Je veux parler de notre expérience dans le développement d'applications basées sur la plate-forme de recherche en texte intégral Apache Solr.
Notre tâche était de développer un système d'analyse de la parole pour les centres de contact. Le système est basé sur deux technologies de base: la reconnaissance vocale et la recherche indexée. Pour la reconnaissance, nous avons utilisé nos moteurs, et pour l'indexation et la recherche, nous avons choisi Solr.
Pourquoi Solr? Nous n'avons pas effectué notre propre recherche comparative sur les moteurs de recherche indexés, mais
nous avons soigneusement examiné les
opinions de nos collègues . Bien sûr, le choix pourrait être fait en faveur d'Elasticsearch ou de Sphinx, mais, apparemment, les stars de notre projet se sont formées en faveur de Solr, nous l'avons «scié». Déjà au cours du projet, nous avons déterminé que les paramètres disponibles dans Solr sont suffisants pour configurer nos tâches.
Caractéristiques de notre projet
Le système a été développé pour l'analyse des appels des clients, qui sont enregistrés dans le centre de contact pour surveiller la qualité du service. Il n'analyse pas le son, mais le texte obtenu grâce à la reconnaissance automatique du dialogue. Les textes de discours reconnus sont fondamentalement différents des textes que nous rencontrons régulièrement sur des sites Internet ou par e-mail. Même avec une précision de reconnaissance de 100%, les textes de la parole spontanée reconnue peuvent sembler n'avoir aucun sens.
Cela est dû à deux facteurs principaux. Premièrement, dans le discours oral, les expressions non verbales et faciales sont très souvent utilisées, qui ne sont pas reconnues dans le texte, mais sont importantes pour comprendre ce qui a été dit. Deuxièmement, dans la parole, des abréviations et des omissions de structures linguistiques sont constamment utilisées, qui peuvent être restaurées à partir du contexte d'une situation de communication. Ce phénomène en linguistique est appelé ellipse.
Pour voir de vos propres yeux le texte du discours reconnu avec toutes ses fonctionnalités, regardez les sous-titres automatiques de la vidéo sur youtube avec le son désactivé. C'est à propos de ce contenu, le matériel va à l'entrée du système d'analyse vocale.
Requêtes compliquées
Bien que Solr prenne en charge les
instructions et les
regroupements conditionnels standard, ces capacités ne sont souvent pas suffisantes pour implémenter tous les scénarios pour les analystes.
Souvent, l'analyste doit créer une requête avec des paramètres non inclus dans l'index Solr. Par exemple, trouvez tous les mots «merci» qui ont été prononcés au cours des 30 dernières secondes de la conversation. Les mots sont indexés par Solr, mais pas de positions de mots temporaires. Nous appelons ces requêtes «complexes» - les requêtes qui incluent les paramètres de l'indice Solr et tout autre paramètre de sélection de données qui ne sont pas inclus dans l'indice Solr.
Comment un analyste forme-t-il des requêtes?
L'analyste n'a aucune idée de la composition de l'indice Solr, il est important pour lui de rechercher et de recouper tous les attributs des phonogrammes d'appels et leurs transcriptions textuelles. Par conséquent, le concept de «requête complexe» pour l'analyste est purement pragmatique: les requêtes dans lesquelles il existe de nombreux paramètres de sélection, ou les requêtes sont organisées dans une hiérarchie.
Décrivant les actions de l'analyste dans le langage de la théorie des ensembles, nous pouvons dire qu'à l'aide de requêtes, l'analyste explore les relations entre les différents sous-ensembles: intersections, différences, ajouts. À l'aide de requêtes hiérarchiques, l'analyste analyse le tableau de données au niveau de détail requis de sa structure.
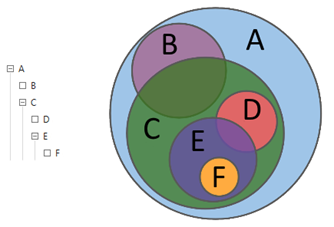 Figure 1. Requêtes hiérarchiques
Figure 1. Requêtes hiérarchiquesLa figure 2 montre un exemple classique d'une requête complexe contenant à la fois des critères de sélection textuels et numériques.
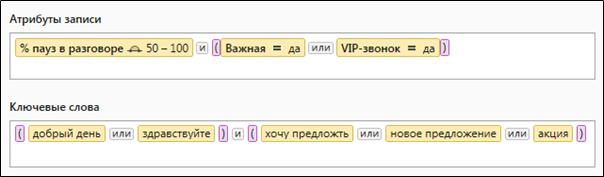 Figure 2. Une requête complexe contenant des paramètres de sélection de données quantitatives et lexicales
Figure 2. Une requête complexe contenant des paramètres de sélection de données quantitatives et lexicalesÀ quoi ressemblent les requêtes pour Solr?
Considérez le mécanisme général pour exécuter une requête dans Solr en utilisant l'exemple de la requête
B de la figure 1. Comme nous pouvons le voir, la requête
B a une requête parent
A , en d'autres termes
B⊆A . Dans l'analyse de la parole, une demande ne peut pas être satisfaite alors qu'au moins un de ses «parents» n'est pas satisfait. Ainsi, la requête
A est exécutée en premier, puis seulement
B. Evidemment,
B doit contenir les conditions de la requête
A.La première chose qui vient à l'esprit est de combiner les conditions des deux requêtes via
AND et de les coller dans la
query :
q=key:A AND key:BCependant, si nous combinons simplement toutes les requêtes consécutives en une seule
query , elle sera grande, elle sera différente pour chaque requête et elle sera calculée dans son intégralité. De plus, les conditions
A affecteront la pertinence des résultats de la requête
B , ce qui ne serait pas souhaitable.
Essayons d'ajouter des requêtes parent en tant que
FilterQuery . Dans ce cas, la requête
A ne sera pas affectée par la non-pertinence et nous pouvons nous attendre à ce qu'elle soit déjà terminée et que ses résultats soient dans le cache. Ainsi, Solr devra calculer uniquement la requête
B , tandis que Solr triera la sélection résultante de la manière dont nous avons besoin:
q=keyword:B &fq=keyword:ASi nous considérons schématiquement le format de la requête à Solr, nous pouvons distinguer deux entités principales:
MainQuery - la requête principale avec un ensemble de paramètres que le document doit satisfaire. Par exemple, une demande de recherche d'opérateurs polis ressemblerait à ceci: text_operator: ” ” .
Cela signifie que le champ text_operator du document de recherche doit contenir la phrase “ ”
FilterQuery - un ensemble de filtres supplémentaires qui limitent la sélection résultante. FilterQuery format MainQuery correspond à MainQuery
La division de la demande en
Main et
Filter vous permet de:
- indiquer explicitement quels paramètres de requête doivent affecter le rang du document dans la sélection et lesquels ne servent qu'à la sélection dans la sélection résultante. La pertinence pour la construction du classement des documents est calculée lorsque la partie de la requête MainQuery est exécutée et lorsque la partie de la requête
FilterQuery est FilterQuery documents qui ne remplissent pas les conditions de la requête - réduire considérablement la charge sur le moteur de recherche, car l'échantillon résultant obtenu après les calculs de
FilterQuery est complètement mis en cache, tandis que les résultats du calcul de MainQuery sont stockés dans le cache uniquement pour les premiers du rang de 50 valeurs
MainQuery et
FiletrQuery ont des effets différents sur les fonctions Solr. Par exemple, pour la
mise en évidence , la fonction responsable de la mise en surbrillance des fragments de document pertinents, seule
MainQuery et les paramètres
FilterQuery pas la
highlighting . C'est logique, car la pertinence est calculée exactement dans la partie de la requête
MainQuery . Voilà à quoi ressemblent les résultats de
highlighting dans une véritable recherche de textes avec les mots «bonjour» et «services».
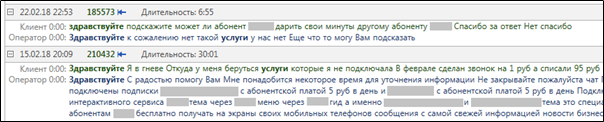 Figure 3. Mise en évidence des mots pertinents après avoir terminé une requête
Figure 3. Mise en évidence des mots pertinents après avoir terminé une requête MainQuery .
Requêtes compliquées dans Solr
Revenons à l'exemple d'un opérateur poli. Dans cet exemple, nous avons déterminé les appels appropriés par la présence de l'expression «bon après-midi» dans le discours de l'opérateur, mais nous n'avons pas indiqué l'intervalle de temps pour rechercher des mots clés par rapport au début ou à la fin de la conversation.
Il semble qu'il y ait tout ce qu'il faut pour cela - la transcription textuelle de la conversation téléphonique contient l'horodatage de chaque mot, ainsi que des informations sur les participants au dialogue auxquels il appartient. Ces données peuvent également être utilisées dans la recherche.
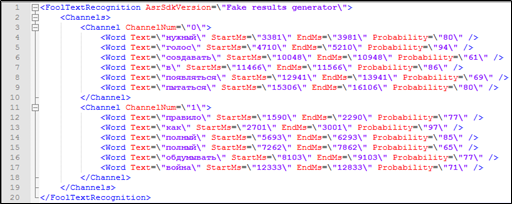 Figure 4. Fragment de décryptage textuel avec balisage non inclus dans l'index Solr: affiliation du locuteur, horodatages.
Figure 4. Fragment de décryptage textuel avec balisage non inclus dans l'index Solr: affiliation du locuteur, horodatages.Mais comment traiter une requête de recherche vers Solr, si des paramètres non indexables sont impliqués dans la requête - l'heure à laquelle le mot est prononcé?
Il existe deux manières évidentes de résoudre ce problème:
- ajouter des paramètres non indexés à l'indice Solr. Dans le même temps, la consommation de mémoire augmentera légèrement, mais l'indice sera considérablement plus lourd
- la sélection des données par des paramètres non indexables doit être effectuée à l'aide de son service, et dans la collecte des documents obtenus après une telle sélection, une recherche à l'aide de l'indice Solr. Dans le même temps, la consommation de mémoire sera nettement supérieure à celle du premier cas, mais les performances seront prévisibles
Nous avons choisi la deuxième option. Pour ce faire, nous avons développé un service qui calcule les collections par requêtes contenant des paramètres logiques et numériques non inclus dans l'index Solr. À la suite du travail de ce service, la partie de la collection qui n'a pas satisfait la demande a été marquée avec une balise spéciale («échappée») puis n'a pas participé au calcul des résultats de la requête.
Imaginez que nous voulons imposer une restriction sur la recherche à la requête
B que nous connaissons déjà, uniquement dans les 30 premières secondes de la boîte de dialogue. À la première étape, nous exécutons
B comme une simple requête, puis «filtrons» les mots qui vont au-delà de la plage sélectionnée afin qu'ils ne tombent pas dans l'index Solr, mais en même temps, nous pouvons restaurer le document d'origine à partir d'eux. Les documents résultants sont placés dans une collection Solr distincte et la recherche de la requête
B y est redémarrée.
Ici, je dois dire que les restrictions sur le début ou la fin de la conversation sont des fleurs, les baies sont des restrictions sur les résultats de la demande des parents. Pensez à l'exécution d'une telle demande.
Imaginez que nos documents se composent de boules avec des chiffres. Essayons de trouver toutes les boules "6" situées dans pas plus de deux boules à droite de "5".
Vous avez déjà réalisé que les numéros des billes sont inclus dans l'indice Solr, et qu'il n'y a pas de distance entre les billes.
|  |
Trouvez tous les documents avec des boules "6" et "5". En tant que MainQuery utilisons une requête pour les boules "5" et une requête pour "6" que nous enverrons à FilterQuery . En conséquence, Solr mettra en évidence les «5» boules dans les résultats de recherche, ce qui simplifiera considérablement notre vie à l'étape suivante. | 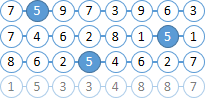 |
| Nous filtrons toutes les balles sauf celles qui sont à la distance souhaitée de «5». Les documents reçus (documents avec les boules souhaitées) seront placés dans une collection séparée. |  |
FilterQuery sur les boules "6" dans la collection résultante, le résultat est les documents que nous FilterQuery . |  |
En pratique, les boules 5 et 6 masquent généralement les requêtes qui occupent plusieurs écrans dans leur représentation textuelle. Je suis heureux que nous ayons mis en œuvre cette recherche pas en vain - les analystes utilisent très souvent des requêtes avec des restrictions du parent.
Conclusion
Qu'avons-nous appris, qu'avons-nous appris et qu'avons-nous réalisé grâce au projet?
Nous savons comment utiliser efficacement Solr pour travailler avec des données de différents types, nous pouvons «apprendre» à Solr à traiter des requêtes avec des paramètres qui ne sont pas inclus dans son index de recherche.
Nous avons développé un système d'analyse vocale industriel fonctionnant sous une charge élevée: des requêtes de recherche complexes d'analystes sont calculées pour des échantillons de jusqu'à cinq millions de documents texte. C'est possible et plus, mais il n'y avait aucun besoin pratique. L'échantillon de travail habituel de l'analyste comprend jusqu'à environ 500 000 SMS d'appels téléphoniques reconnus, et le nombre total d'appels peut atteindre 15 millions.
Pour nos clients dans les centres de contact, le système offre des opportunités sans précédent pour des analyses de nature très différente: analyse des sujets et des raisons des demandes, analyse de la satisfaction client et bien d'autres.
Maintenant, nous connectons de nouvelles sources à nos analyses - des conversations textuelles des clients avec les opérateurs. Nous mettons en œuvre une seule application d'analyse des appels clients sur tous les canaux du centre de contact: téléphone, chat, formulaires sur sites, etc.
Nous nous ferons un plaisir de répondre à vos questions.
Je vous remercie
PS Solr est une chose très difficile et nécessite un bon réglage pour obtenir de bons résultats. Nous raconterons notre expérience dans ce domaine dans les articles suivants.