
Les fichiers PDF contiennent beaucoup d'informations. La plupart sont utilisés pour la même visualisation du document sur différentes plateformes. Mais il y a aussi beaucoup de métadonnées: la date et l'heure de création et d'édition, quelle application a été utilisée, le sujet du document, le titre, l'auteur et bien plus encore. Il s'agit d'un ensemble standard de métadonnées, et il existe des moyens d'insérer des métadonnées personnalisées dans un PDF: des commentaires masqués au milieu du fichier. Dans cet article, nous présenterons certaines formes de métadonnées et montrerons où les rechercher.
Métadonnées d'information
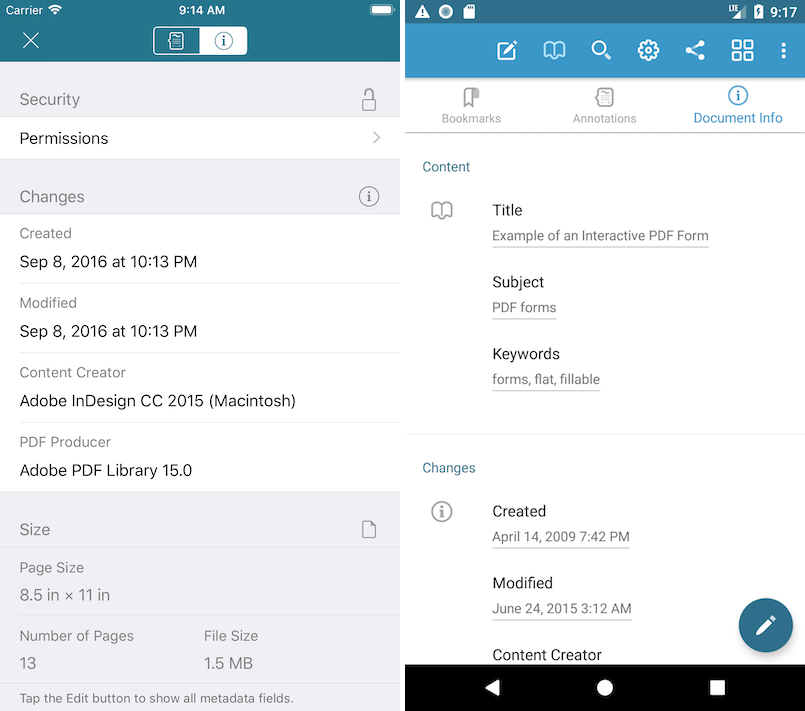
À partir de PDF 1.0, il existe un ensemble normalisé de valeurs qui peuvent être ajoutées au document. Les gestionnaires de fichiers utilisent ces valeurs pour améliorer les recherches de documents. Ils comprennent:
- L'auteur
- Date de création
- Créateur
- Producteur
Dans PDF 1.1, cet ensemble a été étendu pour inclure des données supplémentaires qui aident à trouver des documents:
- Le titre
- Thème
- Mots clefs
- Date d'édition (ModDate)
À strictement parler, ces informations ne sont pas réellement cachées, car de nombreuses applications vous permettent de les visualiser. Mais il n'est pas montré au grand public. Dans tous les cas, si vous êtes préoccupé par la sécurité, vous devez vous fier à ces informations car elles peuvent être modifiées ultérieurement. Étant donné que les métadonnées peuvent être mises à jour séparément du contenu affiché, cela signifie que le gestionnaire de fichiers et les métadonnées afficheront les modifications et que le contenu peut ne pas changer.
Métadonnées supplémentaires
La norme PDF prend désormais en charge encore plus de métadonnées. Au lieu d'un petit ensemble de valeurs par défaut, vous pouvez stocker tout un flux d'informations au format
XMP . En conséquence, tout type de données peut y être intégré. Encore une fois, ils ne sont pas affichés, mais ils peuvent être analysés par le gestionnaire de fichiers.
Le flux XMP peut être encodé, il n'est donc pas toujours lu par des personnes, mais de nombreuses applications peuvent lire et modifier ces informations. Voici un exemple de ce à quoi ressemble XMP dans un format lisible par l'homme:
<xmp:CreateDate>1851-08-18</xmp:CreateDate> <xmp:CreatorTool>Ink and Paper</xmp:CreatorTool> <dc:creator> <rdf:Seq> <rdf:li>Nick Winder</rdf:li> </rdf:Seq> </dc:creator> <dc:title> <rdf:Alt> <rdf:li xml:lang="x-default">My Amazing PDF</rdf:li> </rdf:Alt> </dc:title>
Il est facile de comprendre que ces informations sont inestimables lorsque vous essayez de déterminer l’historique d’un document ou lorsque vous essayez d’intégrer d’autres informations. PSPDFKit pour
iOS et
Android prend en charge la lecture et la modification des métadonnées.
Métadonnées d'objet
Les flux de métadonnées ne sont pas limités aux documents; les métadonnées peuvent également être affectées à n'importe quel objet d'un document. Par exemple, un flux avec une image intégrée. Pour compliquer les choses, les métadonnées auxiliaires peuvent également être stockées dans le flux lui-même. Si nous allons encore plus loin, nous pouvons
intégrer le PDF dans les métadonnées du flux d'images , réalisant ainsi une récursion infinie! Ainsi, la prochaine fois que vous vérifierez les métadonnées pour obtenir des informations, n'oubliez pas que vous devrez peut-être passer par plusieurs niveaux pour trouver les informations que vous recherchez.
Sauvegarde / mise à jour supplémentaire
La norme PDF a un concept de sauvegarde supplémentaire que de nombreuses applications, y compris PSPDFKit, implémentent pour accélérer l'enregistrement. En bref, cette méthode ajoute des informations supplémentaires à la fin du document et les anciens objets qui ne sont plus référencés y resteront suspendus. C'est formidable lorsque vous modifiez des éléments de document à la volée et que vous ne voulez pas attendre un long processus d'enregistrement, ou, par exemple, pour la fonction d'enregistrement automatique, où le processus s'exécute dans le thread d'arrière-plan, et nous voulons utiliser un minimum de ressources.
Comme vous pouvez le comprendre, cela ouvre toute une boîte de Pandore: l'historique du document montre des informations confidentielles ou erronées qui ont été supprimées des yeux, mais elles sont restées dans le document. Dans de telles situations, il est recommandé d'enregistrer complètement le document. Cela entraînera la suppression d'anciens objets ou même un «lissage», de sorte que les
formulaires ne pourront plus être modifiés à l'avenir.
Commentaires PDF
De nombreux langages de programmation fournissent des commentaires afin que le compilateur ou l'interpréteur ignore la chaîne, la même option est dans le PDF. Le symbole% est utilisé dans le format de différentes manières, mais l'un d'eux est une indication d'un commentaire dans le code. Par conséquent, si l'utilisateur ouvre le document dans un éditeur de texte, il peut voir des messages secrets insérés par votre processeur PDF. Les moteurs de rendu PDF ignoreront ces lignes de commentaires, de sorte que le fichier semble correct et n'affiche aucun commentaire après le rendu.
Un gros dictionnaire!
La dernière chose à noter est que le format PDF est en fait un gros dictionnaire! Techniquement, n'importe qui peut intégrer un document et changer quelque chose. Tous les changements ne sont pas aussi faciles que l'édition d'une seule ligne, mais cela peut être fait. Pour cette raison, vous devez toujours vous rappeler quelles informations peuvent être cachées dans le PDF. En outre, si vous traitez des informations confidentielles, vous devez absolument utiliser
des signatures numériques pour vous assurer que le document n'a pas été modifié par une personne autre que son auteur et que l'auteur est bien celui que vous attendez et pas quelqu'un d'autre.
Conclusion
Cet article répertorie certaines façons dont les métadonnées peuvent entrer dans un document à votre insu. Il existe d'autres facteurs à considérer, tels que la
prise en charge JavaScript pour PDF . Avec JavaScript, les options sont généralement infinies. Les objets cachés peuvent également être stockés dans des documents, qui sont généralement analysés mais pas affichés. C'est un bon moyen d'injecter un certain type d'informations dans l'analyseur. Le PDF est une norme très étendue, vous devez donc toujours savoir quel type de logiciel de lecture PDF vous utilisez et lui faire confiance.