L'apprentissage automatique est de plus en plus accessible, il y a plus d'opportunités d'appliquer cette technologie en utilisant des «composants standard». Par exemple, Transfer Learning vous permet d'utiliser l'expérience acquise dans la résolution d'un problème pour résoudre un autre problème similaire. Le réseau neuronal est d'abord entraîné sur une grande quantité de données, puis sur l'ensemble cible.

Dans cet article, je vais vous expliquer comment utiliser la méthode Transfer Learning en utilisant l'exemple de reconnaissance d'images avec des aliments. Je parlerai d'autres outils de machine learning lors de
l' atelier
Machine Learning and Neural Networks for Developers .
Si nous sommes confrontés à la tâche de reconnaissance d'image, vous pouvez utiliser le service prêt à l'emploi. Cependant, si vous devez entraîner le modèle sur votre propre ensemble de données, vous devrez le faire vous-même.
Pour des tâches typiques telles que la classification d'images, vous pouvez utiliser l'architecture prête à l'emploi (AlexNet, VGG, Inception, ResNet, etc.) et former le réseau neuronal sur vos données. Des implémentations de tels réseaux utilisant différents cadres existent déjà, donc à ce stade, vous pouvez utiliser l'un d'entre eux comme une boîte noire, sans approfondir le principe de son fonctionnement.
Cependant, les réseaux de neurones profonds exigent de grandes quantités de données pour la convergence de l'apprentissage. Et souvent, dans notre tâche particulière, il n'y a pas suffisamment de données pour former correctement toutes les couches du réseau neuronal. Transfer Learning résout ce problème.
Transfert d'apprentissage pour la classification d'images
Les réseaux de neurones utilisés pour la classification contiennent généralement
N neurones de sortie dans la dernière couche, où
N est le nombre de classes. Un tel vecteur de sortie est traité comme un ensemble de probabilités d'appartenance à une classe. Dans notre tâche de reconnaissance des images d'aliments, le nombre de classes peut différer de celui de l'ensemble de données d'origine. Dans ce cas, nous devrons jeter complètement cette dernière couche et en mettre une nouvelle, avec le bon nombre de neurones de sortie
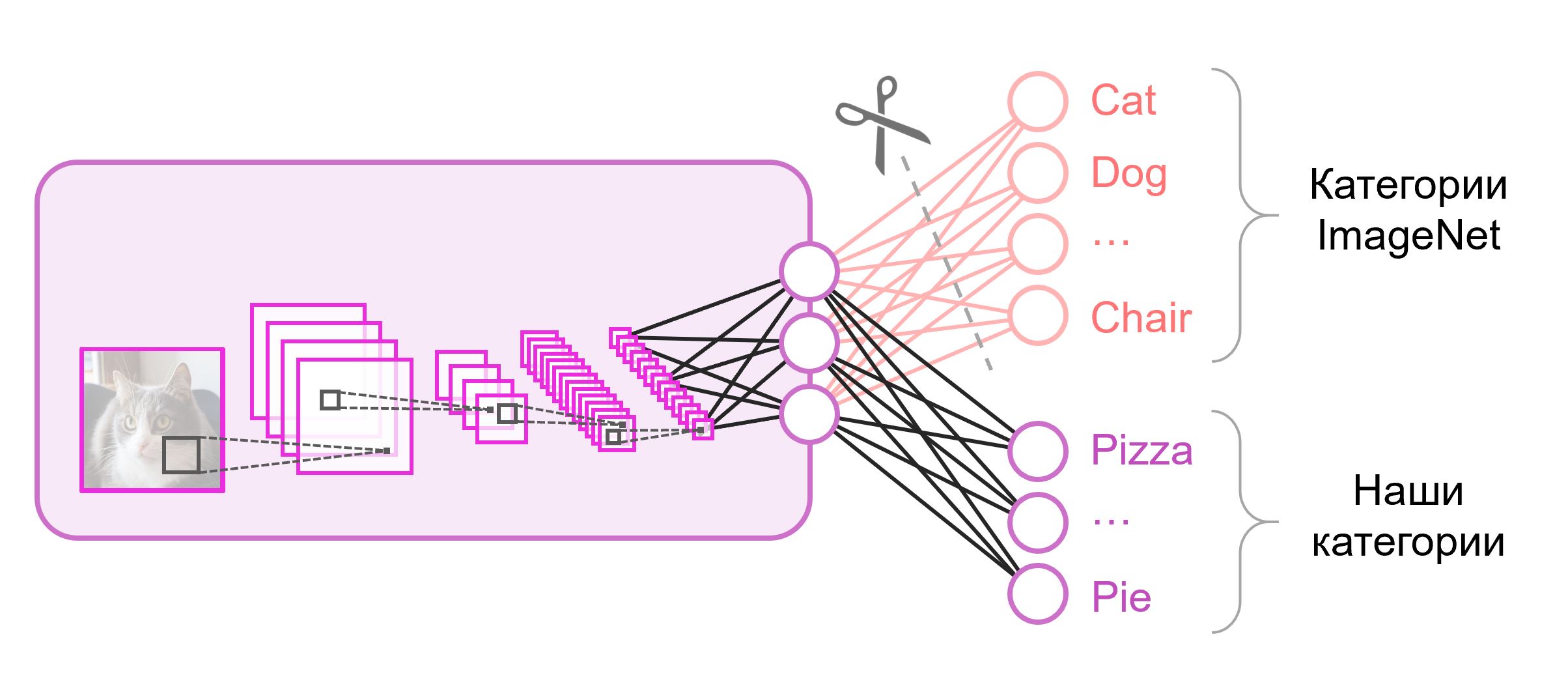
Souvent, à la fin des réseaux de classification, une couche entièrement connectée est utilisée. Depuis que nous avons remplacé cette couche, l'utilisation de poids pré-formés ne fonctionnera pas. Vous devrez l'entraîner à partir de zéro, en initialisant ses poids avec des valeurs aléatoires. Nous chargeons des poids pour toutes les autres couches à partir d'un instantané pré-formé.
Il existe différentes stratégies pour perfectionner le modèle. Nous utiliserons ce qui suit: nous formerons l'ensemble du réseau de bout en bout (de
bout en bout ), et nous ne fixerons pas les poids pré-formés pour leur permettre de s'ajuster un peu et de s'adapter à nos données. Ce processus est appelé
réglage fin .
Composants structurels
Pour résoudre le problème, nous avons besoin des composants suivants:
- Description du modèle de réseau neuronal
- Pipeline d'apprentissage
- Pipeline d'interférence
- Poids pré-formés pour ce modèle
- Données pour la formation et la validation
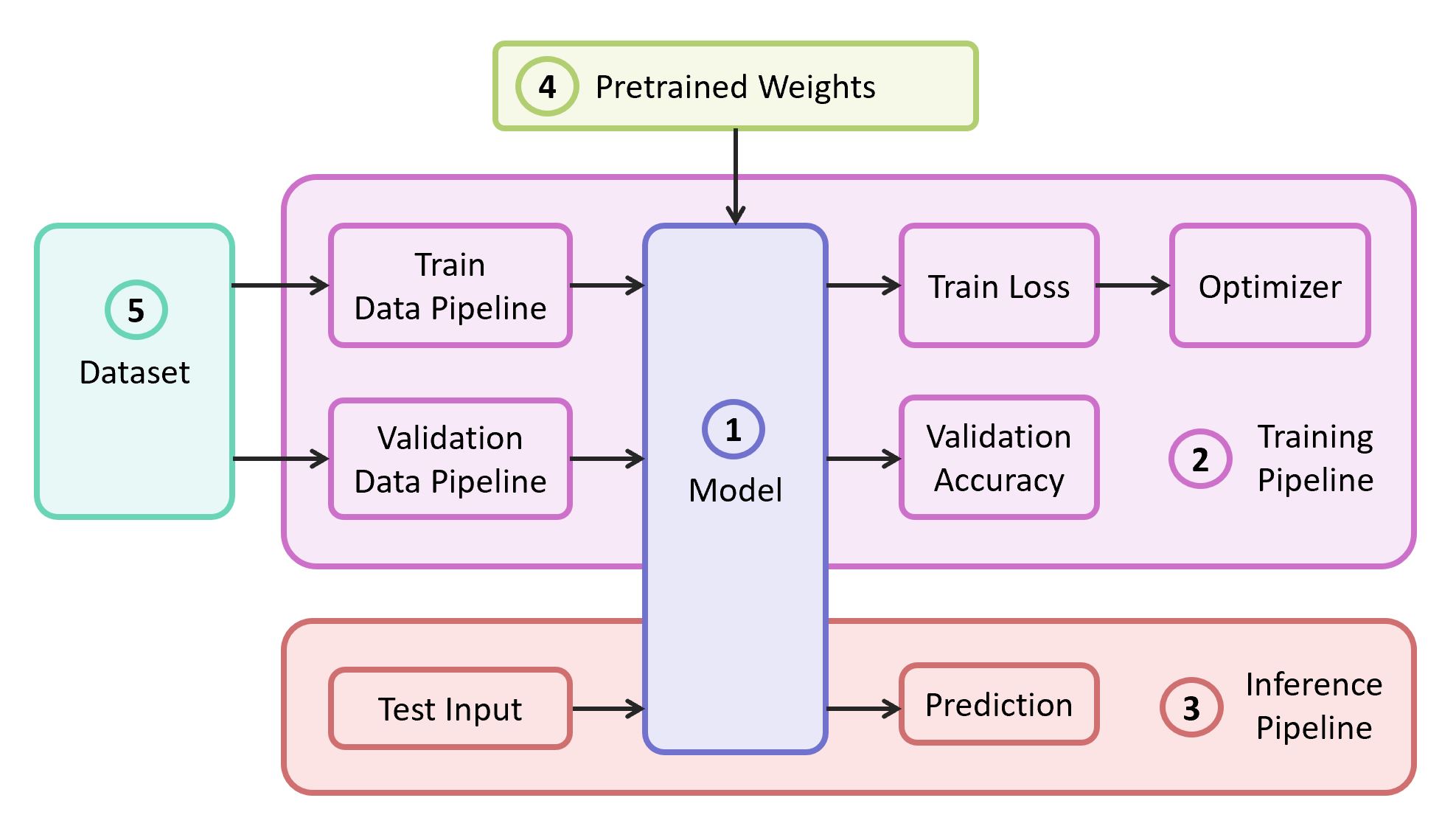
Dans notre exemple, je prendrai les composants (1), (2) et (3) de
mon propre référentiel , qui contient le code le plus léger - vous pouvez facilement le comprendre si vous le souhaitez. Notre exemple sera implémenté sur le framework
TensorFlow populaire. Des poids pré-formés (4) adaptés au cadre sélectionné peuvent être trouvés s'ils correspondent à l'une des architectures classiques. En tant qu'ensemble de données (5) pour la démonstration, je prendrai
Food-101 .
Modèle
Comme modèle, nous utilisons le réseau neuronal
VGG classique (plus précisément
VGG19 ). Malgré certains inconvénients, ce modèle présente une qualité assez élevée. De plus, il est facile à analyser. Sur TensorFlow Slim, la description du modèle semble assez compacte:
import tensorflow as tf import tensorflow.contrib.slim as slim def vgg_19(inputs, num_classes, is_training, scope='vgg_19', weight_decay=0.0005): with slim.arg_scope([slim.conv2d], activation_fn=tf.nn.relu, weights_regularizer=slim.l2_regularizer(weight_decay), biases_initializer=tf.zeros_initializer(), padding='SAME'): with tf.variable_scope(scope, 'vgg_19', [inputs]): net = slim.repeat(inputs, 2, slim.conv2d, 64, [3, 3], scope='conv1') net = slim.max_pool2d(net, [2, 2], scope='pool1') net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], scope='conv2') net = slim.max_pool2d(net, [2, 2], scope='pool2') net = slim.repeat(net, 4, slim.conv2d, 256, [3, 3], scope='conv3') net = slim.max_pool2d(net, [2, 2], scope='pool3') net = slim.repeat(net, 4, slim.conv2d, 512, [3, 3], scope='conv4') net = slim.max_pool2d(net, [2, 2], scope='pool4') net = slim.repeat(net, 4, slim.conv2d, 512, [3, 3], scope='conv5') net = slim.max_pool2d(net, [2, 2], scope='pool5')
Les poids pour VGG19, formés sur ImageNet et compatibles avec TensorFlow, sont téléchargés à partir du référentiel sur GitHub à partir de la section
Modèles pré-formés .
mkdir data && cd data wget http://download.tensorflow.org/models/vgg_19_2016_08_28.tar.gz tar -xzf vgg_19_2016_08_28.tar.gz
Datacet
En tant qu'échantillon de formation et de validation, nous utiliserons l'ensemble de données public
Food-101 , qui contient plus de 100 000 images d'aliments, réparties en 101 catégories.

Téléchargez et décompressez l'ensemble de données:
cd data wget http://data.vision.ee.ethz.ch/cvl/food-101.tar.gz tar -xzf food-101.tar.gz
Le pipeline de données de notre formation est conçu de sorte que, à partir de l'ensemble de données, nous devons analyser les éléments suivants:
- Liste des classes (catégories)
- Tutoriel: liste des chemins d'accès aux images et une liste de bonnes réponses
- Ensemble de validation: liste des chemins d'accès aux images et liste des bonnes réponses
Si votre ensemble de données, alors pour le
train et la
validation, vous devez casser les ensembles vous-même. Food-101 possède déjà une telle partition, et ces informations sont stockées dans le répertoire
meta .
DATASET_ROOT = 'data/food-101/' train_data, val_data, classes = data.food101(DATASET_ROOT) num_classes = len(classes)
Toutes les fonctions auxiliaires responsables du traitement des données sont déplacées vers un fichier
data.py distinct:
data.py from os.path import join as opj import tensorflow as tf def parse_ds_subset(img_root, list_fpath, classes): ''' Parse a meta file with image paths and labels -> img_root: path to the root of image folders -> list_fpath: path to the file with the list (eg train.txt) -> classes: list of class names <- (list_of_img_paths, integer_labels) ''' fpaths = [] labels = [] with open(list_fpath, 'r') as f: for line in f: class_name, image_id = line.strip().split('/') fpaths.append(opj(img_root, class_name, image_id+'.jpg')) labels.append(classes.index(class_name)) return fpaths, labels def food101(dataset_root): ''' Get lists of train and validation examples for Food-101 dataset -> dataset_root: root of the Food-101 dataset <- ((train_fpaths, train_labels), (val_fpaths, val_labels), classes) ''' img_root = opj(dataset_root, 'images') train_list_fpath = opj(dataset_root, 'meta', 'train.txt') test_list_fpath = opj(dataset_root, 'meta', 'test.txt') classes_list_fpath = opj(dataset_root, 'meta', 'classes.txt') with open(classes_list_fpath, 'r') as f: classes = [line.strip() for line in f] train_data = parse_ds_subset(img_root, train_list_fpath, classes) val_data = parse_ds_subset(img_root, test_list_fpath, classes) return train_data, val_data, classes def imread_and_crop(fpath, inp_size, margin=0, random_crop=False): ''' Construct TF graph for image preparation: Read the file, crop and resize -> fpath: path to the JPEG image file (TF node) -> inp_size: size of the network input (eg 224) -> margin: cropping margin -> random_crop: perform random crop or central crop <- prepared image (TF node) ''' data = tf.read_file(fpath) img = tf.image.decode_jpeg(data, channels=3) img = tf.image.convert_image_dtype(img, dtype=tf.float32) shape = tf.shape(img) crop_size = tf.minimum(shape[0], shape[1]) - 2 * margin if random_crop: img = tf.random_crop(img, (crop_size, crop_size, 3)) else:
Formation modèle
Le modèle de code de formation comprend les étapes suivantes:
- Construction de pipelines de données de train / validation
- Construction de graphiques de train / validation (réseaux)
- Fixation de la fonction de classification des pertes ( perte d'entropie croisée ) sur le graphique du train
- Le code nécessaire pour calculer la précision des prédictions sur l'échantillon de validation pendant la formation
- Logique pour charger des balances pré-entraînées à partir d'un instantané
- Création de différentes structures de formation
- Le cycle d'apprentissage lui-même (optimisation itérative)
La dernière couche du graphique est construite avec le nombre de neurones requis et est exclue de la liste des paramètres chargés à partir de l'instantané pré-formé.
Code de formation modèle import numpy as np import tensorflow as tf import tensorflow.contrib.slim as slim tf.logging.set_verbosity(tf.logging.INFO) import model import data
Après avoir commencé la formation, vous pouvez regarder sa progression à l'aide de l'utilitaire TensorBoard, qui est fourni avec TensorFlow et sert à visualiser diverses mesures et autres paramètres.
tensorboard --logdir checkpoints/
À la fin de la formation à TensorBoard, nous voyons une image presque parfaite: une diminution de
la perte de train et une augmentation de la
précision de validation
En conséquence, nous obtenons l'instantané enregistré dans
checkpoints/vgg19_food , que nous utiliserons lors des tests de notre modèle (
inférence ).
Test de modèle
Testez maintenant notre modèle. Pour ce faire:
- Nous construisons un nouveau graphique spécialement conçu pour l'inférence (
is_training=False ) - Charger des poids formés à partir d'un instantané
- Téléchargez et prétraitez l'image de test d'entrée.
- Conduisons l'image à travers le réseau neuronal et obtenons la prédiction
inference.py import sys import numpy as np import imageio from skimage.transform import resize import tensorflow as tf import model
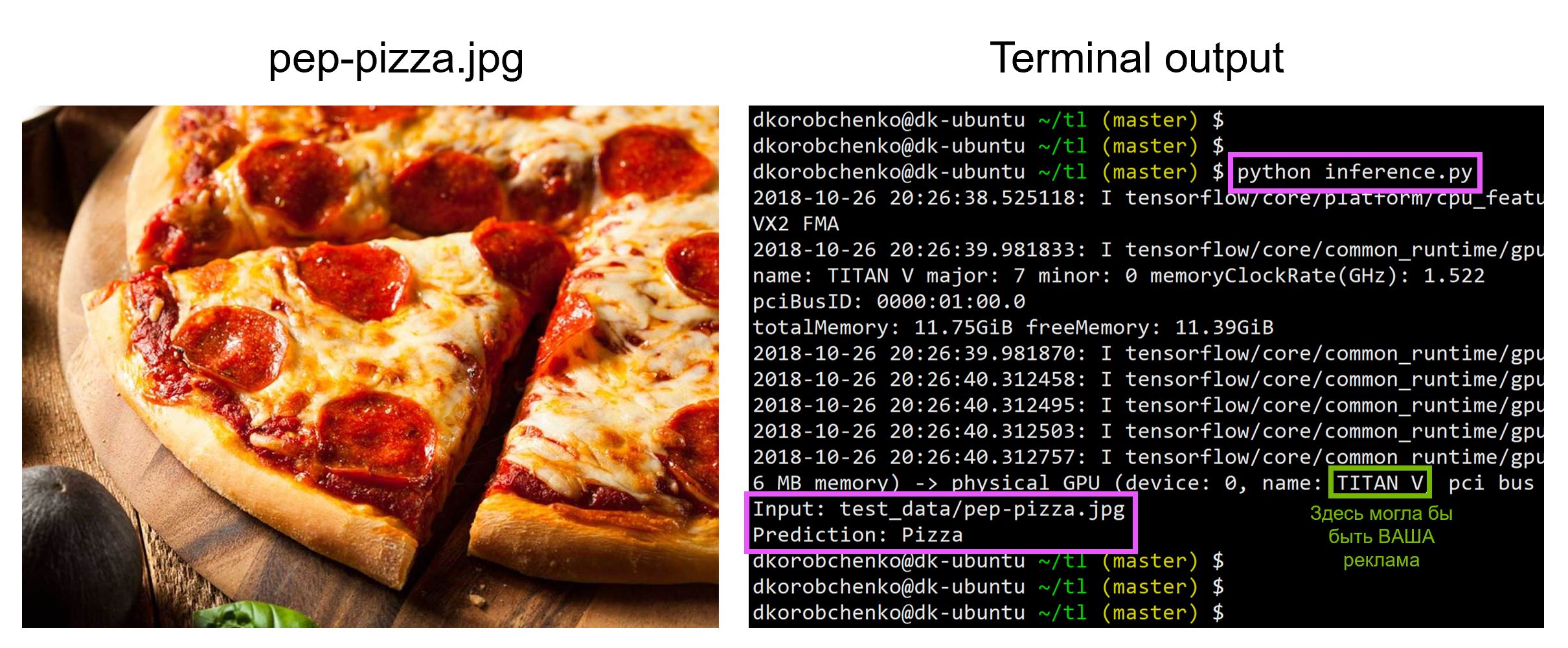
Tout le code, y compris les ressources pour créer et exécuter un conteneur Docker avec toutes les versions nécessaires des bibliothèques, se trouve dans
ce référentiel - au moment de la lecture de l'article, le code dans le référentiel peut avoir des mises à jour.
Lors de l'atelier
«Apprentissage automatique et réseaux de neurones pour les développeurs» , j'analyserai d'autres tâches d'apprentissage automatique et les étudiants présenteront leurs projets d'ici la fin de la session intensive.