Dans les commentaires
sur notre dernier article , il y avait beaucoup de questions sur les technologies que nous utilisons. Dans cet article, je - Igor Mosyagin, développeur R&D de Lamoda - je vais vous en parler. Sous la coupe, vous trouverez une liste exhaustive des langages, outils, plateformes et technologies qui sont passés entre nos mains. Le frontend, le backend, la base de données, les courtiers de messages, les caches et la surveillance, le développement et l'équilibrage sont une histoire détaillée de ce que nous utilisons aujourd'hui et de ce que nous avons abandonné.
Mes collègues et moi sommes prêts à discuter dans les commentaires ou sur le stand de l'entreprise à HighLoad ++ 2018.
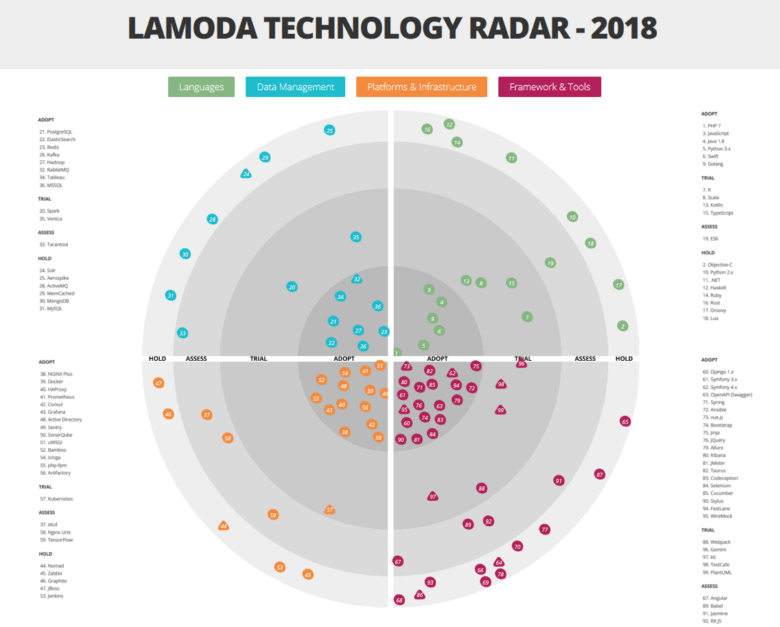
Voir le radar en grand et détaillé ici.Comme nous l'avons déjà dit, un grand nombre de technologies et d'outils différents sont impliqués dans Lamoda. Et ce n'est pas un hasard. Sinon, nous ne pouvons pas faire face à la charge! Nous avons un grand entrepôt automatisé. Notre centre d'appels est desservi par 500 employés, et les processus que nous avons construits nous permettent de rappeler le client dans les 5 minutes après avoir passé la commande. Notre service de livraison fonctionne à des intervalles de 15 minutes. Mais en plus de nos propres systèmes, nous avons une intégration B2B avec d'autres magasins en ligne. Avec une telle variété de tâches et les exigences d'une entreprise aussi dynamique que le commerce électronique, la croissance de la pile technique est inévitable, car nous voulons résoudre chaque problème avec les technologies les plus adaptées. La diversité est inévitable. Nous parlerons des principaux représentants de notre pile ci-dessous. Mais commençons par des mécanismes qui nous permettent de ne pas nous perdre dans cette variété.
Les bases de l'architecture
Nous évoluons activement vers une architecture de microservices. La plupart des systèmes ont déjà été construits conformément à cette idéologie - il y a deux ans, nous avons traversé une phase de transition avec nos problèmes et leurs solutions. Mais nous ne nous attarderons pas sur les détails de ce processus - un rapport d'Andrey Evsyukov "
Caractéristiques des microservices sur l'exemple d'une plate-forme e-Com " en dira beaucoup plus à ce sujet.
Afin de ne pas aggraver la diversité technologique, nous avons introduit une «dictature des pratiques éprouvées», selon laquelle il est recommandé aux créateurs de nouvelles puces d'utiliser les technologies et outils déjà utilisés quelque part dans l'entreprise. La plupart des services communiquent entre eux via l'API (nous utilisons notre modification de la deuxième version de la norme JSONRPC), mais lorsque la logique métier le permet, nous utilisons également le bus de données pour l'interaction.
L'utilisation d'autres technologies n'est pas interdite. Cependant, toute nouvelle idée doit être testée dans un comité d'architecture spécialement créé, qui comprend des dirigeants des principaux domaines.
Compte tenu de la proposition suivante, le comité donne le feu vert à l'expérience ou propose une sorte de remplacement de la pile existante. Soit dit en passant, cette décision dépend en grande partie des circonstances actuelles de l'entreprise. Par exemple, si une équipe arrive la veille de la vente du Black Friday et annonce qu'elle introduira une technologie dans la production dont le comité n'avait jamais entendu parler auparavant, elle sera très probablement refusée. D'un autre côté, la même expérience peut recevoir le feu vert si une nouvelle technologie ou un nouvel outil est introduit dans des circonstances commerciales moins critiques, et la mise en œuvre commencera par des tests en dehors de la production.
Le comité d'architecture est également responsable de la maintenance du radar technologique, en effectuant les changements nécessaires tous les 2-3 mois. L'un des objectifs de cette ressource est de donner aux équipes une idée du type d'expertise dont l'entreprise dispose déjà.
Mais passons au plus intéressant - à l'analyse des secteurs de notre radar.
Il convient de noter que nous utilisons une interprétation légèrement non standard des catégories d'adoption des technologies:
- ADOPTER - technologies et outils qui sont mis en œuvre et activement utilisés;
- TRIAL - technologies et outils qui ont déjà passé la phase de test et se préparent à travailler avec la production (ou même y travaillent déjà);
- ÉVALUER - outils d'essai qui sont en cours d'évaluation et qui n'affectent pas encore la production. Avec leur participation, seuls des projets tests sont mis en œuvre;
- HOLD - dans cette catégorie, nous avons une expertise, mais les outils mentionnés ne sont utilisés qu'avec le soutien de systèmes existants - de nouveaux projets ne sont pas lancés sur eux.
Développement
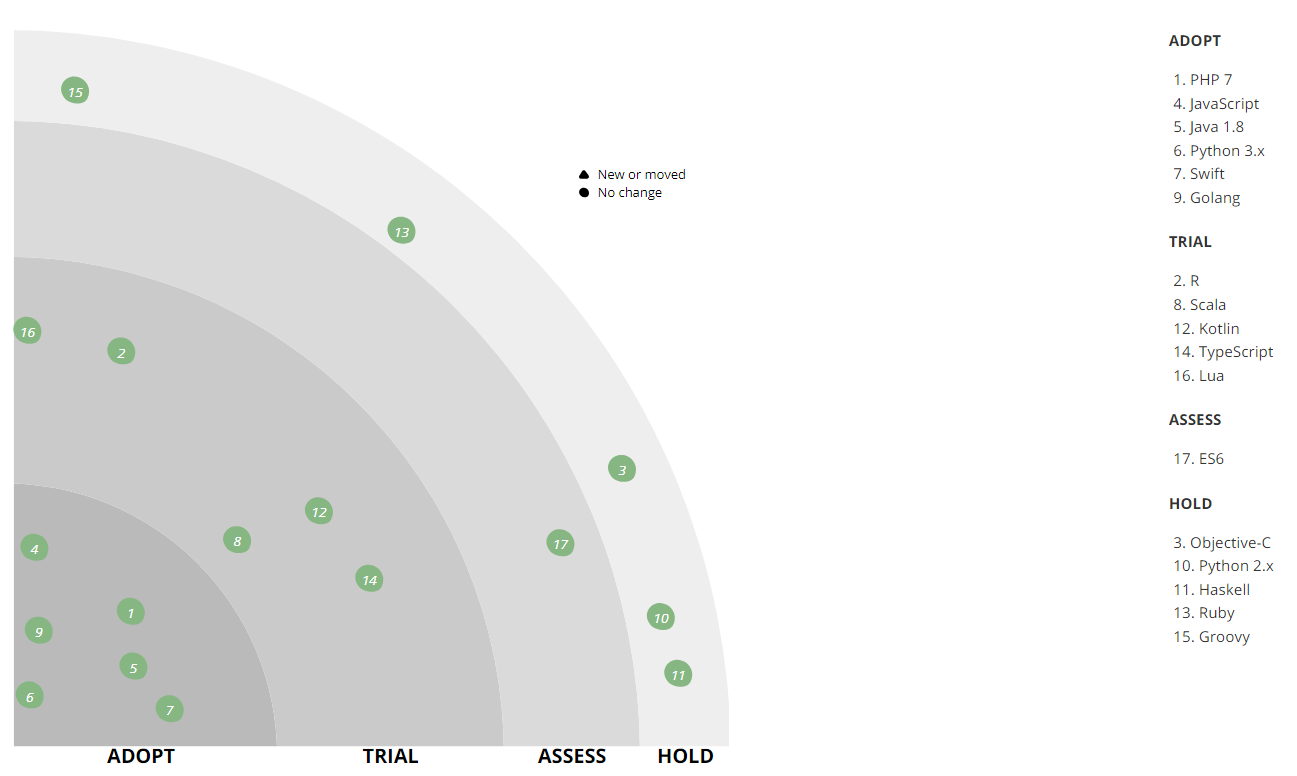
PHP - Python - Aller
Le premier langage sur lequel nous voulons nous attarder est PHP. Aujourd'hui, il ne résout qu'une partie des tâches de backend du magasin, et au départ, tout le backend fonctionnait sur PHP. Alors que l'entreprise se développait sur le front-end, un manque de vitesse et de productivité est devenu perceptible - à l'époque, nous utilisions PHP 5, donc Python l'a remplacé (d'abord 2.x, puis 3.x). Cependant, PHP vous permet d'écrire des modèles commerciaux riches, donc ce langage est resté dans le back-office pour automatiser divers processus opérationnels, en particulier l'intégration avec des magasins en ligne tiers ou des services de livraison, ainsi que l'automatisation d'un studio de contenu qui établit des fiches produits. Maintenant, nous utilisons déjà PHP 7. En PHP, nous avons écrit de nombreuses bibliothèques à usage interne: intégration et wrappers sur notre infrastructure, couche d'intégration entre les services, divers helpers réutilisés. Le premier lot de bibliothèques a déjà été mis en open source sur
notre github.com , et le reste, le plus "mûri", arrivera bientôt. L'une des premières était une machine à états, qui, présente dans presque toutes les applications, s'assure qu'avec la commande avant d'envoyer toutes les actions nécessaires.
Au fil du temps, Python est également devenu insuffisant pour un backend de magasin. Maintenant, nous préférons un Go plus productif et plus léger.
Peut-être que la transition vers Go a été un changement important, car elle a permis d'économiser beaucoup de matériel et de ressources humaines - l'efficacité a considérablement augmenté. Les premiers à avoir réalisé les premiers projets sur Go étaient RnD, ils ne voulaient pas gérer les limitations techniques de Python. Ensuite, dans l'équipe de développement mobile, il y avait des gens qui le connaissaient et l'avaient promu à la production. D'après leur soumission, nous avons effectué des tests et avons été plus que satisfaits du résultat. Dans des cas distincts, après qu'une partie du projet a été réécrite de Python to Go, le chargement des nœuds de cluster a considérablement diminué. Par exemple, la réécriture du moteur de calcul de remise pour le panier de Python to Go nous a permis de traiter 8 fois plus de demandes avec les mêmes capacités matérielles, et le temps de réponse moyen de l'API a été réduit de 25 fois. C'est-à-dire Go s'est avéré être plus efficace que Python (si vous l'écrivez correctement), même si ce n'est pas si pratique pour le développeur.
Le développement mobile devant interagir avec des dizaines d'API internes, un générateur de code a été créé qui, selon la description du service API (selon la spécification Swagger), un client peut générer sur Go. Ainsi, Go a progressivement commencé à correspondre aux services et outils existants, en particulier ceux qui ont créé le «goulot d'étranglement» pour la charge. En plus de faciliter la vie du développeur de backend mobile, nous avons simplifié les conventions internes suivantes sur la façon de développer des API, comment nommer des méthodes, comment passer des paramètres, etc. Cette standardisation a facilité le développement et la mise en œuvre de nouveaux services pour toutes les équipes.
Aujourd'hui, Go est déjà utilisé presque partout - dans toutes les interactions en temps réel avec les utilisateurs - dans le backend du site et des applications mobiles, ainsi que les services auxquels ils sont associés. Et là où il n'y a pas besoin de traitement et de réponse rapides, par exemple dans les tâches d'interaction avec l'entrepôt de données, Python reste, car il n'a pas d'égal pour les tâches de traitement des données (bien qu'il y ait une pénétration de Go ici).
Comme vous pouvez le voir sur le radar, nous avons Java dans l'actif. Il est utilisé dans le système de gestion d'entrepôt (WMS), aidant à récupérer rapidement les commandes. Jusqu'à présent, nous avons une pile assez ancienne et un ancien modèle d'architecture - un monolithe tournant sur Wildfly 10 et 8 Hotspot Java, et il y a également un client distant et riche sur la
plate-forme d'application Netbeans (maintenant cette fonctionnalité est transférée sur le Web). Ici, dans notre arsenal, nous avons des stockages standard pour l'entreprise et même notre propre surveillance. Malheureusement, nous n'avons pas trouvé d'outil permettant de bien visualiser le fonctionnement de l'entrepôt et les processus importants sur celui-ci (lorsqu'une section est surchargée, par exemple), et nous en avons fait un nous-mêmes.
Nous utilisons Python comme langage principal pour l'apprentissage automatique: nous construisons des systèmes de recommandation et classons le catalogue, corrige les fautes de frappe dans les requêtes de recherche et résolvons également d'autres problèmes en conjonction avec Spark sur un cluster Hadoop (PySpark). Python nous aide à automatiser le calcul des métriques internes et les tests AB.
Développement frontend et mobile
L'interface de la boutique en ligne de bureau, ainsi que des sites mobiles, est écrite en JavaScript. Maintenant, le frontend passe progressivement à la spécification ES6, créant de nouveaux projets conformément à celle-ci. Nous utilisons vue.js comme framework principal, mais nous y reviendrons plus en détail dans la section outils.
Le développement d'applications pour les plates-formes mobiles est une unité distincte de l'entreprise, qui comprend des groupes backend, ainsi que des applications Android et iOS avec leurs propres piles et outils technologiques, qui, en raison des différences de plate-forme, sont loin d'être toujours possibles d'unifier à travers l'ensemble de l'unité.
Depuis deux ans maintenant, tout nouveau développement Android est en cours sur Kotlin, ce qui nous permet d'écrire du code plus concis et compréhensible. Parmi les fonctionnalités les plus couramment utilisées, nos développeurs appellent: smartcast, classes scellées, fonctions d'extension, constructeurs typesafe (DSL), fonctionnalité stdlib.
Le développement iOS est en cours sur Swift, qui a remplacé Objective-C.
Langues spéciales
La gamme de tâches de Lamoda ne se limite pas au développement d'une "vitrine" pour différentes plates-formes, respectivement, nous avons un certain nombre de langues qui sont utilisées uniquement dans leurs systèmes, fonctionnent bien là-bas, mais ne seront pas implémentées dans d'autres parties de l'infrastructure:
- R - utilisé pour le traitement des données et les scripts de reporting dans le cadre de la Business Intelligence (BI). Il n'est pas en production et il n'est plus utilisé pour de nouvelles tâches, mais nous avons encore un certain nombre de ces scripts. En résolvant les problèmes avec R, nous avons réalisé que ce langage n'est pas destiné aux applications très chargées. Dans de nouvelles tâches, nous utilisons Python et d'autres technologies incompatibles avec R.
- Scala - utilisé par le bureau de développement de Vilnius pour développer un système d'automatisation de centre d'appels. Initialement, ce système a été écrit en PHP, mais lors de la transition vers une architecture de microservice, un certain nombre de composants ont été réécrits en Scala. Également là-dessus, l'équipe d'ingénierie des données écrit des travaux Spark.
- TypeScript que nous examinons. La livraison est déjà implémentée avec son aide, et à l'avenir, nous utiliserons TypeScript + vue.js sur le frontend.
- Lua est utilisé pour configurer nginx (via l'API nginx), dans d'autres projets il ne l'est pas et ne le sera jamais.
- Nous sommes une entreprise de mode et suivons la mode de la programmation fonctionnelle. Par exemple, un émulateur de dispositif de tri dans l'un de nos entrepôts est écrit en Haskell.
Gestion des données
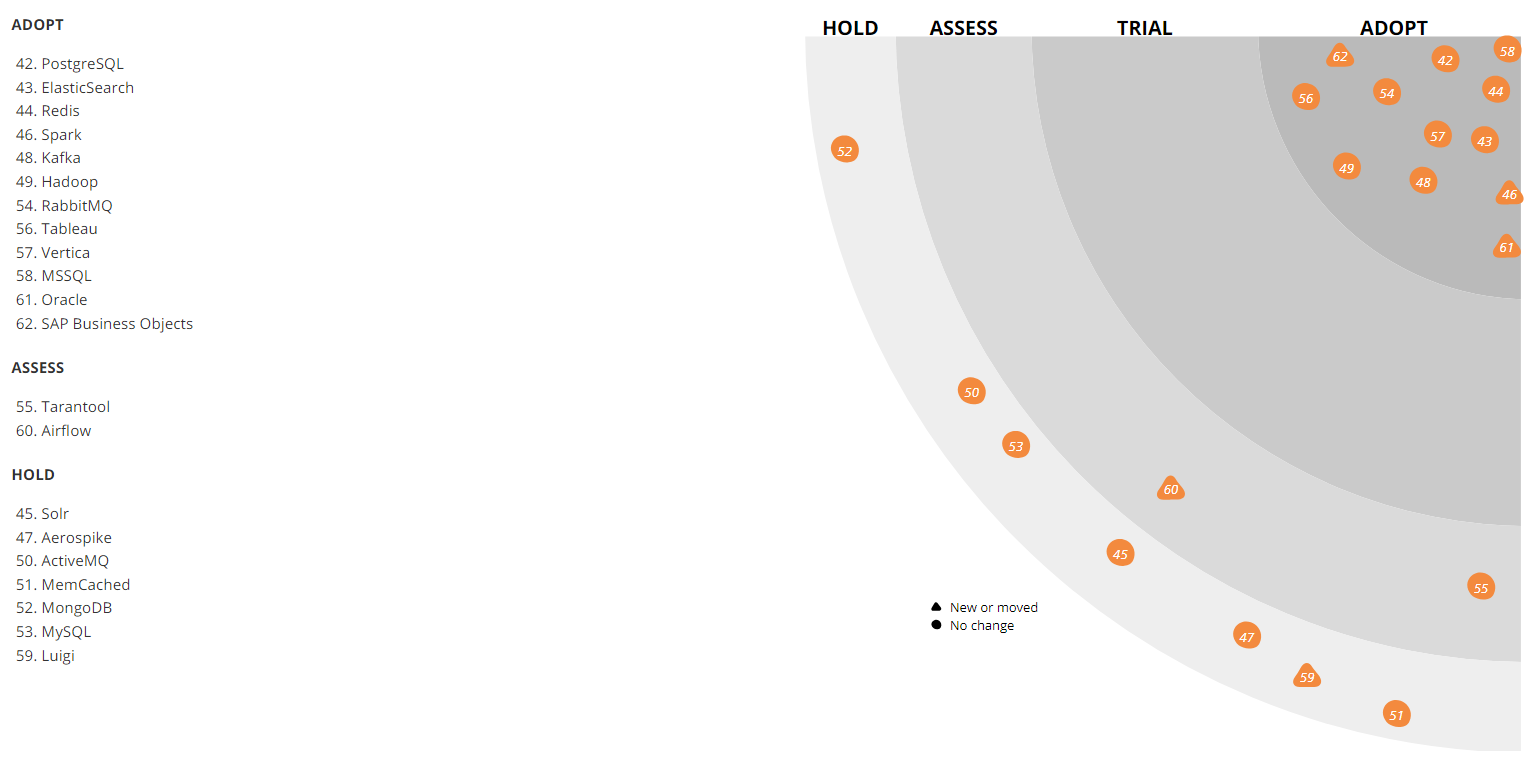
SGBD, recherche et analyse de données
Comme beaucoup, les bases de données les plus diverses que nous avons mises en œuvre sur PostgreSQL - elles sont utilisées partout où des bases de données relationnelles sont nécessaires, par exemple, pour stocker un répertoire. Il est assez facile de trouver des spécialistes de cette technologie, de plus, de nombreux services différents sont disponibles.
Bien sûr, PostgreSQL n'est pas le seul SGBD que l'on puisse trouver dans notre infrastructure informatique. Sur certains systèmes plus anciens, par exemple, MySQL est utilisé, tandis que WMS a un peu de MongoDB. Cependant, pour des charges et une mise à l'échelle élevées (en tenant compte du reste de notre pile technologique), nous ne les utilisons pas pour de nouveaux projets. En général, PostgreSQL est notre tout.
L'Aerospike est également visible sur le radar. Nous l'avons utilisé assez activement, mais le contrat de licence a changé pour le produit, donc la version «notre» s'est avérée un peu coupée. Cependant, maintenant nous l'avons de nouveau regardé. Peut-être allons-nous reconsidérer notre attitude vis-à-vis de l'instrument et l'utiliser plus activement. Désormais, Aerospike est utilisé dans le service d'agrégation d'événements de visualisation de pages et le travail de l'utilisateur avec le panier, ainsi que dans le service de protection sociale («5 personnes ont ajouté ce produit aux favoris cette semaine»). Maintenant, nous faisons des recommandations encore plus fortes à ce sujet.
Apache Solr est utilisé pour rechercher des données de production. En parallèle, nous utilisons également ElasticSearch. Les deux solutions sont open source, mais si plus tôt, lorsque nous implémentions simplement la recherche, Apache Solr possédait déjà la troisième ou la quatrième version et était en développement actif, et ElasticSearch n'avait même pas la première version stable - il était trop tôt pour l'utiliser en production. Maintenant, les rôles ont changé - il est beaucoup plus facile de trouver des solutions pour ElasticSearch, et de nouvelles personnes sont venues vers nous qui sont capables de le préparer. Cependant, dans le prod, nous avons Solr, et nous ne passerons pas à une autre solution au moins avant le Black Friday 2018.
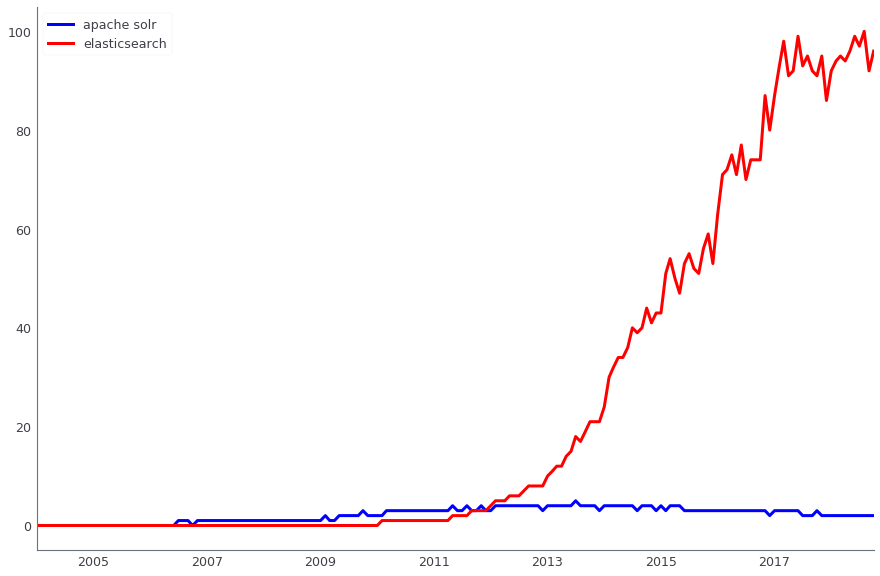 Comparaison de la dynamique des requêtes de recherche Apache Solr (bleu) et ElasticSearch (rouge), selon Google Trends
Comparaison de la dynamique des requêtes de recherche Apache Solr (bleu) et ElasticSearch (rouge), selon Google TrendsL'analyse des données se produit dans plusieurs systèmes, en particulier, nous utilisons activement Apache Hadoop. Dans le même temps, le SGBD de la colonne Vertica est utilisé pour stocker des data marts (avec un volume total d'environ 4 To). Sur ces vitrines, des rapports financiers, opérationnels et commerciaux sont construits. Pour bon nombre de nos tâches ETL, nous utilisions auparavant Luigi, mais nous passons maintenant à Apache Airflow. Nous utilisons également Pentaho pour le stockage relationnel, dans lequel il y a environ un millier de tâches ETL régulières.
Une partie de l'analyse et de la préparation des données pour d'autres systèmes est effectuée dans Spark. À certains endroits, il s'agit non seulement d'un outil d'analyse, mais également d'une partie de notre architecture lambda.
Les systèmes ERP jouent un rôle important dans l'infrastructure informatique: Microsoft Dynamics AX et 1C. En tant que SGBD, Microsoft SQL Server est utilisé. Et pour le reporting, ses composants, tels que les services d'analyse et les services de reporting.
Mise en cache
Pour la mise en cache, nous utilisons Redis. Auparavant, cette tâche était effectuée par MemCached, elle ne pouvait pas être utilisée comme stockage de valeur de clé avec un vidage périodique sur le disque, nous l'avons donc abandonnée.
Files d'attente de messages
En tant que courtier d'événements, nous utilisons deux outils à la fois - Apache Kafka et RabbitMQ.
Apache Kafka est un outil qui nous permet de traiter des dizaines de milliers de messages dans divers systèmes où la messagerie est nécessaire. Des clusters Kafka distincts sont déployés pour certaines parties très chargées du système - par exemple, pour les événements utilisateur ou la journalisation (nous avions un bon
rapport sur la journalisation à Highload ++ 2017 ). Kafka vous permet de faire face à 6000 mille messages en vrac par seconde avec une utilisation minimale de fer.
Dans les systèmes internes, nous utilisons RabbitMQ pour les actions différées.
Plateformes et infrastructure

Livraison continue
Pour le déploiement, Kubernetes est utilisé, qui a remplacé le bundle Nomad + Consul de Hashicorp. La pile précédente fonctionnait très mal avec les mises à niveau matérielles. Lorsque notre équipe Ops a changé les serveurs physiques sur lesquels les nœuds tournaient et les conteneurs ont été stockés, il s'est régulièrement cassé et s'est écrasé, ne voulant pas augmenter. Il n'y avait pas de version stable à l'époque. De plus, nous n’utilisions pas la dernière version en date, la 0.5.6, qui devait encore être mise à jour. La mise à niveau vers la dernière version bêta a nécessité quelques travaux. Par conséquent, il a été décidé de l'abandonner et de passer aux Kubernetes les plus populaires.
Désormais, Nomad et Consul sont toujours utilisés en assurance qualité, mais à l'avenir, il devrait également déménager à Kubernetes.
Pour implémenter la livraison continue, des conteneurs Docker sont utilisés, vers lesquels nous avons migré il y a deux ans. Pour nos services très chargés (panier, catalogue, site Web, système de gestion des commandes), la capacité de récupérer rapidement plusieurs conteneurs supplémentaires d'un service est importante, nous avons donc des conteneurs partout. Et Docker est l'une des méthodes de conteneurisation les plus populaires, donc sa présence sur le radar est assez logique.
En tant que serveur de génération et intégration continue, Bamboo est déployé, utilisé en conjonction avec Jira et Bitbucket (pile standard).
Jenkins est également mentionné dans le radar. Nous l'avons expérimenté, mais nous ne le traînerons pas dans de nouveaux projets. C'est un excellent outil, mais il ne tient tout simplement pas dans notre pile car nous avons déjà Bamboo.
Les conteneurs dockers collectés en bambou sont stockés dans le référentiel sous le contrôle d'Artifactory.
Gestion et équilibrage des processus
Nous utilisons NGINX Plus, mais pas en termes d'équilibrage, car ses métriques ne sont pas suffisantes pour nos tâches. Il ne peut pas dire, par exemple, quelle demande est le plus souvent acheminée ou bloquée. Par conséquent, HAProxy est utilisé pour équilibrer la charge. Il peut fonctionner rapidement et efficacement en conjonction avec nginx, sans charger le processeur et la mémoire. De plus, les mesures dont nous avons besoin sont ici prêtes à l'emploi - HAproxy peut afficher des statistiques par nœuds, par le nombre de connexions à l'heure actuelle, par la façon dont la bande passante est occupée et bien plus encore.
UWSGI est utilisé pour exécuter des applications Python synchrones. Php-fpm a été utilisé comme gestionnaire de processus sur tous les services PHP.
Suivi
Nous utilisons Prometheus pour collecter des métriques de nos applications et machines hôtes (machines virtuelles), ainsi que de la
base de données de séries chronologiques pour l'application . Nous collectons des journaux, pour cela, nous utilisons la pile ELK, en tant que système d'alerte, nous utilisons Icinga, qui est configuré pour ELK et Prometheus. Elle envoie des alertes par mail et SMS. Le service d'assistance 6911 reçoit les mêmes alertes et décide d'attirer des ingénieurs de garde.
Prometheus est impliqué presque partout, et pour cela, nous avons des bibliothèques pour tous les langages, qui permettent d'utiliser seulement quelques lignes de code pour connecter ses métriques au projet. Par exemple, une bibliothèque pour PHP
est disponible en Open Source ).
Pour afficher visuellement les résultats de la surveillance sous la forme de magnifiques tableaux de bord, Grafana est utilisé. Fondamentalement, nous collectons tous les tableaux de bord de Prometheus, bien que parfois d'autres systèmes puissent également servir de sources.
Pour détecter et agréger automatiquement les erreurs, nous utilisons Sentry, qui est intégré à Jira et facilite le démarrage d'un traqueur de tâches pour chacun des problèmes de production. Il sait comment capturer l'erreur avec un retour en arrière et des informations supplémentaires, il est donc pratique de commencer.
Les statistiques sur le code des demandes d'extraction créées sont collectées à l'aide de SonarQube.
Cadres et outils

Lors du développement de l'infrastructure informatique de Lamoda, nous avons expérimenté près de trois douzaines d'outils différents, cette catégorie est donc la plus «à grande échelle» de notre radar. À ce jour, sont activement utilisés:
- Symfony 3.x, et plus récemment - Symfony 4.x - pour le développement en PHP;
- Django et le moteur de modèle Jinja pour le développement Python. Soit dit en passant, Jinja est utilisé, y compris, pour la configuration dans Ansible;
- Flask - pour les services internes (avec Django), mais en production, nous ne le faisons pas glisser;
- Spring - dans le développement Java;
- Bootstrap - pour une variété d'outils internes dans le développement Web (panneau d'administration, tableaux de bord faits maison, etc.);
- jQuery - pour le développement js;
- OpenAPI (Swagger) - pour la documentation de tous les services API, y compris qui sont utilisés pour la génération de code ci-dessus sur Go;
- Webpack - pour empaqueter JS et minimiser CSS;
- Sélénium - pour tester le frontend;
- WireMock, JMeter, Allure et autres sont également utilisés dans les tests;
- Ansible - pour la gestion de la configuration;
- Kibana - pour visualiser les résultats de recherche dans ElasticSearch.
Je voudrais parler séparément du développement JavaScript. Nous, comme beaucoup, avons tout un champ d'expériences. JavaScript . — Angular, ReactJS, vue.js. « », , vue.js, , .
, GO, PHP, Java, JavaScript, PostgreSQL, Docker Kubernetes.
, . , , . -, . , , , .