La reconnaissance optique de caractères (OCR) est le processus d'obtention de textes imprimés au format numérisé. Si vous lisez un roman classique sur un appareil numérique ou si vous demandez à un médecin de récupérer les anciens dossiers médicaux via le système informatique de l'hôpital, vous avez probablement utilisé l'OCR.
L'OCR rend le contenu précédemment statique modifiable, consultable et partageable. Mais de nombreux documents qui doivent être numérisés contiennent des taches de café, des pages aux coins recourbés et de nombreuses rides qui empêchent la numérisation de certains documents imprimés.
Tout le monde sait depuis longtemps qu'il existe des millions de vieux livres qui sont stockés dans le stockage. L'utilisation de ces livres est interdite en raison de leur délabrement et de leur décrépitude, et donc la numérisation de ces livres est si importante.
Le papier considère la tâche d'effacer le texte du bruit, de reconnaître le texte dans une image et de le convertir au format texte.

Pour la formation, 144 photos ont été utilisées. La taille peut être différente, mais doit de préférence être raisonnable. Les images doivent être au format PNG. Après avoir lu l'image, la binarisation est utilisée - le processus de conversion d'une image couleur en noir et blanc, c'est-à-dire que chaque pixel est normalisé dans une plage de 0 à 255, où 0 est noir, 255 est blanc.
Pour former un réseau convolutionnel, vous avez besoin de plus d'images qu'il n'y en a. Il a été décidé de diviser les images en parties. Étant donné que l'échantillon d'apprentissage est composé d'images de différentes tailles, chaque image a été compressée à 448x448 pixels. Le résultat a été 144 images dans une résolution de 448x448 pixels. Ensuite, ils ont tous été coupés en fenêtres de 112 x 112 pixels sans chevauchement.

Ainsi, sur 144 images initiales, environ 2304 images de l'ensemble d'apprentissage ont été obtenues. Mais cela ne suffisait pas. Plus de formation est nécessaire pour une bonne formation au réseau convolutionnel. En conséquence, la meilleure option était de faire pivoter les images de 90 degrés, puis de 180 et 270 degrés. En conséquence, un réseau de la taille [16, 112, 112, 1] est fourni à l'entrée du réseau. Où 16 est le nombre d'images, 112 est la largeur et la hauteur de chaque image, 1 est les canaux de couleur. Il s'est avéré 9216 exemples pour la formation. Cela suffit pour former un réseau convolutionnel.
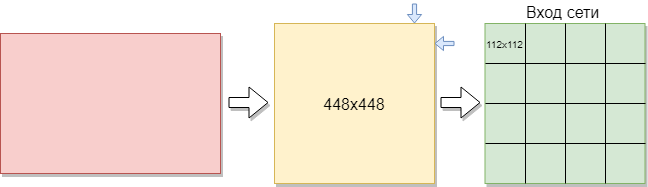
Chaque image a une taille de 112x112 pixels. Si la taille est trop grande, la complexité de calcul augmentera, respectivement, les restrictions sur la vitesse de réponse seront violées, la détermination de la taille dans ce problème est résolue par la méthode de sélection. Si vous sélectionnez une taille trop petite, le réseau ne pourra pas identifier les signes clés. Chaque image a un format noir et blanc, elle est donc divisée en 1 canal. Les images en couleur sont divisées en 3 canaux: rouge, bleu, vert. Puisque nous avons des images en noir et blanc, la taille de chaque image est de 112x122x1 pixels.
Tout d'abord, il est nécessaire de former un réseau neuronal convolutif sur des images préparées et traitées. Pour cette tâche, l'architecture U-Net a été sélectionnée.
Une version réduite de l'architecture a été sélectionnée, composée de seulement deux blocs (la version originale de quatre). Une considération importante était le fait qu'une grande classe d'algorithmes de binarisation bien connus est explicitement exprimée dans une telle architecture ou une architecture similaire (à titre d'exemple, nous pouvons modifier l'algorithme Niblack en remplaçant l'écart-type par l'écart moyen, auquel cas le réseau est construit de manière particulièrement simple).
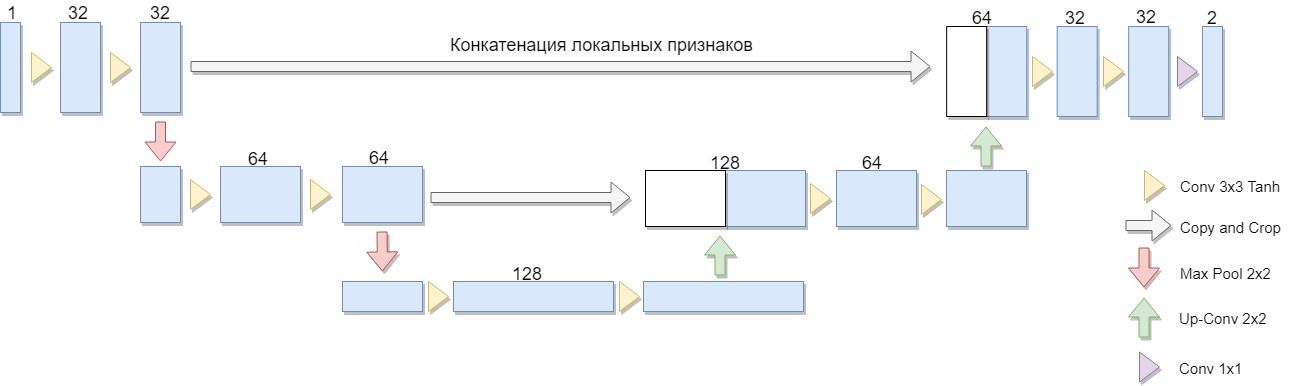
L'avantage de cette architecture est que pour entraîner le réseau, vous pouvez créer une quantité suffisante de données d'apprentissage à partir d'un petit nombre d'images source. De plus, le réseau a un nombre relativement faible de poids en raison de son architecture convolutionnelle. Mais il y a quelques nuances. En particulier, le réseau neuronal artificiel utilisé, à proprement parler, ne résout pas le problème de binarisation: pour chaque pixel de l'image source, il associe un nombre de 0 à 1, qui caractérise le degré d'appartenance de ce pixel à l'une des classes (remplissage significatif ou fond) et qui est nécessaire toujours convertir en réponse binaire finale. [1]
U-Net se compose d'un chemin de compression et de décompression et «avance» entre eux. Le chemin de compression, dans cette architecture, se compose de deux blocs (dans la version originale de quatre). Chaque bloc a deux convolutions avec un filtre 3x3 (en utilisant la fonction d'activation de Tanh après la convolution) et un regroupement avec une taille de filtre 2x2 par étapes de 2. Le nombre de canaux à chaque étape descendante double.
Le chemin de compression se compose également de deux blocs. Chacun d'eux se compose d'un «balayage» avec une taille de filtre de 2x2, divisant par deux le nombre de canaux, la concaténation avec une carte de fonction coupée correspondante du chemin de compression («transfert») et deux convolutions avec un filtre 3x3 (en utilisant la fonction d'activation de Tanh après la convolution). Ensuite, sur la dernière couche, une convolution 1x1 (en utilisant la fonction d'activation Sigmoid) pour obtenir une image plate de sortie. Notez que le rognage de la carte d'entités pendant la concaténation est essentiel en raison de la perte de pixels limites pour chaque convolution. Adam a été choisi comme méthode d'optimisation stochastique.
En général, l'architecture est une séquence de couches de convolution + mise en commun qui réduit la résolution spatiale de l'image, puis l'augmente en la combinant à l'avance avec les données d'image et en passant par les autres couches de convolution. Ainsi, le réseau agit comme une sorte de filtre. [2]
L'échantillon de test était composé d'images similaires, les différences ne concernaient que la texture du bruit et le texte. Des tests de réseau ont eu lieu sur cette image.

À la sortie du réseau neuronal convolutionnel, un tableau de nombres avec une taille de [16,112,112,1] est obtenu. Chaque numéro est un pixel distinct traité par le réseau. Les images ont un format de 112x112 pixels, comme précédemment, elles ont été découpées en morceaux. Elle a besoin de trahir l'apparence d'origine. Nous combinons les images obtenues en une seule partie, par conséquent l'image a un format de 448x448. Ensuite, nous multiplions chaque nombre du tableau par 255 pour obtenir une plage de 0 à 255, où 0 est noir, 255 est blanc. Nous remettons l'image à sa taille d'origine, comme précédemment, elle a été compressée. Le résultat est l'image ci-dessous dans la figure.

Dans cet exemple, on voit que le réseau convolutif a fait face à la plupart du bruit et s'est avéré efficace. Mais il est clairement visible que l'image est devenue plus trouble et que les bruits manqués sont visibles. À l'avenir, cela pourrait affecter la précision de la reconnaissance de texte.
Sur la base de ce fait, il a été décidé d'utiliser un autre réseau de neurones - un perceptron multicouche. Dans le résultat attendu, le réseau devrait rendre le texte dans l'image plus clair et supprimer le bruit manquant du réseau neuronal convolutif.
Une image déjà traitée par le réseau de convolution est envoyée à l'entrée du perceptron multicouche. Dans ce cas, l'échantillon d'apprentissage pour ce réseau sera différent de l'échantillon pour le réseau convolutionnel, car les réseaux traitent l'image différemment. Le réseau convolutionnel est considéré comme le réseau principal et supprime la plupart du bruit dans l'image, tandis que le perceptron multicouche traite ce que la convolution n'a pas réussi à faire.
Voici quelques exemples de l'ensemble de formation pour un perceptron multicouche.

Les données d'image ont été obtenues en traitant l'échantillon d'apprentissage pour le réseau convolutionnel avec un perceptron multicouche. En même temps, le perceptron a été formé sur le même échantillon, mais sur un petit nombre d'exemples et un petit nombre d'époques.
Pour la formation au perceptron, 36 images ont été traitées. Le réseau est formé pixel par pixel, c'est-à-dire qu'un pixel de l'image est envoyé à l'entrée du réseau. À la sortie du réseau, nous obtenons également un neurone de sortie - un pixel, c'est-à-dire la réponse du réseau. Pour augmenter la précision du traitement, 29 neurones d'entrée ont été créés. Et sur l'image obtenue après traitement par le réseau de convolution, 28 filtres sont superposés. Le résultat est 29 images avec différents filtres. Nous envoyons un pixel de chaque 29 images à l'entrée du réseau et un seul pixel est reçu à la sortie du réseau, c'est-à-dire la réponse du réseau.
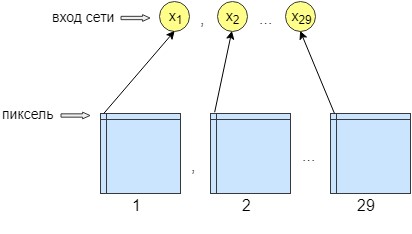
Cela a été fait pour une meilleure formation et un meilleur réseautage. Après cela, le réseau a commencé à augmenter la précision et le contraste de l'image. Il nettoie également les erreurs mineures qui n'ont pas pu effacer le réseau convolutionnel.
En conséquence, le réseau neuronal a 29 neurones d'entrée, un pixel de chaque image. Après les expériences, il a été constaté qu'une seule couche cachée était nécessaire, dans laquelle 500 neurones. Il n'y a qu'un seul moyen de sortir du réseau. Étant donné que la formation a eu lieu pixel par pixel, le réseau a été consulté n * m fois, où n est la largeur de l'image et m est la hauteur, respectivement.

Après avoir traité l'image séquentiellement par deux réseaux de neurones, l'essentiel est de reconnaître le texte. Pour cela, une solution toute faite a été retenue, à savoir la bibliothèque Python Pytesseract. Pytesseract ne fournit pas de vraies liaisons Python. Il s'agit plutôt d'un simple wrapper pour le binaire tesseract. Dans ce cas, tesseract est installé séparément sur l'ordinateur. Pytesseract enregistre l'image dans un fichier temporaire sur le disque, puis appelle le fichier binaire tesseract et écrit le résultat dans un fichier.
Ce wrapper a été développé par Google et est gratuit et gratuit à utiliser. Il peut être utilisé à la fois pour son propre usage et à des fins commerciales. La bibliothèque fonctionne sans connexion Internet, prend en charge de nombreuses langues pour la reconnaissance et impressionne par sa vitesse. Son application peut être trouvée dans diverses applications populaires.
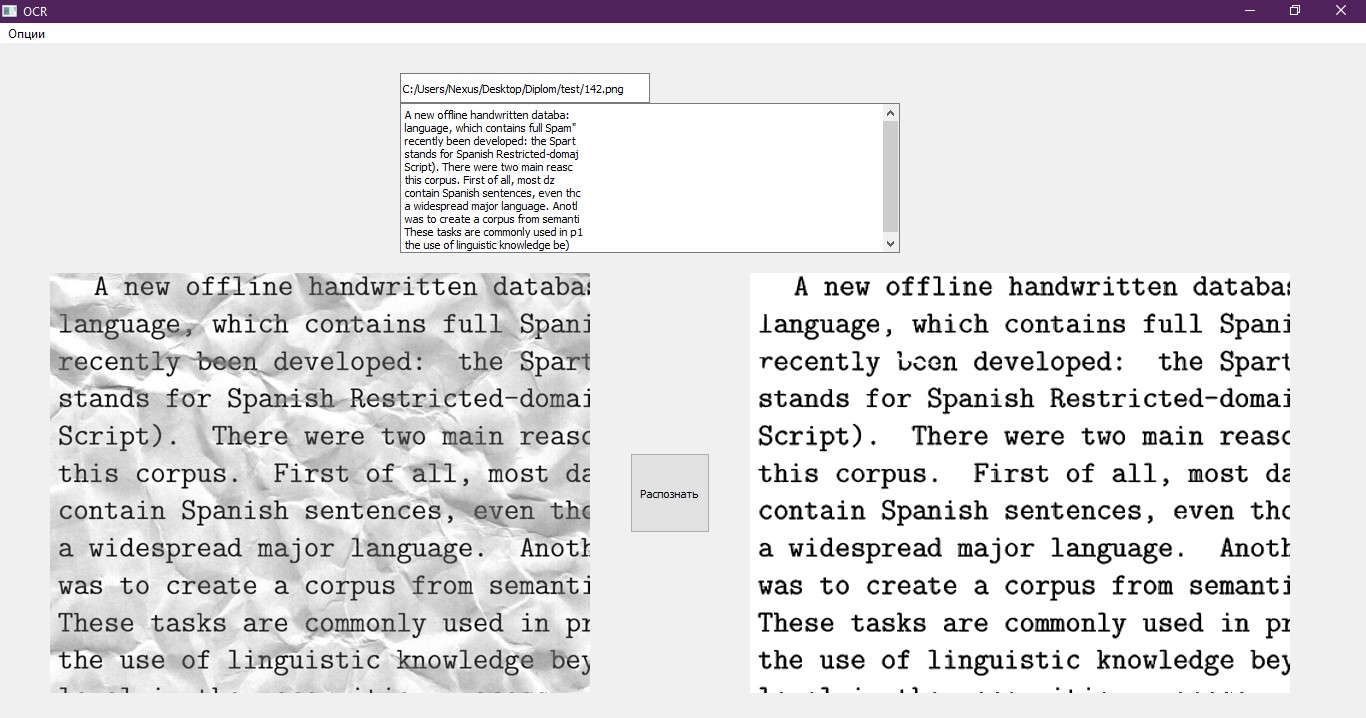
Le dernier élément restant consiste à écrire le texte reconnu dans un fichier dans un format adapté à son traitement. Nous utilisons pour cela un carnet régulier, qui s'ouvre après la fin du programme. De plus, le texte s'affiche sur l'interface de test. Un bon exemple d'interface.
Références:
- L'histoire de la victoire au concours international de reconnaissance de documents de l'équipe SmartEngines [Ressource électronique]. Mode d'accès: https://habr.com/company/smartengines/blog/344550/
- Segmentation d'images à l'aide d'un réseau neuronal: U-Net [ressource électronique]. Mode d'accès: http://robocraft.ru/blog/machinelearning/3671.html
> Dépôt Github