Bonjour à tous!
Après avoir écrit la
première partie, qui n'était pas très sérieuse et pas particulièrement utile sur le plan pratique, ma conscience m'a avalé légèrement. Et j'ai décidé de terminer ce que j'avais commencé. Autrement dit, choisir la même implémentation d'un réseau de neurones pour fonctionner sur Rasperry Pi Zero W en temps réel (bien sûr, autant que possible sur un tel matériel). Pour la chasser des données de la vie réelle et éclairer les résultats sur Habré.
Attention Il y a un code exploitable et quelques chats de plus sous la coupe que dans la première partie. Dans l'image, lit et morue, respectivement.
Quel réseau choisir?
Je rappelle qu'en raison de la faiblesse du fer framboise, le choix des réalisations du réseau neuronal est restreint. À savoir:
1. SqueezeNet.
2. YOLOv3 Tiny.
3. MobileNet.
4. ShuffleNet.
Dans quelle mesure le choix en faveur de SqueezeNet était-il correct dans la
première partie ? .. L'exécution de chacun des réseaux de neurones mentionnés ci-dessus sur votre matériel est un événement assez long. Par conséquent, tourmenté par de vagues doutes, j'ai décidé de google si quelqu'un avait posé une telle question avant moi. Il s'est avéré qu'il s'est posé des questions et a enquêté en détail. Ceux qui le souhaitent peuvent se référer à la
source . Je me limiterai à une seule image:
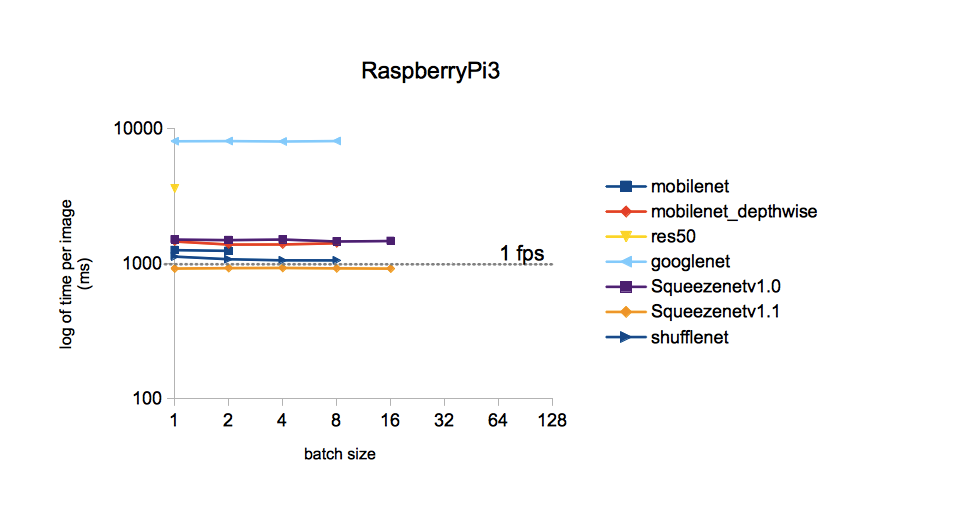
De l'image, il s'ensuit que le temps de traitement d'une image pour différents modèles formés sur l'ensemble de données ImageNet est le moins avec SqueezeNet v.1.1. Nous prendrons cela comme un guide pour l'action. YOLOv3 n'était pas inclus dans la comparaison, mais, pour autant que je m'en souvienne, YOLO est plus cher que MobileNet. C'est-à-dire il devrait également être inférieur en vitesse à SqueezeNet.
Mise en place du réseau sélectionné
Les poids et la topologie de SqueezeNet formés sur l'ensemble de données ImageNet (framework Caffe) peuvent être trouvés sur
GitHub . Au cas où, j'ai téléchargé les deux versions pour pouvoir les comparer plus tard. Pourquoi ImageNet? Cet ensemble de tous disponibles a le nombre maximum de classes (1000 pcs.), Donc les résultats du réseau de neurones promettent d'être assez intéressants.
Cette fois, nous verrons comment le Raspberry Zero gère la reconnaissance d'image par la caméra. Le voici, notre humble travailleur acharné du poste d'aujourd'hui:

J'ai pris le code source du blog Adrian Rosebrock mentionné dans la
première partie comme base du code, à savoir
d'ici . Mais j'ai dû le labourer de manière significative:
1. Remplacez votre modèle par MobileNetSSD sur SqueezeNet.
2. La mise en œuvre de l'Article 1 a conduit à l'augmentation du nombre de classes à 1000. Mais en même temps, la fonction de mise en évidence des objets avec des cadres multicolores (fonction SSD) a, hélas, été supprimée.
3. Supprimer la réception d'arguments via la ligne de commande (pour une raison quelconque, une telle entrée de paramètres me dérange).
4. Supprimez la méthode VideoStream et avec elle la bibliothèque d'imutils chère à Adrian. Initialement, la méthode a été utilisée pour obtenir le flux vidéo de la caméra. Mais avec ma caméra connectée au Raspberry Zero, cela n'a pas fonctionné stupidement, donnant quelque chose comme "Instruction illégale".
5. Ajoutez la fréquence d'images (FPS) à l'image reconnue, réécrivez le calcul FPS.
6. Enregistrez des cadres pour écrire ce message.
Sur la framboise avec Rapbian Stretch OS, Python 3.5.3 et installé via pip3, installez OpenCV 3.4.1, ce qui suit s'est avéré et a commencé:
Code iciimport picamera from picamera.array import PiRGBArray import numpy as np import time from time import sleep import datetime as dt import cv2
Résultats
Le code s'affiche sur l'écran du moniteur connecté au Raspberry, le prochain cadre reconnu sous cette forme. En haut du cadre, seule la classe la plus probable est affichée.

Ainsi, une souris d'ordinateur a été identifiée comme une souris avec une très forte probabilité. Dans le même temps, les images sont mises à jour à une fréquence de 0,34 FPS (c'est-à-dire environ toutes les trois secondes). C'est un peu ennuyeux de tenir l'appareil photo et d'attendre que la prochaine image soit traitée, mais vous pouvez vivre. Soit dit en passant, si vous supprimez le cadre de sauvegarde sur la carte SD, la vitesse de traitement augmentera à 0,37 ... 0,38 FPS. Certes, il existe d'autres moyens de se disperser. Nous attendrons et verrons, en tout cas, nous laisserons cette question pour les prochains messages.
Séparément, je m'excuse pour la balance des blancs. Le fait est que la caméra infrarouge avec le rétro-éclairage activé était connectée à Rapberry, donc la plupart des images ont l'air plutôt étranges. Mais le plus précieux chaque coup du réseau neuronal. De toute évidence, la balance des blancs sur l'ensemble d'entraînement était plus correcte. De plus, j'ai décidé d'insérer uniquement les trames brutes, afin que le lecteur les voie à peu près de la même manière qu'il voit le réseau neuronal.
Tout d'abord, comparons le travail des versions SqueezeNet 1.0 (sur le cadre de gauche) et 1.1 (sur la droite):

On peut voir que la version 1.1 fonctionne deux fois et quart plus vite que 1.0 (0.34 FPS contre 0.15). Le gain de vitesse est palpable. Il ne vaut pas la peine de tirer des conclusions sur la précision de la reconnaissance dans cet exemple, car la précision dépend fortement de la position de la caméra par rapport à l'objet, de l'éclairage, des reflets, des ombres, etc.
Compte tenu de cet avantage de vitesse significatif v1.1 par rapport à v.1.0 à l'avenir, seul SqueezeNet v.1.1 a été utilisé. Pour évaluer les performances du modèle, j'ai pointé la caméra vers divers objets qui
sont venus à la main et j'ai reçu les images suivantes en sortie:

Un clavier est pire qu'une souris. Peut-être que dans le kit d'entraînement, la plupart des claviers étaient blancs.

Un téléphone portable est assez bien défini si vous allumez l'écran. Une cellule avec un écran éteint ne compte pas un réseau neuronal comme une cellule.

Une tasse vide est assez bien définie comme une tasse de café. Jusqu'à présent, tout se passe plutôt bien.

Les ciseaux sont moins bien lotis; ils sont obstinément définis par le filet comme une pince à cheveux. Cependant, entrer dans le pommier si ce n'est la bulle)
Compliquons la tâche
Essayons de mettre quelque chose de délicat sur le réseau neuronal du
porc . Je viens de tomber sur un jouet pour enfant fait maison. Je crois que la plupart des lecteurs le reconnaissent comme un chat jouet. Je me demande à quoi cela sera considéré par notre intelligence artificielle rudimentaire.
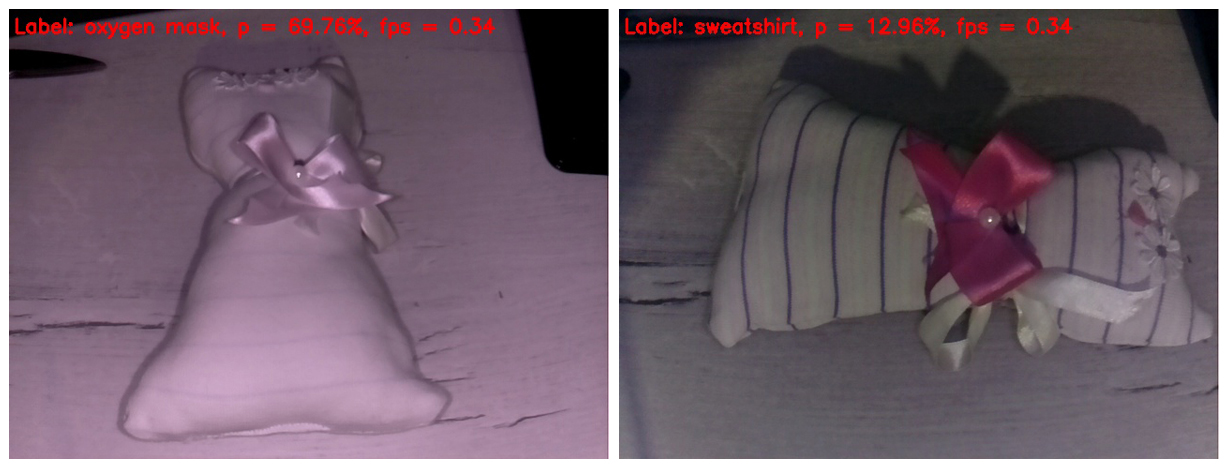
Dans le cadre de gauche, la lumière infrarouge a effacé toutes les bandes du tissu. En conséquence, le jouet a été défini comme un masque à oxygène avec une probabilité assez décente. Pourquoi pas? La forme du jouet ressemble vraiment à un masque à oxygène.
Dans le cadre de droite, j'ai couvert mes doigts avec un reflet infrarouge, de sorte que les rayures sont apparues sur le jouet, et la balance des blancs est devenue plus crédible. En fait, c'est le seul cadre qui semble plus ou moins normal dans ce post. Mais le réseau de neurones a une telle abondance de détails dans l'image confuse. Elle a identifié le jouet comme un sweat-shirt. Je dois dire que cela ne ressemble pas non plus à un "doigt dans le ciel". Frappez sinon dans le "pommier", du moins dans le verger).
Eh bien, nous avons approché en douceur le point culminant de notre action. Le vainqueur hors concours de la bataille, consacré en détail dans le
premier post, entre sur le ring. Et il enlève facilement le cerveau de notre réseau neuronal dès les toutes premières images.

Il est curieux qu'un chat ne change pratiquement pas de position, mais à chaque fois il est déterminé différemment. Et de ce point de vue, il ressemble le plus à une moufette. En deuxième place, la ressemblance avec un hamster. Essayons de changer l'angle.

Oui, si vous photographiez le chat d'en haut, il est déterminé correctement, mais si vous changez un peu la position du corps du chat dans le cadre, pour le réseau neuronal il devient un chien - du husky et du malamute de Sibérie (chien de traîneau esquimau), respectivement.

Et cette sélection est magnifique dans la mesure où un chien de races différentes est défini sur chaque châssis séparé d'un chat. Et les races ne se répètent pas)

Soit dit en passant, il existe des poses dans lesquelles les réseaux de neurones deviennent évidents qu'il s'agit toujours d'un chat, pas d'un chien. Autrement dit, SqueezeNet v.1.1 a quand même réussi à faire ses preuves même sur un tel objet difficile à analyser. Étant donné le succès du réseau de neurones à reconnaître les objets au début du test et à reconnaître un chat comme un chat à la fin, nous déclarons cette fois un solide tirage au combat)
Eh bien, c'est tout. J'invite tout le monde à essayer le code proposé sur leur framboise et tous les objets qui sont venus dans la vue d'objets animés et inanimés. Je serai particulièrement reconnaissant à ceux qui mesurent le FPS sur le Rapberry Pi B +. Je promets d'inclure les résultats dans ce message en référence à la personne qui a envoyé les données. Je crois que cela devrait s'avérer nettement supérieur à 1 FPS!
J'espère que certaines des informations de ce message seront utiles à des fins de divertissement ou d'éducation, et que quelqu'un pourra même proposer de nouvelles idées.
Bonne semaine de travail! Et à bientôt)

UPD1: Sur le Raspberry Pi 3B +, le script ci-dessus fonctionne à une fréquence de 2 avec un petit FPS.
UPD2: Sur RPi 3B + avec Movidius NCS, le script s'exécute à 6 FPS.