Dans les grands services, résoudre un problème en utilisant le machine learning signifie ne faire qu'une partie du travail. L'incorporation de modèles ML n'est pas si facile, et la construction de processus CI / CD autour d'eux est encore plus difficile. Lors de la conférence Yandex
«Data & Science: the application program», Adam Eldarov
, responsable de la science des données chez YouDo, a expliqué comment gérer le cycle de vie des modèles, mettre en place des processus de recyclage et de recyclage, développer des microservices évolutifs, et bien plus encore.
- Commençons par l'introduction. Il y a un scientifique des données, il écrit du code dans le cahier Jupyter, fait de l'ingénierie des fonctionnalités, de la validation croisée, forme des modèles de modèles. La vitesse augmente.

Mais à un moment donné, il comprend: pour apporter une valeur commerciale à l'entreprise, il doit attacher la solution quelque part dans la production, à une production mythique, ce qui nous pose beaucoup de problèmes. Dans la plupart des cas, l'ordinateur portable que nous avons vu en production ne peut pas être envoyé. Et la question se pose: comment envoyer ce code à l'intérieur de l'ordinateur portable à un certain service. Dans la plupart des cas, vous devez écrire un service doté d'une API. Ou ils communiquent via PubSub, via des files d'attente.

Lorsque nous faisons des recommandations, nous devons souvent former des modèles et les recycler. Ce processus doit être surveillé. Dans ce cas, il faut toujours vérifier avec des tests à la fois le code lui-même et les modèles, afin qu'à un moment notre modèle ne devienne pas fou et ne commence pas toujours à prédire zéro. Il doit également être vérifié sur de vrais utilisateurs via des tests AB - ce que nous avons fait de mieux ou du moins pas de pire.
Comment abordons-nous le code? Nous avons GitLab. Tout notre code est divisé en plusieurs petites bibliothèques qui résolvent un problème de domaine spécifique. En même temps, il s'agit d'un projet GitLab distinct, d'un contrôle de version Git et du modèle de branchement GitFlow. Nous utilisons des choses comme les hooks de pré-validation afin que vous ne puissiez pas valider du code qui ne satisfait pas nos vérifications de test de statistiques. Et les tests eux-mêmes, les tests unitaires. Nous utilisons pour eux l'approche de test basée sur les propriétés.

Habituellement, lorsque vous écrivez des tests, vous voulez dire que vous avez une fonction de test et les arguments que vous créez avec vos mains, quelques exemples et quelles valeurs votre fonction de test renvoie. C'est gênant. Le code est gonflé, beaucoup en principe sont trop paresseux pour l'écrire. En conséquence, nous avons un tas de code découvert par des tests. Les tests basés sur les propriétés impliquent que tous vos arguments ont une certaine distribution. Faisons un phasage, et plusieurs fois échantillonnons tous nos arguments à partir de ces distributions, appelons la fonction testée avec ces arguments, et vérifions pour certaines propriétés le résultat de cette fonction. En conséquence, nous avons beaucoup moins de code, et en même temps, il y a beaucoup plus de tests.
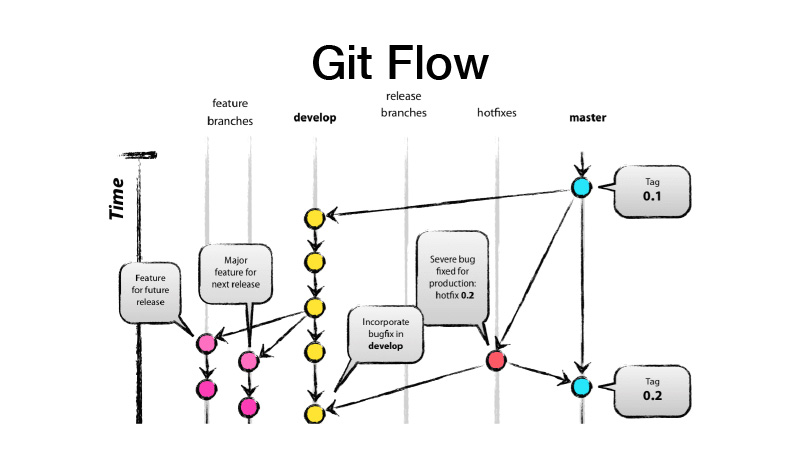
Qu'est-ce que GitFlow? Il s'agit d'un modèle de branchement, ce qui implique que vous avez deux branches principales - développer et maîtriser, où se trouve le code prêt pour la production, et tout développement est effectué dans la branche développer, où toutes les nouvelles fonctionnalités proviennent de brunchs de fonctionnalités. Autrement dit, chaque fonctionnalité est un nouveau brunch de fonctionnalités, tandis que le brunch de fonctionnalités devrait être de courte durée, et pour de bon - également couvert par le basculement des fonctionnalités. Nous faisons ensuite une version, à partir du développement, jetez les modifications sur master et mettez la balise de version de notre bibliothèque ou service dessus.
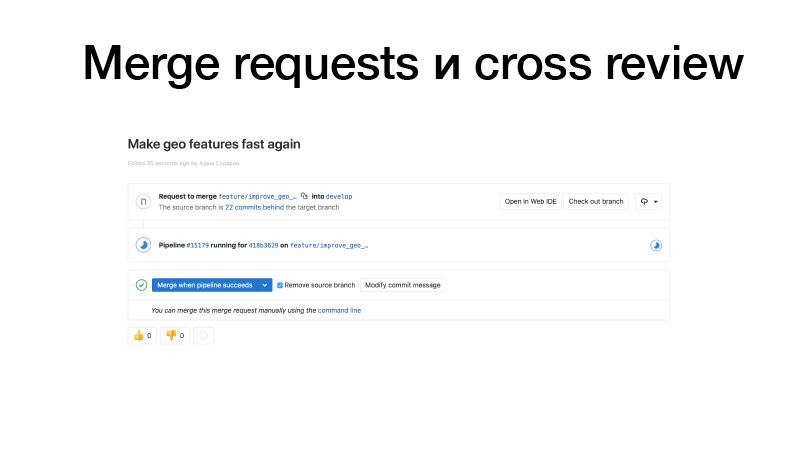
Nous faisons du développement, scions une fonctionnalité, la poussons vers GitLab, créons une demande de fusion du brunch des fonctionnalités aux jeunes filles. Les déclencheurs fonctionnent, exécutent des tests, si tout va bien, nous pouvons le geler. Mais ce n'est pas nous qui le tenons, mais quelqu'un de l'équipe. Il révise le code et augmente ainsi le facteur de bus. Cette section de code est déjà connue de deux personnes. Par conséquent, si quelqu'un se fait heurter par un bus, quelqu'un sait déjà ce qu'il fait.

L'intégration continue pour les bibliothèques ressemble généralement à des tests pour tout changement. Et si nous le publions, il est également publié sur le serveur PyPI privé de notre package.
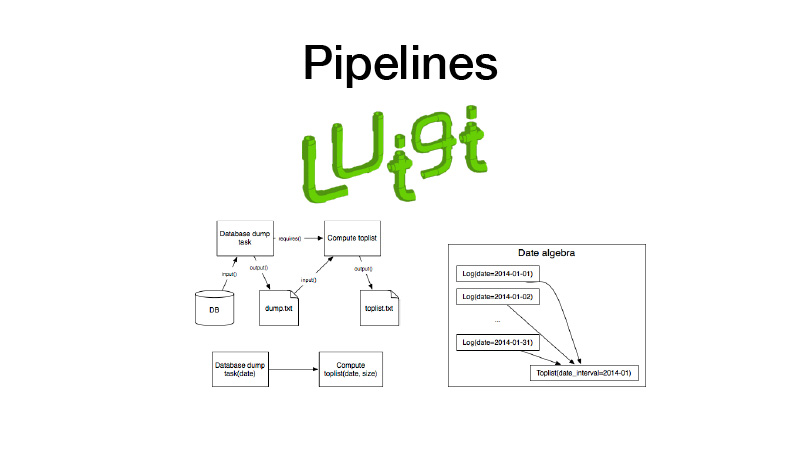
De plus, nous pouvons le collecter dans des pipelines. Pour cela, nous utilisons la bibliothèque Luigi. Il fonctionne avec une entité telle que la tâche, qui a une sortie, où l'artefact créé pendant l'exécution de la tâche est enregistré. Il existe un paramètre de tâche qui paramètre la logique métier qu'il exécute, identifie la tâche et sa sortie. Dans le même temps, les tâches ont toujours des exigences que les autres tâches posent. Lorsque nous exécutons une sorte de tâche, toutes ses dépendances sont vérifiées en vérifiant ses sorties. Si la sortie existe, notre dépendance ne démarre pas. Si l'artefact manque dans un espace de stockage, il démarre. Cela forme un pipeline, un graphique cyclique dirigé.
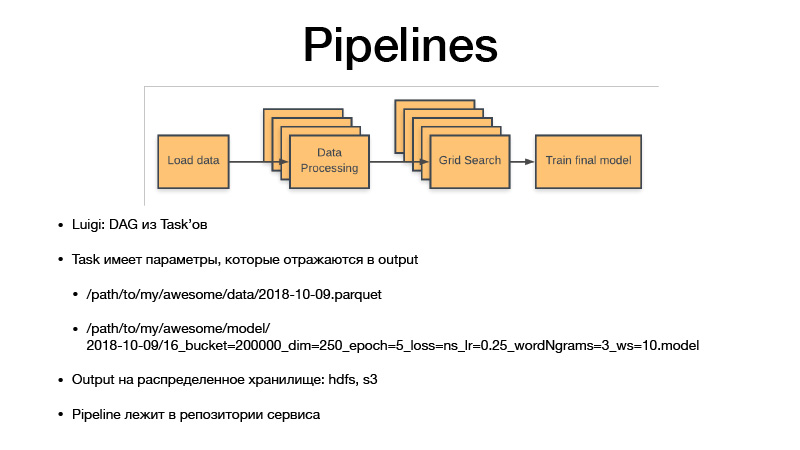
Tous les paramètres identifient la logique métier. Ce faisant, ils identifient l'artefact. C'est toujours une date avec une certaine granularité, sensibilité, ou une semaine, jour, heure, trois heures. Si nous formons un modèle, Luigi taska a toujours des hyperparamètres de cette tâche, ils fuient dans l'artefact que nous produisons, les hyperparamètres sont reflétés dans le nom de l'artefact. Ainsi, nous mettons essentiellement à jour tous les ensembles de données intermédiaires et les artefacts finaux, et ils ne sont jamais écrasés, toujours réservés au stockage, et le stockage est privé HDFS et S3, qui voit les artefacts finaux de certains cornichons, modèles ou autre chose . Et tout le code du pipeline réside dans le projet de service dans le référentiel auquel il se rapporte.

Il doit être corrigé d'une manière ou d'une autre. La pile HashiCorp vient à la rescousse, nous utilisons Terraform pour déclarer l'infrastructure sous forme de code, Vault pour gérer les secrets, il y a tous les mots de passe, les apparences dans la base de données. Consul est un service de découverte distribué par stockage de valeurs clés que vous pouvez utiliser pour configurer. Et Consul vérifie également la santé de vos nœuds et de vos services, vérifiant leur disponibilité.
Et - Nomade. c'est un système d'orchestration, qui délivre vos services et une sorte de travaux par lots.
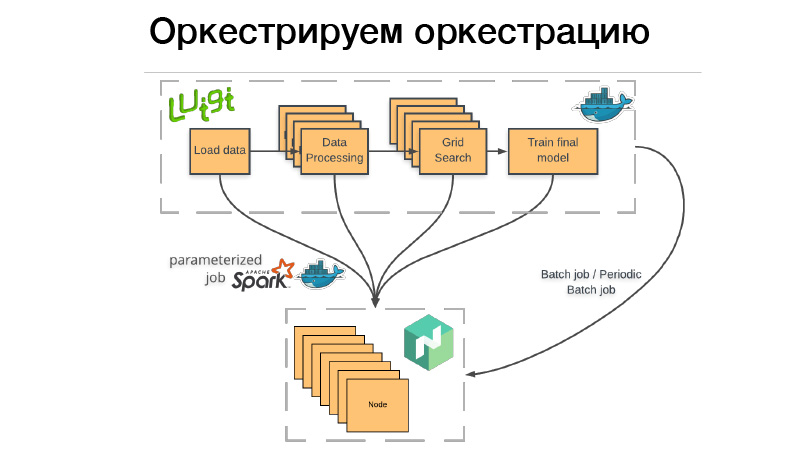
Comment utilisons-nous cela? Il y a un pipeline Luigi, nous allons l'emballer dans le conteneur Docker, déposer la batte ou le travail par lots périodique dans Nomad. Travail par lots - c'est quelque chose de terminé, terminé, et si tout réussit - tout va bien, nous pouvons le redémarrer manuellement. Mais si quelque chose a mal tourné, Nomad le réessaye jusqu'à ce qu'il épuise la tentative, ou il ne se termine pas avec succès.
Travail par lots périodique - c'est exactement la même chose, ne fonctionne que sur un calendrier.
Il y a un problème. Lorsque nous déployons un conteneur sur n'importe quel système d'orchestration, nous devons indiquer la quantité de mémoire dont ce conteneur, CPU ou mémoire a besoin. Si nous avons un pipeline qui fonctionne pendant trois heures, deux heures de cela consomment 10 Go de RAM, 1 heure - 70 Go. Si nous dépassons la limite que nous lui avons donnée, le démon Docker arrive et tue Dockers et (nrzb.) [02:26:13] Nous ne voulons pas intercepter constamment de la mémoire, nous devons donc spécifier tous les 70 Go, la charge de mémoire maximale. Mais voici le problème, tous les 70 Go pour trois heures seront alloués et inaccessibles à tout autre travail.
Par conséquent, nous sommes allés dans l'autre sens. L'ensemble de notre pipeline Luigi ne démarre aucune sorte de logique métier, il lance simplement un ensemble de dés dans Nomad, le travail dit paramétré. En fait, il s'agit d'un analogue des fonctions serveur (NRZB.) [02:26:39], AVS Lambda, qui sait. Lorsque nous créons une bibliothèque, nous déployons via CI tout notre code sous forme de travaux paramétrés, c'est-à-dire un conteneur avec certains paramètres. Supposons, Lite JBM Classifier, qu'il ait un paramètre pour le chemin d'accès aux données d'entrée pour la formation, les hyperparamètres des modèles et le chemin d'accès pour les artefacts de sortie. Tout cela est enregistré dans Nomad, puis à partir du pipeline Luigi, nous pouvons extraire tous ces travaux Nomad via l'API, tandis que Luigi s'assure de ne pas exécuter la même tâche plusieurs fois.
Supposons que nous ayons le même traitement de texte. Il existe 10 modèles conditionnels et nous ne voulons pas redémarrer le traitement de texte à chaque fois. Il ne démarrera qu'une seule fois, et en même temps, il y aura un résultat fini à chaque réutilisation. Et en même temps, tout cela fonctionne de manière distribuée, nous pouvons exécuter une recherche de grille géante sur un grand cluster, avoir seulement le temps de vider le fer.
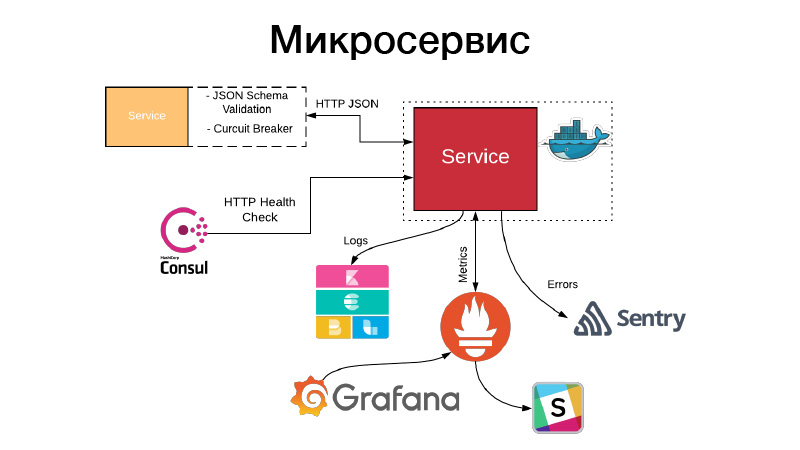
Nous avons un artefact, nous devons en quelque sorte organiser cela sous la forme d'un service. Les services exposent une API HTTP ou communiquent via des files d'attente. Dans cet exemple, il s'agit de l'API HTTP, l'exemple le plus simple. Dans le même temps, la communication avec le service, ou notre service communique avec d'autres services via l'API HTTP JSON, valide le schéma JSON. Le service lui-même décrit toujours un objet JSON dans la documentation de son API et le schéma de cet objet. Mais tous les champs de l'objet JSON ne sont pas toujours nécessaires, donc les contrats axés sur le consommateur sont validés, ce schéma est validé, la communication a lieu via un disjoncteur de modèle pour empêcher notre système distribué de tomber en panne en raison de défaillances en cascade.
Dans le même temps, le service doit définir un contrôle d'intégrité HTTP afin que Consul puisse venir vérifier la disponibilité de ce service. Dans le même temps, Nomad peut faire en sorte qu'il y ait un service pour trois vérifications de bonjour d'affilée, il peut redémarrer le service pour l'aider. Le service écrit tous ses journaux au format JSON. Nous utilisons le pilote de journalisation JSON et la pile Elastics, à chaque point FileBit prend simplement tous les journaux JSON, les jette dans le cache de journaux, à partir de là, ils arrivent à Elastic, nous pouvons analyser KBan. Dans le même temps, nous n'utilisons pas de journaux pour la collecte de métriques et la création de tableaux de bord, il est inefficace, nous utilisons le système d'entraînement Prometheus pour cela, nous avons un processus pour créer des modèles pour chaque service de tableau de bord et nous pouvons analyser les métriques techniques produites par le service.
De plus, en cas de problème, des alertes arrivent, mais dans la plupart des cas, cela ne suffit pas. La sentinelle vient à notre aide, c'est une chose pour l'analyse des incidents. En fait, nous capturons tous les journaux de niveau d'erreur par le gestionnaire Sentry et les poussons dans Sentry. Et puis il y a une trace détaillée, il y a toutes les informations sur l'environnement dans lequel le service était, quelle version, quelles fonctions étaient appelées par quels arguments et quelles variables dans cette étendue étaient avec quelles valeurs. Toutes les configurations, tout cela est visible, et cela aide beaucoup à comprendre rapidement ce qui s'est passé et à corriger l'erreur.
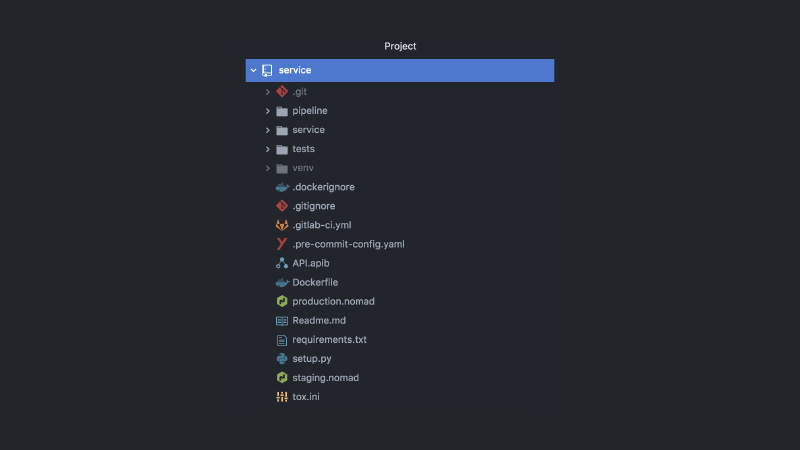
Par conséquent, le service ressemble à ceci. Projet GitLab séparé, code de pipeline, code de test, code de service lui-même, un tas de configurations différentes, Nomad, configurations CI, documentation API, crochets de validation et plus encore.
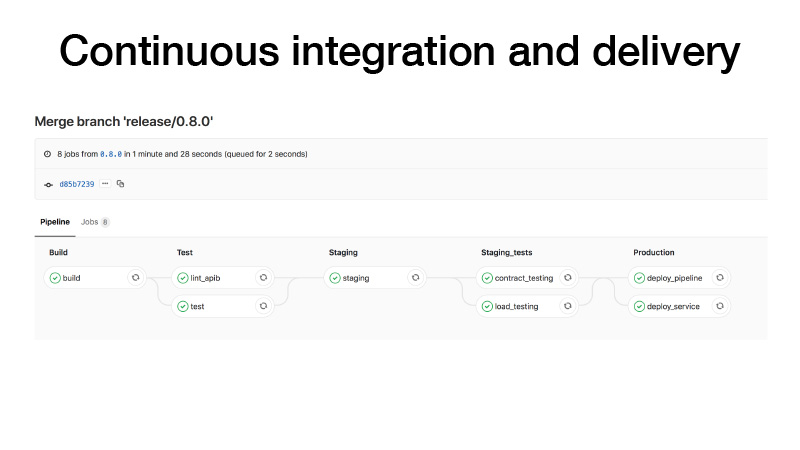
Lorsque nous faisons une version, nous effectuons le CI comme suit: construire un conteneur, exécuter des tests, déposer un cluster sur une mise en scène, exécuter un contrat de test pour notre service là-bas, effectuer des tests de résistance pour nous assurer que notre prédiction n'est pas trop lente et garder la charge que nous pensons . Si tout va bien, nous déploierons ce service en production. Et il y a deux façons: nous pouvons déployer le pipeline, si le travail par lots périodique, il fonctionne quelque part en arrière-plan et produit des artefacts, ou avec les stylos, nous déclenchons une sorte de pipeline, il forme un modèle, après cela, nous comprenons que tout va bien et déployer le service.

Que se passe-t-il d'autre dans ce cas? J'ai dit que dans le développement des brunchs de fonctionnalités, il existe un paradigme tel que les basculements de fonctionnalités. Dans le bon sens, vous devez couvrir les fonctionnalités avec quelques bascules, juste pour réduire une fonctionnalité au combat si quelque chose ne va pas. Nous pouvons ensuite collecter toutes les fonctionnalités dans les trains de versions, et même si les fonctionnalités ne sont pas terminées, nous pouvons les déployer. Le basculement des fonctionnalités sera désactivé. Puisque nous sommes tous des Data Scientists, nous voulons également faire des tests AV. Disons que nous avons remplacé LightGBM par CatBoost. Nous voulons vérifier cela, mais en même temps, le test AV est géré en référence à un ID utilisateur. Le basculement de fonction est lié à l'ID utilisateur et passe donc le test AV. Nous devons vérifier ces mesures ici.
Tous les services sont déployés sur Nomad. Nous avons deux clusters de production Nomad - un pour le travail par lots et un pour les services.
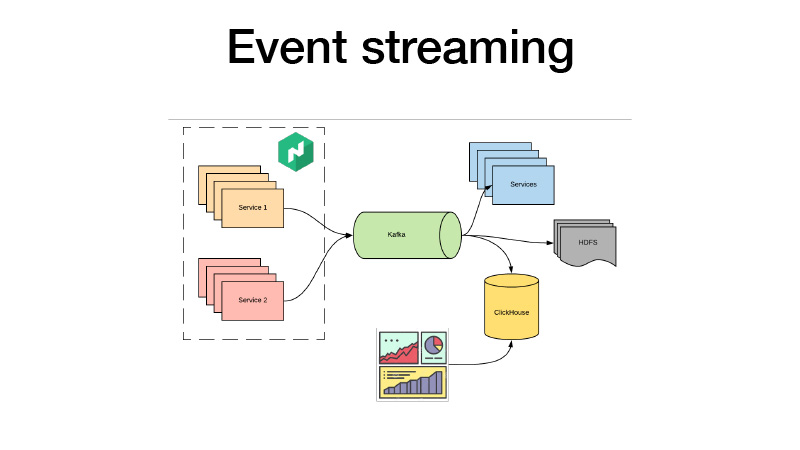
Ils poussent tous leurs événements commerciaux à Kafka. De là, nous pouvons les récupérer. C'est essentiellement une architecture d'agneau. Nous pouvons souscrire à HDFS avec certains services, effectuer des analyses en temps réel et en même temps, nous ratissons tous dans ClickHouse et créons des tableaux de bord pour analyser tous les événements commerciaux de nos services. Nous pouvons analyser les tests AV, peu importe.
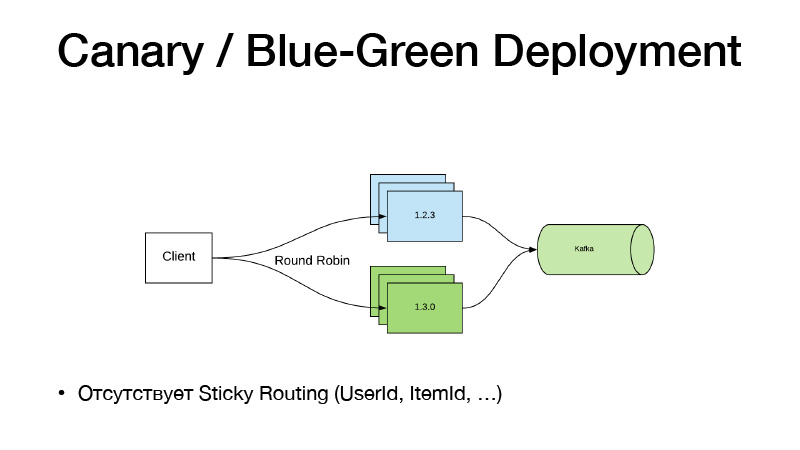
Et si nous n'avons pas changé le code, n'utilisez pas de bascule de fonction. Nous venons de commencer à travailler avec des stylos sur un pipeline, il nous a appris un nouveau modèle. Nous avons une nouvelle voie vers cela. Nous modifions simplement le chemin Nomad vers le modèle dans la configuration, faisons une nouvelle version de service, et ici le paradigme de déploiement Canary vient à notre aide, il est disponible dans Nomad de la boîte.
Nous avons la version actuelle du service dans trois cas. Nous disons que nous voulons trois canaris - trois autres répliques de nouvelles versions sont déployées sans abattre les anciennes. En conséquence, le trafic commence à se diviser en deux parties. Une partie du trafic tombe sur de nouvelles versions de services. Tous les services poussent tous leurs événements professionnels à Kafka. En conséquence, nous pouvons analyser les métriques en temps réel.
Si tout va bien, on peut dire que tout va bien. Déployez, Nomad passera, désactivez doucement toutes les anciennes versions et mettez à l'échelle les nouvelles.
Ce modèle est mauvais en ce sens que si nous devons lier le routage de version à une entité, l'élément utilisateur. Un tel schéma ne fonctionne pas, car le trafic est équilibré via un round-robin. Par conséquent, nous avons suivi le chemin suivant et scié le service en deux parties.
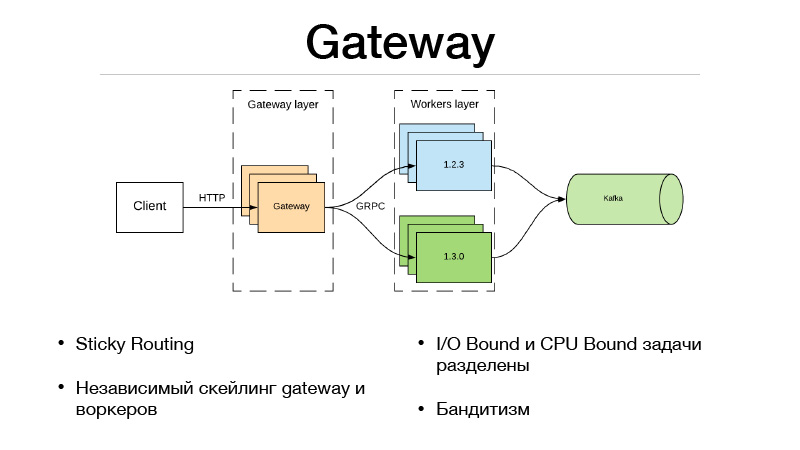
Il s'agit de la couche Gateway et de la couche Workers. Le client communique via HTTP avec la couche passerelle, toute la logique de sélection de version et d'équilibrage du trafic se trouve dans la passerelle. Dans le même temps, toutes les tâches liées aux E / S qui sont nécessaires pour terminer le prédicat se trouvent également dans la passerelle. Supposons que nous obtenions un ID utilisateur dans le prédicat de la demande, que nous devons enrichir avec quelques informations. Nous devons extraire d'autres microservices et récupérer toutes les informations, fonctionnalités ou bases. En conséquence, tout cela se produit dans la passerelle. Il communique avec des travailleurs qui ne sont que dans le modèle et fait une chose - une prédiction. Entrée et sortie.
Mais depuis que nous avons divisé notre service en deux parties, des frais généraux sont apparus en raison d'un appel réseau distant. Comment le niveler? Le framework JRPC de Google, le RPC de Google, qui fonctionne sur HTTP2 vient à la rescousse. Vous pouvez utiliser le multiplexage et la compression. JPRC utilise protobuff. Il s'agit d'un protocole binaire fortement typé qui a une sérialisation et une désérialisation rapides.
En conséquence, nous avons également la possibilité de faire évoluer indépendamment Gateway et Worker. Disons que nous ne pouvons pas conserver une certaine quantité de connexions HTTP ouvertes. D'accord, la mise à l'échelle de la passerelle. Notre prédiction est trop lente, nous n'avons pas le temps de garder la charge - ok, nous faisons évoluer les travailleurs. Cette approche convient très bien aux bandits multi-armés. Dans Gateway, puisque toute la logique d'équilibrage du trafic est implémentée, il peut accéder à des microservices externes et prendre toutes les statistiques pour chaque version, ainsi que prendre des décisions sur la façon d'équilibrer le trafic. Disons en utilisant l'échantillonnage de Thompson.
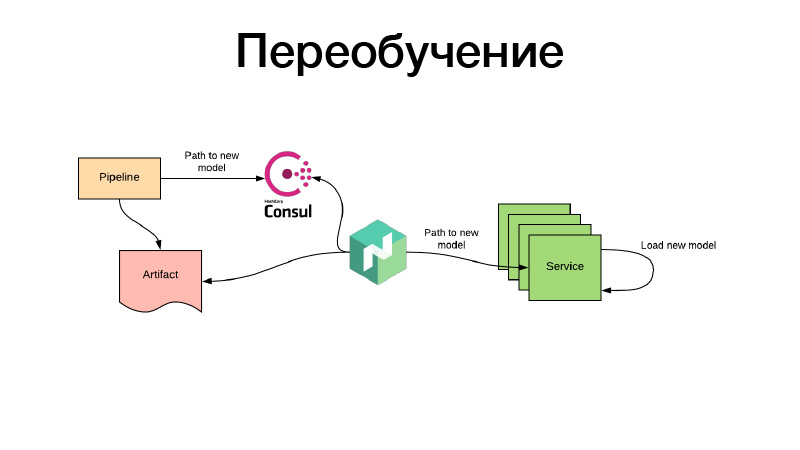
D'accord, les modèles ont été formés d'une manière ou d'une autre, nous les avons enregistrés dans la configuration Nomade. Mais que se passe-t-il s'il existe un modèle de recommandations qui a déjà le temps de devenir obsolète lors de la formation et que nous devons constamment les recycler? Tout se fait de la même manière: grâce à des travaux par lots périodiques, un artefact est produit, disons toutes les trois heures. Dans le même temps, à la fin de ses travaux, le pipeline définit le chemin du nouveau modèle dans Consul. Il s'agit du stockage de valeurs clés, utilisé pour la configuration. Nomad peut configurer des configurations. Soit une variable d'environnement basée sur les valeurs du consul de stockage des valeurs clés. Il surveille les changements et, dès qu'un nouveau chemin apparaît, décide que deux chemins peuvent être empruntés. Il télécharge l'artefact lui-même via un nouveau lien, place le conteneur de services dans Docker à l'aide du volume et le recharge - et fait tout pour qu'il n'y ait pas de temps d'arrêt, c'est-à-dire lentement, individuellement. Ou il rend une nouvelle configuration et lui rapporte le service. Ou le service lui-même le détecte - et à l'intérieur de lui-même peut, indépendamment, mettre à jour en direct son modelka. C'est tout, merci.