L'une des tâches les plus importantes dans le domaine de la science des données est non seulement la construction d'un modèle capable de faire des prédictions de haute qualité, mais également la capacité d'interpréter de telles prédictions.
Si nous savons non seulement que le client est enclin à acheter un produit, mais comprenons également ce qui influence son achat, nous serons en mesure de construire une stratégie d'entreprise à l'avenir visant à améliorer l'efficacité des ventes.
Ou le modèle a prédit que le patient tomberait malade bientôt. La précision de ces prédictions n'est pas très élevée, car Il existe de nombreux facteurs cachés dans le modèle, mais une explication des raisons pour lesquelles le modèle a fait une telle prédiction peut aider le médecin à prêter attention aux nouveaux symptômes. Ainsi, il est possible d'élargir les limites d'application du modèle si sa précision en elle-même n'est pas trop élevée.
Dans cet article, je veux parler de la technique
SHAP , qui vous permet de regarder sous le capot d'une variété de modèles.
Si, avec les modèles linéaires, cela devient de moins en moins clair, plus la valeur absolue du coefficient sous le prédicteur est élevée, plus ce prédicteur est important, alors expliquer l'importance des caractéristiques du même renforcement de gradient est sensiblement plus difficile.
Pourquoi il y avait un besoin pour une telle bibliothèque

Dans la pile sklearn, dans les packages xgboost, lightGBM, il y avait des méthodes intégrées pour évaluer l'importance des fonctionnalités (importance des fonctionnalités) pour les "modèles en bois":
- Gain
Cette mesure montre la contribution relative de chaque entité au modèle. pour le calcul, nous passons par chaque arbre, regardons chaque nœud d'arbre dont la caractéristique conduit à la partition du nœud et dans quelle mesure l'incertitude du modèle diminue en fonction de la métrique (impureté de Gini, gain d'informations).
Pour chaque entité, sa contribution sur tous les arbres est résumée.
- Couverture
Affiche le nombre d'observations pour chaque entité. Par exemple, vous avez 4 fonctionnalités, 3 arbres. Supposons que l'entité 1 aux nœuds de l'arbre contienne respectivement 10, 5 et 2 observations dans les arbres 1, 2 et 3. Ensuite, pour cette entité, l'importance sera de 17 (10 + 5 + 2).
- La fréquence
Il montre à quelle fréquence cette entité se trouve dans les nœuds de l'arbre, c'est-à-dire que le nombre total de divisions d'arbre en nœuds pour chaque entité dans chaque arbre est pris en compte.
Le principal problème dans toutes ces approches est qu'il n'est pas clair comment exactement cette caractéristique affecte la prédiction du modèle. Par exemple, nous avons appris que le niveau de revenu est important pour évaluer la solvabilité d'un client d'une banque pour rembourser un prêt. Mais comment exactement? Combien de prévisions de modèles de biais de revenus plus élevés?
Bien sûr, nous pouvons faire plusieurs prédictions en modifiant le niveau de revenu. Mais que faire des autres fonctionnalités? Après tout, nous nous trouvons dans une situation dont nous avons besoin pour comprendre l'influence du revenu
indépendamment des autres caractéristiques, avec leur valeur moyenne.
Il y a une sorte de client bancaire moyen "dans le vide". Comment les prédictions du modèle changeront-elles avec les changements de revenu?
Ici, la bibliothèque
SHAP vient à la rescousse.
Nous calculons l'importance des fonctionnalités à l'aide de SHAP
Dans la bibliothèque
SHAP , pour évaluer l'importance des
fonctionnalités, les valeurs de Shapley sont calculées (par le nom d'un mathématicien américain et la bibliothèque est nommée).
Pour évaluer l'importance d'une fonction, les prédictions du modèle sont évaluées
avec et
sans cette fonction.
Un peu de préhistoire

La signification de Shapley vient de la théorie des jeux.
Considérez le scénario: un groupe de personnes joue aux cartes. Comment répartir le prix entre eux en fonction de leur contribution?
Un certain nombre d'hypothèses sont émises:
- Le montant de la récompense pour chaque joueur est égal à la cagnotte totale
- Si deux joueurs apportent une contribution égale au jeu, ils reçoivent une récompense égale.
- Si un joueur n'a fait aucune contribution, il ne reçoit pas de récompense.
- Si un joueur a passé deux parties, sa récompense totale se compose du montant des récompenses pour chacun des jeux
Nous présentons les caractéristiques du modèle en tant que joueurs, et le prize pool comme prédiction finale du modèle.
Regardons un exemple.
La formule de calcul de la valeur de Shapley pour la fonction i-ème:
$$ afficher $$ \ commencer {équation *} \ phi_ {i} (p) = \ sum_ {S \ subseteq N / \ {i \}} \ frac {| S |! (n - | S | -1) !} {n!} (p (S \ cup \ {i \}) - p (S)) \ end {equation *} $$ display $$
Ici:
p (S \ cup \ {i \}) Est une prédiction d'un modèle avec la fonction i-ème,
- il s'agit d'une prédiction du modèle sans la i-ème fonction,
- nombre de fonctionnalités,
- un ensemble arbitraire de fonctionnalités sans la i-ème fonctionnalité
La valeur de Shapley pour la i-ème fonctionnalité est calculée pour chaque échantillon de données (par exemple, pour chaque client de l'échantillon) sur toutes les combinaisons possibles de fonctionnalités (y compris l'absence de toutes les fonctionnalités), puis les valeurs obtenues sont additionnées modulo et l'importance finale de la i-ème fonctionnalité est obtenue.
Ces calculs sont extrêmement coûteux, par conséquent, sous le capot, divers algorithmes d'optimisation des calculs sont utilisés, pour plus de détails, voir le lien ci-dessus sur le github.
Prenons l'exemple vanilla de la
documentation xgboost .
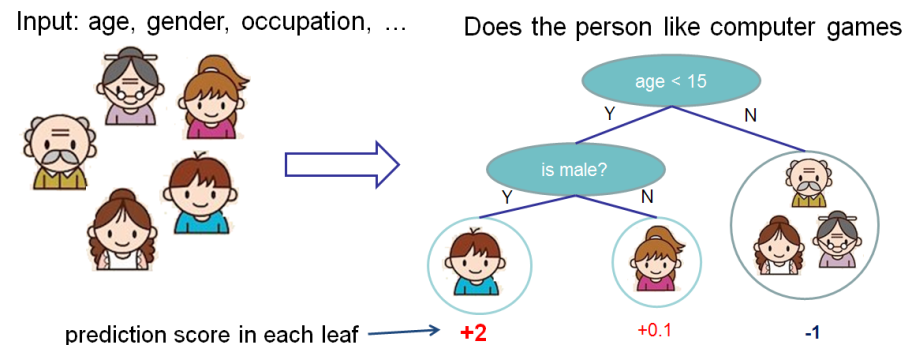
Nous voulons évaluer l'importance des fonctionnalités pour prédire si une personne aime les jeux informatiques.
Dans cet exemple, par souci de simplicité, nous avons deux caractéristiques: l'âge (âge) et le sexe (sexe). Le genre (gender) prend les valeurs 0 et 1.
Prenez Bobby (le petit garçon dans le nœud le plus à gauche de l'arbre) et calculez la valeur de Shapley pour l'âge de la fonction (age).
Nous avons deux ensembles de fonctionnalités S:
\ {\} - pas de fonctionnalités
\ {gender \} - il n'y a qu'un genre de fonctionnalité.
La situation lorsqu'il n'y a pas de valeurs de fonction
Différents modèles fonctionnent différemment avec des situations où il n'y a pas de fonctionnalités pour l'échantillon de données, c'est-à-dire que pour toutes les fonctionnalités, les valeurs sont NULL.
Dans ce cas, il considérera que le modèle fait la moyenne des prédictions sur les branches d'arbre, c'est-à-dire que la prédiction sans caractéristiques sera
.
Si l'on ajoute la connaissance de l'âge, alors la prédiction du modèle sera
.
En conséquence, la valeur de Shapley pour le cas de l'absence de fonctionnalités:
\ frac {| S |! (n - | S | -1)!} {n!} (p (S \ cup \ {i \}) - p (S)) = \ frac {1 (2-0 -1)!} {2!} (1,025) = 0,5125
La situation quand on connaît le sexe
Pour bobby pour
prédiction sans caractéristiques âge, uniquement avec caractéristiques sexe est égal
. Si nous connaissons l'âge, alors la prédiction est l'arbre le plus à gauche, c'est-à-dire 2.
Par conséquent, la valeur de Shapley pour ce cas:
$$ afficher $$ \ commencer {équation *} \ frac {| S |! (n - | S | -1)!} {n!} (p (S \ cup \ {i \}) - p (S) ) = \ frac {1 (2-1-1)!} {2!} (1.975) = 0.9875 \ end {équation *} $$ display $$
Résumer
La valeur totale de Shapley pour les caractéristiques d'âge (âge):
$$ afficher $$ \ commencer {équation *} \ phi_ {Age Bobby} = 0,9875 + 0,5125 = 1,5 \ fin {équation *} $$ afficher $$
Un véritable exemple commercial
La bibliothèque SHAP possède une riche fonctionnalité de visualisation qui aide à expliquer facilement et simplement le modèle à la fois pour l'entreprise et l'analyste lui-même, afin d'évaluer l'adéquation du modèle.
Dans l'un des projets, j'ai analysé les sorties de salariés de l'entreprise. Comme modèle, xgboost a été utilisé.
Code en python:
import shap shap_test = shap.TreeExplainer(best_model).shap_values(df) shap.summary_plot(shap_test, df, max_display=25, auto_size_plot=True)
Le graphique résultant de l'importance des fonctionnalités:
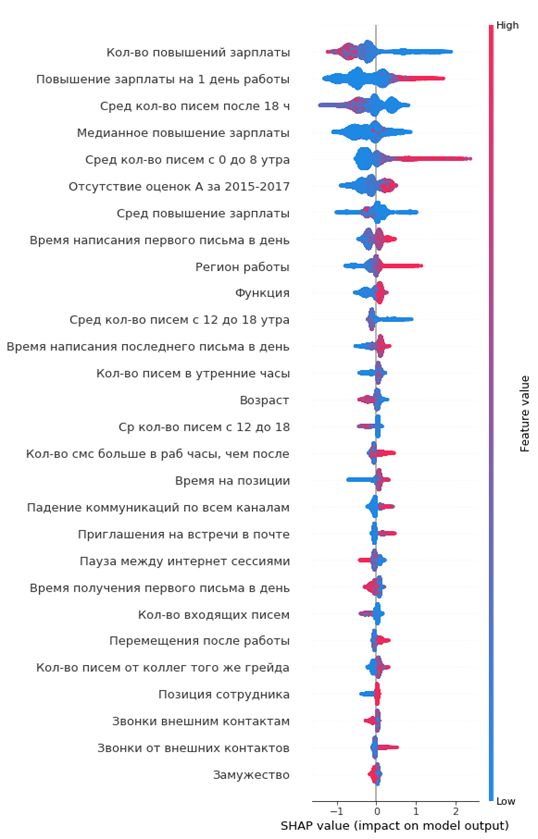
Comment le lire:
- les valeurs à gauche de la ligne verticale centrale sont la classe négative (0), à droite - positive (1)
- plus la ligne du graphique est épaisse, plus ces points d'observation sont nombreux
- plus les points du graphique sont rouges, plus la valeur des caractéristiques
À partir du graphique, vous pouvez tirer des conclusions intéressantes et vérifier leur adéquation:
- plus l’augmentation de salaire de l’employé est faible, plus la probabilité de son départ est élevée
- il y a des régions de bureaux où les sorties sont plus importantes
- plus l'employé est jeune, plus la probabilité de son départ est élevée
- ...
Vous pouvez immédiatement dresser le portrait de la salariée sortante: elle n'a pas reçu d'augmentation de salaire, il était assez jeune, célibataire, longtemps au même poste, il n'y a pas eu d'augmentation de grade, il n'y a pas eu de cotations annuelles élevées, il a commencé à communiquer peu avec ses collègues.
Simple et pratique!
Vous pouvez expliquer la prédiction pour un employé spécifique:

Ou voyez la dépendance des prédictions sur une caractéristique spécifique sous la forme d'un graphique 2D:
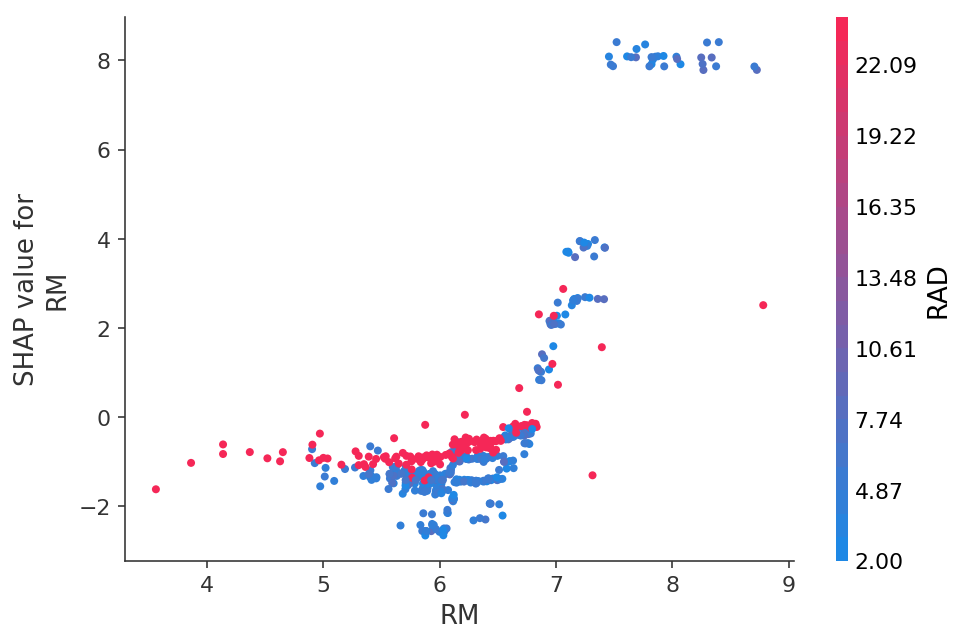
Vous pouvez même visualiser les prédictions des réseaux de neurones en images:

Conclusion
J'ai moi-même appris les valeurs SHAP il y a environ six mois et cela a complètement remplacé d'autres méthodes pour évaluer l'importance des fonctionnalités.
Les principaux avantages:
- visualisation et interprétation pratiques
- calcul honnête de l'importance des fonctionnalités
- la capacité d'évaluer les fonctionnalités d'un sous-échantillon particulier de données (par exemple, la différence entre nos clients et les autres clients de l'échantillon) se fait par un simple filtre de l'ensemble de données dans pandas et son analyse dans shap, littéralement quelques lignes de code