Création de routage client / recherche sémantique et mise en cluster de corpus externes arbitraires chez Profi.ru
TLDR
Ceci est un très court résumé (ou un teaser) sur ce que nous avons réussi à faire en environ 2 mois dans le département Profi.ru DS (j'étais là un peu plus longtemps, mais l'intégration de moi-même et de mon équipe était une chose distincte à être fait au début).
Objectifs projetés
- Comprendre l'entrée / l'intention du client et acheminer les clients en conséquence (nous avons finalement opté pour un classificateur agnostique de la qualité d'entrée, bien que nous ayons également pris en compte les modèles de niveau de caractères et les modèles de langage.
- Trouvez des services totalement nouveaux et des synonymes pour les services existants;
- Comme sous-objectif de (2) - apprendre à construire des grappes appropriées sur des corpus externes arbitraires;
Objectifs atteints
Évidemment, certains de ces résultats ont été obtenus non seulement par notre équipe, mais par plusieurs équipes (c'est-à-dire que nous n'avons évidemment pas fait la partie de grattage pour les corpus de domaine et l'annotation manuelle, bien que je pense que le grattage peut également être résolu par notre équipe - vous avez juste besoin assez de procurations + probablement une certaine expérience avec le sélénium).
Objectifs commerciaux:
- ~
88+% (vs ~ 60% avec la recherche élastique) de précision sur le routage client / classification d'intention (~ 5k classes); - La recherche est indépendante de la qualité de la saisie (erreurs d'impression / saisie partielle);
- Le classificateur généralise, la structure morphologique de la langue est exploitée;
- Le classificateur bat sévèrement la recherche élastique sur divers repères (voir ci-dessous);
- Pour être prudent - au moins
1,000 nouveaux services ont été trouvés + au moins 15,000 synonymes (contre l'état actuel de 5,000 + 30,000 ). Je m'attends à ce que ce chiffre double, voire triple;
La dernière puce est une estimation approximative, mais conservatrice.
Des tests AB suivront également. Mais je suis confiant dans ces résultats.
Objectifs "scientifiques":
- Nous avons comparé de manière approfondie de nombreuses techniques modernes d'incorporation de phrases en utilisant une tâche de classification en aval + KNN avec une base de données de synonymes de service;
- Nous avons réussi à battre la recherche élastique faiblement supervisée (essentiellement leur classifieur est un sac de ngrammes) sur cette référence (voir détails ci-dessous) en utilisant des méthodes NON SUPERVISÉES ;
- Nous avons développé une nouvelle façon de construire des modèles de PNL appliqués (un bi-LSTM + un sac de plongements vanille, essentiellement un texte rapide rencontre RNN) - cela prend en considération la morphologie de la langue russe et se généralise bien;
- Nous avons démontré que notre technique finale d'intégration (une couche de goulot d'étranglement du meilleur classificateur) combinée à des algorithmes non supervisés de pointe (UMAP + HDBSCAN) peut produire des amas stellaires;
- Nous avons démontré en pratique la possibilité, la faisabilité et l'utilisabilité de:
- Distillation des connaissances;
- Augmentations pour les données texte (sic!);
- La formation de classificateurs basés sur du texte avec des augmentations dynamiques a réduit considérablement le temps de convergence (10x) par rapport à la génération de jeux de données statiques plus grands (c'est-à-dire que le CNN apprend à généraliser l'erreur affichée avec des phrases considérablement moins augmentées);
Structure globale du projet
Cela n'inclut pas le classificateur final.
Finalement, nous avons abandonné les faux modèles de perte de RNN et de triplet au profit du goulot d'étranglement du classificateur.

Qu'est-ce qui fonctionne en PNL maintenant?
Une vue à vol d'oiseau:

Vous savez peut-être aussi que la PNL connaît peut-être le moment Imagenet maintenant .
Hack UMAP à grande échelle
Lors de la création de clusters, nous sommes tombés sur un moyen / hack d'appliquer essentiellement UMAP à des ensembles de données de taille 100m + point (ou peut-être même 1 milliard). Construisez essentiellement un graphique KNN avec FAISS , puis réécrivez simplement la boucle UMAP principale dans PyTorch à l'aide de votre GPU. Nous n'en avions pas besoin et avons abandonné le concept (nous n'avions que 10 à 15 millions de points après tout), mais veuillez suivre ce fil pour plus de détails.
Ce qui fonctionne le mieux
- Pour une classification supervisée, le texte rapide rencontre le RNN (bi-LSTM) + un ensemble de n-grammes soigneusement choisi;
- Implémentation - python ordinaire pour n-grammes + couche de sac PyTorch Embedding;
- Pour le clustering - la couche de goulot d'étranglement de ce modèle + UMAP + HDBSCAN;
Meilleurs benchmarks classificateurs
Ensemble de développement annoté manuellement
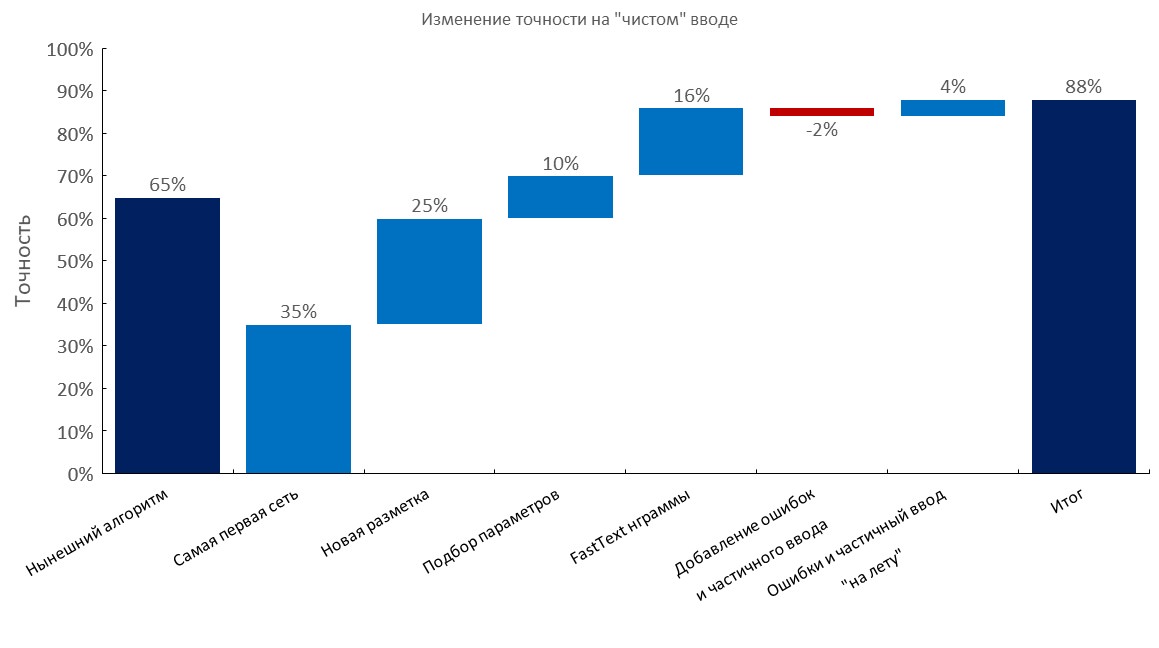
De gauche à droite:
(Précision Top1)
- Algorithme actuel (recherche élastique);
- First RNN;
- Nouvelle annotation;
- Tuning
- Couche de sac d'intégration de texte rapide;
- Ajout de fautes de frappe et entrée partielle;
- Génération dynamique d'erreurs et saisie partielle ( temps de formation réduit 10x );
- Score final;
Ensemble de développement annoté manuellement + 1 à 3 erreurs par requête

De gauche à droite:
(Précision Top1)
- Algorithme actuel (recherche élastique);
- Couche de sac d'intégration de texte rapide;
- Ajout de fautes de frappe et entrée partielle;
- Génération dynamique d'erreurs et saisie partielle;
- Score final;
Ensemble de développement annoté manuellement + entrée partielle
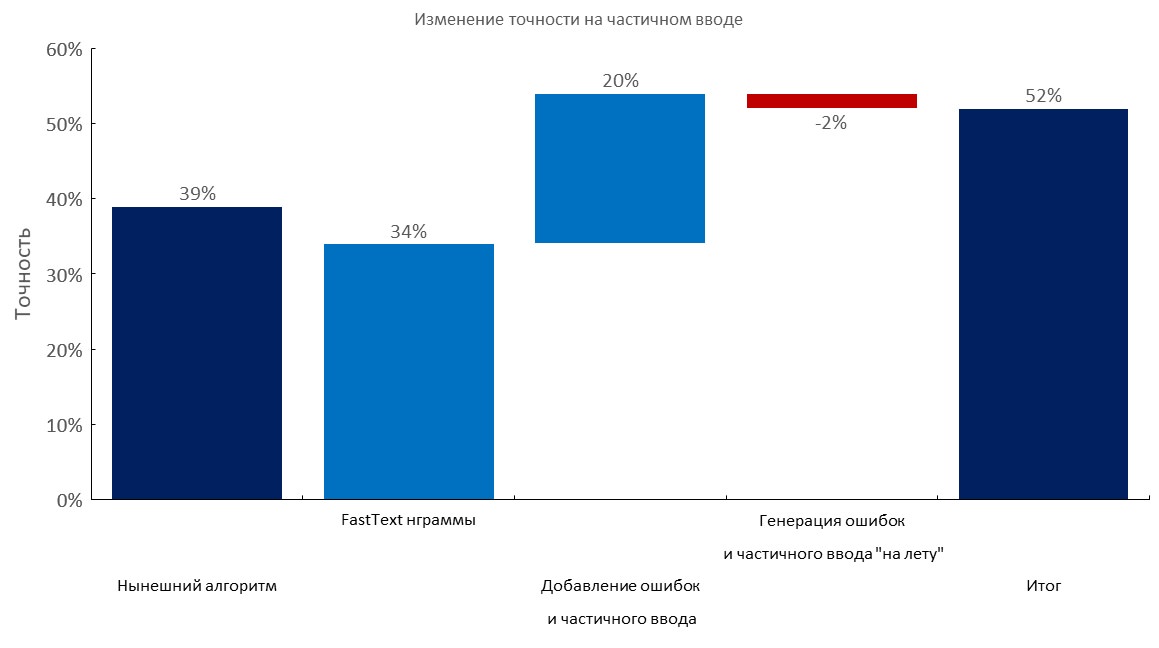
De gauche à droite:
(Précision Top1)
- Algorithme actuel (recherche élastique);
- Couche de sac d'intégration de texte rapide;
- Ajout de fautes de frappe et entrée partielle;
- Génération dynamique d'erreurs et saisie partielle;
- Score final;
Corpus à grande échelle / sélection n-gramme
- Nous avons collecté les plus grands corpus pour la langue russe:
- Areneum - une version traitée est disponible ici - les auteurs de l'ensemble de données n'ont pas répondu;
- Taiga
- Common crawl et wiki - veuillez suivre ces articles;
- Nous avons collecté un dictionnaire de
100m mots en utilisant l' exploration de 1 To ; - Utilisez également ce hack pour télécharger ces fichiers plus rapidement (du jour au lendemain);
- Nous avons sélectionné un ensemble optimal de
1m n-grammes pour que notre classificateur se généralise le mieux ( 500k n-grammes les plus populaires à partir de texte rapide formés sur Wikipedia russe + 500k n-grammes les plus populaires sur nos données de domaine);
Test de résistance de nos 1M n-grammes sur 100M de vocabulaire:

Augmentations de texte
En bref:
- Prenez un grand dictionnaire avec des erreurs (par exemple 10-100m de mots uniques);
- Générer une erreur (déposer une lettre, échanger une lettre en utilisant les probabilités calculées, insérer une lettre aléatoire, peut-être utiliser la disposition du clavier, etc.);
- Vérifiez que le nouveau mot est dans le dictionnaire;
Nous avons forcé de nombreuses requêtes à des services comme celui-ci (dans le but de procéder à une rétro-ingénierie de leur jeu de données), et ils ont un très petit dictionnaire à l'intérieur (ce service est également alimenté par un classificateur d'arbre avec des fonctionnalités de n-gramme). C'était assez drôle de voir qu'ils ne couvraient que 30 à 50% des mots que nous avions sur certains corpus .
Notre approche est de loin supérieure si vous avez accès à un vocabulaire de grand domaine .
Meilleurs résultats non supervisés / semi-supervisés
KNN utilisé comme référence pour comparer différentes méthodes d'intégration.
(taille du vecteur) Liste des modèles testés:
- (512) Détecteur de fausses phrases à grande échelle formé sur 200 Go de données d'analyse communes;
- (300) Détecteur de fausses phrases formé pour distinguer une phrase aléatoire de Wikipédia d'un service;
- (300) Texte rapide obtenu à partir d'ici, pré-formé sur le corpus araneum;
- (200) Texte rapide formé sur nos données de domaine;
- (300) Fast-text formé sur 200 Go de données Common Crawl;
- (300) Un réseau siamois avec perte de triplets formé avec des services / synonymes / phrases aléatoires de Wikipédia;
- (200) Première itération de la couche d'intégration du sac d'intégration RNN, une phrase est codée comme un sac complet d'intégration;
- (200) Idem, mais d'abord la phrase est divisée en mots, puis chaque mot est intégré, puis la moyenne est prise;
- (300) Comme ci-dessus mais pour le modèle final;
- (300) Comme ci-dessus mais pour le modèle final;
- (250) Couche goulot d'étranglement du modèle final (250 neurones);
- Ligne de base de recherche élastique faiblement supervisée;
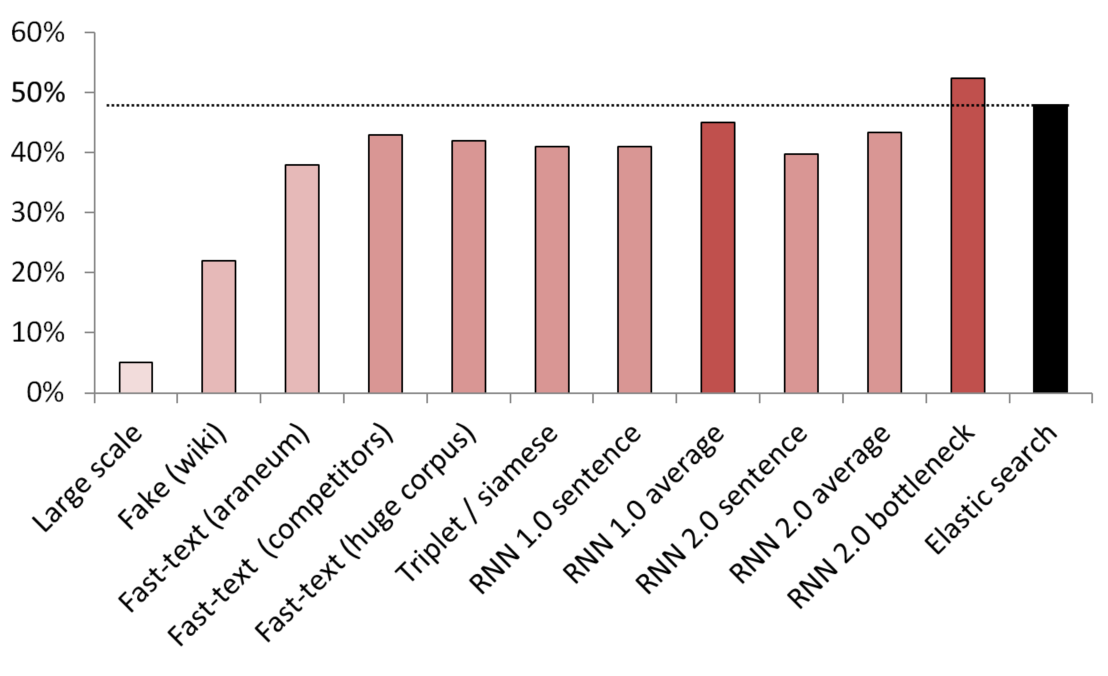
Pour éviter les fuites, toutes les phrases aléatoires ont été échantillonnées au hasard. Leur longueur en mots était la même que la durée des services / synonymes auxquels ils étaient comparés. Des mesures ont également été prises pour s'assurer que les modèles ne se contentent pas d'apprendre en séparant les vocabulaires (les intégrations ont été gelées, Wikipédia a été sous-échantillonné pour s'assurer qu'il y avait au moins un mot de domaine dans chaque phrase Wikipédia).
Visualisation de cluster
3D

2D

"Interface" d'exploration de clusters
Vert - nouveau mot / synonyme.
Fond gris - probablement nouveau mot.
Texte gris - synonyme existant.

Tests d'ablation et ce qui fonctionne, ce que nous avons essayé et ce que nous n'avons pas fait
- Voir les tableaux ci-dessus;
- Moyenne simple / moyenne tf-idf des intégrations de texte rapide - une base de données TRÈS formidable ;
- Texte rapide> Word2Vec pour le russe;
- L'incorporation de phrases par le type de détection de fausses phrases fonctionne, mais pâlit en comparaison avec d'autres méthodes;
- BPE (phrasepiece) n'a montré aucune amélioration sur notre domaine;
- Les modèles au niveau des ombles ont eu du mal à se généraliser, malgré le récent papier de Google;
- Nous avons essayé un transformateur à têtes multiples (avec des classificateurs et des têtes de modélisation de langage), mais sur l'annotation disponible, il fonctionnait à peu près de la même manière que les modèles LSTM à base de vanille ordinaire. Lorsque nous avons migré vers l'intégration de mauvaises approches, nous avons abandonné cette ligne de recherche en raison de la faible praticité du transformateur et de l'impossibilité d'avoir une tête LM avec une couche de sac d'intégration;
- BERT - semble être exagéré, certaines personnes affirment également que les transformateurs s'entraînent littéralement pendant des semaines;
- ELMO - l'utilisation d'une bibliothèque comme AllenNLP semble contre-productive à mon avis à la fois dans les environnements de recherche / production et d'éducation pour des raisons que je ne fournirai pas ici;
Déployer
Fait en utilisant:
- Conteneur Docker avec un simple service Web;
- Le processeur uniquement pour l'inférence suffit;
- ~
2.5 ms par requête sur CPU, le traitement par lots n'est pas vraiment nécessaire; - ~
1GB Go de mémoire RAM; - Presque pas de dépendances, à part
PyTorch , numpy et pandas (et le serveur web ofc). - Imitez la génération de n-gramme de texte rapide comme ceci ;
- Incorporation de la couche de sac + index comme simplement stocké dans un dictionnaire;