Les articles précédents sur le blog d'entreprise ne contenaient pas une seule équipe de console, et nous avons décidé de rattraper notre retard.
Notre entreprise a une métrique conçue pour empêcher les gros fakaps sur l'hébergement partagé. Sur chaque serveur d'hébergement partagé, il existe un site de test sur WordPress, auquel on accède périodiquement.
Voici à quoi ressemble le site de test sur chaque serveur d'hébergement partagé
La vitesse et le succès de la réponse du site sont mesurés. Tout employé de l'entreprise peut consulter les statistiques générales et voir dans quelle mesure l'entreprise se porte bien. Peut voir le pourcentage de réponses réussies d'un site de test pour l'ensemble de l'hébergement ou pour un serveur spécifique. Il n'est pas nécessaire d'être un employé de l'entreprise - dans le panneau de configuration, les clients voient également des statistiques sur le serveur où se trouve leur compte.
Nous avons appelé cette métrique de disponibilité (le pourcentage de réponses réussies du site de test à toutes les demandes adressées au site de test). Pas un très bon nom, il est facile de le confondre avec uptime-which-total-time-after-last-reboot-server .
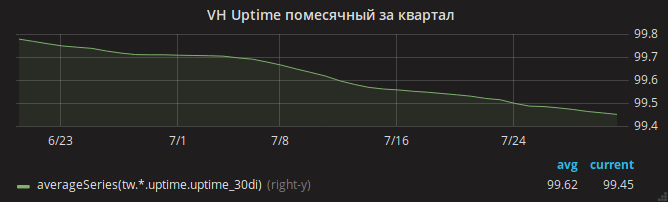
L'été est passé et le temps de disponibilité a lentement diminué.
Les administrateurs ont immédiatement identifié la raison - manque de RAM. Il était facile de voir les cas de MOO dans les journaux lorsque le serveur était à court de mémoire et que le noyau avait tué nginx.
Le chef du département, Andrey, divise une tâche en plusieurs à la main d'un assistant et les met en parallèle avec différents administrateurs. On va analyser les paramètres d'Apache - peut-être que les paramètres ne sont pas optimaux et avec beaucoup de trafic, Apache utilise toute la mémoire? Un autre analyse la consommation de mémoire de mysqld - tout à coup, il y a des paramètres obsolètes à partir du moment où l'hébergement partagé utilisait le système d'exploitation Gentoo? Le troisième examine les modifications récentes apportées aux paramètres de nginx.
Un par un, les administrateurs reviennent avec des résultats. Chacun a réussi à réduire la consommation de mémoire dans la zone qui lui était allouée. Dans le cas de nginx, par exemple, un mod_security inclus mais non utilisé a été détecté. Le MOO, quant à lui, est également fréquent.
Enfin, il est possible de remarquer que la consommation de mémoire centrale (en particulier, SUnreclaim) est terriblement importante sur certains serveurs. Ni dans la sortie ps ni dans htop ce paramètre n'est visible, donc nous ne l'avons pas remarqué tout de suite! Exemple de serveur avec SUnreclaim infernal:
root@vh28.timeweb.ru:~
24 gigaoctets de RAM sont donnés au noyau, et le noyau les dépense car personne ne sait quoi!
L'administrateur (appelons-le Gabriel) se précipite dans la bataille. Réassemble le noyau avec les options KMEMLEAK pour la détection des fuites.
Options de reconstructionPour activer KMEMLEAK, spécifiez simplement les options listées ci-dessous et chargez le noyau avec le paramètre kmemleak = on.
CONFIG_HAVE_DEBUG_KMEMLEAK=y CONFIG_DEBUG_KMEMLEAK=y CONFIG_DEBUG_KMEMLEAK_DEFAULT_OFF=y CONFIG_DEBUG_KMEMLEAK_EARLY_LOG_SIZE=10000
KMEMLEAK écrit (dans /sys/kernel/debug/kmemleak ) ces lignes:
unreferenced object 0xffff88013a028228 (size 8): comm "apache2", pid 23254, jiffies 4346187846 (age 1436.284s) hex dump (first 8 bytes): 00 00 00 00 00 00 00 00 ........ backtrace: [<ffffffff818570c8>] kmemleak_alloc+0x28/0x50 [<ffffffff811d450a>] kmem_cache_alloc_trace+0xca/0x1d0 [<ffffffff8136dcc3>] apparmor_file_alloc_security+0x23/0x40 [<ffffffff81332d63>] security_file_alloc+0x33/0x50 [<ffffffff811f8013>] get_empty_filp+0x93/0x1c0 [<ffffffff811f815b>] alloc_file+0x1b/0xa0 [<ffffffff81728361>] sock_alloc_file+0x91/0x120 [<ffffffff8172b52e>] SyS_socket+0x7e/0xc0 [<ffffffff81003854>] do_syscall_64+0x54/0xc0 [<ffffffff818618ab>] return_from_SYSCALL_64+0x0/0x6a [<ffffffffffffffff>] 0xffffffffffffffff unreferenced object 0xffff880d67030280 (size 624): comm "hrrb", pid 23713, jiffies 4346190262 (age 1426.620s) hex dump (first 32 bytes): 01 00 00 00 03 00 ff ff 00 00 00 00 00 00 00 00 ................ 00 e7 1a 06 10 88 ff ff 00 81 76 6e 00 88 ff ff ..........vn.... backtrace: [<ffffffff818570c8>] kmemleak_alloc+0x28/0x50 [<ffffffff811d4337>] kmem_cache_alloc+0xc7/0x1d0 [<ffffffff8172a25d>] sock_alloc_inode+0x1d/0xc0 [<ffffffff8121082d>] alloc_inode+0x1d/0x90 [<ffffffff81212b01>] new_inode_pseudo+0x11/0x60 [<ffffffff8172952a>] sock_alloc+0x1a/0x80 [<ffffffff81729aef>] __sock_create+0x7f/0x220 [<ffffffff8172b502>] SyS_socket+0x52/0xc0 [<ffffffff81003854>] do_syscall_64+0x54/0xc0 [<ffffffff818618ab>] return_from_SYSCALL_64+0x0/0x6a [<ffffffffffffffff>] 0xffffffffffffffff
Gabriel ne nous a pas révélé tous ses secrets et n'a pas expliqué comment, à partir des lignes ci-dessus, il a découvert la cause exacte de la fuite de mémoire. Très probablement, il a utilisé la commande addr2line /usr/lib/debug/lib/modules/`uname -r`/vmlinux ffffffff81722361 pour trouver la ligne exacte. Ou vient d'ouvrir le net/socket.c et de le regarder jusqu'à ce que le fichier devienne inconfortable.
Le problème s'est avéré être un correctif sur le net/socket.c , qui a été ajouté à notre référentiel il y a de nombreuses années. Son but est d'interdire aux clients d'utiliser l'appel système bind (), il s'agit d'une simple protection contre le serveur proxy démarré par les clients. Le patch a rempli son objectif, mais n'a pas effacé la mémoire après lui-même.
Peut-être qu'il y avait un nouveau malware à la mode en PHP qui tentait d'exécuter un serveur proxy en boucle - ce qui a conduit à des centaines de milliers d'appels bind () bloqués et à la perte de gigaoctets de RAM.
Ensuite, c'était simple - Gabriel a corrigé le correctif et reconstruit le noyau. Ajout de la surveillance de la valeur de SUnreclaim sur tous les serveurs exécutant Linux. Les ingénieurs ont averti les clients et ont redémarré l'hébergement dans le nouveau cœur.
OOM a disparu.
Mais le problème de la disponibilité des sites est resté
Sur tous les serveurs, le site de test a cessé de répondre plusieurs fois par jour.
Ici, l'auteur commençait à déchirer les cheveux sur différentes parties du corps. Mais Gabriel est resté calme et a activé l'enregistrement du trafic vers certaines parties des serveurs d'hébergement.
Dans le vidage du trafic, il a été constaté que le plus souvent la demande au site de test tombe après la réception soudaine d'un paquet TCP RST . En d'autres termes, la requête a atteint le serveur, mais la connexion a finalement été interrompue par nginx.
Encore plus intéressant! L'utilitaire strace lancé par Gabriel montre que le démon nginx n'envoie pas ce paquet. Comment est-ce possible, car seul nginx écoute sur le port 80?
La raison en était une combinaison de plusieurs facteurs:
- dans les paramètres nginx, l'option de
reuseport est reuseport (y compris l' SO_REUSEPORT socket SO_REUSEPORT ), qui permet à différents processus d'accepter des connexions à la même adresse et au même port - dans (à ce moment-là, la plus récente) version de nginx 1.13.0, il y a un bogue à cause duquel lors du démarrage du test de configuration
nginx -t via nginx -t et en utilisant l' SO_REUSEPORT ce processus de test nginx a vraiment commencé à écouter le port 80 et à intercepter les demandes de clients réels . Et à la fin du processus de test de configuration, les clients ont reçu la Connection reset by peer - enfin, lors de la surveillance du zabbix, la surveillance de l'exactitude de la configuration de nginx a été configurée sur tous les serveurs sur lesquels nginx est installé: la commande
nginx -t été appelée sur eux une fois par minute.
Ce n'est qu'après la mise à jour de nginx que vous pourrez expirer calmement. Le graphique de disponibilité des sites a augmenté.
Quelle est la morale de toute cette histoire? Soyez optimiste et évitez d'utiliser des noyaux auto-assemblés.