Bonjour à tous!
Nous avons ouvert un nouveau volet pour le cours d'
apprentissage automatique , alors attendez dans un proche avenir les articles liés à cette discipline, pour ainsi dire. Eh bien, bien sûr, des séminaires ouverts. Voyons maintenant ce qu'est l'apprentissage par renforcement.
L'apprentissage renforcé est une forme importante d'apprentissage automatique, où un agent apprend à se comporter dans un environnement en effectuant des actions et en voyant les résultats.
Ces dernières années, nous avons connu de nombreux succès dans ce domaine de recherche fascinant. Par exemple,
DeepMind et Deep Q Learning Architecture en 2014,
victoire sur go champion avec AlphaGo en 2016,
OpenAI et PPO en 2017, entre autres.
 DeepMind DQN
DeepMind DQNDans cette série d'articles, nous nous concentrerons sur l'étude des différentes architectures utilisées aujourd'hui pour résoudre le problème de l'apprentissage renforcé. Il s'agit notamment de Q-learning, Deep Q-learning, Policy Gradients, Actor Critic et PPO.
Dans cet article, vous apprendrez:
- Qu'est-ce que l'apprentissage par renforcement et pourquoi les récompenses sont une idée centrale
- Trois approches d'apprentissage par renforcement
- Que signifie «profond» dans l'apprentissage par renforcement profond
Il est très important de maîtriser ces aspects avant de plonger dans la mise en place d'agents d'apprentissage par renforcement.
L'idée de la formation de renforcement est que l'agent apprendra de l'environnement en interagissant avec lui et en recevant des récompenses pour effectuer des actions.

L'apprentissage par l'interaction avec l'environnement provient de notre expérience naturelle. Imaginez que vous êtes un enfant dans le salon. Vous voyez la cheminée et allez-y.
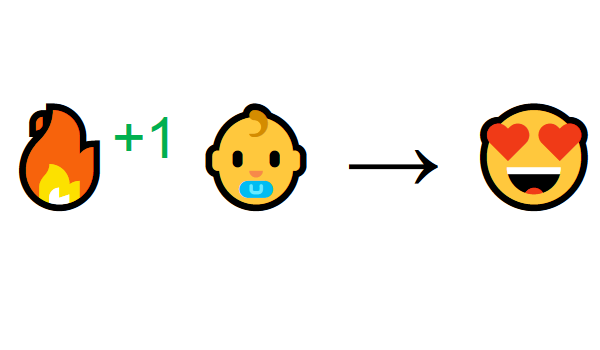
A proximité chaleureux, vous vous sentez bien (récompense positive +1). Vous comprenez que le feu est une chose positive.
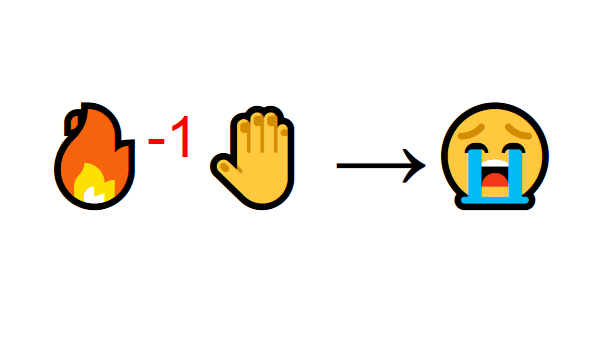
Mais ensuite, vous essayez de toucher le feu. Aïe! Il s'est brûlé la main (récompense négative -1). Vous venez de réaliser que le feu est positif lorsque vous êtes à une distance suffisante car il produit de la chaleur. Mais si vous vous approchez de lui, vous serez brûlé.
C'est ainsi que les gens apprennent par l'interaction. L'apprentissage renforcé est simplement une approche informatique de l'apprentissage par l'action.
Processus d'apprentissage par renforcement

Par exemple, imaginez un agent apprenant à jouer à Super Mario Bros. Le processus d'apprentissage par renforcement (RL) peut être modélisé comme un cycle qui fonctionne comme suit:
- L'agent reçoit l'état S0 de l'environnement (dans notre cas, nous obtenons la première image du jeu (état) de Super Mario Bros (environnement))
- Sur la base de cet état S0, l'agent entreprend l'action A0 (l'agent se déplace vers la droite)
- L'environnement passe à un nouvel état S1 (nouvelle trame)
- L'environnement donne une récompense à l'agent R1 (pas mort: +1)
Ce cycle RL produit une séquence d'
états, d'actions et de récompenses.L'objectif de l'agent est de maximiser les récompenses cumulées attendues.
Hypothèses de récompense d'idée centralePourquoi l'objectif d'un agent est-il de maximiser les récompenses cumulées attendues? Eh bien, l'apprentissage par renforcement est basé sur l'idée d'une hypothèse de récompense. Tous les objectifs peuvent être décrits en maximisant les récompenses cumulées attendues.
Par conséquent, dans la formation de renforcement, afin d'obtenir le meilleur comportement, nous devons maximiser les récompenses accumulées attendues.La récompense accumulée à chaque pas de temps t peut s'écrire:

Cela équivaut à:
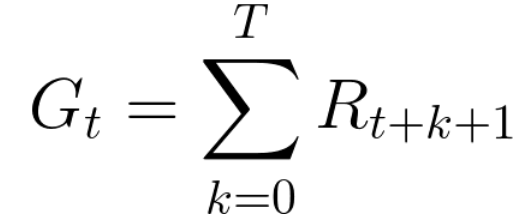
Cependant, en réalité, nous ne pouvons pas simplement ajouter de telles récompenses. Les récompenses qui arrivent plus tôt (au début du jeu) sont plus probables, car elles sont plus prévisibles que les récompenses à l'avenir.

Supposons que votre agent soit une petite souris et que votre adversaire soit un chat. Votre objectif est de manger le maximum de fromage avant que le chat ne vous mange. Comme nous le voyons dans le diagramme, une souris est plus susceptible de manger du fromage à côté d'elle-même que du fromage près d'un chat (plus on est près de lui, plus il est dangereux).
En conséquence, la récompense d'un chat, même si elle est supérieure (plus de fromage), sera réduite. Nous ne sommes pas sûrs de pouvoir en manger. Pour réduire la rémunération, nous procédons comme suit:
- Nous déterminons le taux d'actualisation appelé gamma. Il doit être compris entre 0 et 1.
- Plus le gamma est grand, plus la remise est faible. Cela signifie que l'agent d'apprentissage se préoccupe davantage des récompenses à long terme.
- En revanche, plus le gamma est petit, plus la remise est importante. Cela signifie que la priorité est donnée aux récompenses à court terme (fromage le plus proche).
La contrepartie attendue cumulée, compte tenu de l'actualisation, est la suivante:
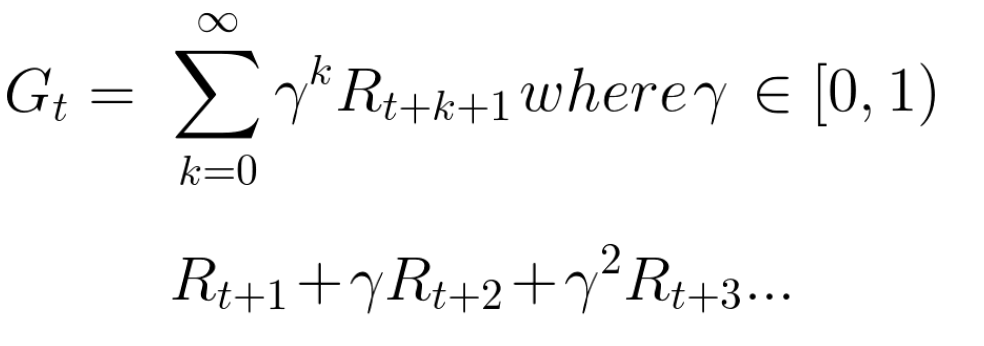
En gros, chaque récompense sera réduite en utilisant le gamma de l'indicateur de temps. À mesure que le pas de temps augmente, le chat se rapproche de nous, de sorte que la récompense future devient de moins en moins probable.
Tâches occasionnelles ou continuesUne tâche est une instance du problème d'apprentissage avec renforcement. Nous pouvons avoir deux types de tâches: épisodiques et continues.
Tâche épisodiqueDans ce cas, nous avons un point de départ et un point d'arrivée
(état terminal). Cela crée un épisode : une liste d'états, d'actions, de récompenses et de nouveaux états.
Prenez Super Mario Bros par exemple: l'épisode commence avec le lancement du nouveau Mario et se termine lorsque vous êtes tué ou atteignez la fin du niveau.
 Le début d'un nouvel épisodeTâches continuesCe sont des tâches qui durent indéfiniment (sans état terminal)
Le début d'un nouvel épisodeTâches continuesCe sont des tâches qui durent indéfiniment (sans état terminal) . Dans ce cas, l'agent doit apprendre à choisir les meilleures actions et en même temps interagir avec l'environnement.
Par exemple, un agent qui effectue des transactions boursières automatisées. Il n'y a pas de point de départ et d'état terminal pour cette tâche.
L'agent continue de travailler jusqu'à ce que nous décidions de l'arrêter. Monte Carlo vs méthode de décalage horaire
Monte Carlo vs méthode de décalage horaireIl y a deux façons d'apprendre:
- Récolter des récompenses à la fin de l'épisode puis calculer le maximum de récompenses futures attendues - approche Monte Carlo
- Évaluation des récompenses à chaque étape - une différence temporaire
Monte CarloÀ la fin de l'épisode (l'agent atteint un «état terminal»), l'agent examine la récompense totale accumulée pour voir dans quelle mesure il a réussi. Dans l'approche Monte Carlo, les récompenses ne sont reçues qu'à la fin de la partie.
Ensuite, nous commençons un nouveau jeu avec des connaissances augmentées.
L'agent prend les meilleures décisions à chaque itération.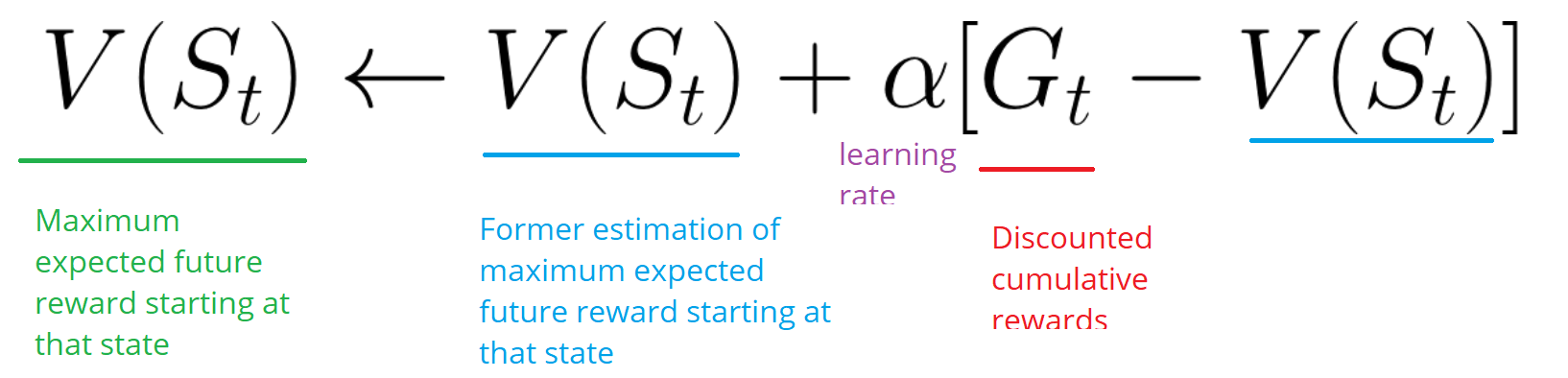
Voici un exemple:
Si nous prenons le labyrinthe comme un environnement:
- Nous partons toujours du même point de départ.
- Nous arrêtons l'épisode si le chat nous mange ou si nous bougeons> 20 pas.
- À la fin de l'épisode, nous avons une liste d'états, d'actions, de récompenses et de nouveaux états.
- L'agent résume la récompense totale de Gt (pour voir comment il l'a fait).
- Ensuite, il met à jour V (st) selon la formule ci-dessus.
- Ensuite, un nouveau jeu commence avec de nouvelles connaissances.
En exécutant de plus en plus d'épisodes, l'
agent apprendra à jouer de mieux en mieux.Différences de temps: apprendre à chaque pas de tempsLa méthode d'apprentissage par différence temporelle (TD) n'attendra pas la fin de l'épisode pour mettre à jour la récompense la plus élevée possible. Il mettra à jour V en fonction de l'expérience acquise.
Cette méthode est appelée TD (0) ou
TD par étapes (met à jour la fonction utilitaire après une seule étape).
Les méthodes TD n'attendent que le prochain
pas de temps pour mettre à jour les valeurs. Au temps t + 1
, une cible TD est formée en utilisant la récompense Rt + 1 et la note actuelle V (St + 1).La cible TD est une estimation de la valeur attendue: en fait, vous mettez à jour la note V (St) précédente vers la cible en une seule étape.
Exploration / exploitation de compromisAvant d'envisager différentes stratégies pour résoudre les problèmes d'entraînement par renforcement, nous devons considérer un autre sujet très important: le compromis entre l'exploration et l'exploitation.
- L'intelligence trouve plus d'informations sur l'environnement.
- L'exploitation utilise des informations connues pour maximiser les récompenses.
N'oubliez pas que l'objectif de notre agent RL est de maximiser les récompenses cumulées attendues. Cependant, nous pouvons tomber dans un piège commun.
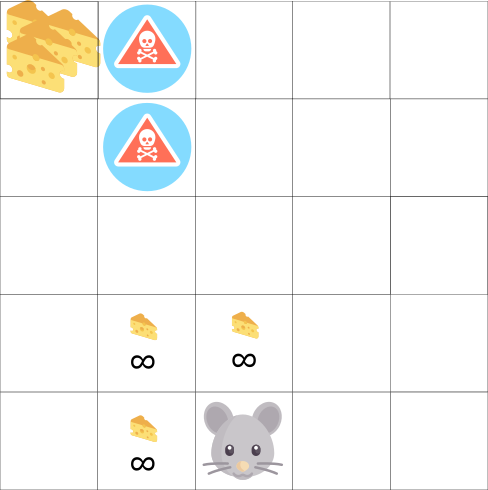
Dans ce jeu, notre souris peut avoir un nombre infini de petits morceaux de fromage (+1 chacun). Mais au sommet du labyrinthe, il y a un morceau de fromage géant (+1000). Cependant, si nous nous concentrons uniquement sur les récompenses, notre agent n'atteindra jamais un gigantesque morceau. Au lieu de cela, il n'utilisera que la source de récompenses la plus proche, même si cette source est petite (exploitation). Mais si notre agent reconnait un peu, il pourra trouver une grosse récompense.
C'est ce que nous appelons un compromis entre exploration et exploitation. Nous devons définir une règle qui aidera à faire face à ce compromis. Dans les prochains articles, vous apprendrez différentes façons de procéder.
Trois approches d'apprentissage par renforcementMaintenant que nous avons identifié les principaux éléments de l'apprentissage par renforcement, passons à trois approches pour résoudre l'apprentissage renforcé: basé sur les coûts, basé sur les politiques et basé sur le modèle.
Basé sur le coûtDans le RL basé sur les coûts, l'objectif est d'optimiser la fonction d'utilité V (s).
Une fonction d'utilité est une fonction qui nous informe de la récompense maximale attendue qu'un agent recevra dans chaque état.
La valeur de chaque état est le montant total de la récompense que l'agent peut s'attendre à accumuler à l'avenir, à partir de cet état.
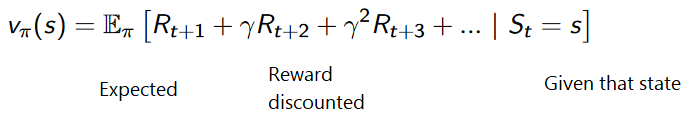
L'agent utilisera cette fonction utilitaire pour décider de l'état à choisir à chaque étape. L'agent sélectionne l'état avec la valeur la plus élevée.
Dans l'exemple du labyrinthe, à chaque étape, nous prendrons la valeur la plus élevée: -7, puis -6, puis -5 (etc.) pour atteindre l'objectif.
Basé sur la politiqueDans RL basé sur des politiques, nous voulons optimiser directement la fonction de politique π (s) sans utiliser la fonction d'utilité. Une politique est ce qui détermine le comportement d'un agent à un moment donné.
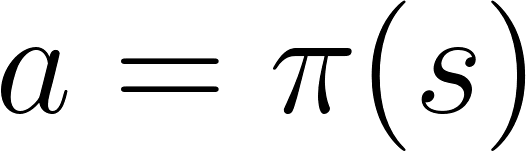 action = politique (état)
action = politique (état)Nous étudions la fonction de la politique. Cela nous permet de corréler chaque état avec la meilleure action appropriée.
Il existe deux types de politiques:
- Déterministe: la politique dans un État donné renverra toujours la même action.
- Stochastique: affiche la probabilité de distribution par action.

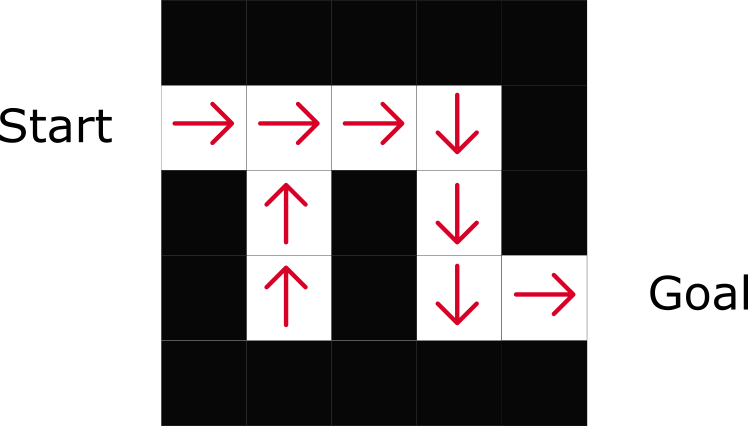
Comme vous pouvez le voir, la politique indique directement la meilleure action pour chaque étape.
Basé sur le modèleDans RL basé sur un modèle, nous modélisons l'environnement. Cela signifie que nous créons un modèle de comportement environnemental. Le problème est que chaque environnement aura besoin d'une vue différente du modèle. C'est pourquoi nous ne nous concentrerons pas beaucoup sur ce type de formation dans les articles suivants.
Présentation de l'apprentissage par renforcement profondL'apprentissage par renforcement profond introduit des réseaux de neurones profonds pour résoudre les problèmes d'apprentissage renforcé - d'où le nom «profond».
Par exemple, dans le prochain article, nous travaillerons sur Q-Learning (apprentissage par renforcement classique) et Deep Q-Learning.
Vous verrez la différence dans le fait que dans la première approche, nous utilisons l'algorithme traditionnel pour créer la table Q, ce qui nous aide à trouver l'action à entreprendre pour chaque état.
Dans la deuxième approche, nous utiliserons un réseau de neurones (pour approximer les récompenses basées sur l'état: valeur q).
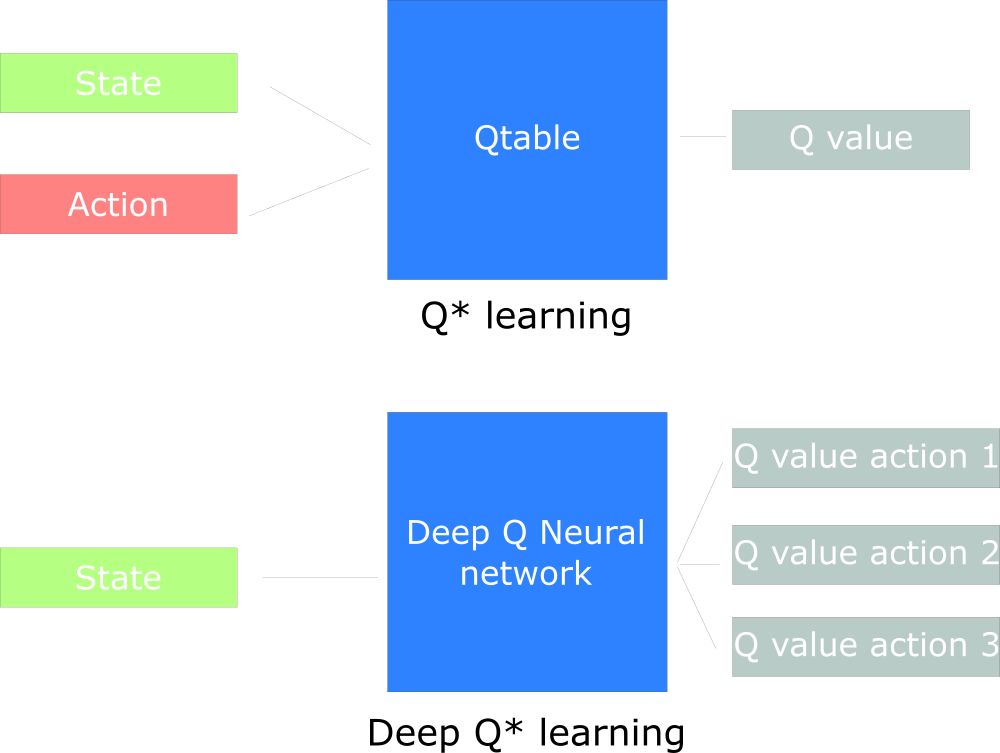 Tableau de conception inspiré par Udacity Q
Tableau de conception inspiré par Udacity Q
C’est tout. Comme toujours, nous attendons vos commentaires ou questions ici, ou vous pouvez les poser au professeur de cours
Arthur Kadurin dans sa
leçon ouverte sur le réseautage.