau existant et formé. Nous pouvons prendre la sortie de n'importe laquelle des couches du réseau existant et la transférer comme entrée vers le nouveau réseau neuronal. Ainsi, en enseignant le réseau neuronal nouvellement créé, au fil du temps, il peut être appris à reconnaître de nouvelles fonctionnalités d'un niveau supérieur et à classer correctement les images de classes que le modèle d'origine n'avait jamais vues auparavant.
Pour nos besoins, prenez le réseau neuronal MobileNet du package
@ tensorflow-models / mobilenet . MobileNet est tout aussi puissant que VGG-16, mais il est beaucoup plus petit, ce qui accélère la distribution directe, c'est-à-dire la propagation réseau (propagation directe) et réduit le temps de téléchargement dans le navigateur. MobileNet s'est formé sur l'
ensemble de données de classification d'images
ILSVRC-2012-CLS .
Lors du développement d'un modèle avec un transfert d'apprentissage, nous avons deux choix:
- Sortie à partir de quelle couche du modèle source à utiliser comme entrée pour le modèle cible.
- Combien de couches du modèle cible allons-nous former, le cas échéant.
Le premier point est très significatif. Selon la couche sélectionnée, nous obtiendrons des caractéristiques à un niveau d'abstraction inférieur ou supérieur en entrée de notre réseau neuronal.
Nous n'entraînerons aucune couche de MobileNet. Nous
global_average_pooling2d_1 sortie de
global_average_pooling2d_1 et la transmettons en entrée à notre petit modèle. Pourquoi ai-je choisi cette couche particulière? Empiriquement. J'ai fait quelques tests, et cette couche fonctionne plutôt bien.
Définition du modèle
La tâche initiale consistait à classer l'image en trois classes: main, pied et autres mouvements. Tout d'abord, résolvons le plus petit problème: nous déterminerons s'il y a ou non un coup de main dans le cadre. Il s'agit d'un problème de classification binaire typique. Pour cela, nous pouvons définir le modèle suivant:
import * as tf from '@tensorflow/tfjs'; const model = tf.sequential(); model.add(tf.layers.inputLayer({ inputShape: [1024] })); model.add(tf.layers.dense({ units: 1024, activation: 'relu' })); model.add(tf.layers.dense({ units: 1, activation: 'sigmoid' })); model.compile({ optimizer: tf.train.adam(1e-6), loss: tf.losses.sigmoidCrossEntropy, metrics: ['accuracy'] });
Un tel code définit un modèle simple, une couche de
1024 unités et l'activation
ReLU , ainsi qu'une unité de sortie qui passe par la
sigmoid activation
sigmoid . Ce dernier donne un nombre de
0 à
1 , selon la probabilité de coup de main dans ce cadre.
Pourquoi ai-je choisi
1024 unités pour le deuxième niveau et une vitesse d'entraînement de
1e-6 ? Eh bien, j'ai essayé plusieurs options différentes et j'ai vu que ces options fonctionnaient mieux. La méthode Spear ne semble pas être la meilleure approche, mais dans une large mesure, c'est ainsi que les paramètres hyperparamétriques dans le travail d'apprentissage en profondeur - sur la base de notre compréhension du modèle, nous utilisons l'intuition pour mettre à jour les paramètres orthogonaux et vérifier empiriquement le fonctionnement du modèle.
La méthode de
compile compile les couches ensemble, préparant le modèle pour la formation et l'évaluation. Ici, nous annonçons que nous voulons utiliser l'algorithme d'optimisation d'
adam . Nous déclarons également que nous allons calculer la perte (perte) de l'entropie croisée et indiquer que nous voulons évaluer la précision du modèle. TensorFlow.js calcule ensuite la précision à l'aide de la formule:
Accuracy = (True Positives + True Negatives) / (Positives + Negatives)Si vous transférez la formation à partir du modèle MobileNet d'origine, vous devez d'abord la télécharger. Comme il n'est pas pratique de former notre modèle sur plus de 3 000 images dans un navigateur, nous utiliserons Node.js et chargerons le réseau neuronal à partir du fichier.
Téléchargez MobileNet
ici . Le catalogue contient le fichier
model.json , qui contient l'architecture du modèle - couches, activations, etc. Les fichiers restants contiennent des paramètres de modèle. Vous pouvez charger le modèle à partir d'un fichier à l'aide de ce code:
export const loadModel = async () => { const mn = new mobilenet.MobileNet(1, 1); mn.path = `file://PATH/TO/model.json`; await mn.load(); return (input): tf.Tensor1D => mn.infer(input, 'global_average_pooling2d_1') .reshape([1024]); };
Notez que dans la méthode
loadModel nous retournons une fonction qui accepte un tenseur unidimensionnel en entrée et retourne
mn.infer(input, Layer) . La méthode d'
infer prend un tenseur et une couche comme arguments. Le calque détermine le calque caché dont nous voulons la sortie. Si vous ouvrez
model.json et
global_average_pooling2d_1 , vous trouverez un tel nom sur l'une des couches.
Vous devez maintenant créer un ensemble de données pour l'apprentissage du modèle. Pour ce faire, nous devons passer toutes les images via la méthode d'inférence dans MobileNet et leur attribuer des étiquettes:
1 pour les images avec traits et
0 pour les images sans traits:
const punches = require('fs') .readdirSync(Punches) .filter(f => f.endsWith('.jpg')) .map(f => `${Punches}/${f}`); const others = require('fs') .readdirSync(Others) .filter(f => f.endsWith('.jpg')) .map(f => `${Others}/${f}`); const ys = tf.tensor1d( new Array(punches.length).fill(1) .concat(new Array(others.length).fill(0))); const xs: tf.Tensor2D = tf.stack( punches .map((path: string) => mobileNet(readInput(path))) .concat(others.map((path: string) => mobileNet(readInput(path)))) ) as tf.Tensor2D;
Dans le code ci-dessus, nous lisons d'abord les fichiers dans des répertoires avec et sans hits. Ensuite, nous déterminons le tenseur unidimensionnel contenant les étiquettes de sortie. Si nous avons
n images avec traits et
m autres images, le tenseur aura
n éléments avec une valeur de 1 et
m éléments avec une valeur de 0.
Dans
xs nous
infer résultats de l'appel de la méthode d'
infer pour des images individuelles. Notez que pour chaque image, nous appelons la méthode
readInput . Voici sa mise en œuvre:
export const readInput = img => imageToInput(readImage(img), TotalChannels); const readImage = path => jpeg.decode(fs.readFileSync(path), true); const imageToInput = image => { const values = serializeImage(image); return tf.tensor3d(values, [image.height, image.width, 3], 'int32'); }; const serializeImage = image => { const totalPixels = image.width * image.height; const result = new Int32Array(totalPixels * 3); for (let i = 0; i < totalPixels; i++) { result[i * 3 + 0] = image.data[i * 4 + 0]; result[i * 3 + 1] = image.data[i * 4 + 1]; result[i * 3 + 2] = image.data[i * 4 + 2]; } return result; };
readInput appelle d'abord la fonction
readImage , puis délègue son appel à
imageToInput . La fonction
readImage lit une image à partir du disque, puis décode jpg à partir du tampon à l'aide du package
jpeg-js . Dans
imageToInput nous convertissons l'image en un tenseur tridimensionnel.
Par conséquent, pour chaque
i de
0 à
TotalImages doit être
ys[i] égal à
1 si
xs[i] correspond à l'image avec un hit, et
0 sinon.
Formation modèle
Maintenant, le modèle est prêt pour la formation! Appelez la méthode d'
fit :
await model.fit(xs, ys, { epochs: Epochs, batchSize: parseInt(((punches.length + others.length) * BatchSize).toFixed(0)), callbacks: { onBatchEnd: async (_, logs) => { console.log('Cost: %s, accuracy: %s', logs.loss.toFixed(5), logs.acc.toFixed(5)); await tf.nextFrame(); } } });
Les appels de code ci-dessus
fit à trois arguments:
xs , ys et l'objet de configuration. Dans l'objet de configuration, nous définissons le nombre d'ères que le modèle, la taille du paquet et le rappel que TensorFlow.js générera après le traitement de chaque paquet seront formés.
La taille du paquet détermine
xs et
ys pour former le modèle à une époque. Pour chaque époque, TensorFlow.js sélectionnera un sous-ensemble de
xs et les éléments correspondants de
ys , effectuera une distribution directe, recevra la sortie de la couche avec activation
sigmoid , puis, en fonction de la perte, effectuera l'optimisation à l'aide de l'algorithme
adam .
Après avoir démarré le script de formation, vous verrez un résultat similaire à celui ci-dessous:
Coût: 0,84212, précision: 1,00000
eta = 0,3> ---------- acc = 1,00 perte = 0,84 Coût: 0,79740, précision: 1,00000
eta = 0,2 => --------- acc = 1,00 perte = 0,80 Coût: 0,81533, précision: 1,00000
eta = 0,2 ==> -------- acc = 1,00 perte = 0,82 Coût: 0,64303, précision: 0,50000
eta = 0,2 ===> ------- acc = 0,50 perte = 0,64 Coût: 0,51377, précision: 0,00000
eta = 0,2 ====> ------ acc = 0,00 perte = 0,51 Coût: 0,46473, précision: 0,50000
eta = 0,1 =====> ----- acc = 0,50 perte = 0,46 Coût: 0,50872, précision: 0,00000
eta = 0,1 ======> ---- acc = 0,00 perte = 0,51 Coût: 0,62556, précision: 1,00000
eta = 0,1 =======> --- acc = 1,00 perte = 0,63 Coût: 0,65133, précision: 0,50000
eta = 0,1 ========> - acc = 0,50 perte = 0,65 Coût: 0,63824, précision: 0,50000
eta = 0.0 ===========>
293ms 14675us / step - acc = 0,60 perte = 0,65
Époque 3/50
Coût: 0,44661, précision: 1,00000
eta = 0,3> ---------- acc = 1,00 perte = 0,45 Coût: 0,78060, précision: 1,00000
eta = 0,3 => --------- acc = 1,00 perte = 0,78 Coût: 0,79208, précision: 1,00000
eta = 0,3 ==> -------- acc = 1,00 perte = 0,79 Coût: 0,49072, précision: 0,50000
eta = 0,2 ===> ------- acc = 0,50 perte = 0,49 Coût: 0,62232, précision: 1,00000
eta = 0,2 ====> ------ acc = 1,00 perte = 0,62 Coût: 0,82899, précision: 1,00000
eta = 0,2 =====> ----- acc = 1,00 perte = 0,83 Coût: 0,67629, précision: 0,50000
eta = 0,1 ======> ---- acc = 0,50 perte = 0,68 Coût: 0,62621, précision: 0,50000
eta = 0,1 =======> --- acc = 0,50 perte = 0,63 Coût: 0,46077, précision: 1,00000
eta = 0,1 ========> - acc = 1,00 perte = 0,46 Coût: 0,62076, précision: 1,00000
eta = 0.0 ===========>
304ms 15221us / step - acc = 0,85 perte = 0,63
Remarquez comment la précision augmente avec le temps et la perte diminue.
Sur mon jeu de données, le modèle après l'entraînement a montré une précision de 92%. Gardez à l'esprit que la précision peut ne pas être très élevée en raison du petit ensemble de données d'entraînement.
Exécution du modèle dans un navigateur
Dans la section précédente, nous avons formé le modèle de classification binaire. Maintenant, exécutez-le dans un navigateur et connectez-vous à
MK.js !
const video = document.getElementById('cam'); const Layer = 'global_average_pooling2d_1'; const mobilenetInfer = m => (p): tf.Tensor<tf.Rank> => m.infer(p, Layer); const canvas = document.getElementById('canvas'); const scale = document.getElementById('crop'); const ImageSize = { Width: 100, Height: 56 }; navigator.mediaDevices .getUserMedia({ video: true, audio: false }) .then(stream => { video.srcObject = stream; });
Il y a plusieurs déclarations dans le code ci-dessus:
video HTML5 videoLayer MobileNet,mobilenetInfer — , MobileNet . MobileNetcanvas HTML5 canvas ,scale — canvas ,
Après cela, nous obtenons le flux vidéo de la caméra de l'utilisateur et le définissons comme source pour l'élément video.L'étape suivante consiste à implémenter un filtre en niveaux de gris qui accepte canvaset convertit son contenu: const grayscale = (canvas: HTMLCanvasElement) => { const imageData = canvas.getContext('2d').getImageData(0, 0, canvas.width, canvas.height); const data = imageData.data; for (let i = 0; i < data.length; i += 4) { const avg = (data[i] + data[i + 1] + data[i + 2]) / 3; data[i] = avg; data[i + 1] = avg; data[i + 2] = avg; } canvas.getContext('2d').putImageData(imageData, 0, 0); };
Dans la prochaine étape, nous connecterons le modèle avec MK.js: let mobilenet: (p: any) => tf.Tensor<tf.Rank>; tf.loadModel('http://localhost:5000/model.json').then(model => { mobileNet .load() .then((mn: any) => mobilenet = mobilenetInfer(mn)) .then(startInterval(mobilenet, model)); });
Dans le code ci-dessus, nous chargeons d'abord le modèle que nous avons formé ci-dessus, puis téléchargeons MobileNet. Nous passons MobileNet dans la méthode mobilenetInferpour obtenir le moyen de calculer la sortie de la couche réseau cachée. Après cela, nous appelons la méthode startIntervalavec deux réseaux comme arguments. const startInterval = (mobilenet, model) => () => { setInterval(() => { canvas.getContext('2d').drawImage(video, 0, 0); grayscale(scale .getContext('2d') .drawImage( canvas, 0, 0, canvas.width, canvas.width / (ImageSize.Width / ImageSize.Height), 0, 0, ImageSize.Width, ImageSize.Height )); const [punching] = Array.from(( model.predict(mobilenet(tf.fromPixels(scale))) as tf.Tensor1D) .dataSync() as Float32Array); const detect = (window as any).Detect; if (punching >= 0.4) detect && detect.onPunch(); }, 100); };
La partie la plus intéressante commence dans la méthode startInterval! Tout d'abord, nous exécutons un intervalle où tout le monde 100msappelle une fonction anonyme. Dans celui-ci, la canvasvidéo avec l'image actuelle est rendue en premier dessus . Ensuite, nous réduisons la taille du cadre 100x56et lui appliquons un filtre en niveaux de gris.L'étape suivante consiste à transférer la trame vers MobileNet, à obtenir la sortie de la couche cachée souhaitée et à la transférer comme entrée dans la méthode de predictnotre modèle. Cela renvoie un tenseur avec un élément. En utilisant, dataSyncnous obtenons la valeur du tenseur et l'assignons à une constante punching.Enfin, nous vérifions: si la probabilité d'un coup de main dépasse 0.4, alors nous appelons la méthode onPunchglobale de l'objet Detect. MK.js fournit un objet global avec trois méthodes:onKick, onPunchet onStandque nous pouvons utiliser pour contrôler l'un des personnages.C'est fait!
Voici le résultat!
Reconnaissance des coups de pied et des bras avec classification N
Dans la section suivante, nous créerons un modèle plus intelligent: un réseau neuronal qui reconnaît les coups de poing, les coups de pied et d'autres images. Cette fois, commençons par préparer l'ensemble de formation: const punches = require('fs') .readdirSync(Punches) .filter(f => f.endsWith('.jpg')) .map(f => `${Punches}/${f}`); const kicks = require('fs') .readdirSync(Kicks) .filter(f => f.endsWith('.jpg')) .map(f => `${Kicks}/${f}`); const others = require('fs') .readdirSync(Others) .filter(f => f.endsWith('.jpg')) .map(f => `${Others}/${f}`); const ys = tf.tensor2d( new Array(punches.length) .fill([1, 0, 0]) .concat(new Array(kicks.length).fill([0, 1, 0])) .concat(new Array(others.length).fill([0, 0, 1])), [punches.length + kicks.length + others.length, 3] ); const xs: tf.Tensor2D = tf.stack( punches .map((path: string) => mobileNet(readInput(path))) .concat(kicks.map((path: string) => mobileNet(readInput(path)))) .concat(others.map((path: string) => mobileNet(readInput(path)))) ) as tf.Tensor2D;
Comme précédemment, nous avons d'abord lu les catalogues avec des images de coups de poing à la main, au pied et d'autres images. Après cela, contrairement à la dernière fois, nous formons le résultat attendu sous la forme d'un tenseur bidimensionnel et non unidimensionnel. Si nous avons n images avec un coup de pied, m images avec un coup de pied et k autres images, alors le tenseur ysaura des néléments avec une valeur [1, 0, 0], des méléments avec une valeur [0, 1, 0]et des kéléments avec une valeur [0, 0, 1].Un vecteur d' néléments dans lequel il y a des n - 1éléments avec une valeur 0et un élément avec une valeur 1, nous appelons un vecteur unitaire (un vecteur chaud).Après cela, nous formons le tenseur d'entréexsempiler la sortie de chaque image de MobileNet.Ici, vous devez mettre à jour la définition du modèle: const model = tf.sequential(); model.add(tf.layers.inputLayer({ inputShape: [1024] })); model.add(tf.layers.dense({ units: 1024, activation: 'relu' })); model.add(tf.layers.dense({ units: 3, activation: 'softmax' })); await model.compile({ optimizer: tf.train.adam(1e-6), loss: tf.losses.sigmoidCrossEntropy, metrics: ['accuracy'] });
Les deux seules différences par rapport au modèle précédent sont:- Le nombre d'unités dans la couche de sortie
- Activations dans la couche de sortie
Il y a trois unités dans la couche de sortie, car nous avons trois catégories d'images différentes:- Coup de main
- Coup de pied
- Autre
L'activation est déclenchée sur ces trois unités softmax, qui convertit leurs paramètres en un tenseur à trois valeurs. Pourquoi trois unités pour la couche de sortie? Chacune des trois valeurs pour trois classes peut être représenté par deux bits: 00, 01, 10. La somme des valeurs du tenseur créé softmaxest 1, c'est-à-dire que nous n'obtiendrons jamais 00, nous ne pourrons donc pas classer les images d'une des classes.Après avoir entraîné le modèle au fil des 500âges, j'ai atteint une précision d'environ 92%! Ce n'est pas mal, mais n'oubliez pas que la formation s'est déroulée sur un petit ensemble de données.La prochaine étape consiste à exécuter le modèle dans un navigateur! Étant donné que la logique est très similaire à l'exécution du modèle pour la classification binaire, jetez un œil à la dernière étape, où l'action est sélectionnée en fonction de la sortie du modèle: const [punch, kick, nothing] = Array.from((model.predict( mobilenet(tf.fromPixels(scaled)) ) as tf.Tensor1D).dataSync() as Float32Array); const detect = (window as any).Detect; if (nothing >= 0.4) return; if (kick > punch && kick >= 0.35) { detect.onKick(); return; } if (punch > kick && punch >= 0.35) detect.onPunch();
Nous appelons d'abord MobileNet avec un cadre réduit dans des tons de gris, puis nous transférons le résultat de notre modèle formé. Le modèle renvoie un tenseur unidimensionnel, que nous convertissons en Float32Arrayc dataSync. Dans l'étape suivante, nous utilisons Array.frompour convertir un tableau typé en un tableau JavaScript. Ensuite, nous extrayons les probabilités qu'un tir avec une main, un coup de pied ou rien soit présent sur le cadre.Si la probabilité du troisième résultat dépasse 0.4, nous revenons. Sinon, si la probabilité d'un coup de pied est plus élevée 0.32, nous envoyons une commande de coup de pied à MK.js. Si la probabilité d'un coup de pied est plus élevée 0.32et plus élevée que la probabilité d'un coup de pied, alors envoyez l'action d'un coup de pied.En général, c'est tout! Le résultat est présenté ci-dessous:
Reconnaissance de l'action
Si vous collectez un ensemble de données important et varié sur les personnes qui battent avec leurs mains et leurs pieds, vous pouvez créer un modèle qui fonctionne parfaitement sur des cadres individuels. Mais est-ce suffisant? Et si nous voulons aller encore plus loin et distinguer deux types de coups de pied différents: d'un virage et d'un dos (coup de pied arrière).Comme on peut le voir dans les images ci-dessous, à un certain moment sous un certain angle, les deux traits se ressemblent:
 mais si vous regardez la performance, les mouvements sont complètement différents:
mais si vous regardez la performance, les mouvements sont complètement différents: comment pouvez-vous former un réseau neuronal à analyser une séquence d'images, et pas seulement une image?À cette fin, nous pouvons explorer une autre classe de réseaux de neurones, appelés réseaux de neurones récurrents (RNN). Par exemple, les RNN sont parfaits pour travailler avec des séries chronologiques:
comment pouvez-vous former un réseau neuronal à analyser une séquence d'images, et pas seulement une image?À cette fin, nous pouvons explorer une autre classe de réseaux de neurones, appelés réseaux de neurones récurrents (RNN). Par exemple, les RNN sont parfaits pour travailler avec des séries chronologiques:- Traitement du langage naturel (NLP), où chaque mot dépend du précédent et du suivant
- Prédire la page suivante en fonction de votre historique de navigation
- Reconnaissance de trame
L'implémentation d'un tel modèle dépasse le cadre de cet article, mais regardons un exemple d'architecture pour avoir une idée de la façon dont tout cela fonctionnera ensemble.La puissance de RNN
Le schéma ci-dessous montre le modèle de reconnaissance des actions: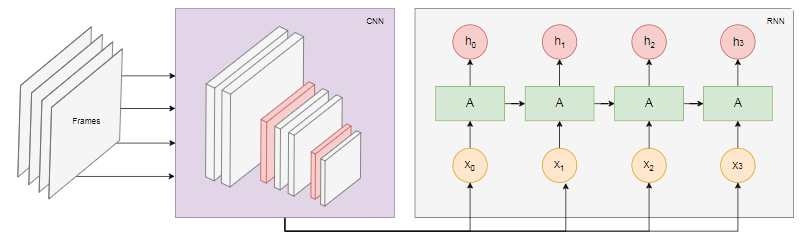 Nous prenons les dernières
Nous prenons les dernières nimages de la vidéo et les transférons sur CNN. La sortie CNN pour chaque trame est transmise comme entrée RNN. Un réseau de neurones récurrent déterminera les relations entre les cadres individuels et reconnaîtra à quelle action ils correspondent.Conclusion
Dans cet article, nous avons développé un modèle de classification d'images. À cet effet, nous avons collecté un ensemble de données: nous avons extrait des images vidéo et les avons divisées manuellement en trois catégories. Ensuite, les données ont été augmentées en ajoutant des images à l'aide d' imgaug .Après cela, nous avons expliqué ce qu'est le transfert d'apprentissage et utilisé le modèle MobileNet formé à partir du package @ tensorflow-models / mobilenet à nos propres fins . Nous avons chargé MobileNet à partir d'un fichier dans le processus Node.js et formé une couche dense supplémentaire où les données ont été alimentées à partir de la couche MobileNet cachée. Après l'entraînement, nous avons atteint une précision de plus de 90%!Pour utiliser ce modèle dans un navigateur, nous l'avons téléchargé avec MobileNet et commencé à catégoriser les images de la webcam de l'utilisateur toutes les 100 ms. Nous avons connecté le modèle avec le jeuMK.js et utilisé la sortie du modèle pour contrôler l'un des caractères.Enfin, nous avons examiné comment améliorer le modèle en le combinant avec un réseau neuronal récurrent pour reconnaître les actions.J'espère que vous n'avez pas moins apprécié ce petit projet que moi!