Il s'agit d'un didacticiel de la bibliothèque TensorFlow. Considérez-le un peu plus profondément que dans les articles sur la reconnaissance des nombres manuscrits. Ceci est un tutoriel sur les méthodes d'optimisation. Ici, vous ne pouvez pas vous passer des mathématiques. Ce n'est pas grave si vous l'avez complètement oublié. Rappel. Il n'y aura pas de preuves formelles et de conclusions complexes, seulement le minimum nécessaire pour une compréhension intuitive. Pour commencer, un petit aperçu de la façon dont cet algorithme peut être utile pour optimiser un réseau de neurones.

Il y a six mois, un ami m'a demandé de montrer comment créer un réseau neuronal en Python. Sa société produit des instruments de mesures géophysiques. Plusieurs sondes différentes lors du forage mesurent un ensemble de signaux associés aux paramètres de l'environnement entourant le puits. Dans certains cas complexes, calculez avec précision les paramètres environnementaux à partir de signaux pendant une longue période, même sur un ordinateur puissant, et il est nécessaire d'interpréter les résultats de mesure sur le terrain. Il y avait une idée de compter plusieurs centaines de milliers de cas sur un cluster, et de former un réseau neuronal sur eux. Le réseau neuronal étant très rapide, il peut être utilisé pour déterminer des paramètres cohérents avec les signaux mesurés, en plein processus de forage. Les détails sont dans l'article:
Kushnir, D., Velker, N., Bondarenko, A., Dyatlov, G., et Dashevsky, Y. (2018, 29 octobre). Simulation en temps réel de l'outil de résistivité azimutale profonde dans un modèle de défaut 2D à l'aide de réseaux de neurones (russe). Société des ingénieurs pétroliers. doi: 10.2118 / 192573-RU
Un soir, j'ai montré comment les keras pouvaient implémenter un réseau neuronal simple, et un ami au travail a commencé à s'entraîner sur les données comptées. Après quelques jours, nous avons discuté du résultat. De mon point de vue, il avait l'air prometteur, mais un ami a dit qu'il avait besoin de calculs avec la précision de l'appareil. Et si l' erreur quadratique moyenne s'est avérée être d'environ 1, alors 1e-3 était nécessaire. 3 commandes de moins. Mille fois.
Les expériences avec l'architecture des réseaux de neurones, la normalisation des données et les approches d'optimisation n'ont donné presque rien. Quelques semaines plus tard, un ami a appelé et a dit qu'il avait installé MatLab et avait résolu le problème par la méthode Levenberg-Marquardt (ci-après nous appellerons LM ). Il a été optimisé pendant longtemps (plusieurs jours), il n'a pas fonctionné sur le GPU, mais le résultat était le bon. Cela ressemblait à un défi.
Une recherche rapide d'un optimiseur LM prêt à l'emploi pour les kéros ou TensorFlow a échoué. Je ne suis tombé que sur la bibliothèque pyrenn, mais sa fonctionnalité me semblait médiocre. J'ai décidé de le mettre en œuvre moi-même. À première vue, tout avait l'air simple et deux soirées auraient dû suffire. Cela a pris plus de temps. Il y avait deux problèmes:
- TensorFlow. Un tas d'articles, mais presque tous les niveaux "mais écrivons
bonjour la reconnaissance des chiffres manuscrits du monde ." - Math J'ai beaucoup oublié, et les auteurs d'articles mathématiques ne se soucient pas du tout de gens comme moi: des formules solides sans explication, "évidemment!" et ainsi de suite.
En conséquence, il a écrit un article pour ceux qui ont oublié les mathématiques et veulent comprendre TensorFlow un peu plus profondément, mais sans hardcore. L'article contient beaucoup de texte et peu de code. L'option opposée, lorsqu'il y a peu de texte et beaucoup de code, est ici Jupyter Notebook Levenberg-Marquardt .
Découvrez la fonction Rosenbrock
Nous générerons des données d'entraînement par la fonction Rosenbrock , qui est souvent utilisée comme référence pour les algorithmes d'optimisation:
f ( x , y ) = ( a - x ) 2 + b ( y - x 2 ) 2
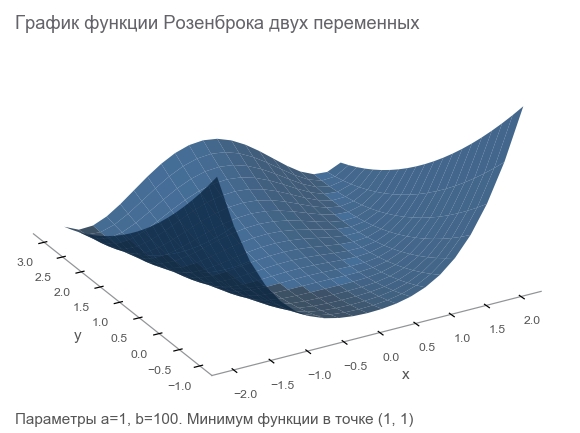
Pourquoi est-elle bonne?
- Beau programme. On l'appelle la vallée de Rosenbrock et la fonction banane de Rosenbrock intraduisible.
- Le minimum global se situe à l'intérieur d'une longue vallée plate parabolique et étroite. Trouver une vallée est trivial et un minimum global est difficile.
- Il existe une option multidimensionnelle. Trouver une bonne fonction pour de nombreuses variables n'est pas si simple.
Nous allons commencer à en écrire du code en connectant les bibliothèques nécessaires à la poursuite des travaux:
import numpy as np import tensorflow as tf import math def rosenbrock(x, y, a, b): return (a - x)**2 + b*(y - x**2)**2
Nous énonçons le problème
Puisque nous parlions d'un appareil de mesure, continuons à utiliser l'analogie. Notre appareil dans un monde fictif peut mesurer des coordonnées ( x , y ) et hauteur z . Les physiciens ont étudié le monde et ont dit: " Oui, c'est Rosenbrock! Connaissant les coordonnées, vous pouvez calculer avec précision la hauteur, vous n'avez pas besoin de la mesurer. ". En d'autres termes, les scientifiques nous ont donné un modèle z = r o s i e r ( x , y , a , b ) qui dépend des paramètres ( a , b ) . Ces paramètres, bien que constants dans un monde fictif, sont inconnus. Ils doivent être trouvés.
Nous avons mené une série d'expériences qui ont donné m des points (x1,y1,z1),(x2,y2,z2),...,(xm,ym,zm) :
La première façon d'optimiser est d'essayer de deviner les paramètres. Nous utilisons la bibliothèque Numpy:
x, y = data_points[:, 0], data_points[:, 1] z = data_points[:, 2]
Comment comprendre à quel point nous avons tort? Compter les résidus - tailles d'erreur. m les points donnent m résidus - vous avez besoin d'un indicateur intégré. Nous plaçons chaque résidu dans un carré et calculons la moyenne:
MSE(a,b)= frac1m summi=1(zi− widehatzi)2
Cette mesure de proximité est appelée l' erreur quadratique moyenne (ci-après dénommée mse ):
[Out]: 3868.2291666666665
En minimisant mse , nous résolvons le problème des moindres carrés ( minimisation des carrés non linéaires ):
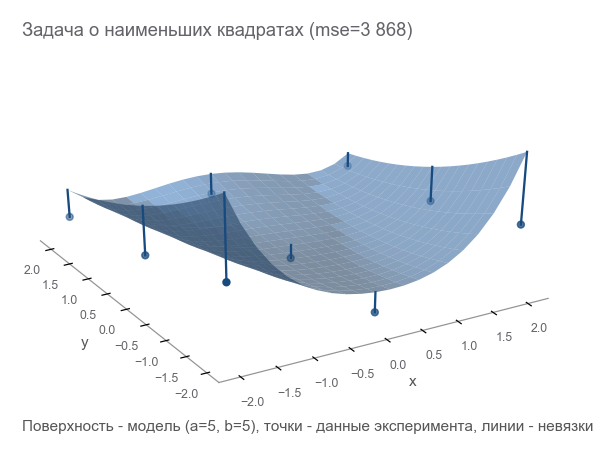
On peut voir que les paramètres ne devinaient pas du tout.
Nous formulons le problème sur TensorFlow
Le modèle a la forme z=rosier(x,y,a,b) . Nous le portons au formulaire y=f(x,p) (généralement les maths écrivent beta au lieu de p mais les programmeurs n'utilisent pas la version bêta). Maintenant, le modèle a la forme y=rosier(x,p) où y - hauteur x Est le vecteur de coordonnées de deux éléments (composant), et p - vecteur de paramètres.
Les programmeurs considèrent souvent les vecteurs comme des tableaux unidimensionnels. Ce n'est pas tout à fait correct. Un tableau de nombres est un moyen de représenter un vecteur. Vous pouvez représenter un vecteur comme un tableau de dimension N , tableau bidimensionnel 1 foisN , et même un tableau N fois1 dans les cas où le fait que le vecteur soit un vecteur colonne (par exemple, pour multiplier une matrice par lui) est important:
beginbmatrixx1 vdotsxN endbmatrix
TensorFlow utilise le concept de tenseur . Un tenseur , comme un tableau, peut être unidimensionnel (pour représenter un vecteur ), bidimensionnel (pour un vecteur de matrice ou de colonne ) et n'importe quelle dimension plus grande.
Le code TensorFlow n'est pas différent dans sa forme du code Numpy. Le contenu est énorme. Le code Numpy calcule la valeur mse. Le code TensorFlow n'effectue aucun calcul, il forme un graphique de flux de données que mse peut calculer . Un moment très tolérant au cerveau est le travail de la fonction rosenbrock . Nous l'utilisons dans les deux cas. Mais lorsque nous passons les tableaux Numpy, il effectue les calculs selon la formule et renvoie les nombres. Et lorsque nous transférons les tenseurs vers TensorFlow, il forme un sous - graphique du flux de données et renvoie son bord sous la forme d'un tenseur. Miracles du polymorphisme, mais n'en abusez pas:
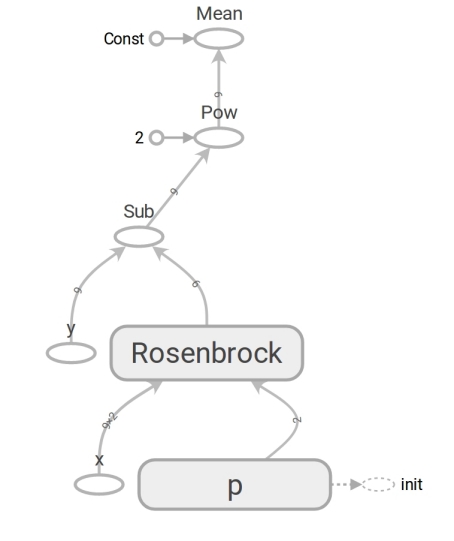
Grâce à la présence d'un tel graphe de flux de données, TensorFlow en particulier est capable de calculer automatiquement des dérivées (en utilisant la technique de différenciation automatique en mode inverse ).
Un moment de maths. Les blocs "pour ceux qui ont oublié" seront cachés dans un spoiler.
Dérivée (nombre entré - nombre restant)Vous vous souvenez très probablement de la définition de la dérivée d'une fonction scalaire (renvoyant un nombre) d'une variable: pour f: mathbbR rightarrow mathbbR dérivé f au point x in mathbbR défini comme:
f′(x)= limh to0 fracf(x+h)−f(x)h
Les dérivés sont un moyen de mesurer le changement . Dans le cas scalaire, la dérivée montre à quel point la fonction va changer f si x passer à une petite valeur varepsilon :
f(x+ varepsilon) environf(x)+ varepsilonf′(x)
Pour plus de commodité, nous désignons y=f(x) et le dérivé y par x nous écrirons comment frac partialy partialx . Un tel dossier souligne que frac partialy partialx - taux de variation entre les variables x et y . Plus précisément, si x changer pour varepsilon alors y passer à environ varepsilon frac partialy partialx . Vous pouvez également l'écrire comme ceci:
x rightarrowx+ Deltax Rightarrowy rightarrow approxy+ frac partialy partialx Deltax
Lit comme: "changer x sur x+ Deltax changer y à environ y+ Deltax frac partialy partialx ". Un tel record met clairement en évidence le lien entre le changement x et changer y .
Nous avons construit un graphique de flux de données, exécutons le calcul mse:
[Out]: 3868.2291666666665
Le résultat est le même qu'avec Numpy. Ils ne se sont donc pas trompés.
Commencez à optimiser
Malheureusement, il n'a pas été possible de deviner les paramètres. Mais alors nous:
- Nous fixons le critère d'optimalité - la valeur minimale de mse.
- Des paramètres variables ont été déterminés: vecteur p avec composants a , b Fonctions de Rosenbrock.
- Nous n'avons pas encore pensé aux limitations, mais elles ne sont pas là.
Dans la dernière étape, nous avons construit un graphe de flux de données avec un tenseur de perte finie ( fonction de perte ). Le but de l'optimisation est de trouver la valeur du vecteur paramètre p à laquelle la valeur de la fonction de perte est minimale. Nous avons eu de la chance, le graphe de cette fonction est très simple (concave et sans minima local):
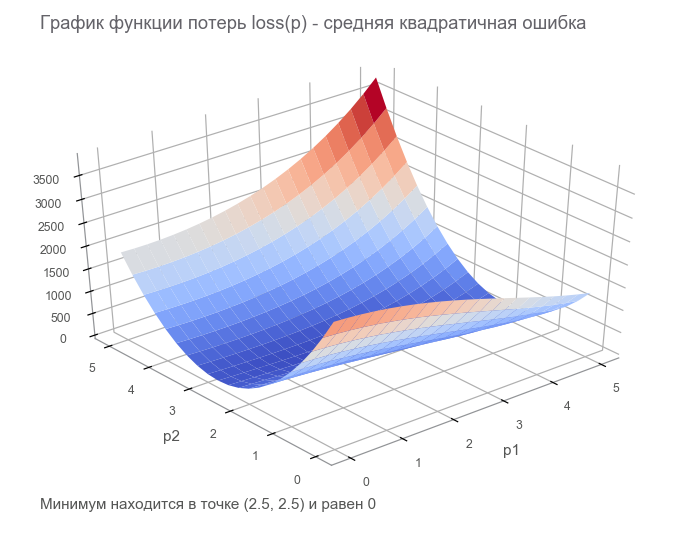
Débuter avec l'optimisation. Pour commencer, nous écrivons un cycle généralisé:
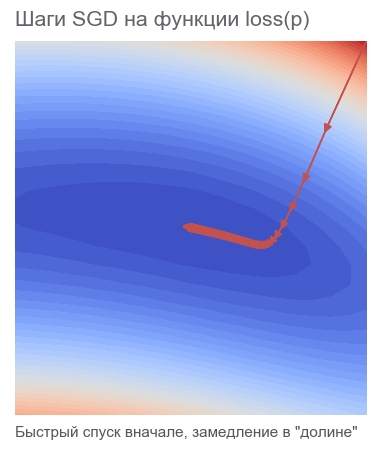
Nous optimisons par la méthode de la descente de gradient la plus rapide (SGD)
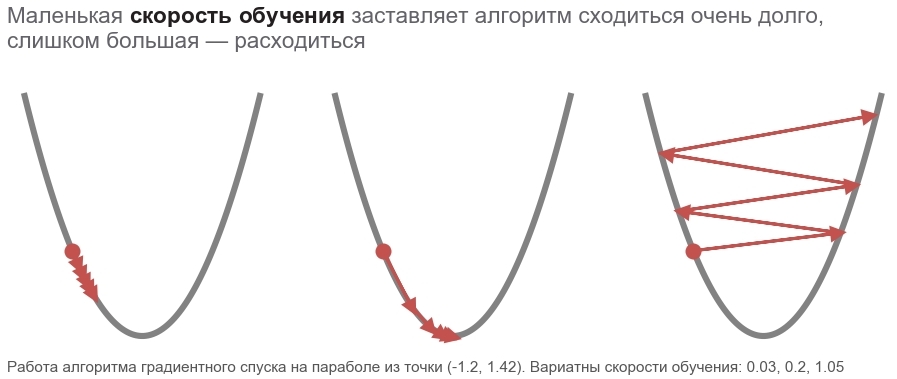
Les actions de cette méthode peuvent être comparées à la conduite d'un skieur audacieux, qui descend toujours la pente (dans la direction la plus raide). Dans ce cas, seule la pente au point de localisation est prise en compte. Et si la pente est forte, le skieur vole sur une longue distance avant le prochain changement. Avec une faible pente, il se déplace par petites étapes. Peut-être comment s'envoler dans un arbre (l' algorithme diverge ), et se coincer dans une fosse ( minimum local ).

Vous pouvez écrire comme suit (changer boldsymbolp sur boldsymbolp−... ):
boldsymbolp rightarrow boldsymbolp− alpha[ nablapperte( boldsymbolp)]
Grasse boldsymbolp souligne qu'il s'agit du point de localisation réel - la valeur du vecteur de paramètre à l'étape actuelle. À la première étape, c'est notre supposition (5, 5). Il y a deux points intéressants dans la formule: alpha - taux d'apprentissage ( taux d'apprentissage ), nablapperte - gradient ( gradient ) de la fonction de perte par le vecteur de paramètres.
Dégradé (vecteur entré - nombre à gauche)Considérons une fonction qui prend un vecteur en entrée et produit un scalaire: f: mathbbRN rightarrow mathbbR . Dérivé f au point x in mathbbRN maintenant appelé gradient et est un vecteur [ nablaxf(x)] in mathbbRN (lu comme "nabla") composé de dérivées partielles :
nablaxy=( frac partialy partialx1, frac partialy partialx2,..., frac partialy partielxN)
Pour ce cas, l'enregistrement de la dépendance du changement de fonction sur le changement d'argument a la forme suivante:
x rightarrowx+ Deltax Rightarrowy rightarrow approxy+ nablaxy cdot Deltax
Le dossier a beaucoup changé pour tenir compte du fait que x , Deltax et nablaxy - vecteurs en mathbbRN et y - scalaire. Lors de la multiplication des vecteurs nablaxy et Deltax le produit scalaire est utilisé (la somme des produits des composants).
[Out]: step: 1, current loss: 3868.2291666666665 step: 2, current loss: 1381.5379689135807 [...] ENDED ON STEP: 582, FINAL LOSS: 9.698531012270816e-11 PARAMETERS: [2.50000205 2.49999959]
Il a fallu 582 étapes:
Mouvement dans le sens de l'anti-gradientPourquoi allons-nous dans la direction opposée au gradient? Rappelez l'entrée avec le produit scalaire: x rightarrowx+ Deltax Rightarrowy rightarrow approxy+ nablaxy cdot Deltax . Minimiser y . Étant donné que le comportement de la fonction n'est connu que dans un petit voisinage à travers la dérivée, il est nécessaire de se déplacer par petites étapes, mais optimales, en minimisant le produit nablaxy cdot Deltax . Par définition scolaire, le produit scalaire de deux vecteurs est le nombre égal au produit des longueurs de ces vecteurs par le cosinus de l'angle entre eux : a cdotb= gauche|a droite| gauche|b droite|cos angle(a,b) . Pour une longueur fixe de vecteurs, ce produit atteint un minimum avec un cosinus de -1, c'est-à-dire à un angle de 180 degrés, lorsque les vecteurs sont dirigés dans des directions opposées. En conséquence, le produit scalaire minimum nablaxy cdot Deltax atteint lorsque Deltax dans le sens de l' anti-gradient .
Nous optimisons par la méthode Adam
Nous n'irons pas plus loin dans les méthodes de gradient, mais il existe de nombreuses variantes. Vous pouvez les lire dans l'article Méthodes d'optimisation des réseaux de neurones . Dans TensorFlow, de nombreux optimiseurs sont déjà implémentés. Par exemple, Adam:
[Out]: step: 1, current loss: 3868.2291666666665 step: 2, current loss: 34205.72916492336 [...] ENDED ON STEP: 317, FINAL LOSS: 2.424142714263483e-12 PARAMETERS: [2.49999969 2.50000008]
Géré en 317 étapes. Beaucoup plus vite.
Nous optimisons par la méthode de Newton
Les actions des méthodes de second ordre peuvent être comparées à la conduite d'un snowboarder rationnel de freeride qui réfléchit longuement au prochain point de son itinéraire et prend en compte non seulement la pente à l'emplacement, mais aussi la courbure.
En fait, les méthodes de descente de gradient et les méthodes de second ordre tentent de deviner ( approximer ) la fonction au point courant. Les méthodes de gradient se concentrent uniquement sur la pente du graphique de la fonction au point - la dérivée première. Les méthodes du second ordre, en plus du biais, prennent en compte la courbure , la dérivée seconde: "si la courbure persiste, alors où sera le minimum?" Nous calculons et y allons:
Pour construire une telle approximation et calculer le point minimum estimé, vous pouvez utiliser la série Taylor . Pour le cas unidimensionnel, l'approximation par un polynôme de second ordre au point a ressemble à ceci:
f(x) approxf(a)+ fracf′(a)(x−a)1!+ fracf″(a)(x−a)22!
Le minimum est atteint à x=a− fracf′(a)f″(a) . Le cas multidimensionnel semble plus sérieux:
Matrice de Hesse (vecteur entré - nombre à gauche)La matrice de Hesse est une matrice carrée composée de dérivées secondes:
\ boldsymbol {H} y_ {x} = \ begin {bmatrix} \ frac {\ partial ^ 2y} {\ partial x_1 ^ 2} & \ frac {\ partial ^ 2y} {\ partial x_1 \ partial x_2} & \ cdots & \ frac {\ partial ^ 2y} {\ partial x_1 \ partial x_N} \\ \ frac {\ partial ^ 2y} {\ partial x_2 \ partial x_1} & \ frac {\ partial ^ 2y} {\ partial x_2 ^ 2} & \ cdots & \ frac {\ partial ^ 2y} {\ partial x_2 \ partial x_N} \\ \ vdots & \ vdots & \ ddots & \ vdots \\ \ frac {\ partial ^ 2y} {\ partial x_N \ partiel x_1} & \ frac {\ partiel ^ 2y} {\ partiel x_N \ partiel x_2} & \ cdots & \ frac {\ partiel ^ 2y} {\ partiel x_N ^ 2} \ end {bmatrix}
Approximation d'un polynôme de second ordre pour une fonction d'un vecteur à travers un gradient et une matrice de Hesse en un point a ressemble à ceci:
f(x) approxf(a)+(xa) intercal[ nablaxf(a)]+ frac12!(xa) intercal[ boldsymbolHfx(a)](xa)
Le minimum est atteint à x=a−[ boldsymbolHfx(a)]−1[ nablaxf(a)] . La forme coïncide pratiquement avec le cas unidimensionnel: nous avons remplacé la première dérivée par un gradient, la seconde par une matrice de Hesse et fait une correction pour travailler avec des vecteurs. Il est impossible de diviser un vecteur par une matrice, par conséquent, la multiplication par la matrice inverse est utilisée. T signifie transposer . La formule implique que par défaut un vecteur est une colonne. Transposer transforme un vecteur de colonne en vecteur de ligne . Lors de l'implémentation sur TensorFlow, cela doit être pris en compte, mais en sens inverse: par défaut, le vecteur est une chaîne (tenseur unidimensionnel). Juste au cas où: la transposition n'est pas une rotation de 90 degrés, c'est la transformation de lignes en colonnes dans le même ordre.
Ainsi, l'étape de la méthode Newton a la forme suivante:
boldsymbolp rightarrow boldsymbolp−[ boldsymbolHlossp( boldsymbolp)]−1[ nablaploss( boldsymbolp)]
TensorFlow a tout pour implémenter cette méthode:
[Out]: step: 1, current loss: 3868.2291666666665 step: 2, current loss: 105.04357496954218 step: 4, current loss: 9.96663526704236 ENDED ON STEP: 6, FINAL LOSS: 5.882202372519996e-20 PARAMETERS: [2.5 2.5]
Assez 6 étapes:
Optimisé par l'algorithme de Gauss-Newton
La méthode de Newton a un inconvénient - la matrice de Hesse. Grâce à TensorFlow, nous pouvons le compter dans une seule ligne de code. Selon le wiki, Johann Karl Friedrich Gauss a fait la première mention de sa méthode en 1809. Le calcul de la matrice de Hesse pour plusieurs paramètres pour la méthode des moindres carrés pourrait alors prendre beaucoup de temps. Nous pouvons maintenant supposer que l'algorithme de Gauss-Newton utilise l'approximation de la matrice de Hesse à travers la matrice de Jacobi pour simplifier les calculs. Mais du point de vue de l'histoire, ce n'est pas le cas: Ludwig Otto Hesse (qui a développé la matrice qui porte son nom) est né en 1811 - 2 ans après la première mention de l'algorithme. Et Carl Gustav Jacobi avait 5 ans.
L'algorithme de Gauss-Newton ne fonctionne pas avec la fonction de perte. Il fonctionne avec la fonction résiduelle r(p) . Cette fonction prend un vecteur d'entrée de paramètres p et renvoie un vecteur résiduel . Dans notre cas, le vecteur p se compose de 2 composants (paramètres a et b Fonctions de Rosenbrock) et le vecteur résiduel de m (selon le nombre d'expériences). La fonction vectorielle de l'argument vecteur est obtenue. Sa dérivée:
Matrice de Jacobi (vecteur entré - vecteur libéré)Considérons une fonction qui prend un vecteur en entrée et produit également un vecteur: f: mathbbRN rightarrow mathbbRM . Dérivé f au point x a maintenant la taille N foisM , appelée matrice de Jacobi , et se compose de toutes les combinaisons de dérivées partielles:
\ boldsymbol {J} y_ {x} = \ begin {pmatrix} \ frac {\ partial y_ {1}} {\ partial x_ {1}} & \ cdots & \ frac {\ partial y_ {1}} {\ partiel x_ {N}} \\ \ vdots & \ ddots & \ vdots \\ \ frac {\ partial y_ {M}} {\ partial x_ {1}} & \ cdots & \ frac {\ partial y_ {M}} {\ partial x_ {N}} \ end {pmatrix}
Vous remarquerez peut-être que les lignes de la matrice de Jacobi sont les gradients des composants y . Objet (i,j) matrices frac partialy partialx est égal à frac partialyi partialxj et nous dit combien va changer yi lors du changement xj sur une petite valeur. Comme dans les cas précédents, vous pouvez écrire:
x rightarrowx+ Deltax Rightarrowy rightarrow approxy+ boldsymbolJyx Deltax
Ici boldsymbolJyx matrice N foisM et Deltax vecteur de taille N ainsi le produit boldsymbolJyx Deltax Est le produit de la matrice par le vecteur, résultant en un vecteur de taille M .
Afin de ne pas se confondre dans l'abondance des personnages, nous supposons que boldsymbolJr - Matrice de Jacobi des fonctions résiduelles au point courant boldsymbolp . L'algorithme de Gauss-Newton peut alors s'écrire comme suit:
boldsymbolp rightarrow boldsymbolp−[ boldsymbolJ rintercal boldsymbolJr]−1 boldsymbolJ rintercalr( boldsymbolp)
L'enregistrement sous la forme coïncide complètement avec l'enregistrement de la méthode de Newton. Seulement au lieu de la matrice de Hesse est utilisée boldsymbolJ rintercal boldsymbolJr au lieu du gradient boldsymbolJ rintercalr( boldsymbolp) . Ensuite, nous verrons pourquoi une telle approximation peut être utilisée. En attendant, passons à l'implémentation sur TensorFlow:
[Out]: step: 1, current loss: 3868.2291666666665 step: 2, current loss: 14.653025157673625 step: 4, current loss: 4.3918079172783016e-07 ENDED ON STEP: 4, FINAL LOSS: 3.374364957618591e-17 PARAMETERS: [2.5 2.5]
Assez 4 étapes. Moins que pour la méthode de Newton.
Comme le montre le code, la fonction de perte n'est pas utilisée dans l'optimisation, uniquement pour les critères d'arrêt et de journalisation. Comment l'algorithme d'optimisation sait-il quelle fonction minimiser? La réponse est surprenante: pas question! Gauss-Newton minimise uniquement l' erreur quadratique moyenne .
Correction de la partie mathématique de l'article
Nous avons répété tous les calculs dont nous avions besoin. Corrigeons-le un peu afin de nous concentrer davantage uniquement sur la programmation et TensorFlow. Vous aurez peut-être besoin d'un crayon pour tracer la séquence d'actions mathématiques.
Il y a un modèle y=f(x,p) où x - vecteur p - vecteur de paramètres de dimension n et y - scalaire. Des expériences reçues m des points (x1,y1),...,(xm,ym) ( paires de données ). La fonction résiduelle du vecteur dépend uniquement du vecteur de paramètre: r(p)=(r1(p),...rm(p)) où rk(p)=yk− widehatyk=yk−f(xk,p) . , p , xk,yk ? , xk,yk , .
p , ( sum of squared error — sse residual sum-of-squares — rss ) . mse sse , m . . :
loss(p)=r21(p)+⋯+r2m(p)=m∑k=1r2k(p)
p (p) .
, . — . — , r2 2r∂r∂p . :
∇ploss=(m∑k=12rk∂rk∂p1,⋯,m∑k=12rk∂rk∂pn)
. :
[Hlossp]ij=∂2loss∂pi∂pj=m∑k=1(2∂rk∂pi∂rk∂pj+2rk∂2rk∂pi∂pj)
. , , (uv)′=u′v+uv′ .
Super! .
, , , — 2rk∂2rk∂pi∂pj . , , rk , . — . , ? -.
:
Jr=(∂r1∂p1⋯∂r1∂pn⋮⋱⋮∂rm∂p1⋯∂pm∂pn)
, , . Notez que:
2J⊺rJr≈Hlossp
"" . ( ). , — 2rk∂2rk∂pi∂pj , .
( ):
2J⊺rr=∇ploss
, , - — , mse .
. , , . m (x1,y1),...,(xm,ym) , y=rosenbrock(x,p) . p , .
, : " . - ! ". , , , ( supervised learning ). , . : ( training set ) — ; — ( prediction model ) ; — , .
( multi-layer perceptron neural network mlp ). , , :
- ( starting values ) . Xavier'a, .
- ( overfitting ). — . , . — .
- ( scaling of the input ). , .
9 . 500:
500 . — ( learner ), ( outcome measurement ) ( features ) .
( network diagram ). MatLab:
( input ). W ( weights ) 2x10, b ( bias ) 10, ( activation ). () ( hidden layer ) 10 . , , ( output ).
, , ( tanh ):
h1=tanh(xW1+b1)ˆy=h1W2+b2
:
h1=tanh([x1x2][w(1)1,1⋯w(1)1,10w(1)2,1⋯w(1)2,10]+[b(1)1⋯b(1)10])ˆy=[h(1)1⋯h(1)10][w(2)1,1⋮w(2)1,10]+b2
. W1 "" h1 , - W2 . 41 . , .
m×2 , . - ˆy de m :
Adam
Adam rosenbrock . mse :
[Out]: step: 1, current loss: 671.4242576535694 [...] ENDED ON STEP: 40000, FINAL LOSS: 0.22862158574440725 VALIDATION LOSS: 0.29000289644978866
. : , , .
rosenbrock 2 . :
:
Jrp . , 4 W1,b1,W2,b2 . 4 JrW1,Jrb1,JrW2,Jrb2 tf.concat .
. tf.while_loop , ri , , stack .
ri W1 : [∂ri∂w(1)1,1⋯∂ri∂w(1)1,10∂ri∂w(1)2,1⋯∂ri∂w(1)2,10] . tf.reshape (-1,) [∂ri∂w(1)1,1⋯∂ri∂w(1)1,10∂ri∂w(1)2,1⋯∂ri∂w(1)2,10] .
. - . — TensorFlow . — - - W1,b1,W2,b2 . -. Levenberg-Marquardt Jupyter Notebook rosenbrock_train.py . , TensorFlow . - , ( ) , , .
-
hess_approx grad_approx -. rosenbrock , . :
- : Δp=[Δw(1)1,1⋯Δw(1)2,10Δb(1)1⋯Δb(1)10Δw(2)1,1⋯Δw(2)1,10Δb2]
- :
ΔW1=[Δw(1)1,1⋯Δw(1)2,10] , Δb1=[Δb(1)1⋯Δb(1)10] , ΔW2=[Δw(2)1,1⋯Δw(2)1,10] , Δb2=[Δb2] . - , :
ΔW1=[Δw(1)1,1⋯Δw(1)1,10Δw(1)2,1⋯Δw(1)2,10] , ΔW2=[Δw(2)1,1⋮Δw(2)1,10] - .
[Out]: step: 1, current loss: 548.8468777701685 step: 2, current loss: 49648941.340197295 InvalidArgumentError: Input is not invertible.
- . , . - , .
, .
-
. Matlab trainlm . . MathWorks.
- : p→p−[J⊺rJr]−1J⊺rr(p) . - :
p→p−[J⊺rJr+μI]−1J⊺rr(p)
mu I n ( ). mu , -. , . , LM -.
:
mu = tf.placeholder(tf.float64, shape=[1]) n = tf.add_n(parms_sizes) I = tf.eye(n, dtype=tf.float64)
mu ? LM - . , . , mu , . — , mse . , :
[Out]: step: 1, mu: 3.0 current loss: 692.6211687622557 [...] ENDED ON STEP: 100, FINAL LOSS: 0.012346989371823602 VALIDATION LOSS: 0.01859463694102034
100 LM mse 10 , 40 .
. , . , rosenbrock_train.py .
2D . . . , " " ( curse of dimentionality , Bellman, 1961). . .
:
f(x)=N−1∑i=1[100(xi+1−x2i)2+(1−xi)2],x=[x1⋯xN]∈RN
rosenbrock_train.py get_rand_rosenbrock_points .
-
- : " ! 4 , 300! ". , ( ) -. , , . - . . : ? , . . , - :
- 10 000 6D .
- 3 12, 10, 8 (311 ).
- .
- 3.5 .
. - 2 . LM . 20 .
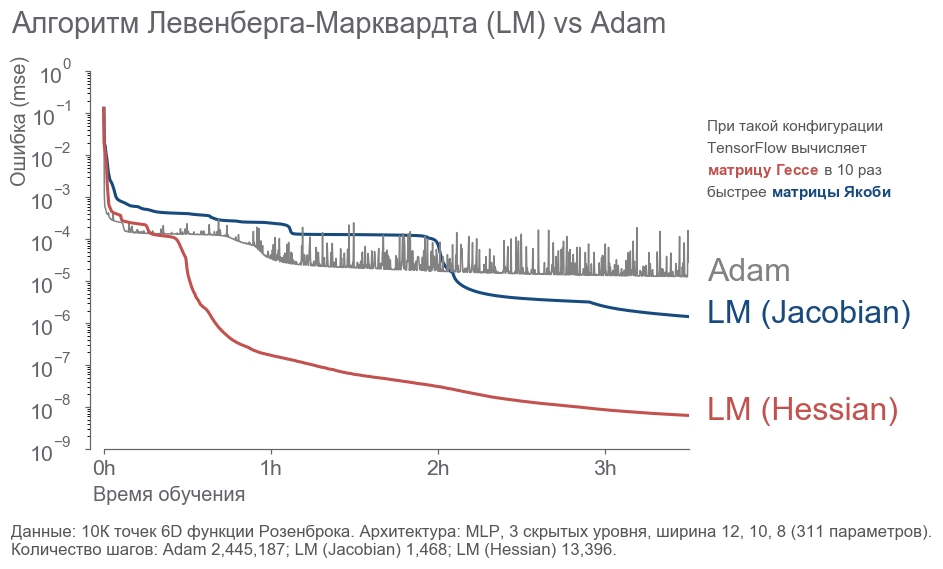
rosenbrock_train.py . . , .
Conclusion
, . " ", , . , . , 273 . - , .
, :
- .
- ( ) -:
[1] Petros Drineas, Ravi Kannan, and Michael W. Mahoney. 2006. Fast Monte Carlo Algorithms for Matrices I: Approximating Matrix Multiplication. SIAM J. Comput. 36, 1 (July 2006), 132-157. DOI= http://dx.doi.org/10.1137/S0097539704442684
[2] Adelman, M., & Silberstein, M. (2018). Faster Neural Network Training with Approximate Tensor Operations. CoRR, abs/1805.08079.
, - . , . "".