Analyse des publications Lenta.ru sur 18 ans (de septembre 1999 à décembre 2017) en utilisant python, sklearn, scipy, XGBoost, pymorphy2, nltk, gensim, MongoDB, Keras et TensorFlow.

L'étude a utilisé les données du post " Analyze this - Lenta.ru " par ildarchegg . L'auteur a aimablement fourni 3 gigaoctets d'articles dans un format pratique, et j'ai décidé que c'était une excellente occasion de tester certaines méthodes de traitement de texte. En même temps, si vous avez de la chance, apprenez quelque chose de nouveau sur le journalisme russe, la société et en général.
Contenu:
MongoDB pour importer json en python
Malheureusement, json avec des textes s'est avéré être un peu cassé, ce n'est pas critique pour moi, mais python a refusé de travailler avec le fichier. Par conséquent, je l'ai d'abord importé dans MongoDB, et seulement ensuite, via MongoClient à partir de la bibliothèque pymongo, j'ai chargé le tableau et l'ai re-stocké en csv en morceaux.
D'après les commentaires: 1. J'ai dû démarrer la base de données avec la commande sudo service mongod start - il existe d'autres options, mais elles n'ont pas fonctionné; 2. mongoimport - une application séparée, elle ne démarre pas à partir de la console mongo, seulement à partir du terminal.
Les lacunes dans les données sont réparties uniformément sur plusieurs années. Je ne prévois pas d'utiliser la période de moins d'un an, j'espère que cela n'affectera pas l'exactitude des conclusions.
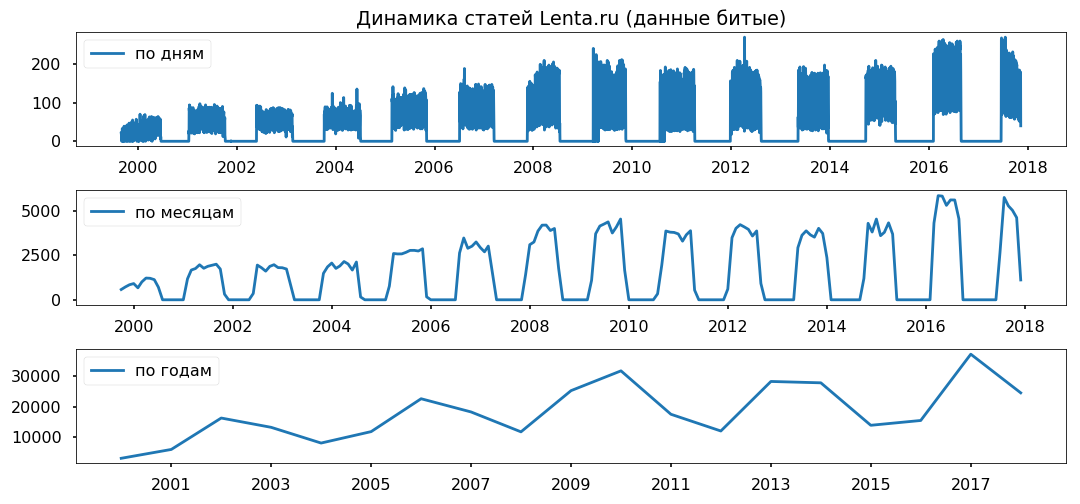
Nettoyage et normalisation du texte
Avant d'analyser directement le tableau, vous devez le mettre sous la forme standard: supprimez les caractères spéciaux, convertissez le texte en minuscules (les méthodes de chaîne pandas ont fait du bon travail), supprimez les mots vides (stopwords.words ('russe') de nltk.corpus), remettez les mots dans leur forme normale en utilisant la lemmatisation (pymorphy2.MorphAnalyzer).
Il y avait quelques défauts, par exemple, Dmitry Peskov est devenu "Dmitry" et "sand", mais dans l'ensemble, j'étais satisfait du résultat.
Nuage de tags
À titre de graine, voyons quelles publications sont sous la forme la plus générale. Nous afficherons les 50 mots les plus fréquemment utilisés par les journalistes de Lenta de 1999 à 2017 sous la forme d'un nuage de tags.

Ria Novosti (la source la plus populaire), milliards de dollars et millions de dollars (sujets financiers), présents (circulation de la parole commune à tous les sites d'actualités), organisme chargé de l'application des lois et affaire pénale (actualités pénales) ), «Premier ministre» et «Vladimir Poutine» (politique) - le style et les thèmes attendus pour le portail d'actualités.
Modélisation sur le thème LDA
Nous calculons les sujets les plus populaires pour chaque année en utilisant le LDA de gensim. LDA (modélisation thématique utilisant la méthode de placement latent Dirichlet) identifie automatiquement les sujets cachés (un ensemble de mots qui se produisent ensemble et le plus souvent) par les fréquences de mots observées dans les articles.
La pierre angulaire du journalisme national était la Russie, Poutine et les États-Unis.
Certaines années, ce sujet s'est dilué avec la guerre tchétchène (de 1999 à 2000), le 11 septembre - en 2001, et l'Irak (de 2002 à 2004). De 2008 à 2009, l'économie est arrivée en première place: intérêts, entreprise, dollar, rouble, milliards, millions. En 2011, ils ont souvent écrit sur Kadhafi.
De 2014 à 2017 les années de l'Ukraine ont commencé et se poursuivent en Russie. Le pic est survenu en 2015, puis la tendance a commencé à décliner, mais reste toujours à un niveau élevé.
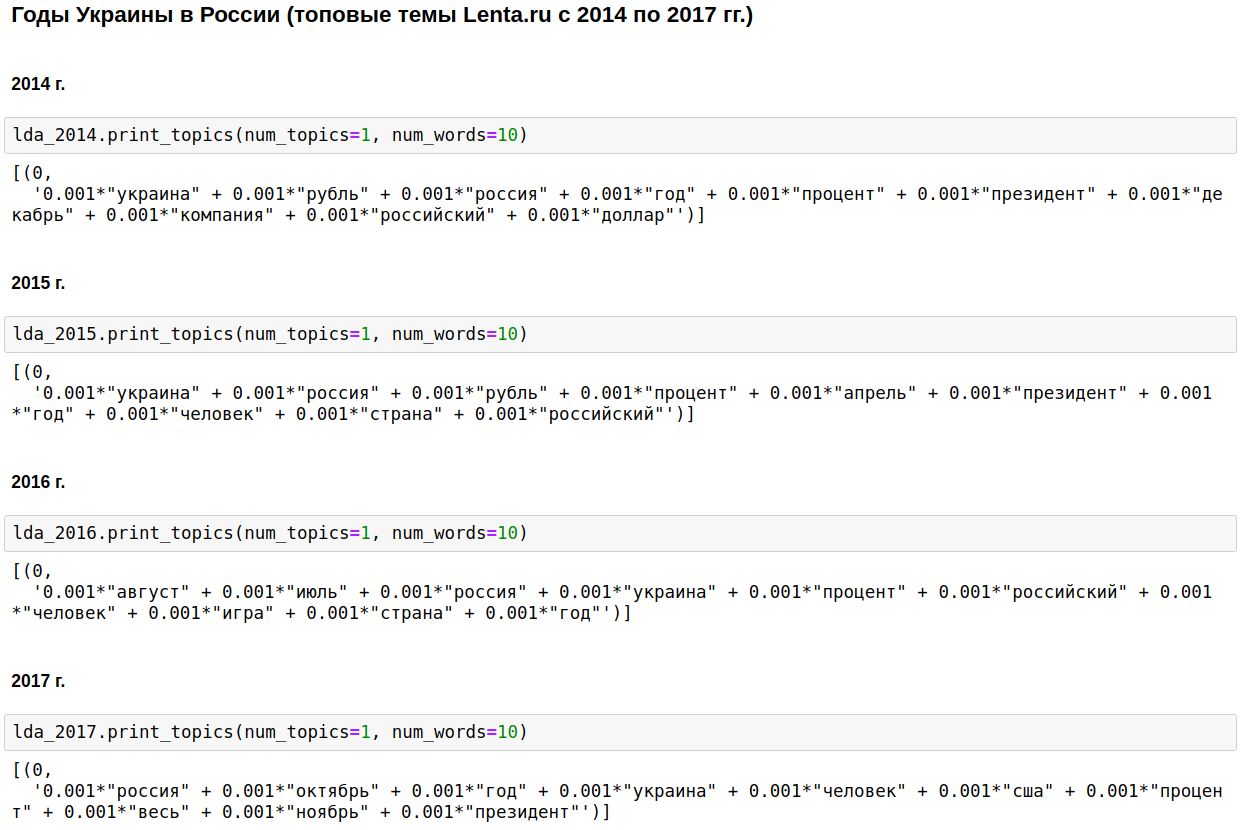
C'est intéressant, bien sûr, mais il n'y a rien que je ne sache ou devine.
Modifions un peu l'approche - sélectionnons les meilleurs sujets pour tout le temps et voyons comment leur ratio a changé d'année en année, c'est-à-dire que nous étudierons l'évolution des sujets.
L'option la plus interprétée était Top 5:
- Crime (homme, police, se produire, détenir, policier);
- Politique (Russie, Ukraine, président, États-Unis, chef);
- Culture (spinner, purulent, instagram, randonnées - oui, c'est notre culture, bien que spécifiquement ce sujet se soit avéré plutôt mélangé);
- Sport (match, équipe, match, club, athlète, championnat);
- Science (scientifique, espace, satellite, planète, cellule).
Ensuite, nous prenons chaque article et voyons comment il se rapporte à un sujet particulier, par conséquent, tous les documents seront divisés en cinq groupes.
La politique s'est avérée être la plus populaire - moins de 80% de toutes les publications. Cependant, le pic de popularité des documents politiques a été franchi en 2014, maintenant leur part diminue, et la contribution à l'agenda d'information de Crime and Sports augmente.
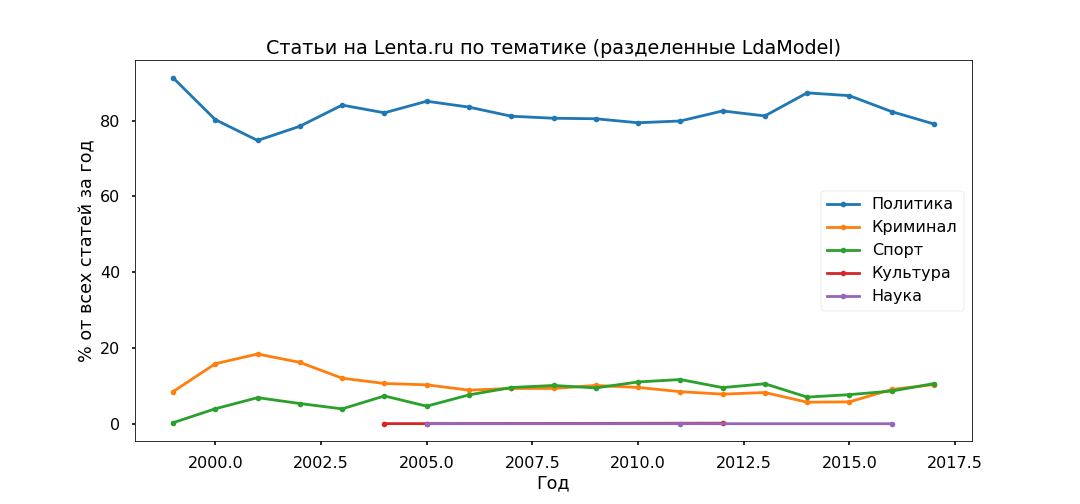
Nous vérifierons l'adéquation des modèles thématiques en utilisant les sous-titres indiqués par les éditeurs. Les principales sous-catégories sont plus ou moins correctement identifiées depuis 2013.

Aucune contradiction particulière n'a été constatée: la politique stagne en 2017, le football et les incidents se développent, l'Ukraine est toujours dans la tendance, avec un pic en 2015.
Prédiction de popularité: XGBClassifier, LogisticRegression, Embedding & LSTM
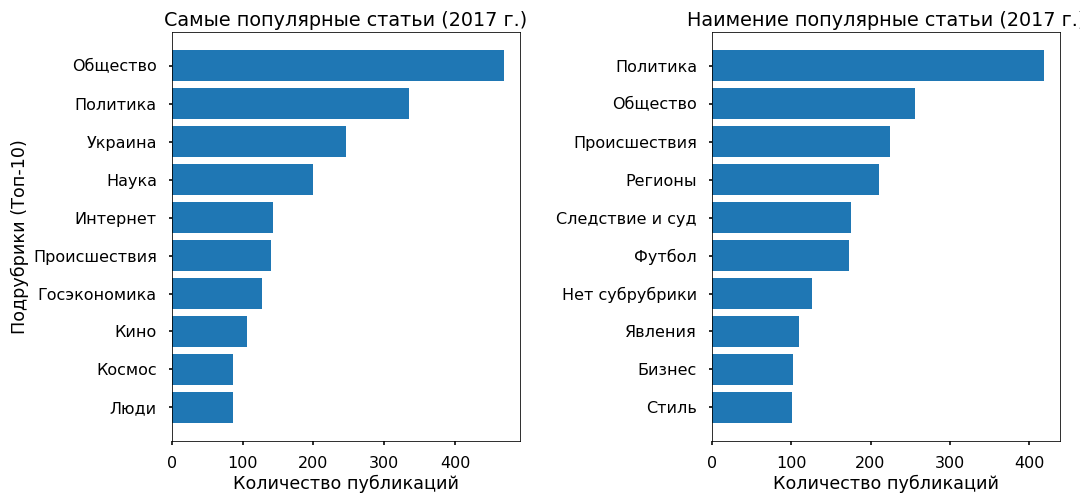
Essayons de comprendre s'il est possible de prédire la popularité d'un article sur la bande à partir du texte, et de quoi dépend généralement cette popularité. En tant que variable cible, j'ai pris le nombre de référentiels Facebook pour 2017.
3 000 articles pour 2017 n'avaient pas de reposts sur Fb - ils ont été classés dans la catégorie «impopulaire», 3 000 matériaux avec le plus grand nombre de reposts ont reçu le label «le plus populaire».
Le texte (6000 publications pour 2017) a été divisé en unogrammes et bigrammes (mots symboliques, phrases à un et deux mots) et une matrice a été construite où les colonnes sont des jetons, des lignes sont des articles et à l'intersection est relative fréquence d'apparition des mots dans les articles. Fonctions utilisées de sklearn - CountVectorizer et TfidfTransformer.
Les données préparées ont été envoyées à l'entrée XGBClassifier (un classificateur basé sur l'augmentation de gradient de la bibliothèque xgboost), qui après 13 minutes d'énumération des hyperparamètres (GridSearchCV avec cv = 3) a donné une précision de 76% sur le test.

Ensuite, j'ai utilisé la régression logistique habituelle (sklearn.linear_model.LogisticRegression) et après 17 secondes, j'ai obtenu une précision de 81%.
Encore une fois, je suis convaincu que les méthodes linéaires conviennent le mieux à la classification des textes, à condition que les données soient soigneusement préparées.
En hommage à la mode, j'ai un peu testé les réseaux de neurones. J'ai traduit les mots en nombres à l'aide de one_hot à partir de keras, apporté tous les articles à la même longueur (fonction pad_sequences à partir de keras) et appliqué LSTM (réseau neuronal convolutionnel utilisant le backend TensorFlow) via la couche Embedding (pour réduire la dimension et accélérer le temps de traitement).
Le réseau a fonctionné en 2 minutes et a montré une précision au test de 70%. Ce n'est pas du tout la limite, mais dans ce cas, cela n'a aucun sens de s'embêter beaucoup.
En général, toutes les méthodes ont produit une précision relativement faible. Comme le montre l'expérience, les algorithmes de classification fonctionnent bien avec une variété de styles - en d'autres termes, sur les documents protégés par le droit d'auteur. Il existe de tels matériaux sur Lenta.ru, mais il y en a très peu - moins de 2%.

Le tableau principal est écrit en utilisant un vocabulaire d'actualité neutre. Et la popularité des nouvelles n'est pas déterminée par le texte lui-même et pas même par le sujet en tant que tel, mais par leur appartenance à une tendance à la hausse de l'information.
Par exemple, plusieurs articles populaires couvrent des événements en Ukraine, les moins populaires ne concernent presque pas ce sujet.
Explorer des objets à l'aide de Word2Vec
En conclusion, je voulais mener une analyse sentimentale - pour comprendre comment les journalistes se rapportent aux objets les plus populaires qu'ils mentionnent dans leurs articles, si leur attitude change avec le temps.
Mais je n'ai pas les données marquées, et une recherche sur les thésaurus sémantiques ne fonctionnera probablement pas correctement, car le vocabulaire des actualités est assez neutre, avare d'émotions. J'ai donc décidé de me concentrer sur le contexte dans lequel les objets sont mentionnés.
J'ai pris l'Ukraine (2015 vs 2017) et Poutine (2000 vs 2017) comme test. J'ai sélectionné les articles dans lesquels ils sont mentionnés, traduit le texte dans un espace vectoriel multidimensionnel (Word2Vec de gensim.models) et projeté en deux dimensions en utilisant la méthode des composants principaux.
Après avoir rendu les images, elles se sont avérées être épiques, pas moins que la taille d'une tapisserie de Bayeux. J'ai découpé les grappes nécessaires pour simplifier la perception, comme j'ai pu, désolé pour les "chacals".


Ce que j'ai remarqué.
Poutine du modèle 2000 est toujours apparu dans le contexte de la Russie et s'est adressé personnellement. En 2017, le président de la Fédération de Russie est devenu un leader (quoi que cela signifie) et s'est éloigné du pays, maintenant, à en juger par le contexte, il est un représentant du Kremlin qui communique avec le monde par le biais de son attaché de presse.
Ukraine-2015 dans les médias russes - guerre, batailles, explosions; il est mentionné dépersonnalisé (Kiev a déclaré, Kiev a commencé). L'Ukraine-2017 apparaît principalement dans le cadre de négociations entre responsables, et ces personnes ont des noms spécifiques.
...
Vous pouvez interpréter les informations reçues pendant un certain temps, mais, comme je pense, il s'agit d'une ressource hors sujet sur cette ressource. Ceux qui le souhaitent peuvent voir par vous-même. Je joins le code et les données.
Lien de script
Liaison de données