 Cet article fait partie de la Chronique de l'architecture logicielle , une série d'articles sur l'architecture logicielle. J'y écris ce que j'ai appris sur l'architecture logicielle, ce que j'en pense et comment j'utilise les connaissances. Le contenu de cet article peut avoir plus de sens si vous lisez les articles précédents de la série.
Cet article fait partie de la Chronique de l'architecture logicielle , une série d'articles sur l'architecture logicielle. J'y écris ce que j'ai appris sur l'architecture logicielle, ce que j'en pense et comment j'utilise les connaissances. Le contenu de cet article peut avoir plus de sens si vous lisez les articles précédents de la série.Dans un
article précédent de la série, j'ai publié une carte conceptuelle qui montre les relations entre les types de code.
Mais il m'a toujours semblé que tout ne s'y reflète pas très bien, je ne savais tout simplement pas comment faire mieux. Il s'agit d'un tronc commun.
En outre, quelques réflexions supplémentaires ont surgi que je vais décrire dans ce court article.
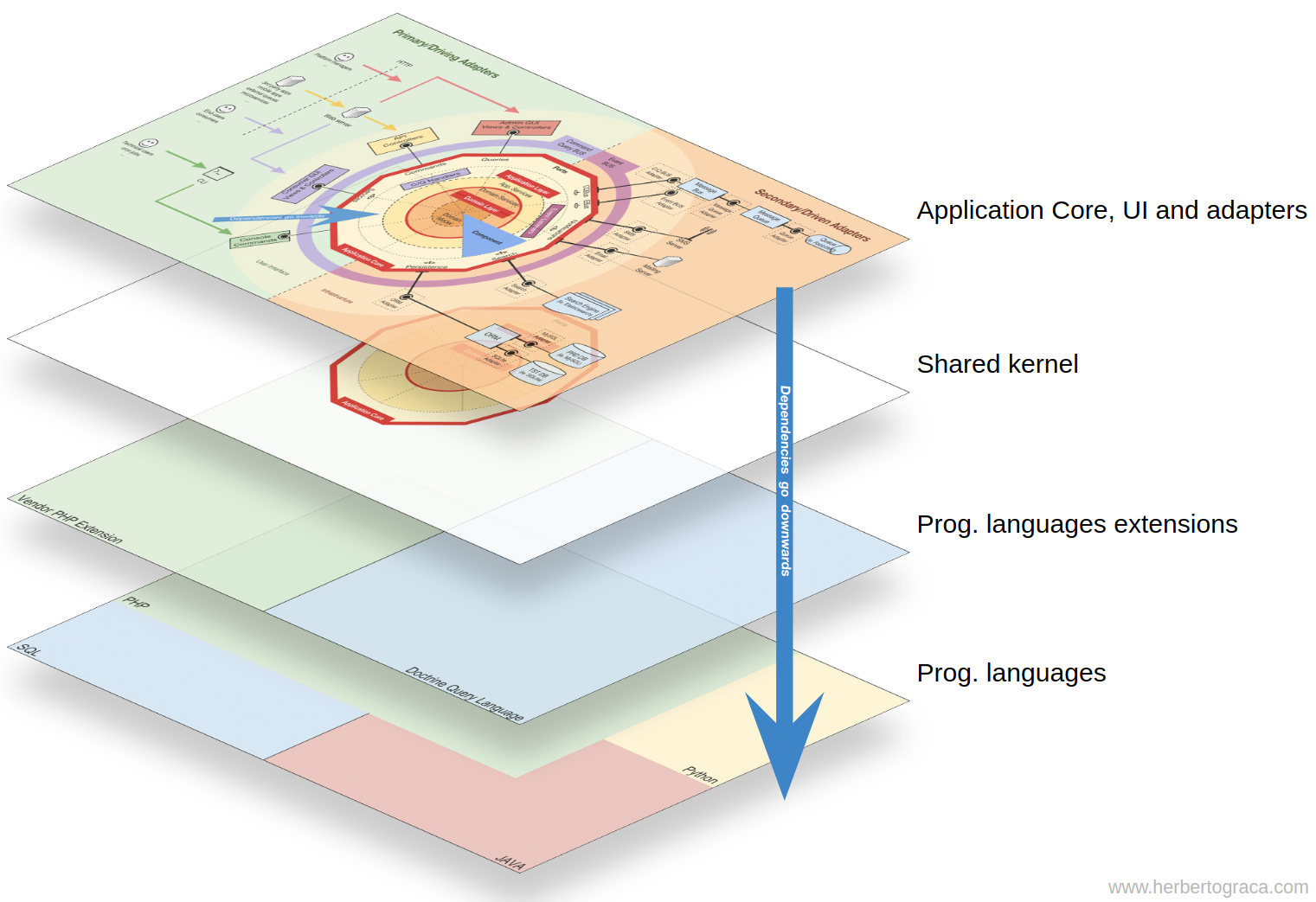
Dans l'infographie du dernier article de cette série, au centre même du diagramme, nous voyons le tronc commun. Il semble être situé à l'intérieur de la couche de domaine et au-dessus des sections coniques, qui sont des contextes limités.

Malgré son emplacement, je ne voulais pas dire que le noyau commun dépend du reste du code ou que le noyau commun est une autre couche à l'intérieur du niveau de domaine.
Qu'est-ce qu'un tronc commun?!
Le noyau commun, tel que défini par Eric Evans, le
père de DDD, est le code que l'équipe de développement décide de répartir entre plusieurs contextes limités:
[...] un sous-ensemble du modèle de domaine que les deux équipes ont convenu d'utiliser ensemble. Bien entendu, avec ce sous-ensemble du modèle, le noyau commun comprend un sous-ensemble du code ou de l'architecture de base de données associée à cette partie du modèle. Ce matériel clairement général a un statut spécial et ne doit pas être modifié sans consulter une autre équipe.
- «Common Kernel» , DDD Wiki de Ward Cunningham
Ainsi, il peut s'agir de tout type de code: code au niveau du domaine, code au niveau de l'application, bibliothèques ... peu importe.

Cependant, dans le contexte de notre carte conceptuelle, je le présente comme un sous-ensemble, comme un type de code spécifique. Dans ma carte conceptuelle, le noyau commun contient du code pour les niveaux de domaine et d'application, qui est partagé dans des contextes limités afin que la communication entre des contextes restreints soit possible.
Par exemple, cela signifie que les événements sont déclenchés dans un ou plusieurs contextes restreints et écoutés dans d'autres contextes restreints. Avec ces événements, nous devons partager tous les types de données utilisés par ces événements, par exemple: identificateurs d'entité, objets de valeur, énumérations, etc. Les objets complexes tels que les entités ne doivent pas être utilisés directement par les événements, car ils peuvent être difficiles sérialiser / désérialiser vers / depuis la file d'attente, donc le code générique ne doit pas être largement distribué.
Bien sûr, si nous avons un système multilingue de microservices, le noyau commun doit être descriptif, en JSON, XML, YAML, etc., afin que tous les microservices puissent le comprendre.
Par conséquent, ce noyau commun est complètement séparé du reste de la base de code, des composants. C'est formidable, car alors les composants, bien que connectés au noyau commun, sont séparés les uns des autres. Le code générique est explicitement identifié et facilement récupéré dans une bibliothèque distincte.
Il est également très pratique si nous décidons d'extraire l'un des contextes limités dans un microservice, séparé du monolithe. Nous savons avec certitude ce qui est commun et pouvons simplement extraire le noyau commun dans la bibliothèque, qui sera installée à la fois dans le monolithe et dans le microservice.
Donc, pour résumer, dans ma carte conceptuelle, le cœur de l'application dépend d'un noyau commun qui contient du code du domaine et des niveaux d'application partagés entre des contextes limités.
Quand la langue ne suffit pas ...
Donc, nous avons le code d'application avec toutes les couches concentriques, et le noyau d'application dépend du noyau commun, qui est sous tout ce code.
Nous pouvons également dire que tout ce code dépend du ou des langages de programmation utilisés, mais c'est un fait tellement évident que nous avons tendance à l'ignorer complètement.
Cependant, la question se pose: "Et si les constructions de langage ne suffisent pas?!" Eh bien, évidemment, nous créons nous-mêmes ces constructions de langage et compensons ainsi les défauts de la langue. Mais j'ai des questions de suivi importantes: «Comment et où justifier l'existence de ce code? Comment indiquer clairement quand et comment l'utiliser? »
Ce que j'ai vu et fait moi-même était un paquet appelé Utils ou Commons, où se trouve ce code. Mais au final, on finit par y jeter tout le code, qu'on ne sait pas où mettre! Toutes sortes de codes à des fins différentes et faciles à utiliser (enveloppés dans un adaptateur utilisé directement ...) y sont finalement déversés. Le paquet n'a pas de sens conceptuel, pas de cohérence, pas de cohérence, pas de clarté, beaucoup d'ambiguïtés.
Je veux abandonner les packages Utils and Commons!
Tous les packages doivent avoir une cohésion conceptuelle! Il devrait être clair quand et comment utiliser le paquet! Aucune ambiguïté!
Par exemple, si une application interagit avec l'interface de ligne de commande d'une manière spéciale, au lieu de placer 'Acme / Util / SpecialCli' dans l'espace de noms, vous pouvez la placer dans 'Acme / App / Infrastructure / Cli / SpecialCli'. Cela signifie que ce package est associé à la CLI, il fait partie de l'infrastructure de l'application Acme App. L'affiliation à l'infrastructure de l'application indique également qu'il existe un port dans le noyau de l'application auquel ce package correspond.
Alternativement, si nous voyons ce paquet comme quelque chose qui manque au langage lui-même, nous pouvons le mettre dans l'espace de noms approprié, par exemple, 'Acme / PhpExtension / SpecialCli'. Cela montre que ce package doit être considéré comme faisant partie du langage lui-même, et donc son code doit être utilisé directement dans la base de code comme toute construction de langage. Bien sûr, si une autre entreprise dépend de ce package, il peut être raisonnable pour elle de ne pas en dépendre directement, mais il est plus sûr de créer un port / adaptateur afin de pouvoir l'échanger contre autre chose. Mais si nous possédons le package, nous pouvons le considérer comme faisant partie du langage, car le risque de devoir le remplacer par une autre alternative n'est pas si grand. Le compromis est toujours la chose.
Un autre exemple de ce qui peut être considéré comme faisant partie du langage est les UUID uniques en PHP. Il est tout à fait possible de les imaginer en dehors du langage, car à chaque fois qu'il y a une nouvelle version et c'est un cauchemar avec support de code, mais c'est un concept très général, un concept large et suffisamment cohérent pour faire partie du langage.
Alors pourquoi ne pas créer une implémentation UUID et l'utiliser comme une partie de PHP lui-même, comment utiliser un objet DateTime?! Pendant que nous contrôlons la mise en œuvre, je ne vois aucun défaut.
Qu'en est-il du langage de requête de doctrine (DQL)? (Doctrine est le port Hibernate en PHP) peut-on regarder DQL comme s'il s'agissait de SQL, Elasticsearch QL ou Mongo QL?
Conclusion
Donc, au niveau macro, je vois quatre types de code de base et je pense qu'il est important de les montrer clairement dans l'organisation de la base de code, afin de ne pas se retrouver avec beaucoup de saleté.
Pour moi, la vérité indéniable est que l'
architecture existe toujours, la seule question est de savoir si on la contrôle ou pas?!Organisons donc
clairement le code en fonction de l'architecture , en tout ou en partie, sur une carte conceptuelle - la mienne ou une autre. L'essentiel est d'organiser le code afin que le projet rende compte explicitement de son architecture à travers la structure et l'organisation du code.