Maintenir une énorme base de code tout en garantissant une productivité élevée à un grand nombre de développeurs est un sérieux défi. Au cours des 5 dernières années, Yandex a développé un système spécial d'intégration continue. Dans cet article, nous parlerons de l'échelle de la base de code Yandex, du transfert du développement vers un référentiel unique avec une approche de développement basée sur les troncs, des tâches qu'un système d'intégration continue doit résoudre pour fonctionner efficacement dans de telles conditions.

Il y a de nombreuses années, Yandex n'avait pas de règles particulières dans le développement des services: chaque département pouvait utiliser toutes les langues, toutes les technologies, tous les systèmes de déploiement. Et comme la pratique l'a montré, une telle liberté n'a pas toujours aidé à avancer plus vite. À cette époque, pour résoudre les mêmes problèmes, il y avait souvent plusieurs développements propriétaires ou open source. Au fur et à mesure que l'entreprise grandissait, un tel écosystème fonctionnait moins bien. Dans le même temps, nous voulions rester un seul grand Yandex, et ne pas être scindé en plusieurs sociétés indépendantes, car cela donne beaucoup d'avantages: beaucoup de gens font les mêmes tâches, les résultats de leur travail peuvent être réutilisés. À partir d'une variété de structures de données, telles que des tables de hachage distribuées et des files d'attente sans verrouillage, et se terminant par un grand nombre de codes spécialisés différents que nous avons écrits sur 20 ans.
Beaucoup de tâches que nous résolvons ne résolvent pas dans le monde open-source. Il n'y a pas de MapReduce qui fonctionne bien sur nos volumes (5000+ serveurs) et nos tâches; il n'y a pas de traqueur de tâches qui peut gérer toutes nos dizaines de millions de tickets. C'est attrayant dans Yandex - vous pouvez faire de très grandes choses.
Mais nous perdons sérieusement en efficacité lorsque nous résolvons à nouveau les mêmes problèmes, refaisons des solutions toutes faites, rendant l'intégration entre les composants difficile. Il est bon et pratique de tout faire uniquement pour vous dans votre coin, vous ne pouvez pas penser aux autres pour le moment. Mais dès que le service deviendra suffisamment visible, il aura des dépendances. Il semble seulement que divers services dépendent faiblement les uns des autres, en fait - il y a beaucoup de connexions entre les différentes parties de l'entreprise. De nombreux services sont disponibles via l'application Yandex / Navigateur / etc., ou sont intégrés les uns aux autres. Par exemple, Alice apparaît dans le navigateur, en utilisant Alice, vous pouvez commander un taxi. Nous utilisons tous des composants communs: YT , YQL , Nirvana .
L'ancien modèle de développement avait des problèmes importants. En raison de la présence de nombreux référentiels, il est difficile pour un développeur ordinaire, en particulier un débutant, de découvrir:
- où est le composant?
- comment ça marche: il n'y a aucun moyen de "prendre et lire"
- Qui le développe et le soutient maintenant?
- comment commencer à l'utiliser?
En conséquence, le problème de l'utilisation mutuelle des composants s'est posé. Les composants ne pouvaient presque pas utiliser d'autres composants car ils représentaient des «boîtes noires» les unes pour les autres. Cela a affecté négativement l'entreprise, car non seulement les composants n'ont pas été réutilisés, mais ils ne se sont souvent pas améliorés. De nombreux composants ont été dupliqués, la quantité de code qui devait être prise en charge augmentait considérablement. Nous nous déplacions généralement plus lentement que possible.
Référentiel et infrastructure uniques
Il y a 5 ans, nous avons lancé un projet de transfert de développement vers un référentiel unique, avec des systèmes communs d'assemblage, de test, de déploiement et de surveillance.
L'objectif principal que nous voulions atteindre était de supprimer les obstacles qui empêchent l'intégration du code de quelqu'un d'autre. Le système doit fournir un accès facile au code de travail fini, un schéma clair pour sa connexion et son utilisation, la possibilité de collecte: les projets sont toujours collectés (et réussissent les tests).
À la suite du projet, une seule pile de technologies d'infrastructure pour l'entreprise a vu le jour: stockage du code source, système de révision du code, système de construction, système d'intégration continue, déploiement, surveillance.
Maintenant, la plupart du code source des projets Yandex est stocké dans un référentiel unique, ou est en train de le déplacer:
- Plus de 2000 développeurs travaillent sur des projets.
- plus de 50 000 projets et bibliothèques.
- La taille du référentiel dépasse 25 Go.
- Plus de 3 000 000 de validations ont déjà été validées dans le référentiel.
Avantages pour l'entreprise:
- tout projet du référentiel reçoit une infrastructure prête à l'emploi:
- un système de visualisation et de navigation du code source et un système de révision de code.
- système d'assemblage et assemblage distribué. Il s'agit d'un grand sujet distinct, et nous le couvrirons certainement dans les articles suivants.
- système d'intégration continue.
- déploiement, intégration avec le système de surveillance.
- partage de code, interaction d'équipe active.
- tout le code est commun, vous pouvez venir à un autre projet et y apporter les modifications dont vous avez besoin. Ceci est particulièrement important dans une grande entreprise, car une autre équipe dont vous avez besoin de quelque chose peut ne pas avoir les ressources. Avec le code commun, vous avez la possibilité de faire une partie du travail vous-même et «d'aider à réaliser» les changements dont vous avez besoin.
- Il y a une opportunité de refactoring global. Vous n'avez pas besoin de prendre en charge les anciennes versions de votre API ou bibliothèque, vous pouvez les modifier et modifier les emplacements où elles sont utilisées dans d'autres projets.
- le code devient moins "diversifié". Vous disposez d'un ensemble de moyens pour résoudre les problèmes, et il n'est pas nécessaire d'ajouter un autre moyen qui fait à peu près la même chose, mais avec de légères différences.
- dans le projet à côté de vous, il n'y aura probablement pas de langues et de bibliothèques absolument exotiques.
Il faut également comprendre qu'un tel modèle de développement présente des inconvénients qui doivent être pris en compte:
- Un référentiel partagé nécessite une infrastructure distincte et spécifique.
- la bibliothèque dont vous avez besoin n'est peut-être pas dans le référentiel, mais elle est en open-source. Il y a des coûts pour l'ajouter et le mettre à jour. Très dépendant de la langue et de la bibliothèque, quelque part presque gratuitement, quelque part très cher.
- vous devez constamment travailler sur la "santé" du code. Cela inclut au moins la lutte contre les dépendances inutiles et le code mort.
Notre approche d'un référentiel commun impose des règles générales que chacun doit suivre. Dans le cas de l'utilisation d'un référentiel unique, des restrictions sont placées sur les langues utilisées, les bibliothèques et les méthodes de déploiement. Mais dans le projet voisin, tout sera identique ou très similaire au vôtre, et vous pouvez même y réparer quelque chose.
Le modèle d'un référentiel commun gravite dans toutes les grandes entreprises. Le dépôt monolithique est un sujet vaste et bien étudié et discuté, donc maintenant nous n'entrerons pas dans les détails. Si vous voulez en savoir plus, à la fin de l'article, vous trouverez plusieurs liens utiles qui révèlent ce sujet plus en détail.
Conditions de fonctionnement du système d'intégration continue
Le développement est effectué selon le modèle de développement basé sur Trunk. La plupart des utilisateurs travaillent avec HEAD, ou la copie la plus récente du référentiel, obtenue à partir de la branche principale appelée trunk, dans laquelle le développement est en cours. La validation des modifications dans le référentiel se fait de manière séquentielle. Immédiatement après la validation, le nouveau code est visible et peut être utilisé par tous les développeurs. Le développement dans des branches distinctes n'est pas encouragé, bien que les branches puissent être utilisées pour les versions.
Les projets dépendent du code source. Les projets et les bibliothèques forment un graphique de dépendance complexe. Et cela signifie que les modifications apportées dans un projet affectent potentiellement le reste du référentiel.
Un grand flux de validations va au référentiel:
- plus de 2000 commits par jour.
- jusqu'à 10 changements par minute pendant les heures de pointe.
La base de code contient plus de 500 000 cibles de construction et tests.
Sans un système spécial d'intégration continue dans de telles conditions, il serait très difficile d'avancer rapidement.
Système d'intégration continue
Le système d'intégration continue lance des assemblages et des tests pour chaque changement:
- Contrôles préliminaires. Ils permettent de vérifier le code avant de valider et d'éviter de casser les tests dans le coffre. Les assemblages et les tests sont ensuite exécutés au-dessus de HEAD. À l'heure actuelle, les contrôles préalables à l'audit sont lancés volontairement. Pour les projets critiques, des vérifications préalables à l'audit sont requises.
- Vérifications après validation après validation dans le référentiel.
Les builds et les tests s'exécutent en parallèle sur de grands clusters de centaines de serveurs. Les builds et les tests s'exécutent sur différentes plateformes. Sous la plate-forme principale (linux), tous les projets sont assemblés et tous les tests exécutés, sous les autres plates-formes - un sous-ensemble de ceux configurables par l'utilisateur.
Après avoir reçu et analysé les résultats des assemblages et exécuté les tests, l'utilisateur reçoit des commentaires, par exemple, si les modifications interrompent les tests.

En cas de nouveaux échecs d'assemblage ou de tests, nous envoyons une notification aux propriétaires des tests et à l'auteur des modifications. Le système stocke et affiche également les résultats des contrôles dans une interface spéciale. L'interface Web du système d'intégration affiche la progression et le résultat du test, ventilés par type de test. L'écran avec les résultats de l'analyse peut maintenant ressembler à ceci:
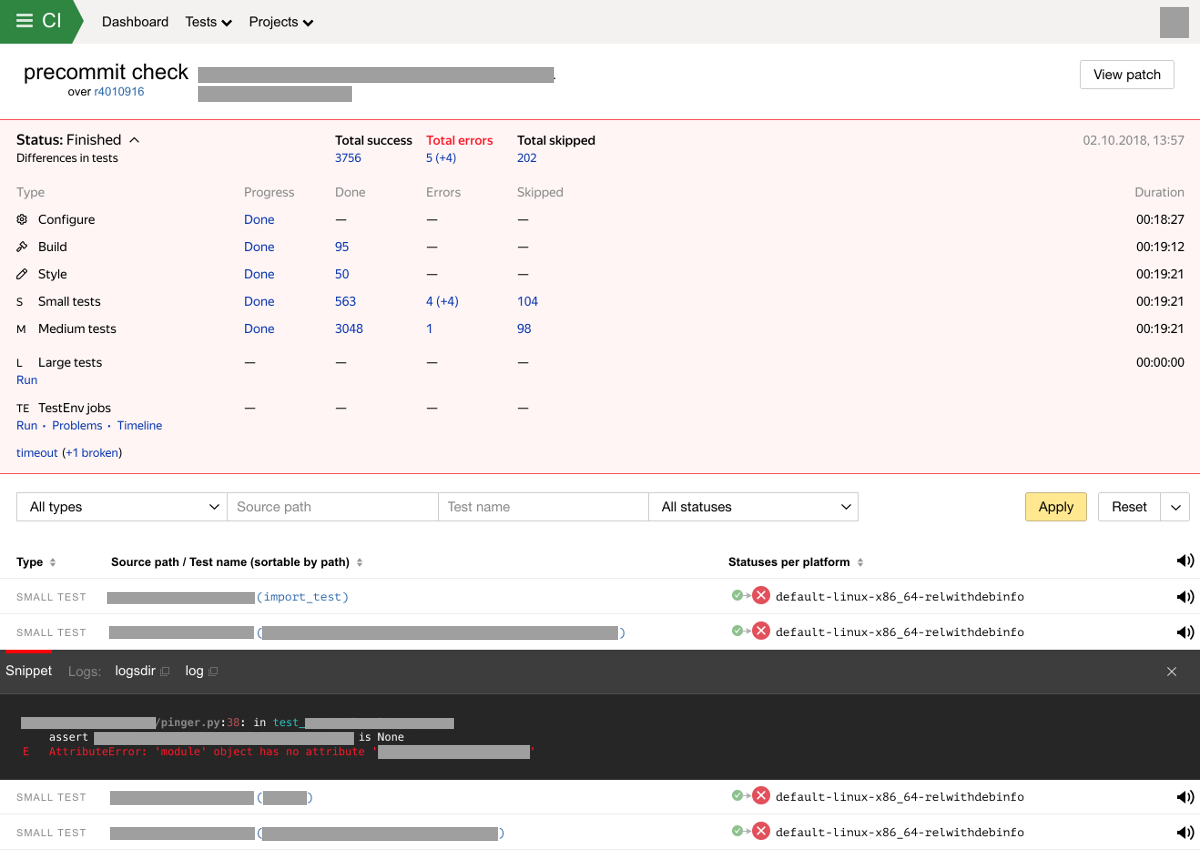
Caractéristiques et capacités du système d'intégration continue
Résolvant divers problèmes rencontrés par les développeurs et testeurs, nous avons développé notre système d'intégration continue. Le système résout déjà de nombreux problèmes, mais beaucoup reste à améliorer.
Types et tailles de tests
Il existe plusieurs types d'objectifs qu'un système d'intégration continue peut déclencher:
- configurer. Phase de configuration effectuée par le système de génération. La configuration comprend une analyse des fichiers de configuration du système d'assemblage, déterminant les dépendances entre les projets et les paramètres de l'assemblage et exécutant les tests.
- construire. Assemblage de bibliothèques et projets.
- style. À ce stade, le style de code correspond aux exigences spécifiées.
- test. Les tests sont divisés en étapes en fonction de leur délai d'expiration du temps de travail et des besoins en ressources informatiques.
- petit. <1 min
- moyen. <10 min
- grand. > 10 min De plus, il peut y avoir des exigences particulières pour les ressources informatiques.
- extra large. Il s'agit d'un type spécial de test. Ces tests se caractérisent par un ensemble des caractéristiques suivantes: un long temps de fonctionnement, une grande consommation de ressources, une grande quantité de données d'entrée, ils peuvent nécessiter des accès spéciaux et, surtout, la prise en charge des scénarios de test complexes décrits ci-dessous. Ces tests sont moins nombreux que les autres types de tests, mais ils sont très importants.
Tester la fréquence de lancement et la détection des défauts binaires
D'énormes ressources sont allouées pour les tests dans Yandex - des centaines de serveurs puissants. Mais même avec un grand nombre de ressources, nous ne pouvons pas exécuter tous les tests pour chaque changement qui les affecte. Mais en même temps, il est très important pour nous d'aider toujours le développeur à localiser l'endroit où le test se casse, en particulier dans un si grand référentiel.
Que faisons-nous. Pour chaque modification de tous les projets concernés, des assemblages, des vérifications de style et des tests avec des tailles petites et moyennes sont exécutés. Les autres tests ne sont pas exécutés pour chaque validation d'influence, mais avec une certaine périodicité, si des validations affectent les tests. Dans certains cas, les utilisateurs peuvent contrôler la fréquence de démarrage; dans d'autres cas, la fréquence de démarrage est définie par le système. Lorsqu'un échec de test est détecté, le processus de recherche d'un commit de rupture de test démarre. Moins le test s'exécute, plus nous rechercherons un commit de rupture après la détection d'un échec.

Lors du démarrage des vérifications préalables à l'audit, nous exécutons également uniquement des assemblages et des tests d'éclairage. Ensuite, l'utilisateur peut lancer manuellement le lancement de tests lourds en sélectionnant dans la liste des tests affectés par les modifications apportées par le système.
Détection de test clignotant
Les tests de clignotement sont des tests dont les résultats d'exécution (réussi / échoué) sur le même code peuvent dépendre de divers facteurs. Les causes des tests clignotants peuvent être différentes: sommeil dans le code de test, erreurs lors du travail avec le multithreading, problèmes d'infrastructure (indisponibilité de tout système), etc. Les tests de clignotement présentent un problème sérieux:
- Ils conduisent au fait que le système d'intégration continue spam de fausses alertes sur les échecs de test.
- Contaminer les résultats des tests. Il devient de plus en plus difficile de décider du succès des résultats de la vérification.
- Retarder la sortie des produits.
- Difficile à détecter. Les tests peuvent clignoter très rarement.
Les développeurs peuvent ignorer les tests clignotants lorsqu'ils analysent les résultats des tests. Parfois incorrect.
Il est impossible d'éliminer complètement les tests de clignotement, cela doit être pris en compte dans un système d'intégration continue.
Actuellement, pour chaque test, nous exécutons tous les tests deux fois pour détecter les tests clignotants. Nous prenons également en compte les réclamations des utilisateurs (destinataires des notifications). Si nous détectons un clignotement, nous marquons le test avec un drapeau spécial (muet) et informons le propriétaire du test. Après cela, seuls les propriétaires de tests recevront des notifications d'échecs de test. Ensuite, nous continuons d'exécuter le test en mode normal, tout en analysant l'historique de ses lancements. Si le test n'a pas clignoté dans une certaine fenêtre de temps, l'automatisation peut décider que le test a cessé de clignoter et vous pouvez effacer l'indicateur.
Notre algorithme actuel est assez simple et de nombreuses améliorations sont prévues à cet endroit. Tout d'abord, nous voulons utiliser des signaux beaucoup plus utiles.
Mise à jour automatique de l'entrée de test
Lors du test des systèmes Yandex les plus complexes, en plus des autres méthodes de test, le test de stratégie de boîte noire + le test basé sur les données est souvent utilisé. Pour garantir une bonne couverture, ces tests nécessitent un grand ensemble de données d'entrée. Les données peuvent être sélectionnées à partir de clusters de production. Mais il y a un problème avec le fait que les données deviennent rapidement obsolètes. Le monde ne s'arrête pas, nos systèmes évoluent constamment. Des données de test obsolètes au fil du temps ne fourniront pas une bonne couverture de test, puis conduiront complètement à une panne de test car les programmes commencent à utiliser de nouvelles données qui ne sont pas disponibles dans des données de test obsolètes.
Afin que les données ne deviennent pas obsolètes, le système d'intégration continue peut les mettre à jour automatiquement. Comment ça marche?
- Les données de test sont stockées dans un stockage spécial de ressources.
- Le test contient des métadonnées décrivant l'entrée requise.
- La correspondance entre l'entrée de test requise et les ressources est stockée dans un système d'intégration continue.
- Le développeur fournit une livraison régulière de nouvelles données au magasin de ressources.
- Le système d'intégration continue recherche les nouvelles versions des données de test dans le référentiel de ressources et commute les données d'entrée.
Il est important de mettre à jour les données afin que le faux test ne se produise pas. Vous ne pouvez pas simplement prendre et, à partir d'un certain commit, commencer à utiliser de nouvelles données, car en cas de panne de test, il ne sera pas clair qui est à blâmer - commit ou nouvelles données. Cela rendra également les tests diff (décrits ci-dessous) inopérants.

Par conséquent, nous faisons en sorte qu'il y ait un petit intervalle de validations, sur lequel le test est lancé avec les anciennes et les nouvelles versions des données d'entrée.

Tests de diff
Les tests diff, nous appelons un type spécial de tests basés sur les données , qui diffèrent de l'approche généralement acceptée en ce sens que le test n'a pas de résultat de référence, mais en même temps, nous devons trouver dans ce qui commet le test a changé son comportement.
L'approche standard des tests basés sur les données est la suivante. Le test a un résultat de référence obtenu lors du premier test. Le résultat de référence peut être stocké dans le référentiel à côté du test. Les exécutions suivantes du test devraient produire le même résultat.

Si le résultat diffère de la référence, le développeur doit décider si cette modification ou erreur attendue. Si la modification est attendue, le développeur doit mettre à jour le résultat de référence en même temps qu'il valide les modifications dans le référentiel.
Il existe des difficultés lors de l'utilisation de cette approche dans un grand référentiel avec des flux de validation importants:
- Il peut y avoir de nombreux tests et les tests peuvent être très difficiles. Le développeur n'a pas la possibilité d'exécuter tous les tests concernés dans un environnement de travail.
- Après avoir apporté des modifications, le test peut échouer si le résultat de référence n'a pas été mis à jour simultanément avec les modifications apportées au code. Ensuite, un autre développeur peut apporter des modifications au même composant et le résultat du test changera à nouveau. Nous obtenons l'imposition d'une erreur sur une autre. Il est très difficile de gérer de tels problèmes, cela prend du temps aux développeurs.
Que faisons-nous. Les tests de diff se composent de 2 parties:
- Vérifiez le composant.
- Nous commençons le test et enregistrons le résultat dans le stockage des ressources.
- Ne comparez pas le résultat avec la référence.
- Nous pouvons détecter certaines des erreurs, par exemple, le programme ne démarre pas / ne se termine pas, se bloque, le programme ne répond pas. La validation du résultat peut également être effectuée: présence de champs dans la réponse, etc.
- Composant diff.
- Comparez les résultats obtenus sur différents lancements et construisez diff. Dans le cas le plus simple, il s'agit d'une fonction qui prend 2 paramètres et renvoie diff.
- L'apparence de diff dépend du test, mais cela devrait être quelque chose de compréhensible pour quelqu'un qui regardera diff. Diff est généralement un fichier html.
Le lancement des composants check et diff est contrôlé par un système d'intégration continue.

Si le système d'intégration continue détecte diff, une recherche binaire est d'abord effectuée pour la validation qui a provoqué la modification. Après avoir reçu une notification du développeur, il devient possible d'étudier le diff et de décider quoi faire ensuite: reconnaître le diff comme prévu (pour cela, vous devez effectuer une action spéciale) ou réparer / "annuler" vos modifications.
À suivre
Dans le prochain article, nous parlerons du fonctionnement du système d'intégration continue.
Les références
Dépôt monolithique, développement basé sur tronc
Tests basés sur les données