Vladimir Ivanov vivanov879 , Sr. L'ingénieur Deep Learning de NVIDIA continue de parler d'apprentissage par renforcement. Cet article se concentrera sur la formation de l'agent pour mener à bien les quêtes et sur la façon dont les réseaux de neurones utilisent des filtres pour reconnaître les images.
Dans un
article précédent, la formation des agents pour les tireurs simples a été discutée.
Vladimir parlera de l'application de l'apprentissage renforcé dans la pratique lors de la
conférence AI le 22 novembre.
La dernière fois, nous avons examiné des exemples de jeux vidéo, où la formation de renforcement permet de résoudre le problème. Curieusement, pour la réussite du jeu du réseau neuronal, seules les informations visuelles étaient nécessaires. Chaque quatrième réseau de neurones d'image analyse la capture d'écran et prend une décision.
À première vue, cela ressemble à de la magie. Une certaine structure complexe, qui est un réseau de neurones, reçoit une image en entrée et émet la bonne solution. Voyons ce qui se passe à l'intérieur: qu'est-ce qui transforme un ensemble de pixels en action?
Avant de passer à l'ordinateur, découvrons ce qu'une personne voit.Lorsqu'une personne regarde une image, son regard s'accroche aux petits détails (visages, figures de personnes, arbres) et à l'image dans son ensemble. Qu'il s'agisse d'un jeu d'enfant dans la ruelle ou d'un match de football, une personne peut comprendre le contenu, l'humeur et le contexte de l'image en fonction de son expérience de vie.

Lorsque nous admirons le travail d'un maître dans une galerie d'art, notre expérience de vie nous dit encore que les personnages sont cachés derrière des couches de peinture. Vous pouvez deviner leurs intentions et leurs mouvements dans l'image.

Dans le cas de la peinture abstraite, l'œil trouve des figures simples dans l'image: cercles, triangles, carrés. Ils sont beaucoup plus faciles à trouver. Parfois, c'est tout ce que l'on peut voir.

Les éléments peuvent être disposés de sorte que l'image prenne une teinte inattendue.

Autrement dit, nous pouvons percevoir l'image dans son ensemble, en faisant abstraction de ses composants spécifiques. Contrairement à nous, un ordinateur n'a pas initialement cette capacité. Nous avons une riche expérience de vie qui nous dit quels articles sont importants et quelles propriétés physiques ils ont. Réfléchissons à la façon de doter la machine d'un outil pour qu'elle puisse étudier les images.
De nombreux heureux propriétaires de téléphones avec des appareils photo de haute qualité avant de publier une photo d'un téléphone sur un réseau social lui imposent divers filtres. En utilisant le filtre, vous pouvez changer l'ambiance de la photo. Vous pouvez mettre en évidence certains objets plus clairement.
De plus, le filtre peut mettre en évidence les bords des objets de la photo.
Étant donné que les filtres ont cette capacité de mettre en évidence différents objets sur une image, donnons à l'ordinateur la possibilité de les récupérer. Qu'est-ce qu'une image numérique? Il s'agit d'une matrice carrée de nombres, à chaque point dont il existe des valeurs d'intensité pour trois canaux de couleur: rouge, vert et bleu. Nous allons maintenant donner au réseau neuronal, par exemple, 32 filtres. Chaque filtre est à son tour superposé à l'image. Le noyau de filtre est appliqué aux pixels voisins.
Initialement, les valeurs fondamentales de chaque filtre sont aléatoires. Mais nous donnerons aux réseaux de neurones la possibilité de les configurer en fonction de la tâche. Après la première couche avec des filtres, nous pouvons en mettre quelques autres. Puisque nous obtenons beaucoup de filtres, nous avons besoin de beaucoup de données pour les configurer. Pour cela, une grande banque d'images balisées convient. Par exemple, jeu de données MSCoco.

Le réseau neuronal ajustera les poids pour résoudre ce problème. Dans notre cas, pour la segmentation d'image, c'est-à-dire la définition de la classe de chaque pixel d'image. Voyons maintenant à quoi ressembleront les images après chaque couche de filtres.
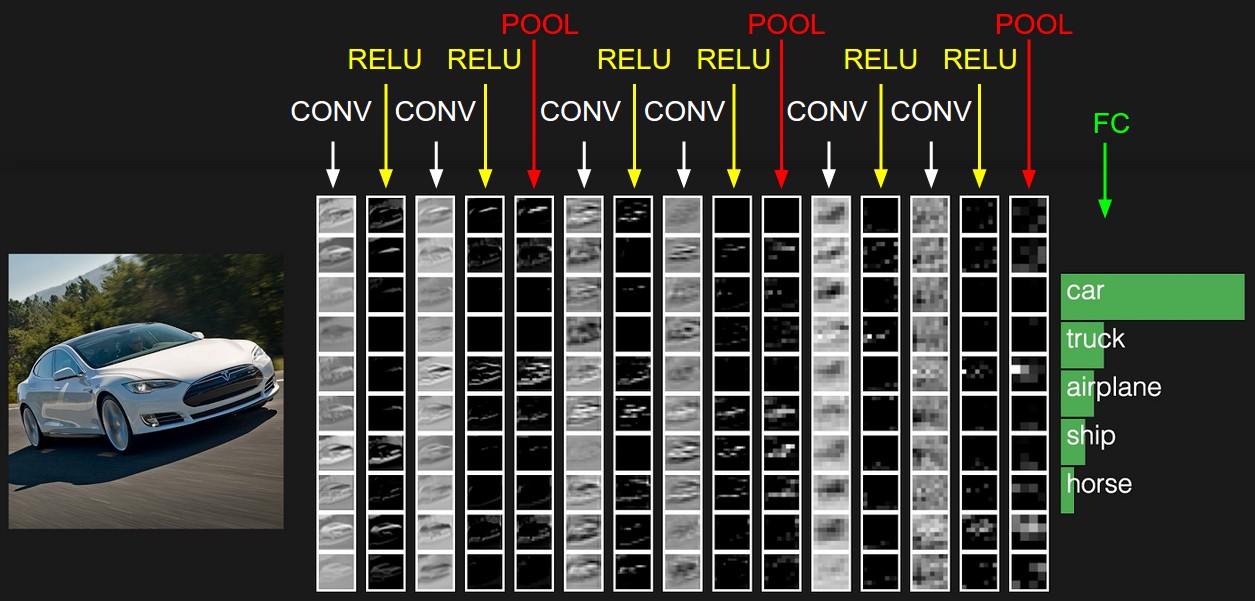
Si vous regardez attentivement, vous remarquerez que les filtres à un degré ou à un autre quittent la voiture et nettoient les environs - la route, les arbres et le ciel.
Revenons à l'agent qui apprend à jouer à des jeux. Par exemple, prenez le jeu de course Mario Kart.
Nous lui avons donné un puissant outil d'analyse d'images - un réseau de neurones. Voyons quels filtres il choisit pour apprendre à rouler. Prenons un espace ouvert pour commencer.
Voyons à quoi ressemble l'image après les 24 premiers films. Les voici sous la forme d'une table 8x3.
Il est tout à fait facultatif que chacune des 24 sorties ait une signification évidente, car les images vont plus loin à l'entrée avec les filtres suivants. Les dépendances peuvent être complètement différentes. Cependant, dans ce cas, vous pouvez trouver une logique dans les sorties. Par exemple, le deuxième filtre de la première ligne met en surbrillance la route en noir. Le premier filtre de la septième ligne duplique sa fonction. Et sur la plupart des autres filtres, les cartes que nous contrôlons sont clairement visibles.
Dans ce jeu, la zone environnante change et un tunnel se rencontre. À quoi un réseau de neurones de course fait-il attention lorsqu'il rencontre une entrée de tunnel?
Les sorties de la première couche de filtres:
Dans la sixième ligne, le premier filtre met en évidence l'entrée du tunnel. Ainsi, lors de la balade, le réseau a appris à les identifier.
Et que se passe-t-il lorsque la machine entre dans le tunnel?
Le résultat des 24 premiers filtres:
Malgré le fait que l'éclairage de la scène a changé, ainsi que l'environnement, le réseau neuronal capture la chose la plus importante - la route et les cartes. Encore une fois, le deuxième filtre de la première ligne, qui était responsable de trouver le chemin en plein air, dans le tunnel conserve ses fonctions. Et de la même manière, le premier filtre de la septième ligne, comme précédemment, trouve le chemin.
Maintenant que nous avons compris ce que le réseau de neurones voit, essayons de l'utiliser pour résoudre des problèmes plus complexes. Avant cela, nous avons considéré des tâches où vous n'avez pratiquement pas besoin de penser à l'avance, mais vous devez résoudre le problème auquel nous sommes confrontés en ce moment. Dans les jeux de tir et les courses, vous devez agir «par réflexe», en répondant rapidement aux changements soudains du jeu. Et pour terminer le jeu de quête? Par exemple, le jeu Montezuma Revenge, dans lequel vous devez trouver les clés et ouvrir les portes verrouillées pour sortir de la pyramide.

La fois précédente, nous avons discuté du fait que l'agent n'apprendra pas à rechercher de nouvelles clés et portes, car ces actions prennent beaucoup de temps de jeu, et donc le signal sous forme de points reçus sera très rare. Si vous utilisez des points pour les ennemis battus en récompense de l'agent, il assommera constamment les crânes roulants et ne cherchera pas de nouveaux mouvements.
Récompensons l'agent pour l'ouverture de nouvelles salles. Nous utiliserons le fait a priori connu qu'il s'agit d'une quête, et toutes les pièces y sont différentes.

Par conséquent, si l'image à l'écran est fondamentalement différente de ce que nous avons vu auparavant, l'agent reçoit une récompense.
Avant cela, nous avons considéré les agents de jeu qui s'appuient uniquement sur des données visuelles lors de la formation. Mais si nous avons accès à d'autres données du jeu, nous les utiliserons également. Prenons par exemple le jeu de Dot. Ici, le réseau reçoit vingt mille numéros à l'entrée, qui décrivent pleinement l'état du jeu. Par exemple, la position des alliés, la santé des tours.

Les joueurs sont divisés en deux équipes, cinq personnes chacune. Une partie dure en moyenne 40 minutes. Chaque joueur sélectionne un héros aux capacités uniques. Et chaque joueur peut acheter des objets qui modifient les paramètres des dégâts, de la vitesse et du champ de vision.
Malgré le fait que le jeu à première vue soit significativement différent de Doom, le processus d'apprentissage reste le même. Sauf pour quelques points. Étant donné que l'horizon de planification dans ce jeu est plus élevé que dans Doom, nous traiterons les 16 dernières images pour prendre des décisions. Et le signal de récompenses que l'agent recevra sera un peu plus compliqué. Il comprend le nombre d'ennemis vaincus, les dégâts infligés, ainsi que l'argent gagné dans le jeu. Afin que les réseaux de neurones jouent ensemble, nous inclurons le bien-être des membres de l'équipe d'agent comme récompense.
En conséquence, l'équipe de bots
bat des équipes de personnes assez fortes, mais perd contre les champions. La raison de la défaite est que les bots ont rarement joué des matchs d'une heure. Et les jeux avec de vraies personnes ont duré plus longtemps que ceux qui se jouaient sur des simulateurs. C'est-à-dire que si un agent se retrouve dans une situation à laquelle il n'a pas été formé, des difficultés commencent à surgir en lui.