Fatal 43 secondes, ce qui a provoqué la dégradation quotidienne du serviceUn
incident s'est produit sur GitHub la semaine dernière qui a dégradé le service pendant 24 heures et 11 minutes. L'incident n'a pas affecté l'ensemble de la plateforme, mais seulement quelques systèmes internes, ce qui a conduit à l'affichage d'informations obsolètes et incohérentes. En fin de compte, les données utilisateur n'ont pas été perdues, mais la réconciliation manuelle de plusieurs secondes d'écriture dans la base de données est toujours en cours. Pour la plupart de l'accident, GitHub n'a pas non plus été en mesure de gérer les webhooks, de créer et de publier des pages GitHub.
Chez GitHub, nous tenons tous à nous excuser sincèrement pour les problèmes que vous avez tous rencontrés. Nous connaissons votre confiance en GitHub et sommes fiers de créer des systèmes durables qui prennent en charge la haute disponibilité de notre plateforme. Nous vous avons laissé tomber cet incident et le regrettons profondément. Bien que nous ne puissions pas résoudre les problèmes dus à la dégradation de la plate-forme GitHub pendant longtemps, nous pouvons expliquer les raisons de ce qui s'est passé, parler des leçons apprises et des mesures qui permettront à l'entreprise de mieux se protéger contre de telles défaillances à l'avenir.
Contexte
La plupart des services utilisateur GitHub fonctionnent dans nos propres
centres de données . La topologie du centre de données est conçue pour fournir un réseau frontalier fiable et extensible devant plusieurs centres de données régionaux qui fournissent le travail des systèmes informatiques et de stockage de données. Malgré les niveaux de redondance intégrés aux composants physiques et logiques du projet, il est toujours possible que les sites ne puissent pas interagir les uns avec les autres pendant un certain temps.
Le 21 octobre, à 22 h 52 UTC, les travaux de réparation prévus pour remplacer l'équipement optique 100G défectueux ont entraîné une perte de communication entre le nœud du réseau sur la côte est (côte est des États-Unis) et le principal centre de données sur la côte est. La connexion entre eux a été rétablie après 43 secondes, mais cette courte déconnexion a provoqué une chaîne d'événements qui a entraîné 24 heures et 11 minutes de dégradation du service.
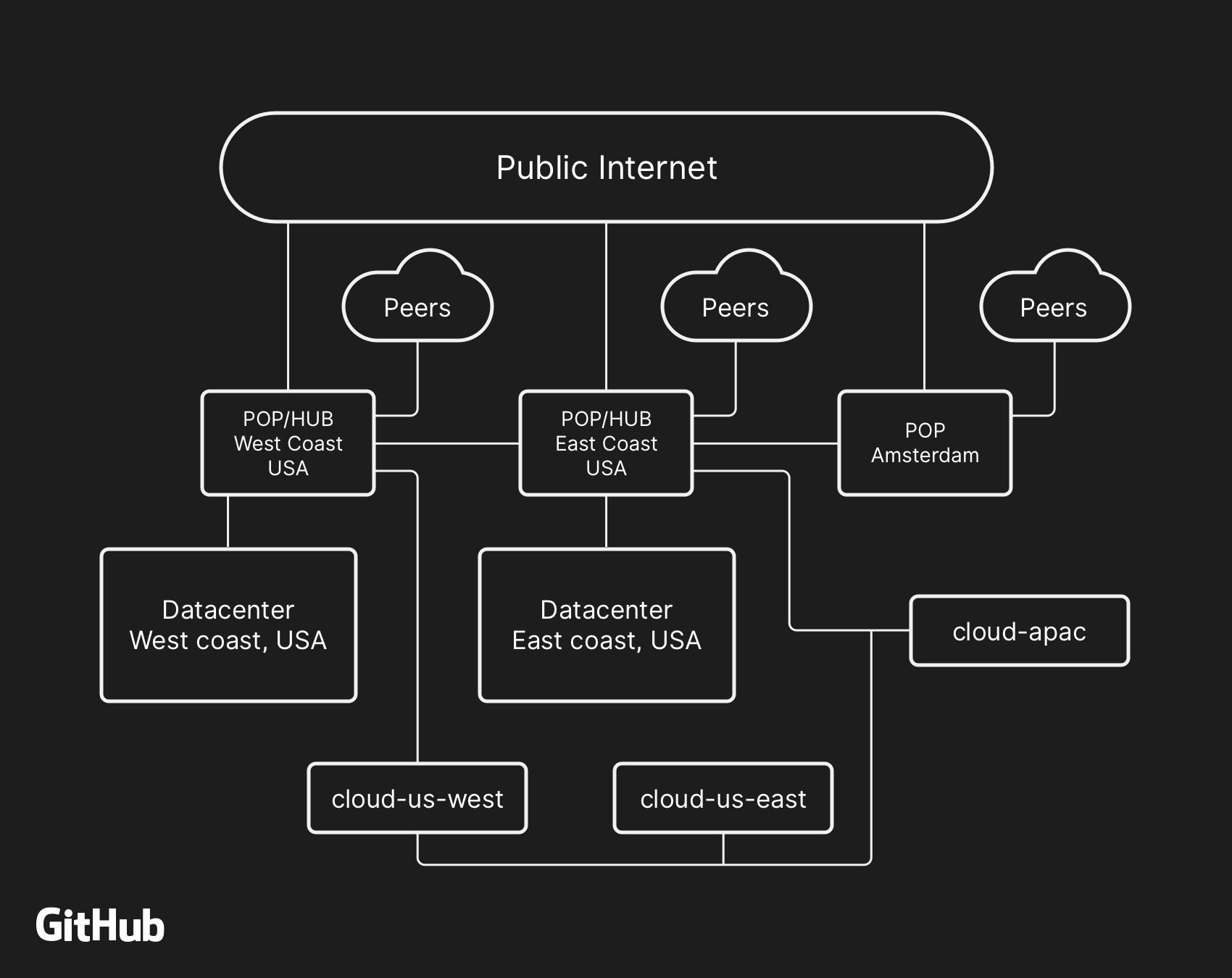 L'architecture de réseau de haut niveau de GitHub, comprenant deux centres de données physiques, 3 POP et un stockage cloud dans plusieurs régions, connectés via l'homologation
L'architecture de réseau de haut niveau de GitHub, comprenant deux centres de données physiques, 3 POP et un stockage cloud dans plusieurs régions, connectés via l'homologationDans le passé, nous avons discuté de la façon dont nous utilisons
MySQL pour stocker les métadonnées GitHub , ainsi que de notre approche pour fournir une
haute disponibilité pour MySQL . GitHub gère plusieurs clusters MySQL dont la taille varie de centaines de gigaoctets à près de cinq téraoctets. Chaque cluster possède des dizaines de réplicas en lecture pour stocker des métadonnées autres que Git, de sorte que nos applications fournissent des demandes de pool, des problèmes, l'authentification, le traitement en arrière-plan et des fonctionnalités supplémentaires en dehors du référentiel d'objets Git. Différentes données dans différentes parties de l'application sont stockées dans différents clusters à l'aide de la segmentation fonctionnelle.
Pour améliorer les performances à grande échelle, les applications dirigent les écritures sur le serveur principal approprié pour chaque cluster, mais dans la grande majorité des cas, délèguent les demandes de lecture à un sous-ensemble de serveurs de réplicas. Nous utilisons
Orchestrator pour gérer les topologies de cluster MySQL et basculer automatiquement. Au cours de ce processus, Orchestrator prend en compte un certain nombre de variables et est assemblé au-dessus de
Raft pour plus de cohérence. Orchestrator peut potentiellement implémenter des topologies que les applications ne prennent pas en charge, vous devez donc vous assurer que votre configuration Orchestrator répond aux attentes au niveau de l'application.
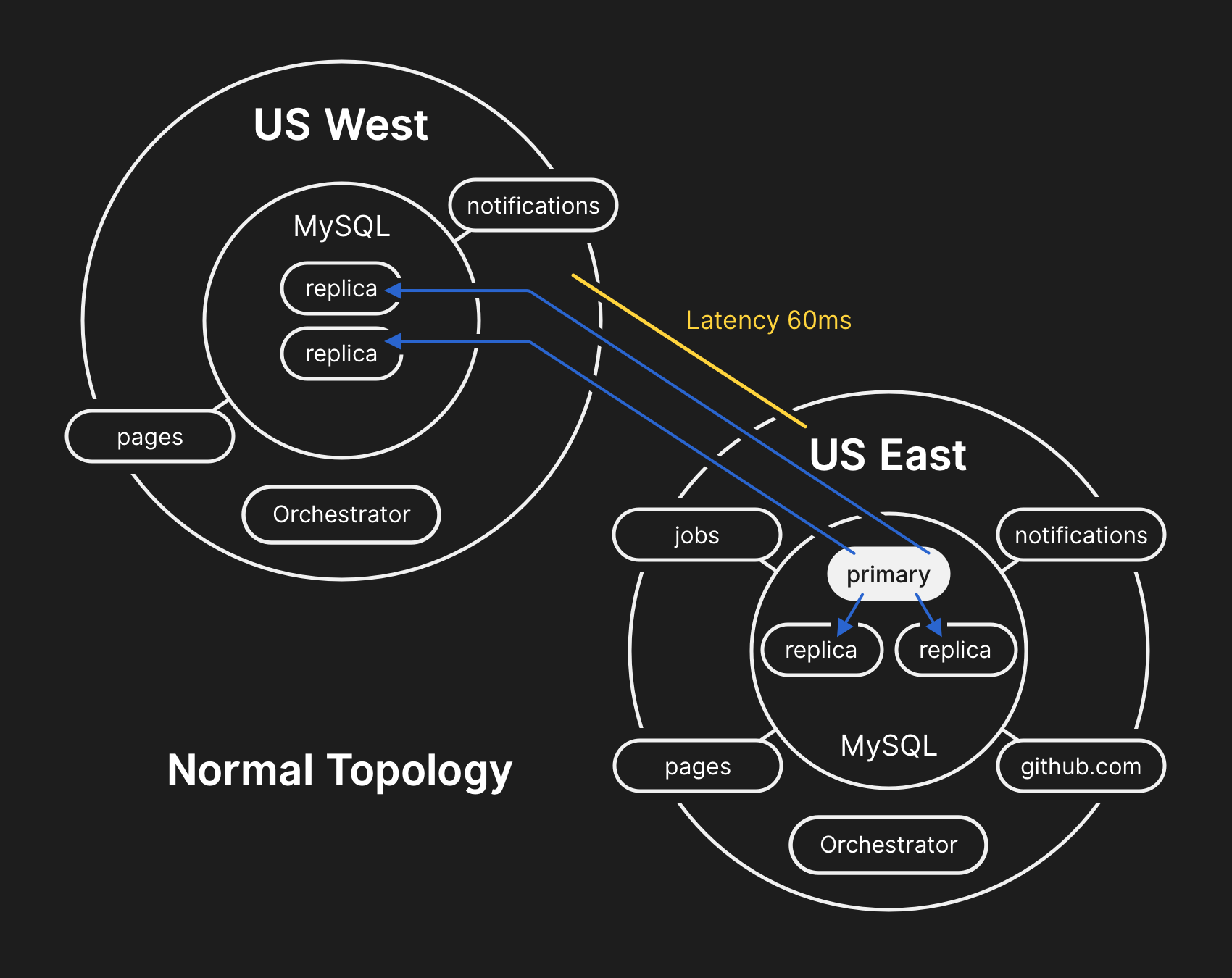 Dans une topologie typique, toutes les applications lisent localement avec une faible latence.
Dans une topologie typique, toutes les applications lisent localement avec une faible latence.Chronique de l'incident
10.21.2018, 22:52 UTC
Au cours de la séparation du réseau susmentionnée, Orchestrator dans le centre de données principal a commencé le processus de désélection du leadership selon l'algorithme de consensus Raft. Le centre de données de la côte ouest et les nœuds de cloud public Orchestrator sur la côte est ont réussi à atteindre un consensus - et ont commencé à résoudre les échecs de cluster pour transmettre les enregistrements au centre de données occidental. Orchestrator a commencé à créer une topologie de cluster de base de données dans l'Ouest. Après la reconnexion, les applications ont immédiatement envoyé du trafic d'écriture vers les nouveaux serveurs principaux dans l'ouest américain.
Sur les serveurs de bases de données du centre de données oriental, il y avait des enregistrements pour une courte période qui n'étaient pas répliqués vers le centre de données occidental. Étant donné que les clusters de bases de données dans les deux centres de données contenaient désormais des enregistrements qui ne se trouvaient pas dans l'autre centre de données, nous n'avons pas pu retourner en toute sécurité le serveur principal au centre de données oriental.
10.21.2018, 22:54 UTC
Nos systèmes de surveillance internes ont commencé à générer des alertes indiquant de nombreux dysfonctionnements du système. À cette époque, plusieurs ingénieurs ont répondu et travaillé sur le tri des notifications entrantes. À 23 h 02, les ingénieurs du premier groupe de réponse ont déterminé que les topologies de nombreux clusters de bases de données étaient dans un état inattendu. Lors de l'interrogation de l'API Orchestrator, la topologie de réplication de la base de données était affichée, ne contenant que les serveurs du centre de données occidental.
10.21.2018, 23:07 UTC
À ce stade, l'équipe d'intervention a décidé de bloquer manuellement les outils de déploiement interne pour empêcher des modifications supplémentaires. À 23 h 09, le groupe a mis le site en
jaune . Cette action a automatiquement attribué à la situation le statut d'incident actif et envoyé un avertissement au coordinateur d'incident. À 23h11, le coordinateur a rejoint le travail et deux minutes plus tard a décidé de
changer le statut en rouge .
10.21.2018, 23:13 UTC
À cette époque, il était clair que le problème affectait plusieurs clusters de bases de données. D'autres développeurs du groupe d'ingénierie de la base de données ont été impliqués dans les travaux. Ils ont commencé à examiner l'état actuel pour déterminer les actions à entreprendre pour configurer manuellement la base de données de la côte est des États-Unis en tant que principale pour chaque cluster et reconstruire la topologie de réplication. Cela n'a pas été facile, car à ce stade, le cluster de bases de données occidentales recevait des enregistrements du niveau application depuis près de 40 minutes. De plus, dans la grappe orientale, il y avait plusieurs secondes d'enregistrements qui n'étaient pas répliqués vers l'ouest et ne permettaient pas la réplication de nouveaux enregistrements vers l'est.
La protection de la confidentialité et de l'intégrité des données utilisateur est la priorité absolue de GitHub. Par conséquent, nous avons décidé que plus de 30 minutes de données enregistrées dans le centre de données occidental ne nous laissaient qu'une seule solution à la situation afin de sauvegarder ces données: le transfert vers l'avant (échec vers l'avant). Cependant, les applications de l'Est, qui dépendent de l'écriture d'informations dans le cluster MySQL occidental, ne sont actuellement pas en mesure de gérer le délai supplémentaire dû au transfert de la plupart de leurs appels de base de données dans les deux sens. Cette décision entraînera le fait que notre service deviendra inapproprié pour de nombreux utilisateurs. Nous pensons que la dégradation à long terme de la qualité de service valait la peine d'assurer la cohérence des données de nos utilisateurs.
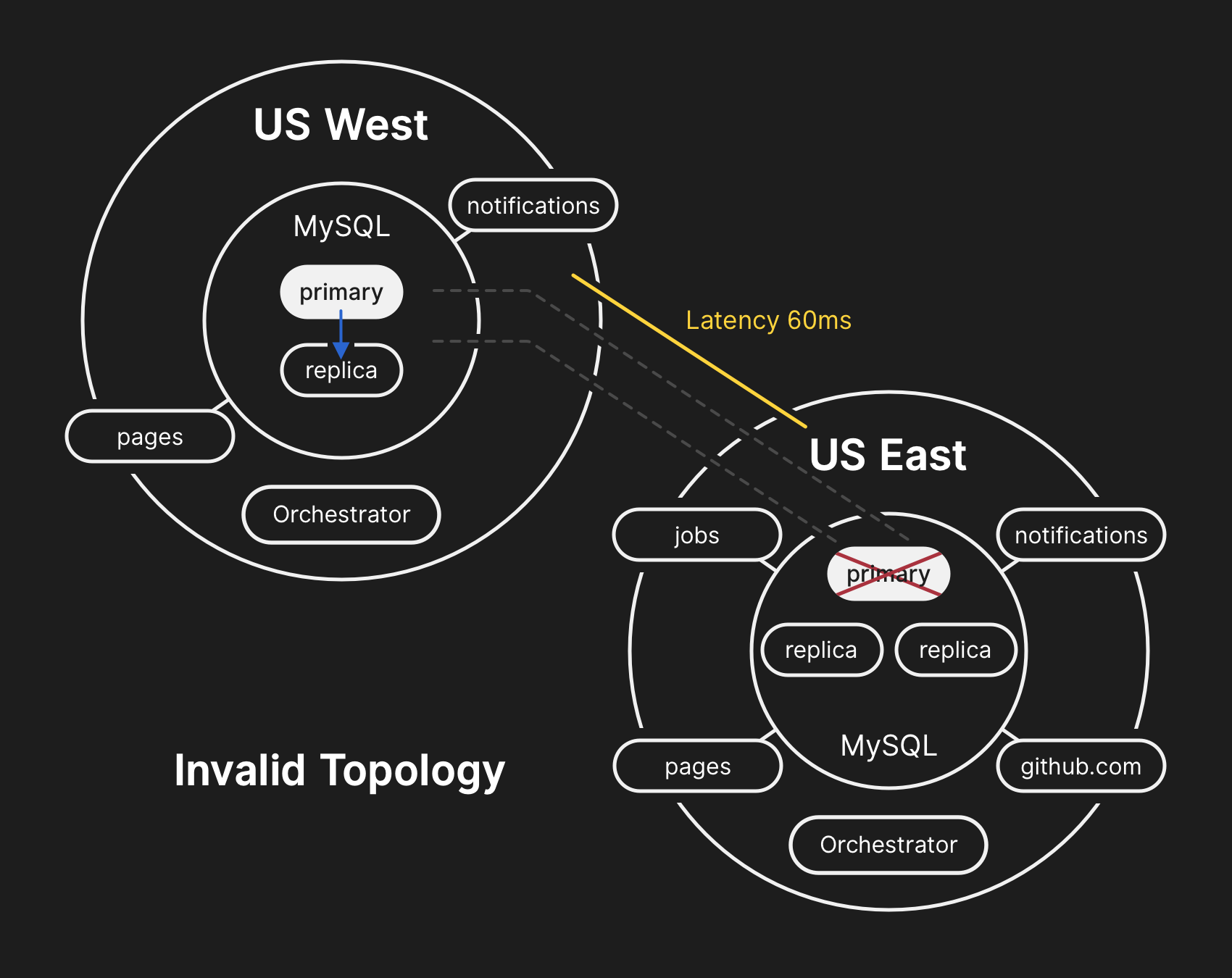 Dans la mauvaise topologie, la réplication d'Ouest en Est est violée et les applications ne peuvent pas lire les données des réplicas actuels, car elles dépendent d'une faible latence pour maintenir les performances des transactions
Dans la mauvaise topologie, la réplication d'Ouest en Est est violée et les applications ne peuvent pas lire les données des réplicas actuels, car elles dépendent d'une faible latence pour maintenir les performances des transactions10.21.2018, 23:19 UTC
Les enquêtes sur l'état des clusters de bases de données ont montré qu'il était nécessaire d'arrêter l'exécution des tâches qui écrivent des métadonnées telles que les requêtes push. Nous avons fait un choix et avons délibérément opté pour une dégradation partielle du service, suspendant les webhooks et l'assemblage des pages GitHub afin de ne pas mettre en péril les données que nous avons déjà reçues des utilisateurs. En d'autres termes, la stratégie était de prioriser: l'intégrité des données au lieu de la convivialité du site et une récupération rapide.
22/10/2018, 00:05 UTC
Les ingénieurs de l'équipe d'intervention ont commencé à développer un plan pour résoudre les incohérences de données et ont lancé des procédures de basculement pour MySQL. Le plan était de restaurer les fichiers à partir de la sauvegarde, de synchroniser les réplicas sur les deux sites, de revenir à une topologie de service stable, puis de reprendre les travaux de traitement dans la file d'attente. Nous avons mis à jour le statut pour informer les utilisateurs que nous allons effectuer un basculement géré du système de stockage interne.
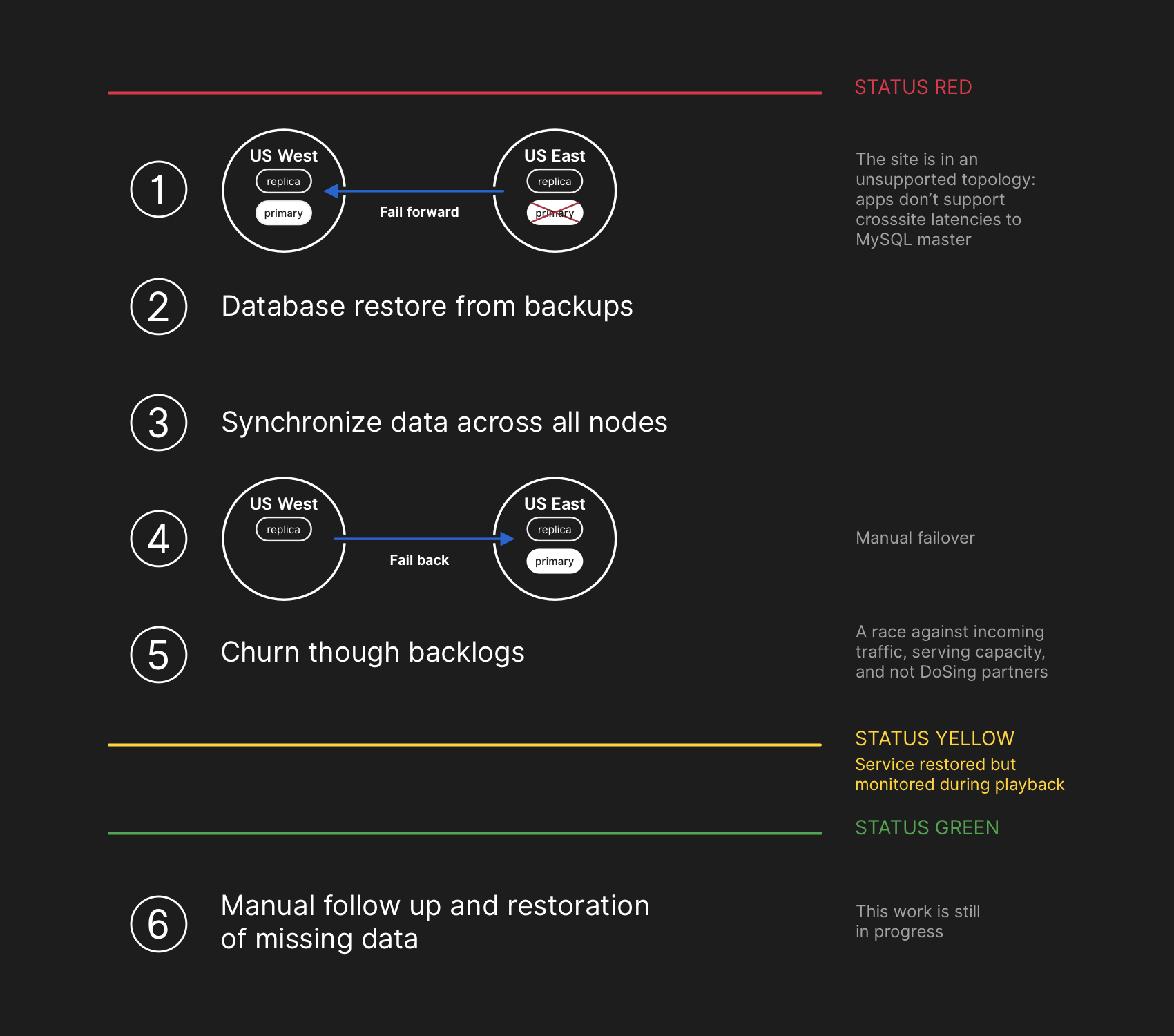 Le plan de récupération impliquait d'aller de l'avant, de restaurer à partir de sauvegardes, de synchroniser, d'annuler et de travailler sur le délai avant de revenir au statut vert
Le plan de récupération impliquait d'aller de l'avant, de restaurer à partir de sauvegardes, de synchroniser, d'annuler et de travailler sur le délai avant de revenir au statut vertBien que les sauvegardes MySQL soient effectuées toutes les quatre heures et stockées pendant de nombreuses années, elles se trouvent dans un stockage cloud distant d'objets blob. La récupération de plusieurs téraoctets à partir d'une sauvegarde a pris plusieurs heures. Le transfert des données du service de sauvegarde à distance a pris beaucoup de temps. La plupart du temps a été consacré au déballage, à la vérification de la somme de contrôle, à la préparation et au téléchargement de fichiers de sauvegarde volumineux sur des serveurs MySQL fraîchement préparés. Cette procédure est testée quotidiennement, donc tout le monde avait une bonne idée du temps que prendrait la récupération. Cependant, avant cet incident, nous n'avions jamais eu à reconstruire complètement l'intégralité du cluster à partir d'une sauvegarde. D'autres stratégies ont toujours fonctionné, comme les répliques différées.
22/10/2018, 00:41 UTC
À ce moment, un processus de sauvegarde avait été lancé pour tous les clusters MySQL concernés et les ingénieurs ont suivi les progrès. Dans le même temps, plusieurs groupes d'ingénieurs ont étudié les moyens d'accélérer le transfert et la récupération sans dégradation supplémentaire du site ni risque de corruption des données.
22/10/2018, 06:51 UTC
Plusieurs clusters dans le centre de données oriental ont terminé la récupération des sauvegardes et ont commencé à répliquer de nouvelles données de la côte ouest. Cela a entraîné un ralentissement du chargement des pages qui ont effectué une opération d'écriture à travers le pays, mais la lecture des pages de ces clusters de base de données a retourné des résultats réels si la demande de lecture tombait sur une réplique nouvellement restaurée. D'autres clusters de bases de données plus importants ont continué de se redresser.
Nos équipes ont identifié une méthode de récupération directement depuis la côte ouest pour surmonter les limitations de bande passante causées par le démarrage à partir d'un stockage externe. Il est devenu presque clair à 100% que la récupération se terminera avec succès, et le temps nécessaire pour créer une topologie de réplication saine dépend du temps nécessaire à la réplication de rattrapage. Cette estimation a été interpolée linéairement en fonction de la réplication de télémétrie disponible, et la page d'état a été
mise à
jour pour définir l'attente de deux heures comme temps de récupération estimé.
22/10/2018, 07:46 UTC
GitHub a publié un
article de blog informatif . Nous utilisons nous-mêmes les pages GitHub, et tous les assemblages ont été interrompus il y a quelques heures, la publication a donc nécessité des efforts supplémentaires. Nous nous excusons pour le retard. Nous avions l'intention d'envoyer ce message beaucoup plus tôt et à l'avenir, nous fournirons la publication de mises à jour dans les conditions de ces restrictions.
22/10/2018, 11:12 UTC
Toutes les bases de données primaires sont à nouveau transférées vers l'Est. Cela a conduit le site à devenir beaucoup plus réactif, car les enregistrements étaient désormais acheminés vers un serveur de base de données situé dans le même centre de données physique que notre couche d'application. Bien que cela ait considérablement amélioré les performances, il y avait encore des dizaines de répliques de lecture de la base de données qui étaient plusieurs heures derrière la copie principale. Ces répliques différées ont conduit les utilisateurs à voir des données incohérentes lors de leurs interactions avec nos services. Nous répartissons la charge de lecture sur un large pool de réplicas de lecture, et chaque demande à nos services a de bonnes chances d'entrer dans la réplique de lecture avec un retard de plusieurs heures.
En fait, le temps de rattrapage d'une réplique en retard est réduit de façon exponentielle et non linéaire. Lorsque les utilisateurs aux États-Unis et en Europe se sont réveillés, en raison de la charge accrue des enregistrements dans les clusters de bases de données, le processus de récupération a pris plus de temps que prévu.
22/10/2018, 13:15 UTC
Nous approchions de la charge de pointe sur GitHub.com. L'équipe d'intervention a discuté des prochaines étapes. Il était clair que le retard de réplication vers un état cohérent augmente, et non diminue. Plus tôt, nous avons commencé à préparer des répliques de lecture MySQL supplémentaires dans le cloud public de la côte Est. Une fois disponibles, il est devenu plus facile de répartir le flux des demandes de lecture entre plusieurs serveurs. La réduction de la charge moyenne des réplicas en lecture a accéléré le rattrapage de la réplication.
22/10/2018, 16:24 UTC
Après avoir synchronisé les répliques, nous sommes revenus à la topologie d'origine, éliminant les problèmes de retard et de disponibilité. Dans le cadre d'une décision consciente sur la priorité de l'intégrité des données par rapport à une correction rapide de la situation, nous avons
maintenu le statut rouge du site lorsque nous avons commencé à traiter les données accumulées.
22/10/2018, 16:45 UTC
Au stade de la récupération, il était nécessaire d'équilibrer la charge accrue associée au décalage, surchargeant potentiellement nos partenaires de l'écosystème de notifications et revenant à une efficacité à cent pour cent aussi rapidement que possible. Plus de cinq millions d'événements de raccordement et 80 000 demandes de création de pages Web sont restés dans la file d'attente.
Lorsque nous avons réactivé le traitement de ces données, nous avons traité environ 200 000 tâches utiles avec des webhooks qui dépassaient le TTL interne et ont été abandonnées. En apprenant cela, nous avons arrêté le traitement et commencé à augmenter le TTL.
Pour éviter une nouvelle diminution de la fiabilité de nos mises à jour de statut, nous avons laissé le statut de dégradation jusqu'à ce que nous ayons fini de traiter l'intégralité de la quantité de données accumulées et de nous assurer que les services sont clairement revenus au niveau normal de performance.
22/10/2018, 23h03 UTC
Tous les événements de webhook et assemblages de pages incomplets sont traités, et l'intégrité et le bon fonctionnement de tous les systèmes sont confirmés. Le statut du site est passé
au vert .
Actions supplémentaires
Résolution de l'inadéquation des données
Pendant la récupération, nous avons corrigé les journaux binaires MySQL avec des entrées principalement du centre de données, qui n'étaient pas répliquées vers le centre de l'Ouest. Le nombre total de ces entrées est relativement faible. Par exemple, dans l'un des clusters les plus occupés, il n'y a que 954 enregistrements dans ces secondes. Nous analysons actuellement ces journaux et déterminons quelles entrées peuvent être automatiquement rapprochées et lesquelles nécessitent une assistance utilisateur. Plusieurs équipes participent à ce travail, et notre analyse a déjà déterminé la catégorie d'enregistrements que l'utilisateur a ensuite répétés - et ils ont été enregistrés avec succès. Comme indiqué dans cette analyse, notre objectif principal est de maintenir l'intégrité et la précision des données que vous stockez sur GitHub.
La communication
En essayant de vous transmettre des informations importantes pendant l'incident, nous avons fait plusieurs estimations publiques du temps de récupération en fonction de la vitesse de traitement des données accumulées. Rétrospectivement, nos estimations n'ont pas pris en compte toutes les variables. Nous nous excusons pour la confusion et nous nous efforcerons de fournir des informations plus précises à l'avenir.
Mesures techniques
Au cours de cette analyse, un certain nombre de mesures techniques ont été identifiées. L'analyse se poursuit, la liste peut être complétée.
- Ajustez la configuration d'Orchestrator pour empêcher les bases de données principales de se déplacer hors de la région. Orchestrator a fonctionné selon les paramètres, bien que la couche application ne prenne pas en charge un tel changement de topologie. Le choix d'un leader dans une région est généralement sûr, mais l'apparition soudaine d'un retard dû à la circulation à travers le continent est devenue la principale cause de cet incident. Il s'agit d'un comportement nouveau et émergent du système, car avant nous ne rencontrions pas la section interne du réseau de cette ampleur.
- Nous avons accéléré la migration vers le nouveau système de rapport d'état, qui fournira une plate-forme plus appropriée pour discuter des incidents actifs avec des formulations plus précises et claires. Bien que de nombreuses parties de GitHub aient été disponibles tout au long de l'incident, nous n'avons pu sélectionner que les états vert, jaune et rouge pour l'ensemble du site. Nous admettons que cela ne donne pas une image précise: ce qui fonctionne et ce qui ne fonctionne pas. Le nouveau système affichera les différents composants de la plateforme afin que vous connaissiez l'état de chaque service.
- Quelques semaines avant cet incident, nous avons lancé une initiative d'ingénierie à l'échelle de l'entreprise pour prendre en charge le trafic GitHub à partir de plusieurs centres de données en utilisant l'architecture active / active / active. L'objectif de ce projet est de prendre en charge la redondance N + 1 au niveau du centre de données afin de résister à la défaillance d'un centre de données sans interférence extérieure. Cela représente beaucoup de travail et prendra du temps, mais nous pensons que plusieurs centres de données bien connectés dans différentes régions constitueront un bon compromis. Le dernier incident a poussé cette initiative encore plus loin.
- Nous prendrons une position plus active dans la vérification de nos hypothèses. GitHub se développe rapidement et a accumulé une quantité considérable de complexité au cours de la dernière décennie. Il devient de plus en plus difficile de saisir et de transmettre à la nouvelle génération d'employés le contexte historique des compromis et des décisions prises.
Mesures organisationnelles
Cet incident a grandement influencé notre compréhension de la fiabilité du site. Nous avons appris que resserrer le contrôle opérationnel ou améliorer les temps de réponse ne sont pas des garanties suffisantes de fiabilité dans un système de services aussi complexe que le nôtre. Pour soutenir ces efforts, nous commencerons également une pratique systématique de test des scénarios de panne avant qu'ils ne se produisent réellement. Ce travail comprend un dépannage délibéré et l'utilisation d'outils d'ingénierie du chaos.
Conclusion
Nous savons comment vous comptez sur GitHub dans vos projets et votre entreprise. Nous nous soucions plus que quiconque de la disponibilité de notre service et de la sécurité de vos données. L'analyse de cet incident continuera de trouver une occasion de mieux vous servir et de justifier votre confiance.