
Voici le premier livre à l'origine en russe dans lequel les secrets du traitement des mégadonnées (Big Data) dans les nuages sont examinés avec des exemples réels.
L'accent est mis sur les solutions Microsoft Azure et AWS. Toutes les étapes du travail sont prises en compte: obtention des données préparées pour le traitement dans le cloud, utilisation du stockage cloud, outils d'analyse des données cloud. Une attention particulière est portée aux services SAAS, les avantages des technologies cloud par rapport aux solutions déployées sur des serveurs dédiés ou des machines virtuelles sont démontrés.
Le livre est conçu pour un large public et servira d'excellente ressource pour le développement d'Azure, Docker et d'autres technologies indispensables, sans lesquelles l'entreprise moderne est impensable.
Nous vous invitons à lire le passage "Téléchargement direct des données de streaming"
10.1. Architecture générale
Dans le chapitre précédent, nous avons examiné la situation dans laquelle de nombreuses applications clientes doivent envoyer un grand nombre de messages qui doivent être traités dynamiquement, placés dans le référentiel puis traités à nouveau dans celui-ci. Dans le même temps, il est nécessaire de pouvoir changer la logique du flux de traitement et de stockage des données sans avoir à changer le code client. Et enfin, du point de vue des raisons de sécurité, les clients ne devraient avoir le droit de faire qu'une seule chose - envoyer ou recevoir des messages, mais en aucun cas lire des données ou supprimer des bases de données, et ils ne devraient pas avoir de droits directs pour écrire ces données.
Ces tâches sont très courantes dans les systèmes fonctionnant avec des appareils IoT connectés via une connexion Internet, ainsi que dans les systèmes d'analyse de journaux en ligne. En plus des exigences énumérées ci-dessus pour notre service dédié, il existe deux autres exigences liées aux spécificités de «l'Internet des objets» et pour assurer un traitement fiable des messages. Tout d'abord, le protocole d'interaction entre le client et le récepteur de service doit être très simple pour pouvoir être implémenté sur un appareil aux capacités informatiques limitées et à la mémoire très limitée (par exemple, Arduino, Intel Edison, STM32 Discovery et d'autres plateformes «inappropriées», telles que comme avant RaspberryPi). La prochaine exigence est la livraison fiable des messages indépendamment des défaillances possibles des services de traitement. Il s'agit d'une exigence plus forte que l'exigence d'une grande fiabilité. En effet, pour assurer la fiabilité globale de l'ensemble du système, il est nécessaire que la fiabilité de tous ses composants soit suffisamment élevée et que l'ajout d'un nouveau composant n'entraîne pas une augmentation notable du nombre de pannes. En plus de l'échec de l'infrastructure cloud, une erreur peut se produire dans le service créé par l'utilisateur. Et même dans ce cas, le message doit être traité dès que le service utilisateur est restauré. Pour ce faire, le service de réception de flux de messages doit stocker le message de manière fiable jusqu'à ce qu'il soit traité ou jusqu'à ce que sa durée de vie expire (cela est nécessaire pour éviter un débordement de mémoire pendant un flux de messages continu). Un service avec ces propriétés est appelé Event Hub. Pour les appareils IoT, il existe des hubs spécialisés (IoT Hub), qui ont un certain nombre d'autres propriétés qui sont très importantes pour une utilisation en conjonction avec les appareils Internet of Things (par exemple, la communication bidirectionnelle à partir d'un point, le routage des messages intégré, les «doubles numériques» de l'appareil et un certain nombre de autres). Cependant, ces services sont toujours spécialisés et nous ne les examinerons pas en détail.
Avant de passer au concept de concentration du message, tournons-nous vers les idées qui le sous-tendent.
Supposons que nous ayons une source de message (par exemple, les demandes d'un client) et un service qui devrait les gérer. Le traitement d'une seule demande prend du temps et nécessite des ressources de calcul (CPU, mémoire, IOPS). De plus, lors du traitement d'une demande, les demandes restantes ne peuvent pas être traitées. Pour que les applications clientes ne se figent pas en attendant la sortie d'un service, il est nécessaire de les séparer à l'aide d'un service supplémentaire qui sera chargé de stocker les messages en attendant leur traitement dans la file d'attente. Cette séparation est également nécessaire pour augmenter la fiabilité globale du système. En effet, le client envoie un message au système, mais le service de traitement peut "tomber", mais le message ne doit pas être perdu, il doit être stocké dans un service plus fiable que le service de traitement. La version la plus simple d'un tel service est appelée file d'attente (Fig. 10.1).
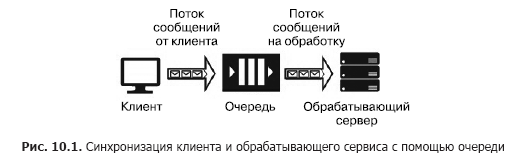
Le service de file d'attente fonctionne comme suit: le client connaît l'URL de la file d'attente et possède des clés d'accès. À l'aide du SDK ou de l'API de la file d'attente, le client y place un message qui contient l'horodatage, l'identificateur et le corps du message avec une charge utile au format JSON, XML ou binaire.
Le code de programme du service comprend un cycle qui «écoute» la file d'attente, récupérant le message suivant à chaque étape, et s'il y a un message dans la file d'attente, il est extrait et traité. Si le service traite correctement le message, il est supprimé de la file d'attente. Si une erreur se produit pendant le traitement, elle n'est pas supprimée et peut être traitée à nouveau lorsqu'une nouvelle version du service, avec le code corrigé, est lancée. La file d'attente est conçue pour synchroniser un client (ou un groupe de clients similaires) et exactement un service de traitement (bien que ce dernier puisse être situé sur un cluster de serveurs ou sur une batterie de serveurs). Les services Cloud Queuing incluent Azure Storage Queue, Azure Service Bus Queue et AWS SQS. Les services hébergés sur des machines virtuelles incluent RabbitMQ, ZeroMQ, MSMQ, IBM MQ, etc.
Différents services de file d'attente garantissent différents types de remise de messages:
- Au moins une remise de message ponctuelle
- livraison strictement ponctuelle;
- livraison des messages tout en maintenant l'ordre;
- livraison des messages sans maintenir l'ordre.
La file d'attente fournit une livraison fiable des messages d'une source à un service de traitement, c'est-à-dire une interaction un-à-un. Mais que se passe-t-il s'il est nécessaire de fournir la livraison de messages à plusieurs services? Dans ce cas, vous devez utiliser un service appelé "rubrique" (rubrique) (Fig. 10.2).
Un élément important de cette architecture est les «abonnements». Il s'agit du chemin enregistré dans la section le long de laquelle le message est envoyé. Les messages sont publiés dans le sujet par le client et transférés vers l'un des abonnements, d'où ils sont extraits par l'un des services et traités par celui-ci. Les rubriques fournissent une architecture d'interaction client-service un-à-plusieurs. Des exemples de tels services incluent la rubrique Azure Service Bus et AWS SNS.
Supposons maintenant qu'il existe un grand nombre de clients hétérogènes qui doivent envoyer de nombreux messages à divers services, c'est-à-dire que nous devons construire un système d'interaction plusieurs-à-plusieurs. Bien sûr, une telle architecture peut être construite en utilisant plusieurs sections, mais une telle construction n'est pas évolutive et nécessite des efforts d'administration et de surveillance. Cependant, il existe des services distincts - les concentrateurs de messages (Fig. 10.3).
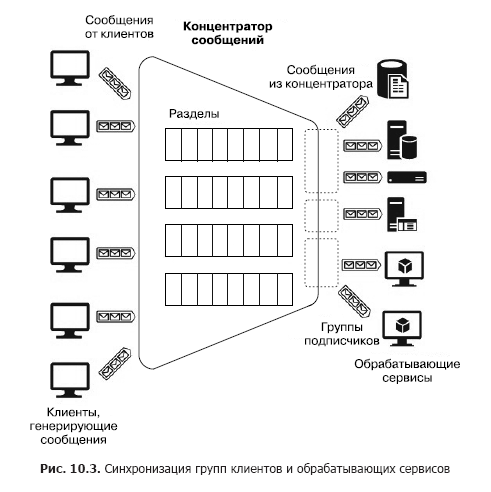
Le concentrateur accepte les messages de nombreux clients. Tous les clients peuvent envoyer des messages à un point de terminaison de service commun ou se connecter séparément à différents points de terminaison via des touches spéciales. Ces clés vous permettent de gérer les clients de manière flexible: déconnectez certains, connectez-en de nouveaux, etc. À l'intérieur du concentrateur, il y a également des partitions. Mais dans ce cas, ils peuvent être distribués à tous les clients afin d'augmenter la productivité (round robin - «avec ajout cyclique») ou le client peut publier des messages dans l'une des sections. D'un autre côté, les services de traitement sont regroupés en groupes de consommateurs. Un ou plusieurs services peuvent être connectés à un groupe. Ainsi, un concentrateur de messages est le service le plus flexible qui peut être configuré comme une file d'attente, une section ou un groupe de files d'attente ou un ensemble de sections. En général, un concentrateur de messages fournit une relation plusieurs-à-plusieurs entre les clients et les services. Ces concentrateurs incluent Apache Kafka, Azure Event Hub et AWS Kinesis Stream.
Avant d'examiner les services PaaS basés sur le cloud, nous allons prêter attention à un service très puissant et bien connu - Apache Kafka. Dans les environnements cloud, il est accessible en tant que distribution déployée directement sur un cluster de machines virtuelles ou en utilisant le service HDInsight. Donc, Apache Kafka est un service qui offre les fonctionnalités suivantes:
- Publication et abonnement à un flux de messages
- stockage fiable des messages;
- Application de services de traitement de messages en streaming tiers.
Physiquement, Kafka s'exécute dans un cluster d'un ou plusieurs serveurs. Kafka fournit une API pour interagir avec des clients externes (Fig. 10.4).
Considérez ces API dans l'ordre.
- Les API des fournisseurs permettent aux applications clientes de publier des flux de messages dans une ou plusieurs rubriques Kafka.
- Les API grand public donnent aux applications clientes la possibilité de s'abonner à un ou plusieurs sujets et de traiter les flux de messages fournis par les sujets aux clients.
- Les API du processeur de flux permettent aux applications d'interagir avec le cluster Kafka en tant que processeur de streaming. Les sources pour un processeur peuvent être un ou plusieurs sujets. Dans ce cas, les messages traités sont également placés dans un ou plusieurs sujets.
- Les API de connecteur permettent de connecter des sources de données externes (par exemple, RDB) en tant que sources de messages (par exemple, il est possible d'intercepter des événements de changement de données dans la base de données) et en tant que récepteurs.
Dans Kafka, l'interaction entre les clients et le cluster a lieu via TCP, ce qui est facilité par les SDK existants pour divers langages de programmation, dont .Net. Mais les langages de base du SDK sont Java et Scala.
Dans un cluster, le stockage des flux de messages (dans la terminologie Kafka également appelée entrées) se produit logiquement dans des objets appelés sujets (Fig. 10.5). Chaque enregistrement se compose d'une clé, d'une valeur et d'un horodatage. En substance, un sujet est une séquence d'enregistrements (messages) qui ont été publiés par les clients. Les sujets Kafka prennent en charge de 0 à plusieurs abonnés. Chaque rubrique est physiquement représentée sous la forme d'un journal partitionné. Chaque section est une séquence ordonnée d'enregistrements, à laquelle de nouveaux enregistrements arrivant à l'entrée de Kafka sont constamment ajoutés.
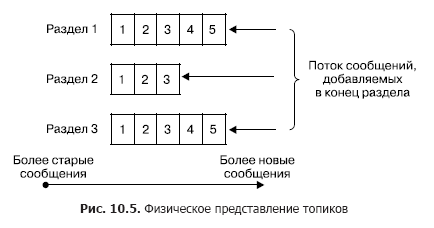
Chaque entrée de la section correspond à un numéro de la séquence, également appelé décalage, qui identifie de façon unique ce message dans la séquence. Contrairement à la file d'attente, Kafka supprime le message non pas après le traitement du service, mais après la durée de vie des messages. Il s'agit d'une propriété très importante, offrant la possibilité de lire d'un sujet à différents consommateurs. De plus, un biais est associé à chaque consommateur (Fig. 10.6). Et chaque acte de lecture n'entraîne qu'une augmentation de valeur pour chaque client individuellement et est déterminé précisément par le client.
Dans le cas normal, ce décalage augmente de un après avoir lu avec succès un message de la rubrique. Mais si nécessaire, le client peut décaler ce décalage et répéter l'opération de lecture.
L'utilisation du concept de sections a les objectifs suivants.
Premièrement, les sections offrent la possibilité de mettre à l'échelle des sujets lorsqu'un sujet ne tient pas dans le même nœud. En même temps, chaque section a un nœud principal (ne le confondez pas avec le nœud principal du cluster entier) et zéro ou plusieurs nœuds suiveurs. Le nœud principal est responsable du traitement des opérations de lecture / écriture, tandis que les suiveurs sont ses copies passives. Si le nœud maître tombe en panne, l'un des nœuds successeurs deviendra automatiquement le nœud principal. Chaque nœud de cluster est le chef de file pour certaines sections et un suiveur pour d'autres. Deuxièmement, une telle réplication augmente les performances de lecture en raison de la possibilité d'opérations de lecture parallèles.
Le producteur peut placer le message dans n'importe quel sujet de son choix de manière explicite ou en mode round robin implicitement (c'est-à-dire avec un remplissage uniforme). Les consommateurs sont unis dans les groupes dits de consommateurs, et chaque message publié dans le sujet est remis à un client dans chaque groupe de consommateurs. Dans ce cas, les clients peuvent être physiquement hébergés sur un ou plusieurs serveurs / machines virtuelles. Plus en détail, la remise des messages est la suivante. Pour tous les clients appartenant au même groupe de consommateurs, des messages peuvent être répartis entre les clients afin d'optimiser la charge. Si les clients appartiennent à différents groupes de consommateurs, chaque message sera envoyé à chaque groupe. La séparation des messages des sections par différents groupes de consommateurs est illustrée à la Fig. 10.7.
Je vais maintenant décrire brièvement les principaux paramètres de livraison et de stockage des messages garantis par Kafka.
- Les messages envoyés par le fabricant à un sujet spécifique seront ajoutés strictement dans l'ordre dans lequel ils ont été envoyés.
- Le client voit l'ordre des messages dans la rubrique qui a été reçue lors de l'enregistrement des messages. En conséquence, les messages sont transmis du producteur au consommateur strictement dans l'ordre où ils sont reçus.
- La réplication N-fois du sujet garantit la stabilité du sujet à la défaillance de N-1 nœuds sans perte de performances.
Ainsi, le service Apache Kafka peut être utilisé dans les modes suivants.
- Service - courtier de messages (file d'attente) ou service de publication - abonnement aux messages (rubrique). En effet, Kafka est basé sur un groupe de sujets qui peuvent être convertis en file d'attente avec un abonné. (Il faut se rappeler: contrairement aux services de courtage de messages habituels, construits sur le principe des files d'attente, dans Kafka, les messages ne sont supprimés qu'après l'expiration de sa durée de vie, tandis que les courtiers mettent en œuvre le principe Peek-Delete, c'est-à-dire la récupération et la suppression après un traitement réussi. ) Le principe des groupes de consommateurs résume ces deux concepts, et la possibilité de publier des messages dans tous les sujets avec la distribution de round robin fait de Kafka un courtier de messages multimode universel.
- Service d'analyse de messages en streaming. Cela est possible grâce à l'API pour les processeurs de streaming inclus dans Kafka, qui vous permet de construire des systèmes complexes, créés sur la base d'Event Driven, avec des services qui filtrent les messages ou y répondent, ainsi que des services qui agrègent les messages.
Toutes ces propriétés permettent d'utiliser Kafka en tant que composant clé d'une plate-forme qui fonctionne avec des données en streaming et possède de grandes capacités pour construire des systèmes de traitement de messages complexes. Mais en même temps, Kafka est assez compliqué en termes de déploiement et de configuration d'un cluster de plusieurs nœuds, ce qui nécessite un effort administratif important. Mais, d'autre part, étant donné que les idées sous-jacentes à Kafka sont très bien adaptées à la construction de systèmes, à la diffusion de messages et à la réception de messages, les fournisseurs de cloud fournissent des services PaaS qui mettent en œuvre ces idées et masquent toutes les difficultés de construction et d'administration d'un cluster Kafka. Mais comme ces services ont un certain nombre de restrictions en termes de personnalisation et d'extension au-delà des limites allouées aux services, les fournisseurs de cloud fournissent des services IaaS / PaaS spéciaux pour le déploiement physique de Kafka dans un cluster de machines virtuelles. Dans ce cas, l'utilisateur a une liberté de configuration et d'extension presque complète. Ces services incluent Azure HDInsight. Cela a déjà été mentionné ci-dessus. Il a été créé afin, d'une part, de fournir à l'utilisateur des services de l'écosystème Hadoop par lui-même, sans wrappers externes, et d'autre part, de soulager les difficultés résultant de l'installation, de l'administration et de la configuration directes de l'IaaS. L'hébergement Docker est un peu à part. Puisqu'il s'agit d'un sujet extrêmement important, nous allons l'examiner, mais familiarisez-vous d'abord avec les services PaaS mis en œuvre en utilisant les concepts de base de Kafka.
10.2. Hub d'événements Azure
Considérez le service de concentrateur de messages Azure Event Hub. Il s'agit d'un service construit sur le modèle PaaS. Différents groupes de clients peuvent agir comme sources de messages pour Azure Event Hub (figure 10.8). Tout d'abord, il s'agit d'un très grand groupe de services cloud dont les sorties ou les déclencheurs peuvent être configurés pour envoyer des messages directement au Event Hub. Ceux-ci peuvent être Stream Analytics Job, Event Grid et un groupe important de services qui redirigent les événements - les journaux dans Event Hub (principalement construits à l'aide de AppService: Api App, Web App, Mobile App et Function App).
Les messages remis au concentrateur peuvent être capturés directement et stockés dans le stockage Blob ou Data Lake Store.
Le groupe de sources suivant est constitué de clients ou d'appareils logiciels externes pour lesquels il n'existe pas de SDK Azure Event Hub et qui ne peuvent pas être directement intégrés aux services Azure. Ces clients incluent principalement des appareils IoT. Ils peuvent envoyer des messages au Event Hub via HTTPS ou AMQP. La réflexion sur la manière de connecter ces appareils dépasse le cadre de notre livre.
Enfin, les clients logiciels qui génèrent des messages et les envoient au Event Hub à l'aide du SDK Azure Event Hub. Ce groupe comprend Azure PowerShell et Azure CLI.
En tant que récepteurs de messages (consommateurs - «consommateurs») du Event Hub, Stream Analytics Job ou le service d'intégration Event Grid peuvent être utilisés. De plus, il est possible de recevoir des messages de clients logiciels à l'aide du SDK Azure Event Hub. Les consommateurs se connectent à Event Hub à l'aide du protocole AMQP 1.0.
Considérez les concepts de base d'Azure Event Hub nécessaires pour comprendre comment l'utiliser et le configurer. Toute source (également appelée éditeur dans la documentation) qui envoie un message au concentrateur doit utiliser le protocole HTTPS ou AMQP 1.0. Le choix d'un protocole est déterminé par le type de client, le réseau de communication et les exigences de débit de messages. AMQP nécessite une connexion permanente entre deux sockets TCP bidirectionnels. Il est protégé en utilisant le protocole de cryptage de la couche de transport TLS ou SSL / TLS. , , AMQP , HTTPS, . HTTPS.
, SAS (Shared Access Signature) tokens. SAS- SAS . SAS-, ( ).
256 . , .
, Event Hub. , , , -. EventHub (partitions). EventHub — , « — » (FIFO) (. 10.9).
— Event Hub. Event Hub 2 32 , Event Hub. , .
( ) , ( , — . ), (retention period), . . . , Azure Event Hub (offset). — , , , , . . Azure Event Hub SDK , , . -, .
, , , , . Azure Event Hub SDK , . , Storage Account. Azure, Event Hub, .
Event Hub (partition key), . — . , ( ) . , (round robin).
. , (consumer group) (. 10.11). . (view) ( ) , , . , . — 20, , .
. , . , (throughput unit). :
. , . . . Faites attention! , , , Event Hub.
(namespace) (. 10.12).
»Plus d'informations sur le livre sont disponibles sur
le site Web de l'éditeur»
Contenu»
Extrait20% de réduction sur les
colporteurs -
BigData