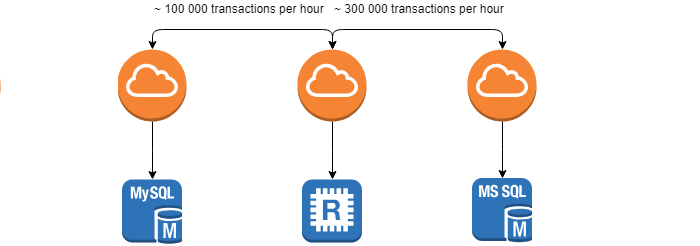
Lors du développement et de l'utilisation de systèmes distribués, nous sommes confrontés à la tâche de surveiller l'intégrité et l'identité des données entre les systèmes - la tâche de réconciliation .
Les exigences que le client fixe sont le temps minimum pour cette opération, car plus tôt l'écart est trouvé, plus il sera facile d'éliminer ses conséquences. La tâche est sensiblement compliquée par le fait que les systèmes sont en mouvement constant (~ 100 000 transactions par heure) et 0% des écarts ne peuvent pas être atteints.
Idée principale
L'idée principale de la solution peut être décrite dans le diagramme suivant.
Nous considérons chacun des éléments séparément.
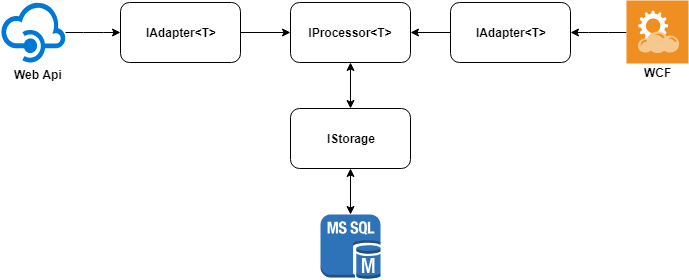
Adaptateurs de données
Chacun des systèmes est conçu pour son propre domaine et, par conséquent, les descriptions d'objets peuvent varier considérablement. Nous devons comparer seulement un certain ensemble de champs de ces objets.
Pour simplifier la procédure de comparaison, nous amenons les objets dans un format unique en écrivant un adaptateur pour chaque source de données. Le fait de ramener les objets dans un seul format peut réduire considérablement la quantité de mémoire utilisée, car nous ne stockerons que les champs comparés.
Sous le capot, l'adaptateur peut avoir n'importe quelle source de données: HttpClient , SqlClient , DynamoDbClient , etc.
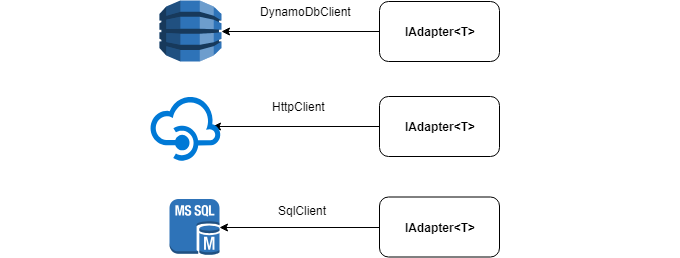
Voici l'interface IAdapter que vous souhaitez implémenter:
public interface IAdapter<T> where T : IModel { int Id { get; } Task<IEnumerable<T>> GetItemsAsync(ISearchModel searchModel); } public interface IModel { Guid Id { get; } int GetHash(); }
Stockage
La réconciliation des données ne peut commencer qu'après que toutes les données ont été lues, car les adaptateurs peuvent les renvoyer dans un ordre aléatoire.
Dans ce cas, la quantité de RAM peut ne pas être suffisante, surtout si vous exécutez plusieurs rapprochements en même temps, ce qui indique de grands intervalles de temps.
Considérez l'interface IStorage
public interface IStorage { int SourceAdapterId { get; } int TargetAdapterId { get; } int MaxWriteCapacity { get; } Task InitializeAsync(); Task<int> WriteItemsAsync(IEnumerable<IModel> items, int adapterId); Task<IEnumerable<IResultModel>> GetDifferenceAsync(ISearchDifferenceModel model); } public interface ISearchDifferenceModel { int Offset { get; } int Limit { get; } }
Dépôt. Implémentation basée sur MS SQL
Nous avons implémenté IStorage en utilisant MS SQL, ce qui nous a permis d'effectuer la comparaison complètement du côté serveur Db.
Pour stocker les valeurs demandées, créez simplement le tableau suivant:
CREATE TABLE [dbo].[Storage_1540747667] ( [id] UNIQUEIDENTIFIER NOT NULL, [adapterid] INT NOT NULL, [qty] INT NOT NULL, [price] INT NOT NULL, CONSTRAINT [PK_Storage_1540747667] PRIMARY KEY ([id], [adapterid]) )
Chaque enregistrement contient des champs système ( [id] , [adapterId] ) et des champs de comparaison ( [qty] , [price] ). Quelques mots sur les champs système:
[id] - identifiant unique de l'entrée, le même dans les deux systèmes
[adapterId] - identifiant de l'adaptateur via lequel l'enregistrement a été reçu
Comme les processus de réconciliation peuvent être lancés en parallèle et avoir des intervalles qui se croisent, nous créons une table avec un nom unique pour chacun d'eux. Si le rapprochement a réussi, ce tableau est supprimé, sinon un rapport est envoyé avec une liste des enregistrements dans lesquels il y a des écarts.
Dépôt. Comparaison de valeur
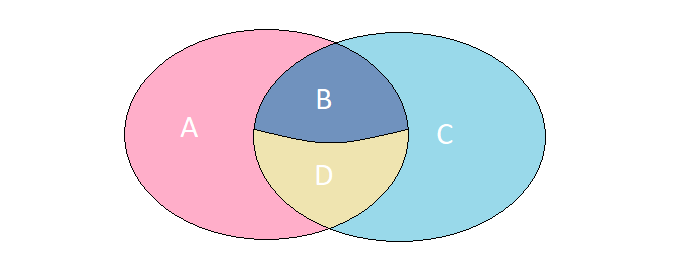
Imaginez que nous ayons 2 ensembles dont les éléments ont un ensemble de champs absolument identiques. Considérons 4 cas possibles de leur intersection:
A. Les éléments sont présents uniquement dans l'ensemble de gauche.
B. Les éléments sont présents dans les deux ensembles, mais ont des significations différentes.
S Les éléments ne sont présents que dans le bon ensemble.
D Les éléments sont présents dans les deux ensembles et ont la même signification.
Dans un problème spécifique, nous devons trouver les éléments décrits dans les cas A, B, C. Vous pouvez obtenir le résultat souhaité en une seule requête vers MS SQL via FULL OUTER JOIN :
select [s1].[id], [s1].[adapterid] from [dbo].[Storage_1540758006] as [s1] full outer join [dbo].[Storage_1540758006] as [s2] on [s2].[id] = [s1].[id] and [s2].[adapterid] != [s1].[adapterid] and [s2].[qty] = [s1].[qty] and [s2].[price] = [s1].[price] where [s2].[id] is nul
La sortie de cette demande peut contenir 4 types d'enregistrements qui répondent aux exigences initiales
| # | id | adaptateurid | commenter |
|---|
| 1 | guid1 | adp1 | L'enregistrement n'est présent que dans l'ensemble de gauche. Cas A |
| 2 | guid2 | adp2 | L'enregistrement n'est présent que dans le bon ensemble. Cas C |
| 3 | guid3 | adp1 | Les enregistrements sont présents dans les deux ensembles, mais ont des significations différentes. Cas B |
| 4 | guid3 | adp2 | Les enregistrements sont présents dans les deux ensembles, mais ont des significations différentes. Cas B |
Dépôt. Hachage
En utilisant le hachage sur des objets comparés, vous pouvez réduire considérablement le coût des opérations d'écriture et de comparaison. Surtout quand il s'agit de comparer des dizaines de champs.
La méthode la plus universelle de hachage d'une représentation sérialisée d'un objet s'est avérée être.
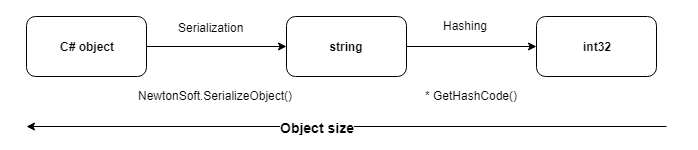
1. Pour le hachage, nous utilisons la méthode standard GetHashCode () , qui renvoie int32 et est remplacée pour tous les types primitifs.
2. Dans ce cas, la probabilité de collisions est peu probable, car seuls les enregistrements ayant les mêmes identificateurs sont comparés.
Considérez la structure de table utilisée dans cette optimisation:
CREATE TABLE [dbo].[Storage_1540758006] ( [id] UNIQUEIDENTIFIER NOT NULL, [adapterid] INT NOT NULL, [hash] INT NOT NULL, CONSTRAINT [PK_Storage_1540758006] PRIMARY KEY ([id], [adapterid], [hash]) )
L'avantage d'une telle structure est le coût constant de stockage d'un enregistrement (24 octets), qui ne dépendra pas du nombre de champs comparés.
Naturellement, la procédure de comparaison subit ses modifications et devient beaucoup plus simple.
select [s1].[id], [s1].[adapterid] from [dbo].[Storage_1540758006] as [s1] full outer join [dbo].[Storage_1540758006] as [s2] on [s2].[id] = [s1].[id] and [s2].[adapterid] != [s1].[adapterid] and [s2].[hash] = [s1].[hash] where [s2].[id] is null
CPU
Dans cette section, nous parlerons d'une classe qui contient toute la logique métier de la réconciliation, à savoir:
1. lecture parallèle des données des adaptateurs
2. hachage des données
3. enregistrement tamponné des valeurs dans la base de données
4. livraison des résultats
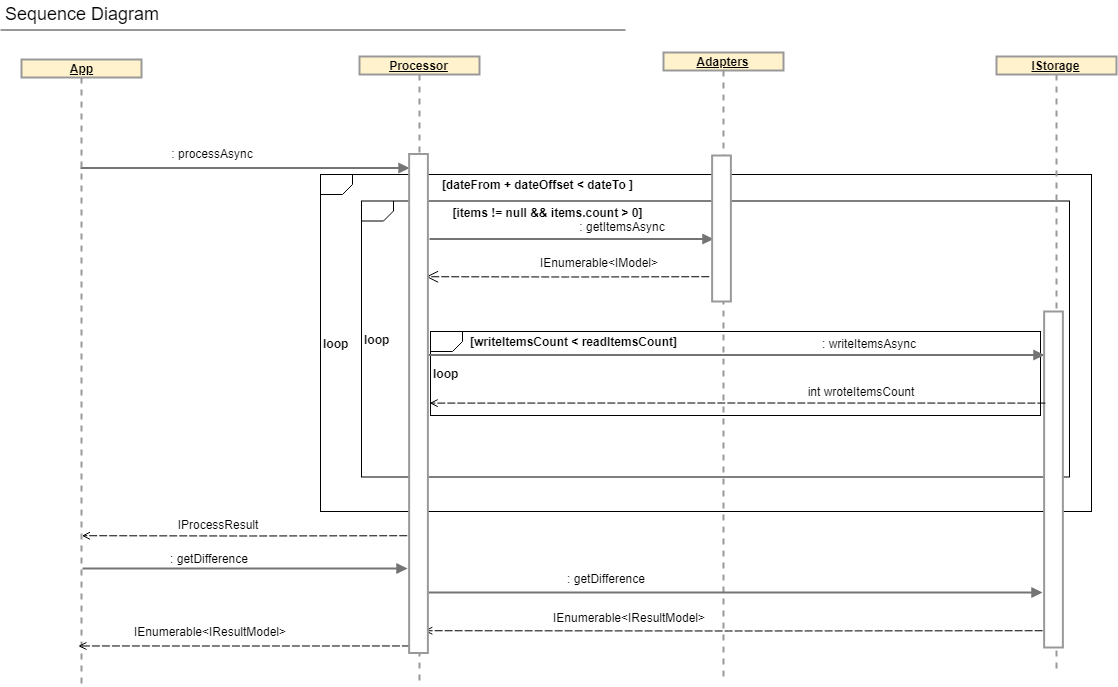
Une description plus complète du processus de réconciliation peut être obtenue en consultant le diagramme de séquence et l'interface IProcessor.
public interface IProcessor<T> where T : IModel { IAdapter<T> SourceAdapter { get; } IAdapter<T> TargetAdapter { get; } IStorage Storage { get; } Task<IProcessResult> ProcessAsync(); Task<IEnumerable<IResultModel>> GetDifferenceAsync(ISearchDifferenceModel model); }
Remerciements
Un grand merci à mes collègues de MySale Group pour leurs commentaires: AntonStrakhov , Nesstory , Barlog_5 , Kostya Krivtsun et VeterManve - l'auteur de l'idée.