Remarque perev. R: L'article original a été écrit par des représentants de BlueData, une entreprise fondée par des gens de VMware. Elle se spécialise dans la facilitation (plus facile, plus rapide, moins chère) du déploiement de solutions pour l'analyse de Big Data et l'apprentissage automatique dans divers environnements. L'initiative récente de la société appelée BlueK8s , dans laquelle les auteurs souhaitent assembler une galaxie d'outils Open Source "pour déployer des applications avec état et les gérer dans Kubernetes", est également appelée à y contribuer. L'article est consacré au premier d'entre eux - KubeDirector, qui, selon le plan des auteurs, aide un passionné du domaine du Big Data, qui n'a pas de formation spéciale en Kubernetes, à déployer des applications comme Spark, Cassandra ou Hadoop dans K8s. De brèves instructions sur la façon de procéder sont fournies dans l'article. Cependant, gardez à l'esprit que le projet a un état de préparation précoce - pré-alpha.
KubeDirector est un projet Open Source conçu pour simplifier le lancement de clusters à partir d'applications complexes évolutives avec état dans Kubernetes. KubeDirector est implémenté à l'aide du cadre CRD (
Custom Resource Definition ), utilise les capacités d'extension de l'API Kubernetes native et s'appuie sur leur philosophie. Cette approche offre une intégration transparente avec la gestion des utilisateurs et des ressources dans Kubernetes, ainsi qu'avec les clients et utilitaires existants.
Le projet KubeDirector
récemment annoncé fait partie d'une initiative Open Source plus large pour Kubernetes appelée BlueK8s. Maintenant, je suis heureux d'annoncer la disponibilité du code
KubeDirector (pré-alpha)
précoce . Ce message montrera comment cela fonctionne.
KubeDirector offre les fonctionnalités suivantes:
- Pas besoin de modifier le code pour exécuter des applications avec état autres que le cloud natif de Kubernetes. En d'autres termes, il n'est pas nécessaire de décomposer les applications existantes pour qu'elles correspondent au modèle d'architecture de microservice.
- Prise en charge native du stockage de la configuration et de l'état spécifiques à l'application.
- Modèle de déploiement indépendant de l'application qui minimise le temps de démarrage des nouvelles applications avec état dans Kubernetes.
KubeDirector permet aux scientifiques des données, habitués aux applications distribuées avec un traitement intensif des données, telles que Hadoop, Spark, Cassandra, TensorFlow, Caffe2, etc., de les exécuter dans Kubernetes avec une courbe d'apprentissage minimale et sans avoir besoin d'écrire du code sur Go. Lorsque ces applications sont contrôlées par KubeDirector, elles sont définies par de simples métadonnées et leur ensemble de configurations associé. Les métadonnées d'application sont définies comme une ressource
KubeDirectorApp .
Pour comprendre les composants de KubeDirector, clonez le référentiel sur
GitHub avec une commande comme la suivante:
git clone http://<userid>@github.com/bluek8s/kubedirector.
La définition de
KubeDirectorApp pour l'application Spark 2.2.1 se trouve dans le
kubedirector/deploy/example_catalog/cr-app-spark221e2.json :
~> cat kubedirector/deploy/example_catalog/cr-app-spark221e2.json
{ "apiVersion": "kubedirector.bluedata.io/v1alpha1", "kind": "KubeDirectorApp", "metadata": { "name" : "spark221e2" }, "spec" : { "systemctlMounts": true, "config": { "node_services": [ { "service_ids": [ "ssh", "spark", "spark_master", "spark_worker" ], …
La configuration du cluster d'applications est définie comme une ressource
KubeDirectorCluster .
La définition de
KubeDirectorCluster pour l'exemple de cluster Spark 2.2.1 est disponible sur
kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml :
~> cat kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml
apiVersion: "kubedirector.bluedata.io/v1alpha1" kind: "KubeDirectorCluster" metadata: name: "spark221e2" spec: app: spark221e2 roles: - name: controller replicas: 1 resources: requests: memory: "4Gi" cpu: "2" limits: memory: "4Gi" cpu: "2" - name: worker replicas: 2 resources: requests: memory: "4Gi" cpu: "2" limits: memory: "4Gi" cpu: "2" - name: jupyter …
Lancez Spark sur Kubernetes avec KubeDirector
Le démarrage de clusters Spark dans Kubernetes avec KubeDirector est simple.
Tout d'abord, assurez-vous que Kubernetes est en cours d'exécution (version 1.9 ou supérieure) à l'aide de la commande de
kubectl version :
~> kubectl version Client Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T18:02:47Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"} Server Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T17:53:03Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"}
Déployez le service KubeDirector et des exemples de
KubeDirectorApp ressources
KubeDirectorApp à l'aide des commandes suivantes:
cd kubedirector make deploy
En conséquence, il commencera sous KubeDirector:
~> kubectl get pods NAME READY STATUS RESTARTS AGE kubedirector-58cf59869-qd9hb 1/1 Running 0 1m
Affichez la liste des applications installées dans KubeDirector en exécutant
kubectl get KubeDirectorApp :
~> kubectl get KubeDirectorApp NAME AGE cassandra311 30m spark211up 30m spark221e2 30m
Vous pouvez maintenant démarrer le cluster Spark 2.2.1 à l'aide de l'exemple de fichier pour
KubeDirectorCluster et de la commande
kubectl create -f deploy/example_clusters/cr-cluster-spark211up.yaml . Vérifiez qu'il a démarré:
~> kubectl get pods NAME READY STATUS RESTARTS AGE kubedirector-58cf59869-djdwl 1/1 Running 0 19m spark221e2-controller-zbg4d-0 1/1 Running 0 23m spark221e2-jupyter-2km7q-0 1/1 Running 0 23m spark221e2-worker-4gzbz-0 1/1 Running 0 23m spark221e2-worker-4gzbz-1 1/1 Running 0 23m
Spark est également apparu dans la liste des services en cours d'exécution:
~> kubectl get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 21s svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 20s svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 20s svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 20s svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 20s
Si vous accédez au port 31533 dans votre navigateur, vous pouvez voir l'interface utilisateur de Spark Master:
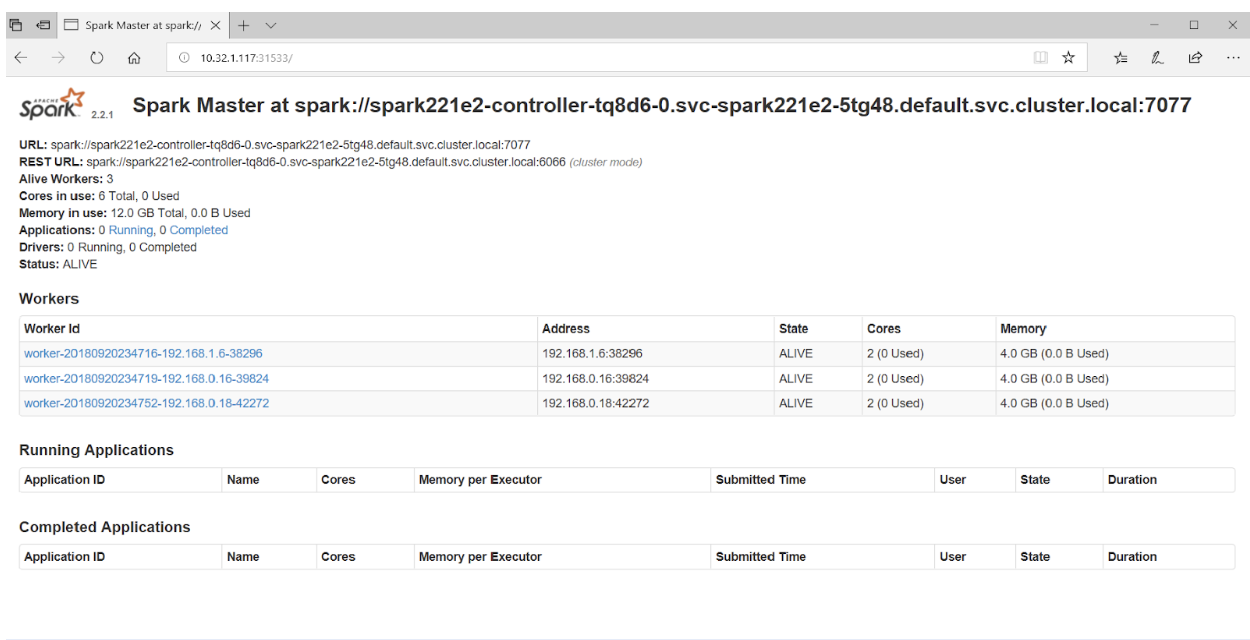
C'est tout! Dans l'exemple ci-dessus, en plus du cluster Spark, nous avons également déployé le
bloc-notes Jupyter .
Pour démarrer une autre application (par exemple, Cassandra), spécifiez simplement un autre fichier avec
KubeDirectorApp :
kubectl create -f deploy/example_clusters/cr-cluster-cassandra311.yaml
Vérifiez que le cluster Cassandra a démarré:
~> kubectl get pods NAME READY STATUS RESTARTS AGE cassandra311-seed-v24r6-0 1/1 Running 0 1m cassandra311-seed-v24r6-1 1/1 Running 0 1m cassandra311-worker-rqrhl-0 1/1 Running 0 1m cassandra311-worker-rqrhl-1 1/1 Running 0 1m kubedirector-58cf59869-djdwl 1/1 Running 0 1d spark221e2-controller-tq8d6-0 1/1 Running 0 22m spark221e2-jupyter-6989v-0 1/1 Running 0 22m spark221e2-worker-d9892-0 1/1 Running 0 22m spark221e2-worker-d9892-1 1/1 Running 0 22m
Kubernetes exécute désormais le cluster Spark (avec Jupyter Notebook) et le cluster Cassandra. La liste des services peut être consultée avec la commande
kubectl get service :
~> kubectl get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d svc-cassandra311-seed-v24r6-0 NodePort 10.96.94.204 <none> 22:31131/TCP,9042:30739/TCP 3m svc-cassandra311-seed-v24r6-1 NodePort 10.106.144.52 <none> 22:30373/TCP,9042:32662/TCP 3m svc-cassandra311-vhh29 ClusterIP None <none> 8888/TCP 3m svc-cassandra311-worker-rqrhl-0 NodePort 10.109.61.194 <none> 22:31832/TCP,9042:31962/TCP 3m svc-cassandra311-worker-rqrhl-1 NodePort 10.97.147.131 <none> 22:31454/TCP,9042:31170/TCP 3m svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 24m svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 24m svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 24m svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 24m svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 24m
PS du traducteur
Si vous êtes intéressé par le projet KubeDirector, vous devez également faire attention à
son wiki . Malheureusement, il n'a pas été possible de trouver une feuille de route publique, cependant, les
problèmes sur GitHub ont mis en lumière le développement du projet et les opinions de ses principaux développeurs. De plus, pour ceux qui s'intéressent à KubeDirector, les auteurs fournissent des liens vers le
chat Slack et
Twitter .
Lisez aussi dans notre blog: