Une autre transcription du rapport avec
Pixonic DevGAMM Talks . Anton Kosyakin est chef de produit technique et travaille sur la plate-forme ALICE (telle une Jira pour les hôtels). Il a expliqué comment ils ont intégré les outils de test existants dans le projet, pourquoi les tests de charge sont nécessaires, quels outils la communauté propose et comment exécuter ces outils dans le cloud. Voici une présentation et le texte du rapport.
Nous fabriquons un produit appelé ALICE Platform et je vais maintenant vous expliquer comment ils ont résolu le problème des tests de charge.

ALICE est Jira pour les hôtels. Nous créons une plateforme pour les aider à gérer leurs entrailles. Concierge, réceptionniste, nettoyeurs - ils ont également besoin de billets. Par exemple: un invité appelle> dit que vous devez nettoyer la pièce> l'employé crée un ticket> les gars qui nettoient, savent à qui la tâche est confiée> exécuter> changer le statut.
Nous avons B2B, donc les chiffres ne sont peut-être pas impressionnants - seulement 1 000 hôtels, 5 000 DAU. Pour les jeux, ce n'est pas beaucoup, mais pour nous, c'est très cool, car il y a jusqu'à 8 serveurs prod et ils peuvent à peine faire face à ces 5 000 utilisateurs actifs. Étant donné que des choses légèrement différentes se produisent sous le capot - un tas de bases de données, de transactions, etc.

Plus important encore: au cours de la dernière année, nous avons grandi 2 fois, nous avons maintenant une équipe d'ingénieurs dans la région de 50 personnes et nous prévoyons de doubler la base d'utilisateurs en 2019. Et c'est le principal défi auquel nous sommes confrontés.
Un exemple tiré de la vie. Vendredi soir, après avoir travaillé une semaine de travail de 60 heures, à 23h00, j'ai terminé le dernier appel, j'ai rapidement terminé la présentation, j'ai sauté dans le train et je suis venu ici. Et il y a environ cinq minutes, j'ai refait un peu ma présentation. Alors maintenant, tout fonctionne pour nous, car nous sommes une startup et c'est cool. Pendant que je conduisais, une partie de l'équipe technique (nous l'appelons le feu en production) a essayé de s'assurer que le système ne tombait pas en panne et, en même temps, les utilisateurs ne l'ont pas remarqué. Ils ont réussi et nous sommes sauvés.
Comme vous pouvez le voir, jusqu'à présent, nous ne dormons pas très bien la nuit. Nous savons avec certitude que notre infrastructure tombera. Nous faisons face à la vérité et nous comprenons cela. Une question: quand? C'est ainsi que nous avons compris que le test de charge est la clé du salut. C'est ce dont nous devons nous soucier.

Quels sont nos objectifs. Tout d'abord, nous devons dès maintenant comprendre exactement la capacité et les performances de notre système, comment il fonctionne pour les utilisateurs actuels. Et cela devrait se produire avant que l'utilisateur ne rompt le contrat avec nous (et cela peut être un client pour 150 hôtels et beaucoup d'argent) en raison du fait que quelque chose ne fonctionne pas ou est très lent. De plus, le service commercial a un plan: double croissance sur l'année prochaine. Et il se trouve que nous avons acheté notre principal concurrent et migré leurs utilisateurs vers nous.
Et nous devons savoir que tout cela peut résister. Sachez à l'avance, avant l'arrivée de ces utilisateurs et tout tombera.
Nous faisons également des sorties. Chaque semaine. Lundi. Bien sûr, toutes les versions n'augmentent pas la fonctionnalité, quelque part la maintenance, quelque part les corrections de bugs, mais nous devons comprendre que les utilisateurs ne le remarqueront pas et que leur expérience ne s'aggravera pas.
Mais nous, en tant que bons développeurs, sommes des gens paresseux et nous n'aimons pas travailler. Par conséquent, ils ont demandé à la communauté et à Google quels services / solutions existent pour les tests de charge. Il y en avait beaucoup. Il y a des choses simples, comme Apache Bench, qui lance simplement un site dans une centaine de threads dans l'url. Il existe une version maléfique et étrange de Bees with Machine Guns, où tout est pareil, mais il démarre les instances qui volent et mettent vos applications. Il y a JMeter, vous pouvez y écrire des scripts, exécuter dans le cloud.

Tout semble aller bien, mais après réflexion, nous avons réalisé que nous devons vraiment travailler et d'abord résoudre plusieurs problèmes.

Tout d'abord, vous devez écrire des scénarios réels qui simuleront une charge complète. Sur certains systèmes, il suffit de générer des appels API aléatoires avec des données aléatoires. Dans notre cas, ce sont de longs scénarios d'utilisation: j'ai reçu un appel, ouvert un écran, conduit toutes les données (qui a appelé ce qu'il veut), enregistrées. Il apparaît ensuite dans l'application mobile d'une autre personne qui exécutera la demande. Pas la tâche la plus triviale.
Et permettez-moi de vous rappeler, des sorties chaque semaine. La fonctionnalité est mise à jour, les scripts doivent être vraiment pertinents. Vous devez d'abord les écrire, puis les soutenir.
Mais ce n'était pas le plus gros problème. Prenez flood.io par exemple. Un outil sympa, vous pouvez y exécuter Selenium - c'est à ce moment que Chrome démarre, vous pouvez le contrôler et il exécute une sorte de script. Vous pouvez y exécuter des scripts JMeter. Mais si nous voulons exécuter Selenium dans les scripts JMeter, tout s'écroule soudainement, car les gars qui l'ont assemblé ont pris un certain nombre de décisions architecturales. Ou, par exemple, certains services peuvent exécuter JUnit - c'est simple et direct, mais l'un de ces services a écrit sa propre JUnit et il ignore simplement certaines choses.

La question de la génération de charge est urgente, car chaque outil demande à sa manière de la générer. Et même lorsque vous avez réussi à vous assurer que les scénarios étaient adéquats, la question se pose: comment exécuter 2 à 4 fois plus? Il semble que ce soit: courir et tout va bien. Mais non. Il y a toutes sortes d'ID dans ces demandes - nous créons quelque chose, obtenons un nouvel ID, changeons l'ancien ID et le test, qui charge l'entité par ID, change son champ en un autre. Et 10 tests qui chargent 10 fois la même entité ne sont pas très intéressants. Parce que 10 fois il est nécessaire de charger différentes entités et de dimensionner correctement cette charge.
OK, nous voulons résoudre le problème des tests de charge afin de comprendre exactement combien d'utilisateurs vont supporter l'application, et que nos plans sont cohérents avec les plans du service commercial. Nous avons analysé les solutions qui sont sur le marché, puis nous avons fait l'inventaire de nos pâtes et bâtonnets.
Comme nous publions chaque semaine, nous avons naturellement automatisé certains tests - intégration et autre chose. Pour cela, nous utilisons du concombre. Il s'agit d'un cadre BDD pour un développement axé sur le comportement. C'est-à-dire nous demandons quelques scripts qui se composent d'étapes.

Notre infrastructure nous a permis d'exécuter des tests d'intégration et fonctionnels en deux modes: il suffit de lancer le backend, de tordre l'API ou d'exécuter Chrome via Selenium et de le gérer.
Nous adorons NewRelic. Il peut simplement surveiller le serveur, les principaux indicateurs. Il s'intègre à la JVM et intercepte tous les appels aux contrôleurs et à l'API Endpoint. Ils ont également une solution pour le navigateur, et puisque nous avons la plupart des fonctionnalités là-bas, il fait également quelque chose dans le navigateur et donne une sorte de métriques.

En conséquence, vous devez tout rassembler. Nous avons déjà automatisé les principaux scénarios. Nos scénarios (parce que c'est comme BDD) imitent de vrais utilisateurs et la charge est similaire à la production réelle. En même temps, nous pouvons l'adapter. Comme cela fait partie du processus de publication, il est toujours mis à jour.

Prenons maintenant n'importe quel outil actuellement sur le marché. Ils fonctionnent sur les mêmes primitives: http, appels API sur http, JSON, JUnit, c'est tout. Mais dès que nous essayons de coller nos tests sur le concombre, ils font de même, opèrent sur les mêmes choses, mais rien ne fonctionne. Nous avons commencé à penser comment faire face à cette tâche.
Une petite digression, parce que BDD n'est pas un terme très populaire dans le développement de jeux, c'est plutôt pour les solutions d'entreprise.

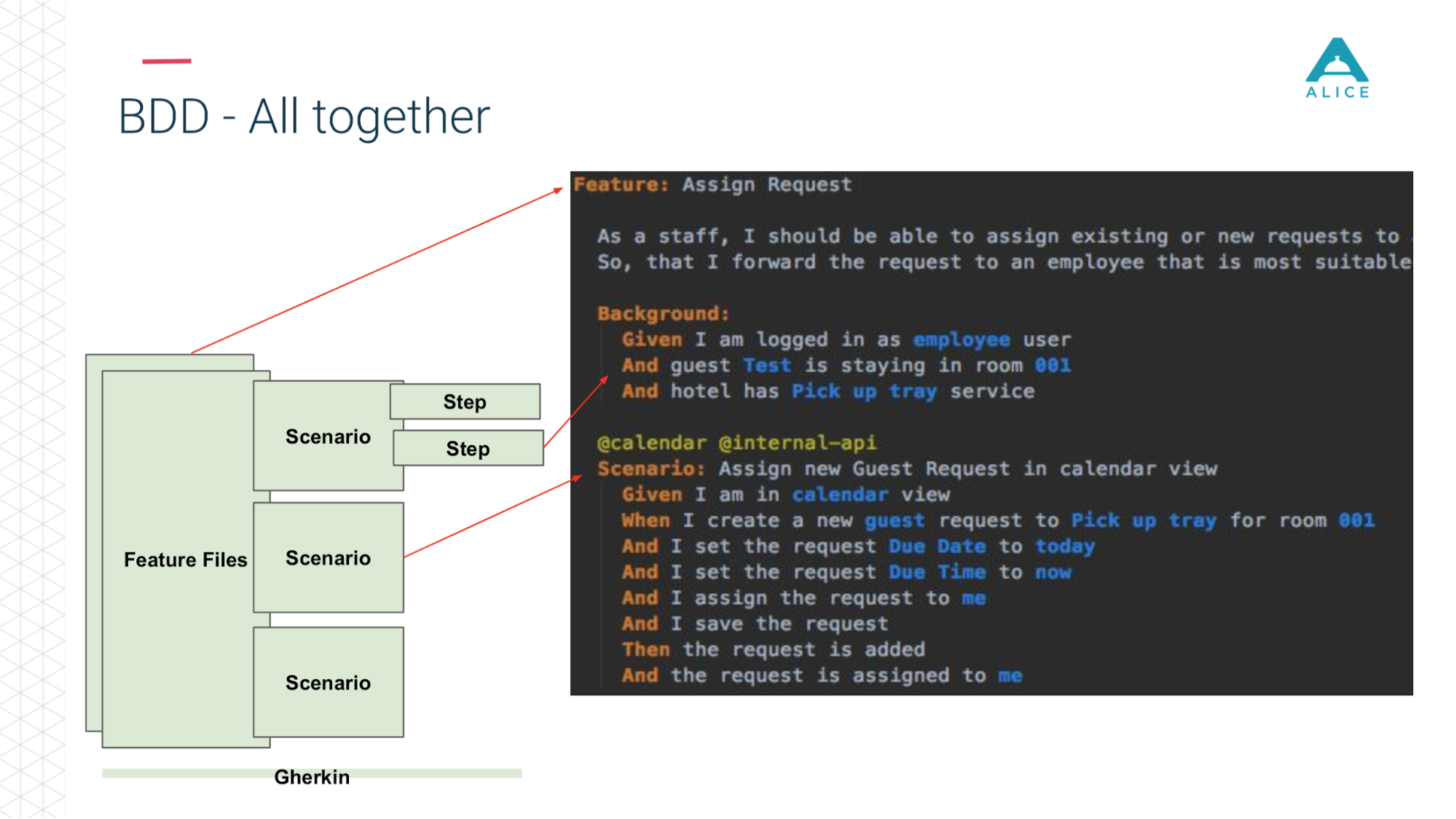
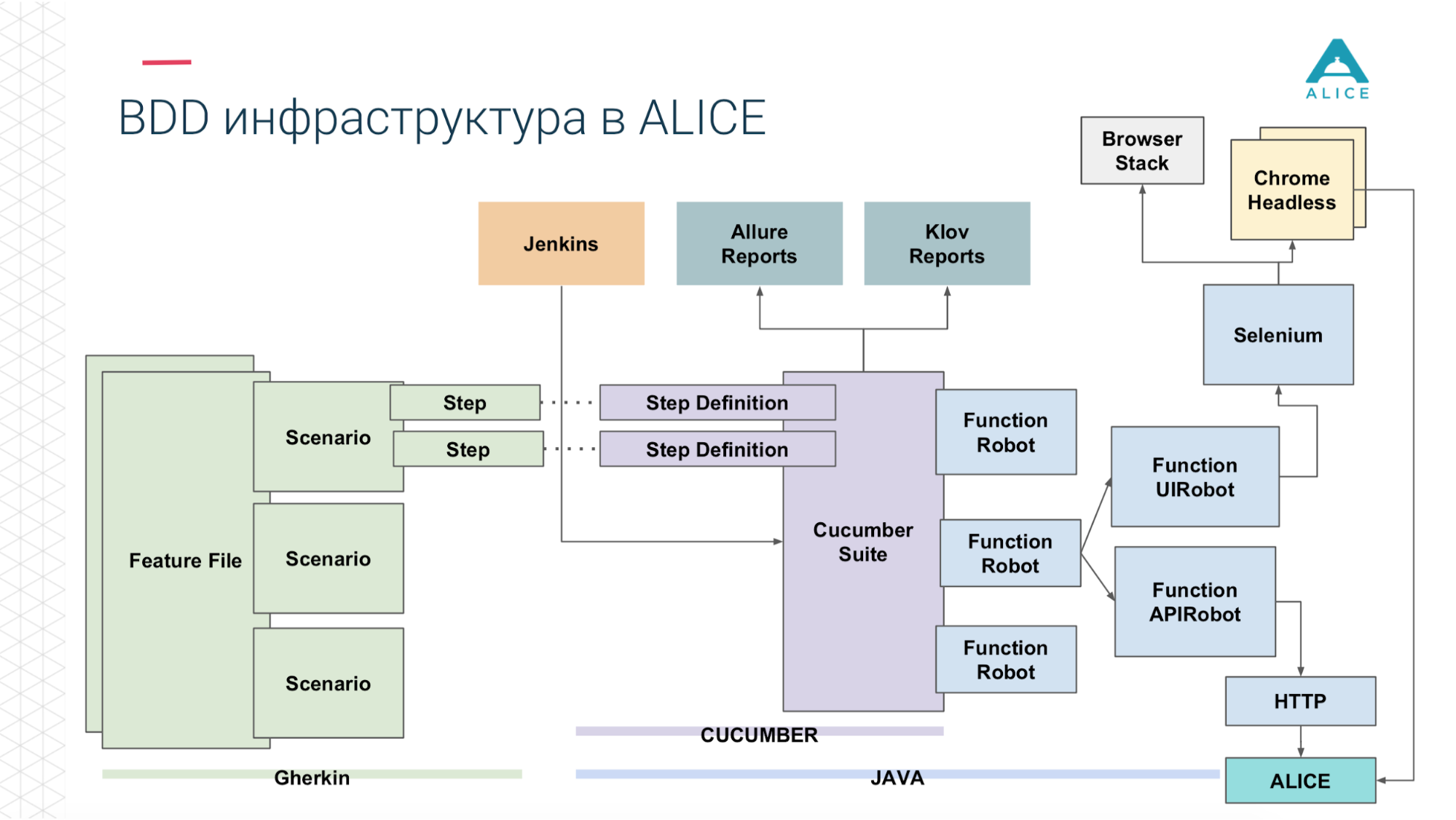
Tous les scénarios décrivent vraiment une sorte de comportement. Le format de description du scénario est très simple: Étant donné, Quand, Alors - en termes de BDD appelé Gherkin. Le concombre pour nous, à l'aide d'annotations et d'attributs, mappe cela au code Java. Il fait ce qu'il voit dans le scénario: vous devez donner une pomme à la personne, trouvons une méthode pour la mettre en œuvre.
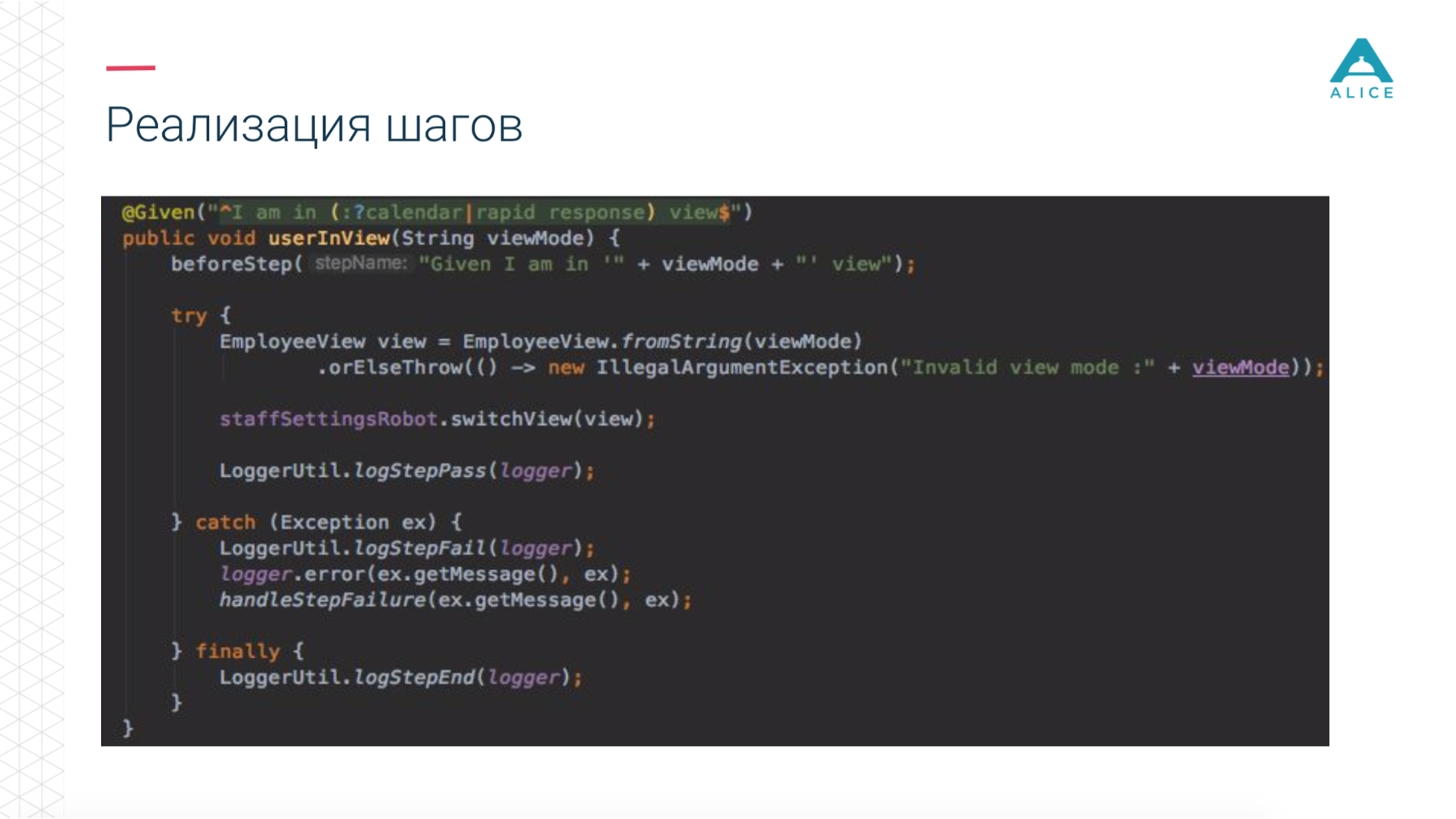
Nous avons ensuite introduit un concept comme Functional Robot. Il s'agit d'un certain client pour l'application, il a des méthodes pour connecter un utilisateur, se déconnecter, créer un ticket, voir une liste de tickets, etc. Et cela peut fonctionner en trois modes: avec une application mobile, une application web et simplement passer des appels API.
Maintenant en un mot la même chose sur les diapositives. Les fichiers de fonctionnalités sont divisés en scripts, il y a des étapes et tout cela est écrit en anglais.
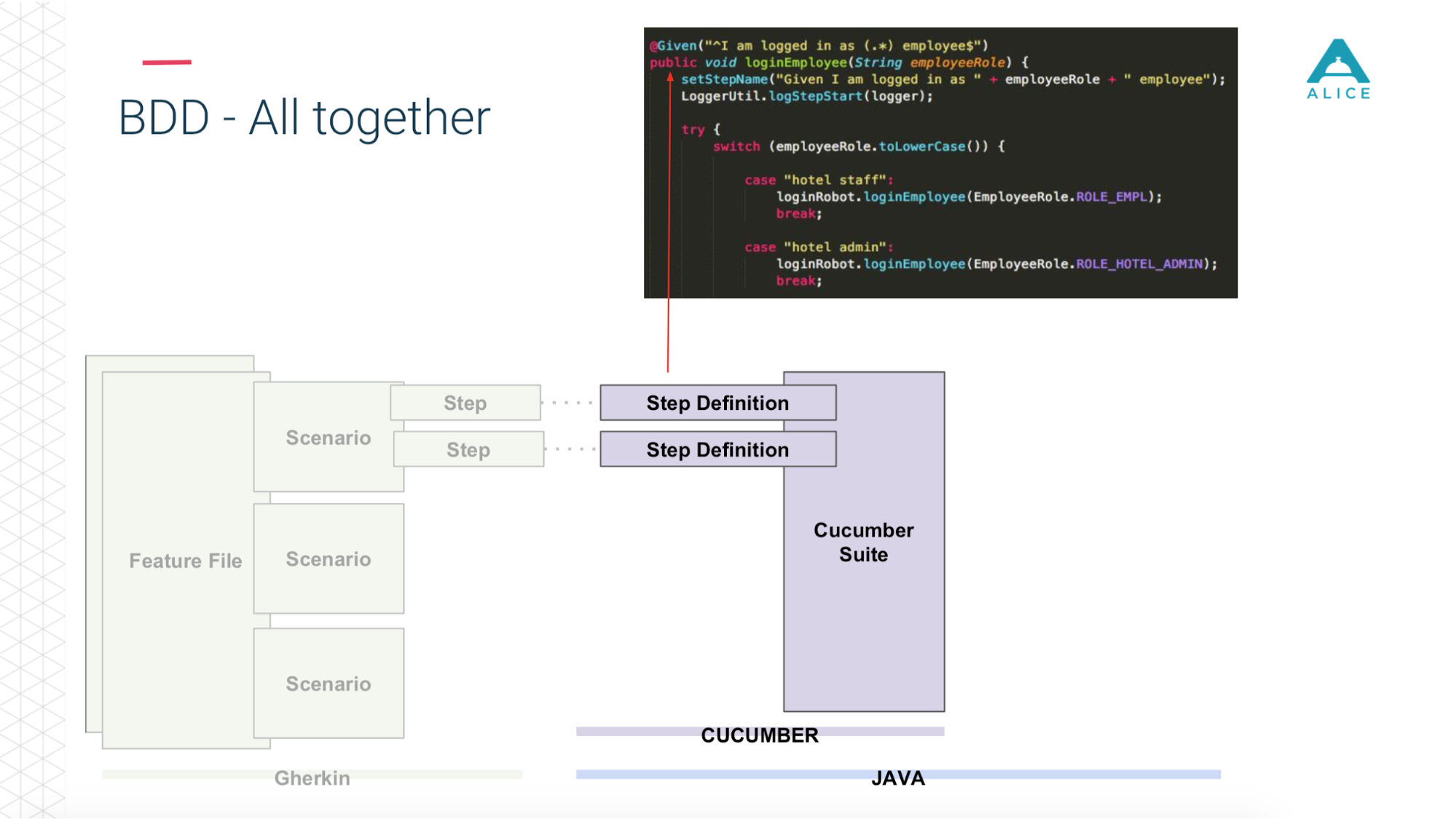
Ensuite, Cucumber, le code Java, entre en jeu, il mappe ces scripts au code qui s'exécute réellement.
Ce code utilise notre application.

Et selon ce que nous avons choisi: soit via Sélénium Chrome va vers l'application ALICE.

Ou la même chose via l'API http.
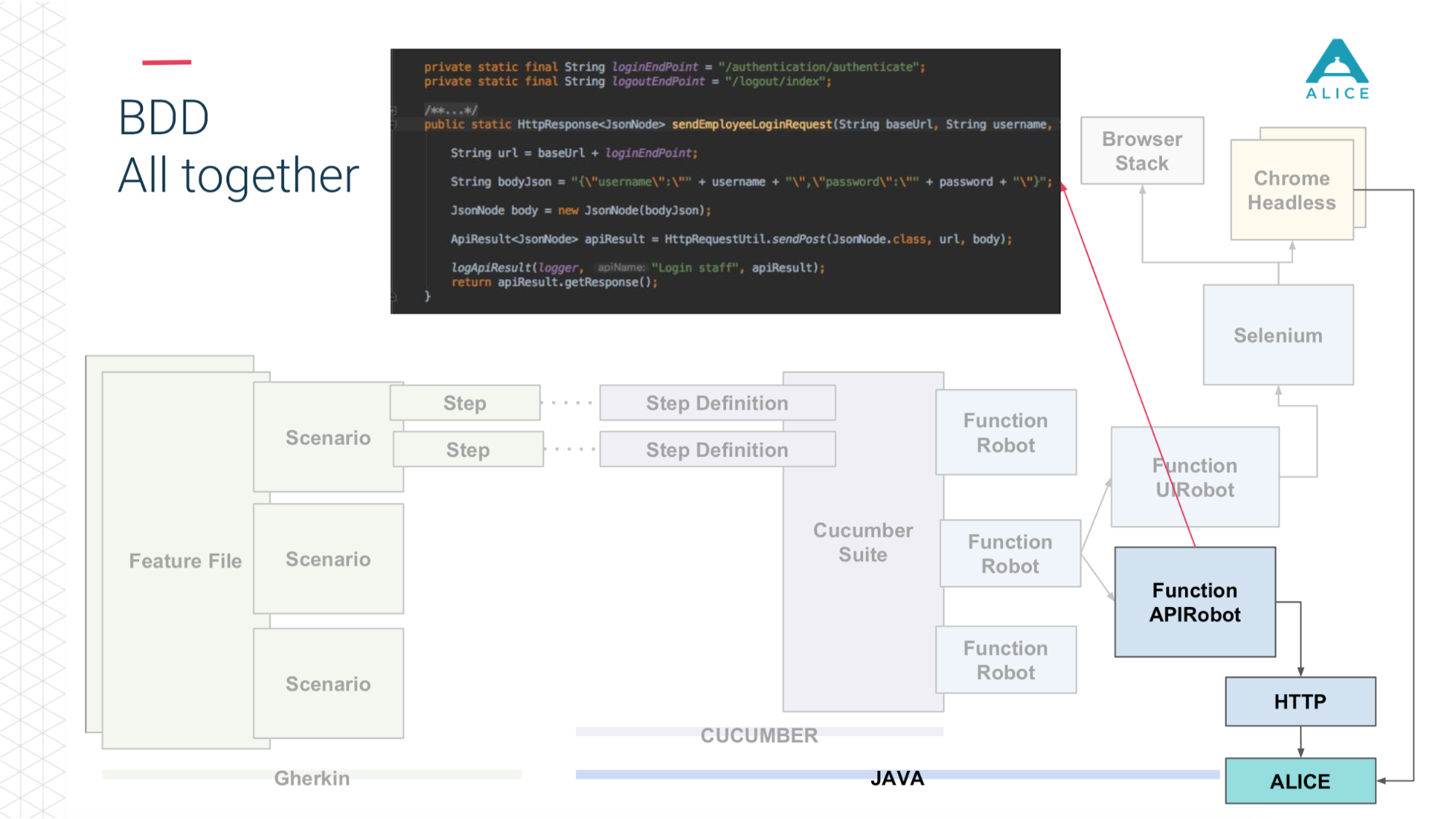
Et puis (grâce aux gars de Yandex pour Allure Reports) tout cela nous est magnifiquement montré - combien de temps cela a pris, quels tests sont retournés, à quelle étape et même appliquer une capture d'écran en cas de problème.
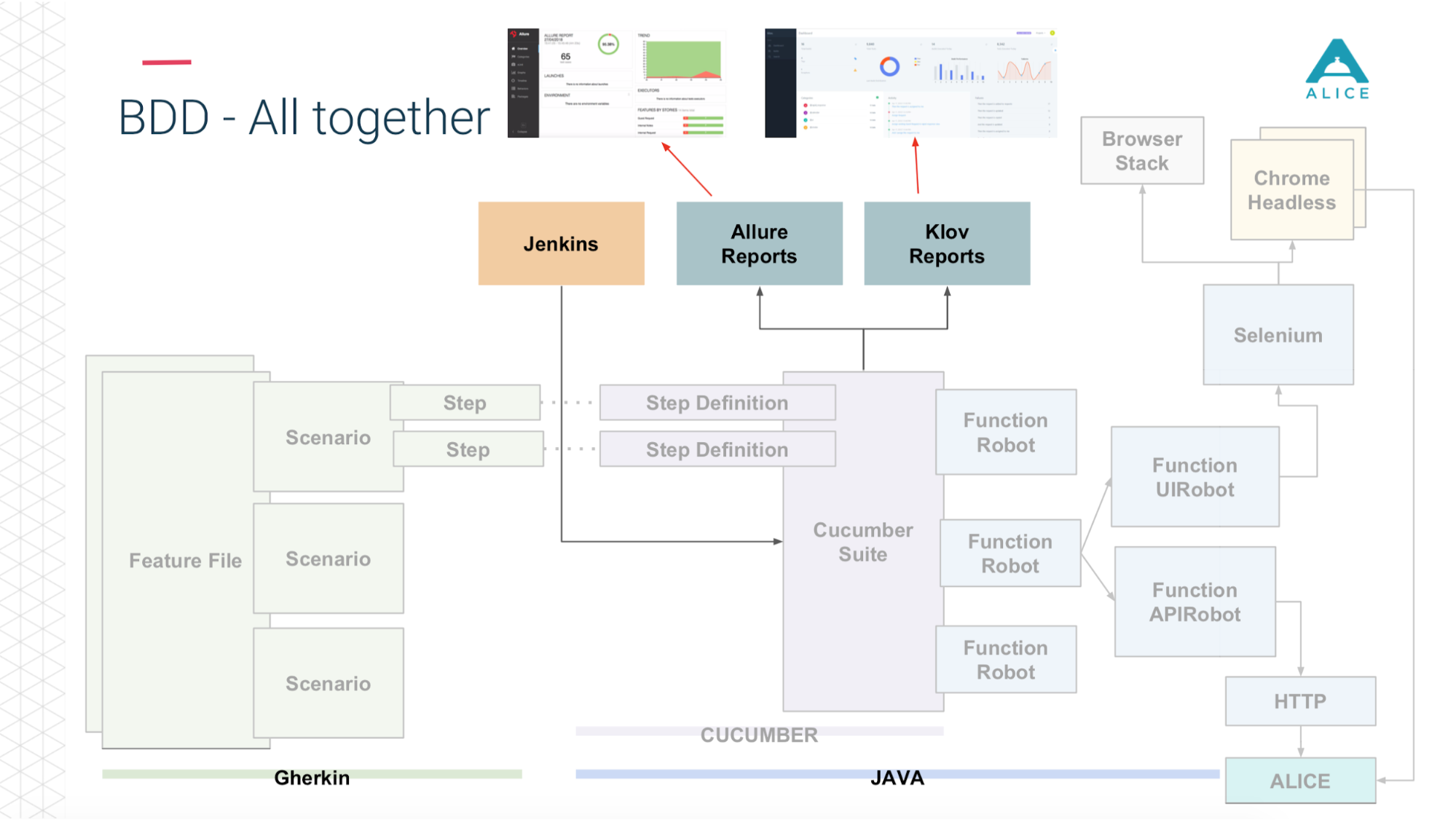
Voici un bref résumé de ce que nous avions déjà.
Comment construire des tests de charge à partir de cela? Nous avons eu Jenkins exécutant la suite Cucumber. Ce sont nos tests et ils sont allés à ALICE. Quel était le principal problème? Jenkins exécute les tests localement; il ne peut pas évoluer pour toujours. Oui, nous sommes hébergés sur Amazon, dans le cloud, nous pouvons demander une machine extra-large. Quoi qu'il en soit, à un moment donné, nous entrerons, au moins, dans le réseau. Il faut en quelque sorte charger cette charge. Merci Amazon, il a pensé pour nous. Nous pouvons emballer notre suite Cucumber dans un conteneur Docker et utiliser le service AWS (appelé Fargate) pour dire «et démarrez-les, s'il vous plaît». Le problème est résolu, nous pouvons exécuter nos tests déjà dans le cloud.

Ensuite, puisque nous sommes dans le cloud, exécutez 5-10-20 Cucumber Suite. Mais il y a une nuance: chaque exécution de tous nos tests fonctionnels génère un rapport. Une fois que nous avons exécuté 400 tests et 400 rapports ont été générés.
Merci encore aux gars de Yandex pour l'open source, nous avons lu la documentation, le code source et réalisé qu'il existe des moyens d'agréger les 400 rapports en un seul. Nous avons légèrement corrigé les données, écrit certaines de nos extensions et tout a fonctionné.
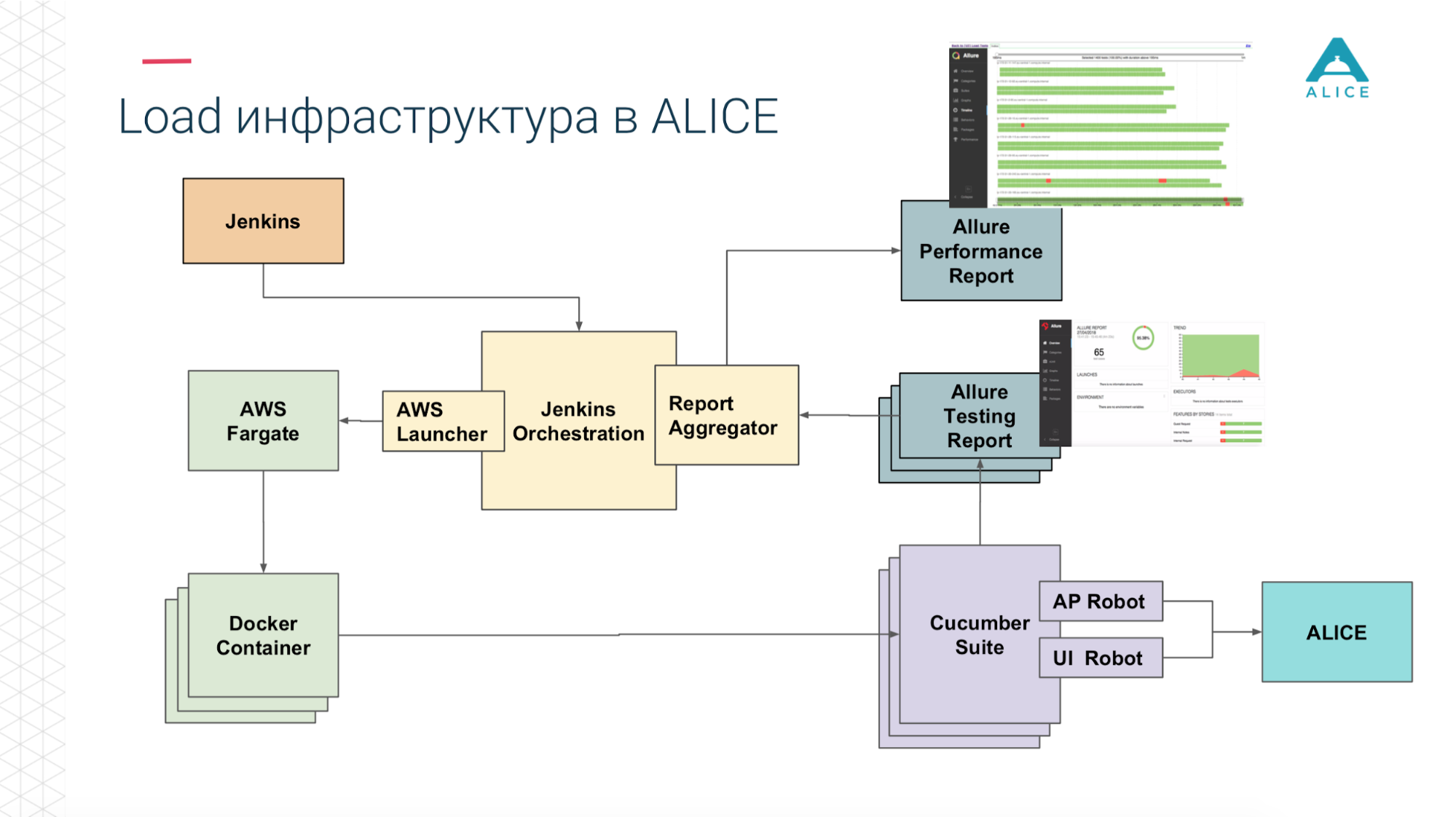
Maintenant de Jenkins, nous disons "donnez-nous 200 instances." Notre script d'orchestration certain va à Amazon, dit "lancer 400 conteneurs". Chacun d'eux contient nos tests d'intégration, ils génèrent un rapport, le rapport est collecté via Aggregator en une seule pièce, placé dans Jenkins, appliqué au travail, cela fonctionne super.
Mais.
Je suis sûr que beaucoup d'entre vous ont reçu des choses étranges de la part des testeurs, comme "J'ai joué à un jeu, j'ai sauté 10 fois, pendant ce temps, j'ai appuyé sur la prise de vue et j'ai accidentellement appuyé sur le bouton d'arrêt - le personnage a commencé à clignoter, à se figer dans l'air, puis l'ordinateur s'est éteint, faire face à cela. " Vous pouvez toujours être d'accord avec une personne et dire, vous savez, qu'il est impossible de se reproduire. Mais nous avons des machines sans âme, elles font tout très rapidement et quelque part où les données ne se sont pas chargées, quelque part elles ne s'affichent pas très rapidement, elles essaient d'appuyer sur un bouton, mais il n'y a pas encore de bouton ou elles utilisent des données qui n'ont pas encore été téléchargées depuis le serveur . Tout s'effondre et le test est imparfait. Bien que (je veux me concentrer sur cela), nous avons du code Java qui exécute Chrome, qui se connecte à un autre Java via un wrapper et fait quelque chose et fonctionne toujours à la vitesse de l'éclair.
Eh bien, le problème évident qui en découle: nous avons 5 000 utilisateurs, et nous avons lancé seulement 100 instances de nos tests fonctionnels et créé la même charge. Ce n'est pas exactement ce que nous voulions, car nous prévoyons que le mois prochain, nous aurons 6 000 utilisateurs. Il est difficile de comprendre une telle charge, de comprendre combien de threads démarrer.
OK, humanisons notre système. Voici à quoi ressemble l'interface utilisateur:

Quelqu'un appelle, le concierge veut appuyer sur le bouton "créer un nouveau ticket", une fenêtre s'ouvre pour lui et il doit remplir tous les champs.
Mais cela ne se produit pas instantanément. La personne réelle jusqu'à ce qu'il atteigne la souris, jusqu'à ce qu'il commence à taper, jusqu'à ce qu'il sélectionne quelque chose, pendant qu'il clique sur Enregistrer. Ralentissons donc nos tests.

Nous l'avons appelé le mode humain. Il vous suffit de mesurer la durée de l'étape et un peu de "sommeil" si elle était trop rapide. Dans le même temps, nous pouvons mesurer combien, en principe, cette étape a pris - si 5 minutes, alors, probablement, l'expérience utilisateur est rompue ici.
Puisque nous avons eu pas mal de tests, nous n'avons pas commencé à réécrire chacun sous cette chose. Ils ont pris AspectJ, l'ont tiré sur notre code, ont ajouté 5 lignes de code supplémentaires, cela fonctionne très bien.
Démo courte.


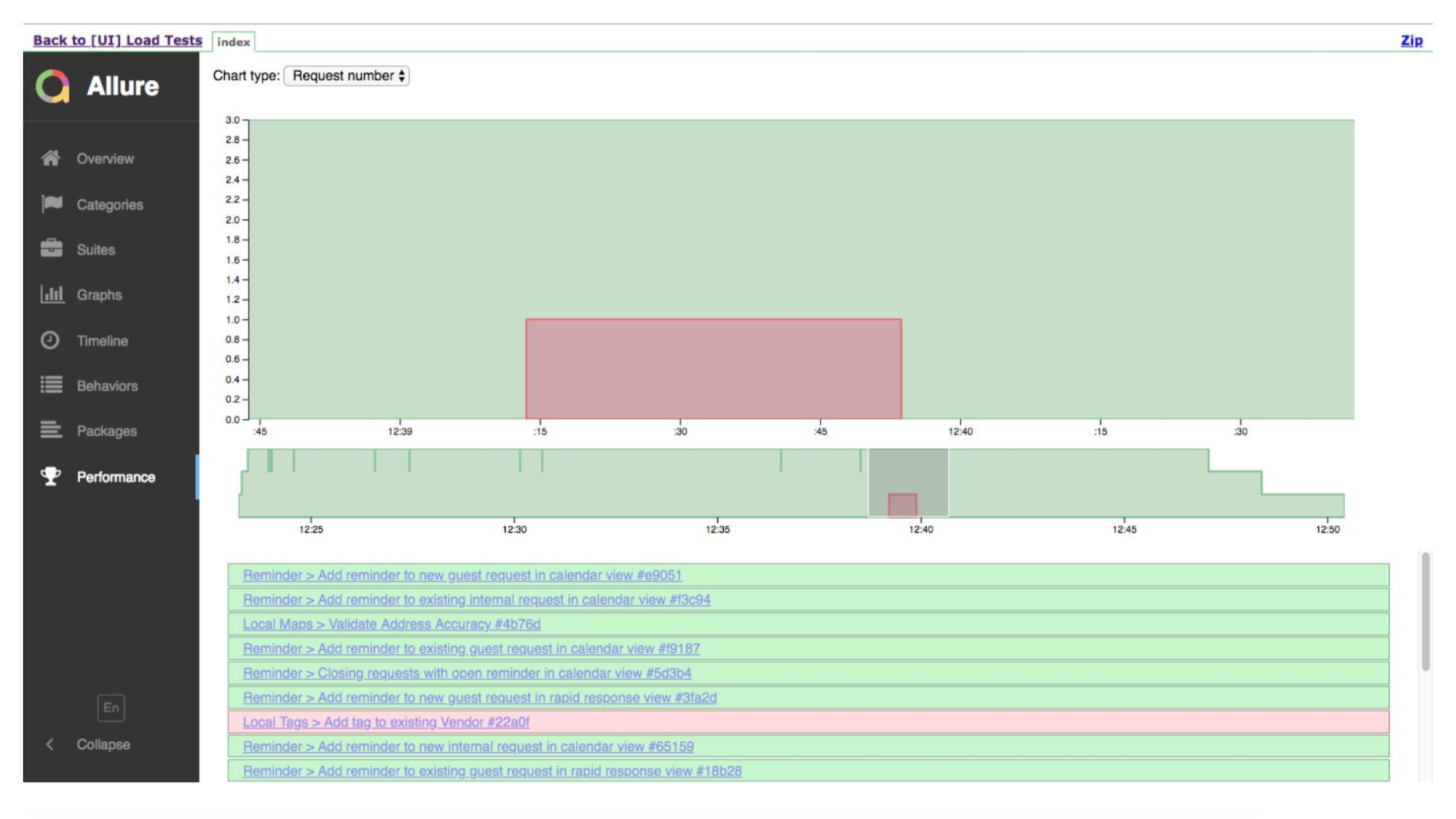
Ceci est une chronologie. Les tests verts sont bons, quelque part est mauvais. Allure nous montrera les détails de l'endroit où il se retourne.
Et voici la chronologie, montrant que nous avons eu de nombreux cas. Ils ont effectué un test, quelque part quelque chose est tombé.
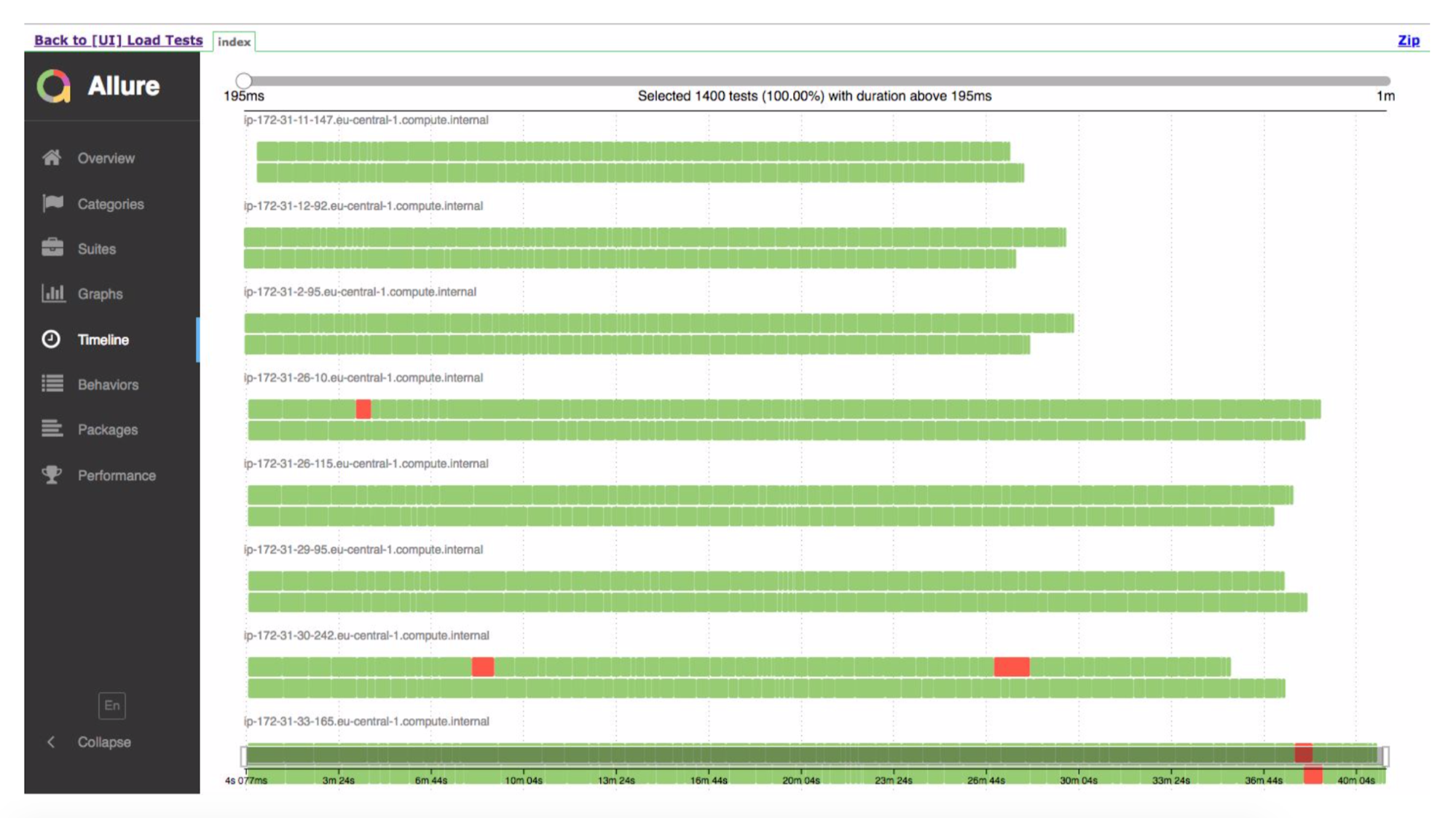
Le système fonctionne vraiment - la semaine dernière, nous avons fait les premiers tests sur la production de combat.
Maintenant sur les prochaines étapes, comment, à notre avis, peut être amélioré.

Plus important encore, nous voulons que les gens aient une expérience utilisateur cool. L'idée est que nous pouvons générer une charge importante sur notre application et tout semble simple - nous avons mesuré trivialement les performances de chaque demande au serveur, qu'il continue de répondre au fur et à mesure que les baisses de performances commencent (le serveur commence à traiter les demandes entrantes plus lentement). Mais non. En réalité, le client / l'application peut envoyer plusieurs requêtes au serveur à la fois, en un tas. Et attendez qu'ils soient tous traités. Et si l'une des demandes, la plus longue, comment cela a fonctionné pendant 5 secondes et continue de fonctionner pendant 5 secondes, alors peu importe comment les autres fonctionnent - aussi rapide ou ralentie à 4 secondes. Après tout, nous attendrons encore le plus longtemps, cinq secondes. Ou vous avez créé un ticket, tout a fonctionné en une milliseconde, mais le ticket est apparu trop tard dans le système en raison de caches d'index internes. L'approche habituelle ne résoudra pas ce problème, nous voulons donc essayer de mesurer tous les scénarios et voir à quel point le script de création de ticket a vraiment empiré.
Parce que nous avons tous les scénarios basés sur des clés usinées, nous pouvons imiter en faisant courir une personne à la réception et 10 nettoyeurs. Puis 20 ou 30 nettoyeurs. Mais le front du peuple est toujours le même. C'est-à-dire nous pouvons générer une charge réelle par des modèles de comportement, très proches d'une charge réaliste.
Également tests multi-régionaux. Notre système est utilisé partout dans le monde (bien que tout soit hébergé en Amérique) et nous pouvons donc générer une charge à la fois de la Russie et de l'Amérique pour voir lequel d'entre eux commence à ralentir plus rapidement.
Questions du public
- Vous êtes obligé d'écrire une grande quantité de logique, et quand quelque chose change un peu, vous cassez beaucoup de choses dans les tests fonctionnels. Il s'avère que cela vous prend presque plus de temps pour supporter les tests que pour développer?"Oui, mais non." C'est BDD, ce ne sont pas des tests tout à fait fonctionnels, ils sont plus proches des tests d'intégration. Et quoi que nous changions, le scénario reste le même. J'appuie sur un bouton, je vois une fenêtre, j'y sais le numéro de la pièce avec laquelle la demande a été reçue, le nom de la personne et la date à laquelle réserver une table. Si la mise en page change, les champs sont inversés, si quelque chose se passe dans le backend, le test est enregistré, car nous sommes à un niveau très élevé, nous cliquons sur les boutons du navigateur. Par conséquent, nous sommes protégés contre un grand nombre de changements. Il y a des moments où tout peut se casser. Par conséquent, dans la procédure de sortie, les gars qui écrivent une nouvelle fonctionnalité - ils sont responsables de voir que quelque chose est cassé et de réparer. Mais jusqu'à présent, il n'y a pas eu de tels problèmes en grand nombre.
- Et vous n'avez pas eu une situation qui, après un changement, tous les tests deviennent rouges.- Ce n'était pas le cas. Théoriquement, cela peut se produire si le script n'a pas de bouton, mais une autre façon d'ouvrir une fenêtre pour entrer les informations de ticket. Mais, comme je l'ai montré précédemment, tous nos scénarios se composent d'étapes. Les étapes sont beaucoup de tout, et si nous avons 100 scripts qui cliquent sur le même bouton, l'étape n'en est qu'un. Et si tout s'est arrêté à cause de cette étape particulière, nous le corrigeons, le réécrivons et tous les tests deviennent immédiatement verts.
Bien qu'une fois, lorsque nous avons accidentellement cassé quelque chose, cela nous est arrivé. Il ne restait que 40% de vert, bien qu'avant c'était 99%. C'était un petit changement. Nous avons corrigé une étape (ligne de code) et tout est redevenu vert.
- Bien que vous n'ayez pas de tests d'intégration, ils ne sont pas entièrement fonctionnels. D'une manière ou d'une autre, il s'agit d'une sorte d'interface graphique où les boutons sont enfoncés, une sorte d'interaction se produit spécifiquement avec le shell externe. Je comprends que vous avez des tests sous cette forme, vous venez de démarrer beaucoup de threads en même temps. Et pourquoi n'ont-ils pas organisé les requêtes générées par des outils standard: JMeter, Gatling, qui n'interagissent pas du tout avec le shell externe, mais versent simplement des requêtes au serveur?- Tout est très simple. Quelle est l'architecture de notre application? Nous avons un backend, nous avons un frontend. Frontend est le web. Il existe une application mobile. Et lorsque je crée un ticket, mon frontend est connecté, par exemple, également aux serveurs d'événements. Je crée un ticket sur le backend et toutes les personnes qui sont assises dans le même hôtel regardent les billets dans le même hôtel, ils arriveront des serveurs d'événements: les gars se mettront à jour, les données y auront changé. Et pour tout mettre ensemble, nous avons un seul point - c'est le client. Il se connecte à un grand nombre de composants différents et soit nous programmons avec nos mains que nous avons créé un ticket dans le backend, puis nous nous connectons au serveur d'événements, nous nous inscrivons dessus et attendons certains événements de celui-ci. Ou ils viennent de lancer un navigateur dans lequel tout a déjà été mis en place, ce code est déjà écrit et nous faisons tout ce dont nous avons besoin.
- Mais ce sont des approches différentes? Ou nous travaillons spécifiquement avec le serveur ou avec la fenêtre. Vous pouvez simuler des demandes sur plusieurs serveurs à la fois.- C'est pourquoi je vous ai dit que nous avons des robots fonctionnels appelés à partir de tests. Il y a ceux qui récupèrent Chrome et effectuent des clics de haut niveau. Il y a ceux qui ne cliquent pas sur le bouton, rien ne se passe, mais au moment de créer le ticket, il envoie une requête au serveur, et on peut exécuter ceci ou cela. Nous avons choisi de parcourir Chrome pour une raison simple: nous voulons simuler de vrais utilisateurs, la façon dont ils l'utilisent vraiment. Pendant le chargement de sa page, tandis que tout était rendu pour lui, tandis que les scripts Java et ainsi de suite fonctionnaient. Nous voulons être aussi proches que possible de l'utilisateur, et c'est du vrai web.
- Mais beaucoup de choses dépendront du type d'utilisateur d'Internet, de l'environnement. Mais plus précisément, le fonctionnement de l'application dépendra de vous déjà et de votre côté. La question est, que testons-nous: en principe, est-ce tout ou partie séparément?- Bonne question, j'ai donc parlé de tests multi-régionaux. Nous pouvons essayer de générer du trafic en provenance du Mexique, où, peut-être, pas très bien avec Internet. Nous pouvons générer du trafic depuis l'Amérique, qui est très proche de la région amazonienne où tout est hébergé. Mais si une personne en arrière-plan a ouvert YouTube ou a commencé à extraire des bitcoins, nous ne pouvons pas déjà le reproduire. Ici, vous devrez attendre un appel de vrais clients et aller vers eux pour comprendre ce qui se passe. Ce n'est pas une solution miracle, oui.- Vous déployez des tests. Avez-vous une sorte de grille de sélénium qui monte ou quoi? Vous les faites toujours multi-régionales.— Cucumber': JAR, JAR Docker image Fargate' , image . flood.io grid Selenium , .
— ? , Chrome, . Internet Explorer 4 ( - ), ? - Android -.— , enterprise. enterprise , requirements. — , , web view. Android web view , .
— , , Load-? ?— .
Environment . . , Load, . 4- , , aliceapp.com. Load- , . , 504, , MySQL ElasticSearch.
— ( ), , ? .— Load- , . C'est-à-dire .
— , ?— , . , , , .
— , , .. html API?— Selenium DOM- : , , key down , — . .
— ? , ?— . , . QC, , QC. Smoke- -. « -, ». — , , , .
Pixonic DevGAMM Talks