La première chose que nous rencontrons lorsque nous parlons d'optimisation proactive est qu'on ne sait pas ce qui doit être optimisé. "Faites ça, je ne sais pas quoi."
- Il n'y a pas d'algorithme classique.
- Le problème n'est pas encore apparu (inconnu), et on ne peut que deviner où il pourrait être.
- Nous devons trouver des points faibles potentiels dans le système.
- Essayez d'optimiser les performances des requêtes à ces endroits.
Les principaux objectifs de l'optimisation proactive
Les tâches principales de l'optimisation proactive diffèrent des tâches de l'optimisation réactive et sont les suivantes:
- éliminer les goulots d'étranglement dans la base de données;
- diminution de la consommation des ressources de la base de données.
Le dernier moment est le plus fondamental. Dans le cas de l'optimisation réactive, nous n'avons pas pour tâche de réduire la consommation de ressources dans son ensemble, mais uniquement celle d'amener le temps de réponse de la fonctionnalité à l'intérieur de limites acceptables.
Si vous travaillez avec des serveurs de combat, vous avez une bonne idée de la signification des incidents de performances. Vous devez tout quitter et résoudre rapidement le problème. RNKO Payment Center LLC travaille avec de nombreux agents, et il est très important pour eux d'avoir le moins de problèmes possible. Alexander Makarov de HighLoad ++ Siberia a expliqué ce qui avait été fait pour réduire considérablement le nombre d'incidents de performances. L'optimisation proactive est venue à la rescousse. Et pourquoi et comment il est produit sur un serveur de combat, lisez ci-dessous.
 À propos du conférencier:
À propos du conférencier: Alexander Makarov (
AL_IG_Makarov ), administrateur principal de la base de données Oracle, RNKO Payment Center LLC. Malgré la position, il y a très peu d'administration en tant que telle, les tâches principales sont liées à la maintenance du complexe et à son développement, en particulier, à la résolution des problèmes de performance.
L'optimisation sur une base de données de combat est-elle proactive?
Tout d'abord, nous traiterons des termes que ce rapport appelle «optimisation proactive des performances». Parfois, vous pouvez rencontrer le point de vue que l'optimisation proactive est lorsque l'analyse des zones à problème est effectuée avant même le lancement de l'application. Par exemple, nous constatons que certaines requêtes ne fonctionnent pas de manière optimale, car il n'y a pas suffisamment d'index ou la requête utilise un algorithme inefficace, et ce travail est effectué sur des serveurs de test.
Néanmoins, nous au RNCO avons fait ce projet
sur des serveurs de combat . Plusieurs fois, j'ai entendu: «Comment cela? Vous le faites sur un serveur de combat - cela signifie que ce n'est pas une optimisation proactive des performances! » Ici, nous devons rappeler l'approche qui est cultivée dans ITIL. Du point de vue ITIL, nous avons:
- les incidents de performance sont ce qui s'est déjà produit;
- les mesures que nous prenons pour éviter que des incidents de performance ne se produisent.
En ce sens, nos actions sont proactives. Malgré le fait que nous résolvions le problème sur un serveur de combat, le problème lui-même ne s'est pas encore posé: l'incident ne s'est pas produit, nous n'avons pas couru et n'avons pas essayé de résoudre ce problème en peu de temps.
Ainsi, dans ce rapport, la proactivité est comprise comme la
proactivité au sens d'ITIL , nous résolvons le problème avant qu'un incident de performance ne se produise.
Point de référence
RNKO "Payment Center" dessert 2 grands systèmes:
- RBS-Retail Bank;
- CFT Bank.
La nature de la charge sur ces systèmes est mixte (DSS + OLTP): il y a quelque chose qui fonctionne très rapidement, il y a des rapports, il y a des charges moyennes.
Nous sommes confrontés au fait que pas très souvent, mais avec une certaine fréquence, des incidents de performance se sont produits. Ceux qui travaillent avec des serveurs de combat imaginent ce que c'est. Cela signifie que vous devez tout quitter et résoudre rapidement le problème, car à ce stade, le client ne peut pas recevoir le service, quelque chose ne fonctionne pas du tout ou fonctionne très lentement.
Étant donné que de nombreux agents et clients sont liés à notre organisation, cela est très important pour nous. Si nous ne pouvons pas résoudre rapidement les incidents de performance, nos clients souffriront d'une manière ou d'une autre. Par exemple, ils ne pourront pas reconstituer une carte ou effectuer un virement. Par conséquent, nous nous sommes demandé ce qui pourrait être fait pour se débarrasser de ces incidents de performances, même rares. Travailler dans un mode lorsque vous devez tout supprimer et résoudre un problème - ce n'est pas tout à fait correct. Nous utilisons des sprints et établissons un plan de travail de sprint. La présence d'incidents de performance est également un écart par rapport au plan de travail.
Il faut faire quelque chose avec ça!
Approches d'optimisation
Nous avons pensé et compris la technologie d'optimisation proactive. Mais avant de parler d'optimisation proactive, je dois dire quelques mots sur l'optimisation réactive classique.
Optimisation réactive
Le scénario est simple, il y a un serveur de combat sur lequel quelque chose s'est produit: ils ont lancé un rapport, les clients reçoivent des déclarations, à ce moment il y a une activité en cours sur la base de données, et soudain quelqu'un a décidé de mettre à jour une sorte de répertoire volumineux. Le système commence à ralentir. En ce moment, le client vient et dit: "Je ne peux pas faire ceci ou cela" - nous devons trouver une raison pour laquelle il ne peut pas faire ceci.
Algorithme d'action classique:- Reproduisez le problème.
- Localisez le problème.
- Optimisez le lieu du problème.
Dans le cadre de l'approche réactive, la tâche principale n'est pas tant de trouver la cause racine elle-même et de l'éliminer, mais de faire fonctionner le système normalement. L'élimination de la cause profonde peut être traitée plus tard. L'essentiel est de restaurer rapidement le serveur afin que le client puisse recevoir le service.
Les principaux objectifs de l'optimisation réactive
En optimisation réactive, deux objectifs principaux peuvent être distingués:
1.
Diminution du temps de réponse .
Une action, par exemple, la réception d'un rapport, d'une instruction, d'une transaction, doit être effectuée pendant une certaine durée planifiée. Il est nécessaire de s'assurer que l'heure de réception du service retourne aux limites acceptables pour le client. Peut-être que le service fonctionne un peu plus lentement que d'habitude, mais pour le client, cela est acceptable. Ensuite, nous pensons que l'incident de performance a été éliminé et nous commençons à travailler sur la cause première.
2.
Une augmentation du nombre d'objets traités par unité de temps lors du traitement par lots .
Lorsque le traitement par lots des transactions est en cours, il est nécessaire de réduire le temps de traitement d'un objet du package.
Avantages d'une approche réactive:●
Une variété d'outils et de techniques est le principal atout d'une approche réactive.
Nous pouvons utiliser les outils de surveillance pour comprendre directement le problème: il n'y a pas assez de CPU, de threads, de mémoire ou le système de disques a glissé ou les journaux sont traités lentement. Il existe de nombreux outils et techniques pour étudier le problème de performances actuel dans la base de données Oracle.
● Le
temps de réponse souhaité est un autre avantage.
Dans le cadre d'un tel travail, nous amenons la situation à un temps de réponse acceptable, c'est-à-dire que nous n'essayons pas de la réduire à la valeur minimale, mais nous atteignons une certaine valeur et après cette action, nous terminons, car nous pensons avoir atteint des limites acceptables.
Inconvénients de l'approche réactive:- Les incidents de performance demeurent - c'est le plus gros inconvénient de l'approche réactive, car nous ne pouvons pas toujours atteindre la cause première. Elle pouvait rester quelque part à l'écart et mentir quelque part plus profondément, malgré le fait que nous ayons atteint des performances acceptables.
Et comment gérer les incidents de performance s'ils ne se sont pas encore produits? Essayons de formuler comment l'optimisation proactive peut être effectuée afin d'éviter de telles situations.
Optimisation proactive
La première chose que nous rencontrons est que l'on ne sait pas ce qui doit être optimisé. "Faites ça, je ne sais pas quoi."
- Il n'y a pas d'algorithme classique.
- Le problème n'est pas encore apparu (inconnu), et on ne peut que deviner où il pourrait être.
- Nous devons trouver des points faibles potentiels dans le système.
- Essayez d'optimiser les performances des requêtes à ces endroits.
Les principaux objectifs de l'optimisation proactive
Les tâches principales de l'optimisation proactive diffèrent des tâches de l'optimisation réactive et sont les suivantes:
- éliminer les goulots d'étranglement dans la base de données;
- diminution de la consommation des ressources de la base de données.
Le dernier moment est le plus fondamental. Dans le cas de l'optimisation réactive, nous n'avons pas pour tâche de réduire la consommation de ressources dans son ensemble, mais uniquement celle d'amener le temps de réponse de la fonctionnalité dans des limites acceptables.
Comment trouver les goulots d'étranglement dans la base de données?
Lorsque nous commençons à réfléchir à ce problème, de nombreuses sous-tâches surviennent immédiatement. Il est nécessaire d'effectuer:
- Test CPU
- test de charge sur les lectures / enregistrements;
- tests de résistance par le nombre de sessions actives;
- test de charge sur ... etc.
Si nous essayons de simuler ces problèmes sur un complexe de test, nous pouvons rencontrer le fait que le problème survenu sur le serveur de test n'a rien à voir avec le combat. Il y a plusieurs raisons à cela, à commencer par le fait que les serveurs de test sont généralement plus faibles. C'est bien s'il est possible de faire du serveur de test une copie exacte de celui de combat, mais cela ne garantit pas que la charge sera reproduite de la même manière, car vous devez reproduire avec précision l'activité de l'utilisateur et de nombreux autres facteurs différents qui affectent la charge finale. Si vous essayez de simuler cette situation, alors, dans l'ensemble, personne ne garantit que exactement la même chose se produira sur le serveur de combat.
Si, dans un cas, le problème est survenu à cause de l'arrivée d'un nouveau registre, dans l'autre, il pourrait survenir parce que l'utilisateur a lancé un énorme rapport faisant un tri important, à cause duquel l'espace disque logique temporaire s'est rempli et, comme en conséquence, le système a commencé à ralentir. Autrement dit, les raisons peuvent être différentes et il n'est pas toujours possible de les prévoir. Par conséquent,
nous avons abandonné les tentatives de recherche de goulots d'étranglement sur les serveurs de test presque dès le début. Nous ne dépendions que du serveur de combat et de ce qui s'y passait.
Que faire dans ce cas? Essayons de comprendre quelles ressources sont les plus susceptibles de manquer en premier lieu.
Diminuer la consommation de ressources de base de données
Sur la base des complexes industriels dont nous disposons, le
manque de ressources le
plus fréquent est observé dans les lectures de disques et les CPU . Par conséquent, en premier lieu, nous chercherons précisément les faiblesses dans ces domaines.
La deuxième question importante: comment chercher quelque chose?
La question est très simple. Nous utilisons Oracle Enterprise Edition avec l'option Diagnostic Pack et nous avons trouvé un tel outil pour nous - les
rapports AWR (dans d'autres éditions d'Oracle, vous pouvez utiliser les
rapports STATSPACK ). Dans PostgreSQL, il y a un analogue - pgstatspack, il y a
pg_profile d' Andrey Zubkov. Le dernier produit, si je comprends bien, est apparu et n'a commencé à se développer que l'année dernière. Pour MySQL, je n'ai pas pu trouver d'outils similaires, mais je ne suis pas un expert MySQL.
L'approche elle-même n'est liée à aucun type particulier de base de données. S'il est possible d'obtenir des informations sur la charge du système à partir d'un rapport, alors, en utilisant la technique dont je vais parler maintenant, vous pouvez effectuer un travail sur l'optimisation proactive
sur n'importe quelle base .
Optimisation des 5 premières opérations
La technologie d'optimisation proactive que nous avons développée et que nous utilisons au centre de paiement RNCO comprend quatre étapes.
Étape 1. Nous recevons le rapport AWR pour la plus grande période possible.La durée la plus longue possible est nécessaire pour faire la moyenne de la charge sur différents jours de la semaine, car elle est parfois très différente. Par exemple, les registres de la semaine dernière arrivent à RBS-Retail Bank mardi, ils commencent à être traités, et toute la journée nous avons une charge moyenne d'environ 2 à 3 fois. Les autres jours, la charge est moindre.
Si vous savez que le système a des spécificités - certains jours la charge est plus importante, certains jours - moins, alors vous devez recevoir des rapports pour ces périodes séparément et travailler avec eux séparément si nous voulons optimiser des intervalles de temps spécifiques . Si vous devez optimiser la situation globale sur le serveur, vous pouvez obtenir un rapport volumineux pour le mois et voir ce que les ressources du serveur consomment réellement.
Parfois, des situations très inattendues se présentent. Par exemple, dans le cas de CFT Bank, une demande qui vérifie la file d'attente du serveur de rapports peut figurer dans le top 10. De plus, cette demande est officielle et n'exécute aucune logique métier, mais vérifie uniquement s'il existe un rapport d'exécution ou non.
Étape 2. Nous regardons les sections:- SQL ordonné par Elapsed Time - requêtes SQL triées par runtime;
- SQL ordonné par CPU Time - pour l'utilisation du CPU;
- SQL ordonné par Gets - par des lectures logiques;
- SQL ordonné par Reads - pour les lectures physiques.
Les autres sections de SQL classées par sont étudiées selon les besoins.
Étape 3. Nous déterminons les opérations parentes et les demandes qui en dépendent.Le rapport AWR comporte des sections distinctes dans lesquelles, selon la version d'Oracle, 15 requêtes principales ou plus sont affichées dans chacune de ces sections. Mais ces requêtes Oracle dans le rapport AWR montrent un gâchis.
Par exemple, il y a une opération parent, à l'intérieur, il peut y avoir 3 requêtes principales. Oracle dans le rapport AWR affichera à la fois l'opération parente et toutes ces 3 requêtes. Par conséquent, vous devez effectuer une analyse de cette liste et voir à quelle opération spécifique les demandes se réfèrent, les regrouper.
Étape 4. Nous optimisons les 5 premières opérations.Après un tel regroupement, la sortie est une liste d'opérations parmi lesquelles vous pouvez sélectionner les plus difficiles. Nous sommes limités à 5 opérations (pas de demandes, à savoir des opérations). Si le système est plus complexe, vous pouvez en prendre plus.
Erreurs de conception de requête courantes
Lors de l'application de cette technique, nous avons compilé une petite liste d'erreurs de conception typiques. Certaines erreurs sont si simples qu'il semble qu'elles ne puissent pas l'être.
●
Manque d'index → Analyse complèteIl y a des cas très fortuits, par exemple, avec l'absence d'index sur le plan de combat. Nous avons eu un exemple concret où une requête pendant longtemps a fonctionné rapidement sans index. Mais il y a eu une analyse complète, et à mesure que la taille de la table augmentait progressivement, la requête a commencé à fonctionner plus lentement et d'un trimestre à l'autre, elle a pris un peu plus de temps. Au final, nous lui avons prêté attention et il s'est avéré que l'indice n'était pas là.
●
Grand choix → Analyse complèteLa deuxième erreur courante est un grand échantillon de données - le cas classique d'une analyse complète. Tout le monde sait qu'une analyse complète ne doit être utilisée que lorsqu'elle est vraiment justifiée. Parfois, il existe des cas où une analyse complète est trouvée où il serait possible de s'en passer, par exemple, si vous transférez les conditions de filtrage du code pl / sql vers la requête.
●
Indice inefficace → Longue analyse de la plage d'indexC'est peut-être même l'erreur la plus courante, pour laquelle, pour une raison quelconque, ils disent très peu - le soi-disant index inefficace (balayage d'index long, balayage de plage INDEX long). Par exemple, nous avons une table pour les registres. Dans la demande, nous essayons de trouver tous les registres de cet agent et, finalement, ajoutons une condition de filtrage, par exemple, pour une certaine période, ou avec un numéro spécifique, ou un client spécifique. Dans de telles situations, l'index est généralement construit uniquement sur le champ "agent" pour des raisons d'universalité d'utilisation. Le résultat est l'image suivante: au cours de la première année de travail, par exemple, l'agent avait 100 entrées dans ce tableau, l'année prochaine déjà 1 000, une autre année, il peut y avoir 10 000 entrées. Un certain temps passe, ces enregistrements deviennent 100 000. De toute évidence, la demande commence à fonctionner lentement, car dans la demande, vous devez ajouter non seulement l'identifiant de l'agent lui-même, mais également un filtre supplémentaire, dans ce cas par date. Sinon, il se trouvera que la taille de l'échantillon augmentera d'année en année, car le nombre de registres pour cet agent augmente. Ce problème doit être résolu au niveau de l'index. S'il y a trop de données, alors nous devrions déjà penser dans le sens du partitionnement.
●
Branches de code de distribution inutilesC'est aussi un cas curieux, mais, néanmoins, cela arrive. Nous regardons les requêtes les plus fréquentes et nous y voyons d'étranges requêtes. Nous venons voir les développeurs et leur disons: «Nous avons trouvé des requêtes, essayons de voir ce qui peut être fait.» Le développeur réfléchit, puis vient après un moment et dit: «Cette branche de code ne devrait pas être sur votre système. Vous n'utilisez pas cette fonctionnalité. " Ensuite, le développeur vous recommande d'activer certains paramètres spéciaux afin de contourner cette section du code.
Etudes de cas
J'aimerais maintenant considérer deux exemples de notre pratique réelle. Lorsque nous traitons les requêtes les plus fréquentes, nous pensons bien sûr d'abord au fait qu'il devrait y avoir quelque chose de très lourd, de non trivial, avec des opérations complexes. En fait, ce n'est pas toujours le cas. Parfois, il existe des cas où des requêtes très simples entrent dans les principales opérations.
Exemple 1
select * from (select o.* from rnko_dep_reestr_in_oper o where o.type_oper = 'proc' and o.ean_rnko in (select l.ean_rnko from rnko_dep_link l where l.s_rnko = :1) order by o.date_oper_bnk desc, o.date_reg desc) where ROWNUM = 1
Dans cet exemple, une requête se compose de seulement deux tables, et ce ne sont pas des tables lourdes - seulement quelques millions d'enregistrements. Cela semblerait plus facile? Cependant, la demande a atteint le sommet.
Essayons de comprendre ce qui ne va pas avec lui.
Ci-dessous, une image de l'Enterprise Manager Cloud Control - données sur les statistiques de cette demande (Oracle a un tel outil). On peut voir qu'il y a une charge régulière sur cette demande (graphique supérieur). Le chiffre 1 sur le côté indique qu'en moyenne, pas plus d'une session n'est en cours d'exécution. Le diagramme vert montre que la
requête utilise uniquement le CPU , ce qui est doublement intéressant.

Essayons de comprendre ce qui se passe ici?

Ci-dessus est un tableau avec des statistiques sur demande. Près de 700 000 lancements - cela ne surprendra personne. Mais l'intervalle de temps entre le premier chargement le 15 décembre et le dernier chargement le 22 décembre (voir l'image précédente) est d'une semaine. Si vous comptez le nombre de démarrages par seconde, il s'avère que la
requête est exécutée en moyenne toutes les secondes .
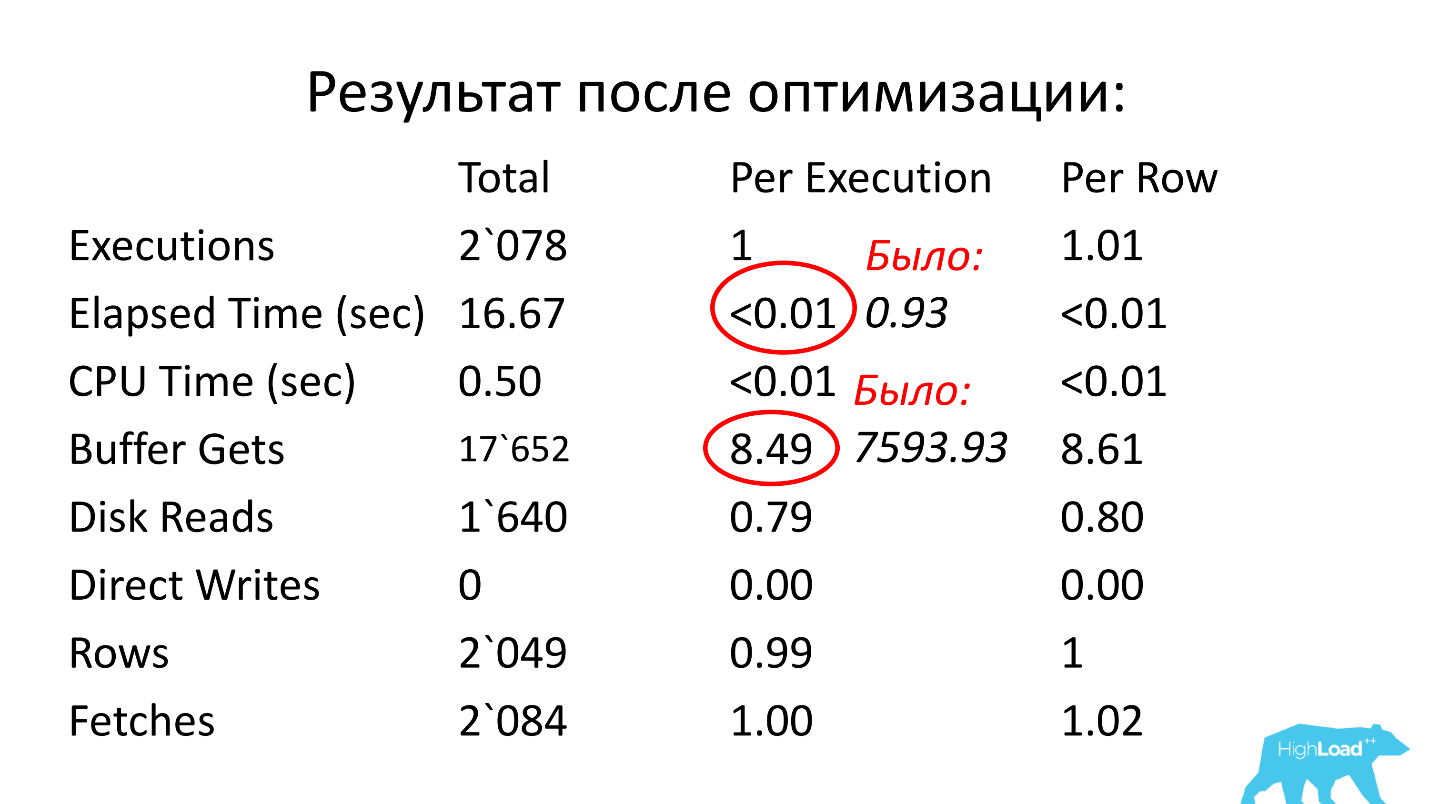
Nous regardons plus loin. Le temps d'exécution de la requête est de 0,93 seconde, soit moins d'une seconde, c'est super. Nous pouvons nous réjouir - la demande n'est pas lourde. Néanmoins, il a atteint le sommet, ce qui signifie qu'il consomme beaucoup de ressources. Où consomme-t-il beaucoup de ressources?
Le tableau comporte une ligne pour les lectures logiques. Nous voyons que pour un lancement, il a besoin de près de 8 000 blocs (généralement 1 bloc fait 8 Ko). Il s'avère que la requête, qui fonctionne une fois par seconde, charge environ 64 Mo de données de la mémoire. Quelque chose ne va pas ici, nous devons comprendre.
Voyons le plan: il y a un scan complet. Eh bien, passons.
Plan hash value: 634977963
Dans la table rnko_dep_reestr_in_oper, il n'y a que 5 millions de lignes et leur longueur moyenne est de 150 octets. Mais il s'est avéré qu'il n'y a pas assez d'index pour le champ qui se connecte - la sous-requête est connectée à la demande via le champ ean_rnko, pour lequel il n'y a pas d'index!
De plus, même s'il apparaît, en fait la situation ne sera pas très bonne. Ce long balayage d'index (long INDEX RANGE SCAN) se produira. ean_rnko est l'identifiant interne de l'agent. Les registres d'agents s'accumuleront et chaque année, la quantité de données que cette demande sélectionnera augmentera et la demande ralentira.
Solution: créez un index pour les champs ean_rnko et date_reg, demandez aux développeurs de limiter la profondeur d'analyse par date dans cette demande. Ensuite, vous pouvez au moins dans une certaine mesure garantir que les performances de la requête resteront approximativement aux mêmes limites, car la taille de l'échantillon sera limitée à un intervalle de temps fixe et la table entière n'aura pas besoin d'être lue. C'est un point très important, regardez ce qui s'est passé.
Après optimisation, le temps de fonctionnement est devenu inférieur à un centième de seconde (il était de 0,93), le nombre de blocs est devenu en moyenne de 8,5 à 1 000 fois moins qu'auparavant.
Exemple 2
select count(1) from loy$barcodes t where t.id_processing = :b1 and t.id_rec_out is null and not t.barcode is null and t.status = 'u' and not t.id_card is null
J'ai commencé l'histoire en disant qu'en général, quelque chose de compliqué est attendu en haut de la requête. Ci-dessus est un exemple d'une requête «complexe» qui va à une table (!), Et elle est également entrée dans les requêtes principales :) Il y a un index sur le champ ID_PROCESSING!
Il y a 3 conditions IS NULL dans cette requête et, comme nous le savons, ces conditions ne sont pas indexées (vous ne pouvez pas utiliser l'index dans ce cas). De plus, il n'y a que deux conditions de type égalité (par ID_PROCESSING et STATUS).
Probablement, le développeur qui examinerait cette requête suggérerait tout d'abord de faire un index sur ID_PROCESSING et STATUS. Mais étant donné la quantité de données qui sera choisie (il y en aura beaucoup), cette solution ne fonctionne pas.
Cependant, la demande consomme beaucoup de ressources, ce qui signifie que quelque chose doit être fait pour le faire fonctionner plus rapidement. Essayons de comprendre les raisons.

Les statistiques ci-dessus sont pour 1 jour, à partir de laquelle on peut voir que la demande est lancée toutes les 5 minutes. La principale consommation de ressources est la lecture du processeur et du disque. Ci-dessous sur le graphique avec des statistiques sur le nombre de démarrages de requêtes, on peut voir que tout est en ordre - le nombre de démarrages ne change presque pas dans le temps - une situation assez stable.

Et si vous regardez plus loin, vous pouvez voir que le temps de requête varie parfois beaucoup - plusieurs fois, ce qui est déjà significatif.
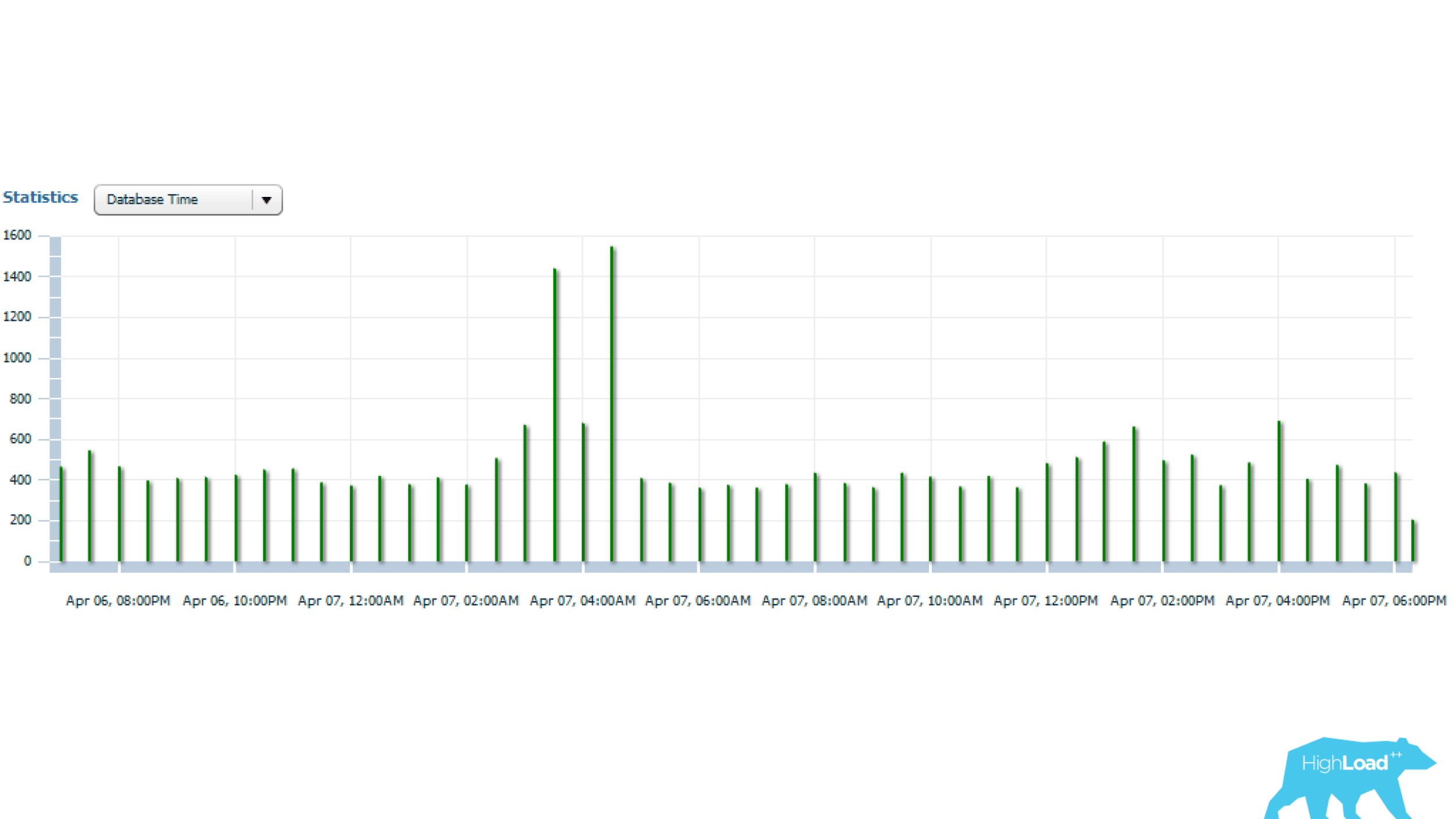
Voyons cela ensuite.
Oracle Enterprise Manager dispose d'un utilitaire de surveillance SQL. Avec cet utilitaire, vous pouvez voir en temps réel la consommation de ressources sur demande.

Rapport ci-dessus pour une demande problématique. Tout d'abord, nous devrions être intéressés par le fait que le SCAN DE LA PLAGE D'INDEX (ligne du bas) dans la colonne Lignes réelles affiche 17 millions de lignes. Cela vaut probablement la peine d'être considéré.
Si nous regardons plus loin le plan de mise en œuvre, il s'avère qu'après le prochain élément du plan, sur ces 17 millions de lignes, il n'en reste que 1705. La question est de savoir pourquoi 17 millions ont été choisis? Il restait environ 0,01% dans l'échantillon final, c'est-à-dire
, manifestement inefficace, qu'un
travail inutile a été effectué . De plus, ce travail se fait toutes les 5 minutes. Voilà le problème! Par conséquent, cette demande a atteint les requêtes principales.
Essayons de résoudre ce problème non trivial. L'index qui se demande en premier lieu est inefficace, vous devez donc trouver quelque chose de délicat et vaincre les conditions IS NULL.
Nouvel index
Nous avons consulté les développeurs, réfléchi et pris cette décision: nous avons fait un index fonctionnel dans lequel il y a une colonne ID_PROCESSING, qui était avec la condition d'égalité dans la demande, et nous avons inclus tous les autres champs comme arguments de cette fonction:
create index gc.loy$barcod_unload_i on gc.loy$barcodes (gc.loy_barcodes_ic_unload(id_rec_out, barcode, id_card, status), id_processing); function loy_barcodes_ic_unload( pIdRecOut in loy$barcodes.id_rec_out%type, pBarcode in loy$barcodes.barcode%type, pIdCard in loy$barcodes.id_card%type, pStatus in loy$barcodes.status%type) return varchar2 deterministic is vRes varchar2(1) := ''; begin if pIdRecOut is null and pBarcode is not null and pIdCard is not null and pStatus = 'U' then vRes := pStatus; end if; return vRes; end loy_barcodes_ic_unload;
Cette fonction est de type déterministe, c'est-à-dire que sur le même ensemble de paramètres elle donne toujours la même réponse. Nous nous sommes assurés que cette fonction renvoyait toujours une valeur - dans ce cas, «U». Lorsque toutes ces conditions sont remplies, «U» est émis, lorsqu'il n'est pas rempli - NULL. Un tel index fonctionnel permet de filtrer efficacement les données.
L'application de cet indice a conduit au résultat suivant:
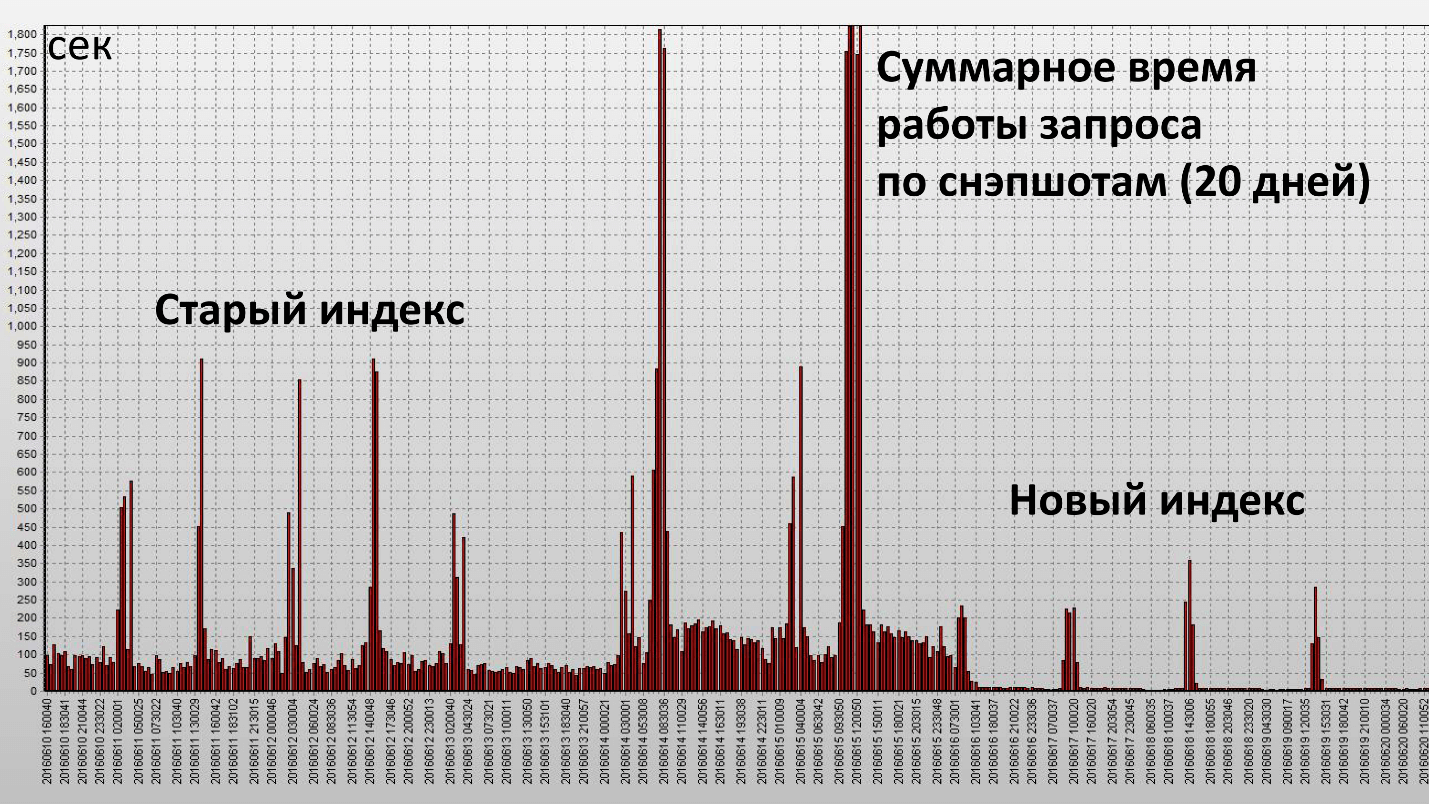
Ici, une colonne est un instantané, ils sont effectués toutes les demi-heures de la base de données. Nous avons atteint notre objectif et cet indice a été vraiment efficace. Voyons les caractéristiques quantitatives:
Statistiques moyennes des demandes
|
| Avant
| APRÈS
|
Temps écoulé, sec
| 143,21
| 60,7
|
Temps CPU, sec
| 33,23
| 45,38
|
Buffer Gets Block
| 6`288`237.67
| 1`589`836
|
Bloc de lecture de disque
| 266`600.33
| 2`680
|
Le temps de fonctionnement a diminué de 2,5 fois et la consommation de ressources (Buffer Gets) - d'environ 4. Le nombre de blocs de données lus sur le disque a diminué de manière très significative.
Résultats d'optimisation proactive
Nous avons reçu:
- réduire la charge sur la base de données;
- améliorer la stabilité de la base de données;
- une réduction significative du nombre d'incidents de performances logicielles.
Les incidents de performances ont diminué de 10 fois . Il s'agit d'un montant subjectif, avant les incidents survenus au complexe RBS-Retail Bank 1 à 2 fois par mois, mais maintenant nous les avons pratiquement oubliés.
Cela soulève la question - qu'en est-il des incidents de performances logicielles? Nous ne les avons pas traités directement?
Retour au dernier horaire. Si vous vous souvenez, il y avait une analyse complète, il était nécessaire de stocker un grand nombre de blocs en mémoire. Étant donné que la demande a été exécutée régulièrement, tous ces blocs ont été stockés dans le cache Oracle. Il s'avère que si à ce moment une charge élevée se produit dans la base de données, par exemple, quelqu'un commence à utiliser activement la mémoire, vous aurez besoin d'un cache pour stocker les blocs de données. Ainsi, une partie des données de notre demande sera évincée, ce qui signifie que nous devrons effectuer des lectures physiques. Si vous effectuez des lectures physiques, le temps d'exécution de la requête augmentera immédiatement considérablement.
La lecture logique fonctionne avec la mémoire, elle se produit rapidement et tout accès au disque est lent (si vous regardez l'heure, en millisecondes). Si vous êtes chanceux et qu'il y a ces données dans le cache du système d'exploitation ou dans le cache de la baie, alors ce seront encore des dizaines de microsecondes. La lecture à partir du cache d'Oracle est beaucoup plus rapide.
Lorsque nous nous sommes débarrassés de l'analyse complète, la nécessité de stocker un si grand nombre de blocs dans le cache (Buffer Cache) a disparu. En cas de pénurie de ces ressources, la demande est plus ou moins stable. Il n'y a plus de pointes aussi importantes que celles de l'ancien index.
Résumé de l'optimisation proactive:- L'optimisation initiale des requêtes doit être effectuée sur des serveurs de test, pour voir comment les requêtes et leur logique métier fonctionnent, afin de ne rien faire de superflu. Ces œuvres restent.
- Mais périodiquement, une fois tous les quelques mois, il est logique de supprimer les rapports à pleine charge du serveur, de rechercher les principales requêtes et opérations dans la base de données et de les optimiser.
Il existe de nombreux outils pour obtenir des statistiques dans une base de données Oracle:- Rapport AWR (DBMS_WORKLOAD_REPOSITORY.awr_report_html);
- Enterprise Manager Cloud Control 12c (Détails SQL);
- Rapport SQL Details Active (DBMS_PERF.report_sql);
- Surveillance SQL (onglet dans EMCC);
- Rapport de surveillance SQL (DBMS_SQLTUNE.report_sql_monitor *).
Certains de ces outils fonctionnent dans la console, c'est-à-dire qu'ils ne sont pas liés à Enterprise Manager.
Exemples d'outils Oracle pour collecter des statistiques Bonus: les spécialistes de RNCO «Payment Center» et de CFT étaient bien préparés pour la conférence de Novossibirsk, ont fait quelques reportages utiles et ont également organisé une véritable radio de sortie. Pendant deux jours, des experts, des conférenciers et des organisateurs ont réussi à visiter la radio CFT. Vous pouvez revenir à l'été sibérien en incluant des entrées, voici les liens vers les blocs:
Kubernetes: avantages et inconvénients ;
Science des données et apprentissage automatique ;
DevOps .
À HighLoad ++ à Moscou, qui a déjà lieu les 8 et 9 novembre, il y aura des choses encore plus intéressantes. Le programme comprend des rapports sur tous les aspects du travail sur des projets très chargés, des master classes, des réunions et des événements de partenaires qui partageront des conseils d'experts et trouveront quelque chose à surprendre. N'oubliez pas d'écrire sur les plus intéressants et notifiez-les dans la newsletter , connectez-vous!