De quoi parlent les «big data» de la ville? Comment les présenter clairement et - plus important encore - comment améliorer la vie des citoyens avec leur aide?
Nous en avons parlé avec
Andrei Karmatsky , PDG d'
Urbica . L'entreprise est spécialisée dans la visualisation de données urbaines. Parmi ses projets figurent une refonte de la carte pour MAPS.ME, une visualisation interactive des statistiques de voyage pour Velobike et une visualisation pour le lancement du système de transport terrestre Magistral.
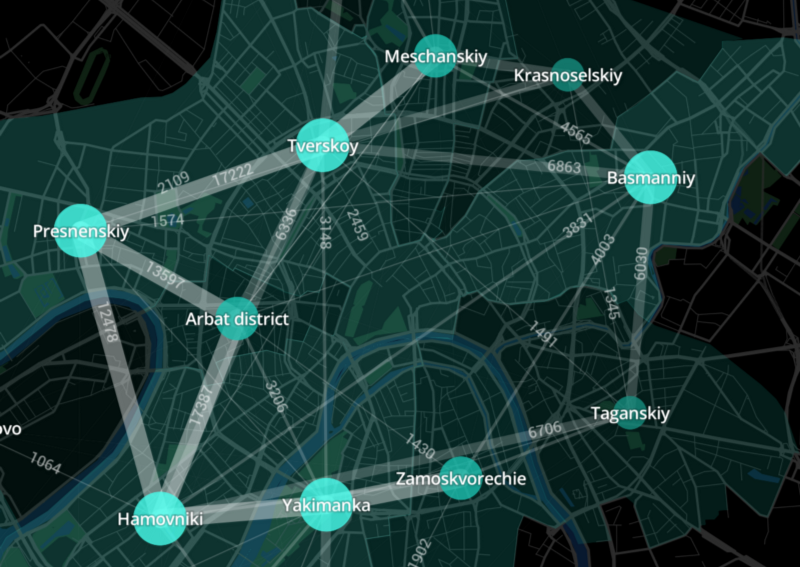 Circulation à vélo entre les zones du centre de Moscou. Source de l'image - Medium Urbiki Blog
Circulation à vélo entre les zones du centre de Moscou. Source de l'image - Medium Urbiki Blog
 Dans bon nombre de ses projets, Urbica suit les mouvements de personnes à l'intérieur de la ville. Quels types de données utilisez-vous?
Dans bon nombre de ses projets, Urbica suit les mouvements de personnes à l'intérieur de la ville. Quels types de données utilisez-vous?Nous ne collectons pas de données par nous-mêmes. Pour chaque projet, nous utilisons les données clients ou organisons leur collecte (par exemple, des études de terrain et des observations de rue pour la validation des données).
Pour visualiser les trajets vers Yandex.Taxi, nous avons utilisé des données sur les transferts en taxi, pour «Velobike», nous avons utilisé des données anonymes sur les mouvements des utilisateurs de services, pour la planification des transports du réseau de routes de transport terrestre Magistral, des données sur les mouvements de passagers sur les véhicules, les données des opérateurs mobiles, données de télémétrie du trafic des véhicules (tous les bus, trolleybus et tramways sont équipés de capteurs GLONASS).
Naturellement, les données qui nous sont transmises sont déjà agrégées et ne violent pas la législation sur les données personnelles.
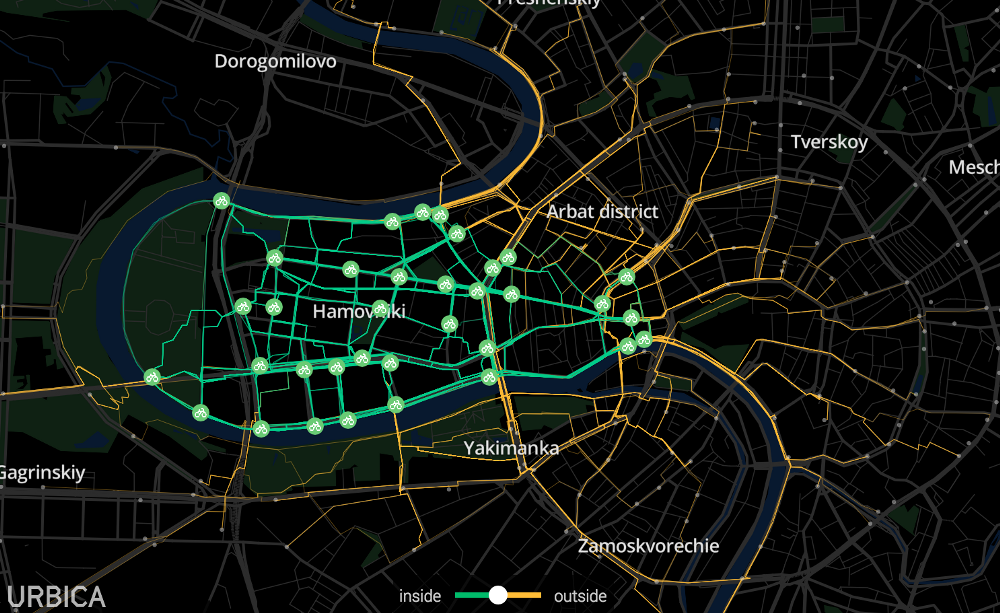
La carte interactive vit sur urbica.co/bikes
Notre histoire avec Velobike a commencé par une visualisation du mouvement des vélos à la fin de la saison pour un stand au Moscow Urban Forum. Ces visualisations ont également été utilisées pour le projet spécial «Affiches» en ligne.
Après avoir visualisé les données, nous avons trouvé beaucoup de choses intéressantes: nous avons clairement montré comment les scénarios d'utilisation de vélos de location à différents tarifs, à différents moments de la journée, dans différents quartiers de la ville diffèrent. En termes simples, la visualisation des données (jusqu'à présent, toute l'analyse était chez Velobike était dans Excel) a permis de voir la différence entre la station de location dans le centre-ville et, par exemple, près du parc Bitsevsky - ce sont des scénarios complètement différents pour l'utilisation d'un vélo, et, par conséquent, , divers modèles de demande.
Parmi les observations intéressantes dans les données, nous avons vu un problème qui peut être résolu à l'aide de l'analyse. La demande à la station de location de vélos est inégale. Cela signifie que vous pouvez venir à la gare et ne pas trouver de vélos gratuits ou ne pas trouver d'espace libre pour garer un vélo déjà loué. Velobike résout ce problème avec une petite flotte de camions qui rééquilibrent le système de location entre 450 stations. Nous avons décidé de développer un système de prévision de la demande et de l'implémenter dans le processus de répartition des chauffeurs afin d'améliorer le service de location en ville et d'optimiser les coûts de maintenance.
Comment fonctionne le système prédictif pour les répartiteurs Velobike? Quelles méthodes y sont utilisées pour les calculs?Pour créer un modèle de prévision de la demande de vélos, nous avons utilisé les statistiques de charge de la station (combien de vélos sont disponibles) pour toutes les saisons précédentes, classé les quartiers de la ville par des signes de changements de densité de population et d'emplois à différents jours de la semaine et de l'heure, pris en compte la topographie (elle affecte grandement l'équilibre des départs Arrivée des cyclistes à la gare). Le modèle prédictif utilise la méthode XGBoost et donne la valeur prédite de la charge de la station (demande potentielle) pour une heure à l'avance - c'est pendant cet intervalle de temps que le conducteur peut arriver à la station et ramasser ou apporter des vélos.
Pour communiquer avec le système, les conducteurs devaient utiliser le chatbot dans Telegram. Avez-vous dû changer votre façon de communiquer à cause des verrous?Nous avons prévu d'introduire un chatbot pour les pilotes système cet été afin de ne pas impliquer le répartiteur dans ce processus, car le modèle ne nécessite dans la plupart des cas aucune participation humaine. Malheureusement, en raison de blocages ce printemps, le chat bot n'a pas été introduit.
Quelles autres données urbaines est-il sensé de parcourir des algorithmes similaires? Où sera-t-il le plus avantageux?Ce modèle particulier, semble-t-il, ne peut être appliqué qu'aux stations de location de vélos, mais il y a beaucoup de tâches intéressantes dans la ville où l'analyse des données pourrait aider. Par exemple, nous trouvons intéressant d'identifier les itinéraires de transport terrestre sous-optimaux et de créer un réseau d'itinéraires plus efficace.
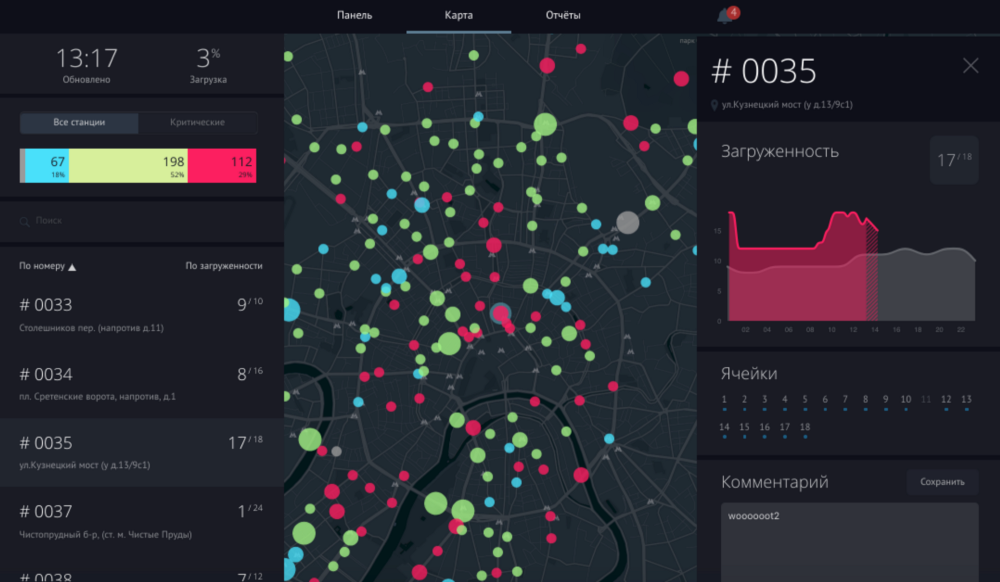
Interface de répartition générale
Urbica est l' un des exposants à AI Conference:
«Nous montrerons les outils et technologies permettant de visualiser de grandes quantités de données que nous avons développées et utilisées dans notre entreprise. Ce sera intéressant pour les entreprises qui ont pour tâche d'analyser visuellement de grandes quantités d'informations. "
Parlons du volet design de votre travail. Quelles sont les tendances dans le domaine de la visualisation des données? Quel design semble visiblement dépassé?La question n'est probablement pas sur la conception, mais plutôt sur la commodité et le contenu de l'information. Les interfaces analytiques, où la visualisation est nécessaire, résolvent principalement les problèmes appliqués et l'objectif principal de la conception d'interfaces avec de grands ensembles de données est de créer des outils pratiques pour résoudre le problème.
Étant engagé dans la visualisation de données, il est très facile d'oublier la tâche d'origine et de se laisser emporter par le processus de visualisation lui-même. Beaucoup de bons projets avec des données de ville doivent être considérés comme de l'art des données, c'est un chemin différent et le but de la visualisation est différent.
Évaluez le travail de vos collègues: quels projets intéressants dans votre région sont sortis récemment?
Nous aimons vraiment le travail des collègues de l'équipe de visualisation Uber. Ils ont créé leur propre outil de visualisation de données
Kepler.GL , l'ont rendu accessible à tous les utilisateurs et ont publié son code en open-source.
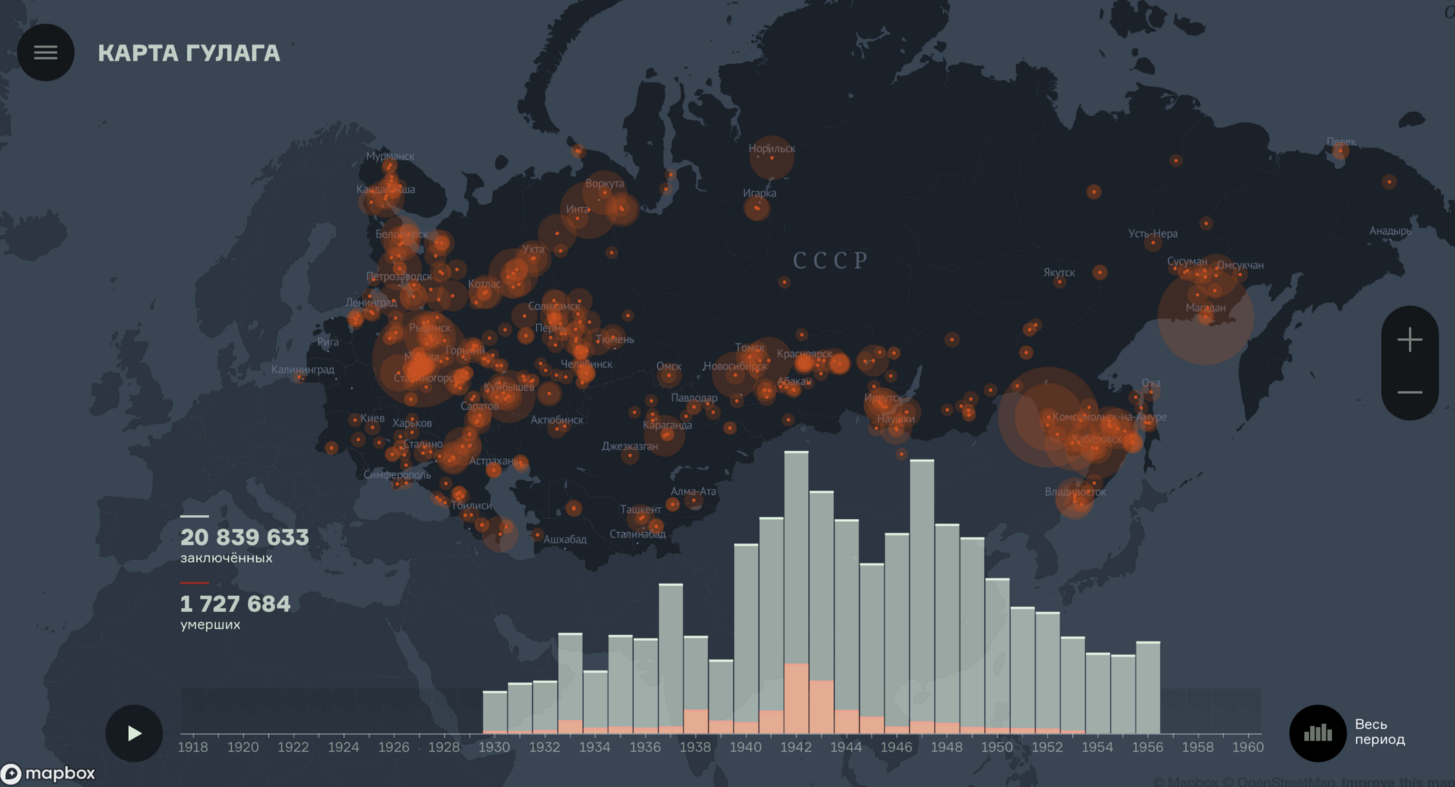 L'élaboration d'une carte interactive du Goulag a pris deux ans. Voir gulagmap.ruParmi tous vos projets à la fois thématiques et par le temps passé, un projet avec une carte interactive GULAG se démarque. Quelle était la différence entre le processus de travail dessus?
L'élaboration d'une carte interactive du Goulag a pris deux ans. Voir gulagmap.ruParmi tous vos projets à la fois thématiques et par le temps passé, un projet avec une carte interactive GULAG se démarque. Quelle était la différence entre le processus de travail dessus?Le travail du Musée d'État de l'histoire du Goulag pour créer une carte interactive des camps est très important pour nous. L'utilisateur final de cette carte ou un visiteur du musée (cette carte sera présentée dans l'exposition mise à jour en décembre) regarde la carte et ne voit qu'un curseur temporaire et des statistiques sur le nombre de prisonniers changeant au fil des ans. Il s'agit de la couche la plus haute du projet. Pour créer cette interface, il a fallu collecter une grande quantité de données qui jusqu'à ce moment n'existaient que sur papier. En collaboration avec le département scientifique du musée, nous avons développé une base de données spéciale et des outils de collecte de données pour transférer des informations des archives vers une carte. Ce projet est également important sur le plan social - de cette manière, nous pouvons attirer l'attention sur l'histoire de notre pays. Vous devez savoir des choses aussi terribles que le Goulag, elles ne peuvent pas être oubliées.
Quels changements le projet a-t-il subis de la première version à la finale?
L'interface de la carte elle-même et le style ont peut-être légèrement changé. Nous avons créé un prototype et développé des interfaces utilisateurs en itérations successives. Mais le contenu interne du projet a beaucoup changé - la première version n'impliquait pas de système de remplissage des données dans la base de données. Au cours du projet, nous avons étudié avec le musée, appris de nouveaux besoins et opportunités pour améliorer le "remplissage" de la carte.
Vous avez développé votre propre composant pour cette carte, React Map GL. Pourquoi est-ce mieux que des solutions toutes faites?Nous utilisons activement les technologies de Mapbox, il fournit les meilleurs outils, à mon avis, pour les développeurs de projets cartographiques. Dans le même temps, nous utilisons React.js sur le frontend. Nous avons examiné les solutions cartographiques Mapbox existantes dans React.js et réalisé que nous avions besoin de notre propre composant.
À peu près la même chose s'est produite avec le projet de visualisation des données de l'étude des agglomérations urbaines: nous avons vu que les solutions prêtes à l'emploi existantes ne nous convenaient pas et avons développé notre propre
serveur de tuiles vectorielles , que nous démontrerons lors de la
conférence AI .
Quelles technologies utilisez-vous le plus souvent dans votre travail?Comme je l'ai déjà dit, pour le développement frontal est React / Redux, pour le backend est Node.js / Rust / Python, pour l'analyse des données - Pyhton, pour le stockage et le géotraitement des données - PostgreSQL / PostGIS. Il n'y a probablement pas de technologies super-exotiques ici.
Qu'est-ce qui est le plus important pour vous dans votre travail? Quel défi mondial essayez-vous de résoudre?
Le plus important est de porter de la valeur et de voir les résultats de votre travail dans l'espace urbain environnant: un musée, une location de vélos ou les transports en commun. L'idée de base de créer «Urbiki» est restée inchangée - nous créons des interfaces dans lesquelles les tableaux de données complexes deviennent compréhensibles et faciles à comprendre.