
Bonjour à tous!
Poursuivant l'étude du sujet de
l' apprentissage en profondeur , nous avons voulu une fois vous
expliquer pourquoi les moutons semblent être partout dans les réseaux de neurones . Ce sujet est
abordé dans le 9ème chapitre du livre de François Scholl.
Ainsi, nous sommes allés aux merveilleuses études de Positive Technologies,
présentées à Habré , ainsi qu'à l'excellent travail de deux employés du MIT qui considèrent que «l'apprentissage automatique malveillant» n'est pas seulement un obstacle et un problème, mais aussi un merveilleux outil de diagnostic.
Ensuite - sous la coupe.
Au cours des dernières années, des cas d'ingérence malveillante ont attiré l'attention de la communauté du deep learning. Dans cet article, nous aimerions décrire ce phénomène en termes généraux et discuter de la manière dont il s'intègre dans le contexte plus large de la fiabilité de l'apprentissage automatique.
Interventions malveillantes: un phénomène intrigantPour décrire la portée de notre discussion, nous donnons quelques exemples de telles interférences malveillantes. Nous pensons que la plupart des chercheurs impliqués dans la région de Moscou sont tombés sur des images similaires:
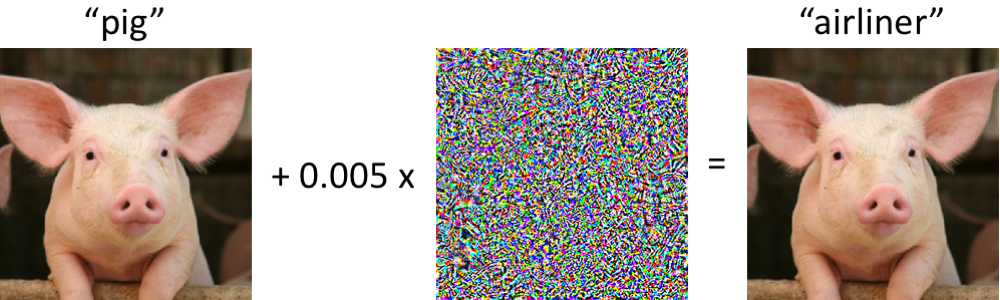
À gauche se trouve un cochon, correctement classé comme porcelet par le réseau neuronal convolutionnel moderne. Une fois que nous apportons des modifications minimes à l'image (tous les pixels sont dans la plage [0, 1], et chacun change de pas plus de 0,005) - et maintenant le réseau renvoie la classe "avion de ligne" avec une grande fiabilité. De telles attaques contre des classificateurs entraînés sont connues depuis au moins 2004 (
lien ), et les premiers travaux sur les interférences malveillantes avec les classificateurs d'images remontent à 2006 (
lien ). Ensuite, ce phénomène a commencé à attirer beaucoup plus d'attention depuis environ 2013, quand il s'est avéré que les réseaux de neurones sont vulnérables aux attaques de ce type (voir
ici et
ici ). Depuis lors, de nombreux chercheurs ont proposé des options pour construire des exemples malveillants, ainsi que des moyens d'augmenter la résistance des classificateurs à de telles perturbations pathologiques.
Cependant, il est important de se rappeler qu'il n'est pas nécessaire de se plonger dans les réseaux de neurones pour observer de tels exemples malveillants.
Quelle est la robustesse des exemples de logiciels malveillants?Peut-être que la situation dans laquelle l'ordinateur confond le porcelet avec l'avion de ligne peut être alarmante au début. Cependant, il convient de noter que le classifieur utilisé dans ce cas (
réseau Inception-v3 ) n'est pas aussi fragile qu'il n'y paraît à première vue. Bien que le réseau se trompe probablement en essayant de classer un porcelet déformé, cela ne se produit que dans le cas de violations spécialement sélectionnées.
Le réseau est beaucoup plus résistant aux perturbations aléatoires de magnitude comparable. Par conséquent, la principale question est de savoir si ce sont les perturbations malveillantes qui provoquent la fragilité des réseaux. Si la malveillance en tant que telle dépend de manière critique du contrôle sur chaque pixel d'entrée, alors lors du classement des images dans des conditions réalistes, de tels échantillons malveillants ne semblent pas être un problème grave.
Des études récentes indiquent le contraire: il est possible d'assurer la stabilité des perturbations aux différents effets de canal dans des scénarios physiques spécifiques. Par exemple, des échantillons malveillants peuvent être imprimés sur une imprimante de bureau ordinaire, de sorte que les images qui y sont photographiées par l’appareil photo d’un smartphone ne
sont toujours pas correctement classées . Vous pouvez également créer des autocollants, à cause desquels les réseaux de neurones classent incorrectement diverses scènes réelles (voir, par exemple,
link1 ,
link2 et
link3 ). Enfin, récemment, les chercheurs ont imprimé une tortue 3D sur une imprimante 3D, que le réseau Inception standard
considère à tort
un fusil à presque n'importe quel angle de vue.
Préparation d'une attaque de classification erronéeComment créer de telles perturbations malveillantes? Il existe de nombreuses approches, mais l'optimisation permet de réduire toutes ces différentes méthodes à une représentation généralisée. Comme vous le savez, la formation des classificateurs est souvent formulée comme la recherche de paramètres de modèle
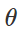
pour minimiser la fonction de perte empirique pour un ensemble d'exemples donné

:
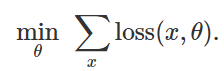
Par conséquent, afin de provoquer une classification erronée pour un modèle fixe
et entrée «inoffensive»
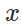
essayer naturellement de trouver une perturbation limitée

de telle sorte que les pertes sur

s'est avéré être maximal:
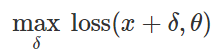
Sur la base de cette formulation, de nombreuses méthodes de création d'entrées malveillantes peuvent être considérées comme divers algorithmes d'optimisation (étapes de gradient individuelles, descente de gradient projetée, etc.) pour divers ensembles de contraintes (petites
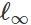
- perturbation normale, petits changements de pixels, etc.). Un certain nombre d'exemples sont donnés dans les articles suivants:
lien1 ,
lien2 ,
lien3 ,
lien4 et
lien5 .
Comme expliqué ci-dessus, de nombreuses méthodes efficaces pour générer des échantillons malveillants fonctionnent avec un classificateur cible fixe. Par conséquent, la question importante est: ces perturbations n'affectent-elles pas uniquement un modèle cible spécifique? Fait intéressant, non. Lors de l'utilisation de nombreuses méthodes de perturbation, les échantillons malveillants résultants sont transférés du classificateur vers le classificateur formé avec un ensemble différent de valeurs aléatoires initiales (graines aléatoires) ou différentes architectures de modèle. De plus, vous pouvez créer des échantillons malveillants qui n'ont qu'un accès limité au modèle cible (parfois dans ce cas, ils parlent d '«attaques de boîte noire»). Voir, par exemple, les cinq articles suivants:
lien1 ,
lien2 ,
lien3 ,
lien4 et
lien5 .
Pas seulement des photosDes échantillons malveillants ne se trouvent pas seulement dans la classification des images. Des phénomènes similaires sont connus dans
la reconnaissance de la parole , dans les
systèmes de questions-réponses , dans l'
apprentissage renforcé et dans la résolution d'autres problèmes. Comme vous le savez déjà, l'étude d'échantillons malveillants se poursuit depuis plus de dix ans:
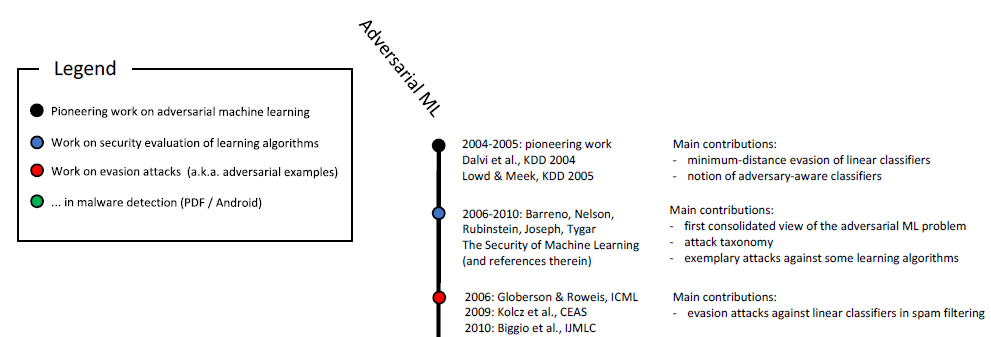
Échelle chronologique de l'apprentissage automatique malveillant (début). La pleine échelle est illustrée à la fig. 6 dans
cette étude .
De plus, les applications liées à la sécurité sont un moyen naturel pour étudier les aspects malveillants de l'apprentissage automatique. Si un attaquant peut tromper le classificateur et transmettre des informations malveillantes (par exemple, du spam ou un virus) comme inoffensifs, un détecteur de spam ou un scanner antivirus basé sur l'apprentissage automatique sera
inefficace . Il convient de souligner que ces considérations ne sont pas purement académiques. Par exemple, l'équipe Google Safebrowsing a publié en 2011 une
étude pluriannuelle sur la façon dont les attaquants ont tenté de contourner leurs systèmes de détection de logiciels malveillants. Consultez également cet
article sur les échantillons malveillants dans le contexte du filtrage du spam dans le courrier GMail.
Pas seulement la sécuritéTous les derniers travaux sur l'étude d'échantillons malveillants sont très clairement soutenus pour garantir la sécurité. C'est un point de vue raisonnable, mais nous pensons que de tels échantillons doivent être considérés dans un contexte plus large.
FiabilitéTout d'abord, les échantillons malveillants posent la question de la fiabilité de l'ensemble du système. Avant de pouvoir raisonnablement discuter des propriétés du classificateur du point de vue de la sécurité, nous devons nous assurer que le mécanisme offre une grande précision de classification. En fin de compte, si nous allons déployer nos modèles formés dans des scénarios du monde réel, il est nécessaire qu'ils démontrent un haut degré de fiabilité lors du changement de la distribution des données sous-jacentes, que ces changements soient dus à des interférences malveillantes ou simplement à des fluctuations naturelles.
Dans ce contexte, les échantillons de logiciels malveillants sont un outil de diagnostic utile pour évaluer la fiabilité des systèmes d'apprentissage automatique. En particulier, l'approche basée sur les logiciels malveillants vous permet d'aller au-delà du protocole d'évaluation standard, où le classificateur formé est exécuté sur un ensemble de tests soigneusement sélectionné (et généralement statique).
Vous pouvez donc arriver à des conclusions étonnantes. Par exemple, il s'avère que l'on peut facilement créer des échantillons malveillants sans même recourir à des méthodes d'optimisation sophistiquées. Dans un
article récent, nous montrons que les classificateurs d'images de pointe sont étonnamment vulnérables aux petites transitions ou virages pathologiques. (Voir
ici et
ici pour d' autres travaux sur ce sujet.)

Par conséquent, même si nous n'attachons pas d'importance, par exemple, aux perturbations de la décharge,, des problèmes de fiabilité dus aux rotations et aux transitions se posent souvent. Dans un sens plus large, il est nécessaire de comprendre les indicateurs de fiabilité de nos classificateurs avant de pouvoir les intégrer dans des systèmes plus importants en tant que composants vraiment fiables.
Le concept de classificateursPour comprendre le fonctionnement d'un classificateur qualifié, vous devez trouver des exemples de ses opérations clairement réussies ou infructueuses. Dans ce cas, des échantillons malveillants illustrent que les réseaux de neurones formés ne correspondent souvent pas à notre compréhension intuitive de ce que signifie «apprendre» un concept spécifique. Ceci est particulièrement important dans l'apprentissage profond, où des algorithmes et des réseaux biologiquement plausibles dont le succès n'est pas inférieur au succès humain sont souvent revendiqués (voir, par exemple,
ici ,
ici ou
ici ). Les échantillons malveillants font clairement douter de cela dans de nombreux contextes:
- Lors de la classification des images, si l'ensemble de pixels est modifié de façon minimale ou si l'image est légèrement pivotée, cela n'empêchera guère une personne de l'attribuer à la bonne catégorie. Néanmoins, ces changements sont complètement coupés par les classificateurs les plus modernes. Si vous placez des objets dans un endroit inhabituel (par exemple, des moutons sur un arbre ), il est également facile de vous assurer que le réseau de neurones interprète la scène de manière très différente de celle d'un être humain.
- Si vous remplacez les mots nécessaires dans un passage de texte, vous pouvez sérieusement confondre le système de questions-réponses , bien que, du point de vue d'une personne, la signification du texte ne changera pas en raison de ces insertions.
- Tout au long de cet article , des exemples de texte soigneusement sélectionnés montrent les limites de Google Translate.
Dans les trois cas, des exemples malveillants aident à tester la force de nos modèles actuels et à souligner dans quelles situations ces modèles agissent complètement différemment de ce qu'une personne ferait.
La sécuritéEnfin, les échantillons malveillants présentent un danger dans les domaines où l'apprentissage automatique atteint déjà une certaine précision sur du matériel «inoffensif». Il y a quelques années à peine, des tâches telles que la classification des images étaient encore très mal exécutées, de sorte que le problème de sécurité dans ce cas semblait secondaire. En fin de compte, le degré de sécurité d'un système d'apprentissage automatique ne devient significatif que lorsque ce système commence à traiter l'entrée «inoffensive» avec une qualité suffisante. Sinon, nous ne pouvons toujours pas faire confiance à ses prévisions.
Maintenant, dans divers domaines, la précision de ces classificateurs s'est considérablement améliorée et leur déploiement dans des situations où les considérations de sécurité sont critiques n'est qu'une question de temps. Si nous voulons aborder cette question de manière responsable, il est important d'étudier leurs propriétés précisément dans le contexte de la sécurité. Mais la question de la sécurité nécessite une approche holistique. La création de certaines fonctionnalités (par exemple, un ensemble de pixels) est beaucoup plus facile que, par exemple, d'autres modalités sensorielles, ou des caractéristiques catégorielles ou des métadonnées. En fin de compte, pour garantir la sécurité, il est préférable de s'appuyer précisément sur les signes qui sont difficiles, voire presque impossibles à changer.
Résultats (est-il trop tôt pour échouer?)Malgré les progrès impressionnants de l'apprentissage automatique que nous avons constatés ces dernières années, il est nécessaire de prendre en compte les limites de capacités des outils dont nous disposons. Il existe une grande variété de problèmes (par exemple, ceux liés à l'honnêteté, à la confidentialité ou aux effets de rétroaction), et la fiabilité est de la plus haute importance. La perception et la cognition humaines résistent à diverses interférences environnementales de fond. Cependant, des échantillons malveillants démontrent que les réseaux de neurones sont encore très loin d'une résilience comparable.
Nous sommes donc convaincus de l'importance d'étudier des exemples malveillants. Leur applicabilité dans l'apprentissage automatique est loin d'être limitée aux problèmes de sécurité, mais peut servir de
norme de diagnostic pour évaluer les modèles formés. L'approche utilisant des échantillons malveillants se compare favorablement aux procédures d'évaluation standard et aux tests statiques dans la mesure où elle identifie des failles potentiellement non évidentes. Si nous voulons comprendre la fiabilité de l'apprentissage automatique moderne, les dernières réalisations sont importantes à étudier du point de vue d'un attaquant (sélection correcte des échantillons malveillants).
Tant que nos classificateurs échouent, même avec des changements minimes entre la formation et la distribution des tests, nous ne pouvons pas atteindre une fiabilité garantie satisfaisante. En fin de compte, nous nous efforçons de créer des modèles qui non seulement seront fiables, mais seront cohérents avec nos idées intuitives sur ce que signifie «étudier» un problème. Ils seront ensuite sûrs, fiables et faciles à déployer dans une grande variété d'environnements.