 Un auto-encodeur variationnel (auto-encoder) est un modèle génératif qui apprend à afficher des objets dans un espace caché donné.
Un auto-encodeur variationnel (auto-encoder) est un modèle génératif qui apprend à afficher des objets dans un espace caché donné.Vous êtes-vous déjà demandé comment fonctionne un modèle d'auto-encodeur variationnel (VAE)? Vous voulez savoir comment VAE génère de nouveaux exemples comme l'ensemble de données sur lequel il a été formé? Après avoir lu cet article, vous aurez une compréhension théorique du fonctionnement interne de la VAE, et vous pourrez également l'implémenter vous-même. Ensuite, je montrerai le code VAE fonctionnel formé sur un ensemble de chiffres manuscrits, et nous nous amuserons à générer de nouveaux chiffres!
Modèles génératifs
La VAE est un modèle génératif - elle estime la densité de probabilité (PDF) des données d'entraînement. Si un tel modèle est formé aux images naturelles, il attribuera une valeur de probabilité élevée à l'image du lion et une valeur faible à l'image des conneries aléatoires.
Le modèle VAE sait également prendre des exemples à partir de PDF formés, ce qui est le plus cool, car il peut générer de nouveaux exemples similaires à l'ensemble de données d'origine!
Je vais expliquer VAE en utilisant le jeu de nombres manuscrits
MNIST . Les données d'entrée pour le modèle sont des images au format
. Le modèle doit évaluer la probabilité d'apparition d'un chiffre comme un chiffre.
Tâche de modélisation d'image
L'interaction entre pixels est une tâche difficile. Si les pixels sont indépendants les uns des autres, vous devez étudier le PDF de chaque pixel indépendamment, ce qui est facile. La sélection est également simple - nous prenons chaque pixel séparément.
Mais dans les images numériques, il existe des dépendances claires entre les pixels. Si vous voyez le début des quatre sur la moitié gauche, vous serez très surpris si la moitié droite est l'achèvement de zéro. Mais pourquoi? ..
Espace caché
Vous savez que chaque image a un numéro. Entrée à
ne contient clairement pas ces informations. Mais ça doit être quelque part ... Ce "quelque part" est un espace caché.

Vous pouvez considérer l'espace caché comme
où chaque vecteur contient
éléments d'information nécessaires pour rendre une image. Supposons que la première dimension contienne un nombre représenté par un chiffre. La deuxième dimension peut être la largeur. Le troisième est l'angle, et ainsi de suite.
Nous pouvons imaginer le processus de dessin d'une personne en deux étapes. Premièrement, une personne détermine - consciemment ou non - tous les attributs du nombre qui va être affiché. Ensuite, ces décisions sont transformées en traits sur papier.
VAE tente de simuler ce processus: pour une image donnée
nous voulons trouver au moins un vecteur caché qui puisse le décrire; un vecteur contenant des instructions pour générer
. En le formulant par la
formule de la probabilité totale , nous obtenons
.
Mettons un certain sens raisonnable dans cette équation:
- Intégrale signifie que les candidats doivent être recherchés dans tous les espaces cachés.
- Pour chaque candidat nous posons la question: est-il possible de générer en utilisant des instructions ? Est-il assez grand ? Par exemple, si code les informations sur le chiffre 7, puis l'image 8 n'est pas possible. Cependant, l'image 1 est acceptable car 1 et 7 sont similaires.
- Nous en avons trouvé un bon. ? Super! Mais attendez une seconde ... combien ça coûte probablement? assez grand? Considérons l'image du nombre inversé 7. Une correspondance idéale serait un vecteur caché décrivant la vue 7, où la taille de l'angle est réglée à 180 °. Cependant, C'est peu probable, car généralement les nombres ne sont pas écrits à un angle de 180 °.
L'objectif de la formation VAE est de maximiser
. Nous modéliserons
utilisant une distribution gaussienne multidimensionnelle
.
modélisé à l'aide d'un réseau neuronal.
Est un hyperparamètre pour multiplier la matrice d'identité
.
Gardez à l'esprit que
- c'est ce que nous allons utiliser pour générer de nouvelles images en utilisant un modèle formé. Le chevauchement d'une distribution gaussienne est uniquement à des fins éducatives. Si nous prenons la fonction delta de Dirac (c'est-à-dire déterministe
), alors nous ne pourrons pas entraîner le modèle en descente de gradient!
Les merveilles de l'espace caché
L'approche de l'espace caché pose deux gros problèmes:
- Quelles informations contient chaque dimension? Certaines dimensions peuvent se rapporter à des éléments abstraits, tels que le style. Même s'il était facile d'interpréter toutes les dimensions, nous ne voulons pas attribuer d'étiquettes à l'ensemble de données. Cette approche ne s'adapte pas à d'autres ensembles de données.
- L'espace caché peut être confondu lorsqu'il existe une corrélation entre les dimensions. Par exemple, un nombre dessiné très rapidement peut conduire simultanément à l'apparition de traits angulaires et plus fins. La définition de ces dépendances est difficile.
L'apprentissage en profondeur vient à la rescousse
Il s'avère que chaque distribution peut être générée en appliquant une fonction assez complexe à la distribution gaussienne multidimensionnelle standard.
Choisissez
comme une distribution gaussienne multidimensionnelle standard. Ainsi modélisé par un réseau de neurones
peut être divisé en deux phases:
- Les premières couches cartographient la distribution gaussienne dans la vraie distribution sur l'espace caché. Nous ne pouvons pas interpréter les mesures, mais cela n'a pas d'importance.
- Les calques suivants seront affichés à partir de l'espace caché dans .
Alors, comment entraînons-nous cette bête?
Formule pour
insoluble, nous l'approximons donc par la méthode de Monte Carlo:
- Sélection \ {z_i \} _ {i = 1} ^ n du précédent
- Rapprochement avec
Super! Alors essayez juste beaucoup de différents
et commencez la fête de propagation des bogues!
Malheureusement depuis
très multidimensionnelle, pour obtenir une approximation raisonnable, de nombreux échantillons sont nécessaires. Je veux dire si vous essayez
, alors quelles sont les chances d'obtenir une image qui ressemble à quelque chose
? Cela explique d'ailleurs pourquoi
doit attribuer une valeur de probabilité positive à toute image possible, sinon le modèle ne pourra pas apprendre: échantillonnage
se traduira par une image qui est presque certainement différente de
, et si la probabilité est 0, les gradients ne pourront pas se propager.
Comment résoudre ce problème?
Coupez le chemin!

La plupart des échantillons
rien ne sera ajouté de la sélection à
- Ils sont trop loin au-delà de ses frontières. Maintenant, si vous saviez à l'avance d'où les prendre ...
Peut entrer
. Étant donné
seront formés pour attribuer des valeurs de probabilité élevées à
susceptibles de générer
. Vous pouvez maintenant effectuer une évaluation en utilisant la méthode de Monte Carlo, en prélevant beaucoup moins d'échantillons
.
Malheureusement, un nouveau problème se pose! Au lieu de maximiser
nous maximisons
. Comment sont-ils liés les uns aux autres?
Conclusion variationnelle
La conclusion variationnelle fait l'objet d'un article séparé, je ne m'y attarderai donc pas ici en détail. Je peux seulement dire que ces distributions sont liées par cette équation:
est la
distance de Kullback - Leibler , qui évalue intuitivement la similitude des deux distributions.
Dans un instant, vous verrez comment maximiser le côté droit de l'équation. Dans ce cas, le côté gauche est également maximisé:
- maximisé.
- jusqu'où de - réel a priori inconnu - sera minimisé.
La signification du côté droit de l'équation est que nous avons ici des tensions:
- D'une part, nous voulons maximiser la qualité doit être décodé .
- D'un autre côté, nous voulons ( encodeur ) était similaire au précédent (distribution gaussienne multidimensionnelle). Cela peut être considéré comme une régularisation.
Minimisation de la divergence
effectué facilement avec la bonne sélection de distributions. Nous simulerons
comme un réseau de neurones dont la sortie est les paramètres d'une distribution gaussienne multidimensionnelle:
- moyenne
- matrice de covariance diagonale
Puis divergence
devient analytiquement résoluble, ce qui est excellent pour nous (et pour les gradients).
La partie
décodeur est un peu plus compliquée. À première vue, je voudrais dire que ce problème est insoluble par la méthode de Monte Carlo. Mais l'échantillon
de
ne permettra pas aux dégradés de se propager à travers
, car la sélection n'est pas une opération différenciable. C'est un problème, car alors les poids des couches émettant
et
.
Nouvelle astuce de paramétrage
Nous pouvons remplacer
transformation paramétrisée déterministe d'une variable aléatoire non paramétrique:
- Un échantillon de la distribution gaussienne standard (sans paramètres).
- Multiplier l'échantillon par la racine carrée .
- Ajout au résultat .
Par conséquent, nous obtenons une distribution égale à
. Maintenant, l'opération de récupération provient de la distribution gaussienne standard. Par conséquent, les gradients peuvent se propager à travers
et
puisque maintenant ce sont des voies déterministes.
Résultat? Le modèle pourra apprendre à ajuster les paramètres
: elle va se concentrer sur le bien
qui sont capables de produire
.
Tout mettre ensemble
Le modèle VAE peut être difficile à comprendre. Nous avons examiné beaucoup de documents difficiles à digérer.
Permettez-moi de résumer toutes les étapes de la mise en œuvre de la VAE.
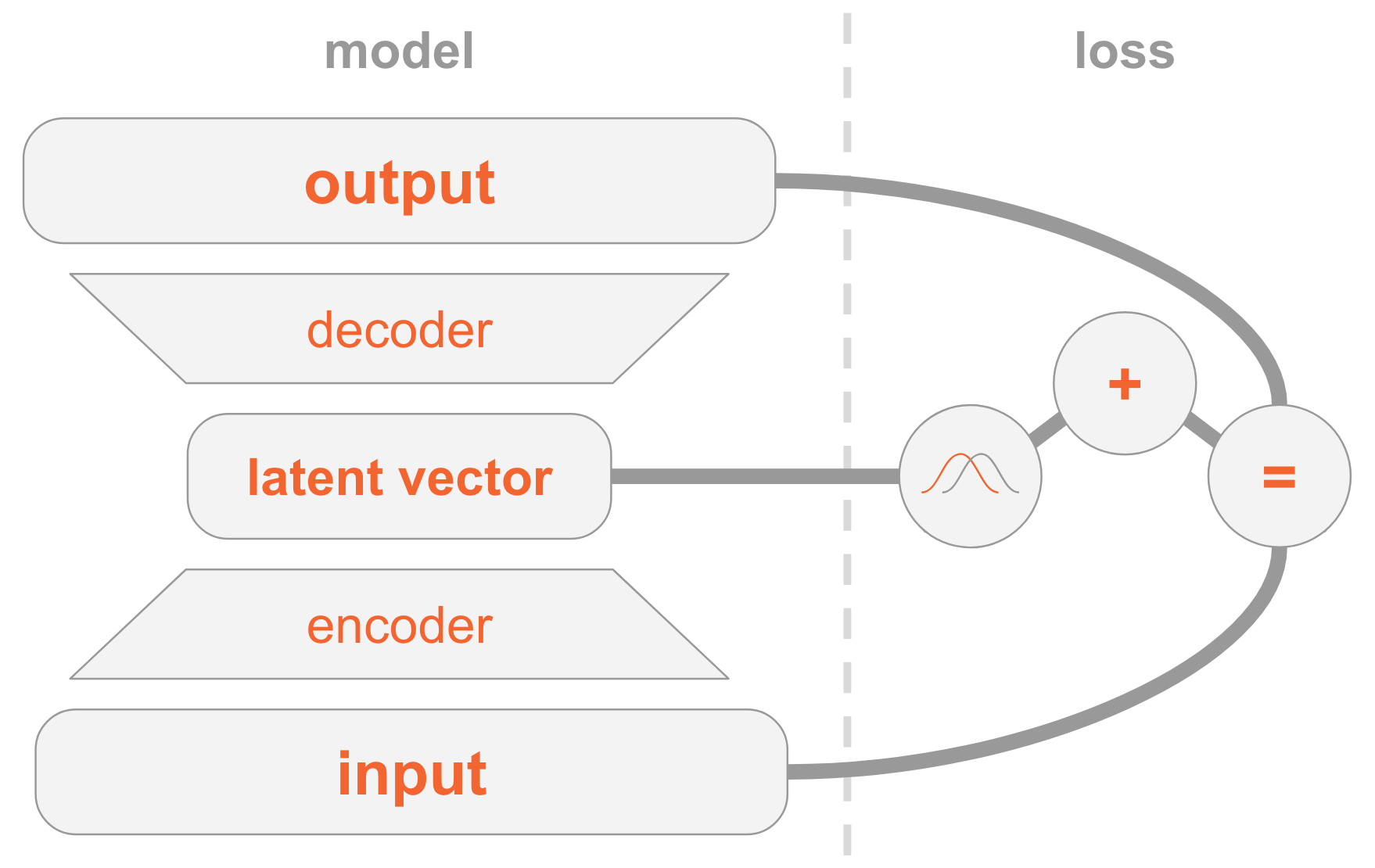
À gauche, nous avons une définition de modèle:
- L'image d'entrée est transmise via le réseau codeur.
- L'encodeur fournit des paramètres de distribution .
- Vecteur caché tiré de . Si l'encodeur est bien formé, alors dans la plupart des cas contenir une description .
- Décodeur décode dans l'image.
Sur le côté droit, nous avons une fonction de perte:
- Erreur de récupération: la sortie doit être similaire à l'entrée.
- doit être similaire à la précédente, c'est-à-dire une distribution normale standard multidimensionnelle.
Pour créer de nouvelles images, vous pouvez directement sélectionner le vecteur caché de la distribution précédente et le décoder en image.
Code de travail
Nous allons maintenant étudier la VAE plus en détail et considérer le code de travail. Vous comprendrez tous les détails techniques nécessaires à la mise en œuvre de la VAE. En bonus, je vais vous montrer une astuce intéressante: comment attribuer des rôles spéciaux à certaines dimensions du vecteur caché afin que le modèle commence à générer des images des nombres indiqués.
import numpy as np import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data import matplotlib.pyplot as plt np.random.seed(42) tf.set_random_seed(42) %matplotlib inline
Je vous rappelle que les modèles sont formés sur
MNIST - un ensemble de chiffres manuscrits. Les images d'entrée sont au format
.
mnist = input_data.read_data_sets('MNIST_data') input_size = 28 * 28 num_digits = 10
Ensuite, nous définissons les hyperparamètres.
N'hésitez pas à jouer avec différentes valeurs pour avoir une idée de la façon dont elles affectent le modèle.
params = { 'encoder_layers': [128],
Modèle

Le modèle se compose de trois sous-réseaux:
- Obtient (image), l'encode en une distribution dans un espace caché.
- Obtient dans l'espace caché (représentation du code de l'image), la décode en l'image correspondante .
- Obtient et détermine le nombre par comparaison avec la couche à 10 dimensions, où la i-ème valeur contient la probabilité du i-ème nombre.
Les deux premiers sous-réseaux sont le fondement de la VAE pure.
La troisième est une
tâche auxiliaire qui utilise certaines des dimensions cachées pour coder les nombres trouvés dans l'image. J'expliquerai pourquoi: plus tôt, nous avons discuté du fait que nous ne nous soucions pas des informations que contient chaque dimension de l'espace caché. Un modèle peut apprendre à coder toute information qu'il juge utile pour sa tâche. Étant donné que nous connaissons l'ensemble de données, nous connaissons l'importance de la dimension, qui contient le type de chiffre (c'est-à-dire sa valeur numérique). Et maintenant, nous voulons aider le modèle en lui fournissant ces informations.
Pour un type de chiffre donné, nous l'encodons directement, c'est-à-dire que nous utilisons un vecteur de taille 10. Ces dix nombres sont associés à un vecteur caché, donc lors du décodage de ce vecteur en image, le modèle utilisera des informations numériques.
Il existe deux façons de fournir des modèles vectoriels à codage direct:
- Ajoutez-le comme entrée au modèle.
- Ajoutez-le comme étiquette, afin que le modèle lui-même calcule la prévision: nous ajouterons un autre sous-réseau qui prédit un vecteur à 10 dimensions, où la fonction de perte est l'entropie croisée avec le vecteur de codage direct attendu.
Choisissez la deuxième option. Pourquoi? Eh bien, lors du test, vous pouvez utiliser le modèle de deux manières:
- Spécifiez l'image comme entrée et affichez un vecteur caché.
- Spécifiez un vecteur caché en entrée et générez une image.
Étant donné que nous voulons prendre en charge la première option, nous ne pouvons pas donner au modèle un chiffre en entrée, car nous ne voulons pas le savoir pendant les tests. Par conséquent, le modèle doit apprendre à le prédire.
def encoder(x, layers): for layer in layers: x = tf.layers.dense(x, layer, activation=params['activation']) mu = tf.layers.dense(x, params['z_dim']) var = 1e-5 + tf.exp(tf.layers.dense(x, params['z_dim'])) return mu, var def decoder(z, layers): for layer in layers: z = tf.layers.dense(z, layer, activation=params['activation']) mu = tf.layers.dense(z, input_size) return tf.nn.sigmoid(mu) def digit_classifier(x, layers): for layer in layers: x = tf.layers.dense(x, layer, activation=params['activation']) logits = tf.layers.dense(x, num_digits) return logits
images = tf.placeholder(tf.float32, [None, input_size]) digits = tf.placeholder(tf.int32, [None])
La formation

Nous allons former un modèle pour optimiser deux fonctions de perte - VAE et classification - à l'aide de
SGD .
À la fin de chaque époque, nous sélectionnons des vecteurs cachés et les décodons en images pour observer visuellement comment le pouvoir générateur du modèle s'améliore au cours des époques. La méthode d'échantillonnage est la suivante:
- Définissez explicitement les dimensions qui sont utilisées pour classer par le chiffre que nous voulons générer. Par exemple, si nous voulons créer une image du nombre 2, nous définissons les mesures .
- Sélectionnez aléatoirement d'autres dimensions de la distribution normale multidimensionnelle. Ce sont les valeurs des différents nombres générés à cette époque. Nous avons donc une idée de ce qui est codé dans d'autres dimensions, par exemple, le style d'écriture manuscrite.
La signification de l'étape 1 est qu'après la convergence, le modèle devrait être capable de classer la figure dans l'image d'entrée selon ces paramètres de mesure. Cependant, ils sont également utilisés dans la phase de décodage pour créer une image. C'est-à-dire que le sous-réseau du décodeur sait: lorsque les mesures correspondent au numéro 2, il doit générer une image avec ce numéro. Par conséquent, si nous réglons manuellement les mesures sur le nombre 2, nous obtiendrons une image générée de cette figure.
samples = [] losses_auto_encode = [] losses_digit_classifier = [] with tf.Session() as sess: sess.run(tf.global_variables_initializer()) for epoch in xrange(params['epochs']): for _ in xrange(mnist.train.num_examples / params['batch_size']): batch_images, batch_digits = mnist.train.next_batch(params['batch_size']) sess.run(train_op, feed_dict={images: batch_images, digits: batch_digits}) train_loss_auto_encode, train_loss_digit_classifier = sess.run( [loss_auto_encode, loss_digit_classifier], {images: mnist.train.images, digits: mnist.train.labels}) losses_auto_encode.append(train_loss_auto_encode) losses_digit_classifier.append(train_loss_digit_classifier) sample_z = np.tile(np.random.randn(1, params['z_dim']), reps=[num_digits, 1]) gen_samples = sess.run(decoded_images, feed_dict={z: sample_z, digit_prob: np.eye(num_digits)}) samples.append(gen_samples)
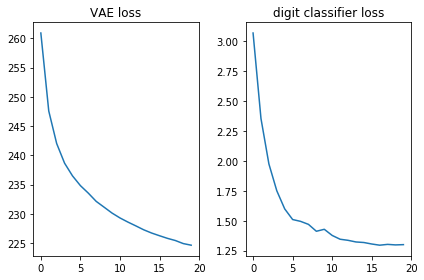
Vérifions que les deux fonctions de perte semblent bonnes, c'est-à-dire qu'elles diminuent:
plt.subplot(121) plt.plot(losses_auto_encode) plt.title('VAE loss') plt.subplot(122) plt.plot(losses_digit_classifier) plt.title('digit classifier loss') plt.tight_layout()
De plus, affichons les images générées et voyons si le modèle peut vraiment créer des images avec des nombres manuscrits:
def plot_samples(samples): IMAGE_WIDTH = 0.7 plt.figure(figsize=(IMAGE_WIDTH * num_digits, len(samples) * IMAGE_WIDTH)) for epoch, images in enumerate(samples): for digit, image in enumerate(images): plt.subplot(len(samples), num_digits, epoch * num_digits + digit + 1) plt.imshow(image.reshape((28, 28)), cmap='Greys_r') plt.gca().xaxis.set_visible(False) if digit == 0: plt.gca().yaxis.set_ticks([]) plt.ylabel('epoch {}'.format(epoch + 1), verticalalignment='center', horizontalalignment='right', rotation=0, fontsize=14) else: plt.gca().yaxis.set_visible(False) plot_samples(samples)
Conclusion
C'est agréable de voir qu'un simple réseau de distribution directe (sans circonvolutions fantaisistes) génère de belles images en seulement 20 époques. Le modèle a rapidement appris à utiliser des mesures spéciales pour les nombres: à la 9e ère, nous voyons déjà la séquence de nombres que nous essayions de générer.
Chaque époque a utilisé des valeurs aléatoires différentes pour d'autres dimensions, donc le style est différent entre les époques, mais il est similaire en leur sein: au moins à l'intérieur de certaines. Par exemple, au 18e, tous les chiffres sont plus gros par rapport au 20e.
Remarques
L'article est basé sur mon expérience et les sources suivantes: