
Lors de la conférence sur l'IA,
Vladimir Ivanov vivanov879 , Sr. parlera de l'utilisation de l'apprentissage renforcé
Ingénieur Deep Learning chez Nvidia . L'expert est engagé dans le machine learning au sein du département de test: «J'analyse les données que nous collectons lors des tests de jeux vidéo et de matériel. Pour cela, j'utilise l'apprentissage automatique et la vision par ordinateur. L'essentiel du travail est l'analyse d'images, le nettoyage des données avant la formation, le balisage des données et la visualisation des solutions obtenues. »
Dans l'article d'aujourd'hui, Vladimir explique pourquoi l'apprentissage renforcé est utilisé dans les voitures autonomes et explique comment un agent est formé pour agir dans un environnement en mutation - à l'aide d'exemples de jeux vidéo.
Au cours des dernières années, l'humanité a accumulé une énorme quantité de données. Certains jeux de données sont partagés et présentés manuellement. Par exemple, l'ensemble de données CIFAR, où chaque image est signée, à quelle classe elle appartient.
Il existe des ensembles de données où vous devez affecter une classe non seulement à l'image dans son ensemble, mais à chaque pixel de l'image. Comme, par exemple, dans CityScapes.

Ce qui unit ces tâches, c'est qu'un réseau de neurones d'apprentissage n'a qu'à se souvenir des schémas des données. Par conséquent, avec des quantités de données suffisamment importantes, et dans le cas du CIFAR, il s'agit de 80 millions d'images, le réseau neuronal apprend à se généraliser. En conséquence, elle gère bien la classification des images qu'elle n'avait jamais vues auparavant.
Mais agissant dans le cadre de la technique pédagogique avec l'enseignant, qui travaille pour le marquage des images, il est impossible de résoudre des problèmes où l'on ne veut pas prédire l'étiquette mais prendre des décisions. Comme, par exemple, dans le cas de la conduite autonome, où la tâche consiste à atteindre de manière sûre et fiable le point final de l'itinéraire.
Dans les problèmes de classification, nous avons utilisé la technique d'enseignement avec l'enseignant - lorsque chaque image est affectée à une classe spécifique. Mais que se passe-t-il si nous n'avons pas un tel balisage, mais qu'il existe un agent et un environnement dans lesquels il peut effectuer certaines actions? Par exemple, que ce soit un jeu vidéo, nous pouvons cliquer sur les flèches de contrôle.

Ce type de problème devrait être résolu par une formation de renforcement. Dans l'énoncé général du problème, nous voulons apprendre à effectuer la séquence correcte d'actions. Il est fondamentalement important que l'agent ait la capacité d'exécuter des actions encore et encore, explorant ainsi l'environnement dans lequel il se trouve. Et au lieu de la bonne réponse, que faire dans une situation particulière, il reçoit une récompense pour une tâche correctement accomplie. Par exemple, dans le cas d'un taxi autonome, le chauffeur recevra un bonus pour chaque trajet effectué.
Revenons à un exemple simple - un jeu vidéo. Prenez quelque chose de simple, comme le jeu de tennis de table Atari.
Nous contrôlerons la tablette à gauche. Nous jouerons contre le joueur informatique programmé sur les règles à droite. Étant donné que nous travaillons avec une image et que les réseaux de neurones sont les plus efficaces pour extraire des informations à partir d'images, appliquons une image à l'entrée d'un réseau de neurones à trois couches avec une taille de noyau 3x3. A la sortie, elle devra choisir l'une des deux actions: déplacer le plateau vers le haut ou vers le bas.
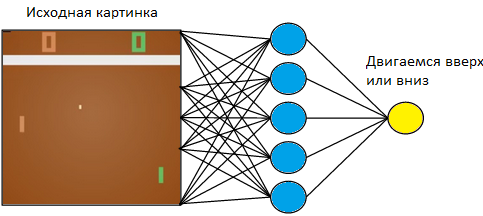
Nous formons le réseau neuronal pour effectuer des actions qui mènent à la victoire. La technique d'entraînement est la suivante. Nous avons laissé le réseau neuronal jouer quelques parties de tennis de table. Ensuite, nous commençons à trier les jeux joués. Dans ces jeux où elle a gagné, nous marquons les images étiquetées «Up» où elle a soulevé la raquette et «Down» où elle l'a abaissée. Dans les matchs perdus, nous faisons le contraire. Nous marquons ces photos où elle a abaissé la planche avec l'étiquette «Up», et où elle l'a soulevée, «Down». Ainsi, nous réduisons le problème à l'approche que nous connaissons déjà - la formation avec un enseignant. Nous avons un ensemble d'images avec des étiquettes.
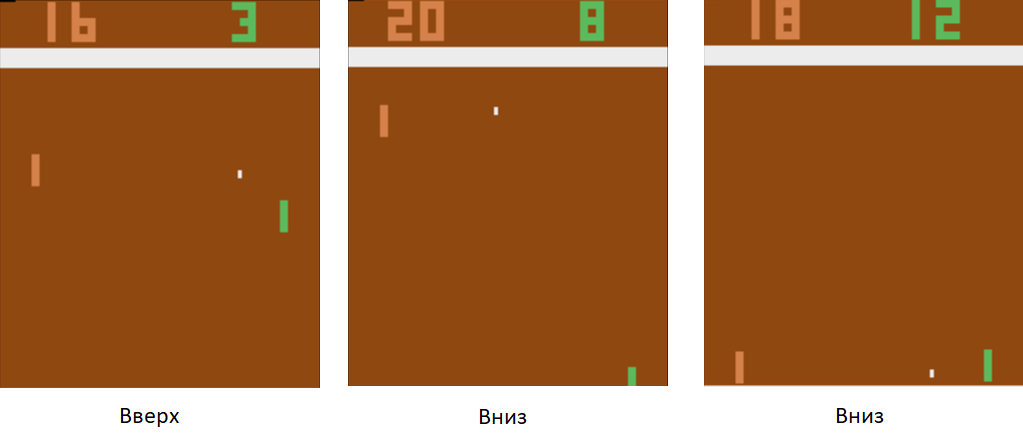
En utilisant cette technique de formation, en quelques heures, notre agent apprendra à battre un joueur d'ordinateur programmé selon les règles.
Que faire de la conduite autonome? Le fait est que le tennis de table est un jeu très simple. Et il peut produire des milliers d'images par seconde. Dans notre réseau, il n'y a maintenant que 3 couches. Par conséquent, le processus d'apprentissage est rapide comme l'éclair. Le jeu génère une énorme quantité de données et nous les traitons instantanément. Dans le cas de la conduite autonome, la collecte de données est beaucoup plus longue et plus coûteuse. Les voitures sont chères, et avec une voiture, nous ne recevrons que 60 images par seconde. De plus, le prix de l'erreur augmente. Dans un jeu vidéo, on pouvait se permettre de jouer jeu après match au tout début de l'entraînement. Mais nous ne pouvons pas nous permettre de gâcher la voiture.
Dans ce cas, aidons le réseau neuronal au tout début de l'entraînement. Nous fixons la caméra sur la voiture, y mettons un conducteur expérimenté et nous enregistrerons des photos de la caméra. Pour chaque photo, nous inscrivons l'angle de braquage de la voiture. Nous formerons le réseau neuronal à copier le comportement d'un conducteur expérimenté. Ainsi, nous avons de nouveau réduit la tâche à l'enseignement déjà connu avec un professeur.
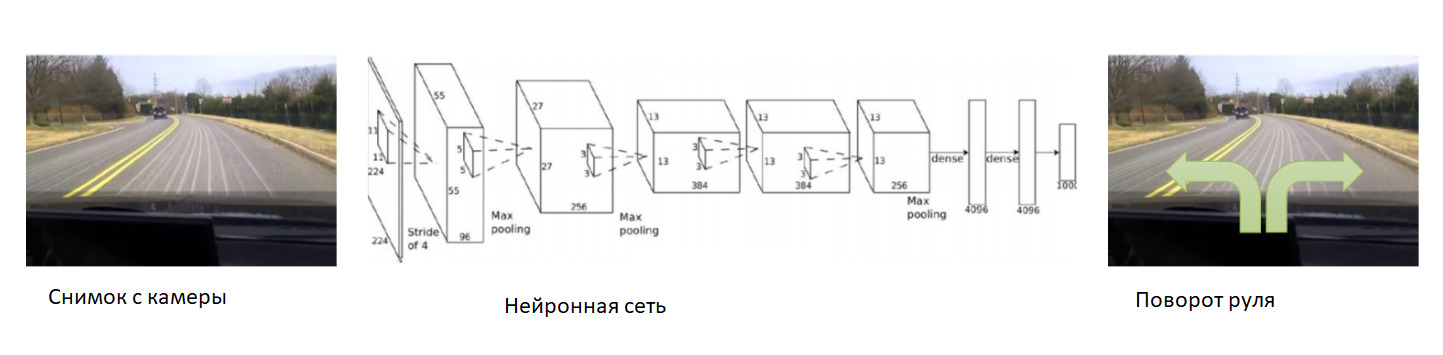
Avec un ensemble de données suffisamment grand et diversifié, qui comprendra différents paysages, saisons et conditions météorologiques, le réseau de neurones apprendra à contrôler avec précision la voiture.
Cependant, il y avait un problème avec les données. Ils sont très longs et coûteux à collecter. Utilisons un simulateur dans lequel toute la physique du mouvement de la voiture sera implémentée - par exemple, DeepDrive. Nous pouvons l'apprendre sans craindre de perdre une voiture.

Dans ce simulateur, nous avons accès à tous les indicateurs de la voiture et du monde. En outre, toutes les personnes, les voitures, leurs vitesses et leurs distances par rapport à elles sont marquées autour.

Du point de vue de l'ingénieur, dans un tel simulateur, vous pouvez essayer en toute sécurité de nouvelles techniques de formation. Que doit faire un chercheur? Par exemple, étudier différentes options de descente de gradient dans des problèmes d'apprentissage avec renforcement. Pour tester une hypothèse simple, je ne veux pas tirer sur des moineaux à partir d'un canon et exécuter un agent dans un monde virtuel complexe, puis attendre des jours consécutifs pour les résultats de la simulation. Dans ce cas, utilisons plus efficacement notre puissance de calcul. Que les agents soient plus simples. Prenons, par exemple, un modèle d'araignée à quatre pattes. Dans le simulateur Mujoco, cela ressemble à ceci:

Nous lui avons confié la tâche de courir à la vitesse la plus élevée possible dans une direction donnée - par exemple, vers la droite. Le nombre de paramètres observés pour une araignée est un vecteur à 39 dimensions, qui enregistre la position et la vitesse de tous ses membres. Contrairement au réseau neuronal pour le tennis de table, où il n'y avait qu'un seul neurone à la sortie, il y en a huit à la sortie (puisque l'araignée dans ce modèle a 8 articulations).
Dans de tels modèles simples, diverses hypothèses sur la technique d'enseignement peuvent être testées. Par exemple, comparons la vitesse d'apprentissage de l'exécution, selon le type de réseau neuronal. Que ce soit un réseau neuronal à une seule couche, un réseau neuronal à trois couches, un réseau convolutionnel et un réseau récurrent:
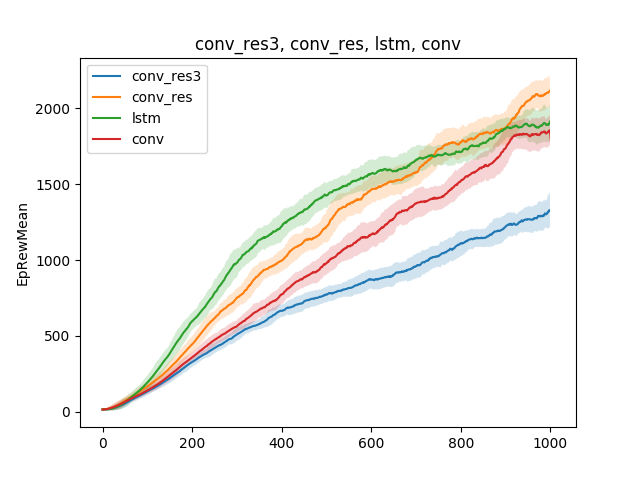
La conclusion peut être tirée comme suit: puisque le modèle d'araignée et la tâche sont assez simples, les résultats de la formation sont approximativement les mêmes pour différents modèles. Un réseau à trois couches est trop complexe et apprend donc moins bien.
Malgré le fait que le simulateur fonctionne avec un modèle d'araignée simple, selon la tâche posée à l'araignée, la formation peut durer des jours. Dans ce cas, animons plusieurs centaines d'araignées sur une surface en même temps au lieu d'une et apprenons des données que nous recevrons de tout le monde. Nous allons donc accélérer la formation de plusieurs centaines de fois. Voici un exemple du moteur Flex.
La seule chose qui a changé en termes d'optimisation du réseau neuronal est la collecte de données. Lorsque nous n'avons exécuté qu'une seule araignée, nous avons reçu des données séquentiellement. Une course après l'autre.

Maintenant, il peut arriver que certaines araignées commencent à peine la course, tandis que d'autres courent depuis longtemps.
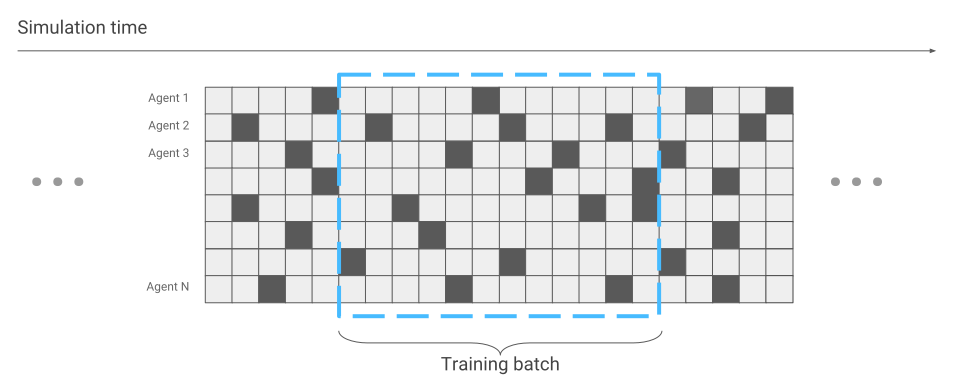
Nous en tiendrons compte lors de l'optimisation du réseau neuronal. Sinon, tout reste le même. En conséquence, nous obtenons une accélération de l'entraînement des centaines de fois, selon le nombre d'araignées qui sont simultanément sur l'écran.
Puisque nous avons un simulateur efficace, essayons de résoudre des problèmes plus complexes. Par exemple, courir sur un terrain accidenté.

Étant donné que l'environnement dans ce cas est devenu plus agressif, modifions et compliquons les tâches pendant la formation. C’est difficile à apprendre, mais facile au combat. Par exemple, toutes les quelques minutes pour changer le terrain. De plus, dirigons les agents externes vers l'agent. Par exemple, jetons des balles sur lui et tournons le vent. L'agent apprend alors à courir même sur des surfaces qu'il n'a jamais rencontrées. Par exemple, montez des escaliers.

Puisque nous avons si bien appris à courir dans les simulations, examinons les techniques d'entraînement au renforcement dans les disciplines compétitives. Par exemple, dans les jeux de tir. La plate-forme VizDoom offre un monde dans lequel vous pouvez tirer, collecter des armes et reconstituer la santé. Dans ce jeu, nous utiliserons également un réseau de neurones. Seulement maintenant, elle aura cinq sorties: quatre pour le mouvement et une pour le tir.
Pour que la formation soit efficace, prenons-la progressivement. Du simple au complexe. À l'entrée, le réseau neuronal reçoit une image, et avant de commencer à faire quelque chose de conscient, il doit apprendre à comprendre en quoi consiste le monde. En étudiant dans des scénarios simples, elle apprendra à comprendre quels objets habitent le monde et comment interagir avec eux. Commençons par le tiret:
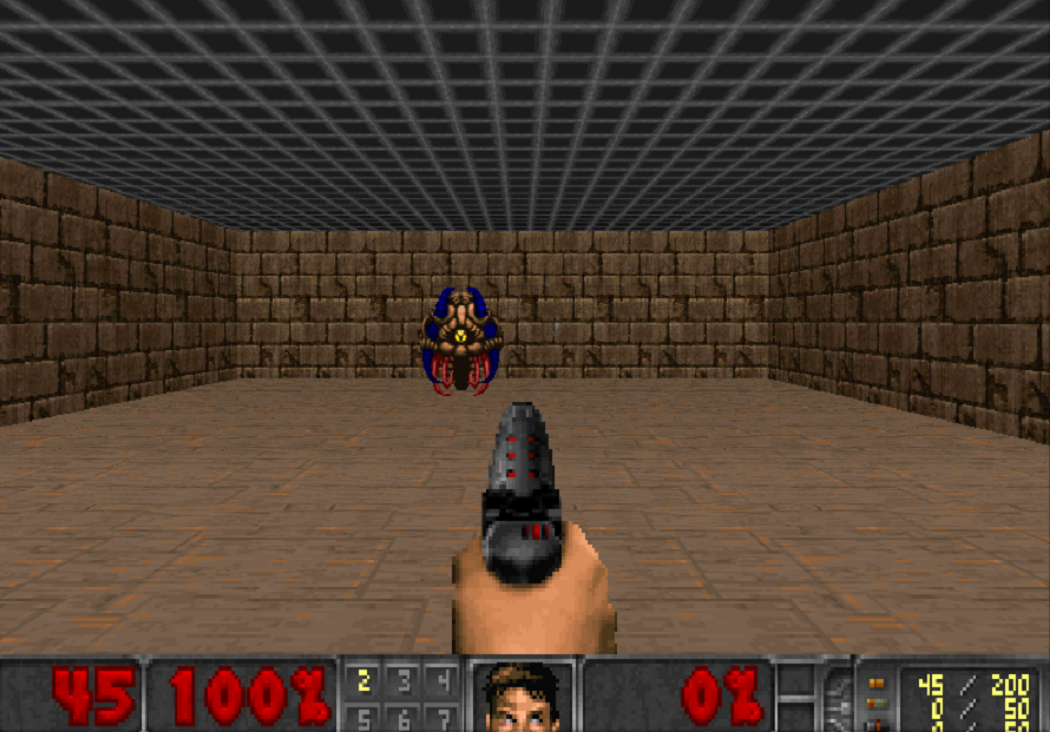
Ayant maîtrisé ce scénario, l'agent comprendra qu'il y a des ennemis, et ils devraient être abattus, car vous obtenez des points pour eux. Ensuite, nous le formerons dans un scénario où la santé diminue constamment et vous devez la reconstituer.

Ici, il apprendra qu'il a la santé et doit être reconstitué, car en cas de décès, l'agent reçoit une récompense négative. De plus, il apprendra que si vous vous rapprochez du sujet, vous pouvez le récupérer. Dans le premier scénario, l'agent ne pouvait pas se déplacer.
Et dans le troisième scénario final, laissons-le tirer avec les bots programmés selon les règles du jeu afin qu'il puisse affiner ses compétences.

Lors de la formation dans ce scénario, la sélection correcte des récompenses que l'agent reçoit est très importante. Par exemple, si vous donnez une récompense uniquement pour les rivaux vaincus, le signal sera très rare: s'il y a peu de joueurs autour, nous recevrons des points toutes les quelques minutes. Par conséquent, utilisons la combinaison de récompenses précédentes. L'agent recevra une récompense pour chaque action utile, qu'il s'agisse d'améliorer la santé, de sélectionner des cartouches ou de frapper un adversaire.
En conséquence, un agent formé avec des récompenses bien choisies est plus fort que ses adversaires les plus exigeants en termes de calcul. En 2016, un tel système a remporté le concours VizDoom avec une marge de plus de la moitié des points marqués à la deuxième place. L'équipe finaliste a également utilisé un réseau de neurones, uniquement avec un grand nombre de couches et des informations supplémentaires du moteur de jeu pendant l'entraînement. Par exemple, des informations sur la présence d’ennemis dans le champ de vision de l’agent.
Nous avons examiné des approches pour résoudre des problèmes, où il est important de prendre des décisions. Mais de nombreuses tâches avec cette approche resteront non résolues. Par exemple, le jeu de quête Montezuma Revenge.
Ici, vous devez rechercher des clés pour ouvrir les portes des chambres voisines. Nous obtenons rarement les clés et nous ouvrons les chambres encore moins souvent. Il est également important de ne pas être distrait par des objets étrangers. Si vous entraînez le système comme nous l'avons fait dans les tâches précédentes et donnez des récompenses aux ennemis battus, il assommera simplement le crâne roulant encore et encore et n'examinera pas la carte. Si vous êtes intéressé, je peux parler de la résolution de ces problèmes dans un article séparé.
Vous pouvez écouter le discours de Vladimir Ivanov à la conférence d'Amnesty International le 22 novembre . Un programme détaillé et des billets sont disponibles sur le
site officiel de l' événement.
Lisez l'interview de Vladimir
ici .