Pourquoi certaines API sont-elles plus pratiques à utiliser que d'autres? Que pouvons-nous faire en tant que fournisseurs frontaux de notre côté pour travailler avec une API de qualité acceptable? Aujourd'hui, je parlerai aux lecteurs de Habr à la fois des options techniques et des mesures organisationnelles qui aideront les fournisseurs frontaux et principaux à trouver un langage commun et à établir un travail efficace.

Cet automne, Yandex.Market fête ses 18 ans. Pendant tout ce temps, l'interface d'affiliation du marché s'est développée. En bref, c'est le panneau d'administration avec lequel les magasins peuvent télécharger des catalogues, travailler avec l'assortiment, surveiller les statistiques, répondre aux avis, etc. Les spécificités du projet sont telles que vous devez beaucoup interagir avec différents backends. Cependant, les données ne peuvent pas toujours être obtenues en un seul endroit, à partir d'un backend spécifique.
Symptômes d'un problème
Alors, imaginez, il y avait une sorte de problème. Le gestionnaire confie la tâche aux concepteurs - ils dessinent la mise en page. Puis il va au back-end - ils font des
plumes et écrivent une liste de paramètres et le format de réponse sur le wiki interne.
Ensuite, le gestionnaire passe au front-end avec les mots «Je vous ai apporté l'API» et vous propose de tout scénariser rapidement, car, selon lui, presque tout le travail a déjà été fait.
Vous regardez la documentation et voyez ceci:
№ | ---------------------- 53 | feed_shoffed_id 54 | fesh 55 | filter-currency 56 | showVendors
Ne remarquez rien d'étrange? Camel, Snake and Kebab Case dans un seul stylo. Je ne parle pas du paramètre fesh. Qu'est-ce que le fesh? Un tel mot n'existe même pas. Essayez de deviner avant d'ouvrir le spoiler.
SpoilerFesh est un filtre par ID de magasin. Vous pouvez passer plusieurs identifiants séparés par des virgules. Un identifiant peut être précédé d'un signe moins, ce qui signifie que ce magasin doit être exclu des résultats.
En même temps, à partir de JavaSctipt, bien sûr, je ne peux pas accéder aux propriétés d'un tel objet via la notation en pointillés. Sans parler du fait que si vous avez plus de 50 paramètres à un endroit, alors, évidemment, dans votre vie, vous vous êtes tourné ailleurs.
Il existe de nombreuses options pour une API peu pratique. Un exemple classique - l'API recherche et renvoie des résultats:
result: [ {id: 1, name: 'IPhone 8'}, {id: 2, name: 'IPhone 8 Plus'}, {id: 3, name: 'IPhone X'}, ] result: {id: 1, name: 'IPhone 8'} result: null
Si les marchandises sont trouvées, nous obtenons un tableau. Si un produit est trouvé, nous obtenons un objet avec ce produit. Si rien n'est trouvé, alors au mieux, nous obtenons null. Dans le pire des cas, le backend répond avec 404 ou même 400 (Bad Request).
Les situations sont plus faciles. Par exemple, vous devez obtenir une liste de magasins dans un backend et stocker les paramètres dans un autre. Dans certains enclos, il n'y a pas assez de données, dans certaines données il y en a trop. Filtrer tout cela sur le client ou faire plusieurs requêtes ajax est une mauvaise idée.
Alors, quelles peuvent être les solutions à ce problème? Que pouvons-nous faire en tant que fournisseurs frontaux de notre côté pour travailler avec une API de qualité acceptable?
Backend frontend
Nous utilisons le client React / Redux dans l'interface partenaire. Sous le client se trouve Node.js, qui fait beaucoup de choses auxiliaires, par exemple, le jette sur la page InitialState pour les éditeurs. Si vous avez un rendu côté serveur, peu importe avec quelle infrastructure client, il est très probable qu'il soit rendu par un nœud. Mais que se passe-t-il si vous allez plus loin et que vous ne contactez pas directement le client dans le backend, mais que vous créez votre API proxy sur le nœud, au maximum adaptée aux besoins du client?
Cette technique est appelée BFF (Backend For Frontend). Ce terme a été introduit pour la première fois par SoundCloud en 2015, et l'idée peut être schématisée comme suit:
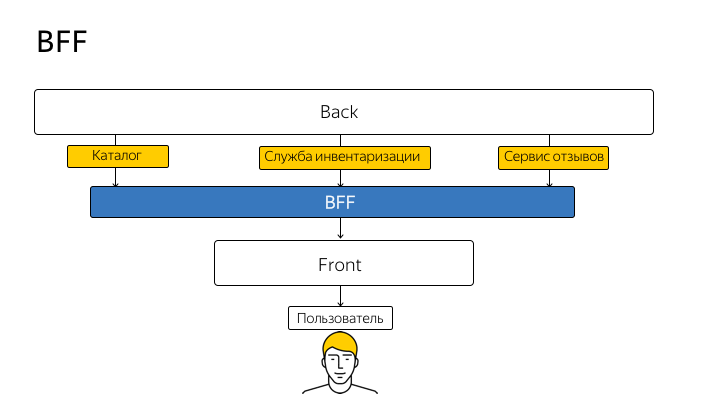
Ainsi, vous arrêtez de passer du code client directement à l'API. Chaque poignée, chaque méthode de la véritable API que vous dupliquez sur le nœud et du client va exclusivement au nœud. Et le nœud envoie déjà la requête par procuration à la véritable API et vous renvoie une réponse.
Cela s'applique non seulement aux requêtes get primitives, mais généralement à toutes les requêtes, y compris avec les données en plusieurs parties / formulaires. Par exemple, un magasin télécharge un fichier .xls avec son catalogue via un formulaire sur un site. Ainsi, dans cette implémentation, le répertoire n'est pas chargé directement dans l'API, mais dans votre handle Nod, qui procède à un streaming vers un véritable backend.
Vous vous souvenez de cet exemple avec résultat lorsque le backend a retourné null, un tableau ou un objet? Maintenant, nous pouvons le ramener à la normale - quelque chose comme ceci:
function getItems (response) { if (isNull(response)) return [] if (isObject(response)) return [response] return response }
Ce code a l'air horrible. Parce qu'il est terrible. Mais nous devons encore le faire. Nous avons le choix: faites-le sur le serveur ou sur le client. Je choisis un serveur.
Nous pouvons également mapper tous ces cas de kebab et de serpent dans un style qui nous convient et immédiatement mettre la valeur par défaut si nécessaire.
query: { 'feed_shoffer_id': 'feedShofferId', 'pi-from': 'piFrom', 'show-urls': ({showUrls = 'offercard'}) => showUrls, }
Quels autres avantages obtenons-nous?
- Filtrage . Le client ne reçoit que ce dont il a besoin, ni plus, ni moins.
- Agrégation Pas besoin de gaspiller le réseau client et la batterie pour faire plusieurs demandes ajax. Un gain de vitesse notable dû au fait que l'ouverture d'une connexion est une opération coûteuse.
- Mise en cache Votre appel groupé répété n'attirera plus personne, mais renvoie simplement 304 Non modifié.
- Masquage des données. Par exemple, vous pouvez avoir des jetons nécessaires entre les backends et ne pas aller au client. Le client peut ne pas avoir le droit de connaître l'existence de ces jetons, sans parler de leur contenu.
- Microservices . Si vous avez un monolithe à l'arrière, alors BFF est la première étape des microservices.
Maintenant sur les inconvénients.
- Difficulté croissante. Toute abstraction est une autre couche qui doit être codée, déployée, prise en charge. Une autre partie mobile du mécanisme qui peut échouer.
- Duplication des poignées. Par exemple, plusieurs points de terminaison peuvent effectuer le même type d'agrégation.
- BFF est une couche limite qui doit prendre en charge le routage général, les restrictions des droits des utilisateurs, la journalisation des requêtes, etc.
Pour niveler ces inconvénients, il suffit d'adhérer à des règles simples. La première consiste à séparer la logique frontale et la logique métier. Votre BFF ne doit pas modifier la logique métier de l'API principale. Deuxièmement, votre couche ne doit convertir les données qu'en cas de nécessité absolue. Nous ne parlons pas d'une API complète et autonome, mais uniquement d'un proxy qui comble le vide et corrige les failles du backend.
GraphQL
GraphQL résout des problèmes similaires. Avec GraphQL, au lieu de nombreux points de terminaison «stupides», vous disposez d'un stylet intelligent qui peut travailler avec des requêtes complexes et générer des données sous la forme dans laquelle le client le demande.
Dans le même temps, GraphQL peut fonctionner au-dessus de REST, c'est-à-dire que la source de données n'est pas la base de données, mais l'API de repos. En raison de la nature déclarative de GraphQL, du fait que tout cela est ami avec React et Editors, votre client devient plus facile.
En fait, je vois GraphQL comme une implémentation de BFF avec son protocole et son langage de requête strict.
C'est une excellente solution, mais elle présente plusieurs inconvénients, en particulier avec la typification, la différenciation des droits, et en général c'est une approche relativement nouvelle. Par conséquent, nous n'y sommes pas encore passés, mais à l'avenir, il me semble que le moyen le plus optimal pour créer une API.
Meilleurs amis pour toujours
Aucune solution technique ne fonctionnera correctement sans changements organisationnels. Vous avez toujours besoin de documentation, de garanties que le format de réponse ne changera pas subitement, etc.
Il faut comprendre que nous sommes tous dans le même bateau. Pour un client abstrait, que ce soit un manager ou votre manager, cela ne fait aucune différence - vous avez GraphQL ou BFF. Il est plus important pour lui que le problème soit résolu et que les erreurs n'apparaissent pas sur le prod. Pour lui, il n'y a pas beaucoup de différence en raison de la faute à laquelle une erreur s'est produite dans le produit - par la faute de l'avant ou de l'arrière. Par conséquent, vous devez négocier avec les backders.
De plus, les défauts dans le dos dont j'ai parlé au début du rapport ne se produisent pas toujours en raison des actions malveillantes de quelqu'un. Il est possible que le paramètre fesh ait également une signification.

Faites attention à la date du commit. Il s'avère que fesh a récemment célébré son dix-septième anniversaire.
Vous voyez des identifiants étranges sur la gauche? C'est SVN, simplement parce qu'il n'y avait pas de gita en 2001. Pas un github en tant que service, mais un github en tant que système de contrôle de version. Il n'est apparu qu'en 2005.
La documentation
Donc, tout ce dont nous avons besoin n'est pas de nous disputer avec le back-end, mais d'être d'accord. Cela ne peut être fait que si nous trouvons une seule source de vérité. Cette source devrait être la documentation.
La chose la plus importante ici est d'écrire de la documentation avant de commencer à travailler sur les fonctionnalités. Comme pour un accord prénuptial, il vaut mieux se mettre d'accord sur tout sur le rivage.
Comment ça marche? Relativement parlant, trois vont: manager, front-end et back-end. Fronteder connaît bien le sujet, sa participation est donc d'une importance cruciale. Ils se réunissent et commencent à réfléchir à l'API: de quelles manières, quelles réponses doivent être retournées, jusqu'au nom et au format des champs.
Swagger
Une bonne option pour la documentation de l'API est le format Swagger , maintenant appelé OpenAPI. Il est préférable d'utiliser Swagger au format YAML, car, contrairement à JSON, il est mieux lu par les humains, mais il n'y a pas de différence pour la machine.
Par conséquent, tous les accords sont fixés au format Swagger et publiés dans un référentiel commun. La documentation du backend de vente doit être dans l'assistant.
Le maître est protégé contre les validations, le code n'y entre que via le pool de requêtes, vous ne pouvez pas le pousser. Le représentant de l'équipe de front est obligé de procéder à un examen du pool de demandes, sans sa mise à niveau le code ne va pas au maître. Cela vous protège des modifications inattendues de l'API sans préavis.
Alors vous vous êtes réunis, a écrit Swagger, donc vous avez signé le contrat. A partir de ce moment, vous en tant que front-end pouvez commencer votre travail sans attendre la création d'une véritable API. Après tout, quel était le point de séparation entre le client et le serveur, si nous ne pouvons pas travailler en parallèle et que les développeurs clients doivent attendre les développeurs de serveurs? Si nous avons un «contrat», nous pouvons paralléliser cette question en toute sécurité.
Faker.js
Faker est idéal à ces fins. Il s'agit d'une bibliothèque pour générer une énorme quantité de fausses données. Il peut générer différents types de données: dates, noms, adresses, etc., tout cela est bien localisé, il y a un support pour la langue russe.
En même temps, le truqueur est ami avec le fanfaron, et vous pouvez tranquillement lever le serveur Mock, qui, basé sur le schéma Swagger, vous générera de fausses réponses le long des chemins nécessaires.
Validation
Swagger peut être converti en schéma json, et à l'aide d'outils comme ajv, vous pouvez valider les réponses du backend directement dans le runtime, dans votre BFF, et signaler les testeurs, les backenders eux-mêmes, en cas de divergences, etc.
Supposons qu'un testeur trouve une sorte de bogue sur le site, par exemple, lorsqu'un bouton est cliqué, rien ne se passe. Que fait le testeur? Il met un ticket sur le front-end: "c'est ton bouton, il n'est pas pressé, répare-le."
S'il y a un validateur entre vous et l'arrière, le testeur saura que le bouton est réellement enfoncé, seul le backend envoie la mauvaise réponse. Faux - c'est une réponse à laquelle le front ne s'attend pas, c'est-à-dire qu'il ne correspond pas au «contrat». Et ici, il est déjà nécessaire de réparer le dos ou de modifier le contrat.
Conclusions
- Nous sommes activement impliqués dans la conception de l'API. Nous concevons l'API de manière à ce qu'elle soit pratique à utiliser après 17 ans.
- Nous avons besoin de la documentation Swagger. Aucune documentation - l'opération principale n'a pas été terminée.
- Il existe de la documentation - nous la publions dans git, et toute modification de l'API doit être mise à jour par le représentant de l'équipe de front.
- Nous élevons le faux serveur et commençons à travailler sur le front sans attendre la vraie API.
- Nous plaçons le nœud sous le frontend et validons toutes les réponses. De plus, nous avons la possibilité d'agréger, de normaliser et de mettre en cache les données.
Voir aussi
→ Comment construire une API de type REST dans un grand projet
→ Backend dans le frontend
→ Utilisation de GraphQL comme implémentation de modèle BFF