Mes merveilleux collègues du service d'assistance technique écrivent non seulement des conseils et des astuces utiles pour la configuration de Veeam Backup & Replication. Depuis la publication de l'
article pour les utilisateurs novices, son auteur, Evgeny Ivanov, tout en continuant à travailler avec l'équipe roumaine de Bucarest, est passé du poste d'ingénieur senior au poste de chef d'équipe. Mais Eugène n'a pas quitté le domaine technique et littéraire, dont un grand merci à lui!
Le nouvel article de Zhenya contient des recommandations pour les spécialistes Veeam Backup & Replication déjà expérimentés qui sont confrontés à la tâche de tirer le meilleur parti des ressources de l'infrastructure de sauvegarde. Cependant, l'article sera utile à ceux qui envisagent simplement d'installer et de configurer notre produit.
 Optimisation de la répartition de la charge en temps de tube chaud
Optimisation de la répartition de la charge en temps de tube chaudPour des conseils utiles, bienvenue au chat.
À propos des avantages d'une installation distribuée
Veeam Backup & Replication est un logiciel modulaire composé de divers composants, chacun remplissant des fonctions spécifiques. Parmi ces composants figurent le directeur général central du serveur de sauvegarde Veeam, du serveur proxy, du référentiel, de l'accélérateur WAN et autres. Un certain nombre de composants peuvent être installés sur une même machine (bien sûr, assez puissants), ce que font de nombreux utilisateurs. Cependant, une installation distribuée a ses avantages, à savoir:
- Pour les entreprises disposant d'un réseau d'agences, il devient possible d'installer localement les composants nécessaires dans ces agences. Cela permet d'optimiser le trafic, en réorganisant la majeure partie de celui-ci localement.
- À mesure que votre infrastructure se développe, vous devez faire évoluer votre solution de sauvegarde. Si la sauvegarde prend plus de temps (la «fenêtre de sauvegarde» s'agrandit), vous pouvez installer un serveur proxy supplémentaire. Si vous devez augmenter la capacité du référentiel de sauvegarde, vous pouvez configurer un référentiel de sauvegarde évolutif et ajouter de nouvelles extensions selon les besoins.
- Pour certains composants, vous pouvez garantir une disponibilité constante (haute disponibilité) - par exemple, si plusieurs serveurs proxy sont déployés et que l'un d'eux s'arrête soudainement, d'autres continueront de fonctionner et la sauvegarde ne sera pas affectée.
Il ne faut pas oublier que les systèmes distribués ne seront efficaces qu'avec une répartition de charge raisonnable. Sinon, des goulots d'étranglement peuvent survenir, une surcharge des composants individuels - et cela se traduit par une baisse générale de la productivité et un ralentissement.
Comment les données sont-elles transmises?
Pour avoir une idée plus claire de l'endroit et de l'endroit où les données sont transférées pendant le processus de sauvegarde, considérez ce diagramme (par exemple, prenez l'infrastructure sur la plate-forme vSphere):

Comme vous pouvez le voir, les données sont transférées de l'emplacement source (source) vers la cible (cible) à l'aide des "agents de transport" (VeeamAgent.exe) travaillant dans les deux emplacements. Ainsi, lorsque le travail de sauvegarde est en cours d'exécution, les événements suivants se produisent:
- L'agent de transport «source» s'exécute sur un serveur proxy; il lit les données d'une banque de données, effectue la compression et la déduplication et envoie les données sous cette forme à l'agent de transport «cible».
- L'agent de transport «cible» s'exécute directement sur le référentiel (Windows / Linux) ou sur la passerelle (serveur de passerelle), si le partage CIFS est utilisé. Cet agent, à son tour, effectue également une déduplication de son côté et enregistre les données dans un fichier de sauvegarde (.VBK, .VIB, etc.).
Ainsi, 2 composants sont toujours impliqués dans la transmission des données, même s'ils sont effectivement situés sur la même machine. Cela doit être pris en compte lors de la planification d'un déploiement de solution.
Équilibrage de charge entre le serveur proxy et le référentiel
Définissons d'abord le concept de «tâche». Dans la terminologie Veeam Backup & Replication, chaque tâche traite un disque d'une machine virtuelle. Autrement dit, si vous avez une tâche de sauvegarde (travail), qui comprend 5 machines virtuelles avec 2 disques chacune, cela signifie que vous devez traiter 10 tâches (et si la machine n'a qu'un seul disque, alors 1 tâche = 1 machine virtuelle). Veeam Backup & Replication est capable de traiter plusieurs tâches en parallèle, mais leur nombre, bien sûr, n'est pas infini.
Pour chaque serveur proxy dans ses propriétés, vous pouvez spécifier le nombre maximal de tâches à exécuter en parallèle:
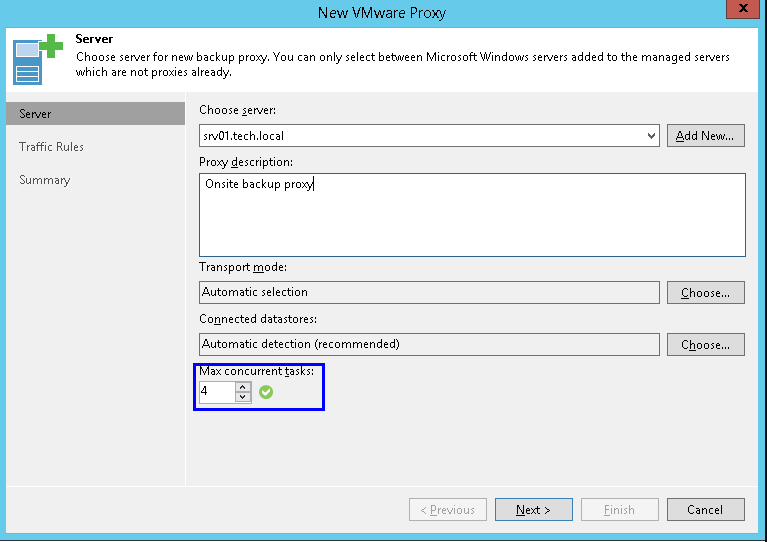
Pour les opérations de sauvegarde standard, la même interprétation sera celle du référentiel: une tâche consiste à transférer des données à partir d'un disque virtuel. Dans l'interface, cela ressemble beaucoup:

Ici, nous devons fixer une
règle très importante
n ° 1: assurez-vous d'équilibrer lors de l'affectation des ressources de proxy et de référentiel et lors de la spécification du nombre maximal de tâches pour le traitement parallèle!Exemple
Supposons que vous ayez 3 proxys, chacun pouvant traiter 4 tâches en parallèle (c'est-à-dire un total de 12 disques virtuels des machines virtuelles source). Mais le référentiel est configuré pour ne traiter que 4 tâches en parallèle (c'est d'ailleurs la valeur par défaut). Avec ces paramètres, seuls 4 lecteurs seront enregistrés en parallèle de l'emplacement source vers la destination, bien qu'ils puissent l'être pour les 12. Autrement dit, les ressources seront sous-chargées.
Cependant, lorsqu'il s'agit de créer une sauvegarde complète synthétique (et des opérations similaires), le concept d'une tâche relative au référentiel prend une signification légèrement différente. Nous nous souvenons que de telles opérations n'impliquent pas de proxy, mais sont effectuées localement sur le référentiel (Windows ou Linux) ou (dans le cas du partage CIFS) à l'aide d'une passerelle.
Dans cette option, lors de la création d'une chaîne de sauvegarde normale, tâche = tâche de sauvegarde. Autrement dit, une limite de 4 tâches pour le traitement parallèle ici signifie que des sauvegardes synthétiques pour 4 tâches de sauvegarde peuvent être créées simultanément sur le référentiel.
Lors de la création d'une chaîne de sauvegardes décomposées conformément aux machines virtuelles d'origine (ce que l'on appelle le «stockage par stockage» - par machine virtuelle), la tâche = 1 machine virtuelle. Autrement dit, une limite de 4 tâches pour le traitement parallèle ici signifie que 4 fichiers VBK pour 4 machines virtuelles peuvent être générés en même temps sur le référentiel.
Ainsi, nous arrivons à la
règle n ° 2: Selon les paramètres de sauvegarde, le même nombre de tâches peut signifier une charge complètement différente sur le référentiel. Par conséquent, lors de la planification des ressources, vous devez absolument vérifier ces mêmes paramètres: mode de sauvegarde, planification des tâches, façon d'organiser les chaînes de sauvegarde.Remarque: Contrairement aux paramètres de proxy, le référentiel peut désactiver la limite du nombre de tâches. Dans ce cas, le référentiel acceptera toutes les données provenant des serveurs proxy. Mais il ne s'agit que d'une apparente absence de restrictions, car il existe un risque de surcharge du référentiel et d'échecs dans le travail des tâches de sauvegarde. Par conséquent, nous déconseillons fortement d'abandonner cette limite.
Un autre exemple
Supposons que vous ayez une tâche de sauvegarde qui comprend un nombre assez important de machines virtuelles avec un total de 100 disques virtuels. Dans le même temps, le référentiel est configuré pour stocker les chaînes de sauvegarde «à la main» (par VM). Les paramètres de traitement parallèle sont les suivants: pour un proxy - 10 disques à la fois et pour un référentiel - il n'y a aucune restriction. Lors d'une sauvegarde incrémentielle, la charge sur le référentiel sera limitée en raison des paramètres du proxy, et donc l'équilibre sera maintenu. Mais vient le moment de créer une sauvegarde complète synthétique. Une telle sauvegarde n'utilise pas de proxy et toutes les opérations de création de «synthétiques» ont lieu exclusivement sur le référentiel. Puisqu'il n'y a aucune restriction sur le traitement parallèle des tâches pour le référentiel, le serveur de référentiel essaiera de traiter la centaine entière à la fois. Cela nécessitera un stress important sur les ressources et entraînera très probablement une surcharge.
Caractéristiques de l'utilisation du partage CIFS comme référentiel
Si vous travaillez avec un référentiel basé sur un serveur Windows ou Linux, l'agent «cible» démarre directement sur ce serveur. Cependant, si vous utilisez le dossier de partage CIFS (partage CIFS) comme référentiel, l'agent «cible» démarre sur une machine spécialement conçue à cet effet - c'est ce que l'on appelle «Passerelle», qui recevra le flux de données entrant de l'agent sur le côté de la machine virtuelle source. L'agent «cible» recevra ces données puis enverra des blocs de données à la balle CIFS. Cette machine auxiliaire doit être placée aussi près que possible de la machine qui fournit les dossiers partagés SMB - ceci est particulièrement important pour les scripts qui utilisent la connectivité WAN.
Règle numéro 3: vous ne devez pas placer la machine auxiliaire (proxy \ passerelle) sur un site et le dossier partagé CIFS sur un autre site (y compris sur le cloud) - sinon vous aurez des problèmes de réseau constants.Vous pouvez également appliquer aux passerelles toutes les considérations ci-dessus d'équilibrage de la charge sur le système. De plus, vous devez garder à l'esprit que la passerelle dispose de 2 paramètres supplémentaires: le serveur peut lui être affecté explicitement ou automatiquement sélectionné:

En principe, tout serveur Windows inclus dans l'infrastructure de sauvegarde Veeam peut être utilisé comme une telle passerelle. Selon votre scénario de déploiement, l'une des options peut vous convenir:
- Un serveur explicitement spécifié - cela, bien sûr, simplifie beaucoup, car vous saurez exactement sur quelle machine l'agent «cible» est exécuté. Cette option est recommandée, en particulier, dans les cas où l'accès à la balle n'est autorisé qu'à partir de certains serveurs, ainsi que pour les scénarios avec une infrastructure distribuée - vous souhaitez probablement utiliser l'agent sur une machine située à proximité du serveur de fichiers avec la cible en tant que personnes raisonnables le ballon.
- Serveur sélectionné automatiquement (option de sélection automatique ). Ici, l'entreprise prend une tournure intéressante: si vous utilisez plusieurs serveurs proxy, puis en choisissant cette option, il s'avère que le programme utilise plus d'une passerelle, répartissant la charge. Je note que «automatiquement» ne signifie pas «arbitrairement» - des règles de sélection tout à fait spécifiques sont appliquées ici.
Comment ça marche?
L'agent «cible» démarre sur le serveur proxy effectuant la sauvegarde.
- Dans le cas de la chaîne de sauvegarde habituelle, la logique est la suivante: si plusieurs tâches sont effectuées simultanément, chacune avec son propre serveur proxy, vous pouvez exécuter plusieurs agents "cibles". Cependant, au sein d'un même travail, la logique est différente: même si les machines virtuelles qu'il contient sont traitées par différents mandataires, l'agent «cible» ne sera lancé que sur un seul - sur celui qui commencera à fonctionner en premier.
- Dans le cas d'une chaîne de sauvegarde «chaîne», un agent «cible» distinct est lancé pour chaque machine virtuelle. Ainsi, même au sein d'une même tâche, la répartition de la charge se produit.
Lors de la création de sauvegardes synthétiques, les serveurs proxy ne sont pas utilisés, et ici la machine pour démarrer l'agent «cible» est sélectionnée comme suit: prenez un serveur de montage auxiliaire (serveur de montage sur lequel les fichiers sont montés, par exemple, pendant les opérations de récupération) associé au référentiel, et il démarre l'agent. Si le serveur de montage n'est pas disponible pour une raison quelconque, il est possible de basculer vers le nord de la sauvegarde Veeam. Comme vous le comprenez, il n'y aura pas de distribution de charge dans cette version.
Par conséquent, je répète: (
IMPORTANT! ) Il n'est pas recommandé pour de tels scénarios de supprimer la limite du nombre de tâches en cours de traitement en parallèle, car lors de l'exécution d'opérations avec des "synthétiques", cela peut entraîner une surcharge énorme du serveur de montage ou même du serveur de sauvegarde Veeam.
Fonctionnalités supplémentaires
Référentiel évolutif. SOBR est un ensemble de référentiels standard (ici, ils sont appelés "extents"). Si vous utilisez déjà SOBR, spécifiez-le dans la tâche de sauvegarde et non l'étendue. Sur l'étendue, vous pouvez utiliser certains paramètres, par exemple, l'équilibrage de charge.
Tous les principes de base qui fonctionnent pour les référentiels réguliers fonctionnent également pour SOBR. Pour optimiser l'utilisation des ressources, vous pouvez conseiller de configurer SOBR avec un stockage «crypto» des sauvegardes (par VM - c'est l'option par défaut), avec la politique de placement «Performance» («optimiser pour de meilleures performances») et la distribution en chaîne entre les référentiels-mesure-s.
Transfert de sauvegardes (copie de sauvegarde). Ici, les agents "source" travailleront sur le référentiel source. Tout ce qui est mentionné ci-dessus est également applicable aux référentiels source (à l'exception du fait que dans le cas d'un travail de transfert de job de copie de sauvegarde, les opérations avec des «synthétiques» ne sont pas effectuées sur le référentiel source).
Remarque: Si le référentiel source est un partage CIFS, l'agent "source" démarre sur le serveur de montage correspondant (avec la possibilité de basculer vers le serveur de sauvegarde Veeam).
Appareils avec déduplication intégrée. Pour les systèmes de stockage DataDomain et StoreOnce (et probablement pour d'autres à l'avenir), pour lesquels l'intégration avec Veeam est configurée, les mêmes considérations s'appliquent que pour le partage CIFS. Pour un référentiel sur StoreOnce avec déduplication côté source (mode
faible bande passante ), seule l'exigence de placer la passerelle aussi près que possible du référentiel perd de sa pertinence - la passerelle d'un site peut être configurée pour envoyer des données à StoreOnce sur un autre site via le WAN.
Serveur proxy préféré. Cette fonctionnalité est apparue, comme vous vous en souvenez, dans la version 9.5, et est responsable de la maintenance de la "liste de priorités de proxy" que le programme respectera lorsqu'il travaillera avec un référentiel spécifique.
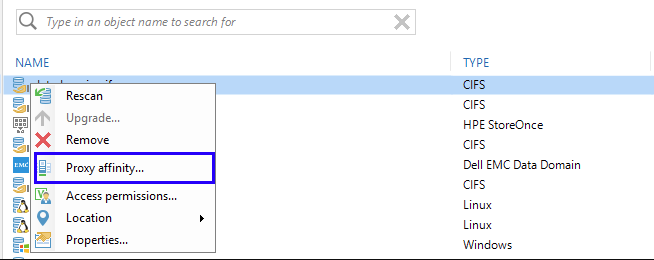
Si le proxy de cette liste n'est pas disponible, la tâche fonctionnera avec tout autre disponible. Cependant, s'il y a accès au proxy, mais que le serveur proxy n'a pas d'emplacements libres pour traiter la tâche, la tâche de sauvegarde sera suspendue en prévision de ceux-ci. Par conséquent, vous devez utiliser cette fonctionnalité très soigneusement (et non dans le style "activé et oublié") - nous avons eu des utilisateurs qui ont donc "raccroché" les tâches de sauvegarde. Vous pouvez en savoir plus sur la fonctionnalité
ici (en anglais).
En conclusion
Peu importe que vous installiez Veeam Backup & Replication pour la première fois ou que vous soyez un utilisateur de longue date - je veux croire que dans cet article, vous trouverez des informations qui vous seront utiles et qui aideront à optimiser le fonctionnement de l'infrastructure de sauvegarde ou même à éliminer les risques potentiels de perte de données. Voici quelques liens plus utiles: