Qu'est-ce que le langage de requête GraphQL? Quels avantages cette technologie offre-t-elle et quels problèmes les développeurs rencontreront-ils lorsqu'ils l'utiliseront? Comment utiliser GraphQL efficacement? À propos de tout cela sous la coupe.

L'article est basé sur le rapport d'introduction de
Vladimir Tsukur (
volodymyrtsukur ) de la conférence
Joker 2017 .
Je m'appelle Vladimir, je dirige le développement d'un des départements de WIX. Plus d'une centaine de millions d'utilisateurs de WIX créent des sites Web de différentes directions - des sites et magasins de cartes de visite aux applications Web complexes où vous pouvez écrire du code et une logique arbitraire. En tant qu'exemple vivant d'un projet sur WIX, je voudrais vous montrer le site
Web à succès
unicornadoptions.com , qui offre la possibilité d'acheter un kit pour apprivoiser une licorne - un excellent cadeau pour un enfant.

Un visiteur de ce site peut choisir un kit qu'il aime apprivoiser une licorne, disons rose, puis voir ce qu'il y a exactement dans ce kit: jouet, certificat, badge. De plus, l'acheteur a la possibilité d'ajouter des marchandises au panier, d'afficher son contenu et de passer une commande. Ceci est un exemple simple d'un site de magasin, et nous en avons plusieurs centaines de milliers. Tous sont construits sur la même plate-forme, avec un backend, avec un ensemble de clients que nous prenons en charge en utilisant l'API pour cela. Il s'agit de l'API qui sera discutée plus loin.
API simple et ses problèmes
Imaginons quelle API à usage général (c'est-à-dire une API pour tous les magasins au-dessus de la plate-forme) nous pourrions créer pour fournir des fonctionnalités de magasin. Concentrons-nous uniquement sur l'obtention de données.
Pour une page de produit sur un tel site, le nom du produit, le prix, les photos, la description, des informations supplémentaires et bien plus doivent être retournés. Dans une solution complète pour les magasins sur WIX, il existe plus de deux douzaines de tels champs de données. La solution standard pour une telle tâche en plus de l'API HTTP est de décrire la ressource
/products/:id , qui renvoie les données produit sur la demande
GET . Voici un exemple de données de réponse:
{ "id": "59eb83c0040fa80b29938e3f", "title": "Combo Pack with Dreamy Eyes 12\" (Pink) Soft Toy", "price": 26.99, "description": "Spread Unicorn love amongst your friends and family by purchasing a Unicorn adoption combo pack today. You'll receive your very own fabulous adoption pack and a 12\" Dreamy Eyes (Pink) cuddly toy. It makes the perfect gift for loved ones. Go on, you know you want to, adopt today!", "sku":"010", "images": [ "http://localhost:8080/img/918d8d4cc83d4e5f8680ca4edfd5b6b2.jpg", "http://localhost:8080/img/f343889c0bb94965845e65d3f39f8798.jpg", "http://localhost:8080/img/dd55129473e04f489806db0dc6468dd9.jpg", "http://localhost:8080/img/64eba4524a1f4d5d9f1687a815795643.jpg", "http://localhost:8080/img/5727549e9131440dbb3cd707dce45d0f.jpg", "http://localhost:8080/img/28ae9369ec3c442dbfe6901434ad15af.jpg" ] }

Regardons maintenant la page du catalogue de produits. Pour cette page, vous avez besoin de la collection de ressources
/ products . Mais uniquement en affichant la collection de produits sur la page du catalogue, toutes les données produit ne sont pas nécessaires, mais uniquement le prix, le nom et l'image principale. Par exemple, la description, les informations supplémentaires, les images d'arrière-plan, etc. ne nous intéressent pas.

Supposons, par souci de simplicité, que nous décidions d'utiliser le même modèle de données produit pour les ressources
/products et
/products/:id . Dans le cas d'une collection de tels produits, il y en aura potentiellement plusieurs. Le schéma de réponse peut être représenté comme suit:
GET /products [ { title price images description info ... } ]
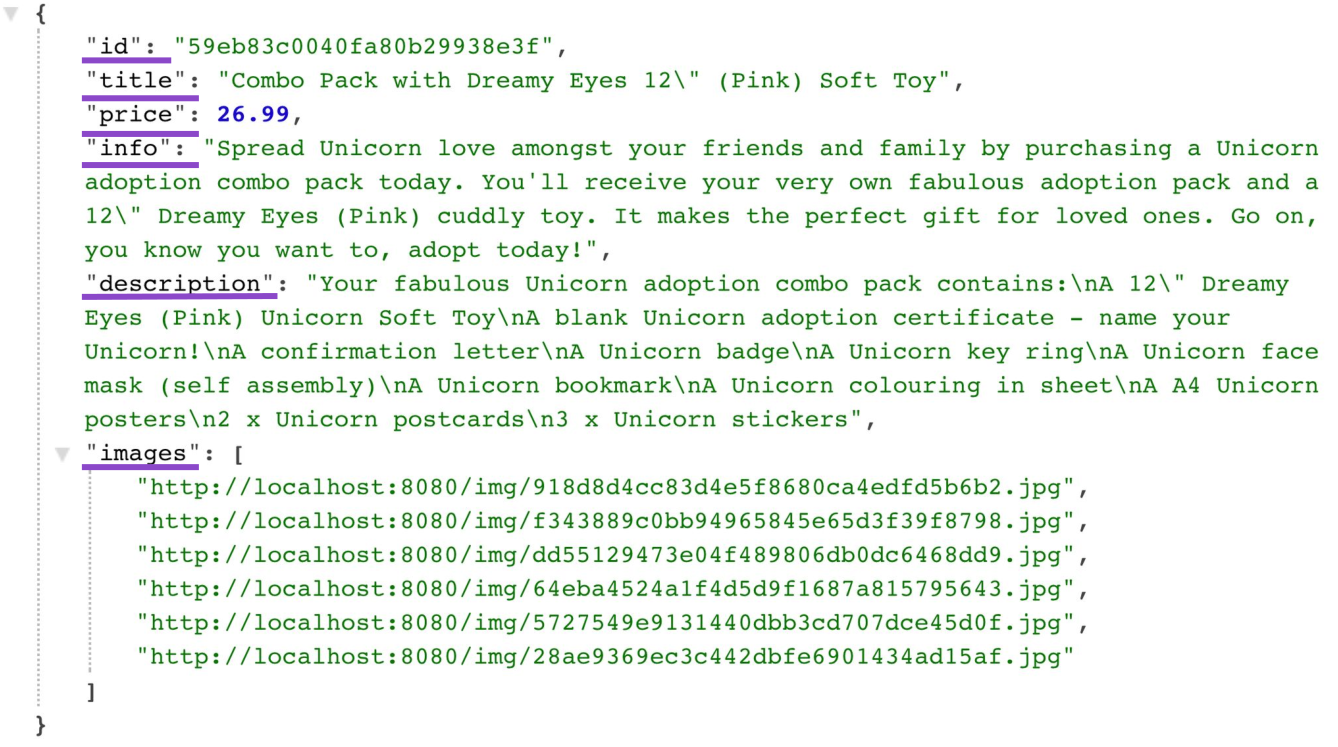
Examinons maintenant la «charge utile» de la réponse du serveur pour la collection de produits. Voici ce qui est réellement utilisé par le client parmi plus de deux douzaines de champs:
{
"id": "59eb83c0040fa80b29938e3f",
"title": "Combo Pack with Dreamy Eyes 12\" (Pink) Soft Toy",
"price": 26.99,
"info": "Spread Unicorn love amongst your friends and family by purchasing a Unicorn adoption combo pack today. You'll receive your very own fabulous adoption pack and a 12\" Dreamy Eyes (Pink) cuddly toy. It makes the perfect gift for loved ones. Go on, you know you want to, adopt todayl",
" description": "Your fabulous Unicorn adoption combo pack contains:\nA 12\" Dreamy Eyes (Pink) Unicorn Soft Toy\nA blank Unicorn adoption certificate — name your Unicorn!\nA confirmation letter\nA Unicorn badge\nA Unicorn key ring\nA Unicorn face mask (self assembly)\nA Unicorn bookmark\nA Unicorn colouring in sheet\nA A4 Unicorn posters\n2 x Unicorn postcards\n3 x Unicorn stickers",
"images": [
"http://localhost:8080/img/918d8d4cc83d4e5f8680ca4edfd5b6b2.jpg",
"http://localhost:8080/img/f343889c0bb94965845e65d3f39f8798.jpg",
"http://localhost:8080/img/dd55129473604f489806db0dC6468dd9.jpg",
"http://localhost:8080/img/64eba4524a1f4d5d9f1687a815795643.jpg",
"http://localhost:8080/img/5727549e9l3l440dbb3cd707dce45d0f.jpg",
"http://localhost:8080/img/28ae9369ec3c442dbfe6901434ad15af.jpg"
],
...
}Évidemment, si je veux garder le modèle de produit simple en renvoyant les mêmes données, je me retrouve avec un problème de fetching, obtenant dans certains cas plus de données que je n'en ai besoin. Dans ce cas, cela est apparu sur la page du catalogue de produits, mais en général, tout écran d'interface utilisateur qui est en quelque sorte connecté au produit ne nécessitera potentiellement de lui qu'une partie (et pas toutes) des données.
Regardons maintenant la page du panier. Dans le panier, en plus des produits eux-mêmes, il y a aussi leur quantité (dans ce panier), le prix, ainsi que le coût total de la commande entière:

Si nous continuons l'approche de la modélisation simple de l'API HTTP, alors le panier peut être représenté à travers la ressource
/ carts /: id , dont la présentation fait référence aux ressources des produits ajoutés à ce panier:
{ "id": 1, "items": [ { "product": "/products/59eb83c0040fa80b29938e3f", "quantity": 1, "total": 26.99 }, { "product": "/products/59eb83c0040fa80b29938e40", "quantity": 2, "total": 25.98 }, { "product": "/products/59eb88bd040fa8125aa9c400", "quantity": 1, "total": 26.99 } ], "subTotal": 79.96 }
Maintenant, par exemple, afin de dessiner un panier avec trois produits à l'avant, vous devez faire quatre demandes: une pour charger le panier lui-même et trois demandes pour charger les données de produit (nom, prix et numéro de référence).
Le deuxième problème que nous avons eu est sous-récupéré. La différenciation des responsabilités entre le panier et les ressources produit a conduit à la nécessité de faire des demandes supplémentaires. Il y a évidemment un certain nombre d'inconvénients ici: en raison
d'un plus grand nombre de demandes, nous atterrissons la batterie du téléphone mobile plus rapidement et obtenons la réponse complète plus lentement. Et l'évolutivité de notre solution soulève également des questions.
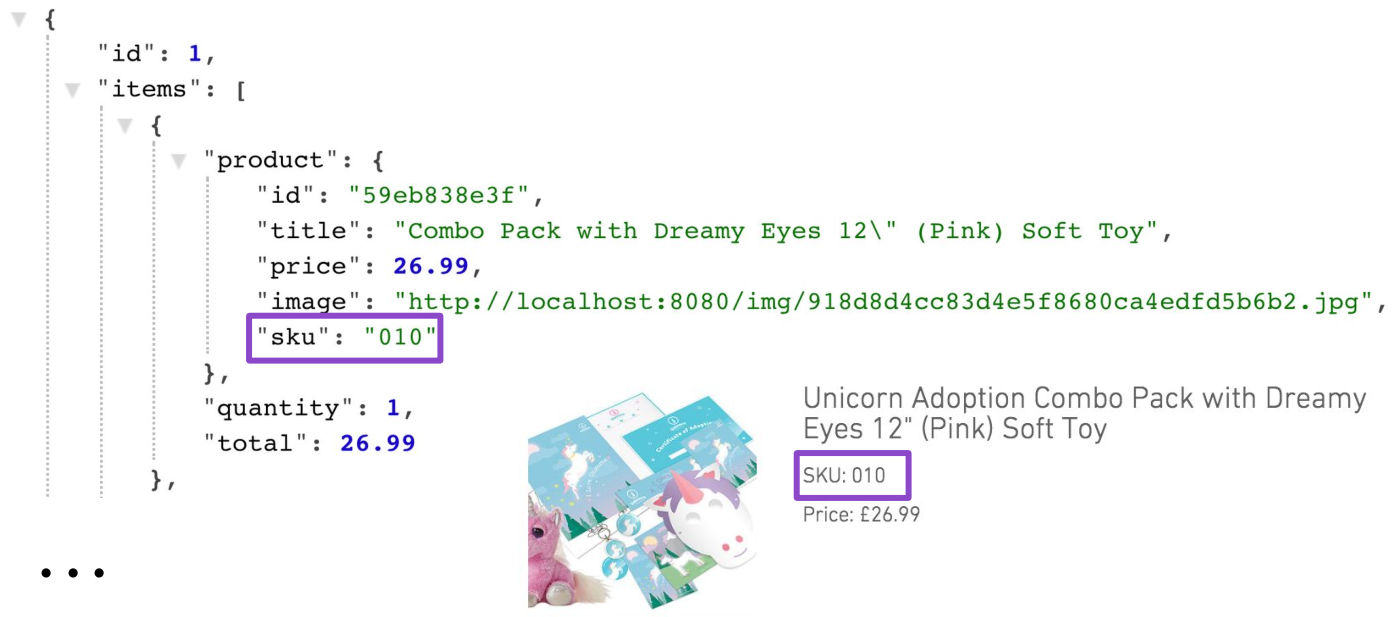
Bien entendu, cette solution n'est pas adaptée à la production. Une façon de résoudre le problème consiste à ajouter un support de projection pour le panier. Une de ces projections pourrait, en plus des données du panier lui-même, renvoyer des données sur les produits. De plus, cette projection sera très spécifique, car c'est sur la page panier que vous avez besoin du numéro d'inventaire (SKU) du produit. Nulle part ailleurs le SKU n'était nécessaire ailleurs.
GET /carts/1?projection=with-products
Un tel «ajustement» des ressources pour une interface utilisateur spécifique ne se termine généralement pas, et nous commençons à générer d'autres projections: de brèves informations sur le panier, la projection du panier pour le Web mobile, puis la projection pour les licornes.

(En général, dans WIX Designer, en tant qu'utilisateur, vous pouvez configurer les données de produit que vous souhaitez afficher sur la page du produit et les données à afficher dans le panier)
Et là, des difficultés nous attendent: nous encadrons le jardin et recherchons des solutions complexes. Il existe peu de solutions standard du point de vue de l'API pour une telle tâche, et elles dépendent généralement fortement du cadre ou de la bibliothèque de description des ressources HTTP.
Plus important encore, il devient maintenant plus difficile de travailler, car lorsque les exigences côté client changent, le backend doit constamment «rattraper» et les satisfaire.
En tant que «cerise sur le gâteau», examinons une autre question importante. Dans le cas d'une simple API HTTP, le développeur du serveur n'a aucune idée du type de données que le client utilise. Le prix est-il utilisé? Description? Une ou toutes les images?
En conséquence, plusieurs questions se posent. Comment travailler avec des données obsolètes / obsolètes? Comment savoir quelles données ne sont plus utilisées? Comment est-il relativement sûr de supprimer des données de la réponse sans casser la plupart des clients? Il n'y a pas de réponse à ces questions avec l'API HTTP habituelle. Malgré le fait que nous soyons optimistes et que l'API semble simple, la situation ne semble pas si chaude. Cette gamme de problèmes d'API n'est pas propre à WIX. Un grand nombre d'entreprises ont dû faire affaire avec eux. Maintenant, il est intéressant de chercher une solution potentielle.
GraphQL. Commencer
En 2012, dans le processus de développement d'une application mobile, Facebook a été confronté à un problème similaire. Les ingénieurs souhaitaient atteindre le nombre minimal d'appels d'applications mobiles vers le serveur, tandis qu'à chaque étape, ils ne recevaient que les données nécessaires et rien d'autre qu'eux. Le résultat de leurs efforts a été GraphQL, présenté à la conférence React Conf 2015. GraphQL est un langage de description de requête, ainsi qu'un environnement d'exécution pour ces requêtes.

Envisagez une approche typique pour travailler avec des serveurs GraphQL.
Nous décrivons le schéma
Le schéma de données dans GraphQL définit les types et les relations entre eux et le fait de manière fortement typée. Par exemple, imaginez un modèle simple de réseau social.
User connaît des amis, des
friends . Les utilisateurs vivent dans la ville et la ville connaît ses habitants à travers le champ des
citizens . Voici ce qu'est un graphique d'un tel modèle dans GraphQL:
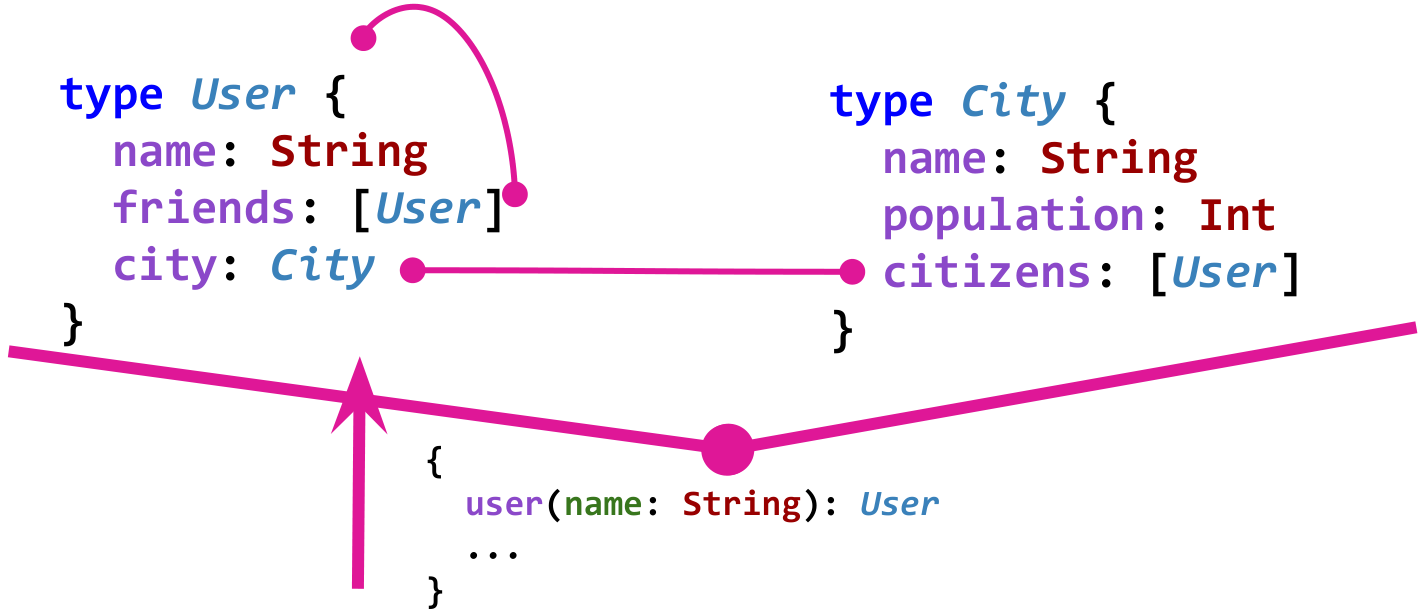
Bien sûr, pour que le graphique soit utile, les soi-disant «points d'entrée» sont également nécessaires. Par exemple, un tel point d'entrée pourrait obtenir un utilisateur par son nom.
Demander des données
Voyons quelle est l'essence du langage de requête GraphQL. Traduisons cette question dans cette langue:
"Pour un utilisateur nommé Vanya Unicorn, je veux connaître les noms de ses amis, ainsi que le nom et la population de la ville dans laquelle Vanya vit" :
{ user(name: "Vanya Unicorn") { friends { name } city { name population } } }
Et voici la réponse du serveur GraphQL:
{ "data": { "user": { "friends": [ { "name": "Lena" }, { "name": "Stas" } ] "city": { "name": "Kyiv", "population": 2928087 } } } }
Remarquez comment le formulaire de demande est «conforme» au formulaire de réponse. Il y a un sentiment que ce langage de requête a été créé pour JSON. Avec une frappe forte. Et tout cela se fait en une seule requête HTTP POST - pas besoin de faire plusieurs appels au serveur.
Voyons à quoi cela ressemble dans la pratique. Ouvrons la console standard pour le serveur GraphQL, qui s'appelle Graph
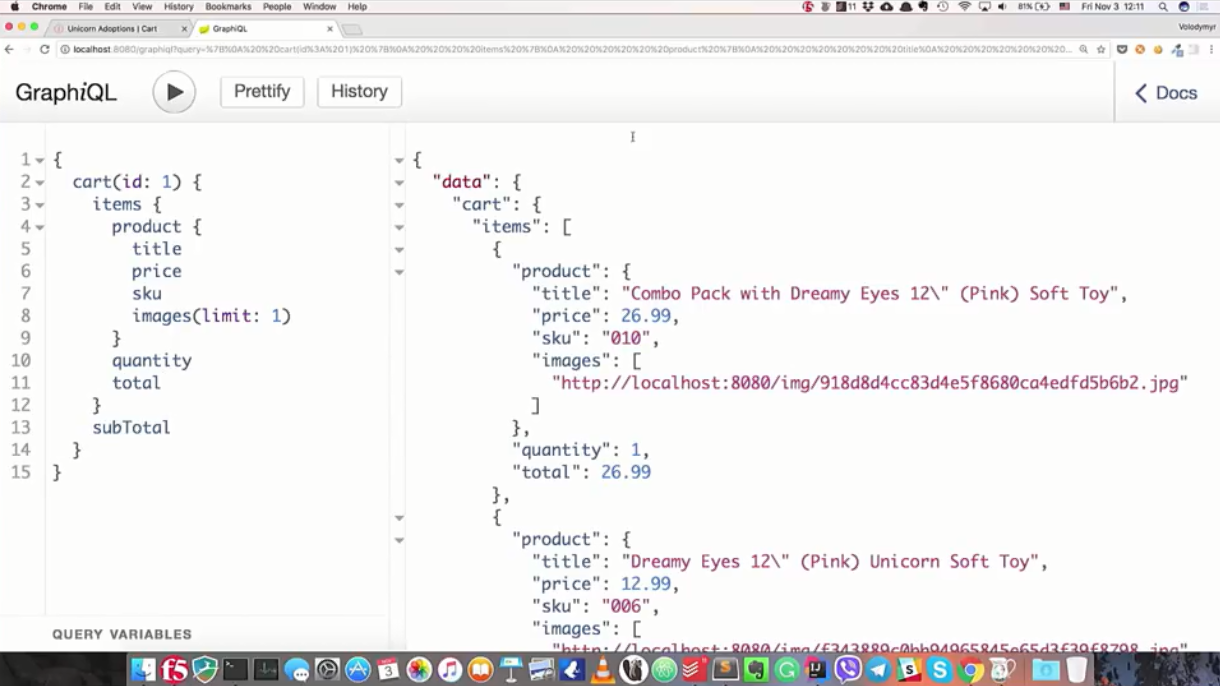
i QL ("graph"). Pour demander un panier, je répondrai à la demande suivante:
"Je souhaite obtenir un panier par identifiant 1, je suis intéressé par toutes les positions de ce panier et les informations produit. D'après les informations, le nom, le prix, le numéro d'inventaire et les images sont importants (et seulement la première). Je suis également intéressé par la quantité de ces produits, quel est leur prix et le coût total dans le panier .
" { cart(id: 1) { items { product { title price sku images(limit: 1) } quantity total } subTotal } }
Après avoir réussi la demande, nous obtenons exactement ce qui a été demandé:
Avantages clés
- Échantillonnage flexible. Le client peut faire une demande selon ses besoins spécifiques.
- Échantillonnage efficace. La réponse renvoie uniquement les données demandées.
- Développement plus rapide. De nombreux changements sur le client peuvent se produire sans avoir à changer quoi que ce soit côté serveur. Par exemple, sur la base de notre exemple, vous pouvez facilement afficher une vue différente du panier pour le Web mobile.
- Analyses utiles. Étant donné que le client doit indiquer les champs explicitement dans la demande, le serveur sait exactement quels champs sont vraiment nécessaires. Et ce sont des informations importantes pour la politique de dépréciation.
- Fonctionne au-dessus de n'importe quelle source de données et transport. Il est important que GraphQL vous permette de travailler au-dessus de n'importe quelle source de données et de tout transport. Dans ce cas, HTTP n'est pas une panacée, GraphQL peut également fonctionner via WebSocket, et nous aborderons ce point un peu plus tard.
Aujourd'hui, un serveur GraphQL peut être créé dans presque toutes les langues. La version la plus complète du serveur
GraphQL est
GraphQL.js pour la plateforme Node. Dans la communauté Java, l'implémentation de référence est
GraphQL Java .
Créer l'API GraphQL
Voyons comment créer un serveur GraphQL sur un exemple de vie concret.
Prenons une version simplifiée d'une boutique en ligne basée sur une architecture de microservice à deux composants:
- Service de chariot offrant du travail avec un panier personnalisé. Stocke les données dans une base de données relationnelle et utilise SQL pour accéder aux données. Service très simple, sans trop de magie :)
- Service produit donnant accès au catalogue de produits, à partir duquel, en fait, le panier est rempli. Fournit une API HTTP pour accéder aux données produit.
Les deux services sont implémentés en plus du Spring Boot classique et contiennent déjà toute la logique de base.
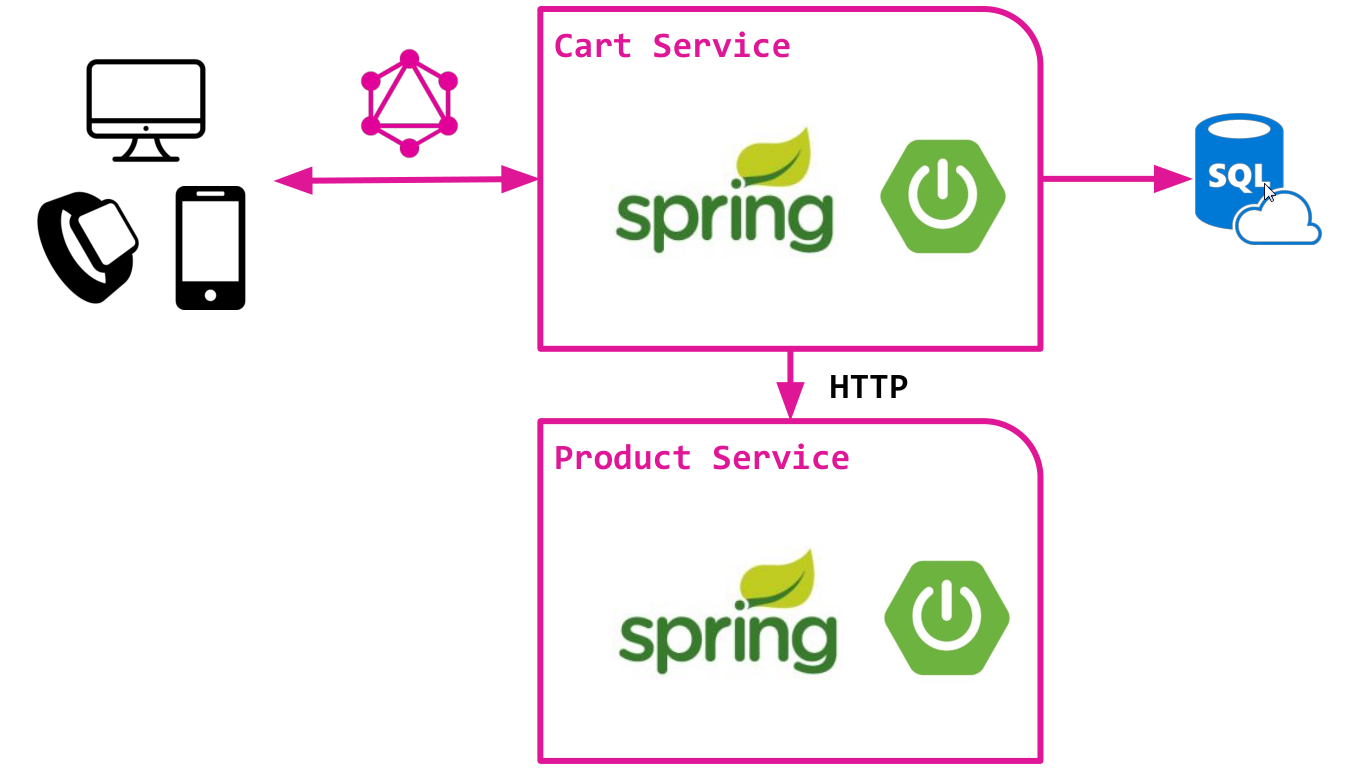
Nous avons l'intention de créer l'API GraphQL en plus du service Cart. Cette API est conçue pour fournir un accès aux données du panier et aux produits qui y sont ajoutés.
Première version
L'implémentation de référence GraphQL pour l'écosystème Java, que nous avons mentionnée précédemment - GraphQL Java, nous aidera.
Ajoutez quelques dépendances à
pom.xml: <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-java</artifactId> <version>9.3</version> </dependency> <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-java-tools</artifactId> <version>5.2.4</version> </dependency> <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-spring-boot-starter</artifactId> <version>5.0.2</version> </dependency> <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphiql-spring-boot-starter</artifactId> <version>5.0.2</version> </dependency>
En plus du
graphql-java mentionné
graphql-java nous aurons besoin d'une bibliothèque d'
graphql-java-tools, ainsi que de «démarreurs» Spring Boot pour GraphQL, ce qui simplifiera considérablement les premières étapes de création d'un serveur GraphQL:
- graphql-spring-boot-starter fournit un mécanisme pour connecter rapidement GraphQL Java à Spring Boot;
- graphiql-spring-boot-starter ajoute une console Web interactive Graph i QL pour exécuter les requêtes GraphQL.
La prochaine étape importante consiste à déterminer le schéma de service graphQL, notre graphique. Les nœuds de ce graphique sont décrits à l'aide de
types et les bords à l'aide de
champs . Une définition de graphique vide ressemble à ceci:
schema { }
Dans ce schéma même, comme vous vous en souvenez, il existe des «points d'entrée» ou des requêtes de niveau supérieur. Ils sont définis via le champ de
requête du schéma. Appelez notre type pour les
points d' entrée
EntryPoints :
schema { query: EntryPoints }
Nous y définissons une recherche de panier par identifiant comme premier point d'entrée:
type EntryPoints { cart(id: Long!): Cart }
Cart n'est rien de plus qu'un
champ en termes GraphQL.
id est un paramètre de ce champ avec le type scalaire
Long . Point d'exclamation
! après avoir spécifié le type signifie que le paramètre est obligatoire.
Il est temps d'identifier et de taper
Cart :
type Cart { id: Long! items: [CartItem!]! subTotal: BigDecimal! }
En plus de l'
id standard, le panier comprend ses éléments d'articles et le montant pour tous les produits de sous-
subTotal . Notez que les
éléments sont définis comme une liste, comme indiqué par les crochets
[] . Les éléments de cette liste sont des types
CartItem . La présence d'un point d'exclamation après le nom du type de champ
! indique que le champ est obligatoire. Cela signifie que le serveur accepte de renvoyer une valeur non vide pour ce champ, le cas échéant.
Reste à regarder la définition du type
CartItem , qui comprend un lien vers le produit (
productId ), combien de fois il est ajouté au panier (
quantity ) et le montant du produit, calculé sur le nombre (
total ):
type CartItem { productId: String! quantity: Int! total: BigDecimal! }
Tout est simple ici - tous les champs de types scalaires sont obligatoires.
Ce schéma n'a pas été choisi par hasard. Le service Cart a déjà défini le panier Cart et ses éléments
CartItem avec exactement les mêmes noms de champs et types que dans le schéma GraphQL. Le modèle de chariot utilise la bibliothèque Lombok pour les getters / setters à génération automatique, les constructeurs et d'autres méthodes. JPA est utilisé pour la persistance dans la base de données.
Classe de
Cart :
import lombok.Data; import javax.persistence.*; import java.math.BigDecimal; import java.util.ArrayList; import java.util.List; @Entity @Data public class Cart { @Id @GeneratedValue private Long id; @ElementCollection(fetch = FetchType.EAGER) private List<CartItem> items = new ArrayList<>(); public BigDecimal getSubTotal() { return getItems().stream() .map(Item::getTotal) .reduce(BigDecimal.ZERO, BigDecimal::add); } }
CartItem Class:
import lombok.AllArgsConstructor; import lombok.Data; import javax.persistence.Column; import javax.persistence.Embeddable; import java.math.BigDecimal; @Embeddable @Data @AllArgsConstructor public class CartItem { @Column(nullable = false) private String productId; @Column(nullable = false) private int quantity; @Column(nullable = false) private BigDecimal total; }
Ainsi, le panier (
Cart ) et les éléments du panier (
CartItem ) sont décrits à la fois dans le diagramme GraphQL et dans le code, et sont «compatibles» entre eux en fonction de l'ensemble des champs et de leurs types. Mais cela ne suffit toujours pas pour que notre service fonctionne.
Nous devons clarifier exactement comment le point d'entrée "
cart(id: Long!): Cart " fonctionnera. Pour ce faire, créez une configuration Java extrêmement simple pour Spring avec un bean de type GraphQLQueryResolver. GraphQLQueryResolver décrit simplement les "points d'entrée" dans le schéma. Nous définissons une méthode avec un nom identique au champ au point d'entrée (
cart ), la
cartService compatible par type de paramètres et utilisons
cartService pour trouver le même panier par identifiant:
@Bean public GraphQLQueryResolver queryResolver() { return new GraphQLQueryResolver () { public Cart cart(Long id) { return cartService.findCart(id); } } }
Ces changements nous suffisent pour obtenir une application qui fonctionne. Après avoir redémarré le service Cart dans la console GraphiQL, la requête suivante commencera à s'exécuter avec succès:
{ cart(id: 1) { items { productId quantity total } subTotal } }
Remarque
- Nous utilisons les types scalaires
Long et String comme identifiants uniques pour le panier et le produit. GraphQL a un type spécial à ces fins - ID . Sémantiquement, c'est un meilleur choix pour une véritable API. Les valeurs de type ID peuvent être utilisées comme clé pour la mise en cache.
- A ce stade du développement de notre application, les modèles de domaine interne et externe sont totalement identiques. Nous parlons des
CartItem Cart et CartItem et de leur utilisation directe dans les résolveurs GraphQL. Dans les applications de combat, il est recommandé de séparer ces modèles. Pour les résolveurs GraphQL, un modèle distinct de la zone de sujet interne doit exister.
Rendre l'API utile
Nous avons donc obtenu le premier résultat, et c'est merveilleux. Mais maintenant, notre API est trop primitive. Par exemple, jusqu'à présent, il n'y a aucun moyen de demander des données utiles sur un produit, telles que son nom, son prix, son article, ses photos, etc. Au lieu de cela, il n'y a qu'un
productId . Rendons l'API vraiment utile et ajoutons une prise en charge complète du concept de produit. Voici à quoi ressemble sa définition dans le diagramme:
type Product { id: String! title: String! price: BigDecimal! description: String sku: String! images: [String!]! }
Ajoutez le champ requis à
CartItem et
productId champ productId comme obsolète:
type Item { quantity: Int! product: Product! productId: String! @deprecated(reason: "don't use it!") total: BigDecimal! }
Nous avons compris le schéma. Et maintenant, il est temps de décrire le fonctionnement de la sélection pour le domaine de
product . Nous nous
CartItem auparavant sur les getters des
CartItem Cart et
CartItem , ce qui permettait à GraphQL Java de lier automatiquement les valeurs. Mais ici, il convient de rappeler que seule la propriété du
product dans la classe
CartItem pas:
@Embeddable @Data @AllArgsConstructor public class CartItem { @Column(nullable = false) private String productId; @Column(nullable = false) private int quantity; @Column(nullable = false) private BigDecimal total; }
Nous avons le choix:
- Ajoutez la propriété du produit à CartItem et "apprenez" comment recevoir les données du produit;
- Déterminez comment obtenir le produit sans modifier la classe CartItem .
La deuxième voie est préférable, car le modèle de description du domaine interne (classe
CartItem ) dans ce cas ne sera pas couvert avec les détails de l'implémentation de l'API Graph
i QL.
Pour atteindre cet objectif, l'interface du marqueur GraphQLResolver vous aidera. En l'implémentant, vous pouvez déterminer (ou remplacer) comment obtenir les valeurs de champ pour le type
T Voici à quoi ressemble le bean correspondant dans la configuration Spring:
@Bean public GraphQLResolver<CartItem> cartItemResolver() { return new GraphQLResolver<CartItem>() { public Product product(CartItem item) { return http.getForObject("http://localhost:9090/products/{id}", Product.class, item.getProductId()); } }; }
Le nom de la méthode du
product n'a pas été choisi par hasard. GraphQL Java recherche des méthodes de téléchargement de données par nom de champ, et nous venons de définir un chargeur pour le champ
product ! Un objet de type
CartItem passé en paramètre définit le contexte dans lequel le produit est sélectionné. Vient ensuite une question de technologie. En utilisant un client
http tel que
RestTemplate nous faisons une requête GET au service Product et convertissons le résultat en
Product , qui ressemble à ceci:
@Data public class Product { private String id; private String title; private BigDecimal price; private String description; private String sku; private List<String> images; }
Ces changements devraient être suffisants pour mettre en œuvre un échantillon plus intéressant, qui inclut la véritable relation entre le panier et les produits qui y sont ajoutés.
Après avoir redémarré l'application, vous pouvez essayer une nouvelle requête dans la console Graph
i QL.
{ cart(id: 1) { items { product { title price sku images } quantity total } subTotal } }
Et voici le résultat de l'exécution de la requête:

Bien que
productId été marqué comme
@deprecated , les requêtes indiquant ce champ continueront de fonctionner. Mais la console Graph
i QL n'offrira pas de saisie semi-automatique pour ces champs et mettra en évidence leur utilisation d'une manière spéciale:

Il est temps de montrer l'Explorateur de documents, qui fait partie de la console Graph
i QL, qui est construit sur la base du schéma GraphQL et affiche des informations sur tous les types définis. Voici à quoi ressemble Document Explorer pour le type
CartItem :

Mais revenons à l'exemple. Afin d'atteindre les mêmes fonctionnalités que dans la toute première démo, il n'y a toujours pas assez de limite pour le nombre d'images retournées. En effet, pour un panier, par exemple, vous n'avez besoin que d'une image pour chaque produit:
images(limit: 1)
Pour ce faire, modifiez le schéma et ajoutez un nouveau paramètre pour le champ
images au type de
produit :
type Product { id: ID! title: String! price: BigDecimal! description: String sku: String! images(limit: Int = 0): [String!]! }
Et dans le code de l'application, nous l'utiliserons à nouveau GraphQLResolver, mais cette fois par type Product: @Bean public GraphQLResolver<Product> productResolver() { return new GraphQLResolver<Product>() { public List<String> images(Product product, int limit) { List<String> images = product.getImages(); int normalizedLimit = limit > 0 ? limit : images.size(); return images.subList(0, Math.min(normalizedLimit, images.size())); } }; }
Encore une fois, j'attire votre attention sur le fait que le nom de la méthode n'est pas accidentel: il coïncide avec le nom du champ images. L'objet contextuel Productdonne accès aux images et limitest un paramètre du champ lui-même.Si le client n'a rien spécifié comme valeur pour limit, alors notre service retournera toutes les images du produit. Si le client a spécifié une valeur spécifique, le service retournera exactement autant (mais pas plus qu'il n'y en a dans le produit).Nous compilons le projet et attendons le redémarrage du serveur. En redémarrant le circuit dans la console et en exécutant la requête, nous voyons qu'une requête à part entière fonctionne vraiment. { cart(id: 1) { items { product { title price sku images(limit: 1) } quantity total } subTotal } }
D'accord, tout cela est très cool. En peu de temps, nous avons non seulement appris ce qu'est GraphQL, mais également transféré un système de microservice simple pour prendre en charge une telle API. Et peu importe pour nous d'où proviennent les données: les API SQL et HTTP s'intègrent bien sous un même toit.Approche Code-First et GraphQL SPQR
Vous avez peut-être remarqué que pendant le processus de développement, il y a eu quelques inconvénients, à savoir la nécessité de garder constamment le schéma et le code GraphQL synchronisés. Les changements de type devaient toujours être effectués à deux endroits. Dans de nombreux cas, il est plus pratique d'utiliser l'approche du code en premier. Son essence est que le schéma de GraphQL est généré automatiquement à partir du code. Dans ce cas, vous n'avez pas besoin de maintenir le circuit séparément. Je vais maintenant vous montrer à quoi ça ressemble.Seules les fonctionnalités de base de GraphQL Java ne nous suffisent pas, nous aurons également besoin de la bibliothèque GraphQL SPQR. La bonne nouvelle est que GraphQL SPQR est un module complémentaire pour GraphQL Java, et non une implémentation alternative du serveur GraphQL en Java.Ajoutez la dépendance souhaitée à pom.xml: <dependency> <groupId>io.leangen.graphql</groupId> <artifactId>spqr</artifactId> <version>0.9.8</version> </dependency>
Voici le code qui implémente la même fonctionnalité basée sur GraphQL SPQR pour le panier: @Component public class CartGraph { private final CartService cartService; @Autowired public CartGraph(CartService cartService) { this.cartService = cartService; } @GraphQLQuery(name = "cart") public Cart cart(@GraphQLArgument(name = "id") Long id) { return cartService.findCart(id); } }
Et pour le produit: @Component public class ProductGraph { private final RestTemplate http; @Autowired public ProductGraph(RestTemplate http) { this.http = http; } @GraphQLQuery(name = "product") public Product product(@GraphQLContext CartItem cartItem) { return http.getForObject( "http://localhost:9090/products/{id}", Product.class, cartItem.getProductId() ); } @GraphQLQuery(name = "images") public List<String> images(@GraphQLContext Product product, @GraphQLArgument(name = "limit", defaultValue = "0") int limit) { List<String> images = product.getImages(); int normalizedLimit = limit > 0 ? limit : images.size(); return images.subList(0, Math.min(normalizedLimit, images.size())); } }
L'annotation @GraphQLQuery est utilisée pour marquer les méthodes du chargeur de champ. L'annotation @GraphQLContextdéfinit le type de sélection pour le champ. Et l'annotation @GraphQLArgumentmarque clairement les paramètres d'argument. Tous ces éléments font partie d'un mécanisme qui aide GraphQL SPQR à générer automatiquement un schéma. Maintenant, si vous supprimez l'ancienne configuration et le schéma Java, redémarrez le service Cart en utilisant les nouvelles puces de GraphQL SPQR, vous pouvez vous assurer que tout fonctionne de la même manière qu'auparavant.Nous résolvons le problème de N + 1
Il est temps de regarder b le détail lshih comment la mise en œuvre de la demande tout « sous le capot ». Nous avons rapidement créé l'API GraphQL, mais fonctionne-t-il efficacement?Prenons l'exemple suivant: L' obtention du panier
obtention du panier cartse produit dans une requête SQL vers la base de données. Les données y itemssont subtotalrenvoyées, car les éléments du panier sont chargés avec toute la collection, en fonction de la stratégie JPA désireuse: @Data public class Cart { @ElementCollection(fetch = FetchType.EAGER) private List<Item> items = new ArrayList<>(); ... }
 Lorsqu'il s'agit de télécharger des données sur des produits, les demandes de service Produit seront exécutées exactement autant que dans ce panier de produits. S'il y a trois produits différents dans le panier, nous recevrons alors trois demandes à l'API HTTP du service produit, et s'il y en a dix, alors le même service devra répondre à dix de ces demandes.
Lorsqu'il s'agit de télécharger des données sur des produits, les demandes de service Produit seront exécutées exactement autant que dans ce panier de produits. S'il y a trois produits différents dans le panier, nous recevrons alors trois demandes à l'API HTTP du service produit, et s'il y en a dix, alors le même service devra répondre à dix de ces demandes. Voici la communication entre le service Cart et le service Produit dans Charles Proxy: En
Voici la communication entre le service Cart et le service Produit dans Charles Proxy: En conséquence, nous revenons au problème classique N + 1. Exactement celui dont ils ont tant cherché à sortir au tout début du rapport. Sans aucun doute, nous avons progressé, car exactement une demande est exécutée entre le client final et notre système. Mais au sein de l'écosystème de serveurs, les performances doivent clairement être améliorées.Je veux résoudre ce problème en obtenant tous les bons produits en une seule demande. Heureusement, le service Produit prend déjà en charge cette fonctionnalité via un paramètre
conséquence, nous revenons au problème classique N + 1. Exactement celui dont ils ont tant cherché à sortir au tout début du rapport. Sans aucun doute, nous avons progressé, car exactement une demande est exécutée entre le client final et notre système. Mais au sein de l'écosystème de serveurs, les performances doivent clairement être améliorées.Je veux résoudre ce problème en obtenant tous les bons produits en une seule demande. Heureusement, le service Produit prend déjà en charge cette fonctionnalité via un paramètre idsdans la ressource de collecte: GET /products?ids=:id1,:id2,...,:idn
Voyons comment vous pouvez modifier l'exemple de code de méthode pour le champ produit . Version précédente: @GraphQLQuery(name = "product") public Product product(@GraphQLContext CartItem cartItem) { return http.getForObject( "http://localhost:9090/products/{id}", Product.class, cartItem.getProductId() ); }
Remplacez-le par un autre plus efficace: @GraphQLQuery(name = "product") @Batched public List<Product> products(@GraphQLContext List<Item> items) { String productIds = items.stream() .map(Item::getProductId) .collect(Collectors.joining(",")); return http.getForObject( "http://localhost:9090/products?ids={ids}", Products.class, productIds ).getProducts(); }
Nous avons fait exactement trois choses:- marqué la méthode du chargeur de démarrage avec une annotation @Batched , indiquant clairement à GraphQL SPQR que le chargement doit avoir lieu avec un lot;
- changé le type de retour et le paramètre de contexte en liste, car travailler avec le lot suppose que plusieurs objets sont acceptés et retournés;
- changé le corps de la méthode, en mettant en œuvre une sélection de tous les produits nécessaires à la fois.
Ces changements suffisent à résoudre notre problème N + 1. La fenêtre de l'application Charles Proxy affiche désormais une demande au service Produit, qui renvoie trois produits à la fois:
Échantillons de terrain efficaces
Nous avons résolu le problème principal, mais vous pouvez faire la sélection encore plus rapidement! Désormais, le service Produit renvoie toutes les données, quels que soient les besoins du client final. Nous pourrions améliorer la requête et renvoyer uniquement les champs demandés. Par exemple, si le client final n'a pas demandé l'image, pourquoi devons-nous les transférer au service Cart?C'est formidable que l'API HTTP du service Produit prenne déjà en charge cette fonctionnalité via le paramètre include pour la même ressource de collecte: GET /products?ids=...?include=:field1,:field2,...,:fieldN
Pour la méthode du chargeur de démarrage, ajoutez un paramètre de type Set avec annotation @GraphQLEnvironment. GraphQL SPQR comprend que le code dans ce cas «demande» une liste de noms de champs qui sont demandés pour le produit, et les remplit automatiquement: @GraphQLQuery(name = "product") @Batched public List<Product> products(@GraphQLContext List<Item> items, @GraphQLEnvironment Set<String> fields) { String productIds = items.stream() .map(Item::getProductId) .collect(Collectors.joining(",")); return http.getForObject( "http://localhost:9090/products?ids={ids}&include={fields}", Products.class, productIds, String.join(",", fields) ).getProducts(); }
Maintenant, notre échantillon est vraiment efficace, dépourvu du problème N + 1 et utilise uniquement les données nécessaires:
Demandes "lourdes"
Imaginez travailler avec un graphique utilisateur dans un réseau social classique tel que Facebook. Si un tel système fournit l'API GraphQL, rien n'empêche le client d'envoyer une demande de la nature suivante: { user(name: "Vova Unicorn") { friends { name friends { name friends { name friends { name ... } } } } } }
Au niveau d'imbrication 5-6, la mise en œuvre complète d'une telle demande conduira à une sélection de tous les utilisateurs dans le monde. Le serveur ne sera certainement pas en mesure de faire face à une telle tâche en une seule fois et très probablement il "tombera" simplement.Il existe un certain nombre de mesures qui doivent être prises afin de vous protéger de telles situations:- Limiter la profondeur de demande. En d'autres termes, les clients ne devraient pas être autorisés à demander des données d'imbrication arbitraire.
- Limitez la complexité de la demande. En affectant un poids à chaque champ et en calculant la somme des poids de tous les champs de la demande, vous pouvez accepter ou rejeter ces demandes sur le serveur.
Par exemple, considérez la requête suivante: { cart(id: 1) { items { product { title } quantity } subTotal } }
De toute évidence, la profondeur d'une telle demande est de 4, car le chemin le plus long se trouve à l'intérieur cart -> items -> product -> title.Si nous supposons que le poids de chaque champ est de 1, alors en tenant compte de 7 champs dans la requête, sa complexité est également de 7.Dans GraphQL Java, la superposition des contrôles est obtenue en indiquant une instrumentation supplémentaire lors de la création de l'objet GraphQL: GraphQL.newGraphQL(schema) .instrumentation(new ChainedInstrumentation(Arrays.asList( new MaxQueryComplexityInstrumentation(20), new MaxQueryDepthInstrumentation(3) ))) .build();
L'instrumentation MaxQueryDepthInstrumentationvérifie la profondeur de la requête et ne permet pas de lancer des requêtes trop "profondes" (dans ce cas, avec une profondeur supérieure à 3).L'instrumentation MaxQueryComplexityInstrumentationavant d'exécuter une requête compte et vérifie sa complexité. Si ce nombre dépasse la valeur spécifiée (20), une telle demande est rejetée. Vous pouvez redéfinir le poids de chaque champ, car certains d'entre eux deviennent évidemment "plus durs" que d'autres. Par exemple, le champ produit peut être affecté de la complexité 10 via l'annotation @GraphQLComplexity,prise en charge dans GraphQL SPQR: @GraphQLQuery(name = "product") @GraphQLComplexity("10") public List<Product> products(...)
Voici un exemple de vérification de profondeur lorsqu'elle dépasse clairement la valeur spécifiée: Au fait, le mécanisme d'instrumentation ne se limite pas à imposer des restrictions. Il peut également être utilisé à d'autres fins, telles que la journalisation ou le traçage.Nous avons examiné les mesures de «protection» spécifiques à GraphQL. Cependant, il existe un certain nombre d'astuces qui méritent une attention particulière quel que soit le type d'API:
Au fait, le mécanisme d'instrumentation ne se limite pas à imposer des restrictions. Il peut également être utilisé à d'autres fins, telles que la journalisation ou le traçage.Nous avons examiné les mesures de «protection» spécifiques à GraphQL. Cependant, il existe un certain nombre d'astuces qui méritent une attention particulière quel que soit le type d'API:- étranglement / limitation de débit - limiter le nombre de demandes par unité de temps
- délais d'expiration - délai pour les opérations avec d'autres services, bases de données, etc.;
- pagination - support de pagination.
Mutation de données
Jusqu'à présent, nous avons envisagé un échantillonnage purement de données. Mais GraphQL vous permet d'organiser organiquement non seulement la réception des données, mais aussi leur modification. Il existe un mécanisme pour cela mutation: schema { query: EntryPoints, mutation: Mutations }
Par exemple, l'ajout d'un produit à un panier peut être organisé par la mutation suivante: type Mutations { addProductToCart(cartId: Long!, productId: String!, count: Int = 1): Cart }
Cela revient à définir un champ, car une mutation a également des paramètres et une valeur de retour.L'implémentation d'une mutation dans le code serveur à l'aide de GraphQL SPQR est la suivante: @GraphQLMutation(name = "addProductToCart") public Cart addProductToCart( @GraphQLArgument(name = "cartId") Long cartId, @GraphQLArgument(name = "productId") String productId, @GraphQLArgument(name = "quantity", defaultValue = "1") int quantity) { return cartService.addProductToCart(cartId, productId, quantity); }
Bien sûr, la plupart du travail utile se fait en interne cartService. Et la tâche de cette méthode intercouche est de l'associer à l'API. Comme dans le cas de l'échantillonnage de données, grâce aux annotations, il est @GraphQL*très facile de comprendre quel schéma GraphQL est généré à partir de cette définition de méthode.Dans la console GraphQL, vous pouvez désormais effectuer une demande de mutation pour ajouter un produit spécifique à notre panier au montant de 2: mutation { addProductToCart( cartId: 1, productId: "59eb83c0040fa80b29938e3f", quantity: 2) { items { product { title } quantity total } subTotal } }
La mutation ayant une valeur de retour, il est possible de lui demander des champs selon les mêmes règles que pour les échantillons ordinaires.Plusieurs équipes de développement WIX utilisent activement GraphQL avec Scala et la bibliothèque Sangria, l'implémentation principale de GraphQL dans ce langage.L'une des techniques utiles utilisées dans WIX est la prise en charge des requêtes GraphQL lors du rendu HTML. Nous faisons cela afin de générer du JSON directement dans le code de la page. Voici un exemple de remplissage d'un modèle HTML: // Pre-rendered <html> <script data-embedded-graphiql> { product(productId: $productId) title description price ... } } </script> </html>
Et voici la sortie: // Rendered <html> <script> window.DATA = { product: { title: 'GraphQL Sticker', description: 'High quality sticker', price: '$2' ... } } </script> </html>
Une telle combinaison de rendu HTML et de serveur GraphQL nous permet de réutiliser notre API au maximum et de ne pas créer une couche supplémentaire de contrôleurs. De plus, cette technique s'avère souvent avantageuse en termes de performances, car après le chargement de la page, l'application JavaScript n'a pas besoin d'aller au backend pour les premières données nécessaires - elle est déjà sur la page.Inconvénients de GraphQL
Aujourd'hui, GraphQL utilise un grand nombre d'entreprises, y compris des géants tels que GitHub, Yelp, Facebook et bien d'autres. Et si vous décidez de rejoindre leur numéro, vous devez connaître non seulement les avantages de GraphQL, mais aussi ses inconvénients, et ils sont nombreux:- -, GraphQL . GraphQL , HTTP API. Cache-Control Last-Modified HTTP GraphQL API. , proxy gateways (Varnish, Fastly ). , GraphQL , , .
- GraphQL — . , API, , .
- GraphQL . .
- . GraphQL — . JSON XML, , , GraphQL, .
- GraphQL . , HTTP PUT POST -. , . GraphQL . .
- . , -: «delete» «kill», «annihilate» «terminate», . GraphQL API . HTTP DELETE .
- Joker 2016 . GraphQL . API- , , , HATEOAS, , « REST». , , GraphQL .
Il convient également de se rappeler que si vous n'avez pas réussi à bien développer l'API HTTP, vous ne pourrez probablement pas développer l'API GraphQL. Après tout, qu'est-ce qui est le plus important dans le développement d'une API? Séparez le modèle de domaine interne du modèle d'API externe. Créez une API basée sur des scénarios d'utilisation et non sur le périphérique interne de l'application. Ouvrez uniquement les informations minimales nécessaires, et pas toutes de suite. Choisissez les bons noms. Décrivez le graphique correctement. Il existe un graphique de ressources dans l'API HTTP et un graphique de champ dans l'API GraphQL. Dans les deux cas, ce graphique doit être fait qualitativement.Il existe des alternatives dans le monde de l'API HTTP, et vous n'avez pas toujours besoin d'utiliser GraphQL lorsque vous avez besoin de sélections complexes. Par exemple, il existe la norme OData, qui prend en charge les sélections partielles et étendues, comme GraphQL, et fonctionne au-dessus de HTTP. Il existe une API JSON standard qui fonctionne avec JSON et prend en charge l'hypermédia et les capacités de récupération complexes. Il y a aussi LinkRest, dont vous pouvez en savoir plus sur le https://youtu.be/EsldBtrb1Qc "> rapport d'Andrus Adamchik sur Joker 2017.Pour ceux qui veulent essayer GraphQL, je recommande fortement de lire des articles comparatifs d'ingénieurs qui connaissent profondément REST et GraphQL d'un point de vue pratique et philosophique:Enfin sur les abonnements et reporter
GraphQL a un avantage intéressant par rapport aux API standard. Dans GraphQL, les cas d'utilisation synchrones et asynchrones peuvent se trouver sous le même toit.Nous avons envisagé de recevoir des données par votre intermédiaire query, de modifier le statut du serveur mutation, mais il y a une autre qualité. Par exemple, la possibilité d'organiser des abonnements subscriptions.Imaginez qu'un client souhaite recevoir des notifications sur l'ajout d'un produit au panier de manière asynchrone. Grâce à l'API GraphQL, cela peut être fait sur la base d'un tel schéma: schema { query: Queries, mutation: Mutations, subscription: Subscriptions } type Subscriptions { productAdded(cartId: String!): Cart }
Le client peut souscrire via la demande suivante: subscription { productAdded(cart: 1) { items { product ... } subTotal } }
Désormais, chaque fois qu'un produit est ajouté au panier 1, le serveur enverra à chaque client abonné un message sur WebSocket avec les données demandées sur le panier. Encore une fois, en poursuivant la politique GraphQL, seules les données demandées par le client lors de la souscription viendront: { "data": { "productAdded": { "items": [ { "product": …, "subTotal": … }, { "product": …, "subTotal": … }, { "product": …, "subTotal": … }, { "product": …, "subTotal": … } ], "subTotal": 289.33 } } }
Le client peut désormais redessiner le panier, pas nécessairement redessiner la page entière.Ceci est pratique car l'API synchrone (HTTP) et l'API asynchrone (WebSocket) peuvent être décrites via GraphQL.Un autre exemple d'utilisation de la communication asynchrone est le mécanisme de report . L'idée principale est que le client choisisse les données qu'il souhaite recevoir immédiatement (de manière synchrone) et celles qu'il est prêt à recevoir plus tard (de manière asynchrone). Par exemple, pour une telle demande: query { feedStories { author { name } message comments @defer { author { name } message } } }
Le serveur retournera d'abord l'auteur et un message pour chaque histoire: { "data": { "feedStories": [ { "author": …, "message": … }, { "author": …, "message": … } ] } }
Après cela, le serveur, après avoir reçu des données sur les commentaires, les livrera au client via WebSocket de manière asynchrone, indiquant dans le chemin pour lequel les commentaires d'historique sont maintenant prêts: { "path": [ "feedStories", 0, "comments" ], "data": [ { "author": …, "message": … } ] }
Exemple de source
Le code utilisé pour préparer ce rapport est disponible sur GitHub .Plus récemment, nous avons annoncé JPoint 2019 , qui se tiendra du 5 au 6 avril 2019. Vous pouvez en savoir plus sur ce que vous pouvez attendre de la conférence de notre hub . Jusqu'au 1er décembre, les billets Early Bird sont toujours disponibles au prix le plus bas.