Je m'appelle Andrey Polyakov, je suis le chef du groupe de documentation API et SDK chez Yandex. Aujourd'hui, je voudrais partager avec vous un rapport que moi et ma collègue, la développeur de documentation senior Julia Pivovarova, avons lu il y a quelques semaines lors du sixième Hyperbaton.
Svetlana Kayushina, chef du service documentation et localisation:
- Les volumes de code de programme dans le monde au cours des dernières années ont considérablement augmenté, continuent de croître, ce qui affecte le travail des rédacteurs techniques, qui ont de plus en plus de tâches pour développer la documentation du programme et le code du document. Nous ne pouvions ignorer ce sujet, nous y avons consacré une section entière. Il s'agit de trois rapports connexes sur l'unification du développement logiciel. J'invite nos spécialistes de la documentation des interfaces logicielles et des bibliothèques à Andrei Polyakov et Julia Pivovarova. Je leur donne la parole.
- Bonjour à tous! Aujourd'hui, Julia et moi vous dirons comment dans Yandex nous avons eu un nouveau regard sur la documentation de l'API et du SDK. Le rapport sera composé de quatre parties, le rapport de veille, nous discuterons, nous parlerons.
Parlons de l'unification de l'API et du SDK, comment nous y sommes arrivés, ce que nous y avons fait. Nous partagerons l'expérience de l'utilisation d'un générateur universel, un pour toutes les langues, et vous expliquerons pourquoi cela ne nous convenait pas, quels étaient les pièges et pourquoi nous sommes passés à la génération de documentation par des générateurs natifs.
À la fin, nous décrirons comment nos processus ont été construits.
Commençons par l'unification. Tout le monde pense à l'unification quand il y a plus de deux personnes dans une équipe: chacun écrit différemment, chacun a ses propres approches, et c'est logique. Il est préférable de discuter de toutes les règles sur la plage avant de commencer à rédiger de la documentation, mais tout le monde ne peut pas le faire.
Nous avons réuni un groupe d'experts pour analyser notre documentation. Nous l'avons fait pour systématiser nos approches. Tout le monde écrit de différentes manières, et acceptons d'écrire dans le même style. C'est le deuxième point, pour lequel nous allions essayer de rendre la documentation uniforme, afin que l'utilisateur ait une expérience utilisateur dans toute la documentation Yandex, à savoir technique.
Le travail a été divisé en trois étapes. Nous avons compilé une description des technologies que nous utilisons dans Yandex, nous avons essayé de distinguer celles que nous pouvons en quelque sorte unifier. Et constituait également la structure générale des documents et modèles standard.

Passons à la description des technologies. Nous avons commencé à étudier les technologies utilisées dans Yandex. Il y en a tellement que nous sommes fatigués de les écrire dans une sorte de cahier, et en conséquence, nous n'avons sélectionné que les plus élémentaires les plus souvent utilisés, que les rédacteurs techniques rencontrent le plus souvent, et nous avons commencé à les décrire.
Qu'entend-on par description technologique? Nous avons identifié les principaux points et l'essence de chaque technologie. Si nous parlons de langages de programmation, alors c'est une description d'entités telles qu'une classe, une propriété, des interfaces, etc. Si nous parlons de protocoles, alors nous décrivons des méthodes HTTP, nous parlons du format du code d'erreur, du code de réponse, etc. un glossaire contenant les éléments suivants: termes en russe, termes en anglais, nuances d'utilisation. Par exemple, nous ne parlons d'aucune méthode SDK, cela vous permet de faire quelque chose. Il FAIT quelque chose, si le programmeur tire un stylo, il donne une réponse.
En plus des nuances, la description contenait également des structures standard, des tours de parole standard, que nous utilisons dans la documentation afin que le rédacteur technique puisse prendre un libellé spécifique et l'utiliser plus loin.
De plus, les rédacteurs techniques écrivent souvent des morceaux de code, des extraits, des exemples, et pour cela, nous avons également décrit notre guide de style pour chaque technologie. Nous nous sommes tournés vers les guides de développement qui se trouvent dans Yandex. Nous avons prêté attention au code de conception, à la description des commentaires, à l'indentation et à tout cela. Nous faisons cela pour que lorsqu'un rédacteur technique vienne avec un morceau de code ou un échantillon écrit à un programmeur, le programmeur regarde l'essence, et non pas la façon dont il est conçu, et cela réduit le temps. Et quand un rédacteur technique peut écrire sur des guides de style Yandex, c'est très cool, peut-être qu'il voudra devenir programmeur plus tard. Le rapport précédent portait sur divers examens. Par exemple, vous pouvez passer aux programmeurs.
Nous avons également développé un démarrage rapide pour les rédacteurs technologiques: comment mettre en place un environnement de développement lorsqu'il se familiarise avec les nouvelles technologies. Par exemple, si le SDK du rédacteur technique est écrit en C #, il vient, configure l'environnement de développement, lit les manuels, se familiarise avec la terminologie. Nous avons également laissé des liens vers la documentation officielle et le RFC, le cas échéant. Nous avons créé un point d'entrée pour les rédacteurs techniques, et cela ressemble à ceci.
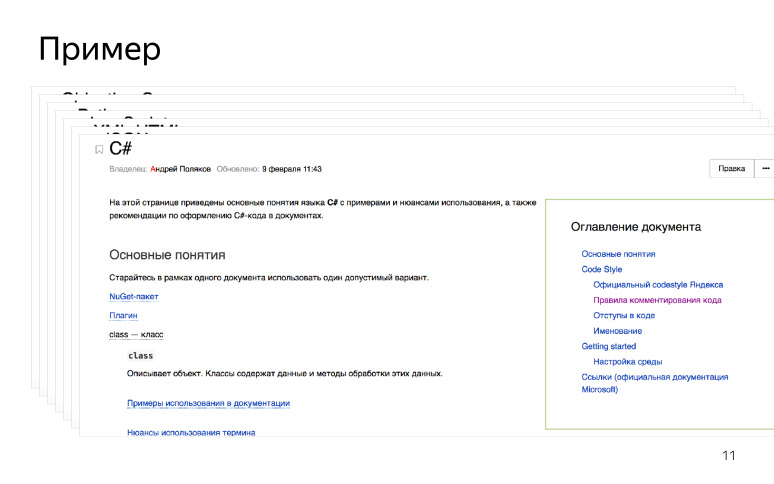
Lorsqu'un rédacteur technique arrive, il apprend une nouvelle technologie et commence à la documenter.
Après avoir décrit les technologies, nous avons ensuite décrit la structure de l'API HTTP.
Nous avons de nombreuses API HTTP différentes, et toutes sont décrites différemment. Faisons un accord et faisons de même!
Nous avons identifié les principales sections qui figureront dans chaque API HTTP:

«Présentation» ou «Introduction»: pourquoi cette API est-elle nécessaire, que vous permet-elle de faire, quel hôte doit être consulté pour obtenir une sorte de réponse.
«Démarrage rapide» lorsqu'une personne passe par certaines étapes et obtient un résultat réussi à la fin pour comprendre le fonctionnement de cette API.
"Connexion / Autorisation". De nombreuses API nécessitent un jeton d'autorisation ou une clé d'API. Ceci est un point important, nous avons donc décidé qu'il s'agissait d'une partie obligatoire de toutes les API.
«Limitations / Limites» lorsque nous parlons de limites sur le nombre de demandes ou sur la taille du corps de la demande, etc.
"Référence", référence. Une très grande partie, qui contient tous les descripteurs HTTP que l'utilisateur peut extraire et obtenir une sorte de résultat.
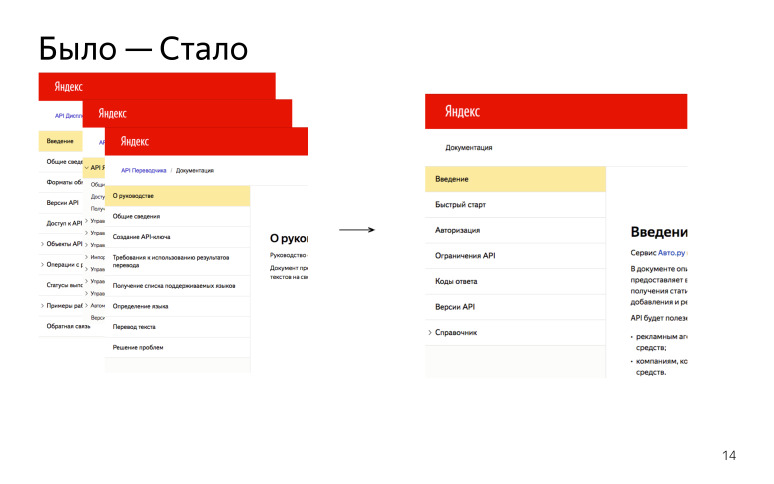
En conséquence, nous avions de nombreuses API différentes, elles étaient décrites différemment, maintenant nous essayons d'écrire tout de la même manière. Un tel profit.
En approfondissant les répertoires, nous avons réalisé que le descripteur HTTP est presque toujours le même. Vous le tirez, c'est-à-dire que vous faites une demande, le serveur renvoie une réponse - le tour est joué. Essayons de l'unifier. Nous avons écrit un modèle qui tentait de couvrir tous les cas. Le rédacteur technique prend le modèle et s'il a une demande PUT, il laisse les parties nécessaires dans le modèle. S'il a une demande GET, il utilise uniquement les parties nécessaires à la demande GET. Un modèle commun pour toutes les demandes qui peuvent être réutilisées. Maintenant, vous n'avez pas besoin de créer une structure de document à partir de zéro, mais vous pouvez simplement prendre le modèle fini.

Chaque stylo décrit à quoi il sert, à quoi il sert. Il y a une section «Format de demande», qui contient les paramètres de chemin, les paramètres de requête, tout ce qui vient dans le corps de la demande s'il est envoyé. Nous avons également mis en évidence la section «Format de réponse»: nous l'écrivons s'il existe un corps de réponse. Dans une section distincte, nous avons mis en évidence les «codes de réponse», car la réponse du serveur est indépendante du corps. Et quitté la section "Exemple". Si nous fournissons une sorte de SDK avec cette API, nous disons que utilisez ce SDK comme ceci, tirez une telle poignée, appelez une telle méthode. Habituellement, nous laissons une sorte d'exemple cURL où l'utilisateur insère simplement son jeton. Et si nous avons un banc de test, il prend simplement la demande et l'exécute. Et obtient une sorte de résultat.

Il s'avère qu'il y avait beaucoup de stylos, ils ont été décrits de différentes manières, et maintenant nous voulons tout rassembler sous une seule forme.
Après avoir terminé avec l'API HTTP, nous sommes passés au SDK mobile.
Il y a une structure générale de document, c'est à peu près la même:
- "Introduction", où nous disons que, ici, ce SDK est utilisé à de telles fins, intégrez-le pour vous-même à de telles fins, il convient à de tels systèmes d'exploitation, nous avons telle ou telle version, etc.
- «Connexion». Contrairement à l'API HTTP, nous ne parlons pas seulement comment obtenir la clé pour utiliser le SDK, si vous en avez besoin, nous parlons de la façon d'intégrer la bibliothèque dans notre projet.
- "Exemples d'utilisation." La plus grande section de volume. Le plus souvent, les développeurs veulent venir dans la documentation et ne pas lire beaucoup d'informations, ils veulent copier un morceau, le coller à eux-mêmes, et tout fonctionnera pour eux. Par conséquent, nous avons considéré cette partie comme très importante et l'avons affectée à la section obligatoire.

- «Répertoire», référence, mais contrairement à la référence de l'API HTTP, nous ne pouvons pas tout unifier ici, car nous générons principalement des répertoires et nous en parlerons plus loin dans le rapport.
- «Versions» ou modifier l'historique, changelog. Les SDK mobiles ont généralement un cycle de publication court, une nouvelle version est publiée toutes les deux semaines. Et il serait préférable pour l'utilisateur de parler de ce qui a changé, est-ce que cela vaut la peine de mettre à jour ou non.
Dans le même temps, l'API possède à la fois les sections requises que nous voyons et les sections que nous recommandons d'utiliser. Si l'API est mise à jour fréquemment, nous disons que vous insérez également l'historique des modifications, qui a changé dans l'API. Et souvent, nos API sont rarement mises à jour, et il est inutile de l'indiquer comme une section obligatoire.

Donc, nous avions beaucoup de SDK qui étaient décrits de différentes manières, nous avons essayé de les transformer approximativement dans le même style. Naturellement, il existe des différences supplémentaires inhérentes uniquement à ce SDK ou à cette API HTTP. Ici, nous avons la liberté de choix. Nous ne disons pas qu'en dehors de ces sections, personne ne peut être fait. Bien sûr, il est possible, nous essayons simplement de faire les sections répertoriées partout, afin qu'il soit clair que si l'utilisateur est passé à un autre SDK dans la documentation, il sait ce qui sera décrit dans la section "Connexion".
Donc, nous avons trouvé des modèles, des guides composés, quel est notre plan d'action maintenant? Nous avons décidé que si nous adaptons l'API, changeons les plumes ou changeons le SDK, nous prenons de nouveaux modèles, prenons une nouvelle structure et commençons à travailler dessus.
Si nous écrivons de la documentation à partir de zéro, alors, bien sûr, nous reprenons une nouvelle structure, prenons de nouveaux modèles et travaillons dessus.
Et si l'API est obsolète, rarement mise à jour ou que personne ne la prend en charge, mais qu'elle existe, refaites-la un peu en termes de ressources. Nous avons juste décidé de le laisser jusqu'à ce qu'il en soit ainsi, mais quand les ressources apparaîtront, nous y retournerons certainement, nous ferons tout cela bien et magnifiquement.
Quels sont les avantages de l'unification? Ils devraient être évidents pour tout le monde:
«UX», nous pensons faire en sorte que l'utilisateur se sente comme chez lui dans notre documentation. Il est venu et sait ce qui est décrit dans les sections où il peut trouver une autorisation, des exemples d'utilisation, une description du stylo. C'est super.
Pour les rédacteurs technologiques, la description de la technologie vous permet de déterminer un certain point d'entrée d'où il vient, et commence à se familiariser avec cette technologie, s'il ne la connaissait pas, commence à comprendre la terminologie, plongez-y.
Le point suivant est l'interchangeabilité. Si le rédacteur technique est parti en vacances ou a tout simplement arrêté d'écrire, un autre rédacteur technique, lors de la saisie du document, sait comment cela fonctionne à l'intérieur. Il est immédiatement clair ce qui est décrit dans la connexion, où chercher des informations sur l'intégration du SDK. Comprendre et faire une petite révision d'un document devient plus facile. Il est clair que chaque projet a ses spécificités, vous ne pouvez pas simplement venir documenter un projet sans le savoir complètement. Mais en même temps, la structure, c'est-à-dire la navigation dans les fichiers, sera à peu près la même.
Et, bien sûr, la terminologie générale. Cette terminologie que nous avons compilée pour les langues, nous avons convenu avec les développeurs et les traducteurs. Nous disons que nous avons C #, il existe un tel terme, nous l’utilisons de cette façon. Nous avons demandé aux développeurs quelle terminologie ils utilisaient et voulions réaliser la synchronisation à cet endroit. Nous avons des accords, et la prochaine fois que nous fournirons la documentation, les développeurs savent que nous avons convenu avec eux des conditions et des guides, nous utilisons ces modèles et prenons en compte les nuances de leur utilisation. Et les traducteurs, à leur tour, savent que nous décrivons le SDK en C # ou Objective-C, donc cette terminologie correspondra à ce qui est décrit dans le guide.
Les guides ont été écrits dans des pages wiki, donc si les langues, les technologies et les protocoles sont mis à jour, tout cela est facilement ajouté à un document existant. Idylle.
Plus tôt vous commencerez à vous unifier et à vous mettre d'accord, mieux ce sera. Il vaut mieux qu'il n'y ait alors aucun héritage de documentation, qui est écrite dans un style différent, ce qui rompt le flux de l'utilisateur dans la documentation. Mieux vaut tout faire plus tôt.
Attirez les développeurs. Ce sont les personnes pour lesquelles vous rédigez de la documentation. Si vous avez vous-même écrit une sorte de guides, peut-être qu'ils ne l'aimeront pas. Il vaut mieux être d'accord avec eux pour que vous ayez une compréhension commune de la terminologie: ce que vous écrivez dans la documentation, comment vous l'écrivez.
Et aussi négocier avec les traducteurs, ils doivent tous le traduire. S'ils traduisent différemment de ce à quoi les développeurs sont habitués, il y aura à nouveau des conflits. (
Voici un lien vers un fragment vidéo avec des questions et réponses - environ Ed.) Nous continuons.
Julia:
- Bonjour, je m'appelle Julia, je travaille chez Yandex depuis cinq ans et je documente l'API et le SDK dans le groupe d'Andrey. Habituellement, tout le monde parle d'une bonne expérience, de sa qualité. Je vais vous dire comment nous avons choisi une stratégie pas entièrement réussie. À cette époque, cela semblait réussi, mais une dure réalité est venue, et nous avons été un peu malchanceux.
Nous avions initialement plusieurs SDK mobiles, et ils ont été écrits principalement en deux langues: Objective-C et Java. Nous leur avons écrit de la documentation manuellement. Au fil du temps, les classes, les protocoles et les interfaces se sont développés. Il y en avait de plus en plus, et nous avons réalisé que nous avions besoin d'automatiser cette entreprise, nous avons examiné ce que sont les technologies.
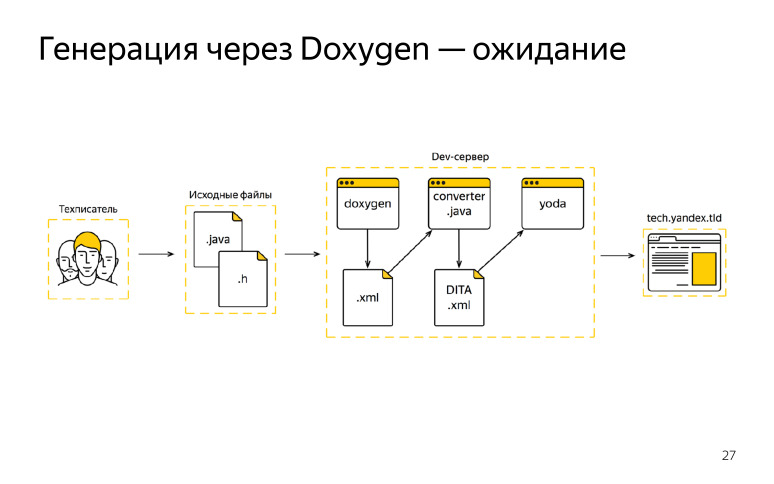
A cette époque, nous aimions Doxygen, il répondait à nos besoins, comme il nous a semblé, et nous l'avons choisi comme générateur unique. Et nous avons dessiné un tel schéma, que nous espérions obtenir, nous voulions y travailler d'une manière ou d'une autre.
Qu'avions-nous? Le rédacteur technique est venu travailler, a reçu le code source du développeur, a commencé à écrire ses commentaires, édite, après que la documentation devait être envoyée à notre devserver, là nous avons exécuté Doxygen, reçu le format XML, mais cela ne correspondait pas à notre norme XML DITA. Nous le savions à l'avance, a écrit un certain convertisseur.
Après avoir obtenu la sortie de Doxygen, nous l'avons transmise à travers le convertisseur et nous avons déjà obtenu notre format. Ensuite, le collecteur de documentation a été connecté, et nous avons publié tout cela sur un domaine externe. Nous avons même eu de la chance quelques itérations, tout a fonctionné pour nous, nous avons été ravis. Mais alors quelque chose s'est mal passé. Le rédacteur technique s'est également mis au travail, a reçu des tâches et des codes sources du développeur, et y a apporté ses corrections. Après cela, il est allé voir le devserver, a lancé Doxygen et il y a eu un incendie.
Nous avons décidé de découvrir quel était le problème. Ensuite, nous avons réalisé que Doxygen ne correspond pas tout à fait à toutes les langues. Nous avons dû analyser le code, sur lequel il est tombé, nous avons trouvé des constructions que Doxygen ne supportait pas et ne prévoyait pas de supporter.
Nous avons décidé, puisque nous travaillons dans ce schéma, nous allons écrire un script de prétraitement, et nous allons en quelque sorte remplacer ces constructions par ce que Doxygen accepte, ou en quelque sorte les ignorer.

Notre cycle a commencé à ressembler à ceci. Nous avons reçu les sources, les avons incluses sur le devserver, puis connecté le script de prétraitement, il a coupé tout le surplus du code, puis Doxygen est entré dans l'entreprise, nous avons reçu le format de sortie Doxygen, également lancé le convertisseur, reçu nos fichiers XML DITA finaux, puis le collecteur de documentation a été connecté, et Nous avons publié notre documentation sur un domaine externe. Il semble que tout semble bien. Ajout d'un script, qu'est-ce qu'il y a là-haut? Au départ, il n'y avait rien. Il y avait trois lignes dans le script, puis cinq, dix lignes, et le tout est passé à des centaines de lignes. Nous avons réalisé que nous commençons à passer la majeure partie de notre temps non pas à écrire de la documentation, mais à analyser le code, à chercher ce qui ne rampe pas où, et à simplement ajouter le script à d'innombrables habitués, à rester dans la folie et à réfléchir à ce qui se passe.
Nous avons réalisé que nous devions changer quelque chose, en quelque sorte arrêter, avant qu'il ne soit trop tard, et jusqu'à ce que notre cycle de sortie se termine.
Par exemple, le script de prétraitement ressemblait à quelque chose comme ça au début et était inoffensif.

Pourquoi avons-nous initialement choisi cette voie? Pourquoi semblait-il bon?

Un générateur est génial, l'a pris, l'a connecté une fois, l'a installé et cela fonctionne. Cela semblait être une bonne approche. De plus, vous pouvez utiliser une seule syntaxe de commentaire pour toutes les langues à la fois. Vous avez écrit une sorte de guide, l'utilisez une fois, insérez immédiatement toutes ces constructions dans le code et faites votre travail, écrivez des commentaires et ne vous attardez pas sur la syntaxe.

Mais cela s'est avéré être l'un des gros inconvénients. Les développeurs ne prenaient pas en charge notre syntaxe commune, ils étaient habitués à utiliser leurs IDE, il y avait déjà des générateurs natifs et leur syntaxe ne correspondait pas à la nôtre. C'était une pierre d'achoppement.
Doxygen a également mal pris en charge les nouvelles fonctionnalités dans les langues. Il a une approche sélective, puisqu'il est lui-même écrit en C ++, il supporte principalement les langages de type C, et le reste selon le principe résiduel. Et les langues sont en train d'être améliorées, Doxygen ne les suit pas tout à fait, et cela est devenu assez gênant pour nous.
Puis un malheur s'est produit. Une nouvelle équipe est venue vers nous et a dit que nous écrivions sur Swift, et Doxygen n'est pas du tout ami avec lui. Nous avons réalisé que tout est temps de s'arrêter et de trouver quelque chose de nouveau. Ensuite, quelques autres équipes sont venues et nous avons réalisé que notre programme ne pouvait pas être mis à l'échelle du tout. Et nous ajoutons constamment quelque chose, nous avons plusieurs de ces scripts, ils vivent dans différentes branches et c'est tout. Nous avons réalisé que nous devions accepter ce que nous n'avions pas de chance, essayer de nouvelles approches et solutions pour trouver. Andrey vous en parlera.
«Nous avons réalisé que dans notre cas, quelque part un générateur universel est apparu, mais pour la plupart, lorsque nous avons commencé à tout mettre à l'échelle, le plan n'a pas fonctionné. Ils sont venus calmement, ont convenu avec tout le monde que nous devons le faire, mais cela n'a pas fonctionné.
En conséquence, nous avons commencé à proposer un nouveau schéma. Elle était avec des générateurs natifs. Qu'avons-nous dans le circuit maintenant? ( , ), , Objective-C Java, , .
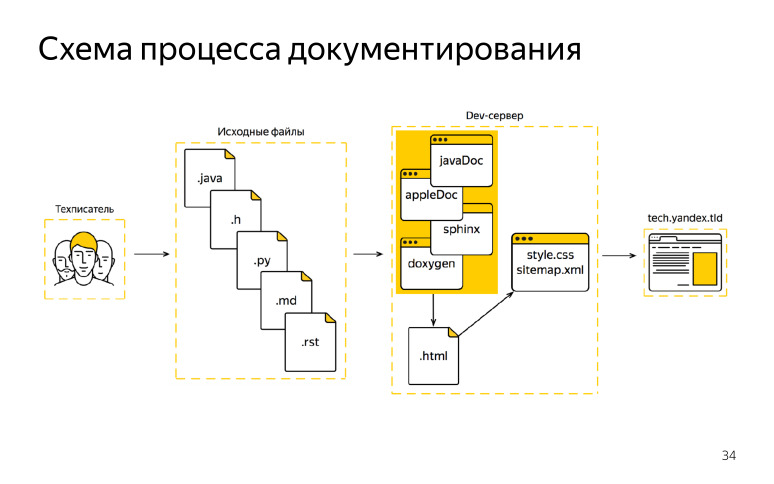
, DITA XML, , , , XML. HTML, . — JavaDoc, AppleDoc, Jazzy. HTML, . HTML, , . , HTML . , , , HTML, . XML , . .
.
— . Doxygen , , . Objective-C, , Java . . , , IDE , IntelliSense, , , , SDK, , . .
, , SDK , , , , HTML, . , , , , , .
. , - , . XML , XML . Doxygen , XML . HTML, XML . . — .
, , . 1500 , : HTML, CSS, .
, , .
. (
— . .)
, , .
— . , . -, . , . ? .
? -, , , , .
- , - , . .
? -, , , , .
. , , , , , , , .
, . , , , , , , .
? — , , , , , . . Bitbucket, - . , .

, . . - , - , , , , , , . , , , , .
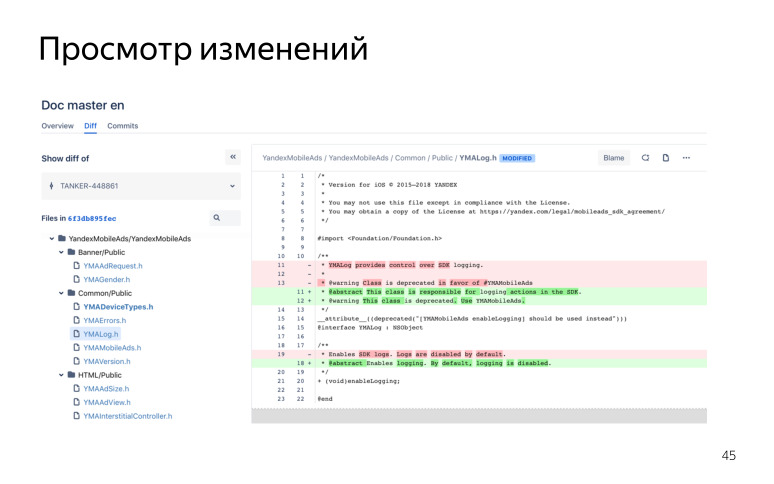
, , .
, SDK , - , , . -, , , , .
, . . — , , .
, . . .
, , , , , , .

, .
. - , . .

, , , , . . , , , - . , . , , .
, .
. , . , , .
, , , — . , , , .
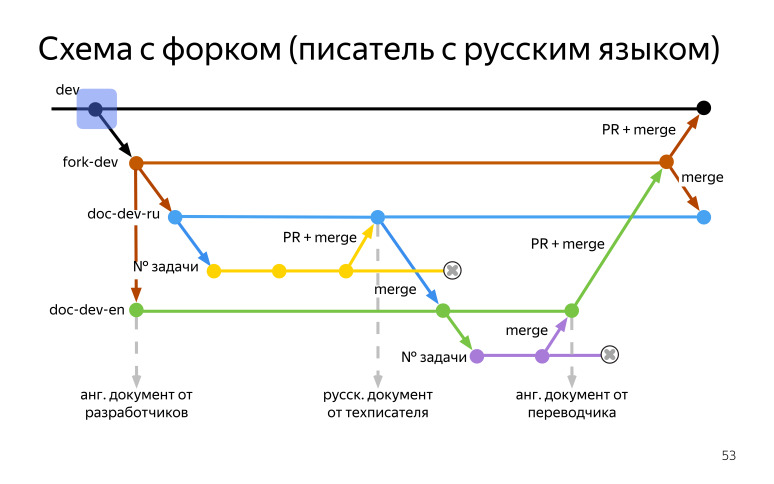
dev , (fork-dev) , . , doc-dev-en, . , , - , , .
(fork-dev) (doc-dev-ru) . , - . . , , doc-dev-ru, . , , - , .
, . (doc-dev-en). , , (doc-dev-en), , . , (fork-dev). , , , , . , , . , dev . , , , .
(fork-dev), , . (fork-dev), , (doc-dev-en), . , , , . , .

, , . dev, (fork-dev) , (doc-dev-ru) (doc-dev-en) . (doc-dev-en), (doc-dev-ru) . , .
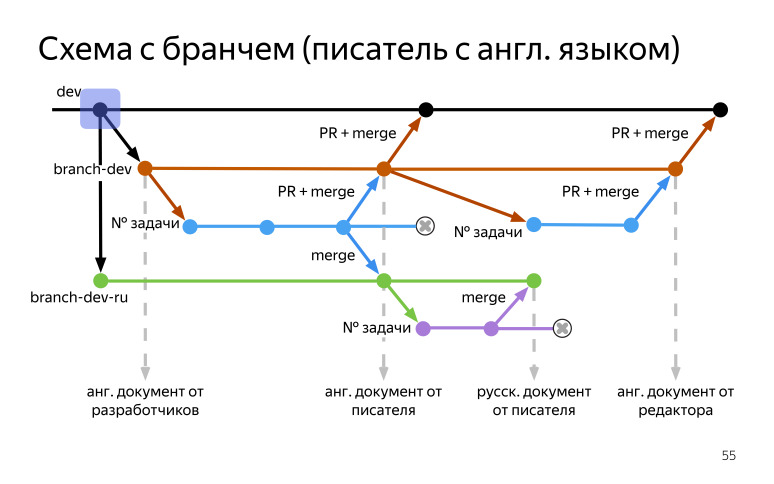
. dev , , (branch-dev). (branch-dev-ru), (branch-dev). , . , . — , — - , , , , .
, , . , , (branch-dev) . , , .
dev. , , , , . .
(branch-dev-ru), , (branch-dev-ru), . .
. (branch-dev), . , , , , , , , , . , , . , , .

, , , , . .
, ? , , . . . , - , . . , .
, , , , , .
, . . . . , , .
— — . — .
. . , . , , , , , , . .
, . . . . , . , . - , . — . .
. , : . , . : , , . , — , — . , — , . .