Synthèse et édition d'images contrôlées à l'aide du nouveau TL-GAN Exemple de synthèse contrôlée dans mon modèle TL-GAN (GAN transparent en espace latent, réseau génératif-contentif avec espace caché transparent)
Exemple de synthèse contrôlée dans mon modèle TL-GAN (GAN transparent en espace latent, réseau génératif-contentif avec espace caché transparent)Tous les codes et les démos en ligne sont disponibles sur
la page du projet .
Nous formons l'ordinateur pour prendre des photos comme décrit
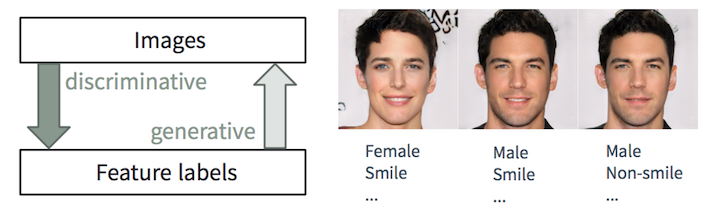 Tâches discriminantes et génératives
Tâches discriminantes et générativesIl est facile pour une personne de
décrire une image, nous apprenons à le faire dès le plus jeune âge. Dans l'apprentissage automatique, c'est la tâche de la classification / régression
discriminante , c'est-à-dire prédiction des caractéristiques des images d'entrée. Les progrès récents des méthodes ML / AI, en particulier dans les modèles d'apprentissage profond, commencent à exceller dans ces tâches, atteignant ou dépassant parfois les capacités humaines, comme le montrent des tâches telles que la reconnaissance visuelle d'objets (par exemple, d'AlexNet à ResNet selon la classification ImageNet) et la détection / segmentation objets (par exemple, de RCNN à YOLO dans le jeu de données COCO), etc.
Néanmoins, la tâche inverse de
créer des images réalistes à partir de la description est beaucoup plus compliquée et nécessite de nombreuses années de formation en conception graphique. Dans l'apprentissage automatique, il s'agit d'une tâche
générative , qui est beaucoup plus compliquée que les tâches discriminatoires, car le modèle génératif devrait générer beaucoup plus d'informations (par exemple, une image complète à un certain niveau de détail et de variation) sur la base de données initiales plus petites.
Malgré la complexité de la création de telles applications,
les modèles génératifs (avec un certain contrôle) sont extrêmement utiles dans de nombreux cas:
- Création de contenu : imaginez qu'une société de publicité crée automatiquement des images attrayantes qui correspondent au contenu et au style de la page Web où ces images sont insérées. Le créateur cherche l'inspiration en commandant l'algorithme pour générer 20 patrons de chaussures associés aux signes «repos», «été» et «passionné». Le nouveau jeu vous permet de générer des avatars réalistes à partir d'une simple description.
- Retouche intelligente basée sur le contenu : le photographe modifie l'expression du visage, le nombre de rides et la coiffure de la photo en quelques clics. Un artiste d'un studio hollywoodien convertit les photos prises par une soirée nuageuse, comme si elles avaient été prises par une matinée lumineuse, avec la lumière du soleil sur le côté gauche de l'écran.
- Augmentation des données : un développeur de drones peut synthétiser des vidéos réalistes pour un scénario d'accident spécifique afin d'augmenter l'ensemble de données de formation. Une banque peut synthétiser certains types de données de fraude mal présentées dans l'ensemble de données existant afin d'améliorer le système anti-fraude.
Dans cet article, nous parlerons de notre travail récent appelé
Transparent Latent-space GAN (TL-GAN) , qui étend les fonctionnalités des modèles les plus modernes, offrant une nouvelle interface. Nous travaillons actuellement sur un document qui aura plus de détails techniques.
Présentation des modèles génératifs
La communauté d'apprentissage en profondeur améliore rapidement les modèles génératifs. Trois types prometteurs peuvent être distingués entre eux:
les modèles autorégressifs , les
auto-encodeurs variationnels (VAE) et
les réseaux contradictoires génératifs (GAN) , illustrés dans la figure ci-dessous. Si vous êtes intéressé par les détails, veuillez lire l'excellent
article du blog OpenAI.
 Comparaison des réseaux génératifs. Image du cours STAT946F17 à l'Université de Waterloo
Comparaison des réseaux génératifs. Image du cours STAT946F17 à l'Université de WaterlooÀ l'heure actuelle, les images de la
plus haute qualité sont générées par les réseaux GAN (photoréalistes et diversifiés, avec des détails convaincants en haute résolution). Jetez un œil au magnifique réseau pg-GAN (
GAN à croissance progressive ) de Nvidia. Par conséquent, dans cet article, nous nous concentrerons sur les modèles GAN.
 Pg-GAN synthétique généré par Nvidia. Aucune des images n'est liée à la réalité.
Pg-GAN synthétique généré par Nvidia. Aucune des images n'est liée à la réalité.GAN Model Issue Management
 Génération d'images aléatoires et contrôléesLa version originale de GAN
Génération d'images aléatoires et contrôléesLa version originale de GAN et de nombreux modèles populaires basés sur elle (tels que
DC-GAN et
pg-GAN ) sont des modèles d'enseignement
sans professeur . Après l'entraînement, le réseau neuronal génératif prend du bruit aléatoire en entrée et crée une image photoréaliste qui se distingue à peine de l'ensemble de données d'apprentissage. Cependant, nous ne pouvons pas contrôler en plus les fonctionnalités des images générées. Dans la plupart des applications (par exemple, dans les scénarios décrits dans la première section), les utilisateurs souhaitent créer des motifs avec
des attributs arbitraires (par exemple, l'âge, la couleur des cheveux, l'expression du visage, etc.) Idéalement, configurez chaque fonction en douceur.
De nombreuses variantes de GAN ont été créées pour une telle synthèse contrôlée. Ils peuvent être conditionnellement divisés en deux types: les réseaux de transfert de style et les générateurs conditionnels.
Réseaux de transfert de style
Les réseaux de transfert de style
CycleGAN et
pix2pix sont formés pour transférer une image d'une zone (domaine) à une autre: par exemple, d'un cheval à un zèbre, d'un croquis à des images en couleur. En conséquence, nous ne pouvons pas changer en douceur un signe spécifique entre deux états discrets (par exemple, ajouter une petite barbe sur le visage). De plus, un réseau est conçu pour un type de transmission, donc dix réseaux neuronaux différents seront nécessaires pour configurer dix fonctions.
Générateurs de conditions
Les générateurs
conditionnels -
GAN conditionnel ,
AC-GAN et Stack-GAN - en cours de formation, étudient simultanément les images et les étiquettes des objets, ce qui vous permet de générer des images avec le réglage des attributs. Lorsque vous souhaitez ajouter de nouvelles fonctionnalités au processus de génération, vous devez recycler l'intégralité du modèle GAN, ce qui nécessite d'énormes ressources de calcul et de temps (par exemple, de plusieurs jours à plusieurs semaines sur le même GPU K80 avec un ensemble idéal d'hyperparamètres). De plus, pour terminer la formation, il est nécessaire de s'appuyer sur un seul ensemble de données contenant toutes les étiquettes d'objets définies par l'utilisateur, et de ne pas utiliser des étiquettes différentes de plusieurs ensembles de données.
Notre réseau concurrentiel génératif avec un espace caché transparent (
Transparent Latent-space GAN , TL-GAN) utilise une approche différente pour la génération contrôlée - et résout ces problèmes. Il offre la possibilité de
configurer de manière transparente une ou plusieurs fonctionnalités à l'aide d'un seul réseau . De plus, vous pouvez ajouter efficacement de nouvelles fonctionnalités personnalisées en moins d'une heure.
TL-GAN: une approche nouvelle et efficace de la synthèse et de l'édition contrôlées
Faire de ce mystérieux espace caché transparent
Prenez le modèle pvGAN de Nvidia, qui génère des images photoréalistes haute résolution de visages, comme indiqué dans la section précédente. Toutes les caractéristiques de l'image 1024 × 1024px générée sont déterminées exclusivement par le vecteur de bruit à 512 dimensions dans l'espace caché (en tant que représentation à faible dimension du contenu de l'image). Par conséquent,
si nous comprenons ce qui constitue un espace caché (c'est-à-dire le rendons transparent), nous pouvons alors contrôler complètement le processus de génération .
 Motivation TL-GAN: Comprendre l'espace caché pour gérer le processus de génération
Motivation TL-GAN: Comprendre l'espace caché pour gérer le processus de générationEn expérimentant avec le réseau pg-GAN pré-formé, j'ai trouvé que l'espace caché a en fait deux bonnes propriétés:
- Il est bien rempli, c'est-à-dire que la plupart des points de l'espace génèrent des images raisonnables.
- Elle est assez continue, c'est-à-dire que l'interpolation entre deux points dans un espace caché conduit généralement à une transition en douceur des images correspondantes.
L'intuition dit que dans l'espace caché, il y a des directions qui prédisent les attributs dont nous avons besoin (par exemple, un homme / une femme). Si c'est le cas, alors les vecteurs unitaires de ces directions deviendront des axes de contrôle du processus de génération (visage plus masculin ou plus féminin).
Approche: extension de l'axe des fonctionnalités
Pour trouver ces axes d'attributs dans un espace caché,
nous construisons une connexion entre le vecteur caché et étiquettes de balise utiliser la formation des enseignants par deux
. Maintenant, le problème est de savoir comment obtenir ces paires, car les ensembles de données existants ne contiennent que des images
et les étiquettes d'objets correspondantes
.
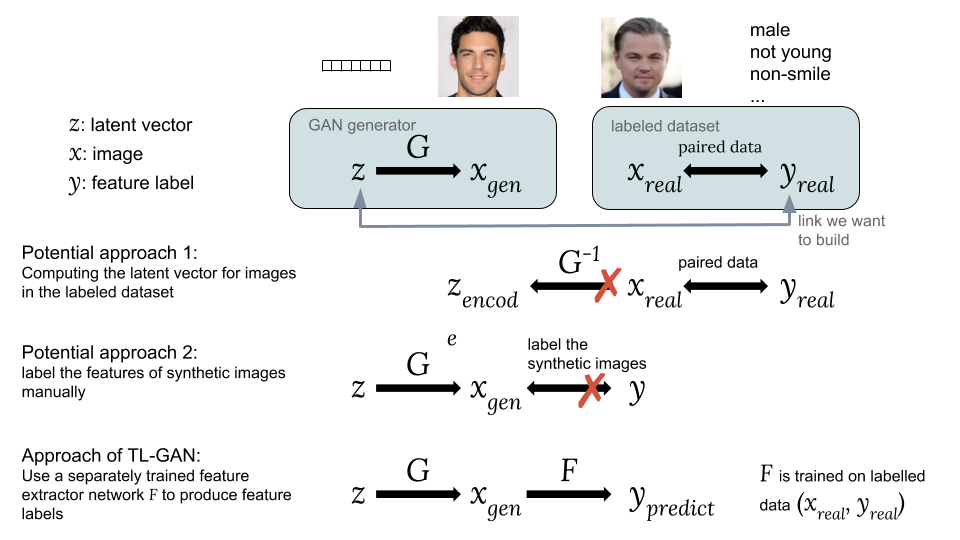 Façons d'associer un vecteur caché z à une étiquette de balise yApproches possibles:Une option consiste à calculer les vecteurs cachés correspondants des images à partir d'un ensemble de données existant avec des étiquettes qui nous intéressent . Cependant, le GAN ne fournit pas un moyen facile de calculer , ce qui rend difficile la mise en œuvre de cette idée.
Façons d'associer un vecteur caché z à une étiquette de balise yApproches possibles:Une option consiste à calculer les vecteurs cachés correspondants des images à partir d'un ensemble de données existant avec des étiquettes qui nous intéressent . Cependant, le GAN ne fournit pas un moyen facile de calculer , ce qui rend difficile la mise en œuvre de cette idée.
La deuxième option est de générer des images synthétiques en utilisant un GAN à partir d'un vecteur caché aléatoire comment . Le problème est que les images synthétiques ne sont pas balisées, il est donc difficile d'utiliser un ensemble accessible de données balisées.La principale innovation de notre modèle TL-GAN est la
formation d'un extracteur séparé (classificateur pour étiquettes discrètes ou régresseur pour continu) avec le modèle
en utilisant un ensemble existant de données balisées (
,
), puis lancer un groupe de générateurs GAN formés
avec réseau d'extraction de fonctionnalités
. Cela vous permet de prédire les étiquettes des entités.
images synthétiques
en utilisant un réseau d'extraction d'entités formé (extracteur). Ainsi, à travers des images synthétiques, un lien s'établit entre
et
comment
et
.
Maintenant, nous avons un vecteur caché et des fonctionnalités appariés. Vous pouvez former le modèle de régresseur
pour ouvrir tout l'axe des entités pour contrôler le processus de génération d'image.
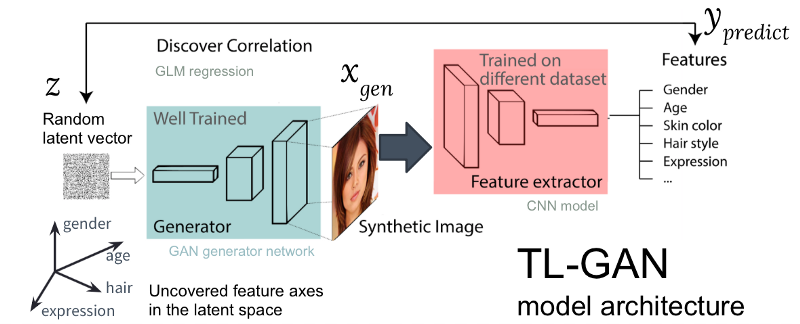 Figure: L'architecture de notre modèle TL-GAN
Figure: L'architecture de notre modèle TL-GANLa figure ci-dessus montre l'architecture du modèle TL-GAN, qui comprend cinq étapes:
- L'étude de la distribution . Nous sélectionnons un modèle GAN bien formé et un réseau génératif. J'ai pris le pg-GAN bien formé (de Nvidia), qui fournit la meilleure génération de visages de qualité.
- Classification . Nous sélectionnons un modèle pré-formé pour extraire des traits (l'extracteur peut être un réseau neuronal convolutionnel ou d'autres modèles de vision par ordinateur) ou nous formons notre propre extracteur à l'aide d'un ensemble de données étiquetées. J'ai formé un simple réseau neuronal convolutif à l'aide du kit CelebA (plus de 30 000 visages avec 40 balises).
- Génération . Nous créons plusieurs vecteurs cachés aléatoires, passons par le générateur GAN entraîné pour créer des images synthétiques, puis utilisons l'extracteur d'entités entraîné pour générer des entités sur chaque image.
- Corrélation . Nous utilisons le modèle linéaire généralisé (GLM) pour implémenter la régression entre les vecteurs cachés et les entités. La pente de la droite de régression devient l'axe des traits .
- Recherche . Nous commençons avec un vecteur caché, le déplaçons le long d'un ou plusieurs axes des signes et étudions comment cela affecte la génération d'images.
J'ai grandement optimisé le processus: sur un modèle GAN pré-formé, l'identification des axes de fonctionnalités
ne prend qu'une heure sur une machine avec un GPU. Ceci est réalisé grâce à plusieurs astuces d'ingénierie, notamment le transfert de la formation, la réduction de la taille des images, la mise en cache préliminaire des images synthétiques, etc.
Résultats
Voyons comment fonctionne cette idée simple.
Déplacement d'un vecteur caché le long des axes des objets
Tout d'abord, j'ai vérifié si les axes de fonctionnalité détectés peuvent être utilisés pour contrôler la fonctionnalité correspondante de l'image générée. Pour ce faire, créez un vecteur aléatoire
dans l'espace caché du GAN et générer une image synthétique
en passant par un réseau génératif
. Ensuite, nous déplaçons le vecteur caché le long d'un axe d'entités
(un vecteur unitaire dans un espace caché, disons, correspondant au sexe du visage) à distance
à un nouveau poste
et générer une nouvelle image
. Idéalement, la caractéristique correspondante de la nouvelle image devrait changer dans la direction attendue.
Les résultats du déplacement d'un vecteur le long de plusieurs axes d'attributs (sexe, âge, etc.) sont présentés ci-dessous. Cela fonctionne étonnamment bien! Vous pouvez
facilement transformer l' image entre un homme / une femme, un jeune / un vieil homme, etc.
 Les premiers résultats du déplacement d'un vecteur caché le long d'axes d'entités enchevêtrés
Les premiers résultats du déplacement d'un vecteur caché le long d'axes d'entités enchevêtrésDémêler les axes d'entités corrélés
Dans les exemples ci-dessus, l'inconvénient de la méthode d'origine est visible, à savoir l'axe confus des attributs. Par exemple, lorsque vous devez réduire les poils du visage, les visages générés deviennent plus féminins, ce qui n'est pas le résultat attendu. Le problème est que le sexe et la barbe sont intrinsèquement
corrélés . Un changement dans un trait entraîne un changement dans un autre. Des choses similaires se sont produites avec d'autres caractéristiques, telles que les cheveux et les cheveux bouclés. Comme le montre la figure ci-dessous, l'axe d'origine de l'attribut "barbe" dans l'espace caché n'est pas perpendiculaire à l'axe "sol".
Pour résoudre le problème, j'ai utilisé les techniques de l'algèbre linéaire simple. En particulier, il a projeté l'axe de la barbe dans une nouvelle direction, orthogonale à l'axe du sol, ce qui élimine efficacement leur corrélation et, ainsi, peut potentiellement démêler ces deux signes sur les faces générées.
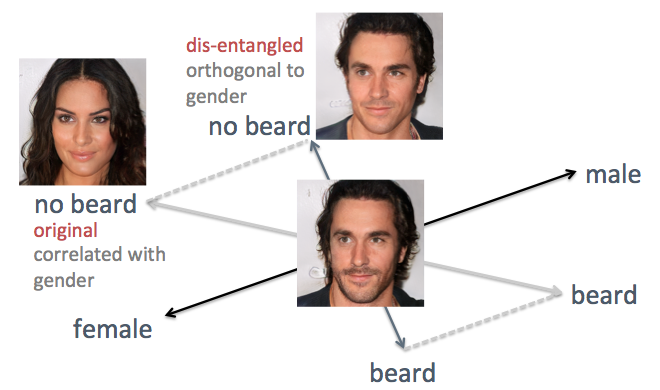 Démêler les axes d'entités corrélés avec des techniques d'algèbre linéaire
Démêler les axes d'entités corrélés avec des techniques d'algèbre linéaireJ'ai appliqué cette méthode à la même personne. Cette fois, les axes de genre et d'âge sont choisis comme supports, projetant tous les autres axes pour qu'ils deviennent orthogonaux au sexe et à l'âge. Les faces sont générées en déplaçant le vecteur caché le long des axes de fonction nouvellement générés (comme illustré dans la figure ci-dessous). Comme prévu, les signes comme les coiffures et les barbes n'affectent plus le sol.
 Amélioration du résultat du déplacement d'un vecteur caché le long d'axes d'entités non emmêlés
Amélioration du résultat du déplacement d'un vecteur caché le long d'axes d'entités non emmêlésMontage interactif flexible
Pour voir avec quelle flexibilité notre modèle TL-GAN est capable de contrôler le processus de génération d'image, j'ai créé une interface graphique interactive avec un changement en douceur des valeurs des objets sur différents axes, comme indiqué ci-dessous.
Montage interactif avec TL-GANEt encore une fois, le modèle fonctionne étonnamment bien si vous changez l'image le long de l'axe des signes!
Résumé
Ce projet démontre une nouvelle méthode de gestion d'un modèle génératif sans enseignant, comme le GAN (Generative adversarial network). À l'aide d'un générateur GAN pré-formé (pg-GAN de Nvidia), j'ai rendu transparent son espace caché en montrant les axes des caractéristiques significatives. Lorsqu'un vecteur se déplace le long d'un tel axe dans un espace caché, l'image correspondante est transformée le long de cette fonction, offrant une synthèse et une édition contrôlées.
Cette méthode présente des avantages évidents:
- Efficacité: pour ajouter un nouveau tuner de tag pour le générateur, vous n'avez pas besoin de recycler le modèle GAN, donc l'ajout de tuners pour 40 tags prend moins d'une heure.
- Flexibilité: vous pouvez utiliser n'importe quel extracteur d'entités formé sur n'importe quel ensemble de données, ajoutant plus de fonctionnalités à un GAN bien formé.
Quelques mots sur l'éthique
Ce travail vous permet de contrôler la génération d'images en détail, mais cela dépend encore largement des caractéristiques de l'ensemble de données. Une formation sur des photos de stars d'Hollywood signifie que le modèle générera très bien des photos de personnes principalement blanches et attrayantes. Cela conduira au fait que les utilisateurs pourront créer des visages représentant seulement une petite partie de l'humanité. Si vous déployez ce service en tant qu'application réelle, il est conseillé d'étendre l'ensemble de données d'origine pour prendre en compte la diversité de nos utilisateurs.
Bien que l'outil puisse grandement aider dans le processus de création, vous devez vous rappeler des possibilités de l'utiliser à des fins inconvenantes. Si nous créons des visages réalistes de tout type, dans quelle mesure pouvons-nous faire confiance à la personne que nous voyons à l'écran? Aujourd'hui, il est important de discuter de questions de ce type. Comme nous l'avons vu dans des exemples récents de technologie
Deepfake , l'IA progresse rapidement, il est donc vital pour l'humanité d'entamer une discussion sur la meilleure façon de déployer de telles applications.
Démo et code en ligne
Tous les codes et les démos en ligne de ce travail sont disponibles sur
la page GitHub .
Si vous voulez jouer avec le modèle dans le navigateur
Vous n'avez pas besoin de télécharger de code, de modèle ou de données. Suivez simplement les instructions de
cette section Lisez
- moi. Vous pouvez changer les visages dans le navigateur comme indiqué dans la vidéo.
Si vous voulez essayer le code
Accédez simplement à la page Lisez-moi du référentiel GitHub. Code compilé sur Anaconda Python 3.6 avec Tensorflow et Keras.
Si vous souhaitez contribuer
Bienvenue N'hésitez pas à soumettre une demande de pool ou à signaler un problème sur GitHub.
À propos de moi
J'ai récemment obtenu un doctorat en neurobiologie computationnelle et cognitive de l'Université Brown et une maîtrise en informatique, avec une spécialisation en apprentissage automatique. Dans le passé, j'ai étudié comment les neurones du cerveau traitent collectivement les informations pour atteindre des fonctions de haut niveau telles que la perception visuelle. J'aime l'approche algorithmique de l'analyse, de la simulation et de la mise en œuvre de l'intelligence, ainsi que l'utilisation de l'IA pour résoudre des problèmes complexes du monde réel. Je suis activement à la recherche d'un emploi en tant que chercheur ML / AI dans l'industrie technologique.
Remerciements
Ce travail a été réalisé en trois semaines en tant que projet pour
le programme de bourses InSight AI . Je remercie le directeur du programme
Emmanuel Amaisen et
Matt Rubashkin pour la direction générale, en particulier Emmanuel pour ses suggestions et la rédaction de l'article. Je remercie également tous les employés d'Insight pour l'excellent environnement d'apprentissage et les autres participants au programme Insight AI dont j'ai beaucoup appris.
Un merci spécial à Rubin Xia pour les nombreux conseils et l'inspiration lorsque j'ai décidé dans quelle direction développer le projet, et pour l'énorme aide dans la structuration et l'édition de cet article.