Salut% username%!
Plus récemment, la conférence Highload ++ s'est terminée (merci encore à toute l'équipe des organisateurs et
olegbunin personnellement. C'était très cool!).
À la veille de la conférence, Alexey
fisher a proposé de créer un groupe d'initiative de «harceleurs» lors de la conférence. Lors des reportages, nous avons écrit de petites notes que nous avons échangées. Certaines notes se sont avérées assez détaillées et détaillées.
La communauté des réseaux sociaux a évalué positivement ce format, j'ai donc (avec permission) décidé de publier un synopsis du premier rapport. Si ce format est intéressant, je peux préparer quelques articles supplémentaires.

Conduit
Avito a de nombreux services et beaucoup de connexions entre eux. Cela pose des problèmes:
- Beaucoup de référentiels. Il est difficile de changer le code partout à la fois
- Les équipes sont limitées par leur contexte. Chevauchement maximum légèrement et pas tous
- Une fragmentation des données est ajoutée.
Un grand nombre d'éléments d'infrastructure:
- Journalisation
- Demande de trace (Jaeger)
- Agrégation d'erreurs (sentinelle)
- Statuts / Messages / Événements de Kubernetes
- Limite de course / disjoncteur (Hystrix)
- Connectivité de service (Istio)
- Surveillance (Grafana)
- Assemblée (Teamcity)
- La communication
- Suivi des tâches
- La documentation
- ...
Il existe un certain nombre de couches; le rapport n'en décrit qu'une seule (PaaS).
La plateforme comprend 3 parties principales:
- Générateurs contrôlés par cli
- Agrégateur (collecteur), contrôlé par un tableau de bord
- Stockage avec déclencheurs pour certaines actions.
Pipeline de développement de microservices standard
CLI-push -> CI -> Bake -> Deploy -> Test -> Canary -> ProductionCLI-push
Pendant longtemps, j'ai appris à faire les bons développeurs. Cela reste tout de même un point faible.
Automatisé via l'utilitaire cli qui aide à créer une base pour le microservice:
- Crée un service de modèle (les modèles pour un certain nombre de PL sont pris en charge).
- Déploie automatiquement l'infrastructure pour le développement local
- Connecte une base de données (ne nécessite pas de configuration, le développeur ne pense pas à l'accès à une base de données).
- Construction en direct
- Génération de disques d'autotest.
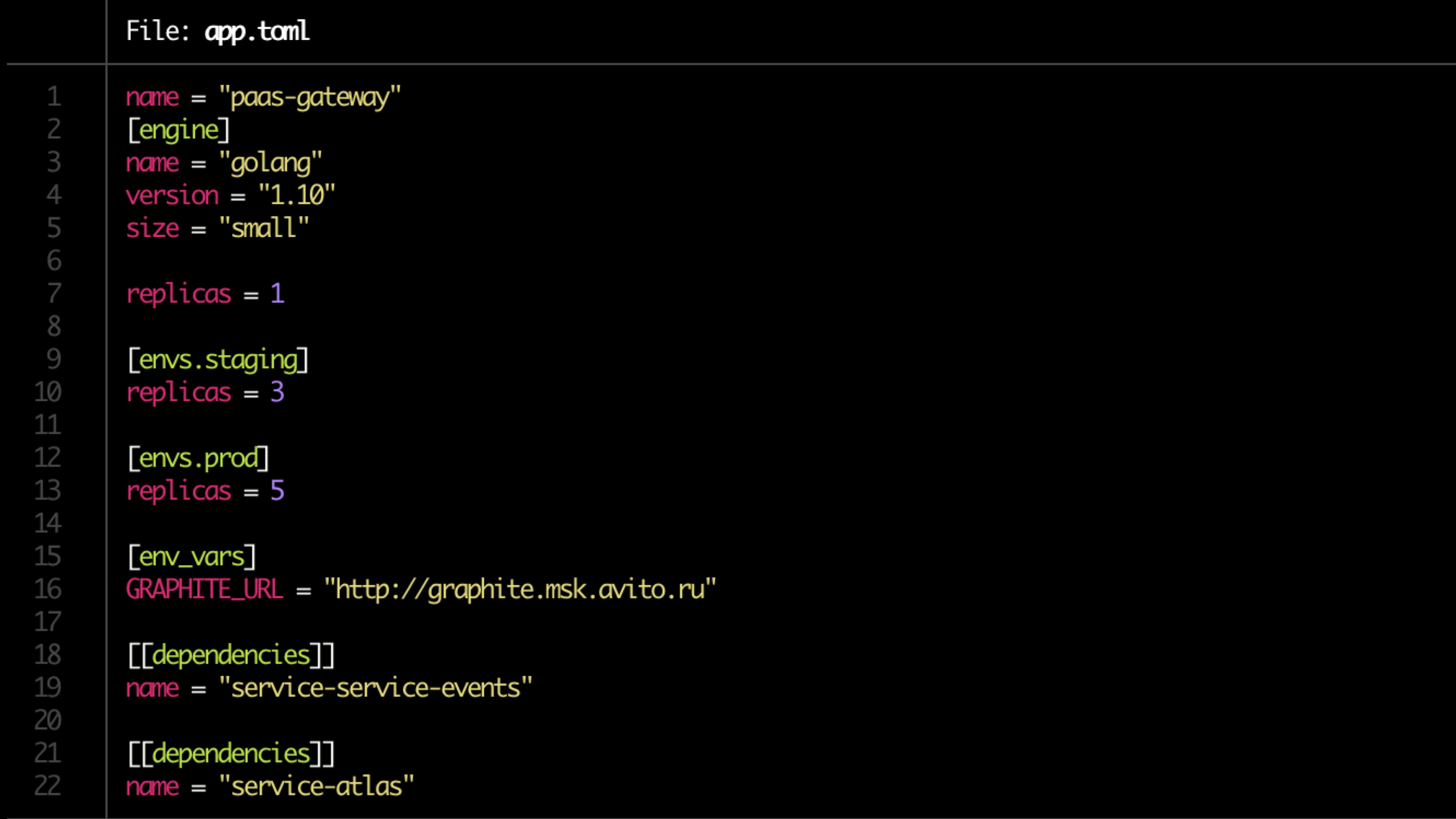
La configuration est décrite dans le fichier toml.
Exemple de fichier:
Validation
Contrôles de validation de base:
- Disponibilité de Dockerfile
- app.toml
- Disponibilité de la documentation
- Dépendances
- Règles d'alerte pour la surveillance (définies par le propriétaire du service)
La documentation
Tout le monde devrait avoir de la documentation, mais presque personne ne l'a
La documentation doit comprendre:
- Description du service (court)
- Lien vers le diagramme d'architecture
- Runbook
- FAQ
- Description de l'API Endpoint
- Étiquettes (liaison au produit, fonctionnalité, division structurelle)
- Le (s) propriétaire (s) du service (il peut y en avoir plusieurs, dans la plupart des cas, il peut être déterminé automatiquement).
La documentation doit être revue.
Préparation du pipeline
- Référentiels de cuisine
- Créer un pipeline dans TeamCity
- Nous fixons les droits
- Nous recherchons le propriétaire (deux, un peu fiable)
- Enregistrer le service dans Atlas (produit interne)
- Vérifiez la migration.
Cuire
- Création de l'application dans l'image docker.
- Génération de diagrammes de barre pour le service lui-même et les ressources associées (DB, cache)
- Des tickets sont créés pour que les administrateurs ouvrent les ports, les restrictions de mémoire et de CPU sont prises en compte.
- Exécutez des tests unitaires. La couverture du code est maintenue. Si en dessous d'un certain niveau, le déploiement se termine. Si la couverture ne progresse pas, les notifications sont envoyées.
La recherche de propriétaire est déterminée par le push (le nombre de push et la quantité de code qu'ils contiennent).
S'il y a des migrations potentiellement dangereuses (alter), le déclencheur est enregistré dans l'Atlas et le service est mis en quarantaine.
La quarantaine est résolue par le push aux propriétaires (en mode manuel?)
Vérification de convention
Nous vérifions:
- Point de terminaison de service
- Conformité des réponses au schéma
- Format du journal
- Définition d'en-têtes (y compris X-Source-ID lors de l'envoi de messages au bus pour suivre la connectivité via le bus)
Les tests
Les tests sont effectués en boucle fermée (par exemple, hoverfly.io) - une charge typique est enregistrée. Ensuite, il est émulé en boucle fermée.
La correspondance de la consommation des ressources est vérifiée (nous regardons séparément les cas extrêmes - trop peu / beaucoup de ressources), coupée par rps.
Les tests de charge montrent également un delta de performances entre les versions.
Tests canaris
Nous commençons le lancement sur un très petit nombre d'utilisateurs (<0,1%).
Charge minimale 5 minutes. Les 2 heures principales. Ensuite, le volume d'utilisateurs augmente si tout va bien.
Nous regardons:
- Mesures du produit (tout d'abord) - il y en a beaucoup (100500)
- Erreurs de sentinelle
- Statuts de réponse,
- Temps des répondants - temps de réponse exact et moyen
- Latence
- Exceptions (traitées et non traitées)
- Plus spécifique au langage métrique (par exemple les travailleurs php-fpm)
Test de compression
Test d'extrusion.
Nous chargeons les utilisateurs réels 1 instance au point de défaillance. Nous regardons son plafond. Ensuite, ajoutez une autre instance et chargez-la. Nous regardons le prochain plafond. Nous regardons la régression. Nous enrichissons ou remplaçons les données des tests de charge dans Atlas.
Mise à l'échelle
Seul le processeur est mauvais, vous devez ajouter des métriques de produit.
Le schéma final:
- CPU + RAM
- Nombre de demandes
- Temps de réponse
- Prévisions historiques
Lors de la mise à l'échelle, n'oubliez pas de regarder les dépendances de service. N'oubliez pas la cascade de mise à l'échelle (niveau +1). Nous regardons les données historiques du service d'initialisation.
En option
- Gestion des déclencheurs - migrations s'il ne reste plus de version en dessous de X
- Le service n'a pas été mis à jour depuis longtemps
- La quarantaine
- Mises à jour sécurisées
Tableau de bord
Nous regardons tout d'en haut sous une forme agrégée et tirons des conclusions.
- Filtrage des services et des étiquettes
- Intégration avec trace, journalisation, surveillance
- Documentation de service à point unique
- Un point d'affichage unique de tous les événements de service
Un exemple:
