
Comme vous le savez, HTTP 1.1 est un protocole de transfert de données basé sur du texte. Les messages HTTP sont codés à l'aide d'ISO-8859-1 (qui peut être conditionnellement considérée comme une version étendue d'ASCII contenant des trémas, des signes diacritiques et d'autres caractères utilisés dans les langues d'Europe occidentale). Dans le même temps, un autre codage peut être utilisé dans le corps du message, qui doit être indiqué dans l'en-tête "Content-Type". Mais que se passe-t-il si nous devons spécifier des caractères non ASCII non pas dans le corps du message, mais dans les en-têtes eux-mêmes? Le cas le plus courant est probablement de mettre un nom de fichier dans l'en-tête «Content-Disposition». Cela semble être une tâche assez courante, mais sa mise en œuvre n'est pas si évidente.
TL; DR: utilisez l'encodage décrit dans la
RFC 6266 pour «Content-Disposition» et convertissez le texte en latin (translittération) dans les autres cas.
Une petite introduction aux encodages
L'article mentionne et utilise des encodages US-ASCII (souvent appelés simplement ASCII), ISO-8859-1 et UTF-8. Ceci est une petite introduction à ces encodages. La section est destinée aux développeurs qui ne travaillent que rarement ou complètement avec des encodages et ont réussi à les oublier. Si vous ne leur appartenez pas, n'hésitez pas à sauter la section.
ASCII est un encodage simple contenant 128 caractères et comprenant l'alphabet anglais entier, les chiffres, les signes de ponctuation et les caractères de service.
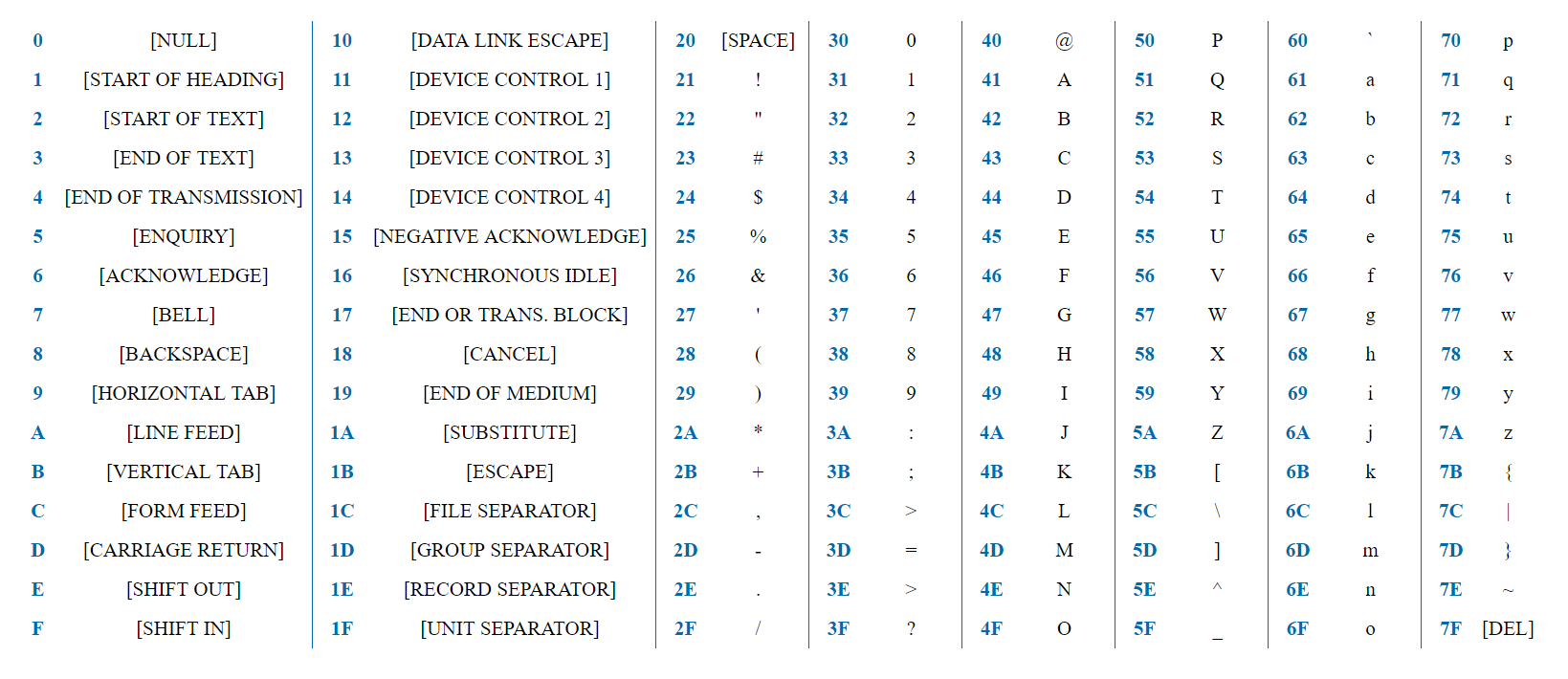
7 bits suffisent pour représenter n'importe quel caractère ASCII. Le mot "test" sera représenté dans la représentation HEX comme 0x74 0x65 0x73 0x74. Le premier bit pour tous les caractères est toujours 0, car les caractères sont codés 128 et l'octet fournit 2 ^ 8 = 256 options.
ISO-8859-1 est un codage destiné aux langues d'Europe occidentale. Contient des signes diacritiques français, des trémas allemands, etc.
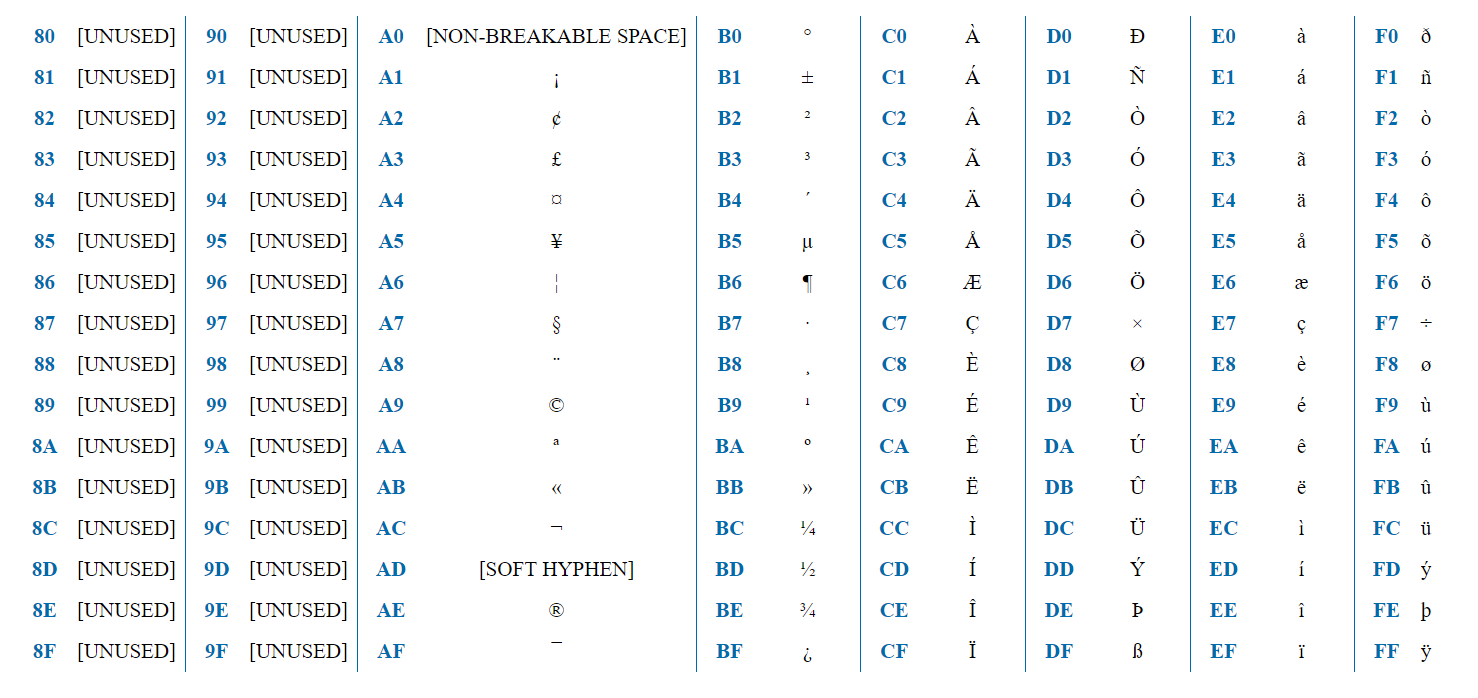
Le codage contient 256 caractères et peut donc être représenté par un octet. La première moitié (128 caractères) est exactement la même que ASCII. Ainsi, si le premier bit = 0, il s'agit d'un caractère ASCII normal. Si 1, il s'agit d'un caractère spécifique à ISO-8859-1.
UTF-8 est l'un des encodages les plus connus avec ASCII. Capable de coder 1.112.064 caractères.
La taille de chaque caractère varie de 1 à 4 octets (
auparavant, jusqu'à 6 octets étaient autorisés).

Le programme travaillant avec ce codage détermine par les premiers bits combien d'octets sont inclus dans le caractère. Si l'octet commence à 0, le caractère est représenté par un octet. 110 - deux octets, 1110 - trois octets, 11110 - 4 octets.
Comme avec ISO-8859-1, les 128 premiers caractères sont entièrement compatibles ASCII. Par conséquent, les textes utilisant uniquement des caractères ASCII seront absolument identiques dans la représentation binaire, que US-ASCII, ISO-8859-1 ou UTF-8 ait été utilisé pour l'encodage.
Utiliser UTF-8 dans le corps d'un message
Avant de passer aux en-têtes, examinons rapidement comment utiliser UTF-8 dans le corps des messages. Pour ce faire, utilisez l'en-tête
"Content-Type" .

Si le "Content-Type" n'est pas spécifié, le navigateur doit alors traiter les messages comme s'ils étaient écrits en ISO-8859-1.
Le navigateur ne doit pas essayer de deviner l'encodage et, de plus, ignorer le "Content-Type". Mais ce qui apparaît réellement dans une situation où le "Content-Type" n'est pas transmis dépend de l'implémentation du navigateur. Par exemple, Firefox fera selon la spécification et lira le message comme s'il était codé en ISO-8859-1. Google Chrome, en revanche, utilisera l'encodage du système d'exploitation, qui pour de nombreux utilisateurs russes est égal à Windows-1251. Dans tous les cas, si le message était en UTF-8, il ne s'affichera pas correctement.

Nous mettons le message UTF-8 dans la valeur d'en-tête
Avec le corps du message, tout est assez simple. Le corps du message suit toujours les en-têtes, il n'y a donc aucun problème technique. Mais qu'en est-il des titres? La spécification
indique explicitement que l'ordre des en-têtes dans le message n'a pas d'importance. C'est-à-dire il n'est pas possible de spécifier l'encodage dans un en-tête via un autre en-tête.
Que se passe-t-il si vous prenez et écrivez simplement la valeur UTF-8 dans la valeur d'en-tête? Nous avons vu qu'une telle astuce avec le corps du message entraînera une simple lecture de la valeur dans ISO-8859-1. Il serait logique de supposer que la même chose se produira avec le titre. Mais ce n'est pas le cas. En fait, dans de nombreux cas, sinon dans la plupart des cas, cette solution fonctionnera. Cela inclut les anciens iPhones, IE11, Firefox, Google Chrome. Le seul navigateur à portée de main lorsque j'ai écrit cet article qui ne voulait pas travailler avec ce titre était Edge.

Ce comportement n'est pas enregistré dans les spécifications. Peut-être que les développeurs de navigateurs ont décidé de leur faciliter la vie et de détecter automatiquement que les en-têtes des messages étaient encodés en UTF-8. En général, ce n'est pas une tâche si difficile. Nous regardons le premier bit: si 0, puis ASCII, si 1 - alors, éventuellement, UTF-8.
Y a-t-il une intersection avec ISO-8859-1 dans ce cas? En fait, presque aucun. Prenez par exemple UTF-8 un caractère de 2 octets (les lettres russes sont représentées par deux octets). Le symbole dans le binaire présenté ressemblera à:
110xxxxx 10xxxxxx . Dans la représentation HEX:
[0xC0-0x6F] [0x80-0xBF] . Dans ISO-8859-1, ces caractères peuvent difficilement encoder quelque chose qui porte une charge sémantique. Par conséquent, le risque que le navigateur déchiffre le message de manière incorrecte est très faible.
Cependant, lorsque vous essayez d'utiliser cette méthode, vous pouvez rencontrer des problèmes techniques: votre serveur Web ou votre infrastructure peut tout simplement ne pas autoriser l'écriture de caractères UTF-8 dans la valeur d'en-tête. Par exemple, Apache Tomcat met 0x3F (point d'interrogation) au lieu de tous les caractères UTF-8. Bien sûr, cette restriction peut être contournée, mais si l'application elle-même se serre la main et ne vous permet pas de faire quelque chose, vous n'avez peut-être pas besoin de le faire.
Mais, que votre framework ou votre serveur vous autorise ou non à écrire des messages UTF-8 dans l'en-tête, je ne recommande pas de le faire. Ce n'est pas une solution documentée qui peut cesser de fonctionner dans les navigateurs à un moment donné.
Translit
Je pense que translit est utilisé - eto bolee horoshee reshenie. Beaucoup de grandes ressources russes populaires ne dédaignent pas d'utiliser la translittération dans les noms de fichiers. Il s'agit d'une solution garantie qui ne cassera pas avec la sortie de nouveaux navigateurs et qui n'a pas besoin d'être testée séparément sur chaque plateforme. Bien sûr, vous devez réfléchir à la façon de convertir tout le spectre des caractères possibles, ce qui peut ne pas être complètement trivial. Par exemple, si l'application est conçue pour un public russe, les lettres tatares ә et ң peuvent apparaître dans le nom du fichier, qui doit être traité d'une manière ou d'une autre, et pas seulement remplacé par "?".
RFC 2047
Comme je l'ai déjà mentionné, le tomkat ne m'a pas permis de mettre UTF-8 dans l'en-tête du message. Cette fonctionnalité de comportement est-elle reflétée dans les documents Java pour les servlets? Oui, réfléchi:
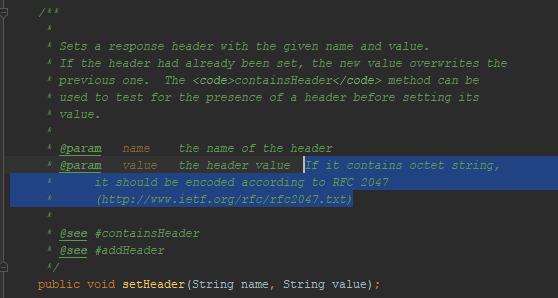
Mentionné
RFC 2047 . J'ai essayé d'encoder des messages en utilisant ce format - le navigateur ne m'a pas compris. Cette méthode de codage ne fonctionne pas dans HTTP. Bien qu'il ait travaillé auparavant. Par exemple, un
ticket pour supprimer la prise en charge de cet encodage dans Firefox.
RFC 6266
Dans le ticket, dont le lien se trouve dans la section précédente,
il y a des références selon lesquelles même après la fin de la prise en charge de la RFC 2047, il existe toujours un moyen de transférer les valeurs UTF-8 au nom des fichiers téléchargés:
RFC 6266 . À mon avis, c'est la décision la plus correcte à ce jour. De nombreuses ressources en ligne populaires l'utilisent.
Chez CUBA Platform, nous utilisons également ce RFC particulier pour générer le «Content-Disposition».
La RFC 6266 est une spécification décrivant l'utilisation de l'en-tête «Content-Disposition». La méthode de codage elle-même est décrite en détail dans une autre spécification,
RFC 8187 .

Le paramètre «filename» contient le nom de fichier en ASCII, «filename *» - dans tout encodage nécessaire. Avec les deux attributs, «nom de fichier» est ignoré dans tous les navigateurs modernes (y compris IE11 et les anciennes versions de Safari). En revanche, la plupart des anciens navigateurs ignorent «nom de fichier *».
Lorsque vous utilisez cette méthode de codage, le paramètre indique d'abord le codage, suivi de la valeur codée. Les caractères visibles de l'encodage ASCII ne nécessitent pas. Les caractères restants sont simplement écrits en représentation hexadécimale, avec un "%" avant chaque octet.
Que faire des autres en-têtes?
Le codage décrit dans RFC 8187 n'est pas universel. Oui, vous pouvez mettre un paramètre avec un préfixe * dans l'en-tête, et cela peut même fonctionner pour certains navigateurs, mais la
spécification prescrit de ne pas le faire.
Dans chaque cas où UTF-8 est pris en charge dans les en-têtes, il y a actuellement une mention explicite de cela dans le RFC correspondant. En plus de Content-Disposition, cet encodage est utilisé, par exemple, dans
la liaison Web et l'
authentification d'accès Digest .
Il convient de noter que les normes dans ce domaine sont en constante évolution. L'utilisation du codage décrit ci-dessus dans HTTP n'a été
proposée qu'en 2010 . L'utilisation de cet encodage dans «Content-Disposition» a été
fixée dans la norme en 2011 . Bien que ces normes ne soient qu'au
stade de «proposition de norme» , elles sont prises en charge partout. L'option selon laquelle nous attendons à l'avenir de nouvelles normes qui permettront un travail plus uniforme avec différents encodages dans les en-têtes n'est pas exclue. Il ne reste donc qu'à suivre l'actualité dans le monde des standards HTTP et leur niveau de support du côté des navigateurs.