
Je suis tombé sur du matériel intéressant sur l'intelligence artificielle dans les jeux. Avec une explication des choses de base sur l'IA à l'aide d'exemples simples, et à l'intérieur il y a de nombreux outils et méthodes utiles pour son développement et sa conception pratiques. Comment, où et quand les utiliser - est également là.
La plupart des exemples sont écrits en pseudocode, donc aucune connaissance approfondie de la programmation n'est requise. Sous la coupe de 35 feuilles de texte avec des images et des gifs, alors préparez-vous.
UPD Je
suis désolé , mais
PatientZero a déjà fait la traduction de cet article sur Habré. Vous pouvez lire sa version
ici , mais pour une raison quelconque, l'article m'a dépassé (j'ai utilisé la recherche, mais quelque chose s'est mal passé). Et puisque j'écris un blog de développement de jeux, j'ai décidé de laisser mon option de traduction aux abonnés (certains moments sont différents pour moi, certains sont intentionnellement manqués sur les conseils des développeurs).
Qu'est-ce que l'IA?
L'IA de jeu se concentre sur les actions qu'un objet doit effectuer en fonction des conditions dans lesquelles il se trouve. Ceci est généralement appelé la gestion des "agents intelligents", où l'agent est un personnage de jeu, un véhicule, un bot et parfois quelque chose de plus abstrait: tout un groupe d'entités ou même une civilisation. Dans chaque cas, c'est une chose qui doit voir son environnement, prendre des décisions sur sa base et agir en accord avec eux. C'est ce qu'on appelle le cycle Sense / Think / Act:
- Sens: l'agent trouve ou reçoit des informations sur des choses dans son environnement qui peuvent affecter son comportement (menaces à proximité, objets à collecter, lieux de recherche intéressants).
- Pensez: l'agent décide de la façon de réagir (considère s'il est sécuritaire de collecter des objets ou s'il doit d'abord se battre / se cacher).
- Agir: l'agent effectue des actions pour mettre en œuvre la décision précédente (commence à se déplacer vers l'adversaire ou l'objet).
- ... maintenant la situation a changé en raison des actions des personnages, donc le cycle se répète avec de nouvelles données.
L'IA a tendance à se concentrer sur la partie sensible de la boucle. Par exemple, les voitures autonomes prennent des photos de la route, les combinent avec des données radar et lidar et interprètent. Habituellement, cela se fait par apprentissage automatique, qui traite les données entrantes et leur donne un sens, en extrayant des informations sémantiques comme "il y a une autre voiture à 20 mètres devant vous". Ce sont les soi-disant problèmes de classification.
Les jeux n'ont pas besoin d'un système complexe pour extraire des informations, car la plupart des données en font déjà partie intégrante. Il n'est pas nécessaire d'exécuter des algorithmes de reconnaissance d'image pour déterminer s'il y a un ennemi à venir - le jeu connaît déjà et transfère les informations directement dans le processus de prise de décision. Par conséquent, une partie du cycle des sens est souvent beaucoup plus simple que penser et agir.
Limitations de l'IA du jeu
L'IA a un certain nombre de restrictions à respecter:
- L'IA n'a pas besoin d'être formée à l'avance, comme s'il s'agissait d'un algorithme d'apprentissage automatique. Il est inutile d'écrire un réseau de neurones pendant le développement pour regarder des dizaines de milliers de joueurs et apprendre la meilleure façon de jouer contre eux. Pourquoi? Parce que le jeu n'est pas sorti, mais il n'y a pas de joueurs.
- Le jeu devrait divertir et défier, donc les agents ne devraient pas trouver la meilleure approche contre les gens.
- Les agents doivent être réalistes pour que les joueurs aient l'impression de jouer contre de vraies personnes. AlphaGo surpassait les humains, mais les mesures prises étaient loin de la compréhension traditionnelle du jeu. Si le jeu imite un adversaire humain, il ne devrait pas y avoir un tel sentiment. L'algorithme doit être modifié afin qu'il prenne des décisions plausibles, pas idéales.
- L'IA devrait fonctionner en temps réel. Cela signifie que l'algorithme ne peut pas monopoliser l'utilisation du processeur pendant longtemps pour la prise de décision. Même 10 millisecondes pour cela est trop long, car la plupart des jeux n'ont que 16 à 33 millisecondes pour terminer tout le traitement et passer à l'image suivante du graphique.
- Idéalement, au moins une partie du système est pilotée par les données afin que les non-codeurs puissent apporter des modifications et des ajustements plus rapidement.
Considérez les approches de l'IA qui couvrent tout le cycle Sense / Think / Act.
Prise de décision de base
Commençons par le jeu le plus simple - Pong. Objectif: déplacer la plate-forme (pagaie) de manière à ce que le ballon rebondisse dessus, plutôt que de passer devant. C'est comme le tennis, dans lequel vous perdez si vous ne frappez pas la balle. Ici, l'IA a une tâche relativement facile - décider dans quelle direction déplacer la plate-forme.

Déclarations conditionnelles
Pour l'IA, Pong a la solution la plus évidente - essayez toujours de positionner la plate-forme sous le ballon.
Un algorithme simple pour cela, écrit en pseudocode:
chaque image / mise à jour pendant le jeu:
si le ballon est à gauche de la raquette:
déplacer la palette vers la gauche
sinon si le ballon est à droite de la raquette:
déplacer la pagaie vers la droiteSi la plateforme se déplace à la vitesse du ballon, alors c'est l'algorithme parfait pour l'IA à Pong. Il n'est pas nécessaire de compliquer quoi que ce soit s'il n'y a pas tant de données et d'actions possibles pour l'agent.
Cette approche est si simple que l'ensemble du cycle Sense / Think / Act est à peine perceptible. Mais il est:
- La partie Sense est en deux instructions if. Le jeu sait où se trouve la balle et où se trouve la plate-forme, donc l'IA se tourne vers elle pour cette information.
- La partie Think se décline également en deux déclarations if. Ils incarnent deux solutions, qui dans ce cas s'excluent mutuellement. Par conséquent, l'une des trois actions est sélectionnée: déplacer la plate-forme vers la gauche, déplacer vers la droite ou ne rien faire si elle est déjà correctement positionnée.
- La partie Act se trouve dans les instructions Move Paddle Left et Move Paddle Right. Selon la conception du jeu, ils peuvent déplacer la plateforme instantanément ou à une certaine vitesse.
De telles approches sont appelées réactives - il existe un ensemble simple de règles (dans ce cas, si des déclarations dans le code) qui répondent à l'état actuel du monde et agissent.
Arbre de décision
L'exemple Pong est en fait égal au concept formel de l'IA appelé l'arbre de décision. L'algorithme le passe pour atteindre une «feuille» - une décision sur l'action à entreprendre.
Faisons un schéma de principe de l'arbre de décision pour l'algorithme de notre plateforme:
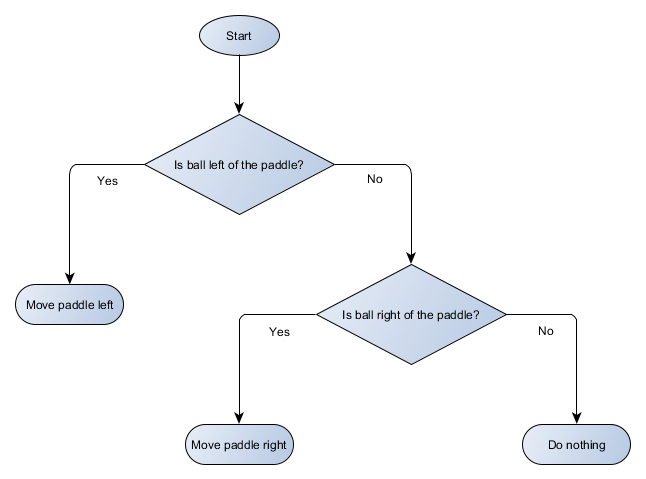
Chaque partie de l'arbre est appelée un nœud - l'IA utilise la théorie des graphes pour décrire ces structures. Il existe deux types de nœuds:
- Noeuds de décision: choisir entre deux alternatives basées sur la vérification d'une certaine condition où chaque alternative est présentée comme un noeud séparé.
- Noeuds finaux: action à effectuer qui représente la décision finale.
L'algorithme commence par le premier nœud (la "racine" de l'arbre). Il décide soit du nœud enfant vers lequel se rendre, soit effectue une action stockée dans le nœud et se termine.
Quel est l'avantage si l'arbre de décision fait le même travail que les instructions if de la section précédente? Ici, il existe un système commun où chaque solution n'a qu'une seule condition et deux résultats possibles. Cela permet au développeur de créer une IA à partir des données représentant les décisions dans l'arborescence, en évitant son codage en dur. Imaginez sous la forme d'un tableau:
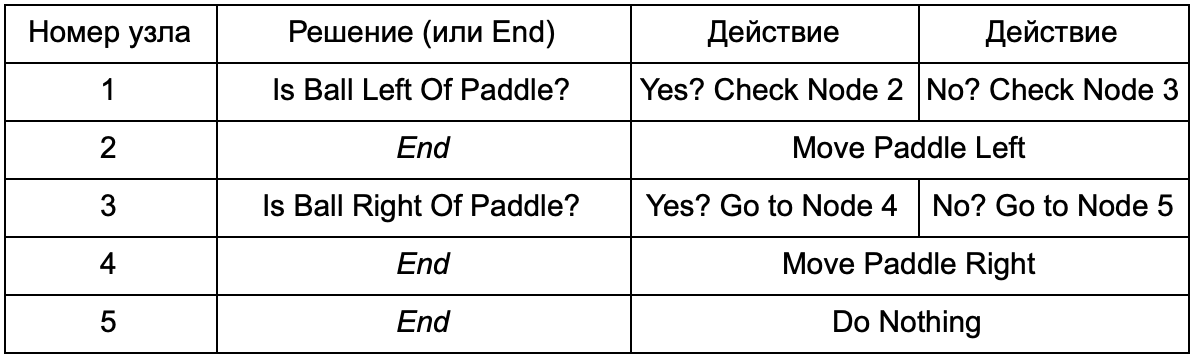
Côté code, vous obtenez un système de lecture des chaînes. Créez un nœud pour chacun d'eux, connectez la logique de décision basée sur la deuxième colonne et les nœuds enfants basés sur les troisième et quatrième colonnes. Vous devez encore programmer les conditions et les actions, mais maintenant la structure du jeu sera plus compliquée. Vous y ajoutez des décisions et des actions supplémentaires, puis configurez l'intégralité de l'IA en modifiant simplement un fichier texte avec une définition d'arbre. Ensuite, transférez le fichier au concepteur de jeu qui peut changer le comportement sans recompiler le jeu et changer le code.
Les arbres de décision sont très utiles lorsqu'ils sont construits automatiquement sur la base d'un grand nombre d'exemples (par exemple, en utilisant l'algorithme ID3). Cela en fait un outil efficace et performant pour classer les situations en fonction des données reçues. Cependant, nous allons au-delà d'un simple système permettant aux agents de sélectionner des actions.
Scénarios
Nous avons démonté un système d'arbre de décision qui utilisait des conditions et des actions pré-créées. Le concepteur d'IA peut organiser l'arborescence comme il le souhaite, mais il doit toujours compter sur l'encodeur qui a tout programmé. Et si nous pouvions donner au designer des outils pour créer nos propres conditions ou actions?
Pour empêcher le programmeur d'écrire du code pour les conditions Is Ball Left Of Paddle et Is Ball Right Of Paddle, il peut créer un système dans lequel le concepteur enregistrera les conditions de vérification de ces valeurs. Ensuite, les données de l'arbre de décision ressembleront à ceci:
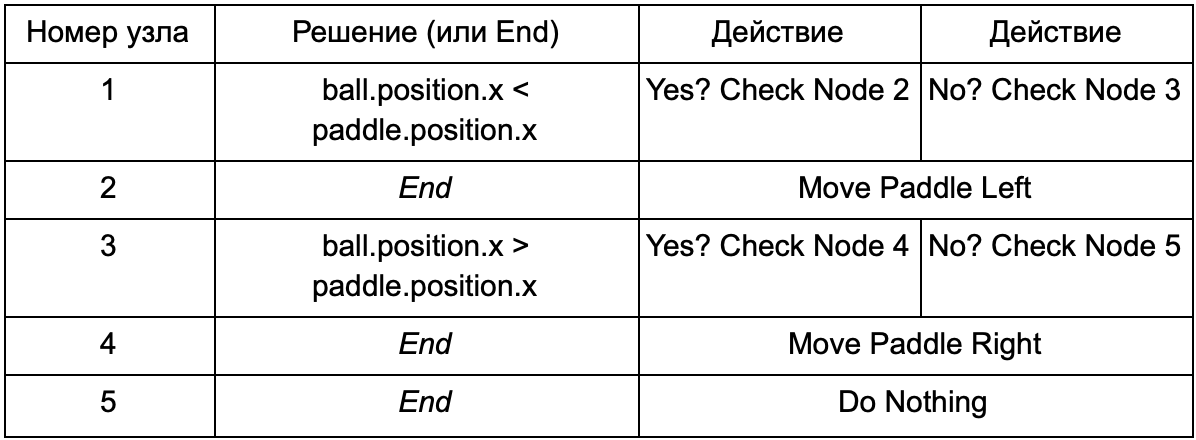
En substance, c'est la même chose que dans le premier tableau, mais les solutions en elles-mêmes ont leur propre code, un peu similaire à la partie conditionnelle de l'instruction if. Côté code, cela serait lu dans la deuxième colonne pour les nœuds de décision, mais au lieu de rechercher une condition spécifique à remplir (Is Ball Left Of Paddle), il évalue l'expression conditionnelle et renvoie respectivement true ou false. Cela se fait en utilisant le langage de script Lua ou Angelscript. En les utilisant, le développeur peut prendre des objets dans son jeu (balle et pagaie) et créer des variables qui seront disponibles dans le script (ball.position). De plus, le langage de script est plus simple que C ++. Il ne nécessite pas d'étape de compilation complète, il est donc idéal pour un ajustement rapide de la logique du jeu et permet aux «non-codeurs» de créer eux-mêmes les fonctions nécessaires.
Dans l'exemple ci-dessus, le langage de script est utilisé uniquement pour évaluer une expression conditionnelle, mais il peut également être utilisé pour des actions. Par exemple, les données Move Paddle Right peuvent devenir une instruction de script (ball.position.x + = 10). Pour que l'action soit également définie dans le script, sans avoir besoin de programmer Move Paddle Right.
Vous pouvez aller encore plus loin et écrire un arbre de décision complet dans un langage de script. Ce sera un code sous la forme d'instructions conditionnelles codées en dur, mais elles seront situées dans des fichiers de script externes, c'est-à-dire qu'elles peuvent être modifiées sans recompiler l'intégralité du programme. Souvent, vous pouvez modifier le fichier de script directement pendant le jeu pour tester rapidement différentes réactions de l'IA.
Réponse à l'événement
Les exemples ci-dessus sont parfaits pour Pong. Ils exécutent en continu le cycle Sense / Think / Act et agissent sur la base de l'état le plus récent du monde. Mais dans les jeux plus complexes, vous devez répondre aux événements individuels et ne pas tout évaluer à la fois. Pong est déjà un exemple infructueux. Choisissez-en un autre.
Imaginez un tireur où les ennemis sont immobiles jusqu'à ce qu'ils trouvent le joueur, après quoi ils agissent en fonction de leur "spécialisation": quelqu'un courra pour "écraser", quelqu'un attaquera de loin. C'est toujours le système réactif de base - «si le joueur est remarqué, alors faites quelque chose» - mais il peut logiquement être divisé en l'événement Player Seen (le joueur est remarqué) et la réaction (sélectionnez la réponse et exécutez-la).
Cela nous ramène au cycle Sense / Think / Act. Nous pouvons encoder la partie Sense, que chaque image vérifiera pour voir si l'IA du joueur est visible. Sinon, rien ne se passe, mais s'il voit, alors l'événement Joueur vu est déclenché. Le code aura une section séparée qui dit: "quand l'événement Player Seen se produit, faites-le", où est la réponse dont vous avez besoin pour vous référer aux parties Penser et Agir. Ainsi, vous configurerez des réactions à l'événement Player Seen: ChargeAndAttack pour le personnage «en pleine croissance» et HideAndSnipe pour le tireur d'élite. Ces relations peuvent être créées dans le fichier de données pour une modification rapide sans avoir à recompiler. Et ici, vous pouvez également utiliser le langage de script.
Prendre des décisions difficiles
Bien que les systèmes de réaction simples soient très efficaces, il existe de nombreuses situations où ils ne sont pas suffisants. Parfois, il est nécessaire de prendre diverses décisions en fonction de ce que fait l'agent en ce moment, mais il est difficile d'imaginer cela comme une condition. Parfois, il y a trop de conditions pour les représenter efficacement dans un arbre de décision ou un script. Parfois, vous devez pré-évaluer comment la situation va changer avant de décider de la prochaine étape. La résolution de ces problèmes nécessite des approches plus sophistiquées.
Machine à états finis
La machine à états finis ou FSM (machine à états) est une façon de dire que notre agent est actuellement dans l'un des états possibles et qu'il peut passer d'un état à l'autre. Il existe un certain nombre de ces états - d'où le nom. Le meilleur exemple de vie est un feu de circulation. À différents endroits, différentes séquences de lumières, mais le principe est le même - chaque état représente quelque chose (se tenir debout, partir, etc.). Un feu de circulation n'est que dans un état à un moment donné et passe de l'un à l'autre en fonction de règles simples.
Avec les PNJ dans les jeux, une histoire similaire. Par exemple, prenez un garde avec les conditions suivantes:
Et de telles conditions pour changer son état:
- Si le garde voit l'ennemi, il attaque.
- Si le garde attaque, mais ne voit plus l'ennemi, il recommence à patrouiller.
- Si le garde attaque, mais est gravement blessé, il s'enfuit.
Vous pouvez également écrire des instructions if avec une variable d'état de garde et diverses vérifications: y a-t-il un ennemi à proximité, quel est le niveau de santé du PNJ, etc. Ajoutons quelques états supplémentaires:
- Inaction (marche au ralenti) - entre les patrouilles.
- Recherche (recherche) - lorsque l'ennemi remarqué a disparu.
- Demandez de l'aide (Trouver de l'aide) - lorsque l'ennemi est vu, mais trop fort pour combattre seul avec lui.
Le choix pour chacun d'eux est limité - par exemple, un garde n'ira pas à la recherche d'un ennemi caché s'il est en mauvaise santé.
En fin de compte, l'énorme liste de "si <x et y, mais pas z>, alors <p>" peut devenir trop lourde, nous devons donc formaliser une méthode qui nous permettra de garder à l'esprit les états et les transitions entre les états. Pour ce faire, nous prenons en compte tous les états, et sous chaque état, nous listons toutes les transitions vers d'autres états, ainsi que les conditions nécessaires pour eux.
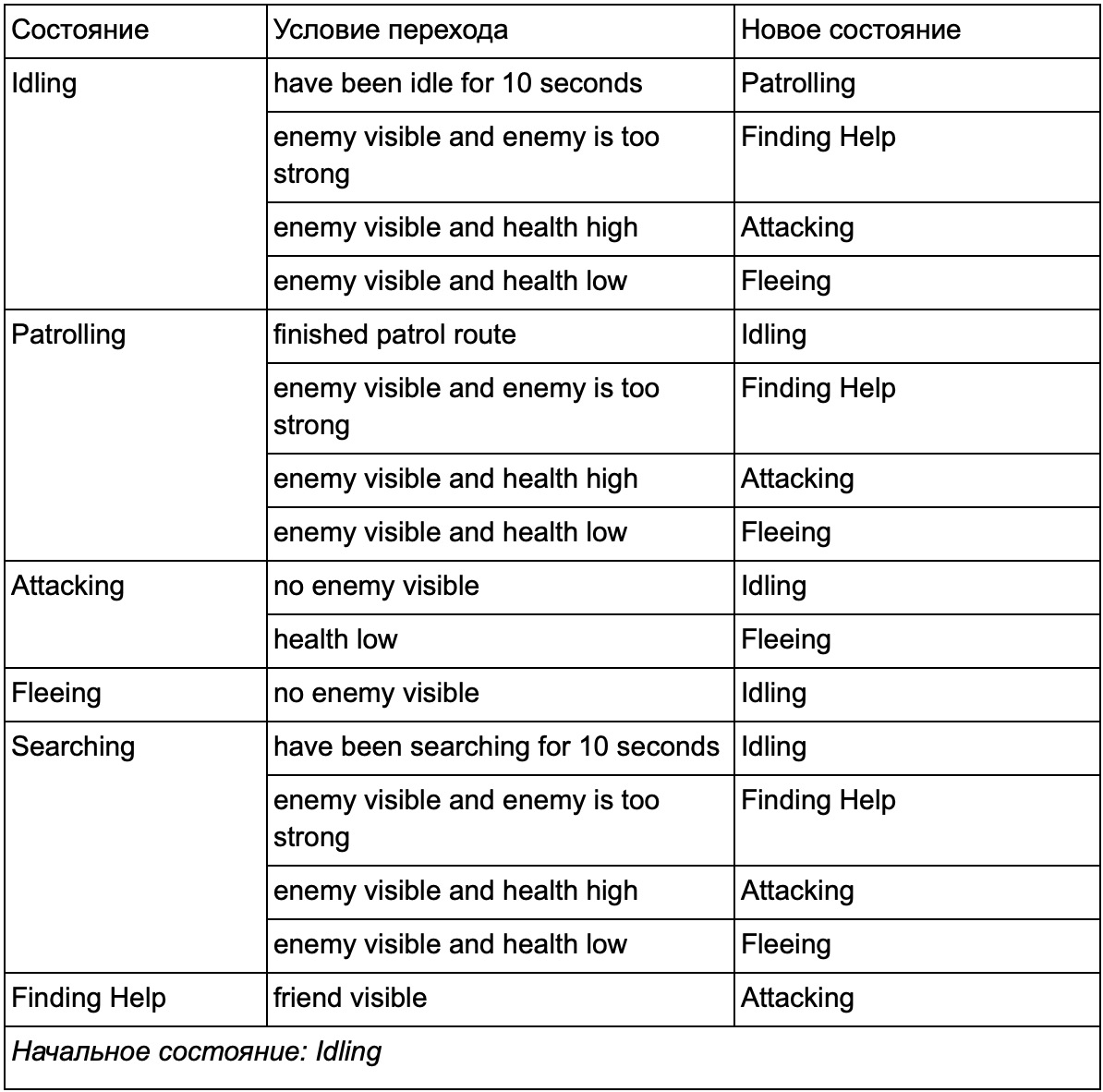
Cette table de transition d'état est un moyen complet de représenter FSM. Dessinons un diagramme et obtenons un aperçu complet de la façon dont le comportement des PNJ change.
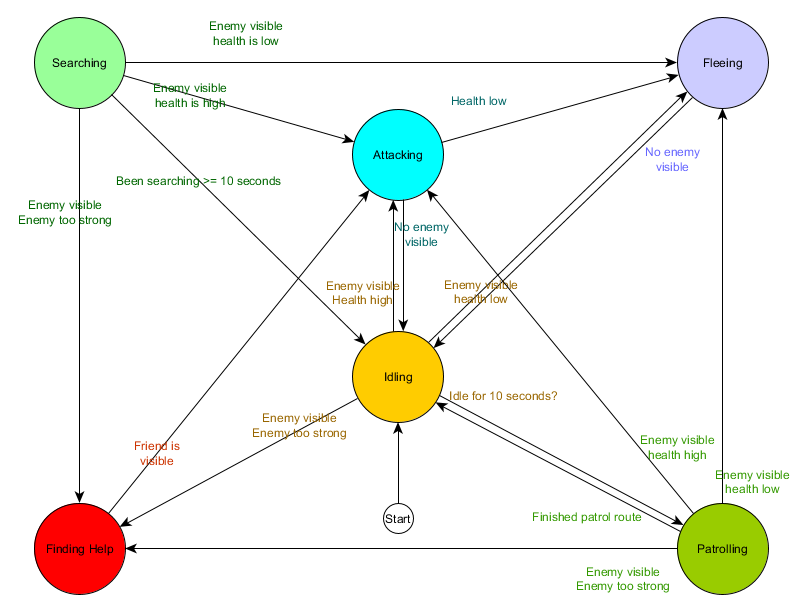
Le graphique reflète l'essence de la prise de décision pour cet agent en fonction de la situation actuelle. De plus, chaque flèche montre une transition entre les états si la condition à côté d'elle est vraie.
A chaque mise à jour, on vérifie l'état actuel de l'agent, on regarde la liste des transitions, et si les conditions de la transition sont remplies, il prend un nouvel état. Par exemple, chaque trame vérifie si le temporisateur de 10 secondes a expiré, et si c'est le cas, le protecteur passe de la marche au ralenti à la patrouille. De la même manière, l'état Attaque vérifie la santé de l'agent - s'il est faible, il passe à l'état Fuite.
Il s'agit de gérer les transitions d'états, mais qu'en est-il du comportement associé aux états eux-mêmes? Concernant l'implémentation du comportement réel pour un état particulier, il existe généralement deux types de «hooks» dans lesquels nous attribuons des actions au FSM:
- Actions que nous effectuons périodiquement pour l'état actuel.
- Les actions que nous entreprenons lors du passage d'un état à un autre.
Exemples pour le premier type. État de patrouille Chaque trame déplacera l'agent le long de l'itinéraire de patrouille. État d'attaque, chaque image tentera de lancer une attaque ou de passer dans un état lorsque cela sera possible.
Pour le deuxième type, considérez la transition «si l'ennemi est visible et l'ennemi est trop fort, passez à l'état Finding Help. L'agent doit choisir où aller pour obtenir de l'aide et enregistrer ces informations afin que l'état de recherche d'aide sache où aller. Dès que de l'aide est trouvée, l'agent revient à l'état Attaquant. À ce stade, il voudra informer l'allié de la menace, afin que l'action NotifyFriendOfThreat puisse se produire.
Et encore une fois, nous pouvons regarder ce système à travers le prisme du cycle Sense / Think / Act. Sense se traduit par des données utilisées par la logique de transition. Pensez - transitions disponibles dans chaque état. Et l'acte est réalisé par des actions effectuées périodiquement au sein de l'État ou lors de transitions entre États.
Parfois, l'interrogation continue des conditions de transition peut être coûteuse. Par exemple, si chaque agent effectue des calculs complexes sur chaque trame pour déterminer s'il voit des ennemis et comprendre s'il est possible de passer de l'état de patrouille à l'attaque, cela prendra beaucoup de temps au processeur.
Des changements importants dans l'état du monde peuvent être considérés comme des événements qui seront traités au fur et à mesure qu'ils se produisent. Au lieu que FSM vérifie la condition de transition «mon agent peut-il voir le joueur?» À chaque trame, vous pouvez configurer un système distinct pour effectuer des vérifications moins souvent (par exemple, 5 fois par seconde). Et le résultat est de donner au joueur vu lorsque le chèque est réussi.
Ceci est transmis au FSM, qui doit maintenant entrer dans la condition reçue de l'événement Joueur vu et réagir en conséquence. Le comportement résultant est le même sauf pour un délai presque imperceptible avant de répondre. Mais la performance est devenue meilleure à la suite de la séparation d'une partie de Sense dans une partie distincte du programme.
Machine à états finis hiérarchique
Cependant, travailler avec de grands FSM n'est pas toujours pratique. Si nous voulons étendre l'état de l'attaque, en la remplaçant par MeleeAttacking (mêlée) et RangedAttacking (à distance) séparés, nous devrons changer les transitions de tous les autres états qui mènent à l'état Attacking (actuel et futur).
Vous avez sûrement remarqué que dans notre exemple, il y a beaucoup de transitions en double. La plupart des transitions à l'état de ralenti sont identiques aux transitions à l'état de patrouille. Ce serait bien de ne pas répéter, surtout si nous ajoutons des états plus similaires. Il est logique de regrouper la marche au ralenti et les patrouilles sous l'étiquette commune de «non-combat», où il n'y a qu'un seul ensemble commun de transitions pour combattre les États. Si nous présentons cette étiquette comme un état, la marche au ralenti et la patrouille deviendront des sous-états. Un exemple d'utilisation d'une table de conversion distincte pour un nouveau sous-état sans combat:
Les principales conditions: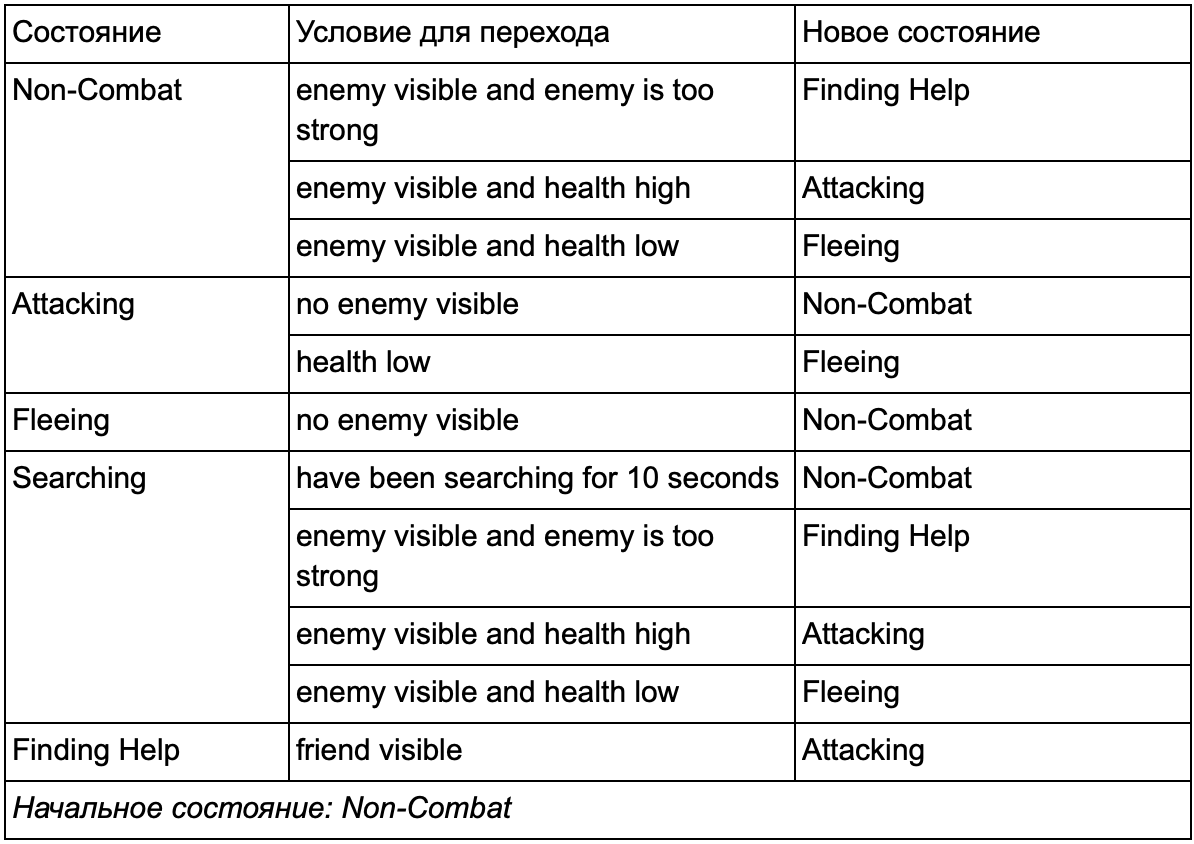 Statut hors combat:
Statut hors combat:
Et sous forme de graphique:
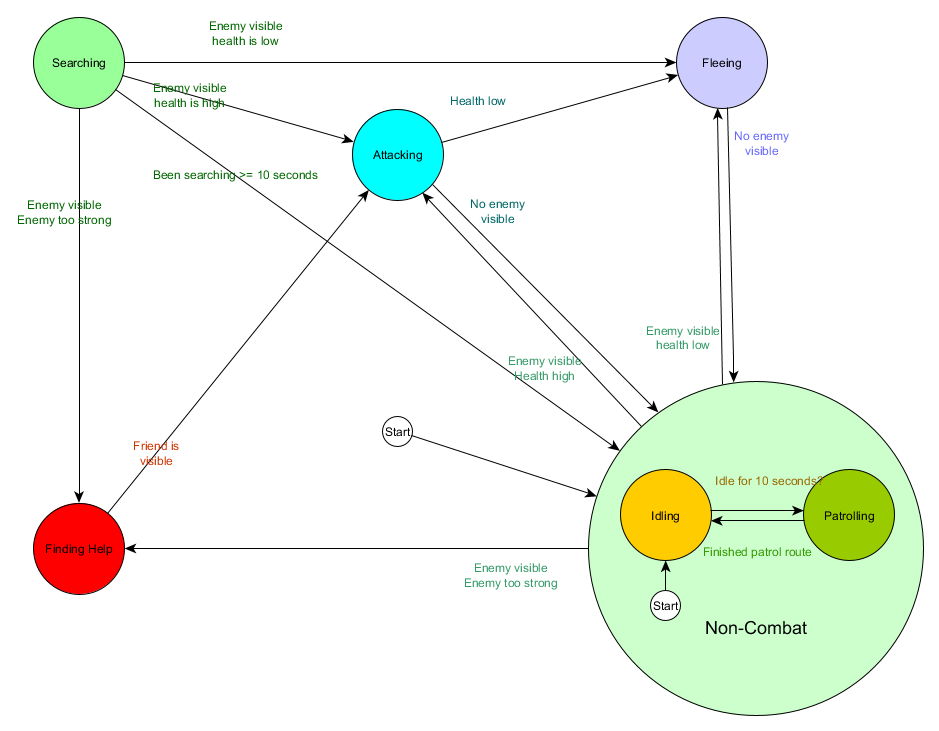
Il s'agit du même système, mais avec un nouvel état de non-combat, qui inclut la marche au ralenti et la patrouille. Avec chaque état contenant des FSM avec des sous-états (et ces sous-états, à leur tour, contiennent leurs propres FSM - et ainsi de suite, autant que vous en avez besoin), nous obtenons une machine à états finis hiérarchique ou HFSM (machine à états hiérarchique). Ayant regroupé un état non combattant, nous avons supprimé un tas de transitions redondantes. Nous pouvons faire de même pour tous les nouveaux États ayant des transitions communes. Par exemple, si à l'avenir nous étendons l'état d'attaque aux états de mêlée et d'attaque de missiles, ce seront des sous-états qui se croiseront en fonction de la distance à l'ennemi et de la présence de munitions. En conséquence, des modèles de comportement complexes et des sous-modèles de comportement peuvent être représentés avec un minimum de transitions dupliquées.
HFSM . , , . , . . , , . , 25%, , , , — . 25% 10%, .
, « », , . .
, : «» , , , . :
- : Succeeded ( ), Failed ( ) Running ( ).
- . Decorator, . Succeed, .
- , , Running .
. HFSM :
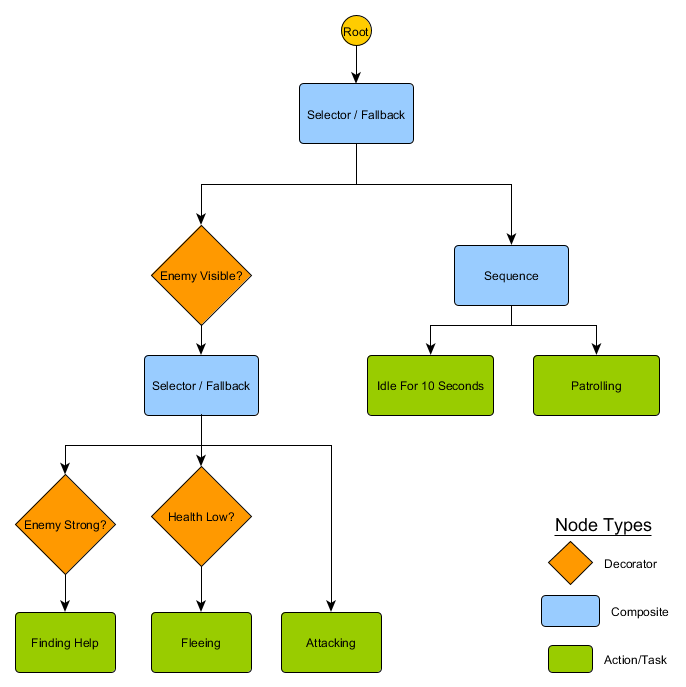
Idling/Patrolling Attacking . , , Fleeing, , — Patrolling, Idling, Attacking .
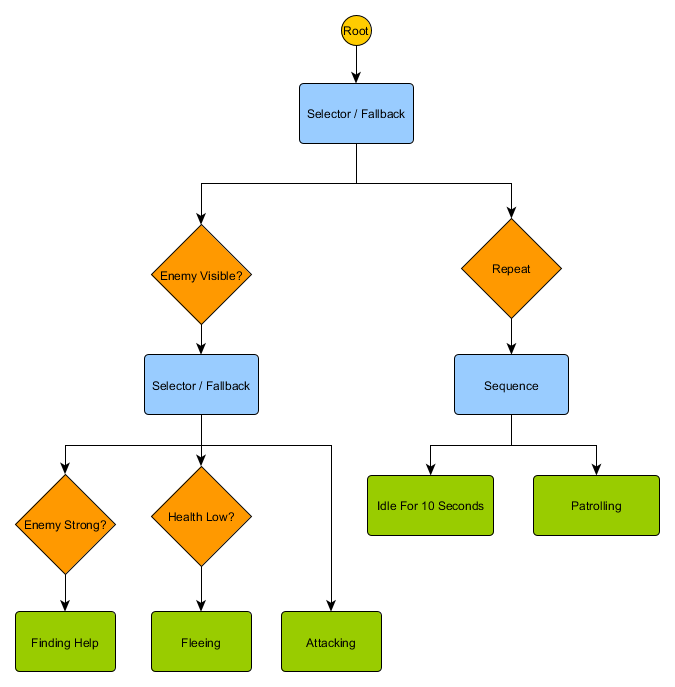
— , . , — , ? , — , Idling 10 , , ?
. , . , .
Utility-based system
. , , . , , .
Utility-based system (, ) . , , , . — , .
, . FSM, , , . , ( , ). , .
— , 0 ( ) 100 ( ). , . :

— . . , , , Fleeing, FindingHelp . FindingHelp . , 50, . .
, . . , Fleeing , , Attacking , . - Fleeing Attacking , , . , , FSM.
. . The Sims, , — «», . , , EatFood , , , EatFood .
, Utility-based system , . . , Utility , , .
, , , . ? , , , , ? .
, , , . , , . . Sense/Think/Act, , Think , Act . , , . — , . , , . :
desired_travel = destination_position – agent_position2D-. (-2,-2), - - (30, 20), , — (32, 22). , — 5 , (4.12, 2.83). 8 .
. , , 5 / ( ), . , .
— , , , . . steering behaviours, : Seek (), Flee (), Arrival () . . , , , .
. Seek Arrival — . Obstacle Avoidance ( ) Separation () , . Alignment () Cohesion () . steering behaviours . , Arrival, Separation Obstacle Avoidance, . .
, — , - Arrival Obstacle Avoidance. , , . : , .
, , - .
Steering behaviours ( ), — . pathfinding ( ), .
— . - , , . . , ( , ). , Breadth-First Search BFS ( ). ( breadth, «»). , , — , , .
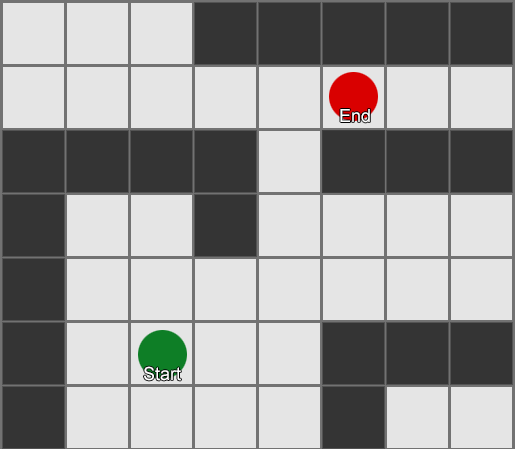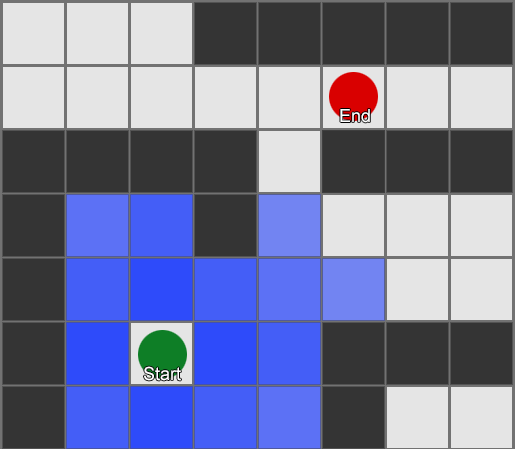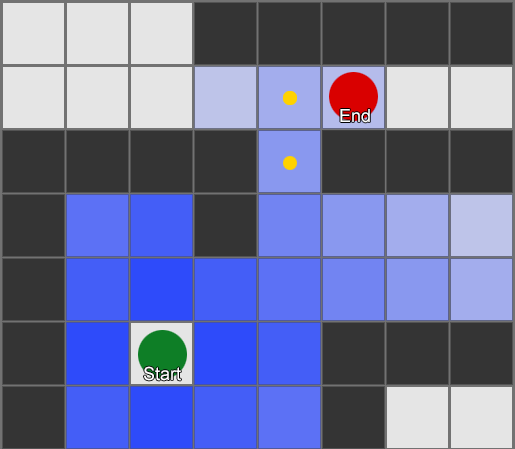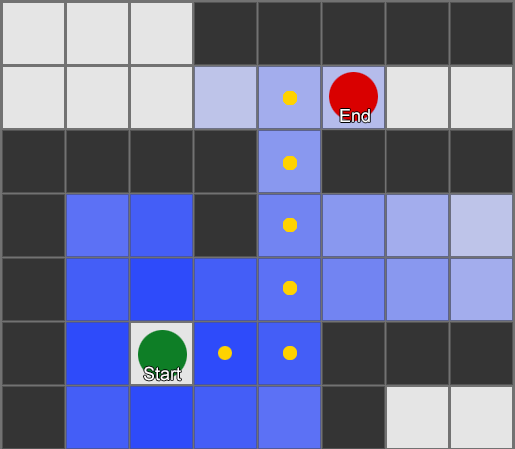
, . (, pathfinding) — , , .
, , steering behaviours, — 1 2, 2 3 . — , — . - .
BFS — «» , «». A* (A star). , - ( , ), , , . , — «» ( ) , ( ).
, , , . , BFS, — .
Mais la plupart des jeux ne sont pas disposés sur la grille, et souvent cela ne peut se faire sans compromettre le réalisme. Des compromis sont nécessaires. Quelle taille doivent avoir les carrés? Trop grand - et ils ne pourront pas imaginer correctement de petits couloirs ou virages, trop petits - il y aura trop de carrés à rechercher, ce qui prendra finalement beaucoup de temps.
La première chose à comprendre est que la grille nous donne un graphe de nœuds connectés. Les algorithmes A * et BFS fonctionnent réellement sur les graphiques et ne se soucient pas du tout de notre grille. Nous pourrions placer les nœuds n'importe où dans le monde du jeu: s'il y a une connexion entre deux nœuds connectés, ainsi qu'entre les points de début et de fin et au moins l'un des nœuds, l'algorithme fonctionnera aussi bien qu'avant. Ceci est souvent appelé le système de points de cheminement, car chaque nœud représente une position significative dans le monde, qui peut faire partie d'un nombre illimité de chemins hypothétiques.
 Exemple 1: un nœud dans chaque carré. La recherche commence au nœud où se trouve l'agent et se termine au nœud du carré souhaité.
Exemple 1: un nœud dans chaque carré. La recherche commence au nœud où se trouve l'agent et se termine au nœud du carré souhaité.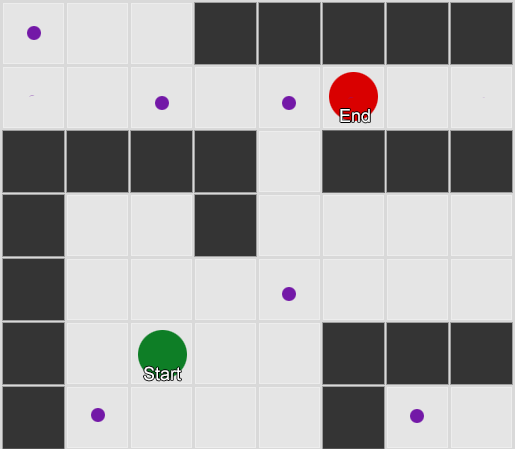 Exemple 2: un plus petit ensemble de nœuds (waypoints). La recherche commence au carré avec l'agent, passe par le nombre de nœuds requis, puis continue vers la destination.
Exemple 2: un plus petit ensemble de nœuds (waypoints). La recherche commence au carré avec l'agent, passe par le nombre de nœuds requis, puis continue vers la destination.Il s'agit d'un système complètement flexible et puissant. Mais vous devez être prudent lorsque vous décidez où et comment placer le point de cheminement, sinon les agents peuvent tout simplement ne pas voir le point le plus proche et ne pourront pas démarrer le chemin. Il serait plus facile de définir automatiquement des points de cheminement en fonction de la géométrie du monde.
Ensuite, un maillage de navigation ou un maillage de navigation apparaît. Il s'agit généralement d'un maillage 2D de triangles qui recouvre la géométrie du monde - partout où l'agent est autorisé à marcher. Chacun des triangles de la grille devient un nœud dans le graphique et a jusqu'à trois triangles adjacents qui deviennent des nœuds adjacents dans le graphique.
Cette image est un exemple du moteur Unity - il a analysé la géométrie dans le monde et créé navmesh (bleu clair dans la capture d'écran). Chaque polygone dans navmesh est une zone dans laquelle un agent peut se tenir ou se déplacer d'un polygone à un autre polygone. Dans cet exemple, les polygones sont plus petits que les étages sur lesquels ils se trouvent - réalisés afin de prendre en compte les dimensions de l'agent, qui iront au-delà de sa position nominale.

Nous pouvons rechercher l'itinéraire à travers cette grille, en utilisant à nouveau l'algorithme A *. Cela nous donnera un itinéraire presque parfait dans le monde qui prend en compte toute la géométrie et ne nécessite pas de nœuds et de waypoints supplémentaires.
Pathfinding est un sujet trop étendu sur lequel une section de l'article ne suffit pas. Si vous souhaitez l'étudier plus en détail, le
site d'Amit Patel vous y aidera.
Planification
Nous avons veillé à ce que, parfois, il ne suffit pas simplement de choisir une direction et de se déplacer - nous devons choisir un itinéraire et effectuer plusieurs virages pour arriver à la destination souhaitée. Nous pouvons résumer cette idée: atteindre l'objectif n'est pas seulement la prochaine étape, mais une séquence entière, où parfois vous devez regarder en avant quelques étapes pour savoir quelle devrait être la première. C'est ce qu'on appelle la planification. L'orientation peut être considérée comme l'un des nombreux ajouts de planification. Du point de vue de notre cycle Sense / Think / Act, c'est là que la partie Think planifie plusieurs parties Act pour l'avenir.
Prenons l'exemple du jeu de société Magic: The Gathering. Nous allons d'abord avec un tel jeu de cartes en main:
- Marais - donne 1 mana noir (carte de la Terre).
- Forêt - donne 1 mana vert (carte de la terre).
- Magicien fugitif - Nécessite 1 mana bleu pour invoquer.
- Mystique elfique - Nécessite 1 mana vert pour invoquer.
Nous ignorons les trois cartes restantes pour le rendre plus facile. Selon les règles, un joueur est autorisé à jouer 1 carte de terrain par tour, il peut «engager» cette carte pour en extraire du mana, puis utiliser des sorts (y compris des créatures invoquées) en fonction de la quantité de mana. Dans cette situation, le joueur humain sait que vous devez jouer à Forest, «taper» 1 mana vert, puis appeler Elvish Mystic. Mais comment devinez-vous l'IA du jeu?
Planification simple
L'approche triviale consiste à essayer chaque action à tour de rôle jusqu'à ce qu'il y en ait une appropriée. En regardant les cartes, l'IA voit ce que Swamp peut jouer. Et le joue. Y a-t-il d'autres actions à gauche ce tour-ci? Il ne peut invoquer ni Elfique Mystique ni Fugitif Magicien, car leurs invocations nécessitent respectivement du mana vert et bleu, et Swamp ne donne que du mana noir. Et il ne pourra pas jouer à Forest, car il a déjà joué à Swamp. Ainsi, l'IA du jeu a respecté les règles, mais l'a mal fait. Cela peut être amélioré.
La planification peut trouver une liste d'actions qui amènent le jeu à son état souhaité. Tout comme chaque carré sur le chemin avait des voisins (dans la recherche de chemin), chaque action du plan a aussi des voisins ou des successeurs. Nous pouvons rechercher ces actions et les actions suivantes jusqu'à ce que nous atteignions l'état souhaité.
Dans notre exemple, le résultat souhaité est «d'invoquer une créature, si possible». Au début du mouvement, nous ne voyons que deux actions possibles autorisées par les règles du jeu:
1. Jouer à Swamp (résultat: Swamp dans le jeu)
2. Jouer à Forest (résultat: Forest dans le jeu)Chaque action entreprise peut conduire à d'autres actions et en fermer d'autres, encore une fois, selon les règles du jeu. Imaginez que nous avons joué à Swamp - cela supprimera Swamp à l'étape suivante (nous l'avons déjà joué), cela supprimera également Forest (car selon les règles, vous pouvez jouer une carte du terrain par tour). Après cela, l'IA ajoute comme étape suivante - obtenir 1 mana noir, car il n'y a pas d'autres options. S'il va plus loin et choisit Tap the Swamp, il recevra 1 unité de mana noir et ne pourra rien en faire.
1. Jouer à Swamp (résultat: Swamp dans le jeu)
1.1 «Tap» Swamp (résultat: Swamp «tap», +1 unité de mana noir)
Aucune action disponible - FIN
2. Jouer à Forest (résultat: Forest dans le jeu)La liste des actions était courte, nous sommes dans une impasse. Répétez le processus pour l'étape suivante. Nous jouons à Forest, ouvrons l'action "obtenir 1 mana vert", qui à son tour ouvrira la troisième action - l'appel d'Elvish Mystic.
1. Jouer à Swamp (résultat: Swamp dans le jeu)
1.1 «Tap» Swamp (résultat: Swamp «tap», +1 unité de mana noir)
Aucune action disponible - FIN
2. Jouer à Forest (résultat: Forest dans le jeu)
2.1 Forêt «Tap» (résultat: «Tap» Forest, +1 unité de mana verte)
2.1.1 Invocation d'un elfique mystique (résultat: elfique mystique dans le jeu, -1 unité de mana vert)
Aucune action disponible - FINEnfin, nous avons examiné toutes les actions possibles et trouvé un plan appelant la créature.
Ceci est un exemple très simplifié. Il est conseillé de choisir le meilleur plan possible, et non celui qui répond à certains critères. En règle générale, vous pouvez évaluer les plans potentiels en fonction du résultat final ou des avantages totaux de leur mise en œuvre. Vous pouvez vous ajouter 1 point pour jouer une carte de la terre et 3 points pour défier une créature. Jouer à Swamp serait un plan donnant 1 point. Et pour jouer à Forest → Tap the Forest → faites appel à Elvish Mystic - il donnera immédiatement 4 points.
C'est ainsi que la planification fonctionne dans Magic: The Gathering, mais selon la même logique, cela s'applique dans d'autres situations. Par exemple, déplacez un pion pour faire de la place pour que l'évêque se déplace aux échecs. Ou couvrez-vous derrière un mur pour tirer en toute sécurité sur XCOM comme ça. En général, vous obtenez le point.
Planification améliorée
Parfois, il y a trop d'actions potentielles pour considérer toutes les options possibles. Revenons à l'exemple avec Magic: The Gathering: disons que dans le jeu et sur vos mains il y a plusieurs cartes de terrain et de créatures - le nombre de combinaisons possibles de mouvements peut être dans les dizaines. Il existe plusieurs solutions au problème.
La première façon est le chaînage arrière. Au lieu de trier toutes les combinaisons, il est préférable de commencer par le résultat final et d'essayer de trouver un itinéraire direct. Au lieu du chemin de la racine de l'arbre à une feuille spécifique, nous nous déplaçons dans la direction opposée - de la feuille à la racine. Cette méthode est plus simple et plus rapide.
Si l'adversaire a 1 unité de santé, vous pouvez trouver un plan pour "infliger 1 ou plusieurs unités de dégâts". Pour y parvenir, un certain nombre de conditions doivent être remplies:
1. Les dégâts peuvent être causés par un sort - ils devraient être dans la main.
2. Pour lancer un sort, vous avez besoin de mana.
3. Pour obtenir du mana, vous devez jouer une carte de terrain.
4. Pour jouer une carte de la terre - vous devez l'avoir en main.
Une autre méthode consiste à rechercher en priorité. Au lieu de parcourir tous les chemins, nous choisissons le plus approprié. Le plus souvent, cette méthode donne un plan optimal sans frais de recherche inutiles. A * est la forme de la meilleure première recherche - en explorant les itinéraires les plus prometteurs dès le début, il peut déjà trouver la meilleure façon sans avoir à vérifier d'autres options.
Monte Carlo Tree Search est une option intéressante et de plus en plus populaire pour la recherche du meilleur avant tout. Au lieu de deviner quels plans sont meilleurs que d'autres lors du choix de chaque action suivante, l'algorithme sélectionne des successeurs aléatoires à chaque étape jusqu'à la fin (lorsque le plan a conduit à la victoire ou à la défaite). Ensuite, le résultat final est utilisé pour augmenter ou diminuer la pondération des options précédentes. Répétant ce processus plusieurs fois de suite, l'algorithme donne une bonne estimation de la prochaine étape qui est la meilleure, même si la situation change (si l'adversaire prend des mesures pour empêcher le joueur).
L'histoire de la planification dans les jeux ne se fera pas sans la planification d'actions orientées vers les objectifs ou GOAP (planification d'actions orientées vers les objectifs). C'est une méthode largement utilisée et discutée, mais à part quelques détails distinctifs, c'est essentiellement la méthode de chaînage vers l'arrière dont nous avons parlé plus tôt. Si la tâche était de «détruire le joueur», et que le joueur est à couvert, le plan peut être le suivant: détruire avec une grenade → le récupérer → le laisser tomber.
Il y a généralement plusieurs objectifs, chacun avec sa propre priorité. Si l'objectif avec la priorité la plus élevée ne peut pas être atteint (aucune combinaison d'actions ne crée un plan pour «détruire le joueur» parce que le joueur n'est pas visible), l'IA retournera aux cibles avec une priorité inférieure.
Formation et adaptation
Nous avons déjà dit que l'IA de jeu n'utilise généralement pas le machine learning car elle n'est pas adaptée à la gestion des agents en temps réel. Mais cela ne signifie pas que vous ne pouvez rien emprunter dans cette région. Nous voulons un tel adversaire dans un jeu de tir à partir duquel nous pouvons apprendre quelque chose. Par exemple, découvrez les meilleures positions sur la carte. Ou un adversaire dans un jeu de combat qui bloquerait les combos fréquemment utilisés par le joueur, motivant les autres à utiliser. L'apprentissage automatique dans de telles situations peut donc être très utile.
Statistiques et probabilités
Avant de passer à des exemples complexes, nous allons estimer jusqu'où nous pouvons aller en prenant quelques mesures simples et en les utilisant pour prendre des décisions. Par exemple, une stratégie en temps réel - comment déterminer si un joueur peut lancer une attaque dans les premières minutes d'une partie et quelle défense se préparer contre cela? Nous pouvons étudier l'expérience passée du joueur pour comprendre quelle pourrait être la réaction future. Pour commencer, nous ne disposons pas de telles données initiales, mais nous pouvons les collecter - chaque fois que l'IA joue contre une personne, il peut enregistrer l'heure de la première attaque. Après plusieurs sessions, nous obtiendrons le temps moyen pendant lequel le joueur attaquera à l'avenir.
Les valeurs moyennes ont un problème: si un joueur «décide» 20 fois et joue lentement 20 fois, alors les valeurs nécessaires seront quelque part au milieu, et cela ne nous donnera rien d'utile. Une solution consiste à limiter l'entrée - vous pouvez considérer les 20 dernières pièces.
Une approche similaire est utilisée pour évaluer la probabilité de certaines actions, en supposant que les préférences passées du joueur seront les mêmes à l'avenir. Si un joueur nous attaque cinq fois avec une boule de feu, deux fois avec la foudre et une fois avec le corps à corps, il est évident qu'il préfère une boule de feu. Nous extrapolons et voyons la probabilité d'utiliser diverses armes: boule de feu = 62,5%, foudre = 25% et mêlée = 12,5%. Notre IA de jeu doit se préparer à la protection contre les incendies.
Une autre méthode intéressante consiste à utiliser le Naive Bayes Classifier (classificateur bayésien naïf) pour étudier de grands volumes de données d'entrée et classer la situation afin que l'IA réponde de la bonne manière. Les classificateurs bayésiens sont surtout connus pour utiliser des filtres anti-spam de messagerie. Là, ils recherchent des mots, les comparent à l'endroit où ces mots sont apparus plus tôt (dans le spam ou non) et tirent des conclusions sur les lettres entrantes. Nous pouvons faire de même, même avec moins d'entrée. Sur la base de toutes les informations utiles que l'IA voit (par exemple, quelles unités ennemies sont créées, ou quels sorts elles utilisent, ou quelles technologies elles ont explorées), et le résultat final (guerre ou paix, "écraser" ou défendre, etc.) - nous sélectionnerons le comportement AI souhaité.
Toutes ces méthodes de formation sont suffisantes, mais il est conseillé de les utiliser sur la base des données des tests. L'IA apprendra à s'adapter aux différentes stratégies utilisées par vos testeurs de jeu. Une IA qui s'adapte à un joueur après une sortie peut devenir trop prévisible, ou vice versa, trop complexe pour gagner.
Adaptation basée sur la valeur
Compte tenu du contenu de notre monde du jeu et des règles, nous pouvons changer l'ensemble de valeurs qui affectent la prise de décision, et pas seulement utiliser les données d'entrée. Nous faisons ceci:
- Laissez l'IA collecter des données sur l'état du monde et les événements clés pendant le jeu (comme indiqué ci-dessus).
- Modifions certaines valeurs importantes en fonction de ces données.
- Nous prenons nos décisions en fonction du traitement ou de l'évaluation de ces valeurs.
Par exemple, un agent dispose de plusieurs salles pour choisir un jeu de tir à la première personne sur la carte. Chaque chambre a sa propre valeur, ce qui détermine à quel point il est souhaitable de visiter. L'IA choisit au hasard la pièce à parcourir en fonction de la valeur de la valeur. Ensuite, l'agent se souvient dans quelle pièce il a été tué et réduit sa valeur (la probabilité qu'il y retourne). De même pour la situation inverse - si l'agent détruit de nombreux adversaires, la valeur de la salle augmente.
Modèle de Markov
Et si nous utilisons les données collectées pour les prévisions? Si nous nous souvenons de chaque pièce dans laquelle nous voyons le joueur pendant une certaine période de temps, nous prédirons dans quelle pièce le joueur peut entrer. En suivant et en enregistrant le mouvement du joueur dans les pièces (valeurs), nous pouvons les prédire.
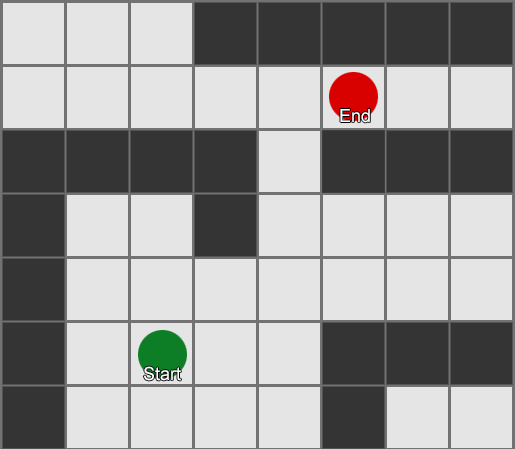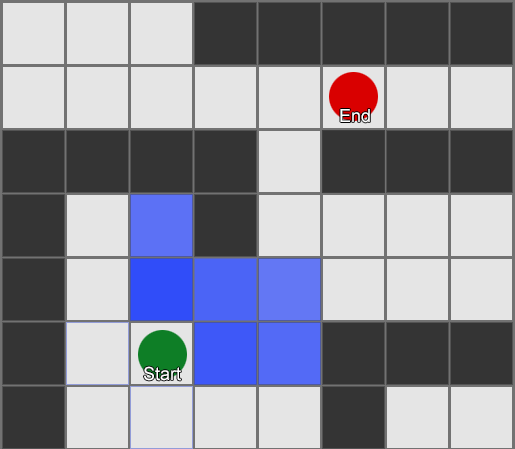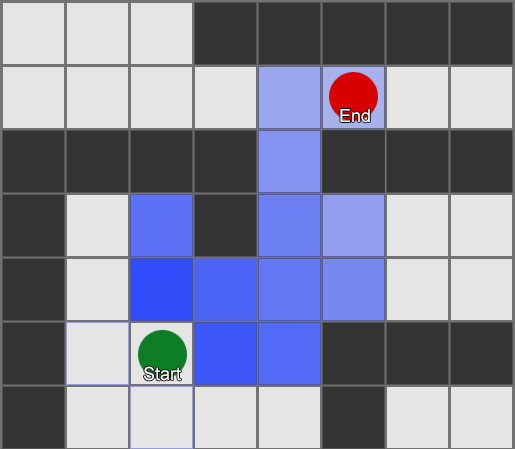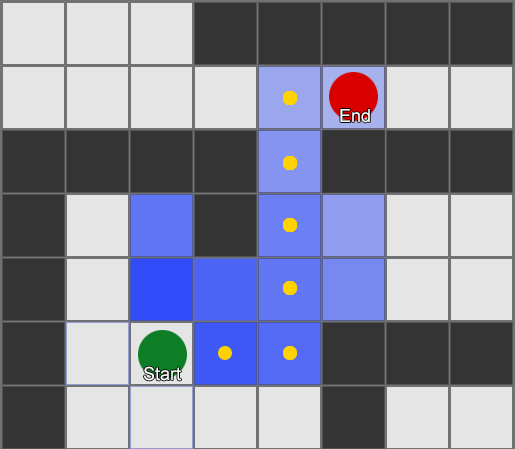
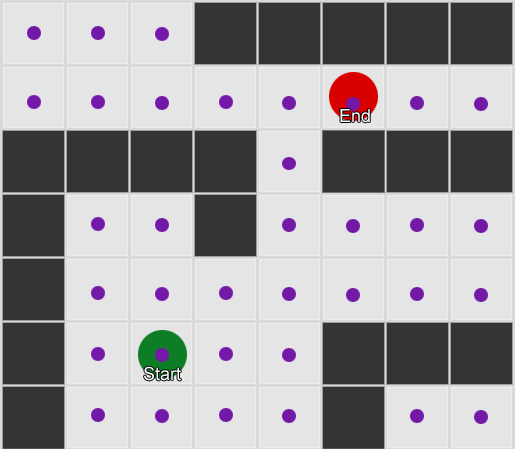
Prenons trois pièces: rouge, verte et bleue. Ainsi que les observations que nous avons enregistrées en regardant une session de jeu:
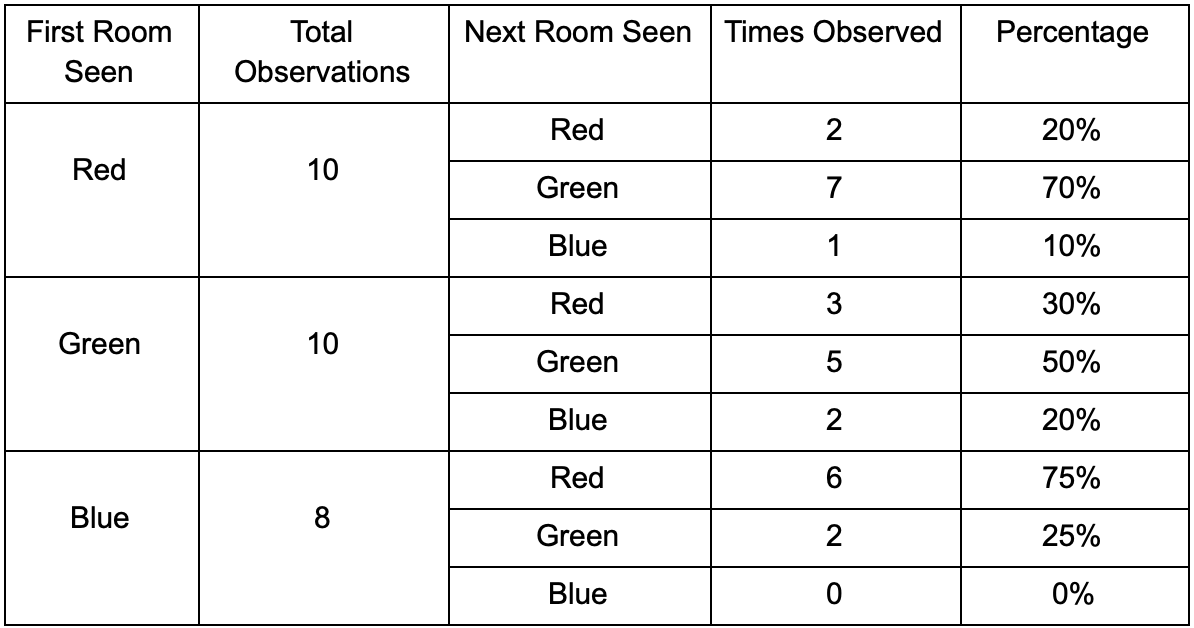
Le nombre d'observations pour chaque pièce est presque égal - nous ne savons toujours pas où faire une bonne place pour une embuscade. La collecte de statistiques est également compliquée par la réapparition de joueurs qui apparaissent uniformément sur la carte. Mais les données sur la pièce voisine, qu'elles entrent après avoir apparu sur la carte, sont déjà utiles.
On peut voir que la salle verte convient aux joueurs - la plupart des gens rouges y vont, dont 50% restent là et plus loin. La chambre bleue, au contraire, n'est pas populaire, elle n'est presque jamais visitée, et si elle l'est, elle ne s'attarde pas.
Mais les données nous disent quelque chose de plus important - lorsque le joueur est dans la salle bleue, la prochaine pièce dans laquelle nous le verrons le plus probablement sera rouge, pas verte. Malgré le fait que la salle verte soit plus populaire que la rouge, la situation change si le joueur est en bleu. L'état suivant (c'est-à-dire la pièce dans laquelle le joueur ira) dépend de l'état précédent (c'est-à-dire la pièce dans laquelle le joueur se trouve maintenant). Grâce à l'étude des dépendances, nous ferons des prévisions plus précises que si nous calculions simplement les observations indépendamment les unes des autres.
La prédiction d'un état futur sur la base de données d'état passées s'appelle le modèle de Markov, et de tels exemples (avec des pièces) sont appelés chaînes de Markov. Étant donné que les modèles représentent la probabilité de changements entre les états successifs, ils sont visuellement affichés sous forme de FSM avec une probabilité proche de chaque transition. Auparavant, nous utilisions FSM pour représenter l'état comportemental dans lequel l'agent se trouvait, mais ce concept s'applique à n'importe quel état, qu'il soit lié à l'agent ou non. Dans ce cas, les états représentent la chambre occupée par l'agent:
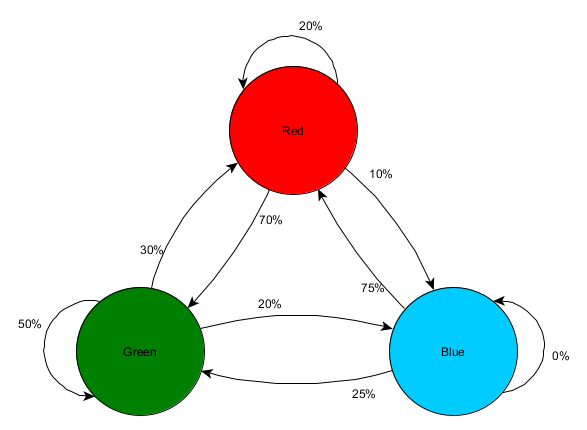
Il s'agit d'une version simple de la représentation de la probabilité relative de changements d'états, ce qui donne à l'IA l'occasion de prédire l'état suivant. Vous pouvez prévoir quelques pas en avant.
Si le joueur est dans la salle verte, il y a 50% de chances qu'il y reste lors de la prochaine observation. Mais quelle est la probabilité qu'il soit toujours là même après? Il y a non seulement une chance que le joueur soit resté dans la salle verte après deux observations, mais aussi une chance qu'il soit parti et soit revenu. Voici le nouveau tableau avec les nouvelles données:
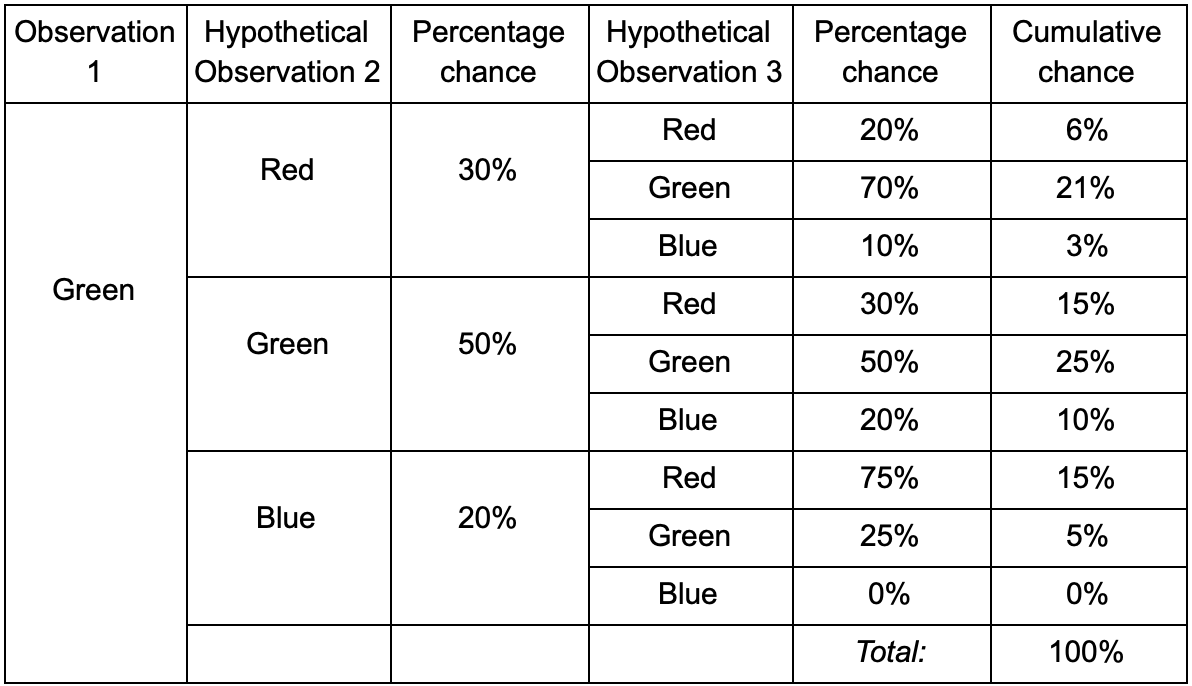
Cela montre que la chance de voir un joueur dans la salle verte après deux observations sera de 51% - 21%, qu'il viendra de la salle rouge, 5% d'entre eux, que le joueur visitera la salle bleue entre eux, et 25%, que le joueur ne le fait pas quittera la salle verte.
Un tableau n'est qu'un outil visuel - une procédure ne nécessite qu'une multiplication des probabilités à chaque étape. Cela signifie que vous pouvez regarder loin dans l'avenir avec un seul amendement: nous supposons que la chance d'entrer dans une pièce dépend complètement de la pièce actuelle. C'est ce qu'on appelle la propriété Markov - l'état futur ne dépend que du présent. Mais ce n'est pas tout à fait exact. Les joueurs peuvent prendre des décisions en fonction d'autres facteurs: le niveau de santé ou la quantité de munitions. Comme nous ne fixons pas ces valeurs, nos prévisions seront moins précises.
N-grammes
- ? La même chose! , , -.
— (, Kick, Punch Block) . , Kick, Kick, Punch, SuperDeathFist, , .
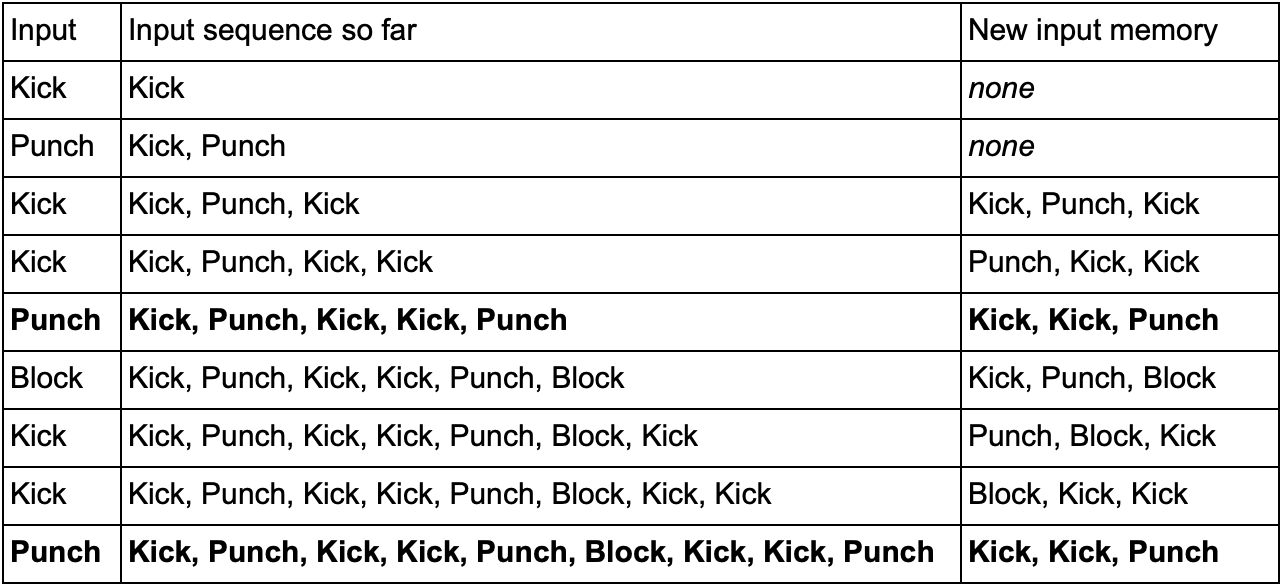
( , SuperDeathFist.)
, Kick, Kick, , Punch. - SuperDeathFist , .
N- (N-grams), N — . 3- (), : . 5- .
N-. N , . , 2- () Kick, Kick Kick, Punch, Kick, Kick, Punch, SuperDeathFist.
, , . Kick, Punch Block, 10-, 60 .
— « / » , . 3- N- , ( N-) , — . Kick Kick Kick Punch. , , , . , , - .
Conclusion
. , .
. , , . , :
- , ,
- / (minimax alpha-beta pruning)
- (, )
- ( , )
- ( )
- ( , anytime, timeslicing)
- :
1. GameDev.net
,
.
2.
AiGameDev.com .
3.
The GDC Vault GDC AI, .
4.
AI Game Programmers Guild .
5. , , YouTube-
AI and Games .
:
1. Game AI Pro , , .
Game AI Pro: Collected Wisdom of Game AI ProfessionalsGame AI Pro 2: Collected Wisdom of Game AI ProfessionalsGame AI Pro 3: Collected Wisdom of Game AI Professionals2. AI Game Programming Wisdom — Game AI Pro. , .
AI Game Programming Wisdom 1AI Game Programming Wisdom 2AI Game Programming Wisdom 3AI Game Programming Wisdom 43.
Artificial Intelligence: A Modern Approach — . — .