Auparavant, sur Avito, vous pouviez trouver le bon produit en utilisant le filtrage par mots clés ou la navigation dans l'arborescence des catégories. Cette méthode, bien qu'elle paraisse familière, n'était pas toujours pratique - pour trouver un produit ou un service, il fallait faire un grand nombre de clics. Il y a plus d'un an, nous avons gagné en pertinence, grâce à quoi la recherche s'est améliorée, et maintenant il est plus facile et plus pratique de trouver un produit ou un service même sur la page principale. Avec cette innovation, des marchandises inadaptées et franchement «poubelles» ont cessé de tomber dans le problème. Et ce n'est là qu'une des étapes pour améliorer votre recherche. Nous modifions progressivement l'infrastructure, ce qui nous permet de travailler plus intensément sur la qualité de la recherche, de l'améliorer plus rapidement et de déployer de nouvelles fonctionnalités qui profitent aux vendeurs et aux acheteurs sur Avito.
Dans l'article, je vais vous dire comment la recherche sur Avito a changé: comment nous avons commencé et comment nous nous dirigeons maintenant vers l'amélioration de la vie de nos utilisateurs, et partagerai nos innovations à la fois dans le produit et dans son remplissage - la partie technique. Il n'y aura pas de viande hardcore ici, mais j'espère que vous l'apprécierez.

Quelques notes d'introduction: Avito est le service publicitaire le plus populaire en Russie. Nous avons plus de 450 000 annonces par jour et le nombre mensuel de visiteurs uniques atteint 35 millions, ce qui fait plus de 140 millions de recherches par jour.
Scénario de recherche typique avant
Regardons un exemple simple du fonctionnement d'une recherche il y a plus d'un an. Supposons que vous ayez besoin d'un piano (enfin, pourquoi pas?). On va à la page principale, on tape «piano».
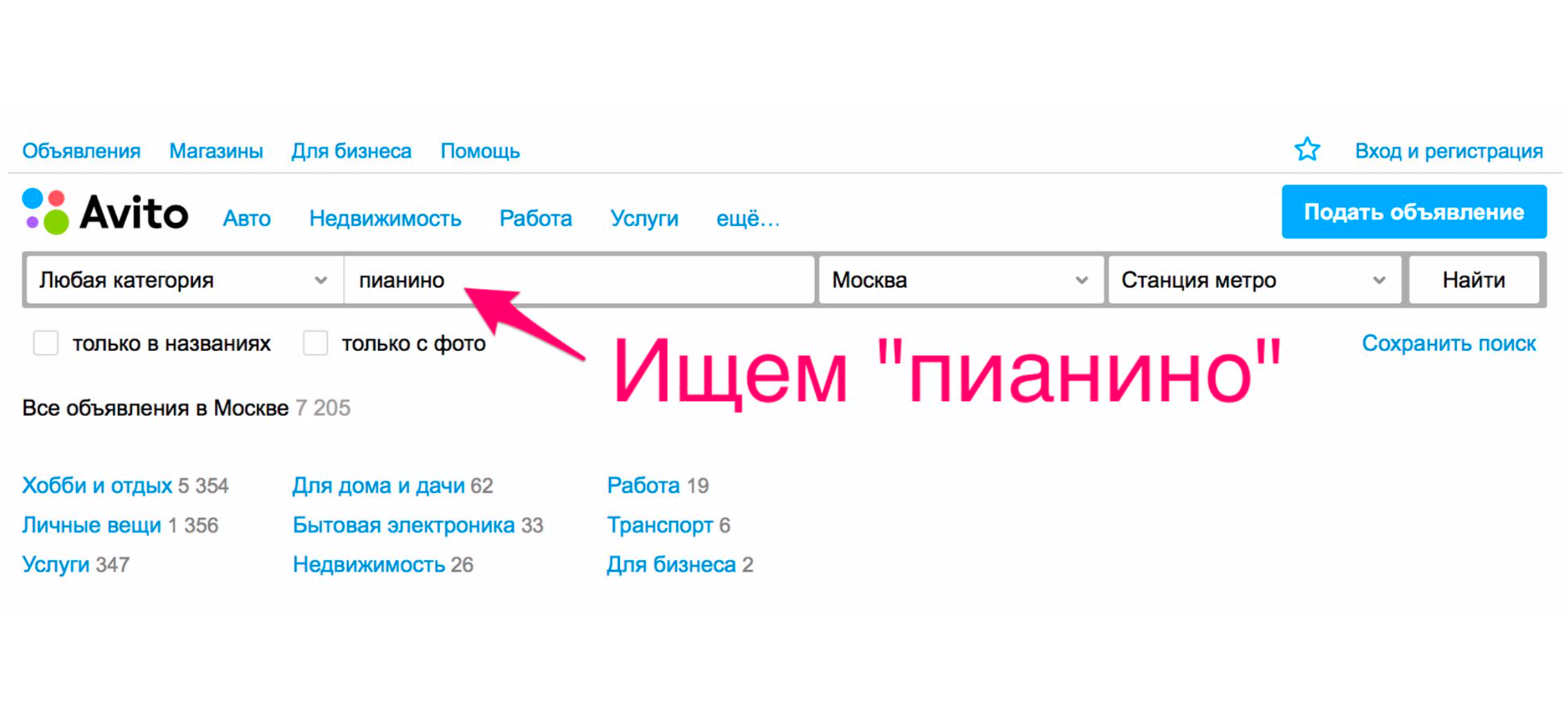
Dans le cadre de l'extradition, vous recevrez très probablement des déménageurs, des services de transport de piano ou quelque chose de similaire, mais pas un instrument de musique.

Cela se produit car nous aurons un tri par date de placement - et ces services sont placés le plus souvent.
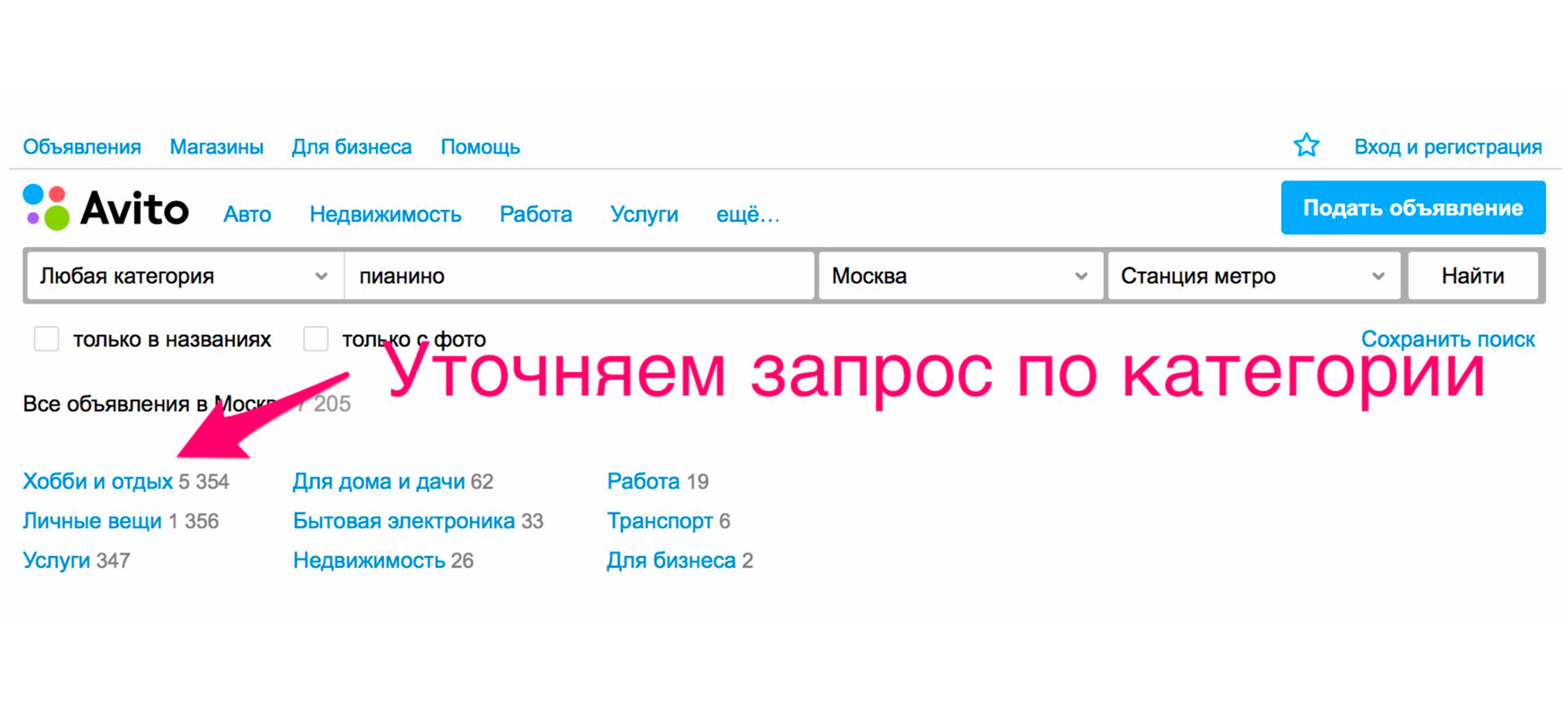
Pour voir le piano, vous devez spécifier la catégorie. On clique sur la rubrique "Hobbies et loisirs", on descend l'arborescence des catégories jusqu'à "Instruments de musique", puis "Instruments à clavier".
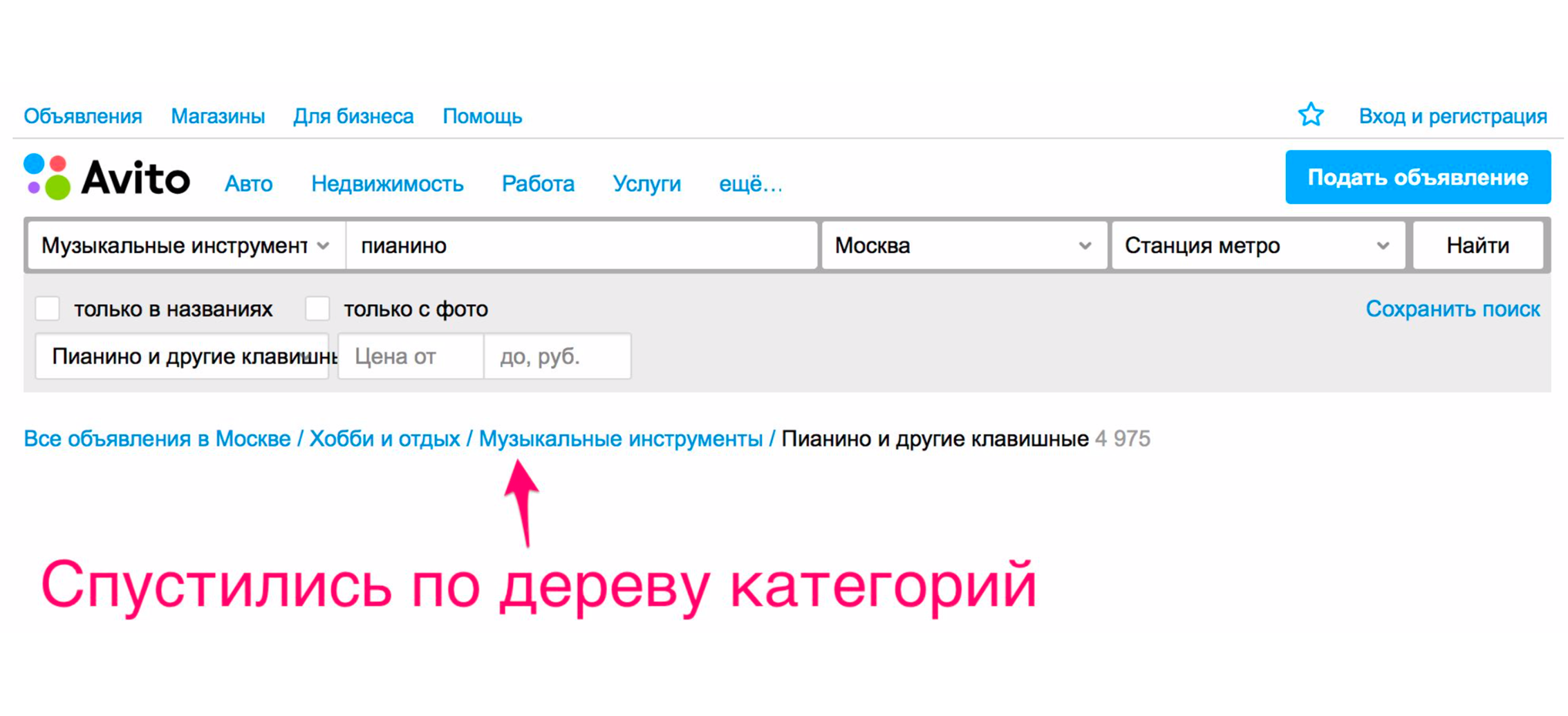
Et seulement après cela, nous voyons le piano que nous recherchions.
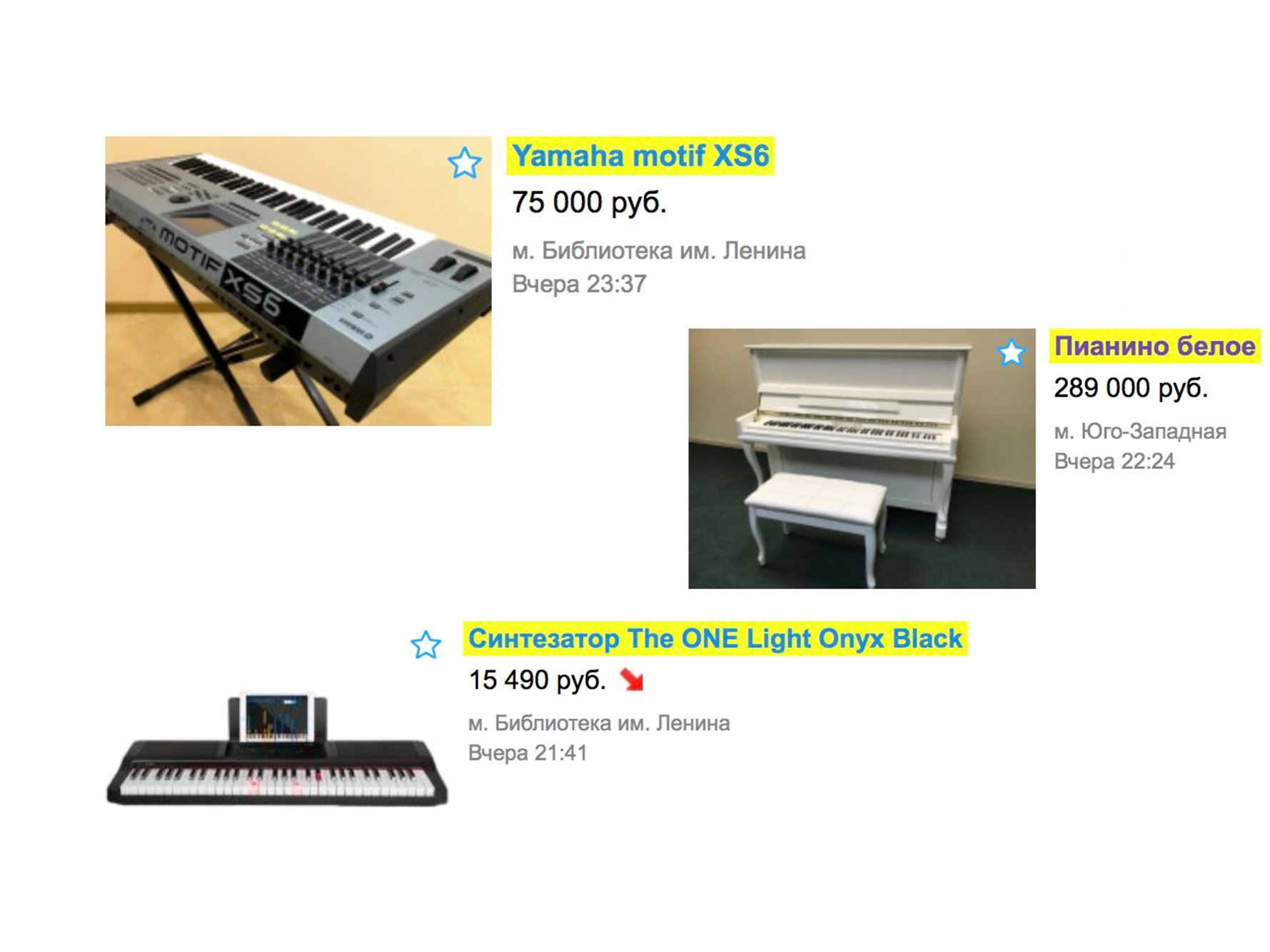
Il s'avère que pour trouver l'annonce souhaitée, il y avait les options suivantes:
- affinement de la catégorie lors de la recherche par mots-clés,
- tri par fraîcheur et prix,
- filtres
- rechercher uniquement par nom.
Ce qui a changé en raison de la pertinence
En raison de leur pertinence, les annonces qui ne correspondent pas du tout ont cessé d'être incluses dans l'émission. Maintenant, si vous cherchez un piano sur la page principale, vous ne verrez probablement pas les services de chargeurs qui vous aideront à le transporter, mais vous verrez immédiatement l'instrument de musique que vous voulez. Dans le même temps, un nouveau tri a été ajouté - «Par défaut». Il est formé de deux indicateurs: la pertinence de l'annonce par rapport à la requête de texte et la fraîcheur.

En haut, vous voyez le plus récent des plus pertinents.
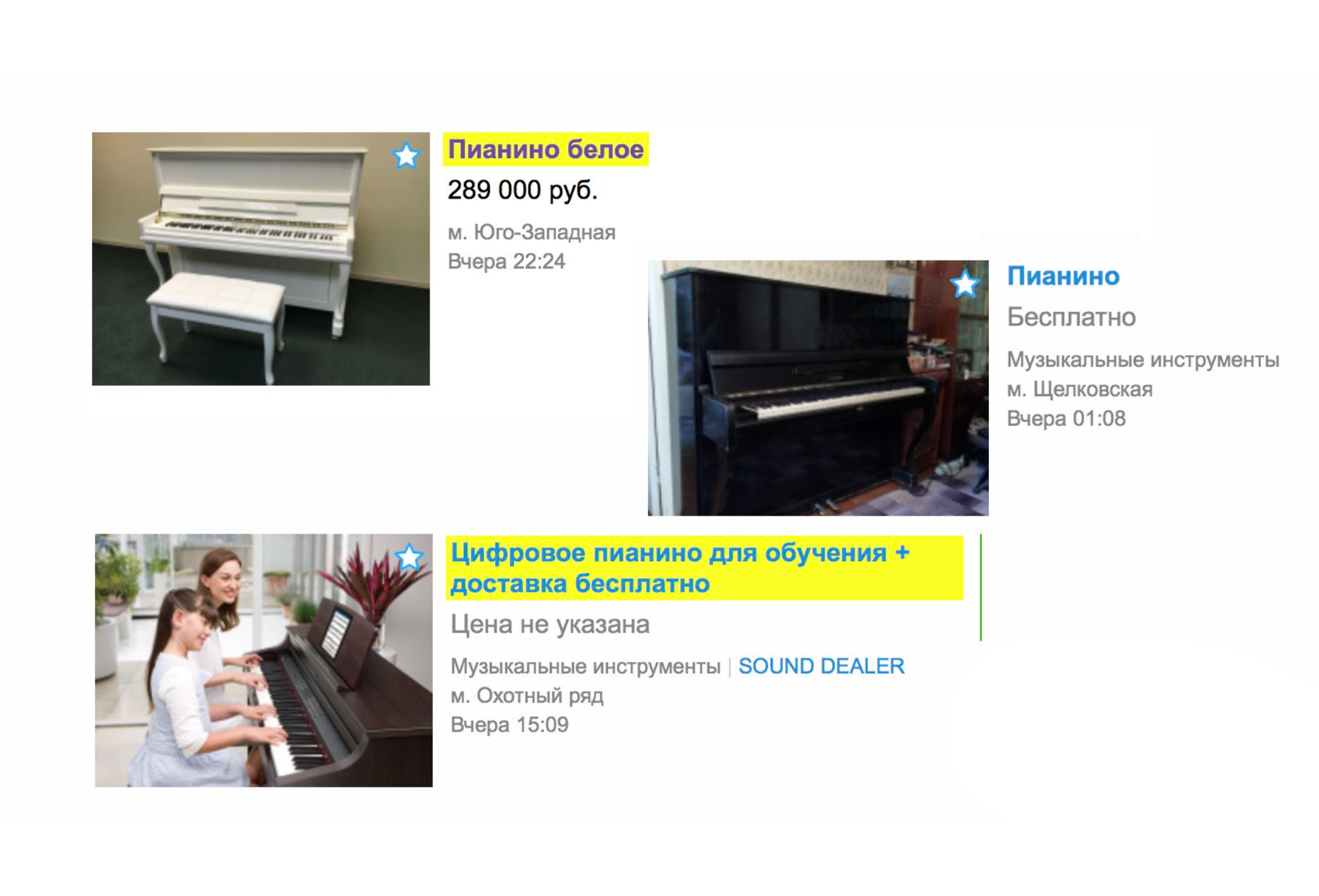
Sur Avito, moyennant des frais supplémentaires, vous pouvez augmenter votre annonce. Et avec l'introduction de la pertinence, les augmentations rémunérées fonctionnent plus efficacement. Ils fonctionneront, tout d'abord, si votre annonce est pertinente pour la requête textuelle.
L'introduction de la pertinence ne signifie pas que nous avons complètement abandonné les transitions vers l'arbre des catégories. Dans la plupart des cas, nous avons réduit le nombre de clics vers l'annonce souhaitée lors de la recherche à partir de la page principale. Si vous avez encore besoin de services de transport, même si vous venez de taper «piano» dans la recherche, parcourez l'arborescence des catégories et vous trouverez ces annonces. La recherche a également commencé à fonctionner plus efficacement et dans la catégorie, par exemple, «Articles personnels» et «Appareils ménagers».
Comment trouver le bon produit en trois clics
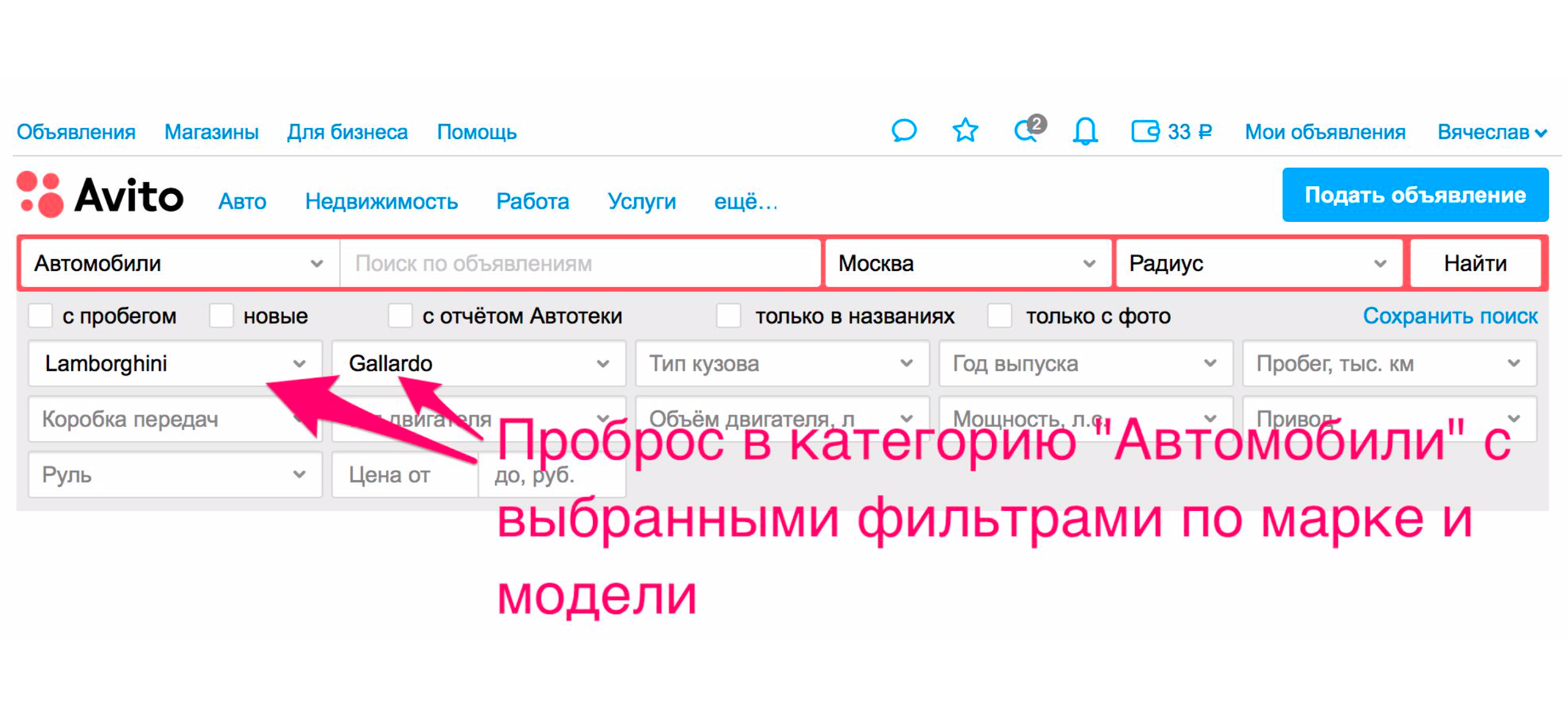
La recherche devient plus pratique pour les utilisateurs, non seulement en raison de la qualité des résultats de la recherche. Il existe d'autres moyens de l'améliorer. L'un d'eux transmet à la catégorie. Par exemple, nous recherchons Lamborghini Gayardo (oui, vous aimez jouer du piano et vous voulez monter Lamborghini). Pour entrer dans la catégorie d'une voiture d'un modèle particulier, vous devez faire deux clics supplémentaires. Avec pertinence, vous obtiendrez très probablement ce que vous voulez.
Mais il existe une méthode supplémentaire qui vous mettra immédiatement dans les voitures. L'émission sera restreinte, la bonne voiture sera sélectionnée dans les filtres et vous recevrez vraiment des voitures dans l'émission.

Une autre façon est d'étendre les balises. Par exemple, lorsque vous entrez le mot «veste», vous obtiendrez des indices.
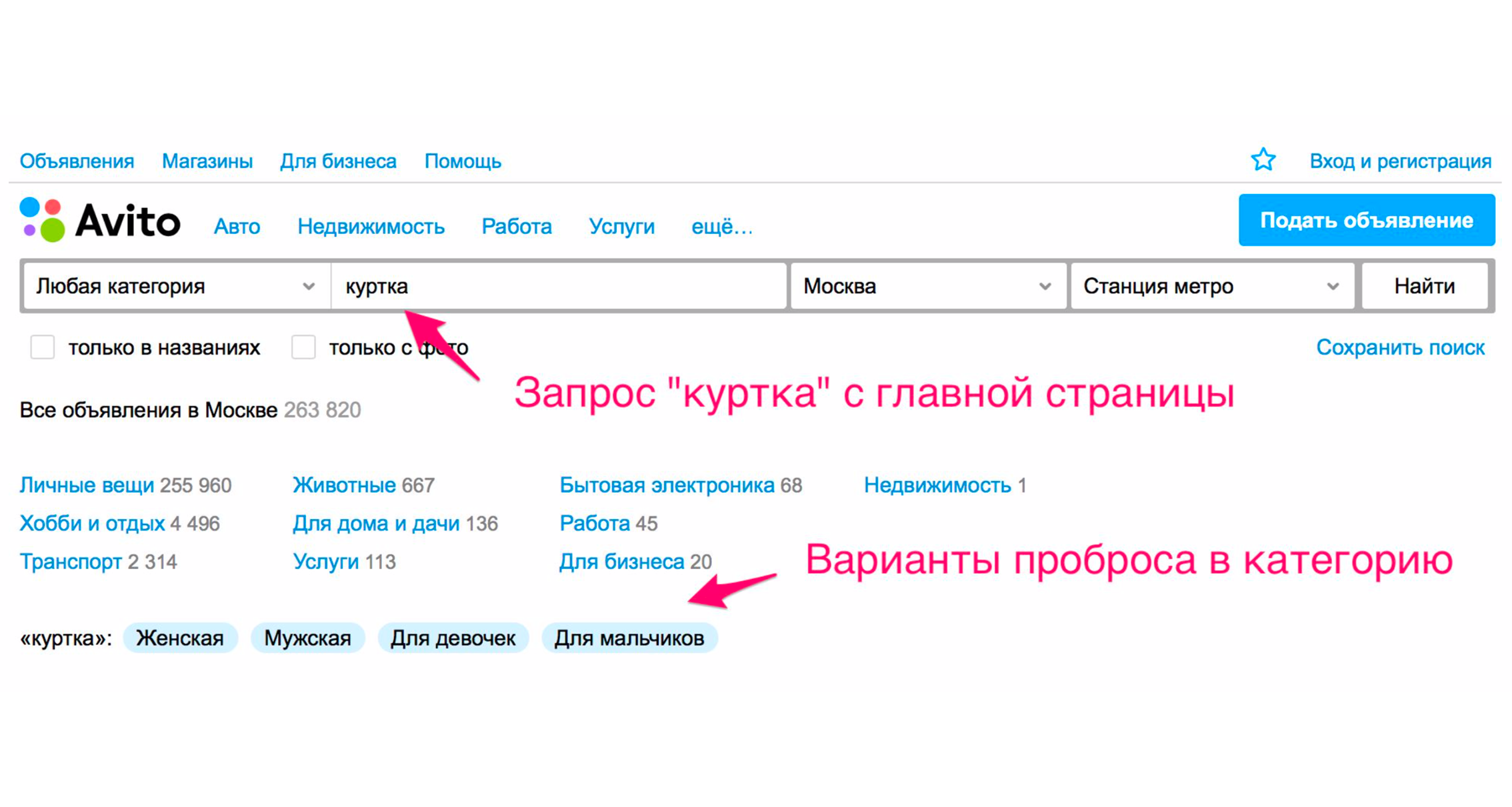
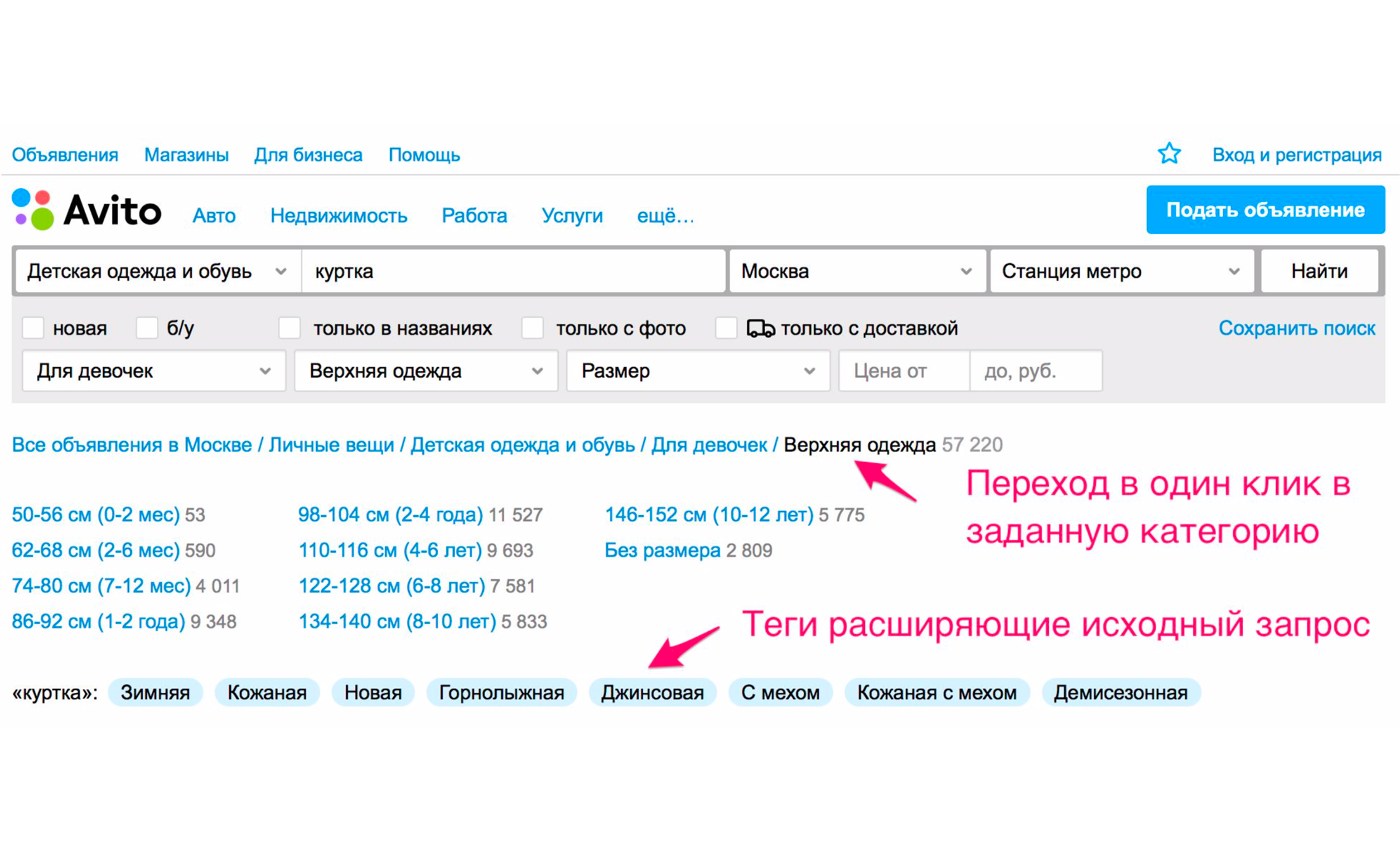
La capture d'écran ci-dessus montre les conseils: le type de vestes - femme, homme, pour filles, pour garçons. Si vous cliquez sur «Pour les filles», vous tomberez immédiatement dans la catégorie où les filtres appropriés seront sélectionnés. Un ensemble de balises supplémentaires supplémentaires apparaîtra également ici: veste d'hiver, cuir, neuf et ainsi de suite. Si vous descendez manuellement l'arborescence des catégories jusqu'au produit souhaité, vous devez effectuer plus d'actions.
Quelle est la différence entre la recherche et les filtres
Lorsque j'ai parlé à RIT ++ , le public avait une question: quelle est la différence entre la recherche de texte et les filtres? Tout est assez simple. Vous pouvez également trouver l'annonce souhaitée sans demande de texte en descendant dans l'arborescence des catégories. Dans ce cas, la recherche trouvera toujours des biens et services, non pas par le texte donné, mais par l'ensemble de paramètres transmis à partir des filtres correspondants de la catégorie sélectionnée.
Chaque catégorie a son propre ensemble de filtres. Par exemple, dans la catégorie «Voitures» - certains filtres, dans la catégorie «Objets personnels» - d'autres filtres. Autrement dit, les filtres sont liés de manière rigide à une catégorie.
Placement de l'annonce en deux minutes
Une innovation importante est apparue pour les vendeurs qu'ils ressentent lors de la soumission de leur annonce. Si votre annonce ne contient aucun "interdit" ou n'est pas un doublon - la bonne annonce habituelle - vous la verrez dans l'émission presque immédiatement. En fait, ce délai dure environ deux minutes, mais dans de rares cas, il peut être prolongé jusqu'à 30 minutes. Auparavant, une annonce n'apparaissait toujours sur le site qu'après une demi-heure.
Assistant Avito
Avito Helper est une extension pour Chrome qui affiche le prix d'un produit similaire sur Avito sur des sites tiers. Dans l'extension, vous pouvez comparer les prix dans de nombreuses boutiques en ligne avec les prix d'Avito, ou simplement rechercher les produits et services nécessaires dans notre service, sans aller directement sur le site Web ou l'application. Nous avons pu implémenter l '«Assistant», notamment grâce aux nouveaux changements d'infrastructure.

L'architecture
Scier un monolithe
Avito a un monolithe en PHP. Il y a un an, toutes les fonctionnalités de recherche qui fonctionnent dans Avito se trouvaient dans ce monolithe. La recherche dans le monolithe a fonctionné avec quatre plates-formes: Android, iOS, la version mobile dans le navigateur et le bureau. Pour donner la sortie, les requêtes SQL correspondantes ont été générées dans Sphinx à l'intérieur de ce code, le traitement était en cours et la sortie a été envoyée au format JSON ou HTML. Ensuite, les utilisateurs ont vu ce qu'ils cherchaient.
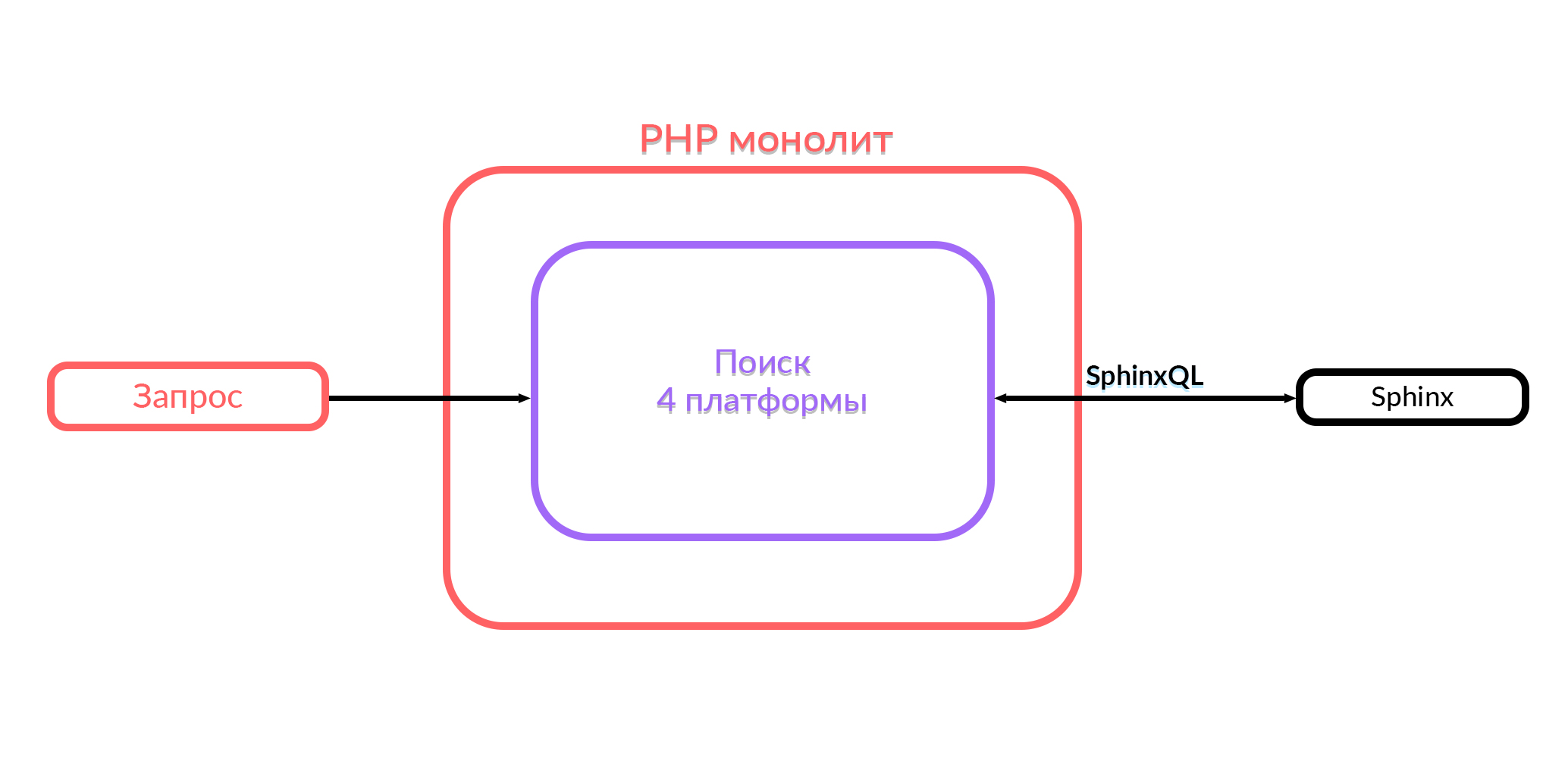
Ce que nous avons maintenant
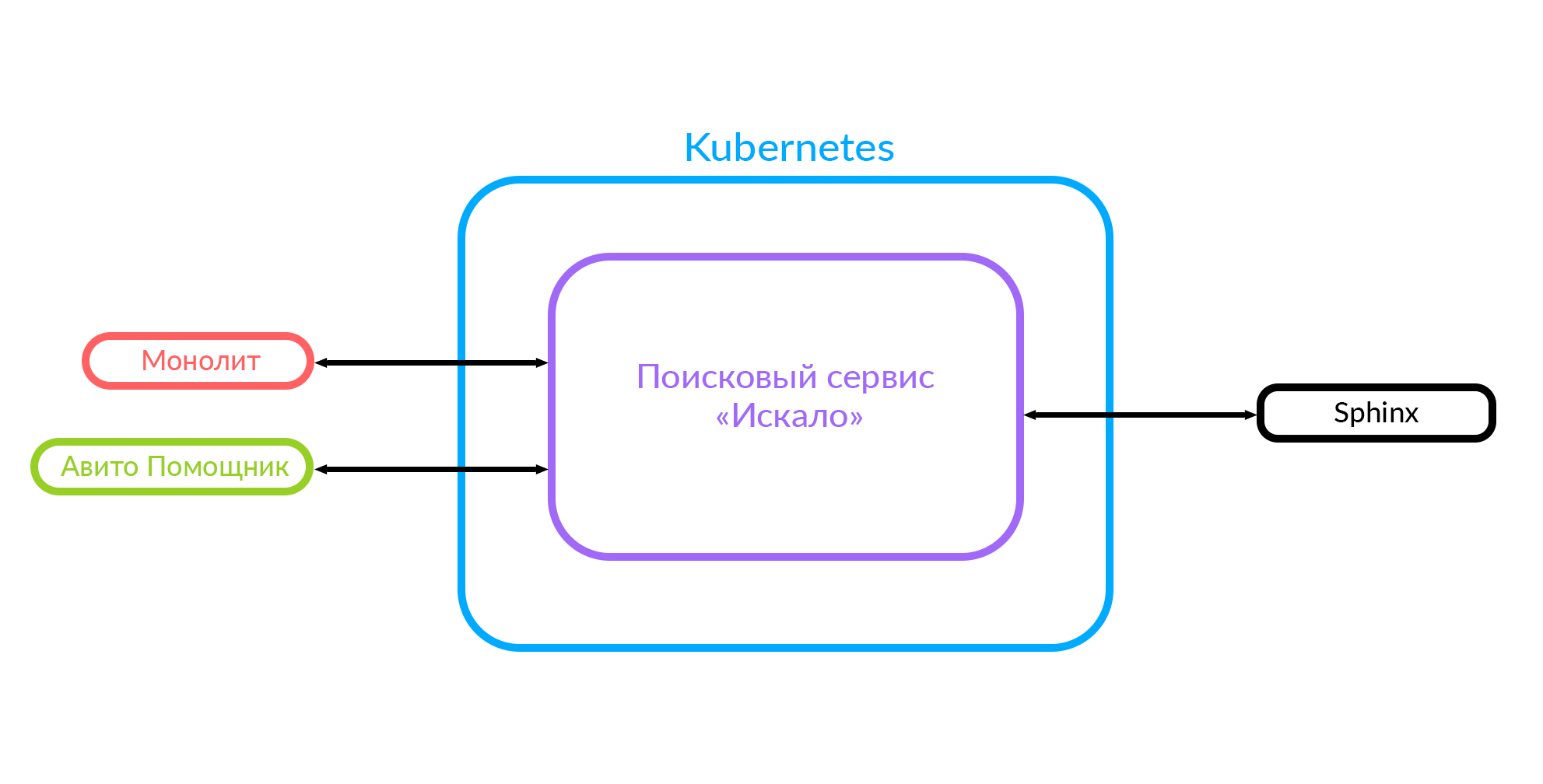
Si vous implémentez de nouvelles fonctionnalités, il est très difficile de l'intégrer à ce monolithe. Par conséquent, nous avons décidé de développer un service de recherche, que nous avons appelé «recherché». Maintenant, le monolithe va à ce service de recherche et le service va à Sphinx.

Raisons de créer un service de recherche
Lors du développement de services, vous devez toujours comprendre pourquoi vous faites cela. Le premier avantage évident est la suppression de la logique de bas niveau. Dans notre cas, cela cache la cuisine pour le traitement des requêtes SphinxQL. De plus, nous pouvons fournir plus facilement des fonctionnalités de recherche aux systèmes tiers.
Exécution de requête asynchrone. Cet avantage est assez évident et selon la mise en œuvre, l'un ou l'autre succès peut être obtenu. Notre service a été implémenté sur Golang, et il y avait des fonctionnalités qui pouvaient être parallélisées - trois demandes dans Sphinx, ce qui a donné de bons résultats.
Déploiement rapide. Nous avons identifié une fonctionnalité distincte avec moins de code, des tests supplémentaires (le monolithe a beaucoup de tests, pas seulement des fonctionnalités de recherche), et il est plus facile à déployer. Plus important encore, grâce à une approche réussie de la mise en œuvre de ce service, nous avons pu réduire des choses intéressantes et implémenter des algorithmes de classement avancés - pour effectuer un traitement assez compliqué que nous ne pouvions pas faire dans un monolithe. Cela nous fournit une très bonne base pour expérimenter la qualité de la recherche.
En prime, nous avons la possibilité de passer de Sphinx à Elastic, car la logique de bas niveau est désormais masquée.
Ce diagramme montre déjà le cas où il existe un monolithe, le service "Recherche" et le service tiers "Avito Assistant".
Comment fonctionne un service de recherche?
Il dispose d'un ensemble d'agrégateurs. Chaque agrégateur exécute une certaine logique métier liée au traitement de l'émission. Il peut former ce problème d'une certaine manière.
La demande arrive au planificateur. L'ordonnanceur sélectionne l'agrégateur en fonction des critères de requête en fonction de ses paramètres (ou si l'agrégateur souhaité est spécifié dans la demande elle-même). L'agrégateur va à Sphinx. Ayant reçu une réponse de Sphinx, il génère une sortie et donne la réponse au client.

Dans ce cas, la demande était à l'extérieur, pas à partir du cloud dans lequel notre service de recherche fonctionne. Mais une autre option est également possible: certains autres de nos services, à l'intérieur du cloud, par exemple, Avito Assistant, se tournent vers un service de recherche. Cette demande va déjà à un autre agrégateur - il existe une autre logique métier. Voici comment cela fonctionne:
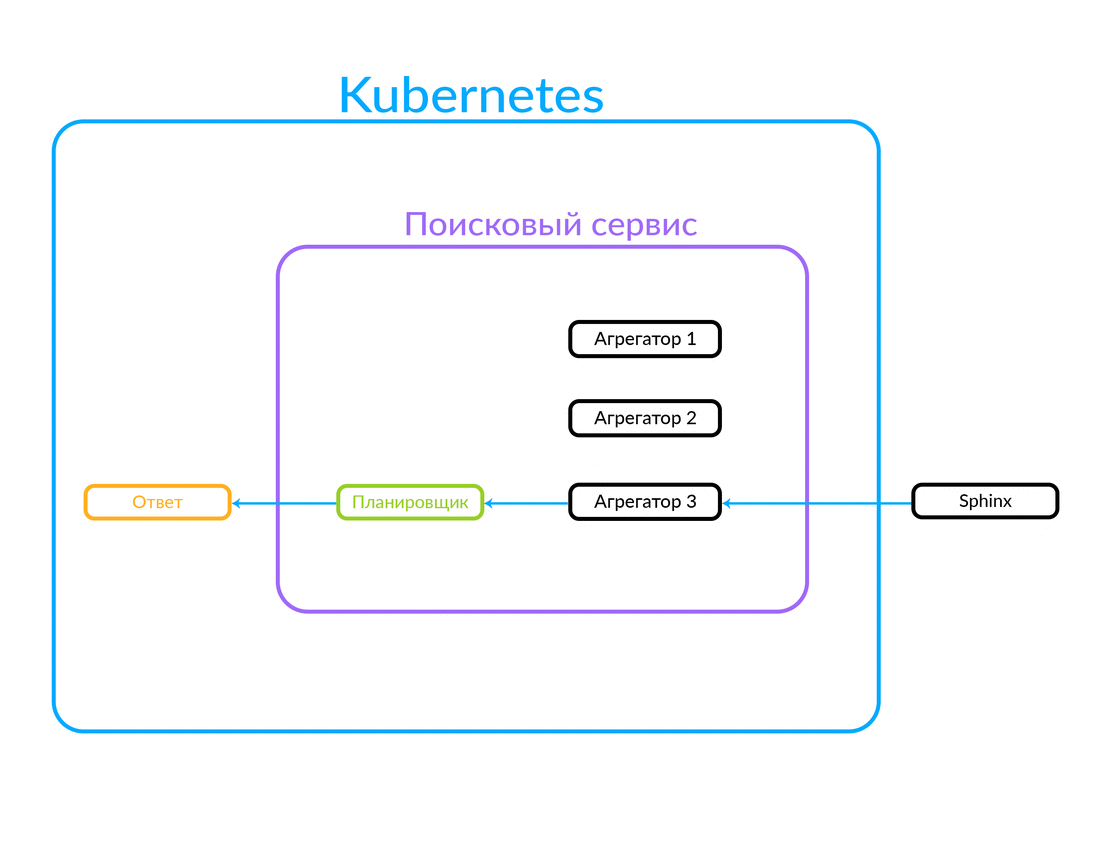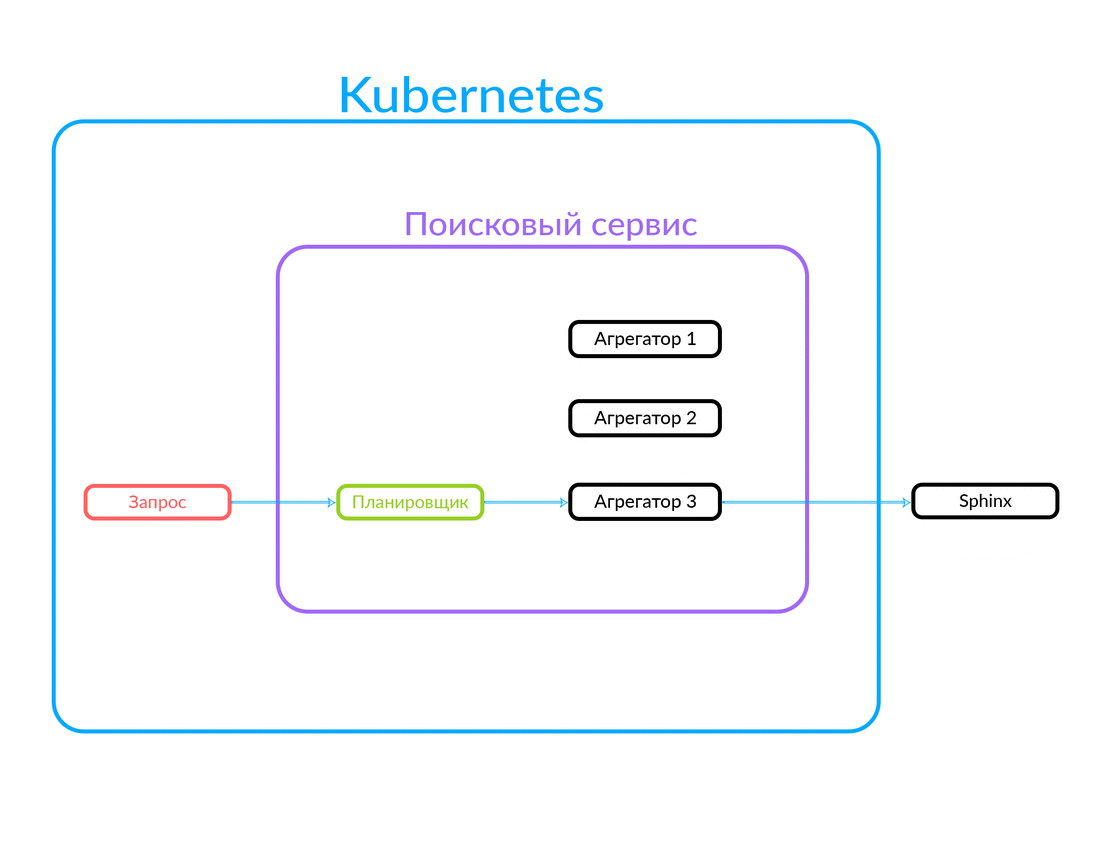
Fonctionnement de l'exécution de requêtes asynchrones sur l'agrégateur
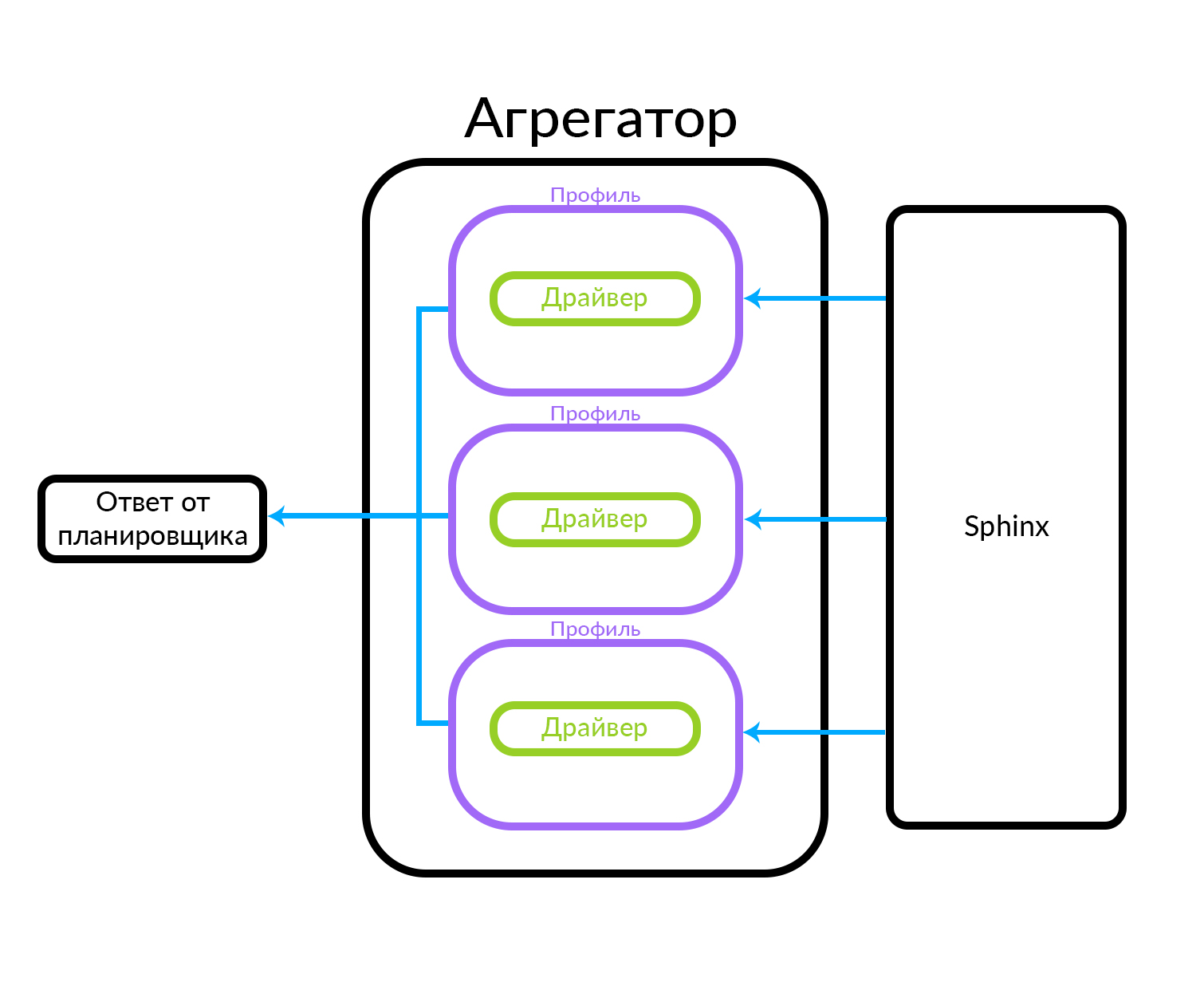
L'agrégateur se compose de plusieurs profils. Un profil est, en gros, une entité dans laquelle vous pouvez obtenir une annonce d'un certain type ou d'une manière spécifique. Par exemple, cela peut s'expliquer par une analogie: il y a des publicités «Premium», «VIP» et régulières sur Avito. L'agrégateur reçoit une demande de l'ordonnanceur, tandis que des demandes parallèles sont exécutées pour l'ensemble de profils connus dans l'agrégateur. Le profil contient un pilote qui accède physiquement au niveau sous-jacent, dans ce cas dans Sphinx, mais il peut s'agir de n'importe quelle autre source de données
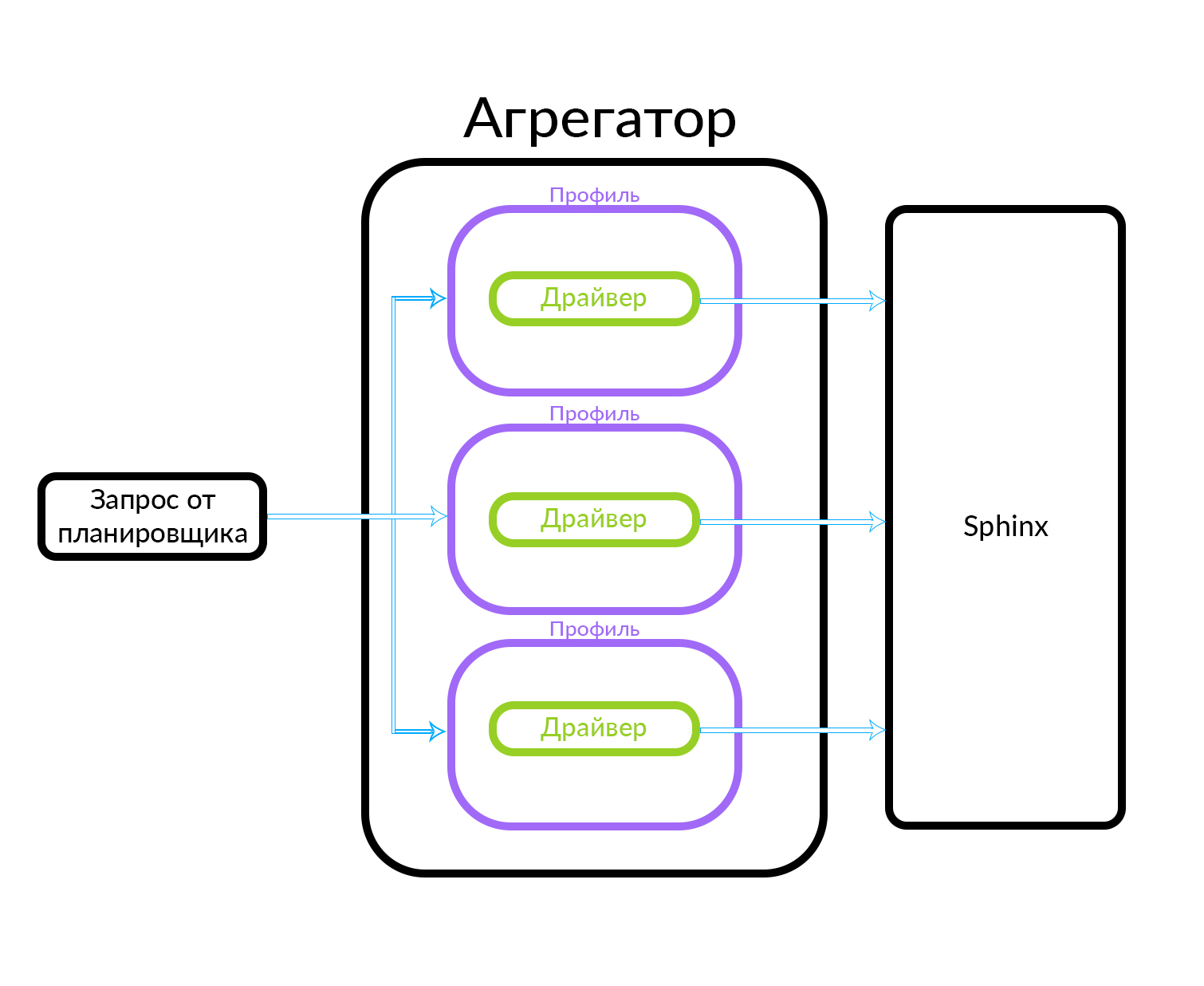
L'agrégateur peut simplement donner au planificateur les résultats des requêtes sur les profils, et il peut également effectuer des actions plus complexes, par exemple, mélanger ces résultats en utilisant l'un ou l'autre algorithme.
Stockage d'index de recherche
Étant donné que nous utilisons Kubernetes dans l'architecture, au RIT ++, on m'a posé une question sur le stockage de l'index de recherche - est-il stocké dans Kubernetes? Non, nous avons Sphinx vivant sur des machines physiques. Chez Kubernetes, nous déployons un service de recherche qui traite la logique de recherche. Le cloud contient également un exemple d'index de recherche pour l'environnement de développement sur lequel les tests sont exécutés, mais il n'est pas souhaitable d'y mettre un index de combat, car les services qui fonctionnent dans Kubernetes sont, tout d'abord, des services sans état.
Charge de service de recherche
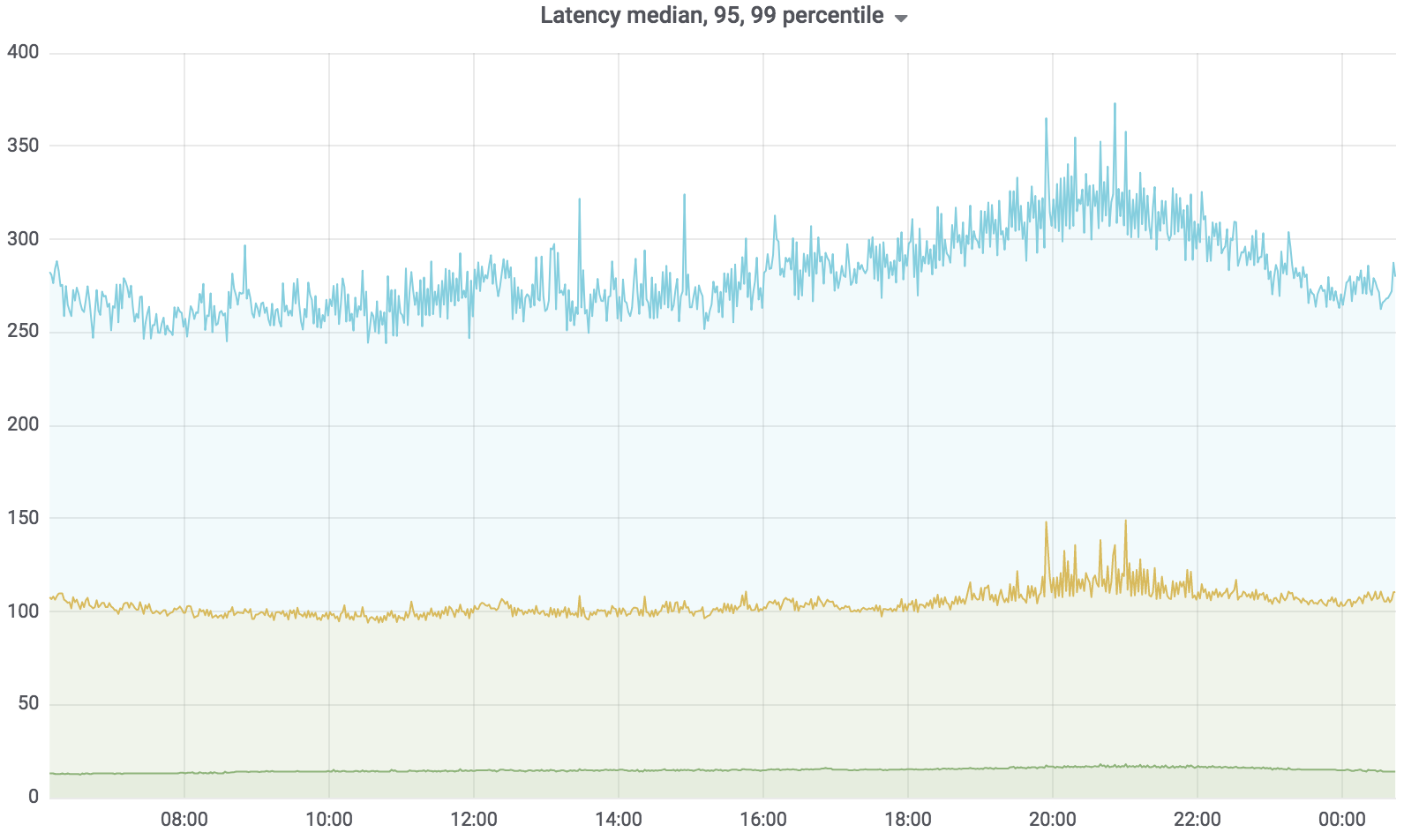
Maintenant que ce service est en bataille, il sert 100% de la charge à quelques exceptions près. La charge qu'il détient est d'environ 200 krpm. Délai: médiane - jusqu'à 17 ms, 95 centile - jusqu'à 120 ms, 99 centile - jusqu'à 320 ms.
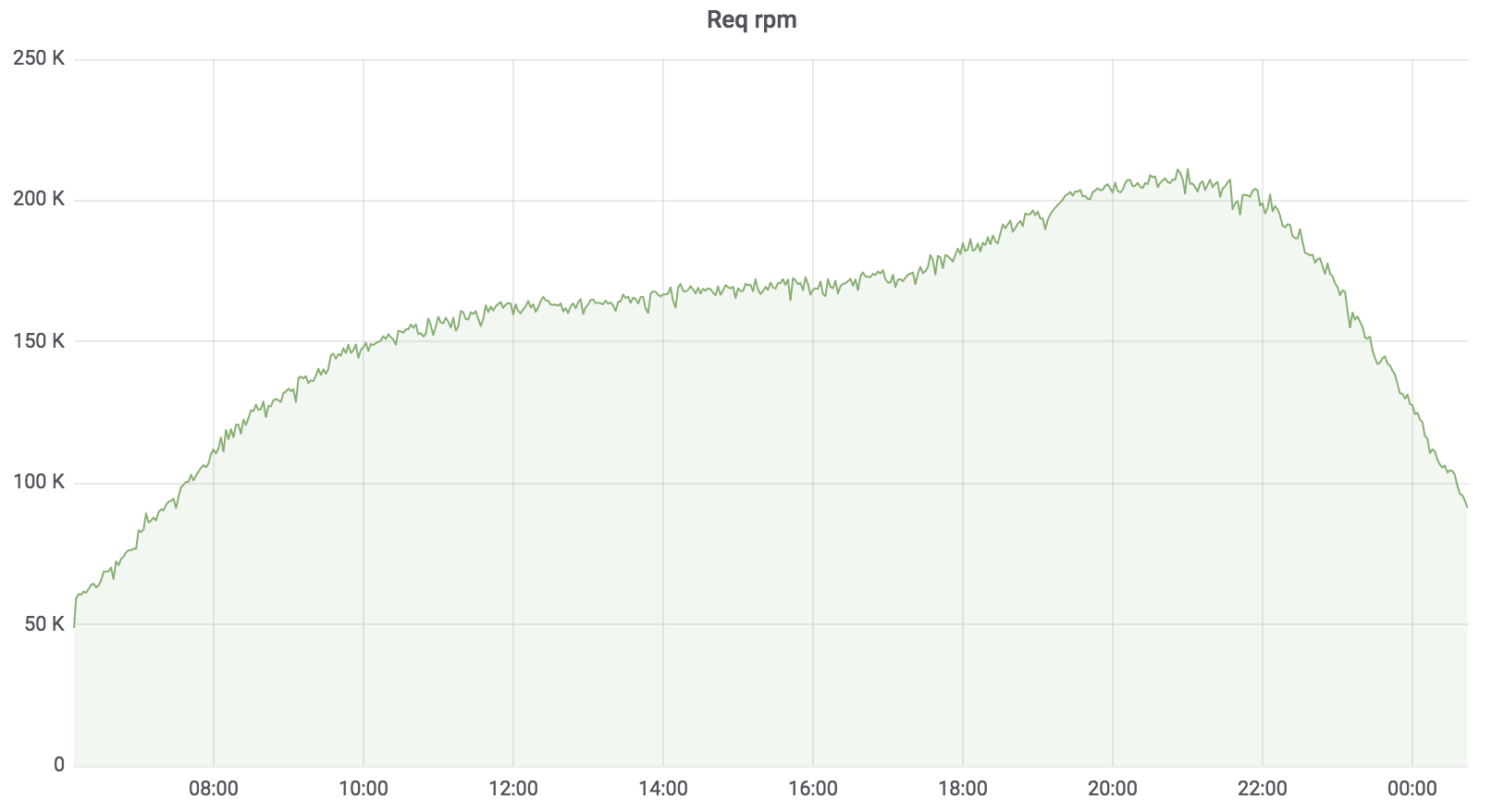
Service de recherche totale
Le service de recherche est écrit en Golang, déployé sur Kubernetes, l'agrégateur fonctionne de manière asynchrone avec plusieurs profils. Le profil fonctionne avec le pilote spécifié, le pilote accède à la source de données spécifiée, par exemple, Sphinx. Le nombre de demandes que notre service dessert est jusqu'à 200 krpm pour le moment. Délai: médiane - jusqu'à 17 ms, 95 centile - jusqu'à 120 ms, 99 centile - jusqu'à 320 ms.
Implémentation du service dans un système fonctionnel
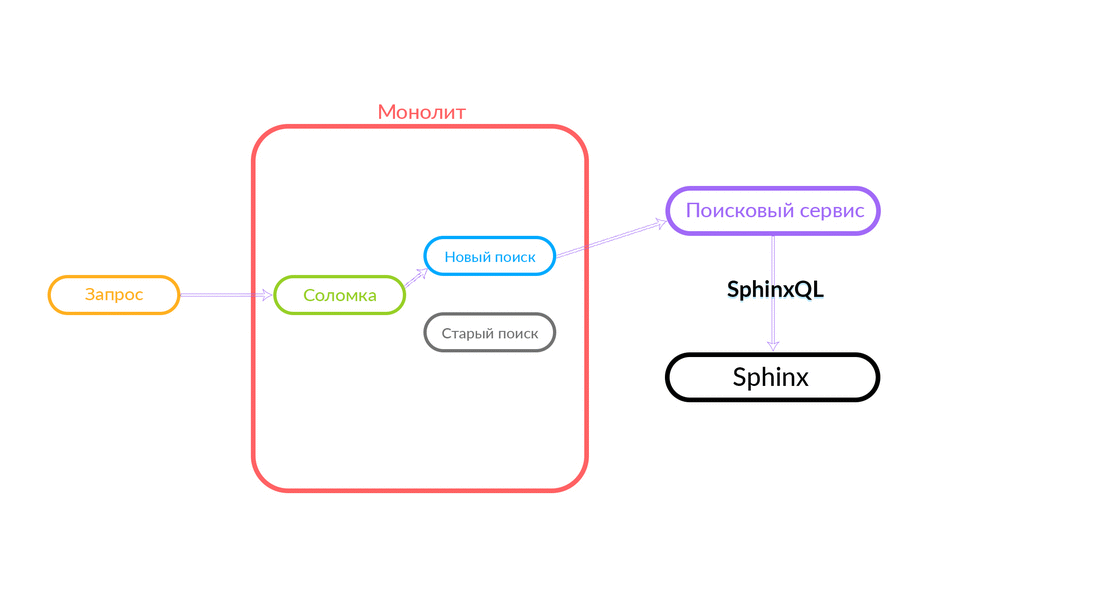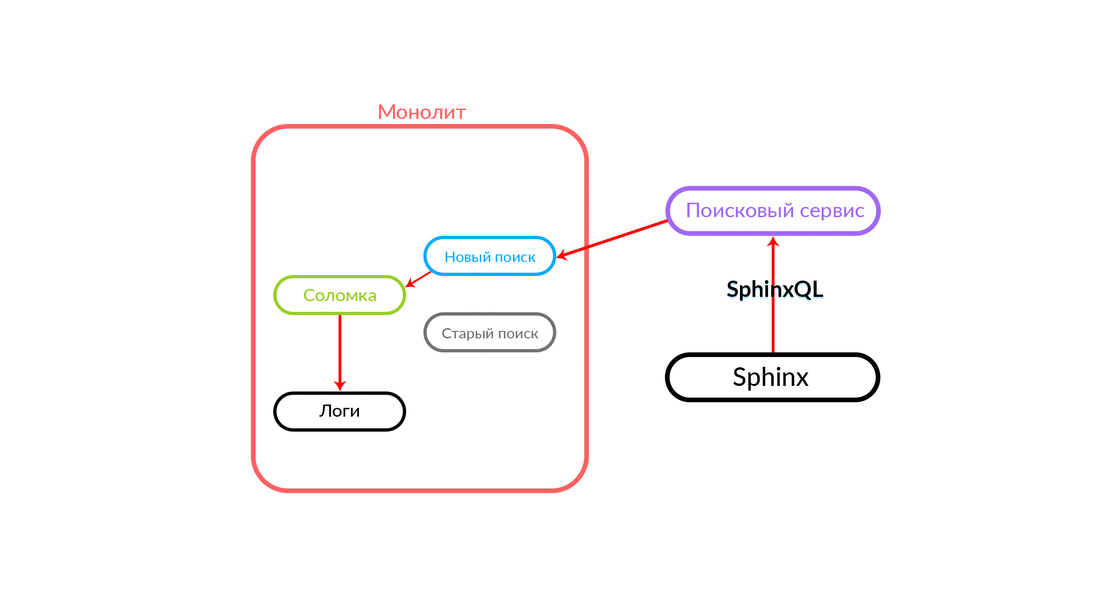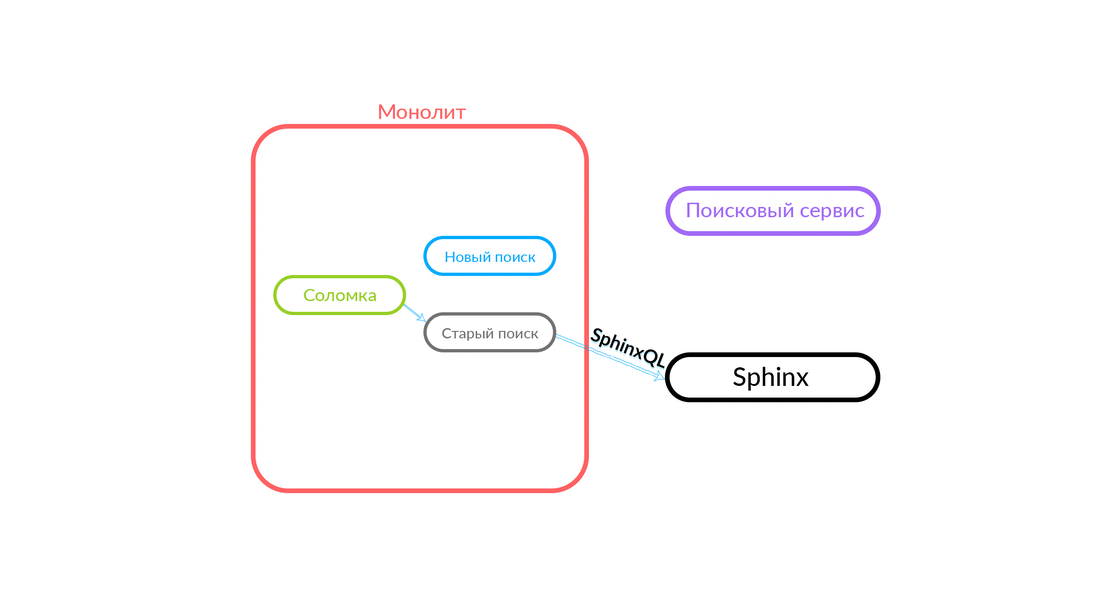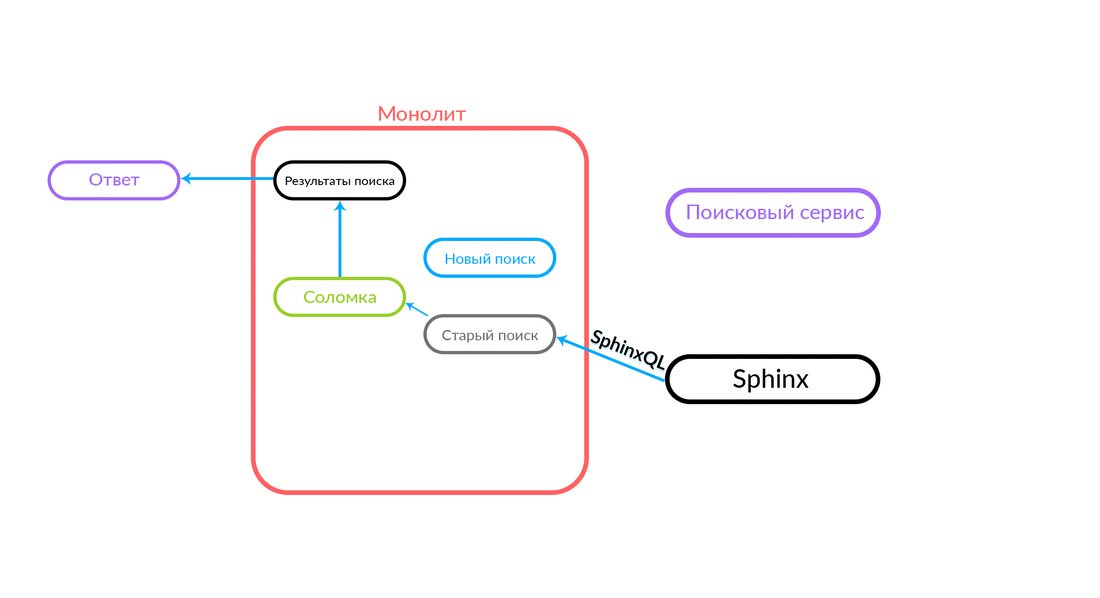
Le problème de la double fonctionnalité est assez évident, nous devons prendre en charge deux bases de code qui doivent effectuer la même tâche. Nous avons besoin d'un repli. Nous l'avons appelé «pailles» - nous nous sommes souvenus de «jeter des pailles». De plus, nous avons besoin d'un contrôle du trafic, il est souhaitable qu'il soit rapide, via un tableau de bord.
Comment fonctionne la "paille"
La requête de recherche concerne la «Paille», qui fonctionne à l'intérieur du monolithe et peut effectuer un nouvel appel à une nouvelle recherche ou à une ancienne. Elle appelle une nouvelle recherche, il la remplit et si elle réussit, nous obtenons simplement le résultat d'une nouvelle recherche.
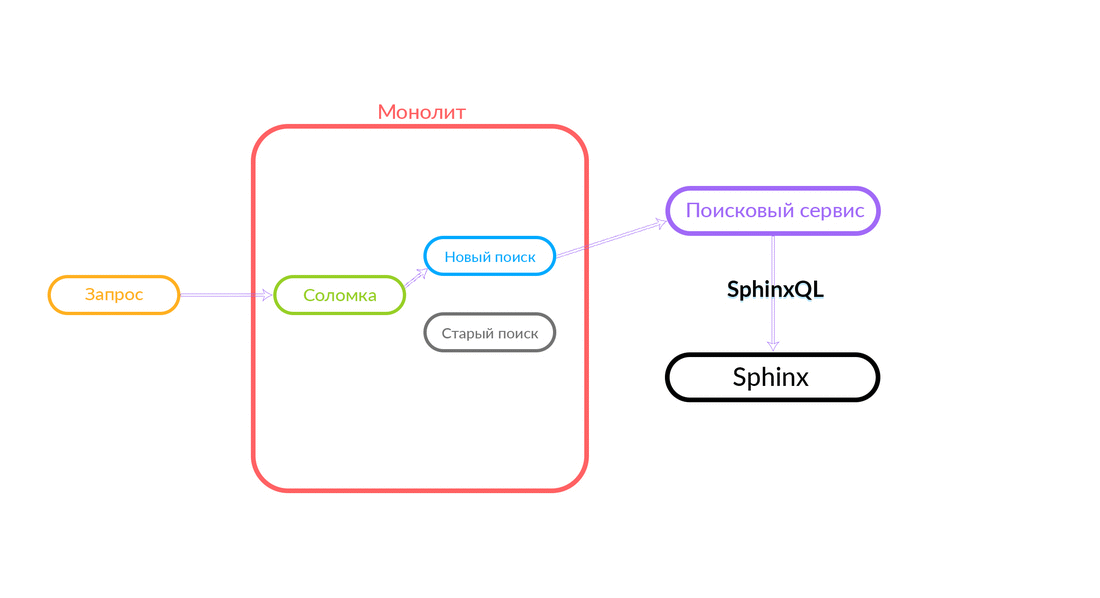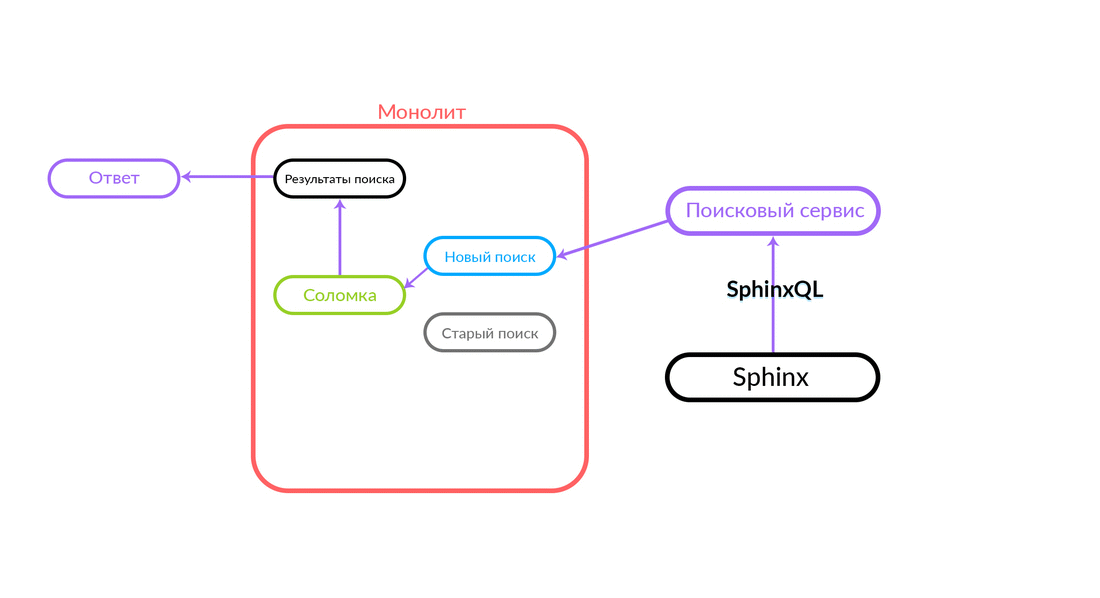
Il y a des situations où certaines requêtes au service de recherche échouent: par exemple, et jusqu'à ce qu'une sorte de fonctionnalité soit implémentée à l'intérieur du service de recherche. Ensuite, nous engageons nécessairement une telle demande - "The Straw" l'exécutera dans l'ancienne recherche. L'ancienne recherche du monolithe se tournera vers Sphinx, et la réponse ira au client. Le client ne ressentira rien.
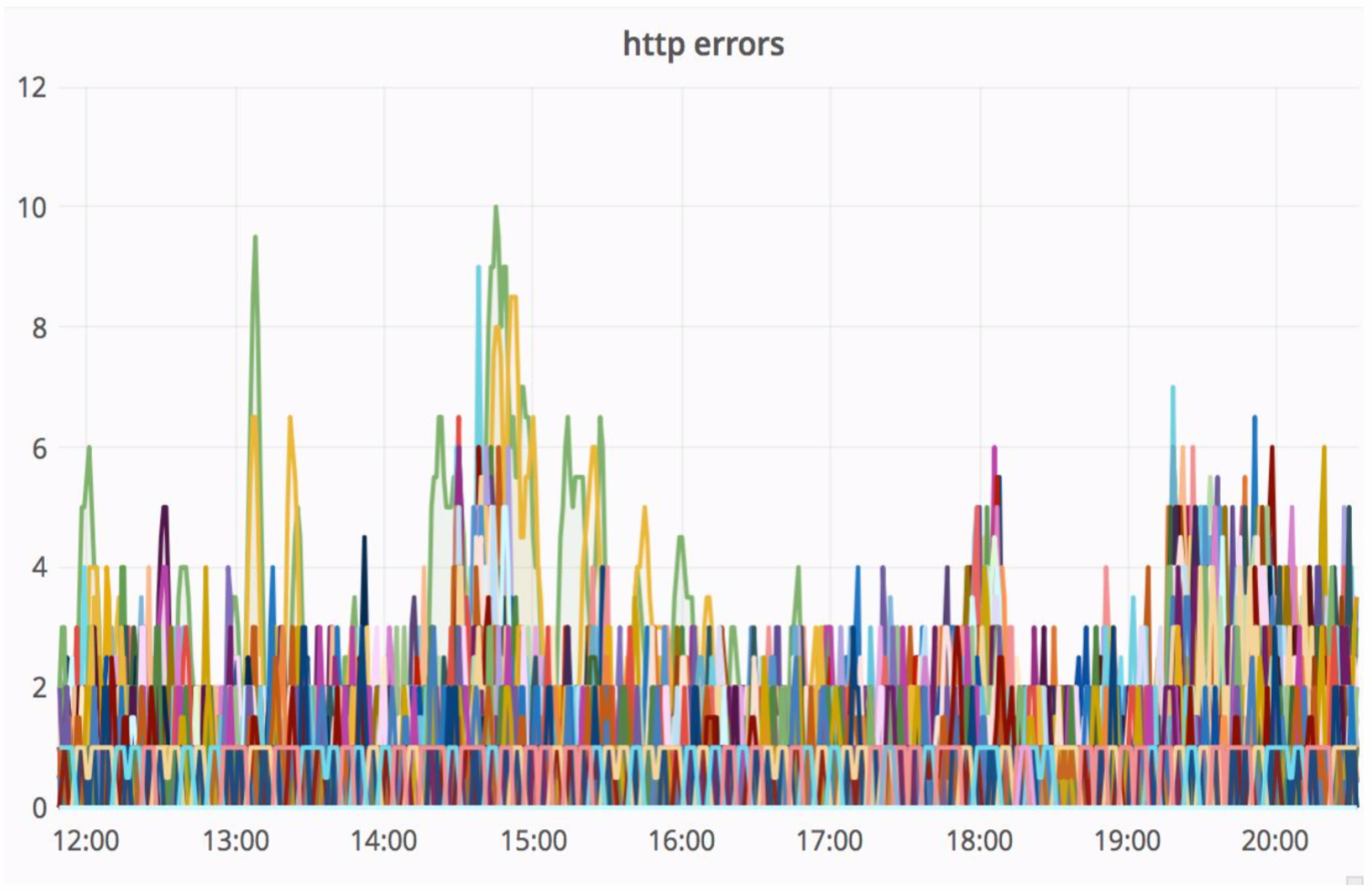
Un schéma assez fiable, et il est toujours intéressant de voir ce qui se passe dans la pratique. Le département d'architecture d'Avito améliore constamment notre cloud, l'optimisant, le rendant plus fiable et plus productif. À un certain stade, il y avait des problèmes lors de l'entretien d'un des nœuds avec une intensité suffisamment élevée, des erreurs provenaient du monolithe (100 erreurs par seconde).

Dans le même temps, le délai de service a fortement augmenté - dans l'image ci-dessous, vous pouvez voir des pics.
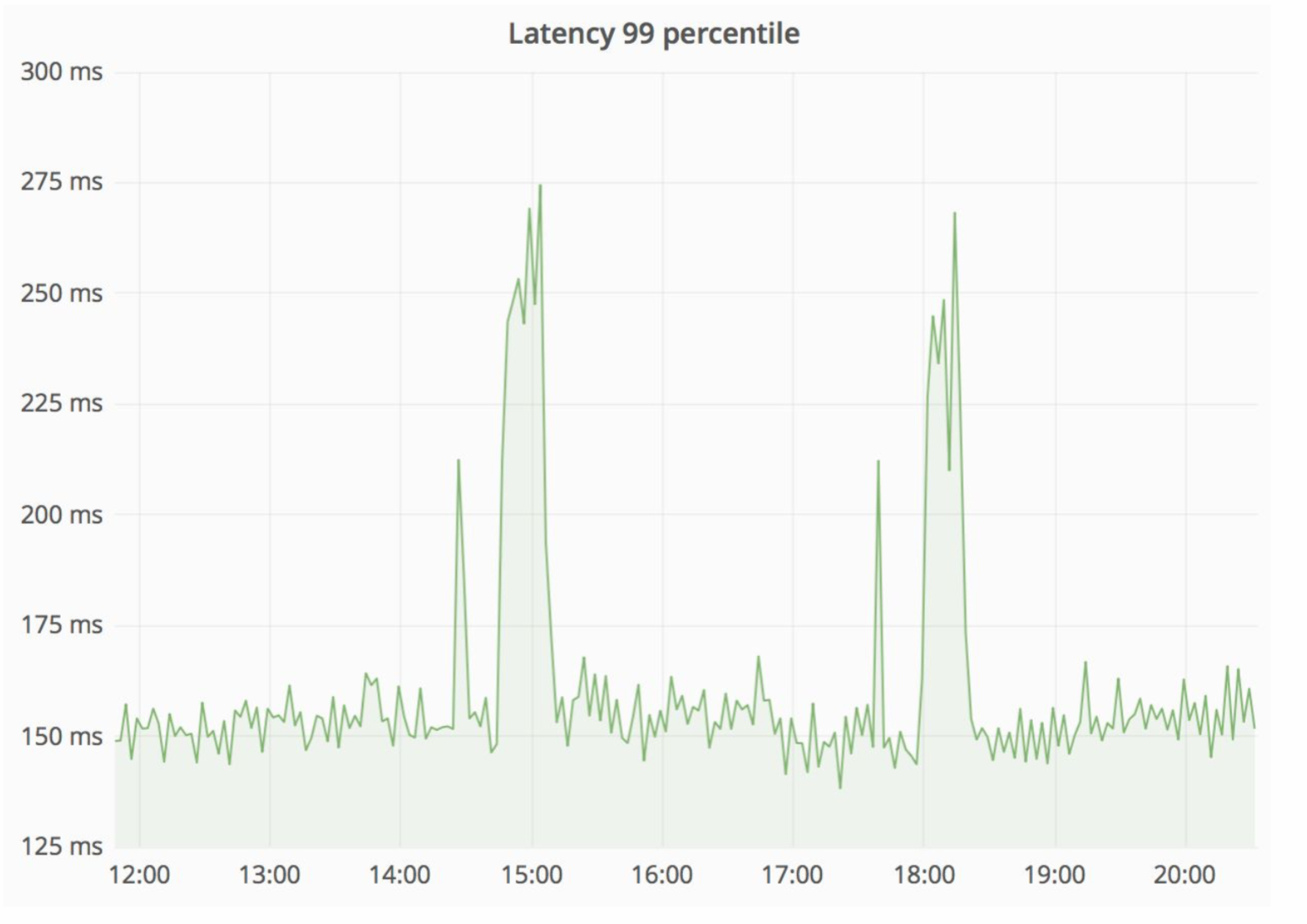
La «paille» a remarquablement résolu cette situation, et les erreurs HTTP résultantes étaient au même niveau - une unité d'erreurs pour l'ensemble de l'Avito. Nos visiteurs n'ont rien remarqué.
Automatisation des expériences
Nous voulons que la recherche se développe rapidement et que le déploiement de nouvelles fonctionnalités soit plus facile. Pour cela, une infrastructure appropriée est nécessaire. Nous avons configuré l'automatisation des tests A / B. À l'aide du tableau de bord, nous pouvons démarrer de nouvelles expériences, les configurer en fonction des innovations ajoutées et, par conséquent, exécuter des expériences sans faire rouler le monolithe.
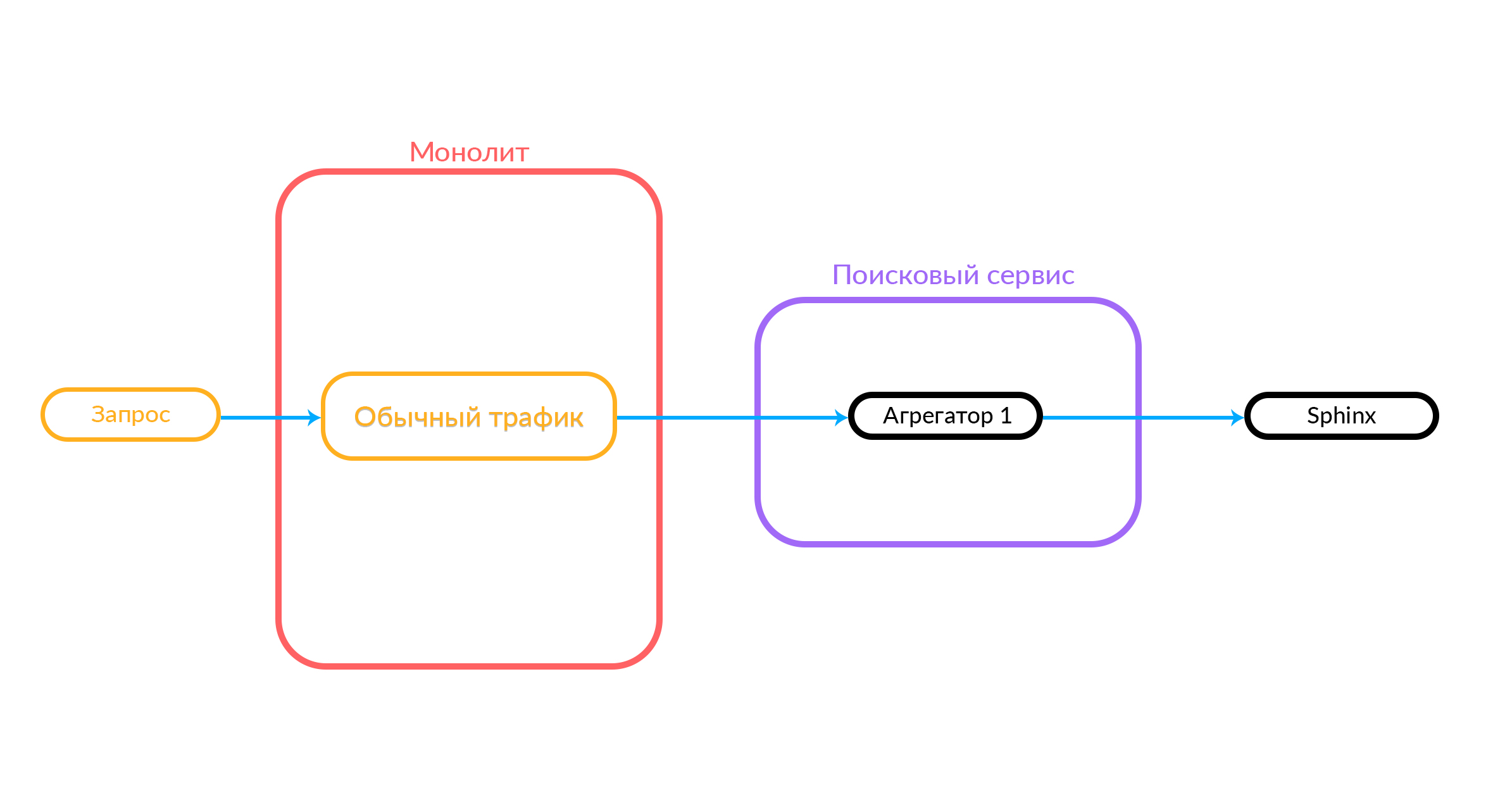
Dans l'état initial, lorsqu'aucune expérience n'était lancée, tous les visiteurs voient la fonctionnalité de recherche habituelle.
Dans une expérience typique, les utilisateurs sont divisés en groupes. Le groupe de contrôle - avec les fonctionnalités habituelles pour nos visiteurs. Il existe plusieurs groupes de tests - avec des innovations. Lorsque nous devons créer une nouvelle expérience, dans le service de recherche, nous implémentons une nouvelle fonctionnalité de recherche (ajouter de nouveaux agrégateurs) et via le tableau de bord, nous configurons l'expérience avec les groupes nécessaires, en les reliant à de nouveaux agrégateurs.
Lors de l'analyse des expériences, nous comparons le comportement des visiteurs du groupe témoin avec ceux du test et, sur cette base, nous tirons des conclusions sur le succès de l'expérience.

Supposons que nous ayons développé une nouvelle formule de classement. Que devons-nous faire pour l'expérimenter?
- Dans le service de recherche, déployez l'agrégateur approprié (que ce soit «Aggregator 2»).
- Créez une expérience via un tableau de bord et connectez l'un des groupes de cette expérience à cet agrégateur.
- Maintenant, si une requête arrive dans la recherche qui tombe dans le groupe de test, elle va au service de recherche sur «Aggregator 2».
Nous pouvons continuer à créer de nouvelles expériences et associer leurs groupes de tests à de nouveaux agrégateurs.
Infrastructure de recherche totale
Il existe un cluster de serveurs Sphinx 3. Il contient 13 krps de requêtes SphinxQL et contient plus de 45 millions d'annonces actives.
Sphinx 3.0 est stable et satisfait de ses performances. Soit dit en passant, les binaires sont dans le domaine public . De plus, grâce à Avito, de nouvelles fonctionnalités sont filmées dans Sphinx 3, par exemple, le fonctionnement du produit scalaire des vecteurs, et les bugs trouvés sont corrigés.
Nous utilisons une architecture de service. Nous avons le service de recherche "Iskalo" et le service "Avito Assistant". Une partie de la fonctionnalité est restée dans le monolithe, mais nous continuons à travailler sur sa découpe.
Conclusions
Au cours de la dernière année, un système de développement de fonctionnalités de recherche avancées a été reçu. Nous avons eu l'opportunité de mener des expériences rapides et flexibles. Et maintenant, la recherche d'utilisateurs est devenue plus pratique, plus rapide et permet de mieux résoudre leurs problèmes.
Et ensuite
De plus, nous continuerons à retirer du monolithe ce qui reste: rendu, filtres. Nous travaillerons pour améliorer la qualité de la recherche, continuerons à ravir nos visiteurs. J'espère aussi.
Si vous avez des questions sur le travail de notre recherche, nous aimerions en savoir plus de détails techniques, écrivez dans les commentaires. Je répondrai avec plaisir. À propos, récemment, Andrey Drozdov a parlé à Highload ++ 2018 avec un rapport sur l'optimisation multicritère des résultats de recherche , voici sa présentation .