Nous vous avons déjà parlé de
statistiques intéressantes
sur les textes , fait une
revue d'articles sur l'utilisation des autocodeurs dans l'analyse des textes , et nous avons surpris avec nos nouveaux algorithmes de
recherche pour les emprunts transférables et la
paraphrase . J'ai décidé de poursuivre notre tradition d'entreprise et, premièrement, de commencer l'article par «T», et deuxièmement, de dire:
- comment trouver rapidement un paragraphe de texte parmi des centaines de millions d'articles;
- ce que le document se transforme après le chargement dans le système anti-plagiat, et que faire ensuite;
- comment se forme un rapport que presque personne ne regarde, mais qui en vaut la peine;
- comment indexer pas tous, mais assez.

Comment tout a commencé
En 2005, le recteur de l'une des plus grandes universités de Moscou est venu chez nous à
Forecsys pour résoudre un problème très grave - dans les établissements d'enseignement, les étudiants ont réussi des diplômes et des notes de cours totalement radiés. Nous avons pris plusieurs centaines de travaux d'excellents étudiants et les avons recherchés dans le réseau avec des requêtes simples. Plus de la moitié des
«excellents étudiants» se sont avérés être des escrocs qui ont téléchargé un diplôme sur Internet et n'ont remplacé que la page de titre. Plus de la moitié des excellents étudiants, Karl! Ce qui est arrivé aux étudiants ordinaires est difficile à imaginer. La façon la plus simple de rechercher un emploi consiste à rechercher une requête contenant des mots comportant des "trous noirs". Nous avons pris conscience de l'ampleur de la catastrophe. Il était urgent de résoudre quelque chose. À cette époque, les universités anglophones étrangères utilisaient déjà des solutions de recherche d'emprunt, mais pour une raison quelconque, personne ne vérifiait le travail en russe.
Les acteurs étrangers ne voulaient pas alors adapter leurs solutions à la langue russe. Par conséquent, le 17 mars 2005, le développement du premier système de recherche d'emprunts intérieurs a commencé. Le mot «anti-plagiat» a été inventé un peu plus tard, et le domaine antiplagiat.ru a été enregistré le 28 avril 2005. Nous avions prévu de publier le site d'ici le 1er septembre 2005, mais, comme c'est souvent le cas avec les programmeurs, nous n'avons pas eu le temps. L'anniversaire officiel de notre entreprise est le jour où antiplagiat.ru a reçu les premiers utilisateurs, à savoir le 4 septembre. Vous savez, je suis même heureux de cela, car lors de la fête d'entreprise à l'occasion de l'anniversaire de l'entreprise, tout le monde peut célébrer calmement, et ne pas s'inquiéter du premier jour d'école de leurs enfants.
Mais quelque chose m'a distrait. En 2005, nous avons créé une sorte de moteur de recherche dans lequel, contrairement à Yandex et Google, la requête n'est pas deux ou trois mots, mais un texte entier composé de plusieurs phrases. Par conséquent, il est raisonnable d'utiliser "Anti-plagiat" si vous avez un texte de 1000 caractères (cela représente environ une demi-page).
Lors du développement du service, un prototype a été réalisé sur php (web part) et Microsoft SQL Server (moteur de recherche). Il est immédiatement devenu clair que cela ne décollerait pas et travaillerait lentement sur plusieurs millions de documents. J'ai donc dû couper mon moteur de recherche. Maintenant, le système est écrit en C # et en python, utilise PostgreSQL et MongoDB (en fait, beaucoup plus, mais plus à ce sujet dans le prochain article). Le moteur de recherche est encore complètement développé par nos soins.
Mettez likes dans les commentaires si vous voulez en savoir plus sur l'histoire du développement du système, le changement dans les processus de l'entreprise et le matériel sur lequel Antiplagiarism a travaillé à différents moments de sa vie, et travaille maintenant.
Le mot qui a donné le nom de l'entreprise est devenu un mot familier. Souvent, dans un moteur de recherche, on peut trouver des expressions telles que «vérifier l'anti-plagiat», «augmenter l'anti-plagiat». Quiconque est en quelque sorte lié au domaine de la recherche d'emprunt en Russie et dans les pays voisins essaie d'utiliser le mot «anti-plagiat» pour le mentionner dans les résultats de recherche. On nous interroge souvent sur d'autres «anti-plagiat». Ainsi, «Anti-plagiat» en est un, c'est une marque déposée et le nom de notre entreprise.
Au tout début de la mise en œuvre du service de recherche de prêts, nous avons décidé de travailler avec le texte comme une séquence de caractères. Diverses constructions sémantiques à partir de textes, la recherche de sens, l'analyse de phrases, etc., ont été immédiatement rejetées. La solution que nous avons choisie offre deux avantages considérables: une vitesse de recherche élevée et un volume d'index de recherche relativement faible.
Il y a actuellement trois produits dans notre gamme. Ils se distinguent par leur fonctionnalité, mais contiennent essentiellement le même principe d'emprunt de recherche. Dans cet article, je vais parler du fonctionnement de notre recherche classique d'emprunt - la fonctionnalité qui est devenue la base du service depuis le tout début et n'a toujours pas changé conceptuellement. Le schéma de recherche d'emprunt, comme vous le voyez sur l'image, est simple et direct, comme dessiner un hibou. D'abord, nous obtenons le document de l'utilisateur, puis nous en extrayons le texte. Ensuite, nous recherchons des emprunts dans ce texte, nous obtenons des «révisions» (comme nous appelons le rapport pour un module de recherche) et, enfin, nous collectons les révisions dans un grand rapport, que nous montrons en conséquence à l'utilisateur.
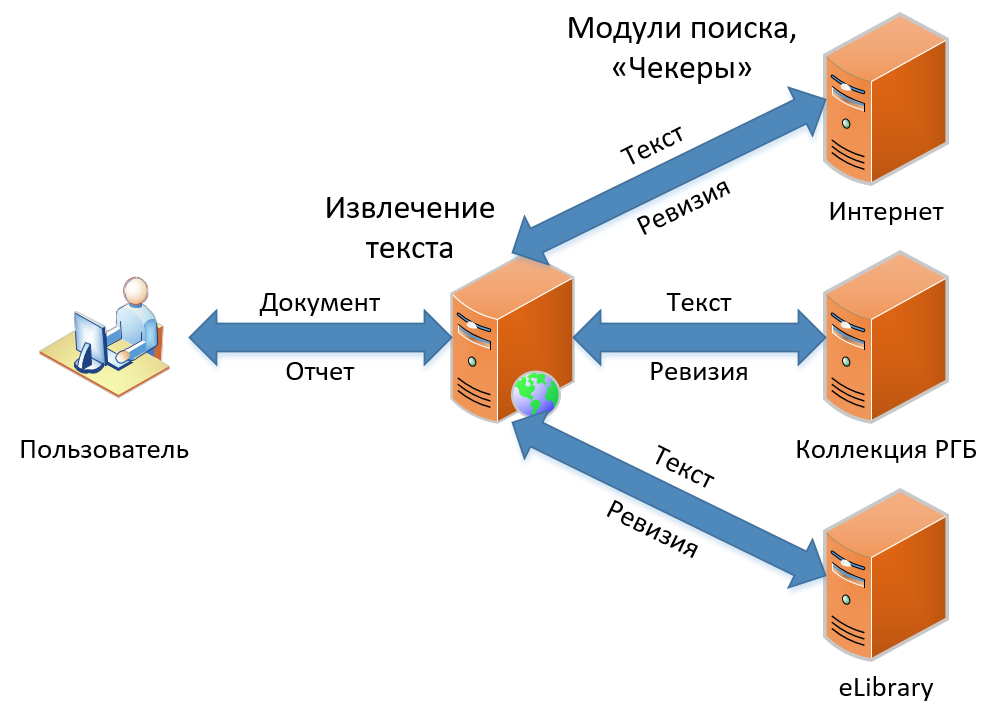
Voyons comment tout cela se passe en détail.
Extraction de texte
Tout d'abord, «Anti-plagiat» est un service de recherche uniquement sur les emprunts de
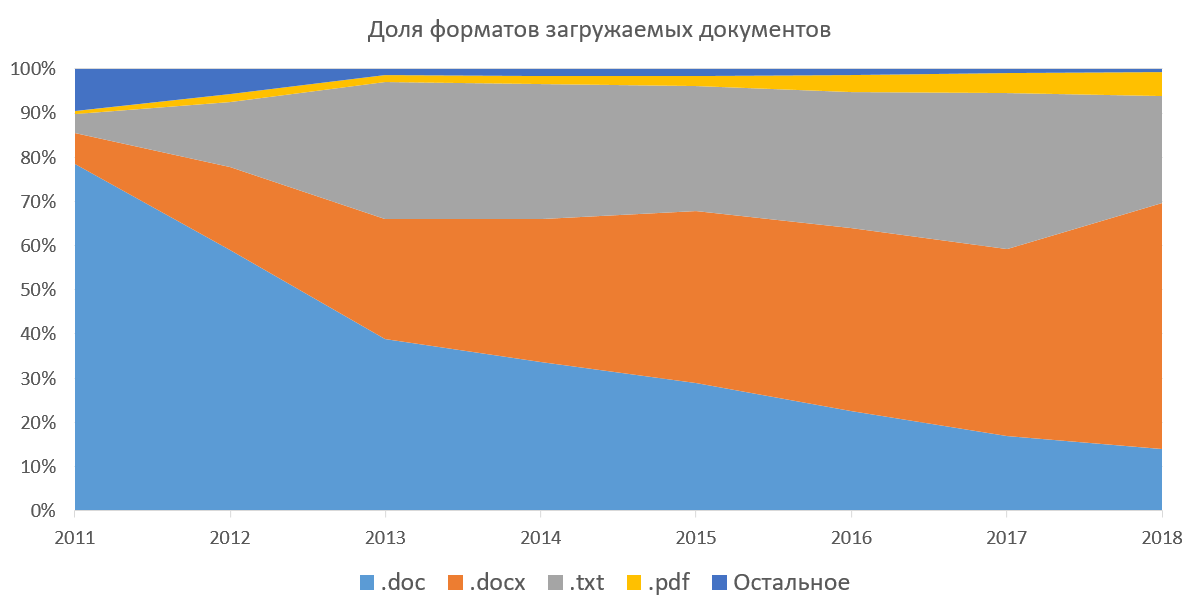
texte , ce qui signifie que nous devons extraire le texte de tous les documents afin de continuer à travailler avec lui. Le système prend en charge la possibilité de télécharger des documents aux formats docx, doc, txt, pdf, rtf, odt, html, pptx et plusieurs autres formats (jamais utilisés). Vous pouvez également télécharger tous ces documents dans des archives (7z, zip, rar). Cette méthode était populaire lorsque nous ne pouvions pas télécharger plusieurs documents à la fois via l'interface Web. Vous trouverez ci-dessous un graphique de la popularité des formats de document téléchargeables dans la partie entreprise de notre système. Il montre comment docx a été supplanté par doc depuis plusieurs années, et la proportion de pdf augmente progressivement. Si vous ne considérez pas txt (extraire du texte car c'est trivial), alors pour nous le plus agréable est le pdf. À l'étranger, le pdf est la norme de facto, il publie des articles, prépare le travail des étudiants. Selon nos statistiques, le pdf gagne progressivement en popularité en Russie et dans les pays de la CEI. Nous-mêmes faisons la promotion de ce format auprès des masses, en recommandant d'y télécharger des documents.
Nous avons limité les formats de téléchargement de documents pour les clients privés au format pdf et txt, et c'est pourquoi nous avons réduit la consommation de ressources et le coût de prise en charge d'un service gratuit. Après tout, vous devez vérifier le texte et ne pas tester le système? Alors, quelle est la différence dans quel format le télécharger?
La prochaine façon la plus simple d'extraire du texte est docx, car, en fait, il s'agit d'une archive zip avec xml à l'intérieur, elle est assez simple à traiter et beaucoup peut être fait à un niveau bas.
La chose la plus difficile pour nous est le doc. Ce format est fermé depuis longtemps, et maintenant il y a un tas de ses implémentations. Le dernier Microsoft Word, qui ne prenait pas en charge .docx (bien que via le pack de compatibilité Microsoft Office), a été publié il y a 20 ans et a été inclus dans Microsoft Office 97. Le format utilise OLE, qui est devenu plus tard COM et ActiveX, tout est binaire, parfois incompatible entre les versions. En général, le terrible rêve d'un programmeur moderne. Heureusement que le format .doc quitte progressivement la scène. Je pense que le moment est venu pour nous de l'aider à prendre sa retraite. Bientôt, nous avertirons volontairement les utilisateurs que ce format est obsolète.
Revenons donc au rapport. Nous avons obtenu le fichier et commencé à extraire le texte. Avec le texte, le système extrait également les positions des mots sur les pages afin qu'à l'avenir il soit possible de montrer à nos utilisateurs le balisage du rapport d'emprunt sur le document lui-même. De plus, au même stade, nous recherchons des solutions de contournement techniques pour l'anti-plagiat.
Dès l'apparition de l '«Anti-plagiat», montrant le pourcentage d'originalité, il y avait des gens qui voulaient passer un chèque d'emprunt avec un minimum d'effort, ainsi que des gens qui offraient un tel service pour de l'argent. Le problème est que le paramètre numérique demande à devenir une estimation. Après tout, c'est tellement simple - au lieu de lire une œuvre en utilisant le système comme outil, ne la lisez pas, mais évaluez-la par le pourcentage d'originalité! C'est ce malheur qui a engendré une telle direction que le réglage des œuvres (un changement dans le texte afin d'augmenter le pourcentage d'originalité de l'œuvre). Pour en savoir plus sur les problèmes liés aux processus universitaires, consultez l'article
"Sur la pratique de la détection des emprunts dans les universités russes" .
Dans les systèmes de recherche étrangers, les problèmes de détection des solutions techniques et de lutte contre celles-ci ne valent pratiquement pas la peine. Le fait est que la «feinte aux oreilles» découverte sera suivie d'une punition très sévère - expulsion et tache indélébile sur la réputation scientifique, incompatible avec une carrière future. Dans notre cas, la situation est ridiculement simple: "Oh, ce système a gâché quelque chose!", "Oh, ce n'est pas moi, c'est lui-même!" L'élève est susceptible d'être envoyé à refaire. Le fait est que la radiation, hélas, n'est pas quelque chose de honteux.
Mais encore une fois distrait. L'OCR est une autre façon d'extraire du texte. Nous imprimons le document sur une imprimante virtuelle, puis le reconnaissons. En savoir plus à ce sujet dans l'article
«La reconnaissance d'images au service de l'anti-plagiat» .
Maintenant, un peu de notre histoire sur l'extraction de textes. Tout d'abord, nous avons extrait des textes à l'aide d'IFilters. Ils sont lents, uniquement sous Windows, et ne renvoient pas d'informations de mise en forme (il n'est pas clair où le texte blanc se trouve sur le fond blanc, alors vous ne pouvez pas marquer les blocs d'emprunt directement dans le document utilisateur). Nous pensions que ces problèmes seraient résolus si nous commencions à utiliser des bibliothèques payantes, mais nous avons également trouvé des limites: comme auparavant sous Windows, ils ne voient pas les formules, parfois ils tombent sur des documents spécialement préparés (différentes bibliothèques sur différentes!). L'idée suivante était d'OCR tous les documents entrants, mais cette approche est très gourmande en ressources (ne traitant que 10 pages par minute sur un cœur), et à certains endroits, le texte n'est pas extrait avec précision.
Nous n'avons pas trouvé de solution miracle, bien que nous pensions à quelques reprises que c'était le bonheur. Cependant, après avoir vécu un peu avec cela, ils ont réalisé que c'était à nouveau une Expérience. L'extraction de texte équilibre sur une ligne fine entre les performances (vous devez extraire le texte de centaines de documents par minute), la fiabilité (vous devez extraire le texte de tout), la fonctionnalité (formatage, solutions de contournement, c'est tout). Maintenant, tout ce qui précède et un peu plus de travail pour nous. Nous expérimentons constamment ce domaine et continuons à rechercher notre bonheur.
Le texte est extrait, les rondes sont trouvées et partiellement éliminées, nous partons à la recherche d'emprunts!
Recherche d'emprunt
L'idée mise en œuvre dans la procédure de recherche a été proposée par Ilya Segalovich et Yuri Zelenkov (vous pouvez lire, par exemple, dans l'article:
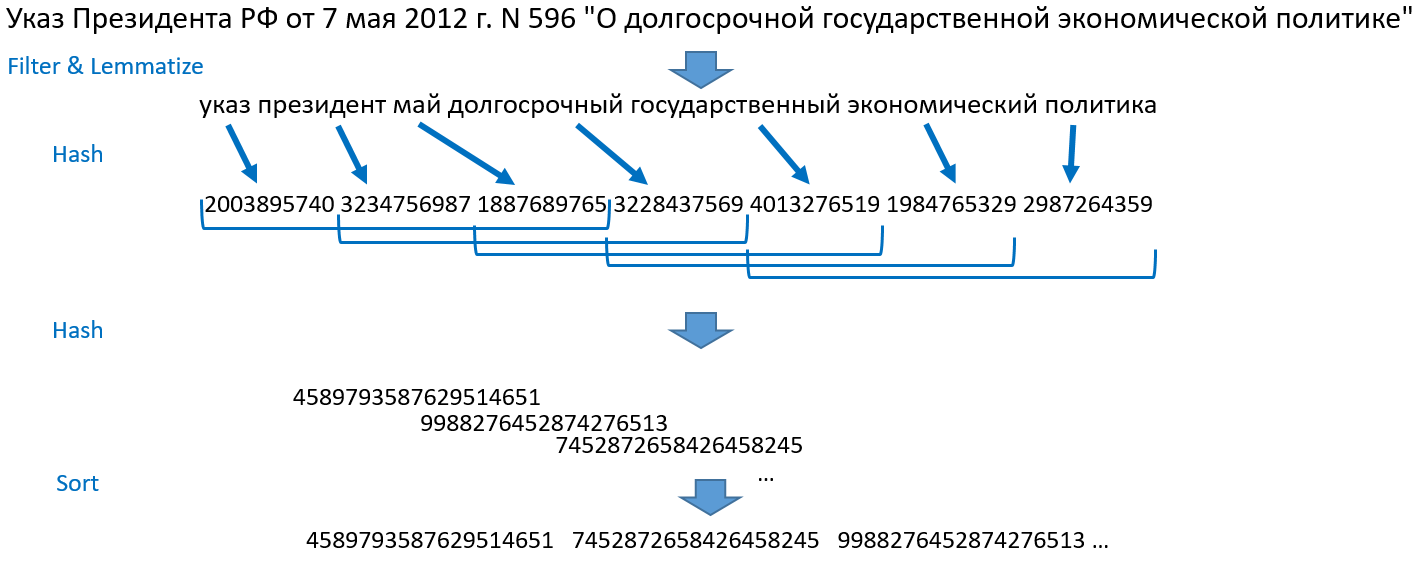
Analyse comparative des méthodes de détermination des doublons flous pour les documents Web ). Je vais vous expliquer comment cela fonctionne pour nous. Prenons, par exemple, la phrase: "Décret du président de la Fédération de Russie du 7 mai 2012 N 596" sur la politique économique à long terme de l'État "".
- Nous décomposons des phrases en mots, nous jetons des chiffres, des signes de ponctuation, des mots vides. Lemmatiser (ramener à la forme normale) tous les mots.
- Nous transformons les mots en entiers par hachage, nous obtenons un tableau de nombres.
- Nous prenons les trois premiers hachages, puis les 2e, 3e, 4e hachage, puis les 3e, 4e, 5e et ainsi de suite jusqu'à la fin du tableau de hachage. C'est du bardeau. Cette méthode a obtenu son nom en raison de ces ensembles superposés en mosaïque. Nous fusionnons chaque tuile en un seul objet et hachons à nouveau.
- Nous trions les nombres résultants, nous obtenons un tableau ordonné d'entiers. C'est la base de la recherche.
Maintenant, pour la recherche, nous avons besoin d'une fonction magique qui, selon une telle liste de hachages, transforme les documents, triés par ordre décroissant du nombre de hachages correspondants, en document source. Cette fonction devrait fonctionner rapidement car nous voulons rechercher dans des milliards de documents. Afin de trouver rapidement un tel ensemble, nous avons besoin d'un index inversé, qui par hachage renvoie une liste de documents dans lesquels se trouve ce hachage. Nous avons mis en place une telle table de hachage géante. Contrairement à nos frères plus âgés, nous stockons cette table sur ssd, pas en mémoire. Nous manquons assez de telles performances. La recherche d'index prend une petite partie de l'ensemble du cycle de traitement des documents. Voyez comment se déroule la recherche:
Étape 1. Recherche d'index
Pour chaque hachage du texte de la requête, nous obtenons une liste des identifiants des documents source dans lesquels il se produit. Ensuite, nous classons la liste des identifiants des documents source en fonction du nombre de hachages rencontrés dans le texte de la requête. Nous obtenons une liste classée des documents candidats pour la source d'emprunt.
Étape 2. Construction de l'audit
Pour une grande demande de texte des candidats, il peut y en avoir environ 10 000. C'est encore beaucoup pour comparer chaque document avec le texte de la demande. Nous agissons avec avidité, mais de manière décisive. Nous prenons le premier document source, faisons une comparaison avec le texte de la demande et excluons de tous les autres candidats les hachages qui figuraient déjà dans ce premier document. Nous supprimons de la liste des candidats ceux qui n'ont aucun hachage, trions à nouveau les candidats en fonction du nouveau nombre de hachages. Nous prenons le premier document de la nouvelle liste, le comparons avec le texte source, supprimons les hachages, supprimons les candidats zéro, trions à nouveau les candidats. Nous le faisons 10 à 20 fois, généralement cela suffit pour que la liste soit épuisée ou seuls les documents qui correspondent à plusieurs hachages y restent.
L'utilisation de hachages de mots nous permet d'effectuer des opérations de comparaison plus rapidement, d'économiser de la mémoire et de stocker non pas les textes des documents sources, mais leurs conversions numériques (TextSpirit, comme nous les appelons affectueusement) obtenues lors de l'indexation, violant ainsi le droit d'auteur. La sélection de fragments d'emprunt spécifiques se fait à l'aide de l'arborescence des suffixes.
À la suite de la vérification avec un module de recherche, nous obtenons une révision, qui contient une liste de sources, leurs métadonnées et les coordonnées des unités d'emprunt par rapport au texte de la demande.
Assemblage du rapport
Soit dit en passant, que se passerait-il si l'un des 10 à 15 modules ne répondait pas à temps? Nous recherchons les collections de RSL, eLibrary et Guarantor. Ces modules de recherche sont situés sur le territoire d'organisations tierces et ne peuvent pas être transférés sur notre site pour des raisons de droit d'auteur. Le point de défaillance ici peut toujours être un canal de communication et divers cas de force majeure dans des centres de données que nous ne contrôlons pas. D'une part, l'emprunt peut être trouvé dans n'importe quel module de recherche, d'autre part, si l'un des composants du système n'est pas disponible, vous pouvez dégrader la qualité de la recherche, mais donner la plupart du résultat, tout en avertissant l'utilisateur que le résultat de certains modules de recherche n'est pas encore prêt. Quelle option appliqueriez-vous? Nous appliquons ces deux options au besoin.

Enfin, toutes les révisions sont reçues, nous commençons l'assemblage du rapport. Il utilise une approche similaire à la préparation d'une révision. Cela ne semble rien de compliqué, mais il y a aussi des tâches intéressantes. Nous avons deux types d'emprunts. Les «citations» sont indiquées en vert - citations correctes (selon GOST) du module «Citation», expressions du type «ce qui était requis pour prouver» du module «Expressions communes», documents réglementaires des bases de données du garant et Lexpro. Tous les autres emprunts sont marqués en orange. Les verts ont priorité sur les oranges, sauf s'ils entrent dans le bloc orange entier.
En conséquence, le rapport peut être comparé au texte imprimé sur du papier posé sur la table, sur lequel des bandes multicolores (blocs d'emprunts et devis) sont gribouillées, se chevauchant de manière fantaisiste. Ce que nous voyons ci-dessus est un rapport. Nous avons deux indicateurs pour chaque source:
La part dans le rapport est le rapport du volume des emprunts, pris en compte à partir de cette source, au volume total du document. Si le même texte a été trouvé dans plusieurs sources, il n'est pris en compte que dans l'une d'entre elles. Lorsque vous modifiez la configuration du rapport (activer ou désactiver les sources), cet indicateur de la source peut changer. Au total, il donne le pourcentage d'emprunts et de citations (selon la couleur de la source).
Partager dans le texte - le rapport entre le volume emprunté à la source donnée du texte et le volume total du document. Cela n'a aucun sens de résumer les parts dans le texte par sources, il en résultera facilement 146% ou même plus. Cet indicateur ne change pas lorsque le rapport change.
Naturellement, le rapport peut être édité. Il s'agit d'une fonction spéciale pour l'expert qui vérifie le travail pour désactiver l'emprunt des propres travaux de l'auteur (il peut sembler que ce fragment ne se trouve pas seulement dans le propre travail de l'auteur, mais aussi ailleurs) et des blocs d'emprunt séparés, changez le type de source de emprunter pour la citation. Suite à l'édition du rapport, l'expert reçoit la valeur réelle de l'emprunt. Tout travail de vérification doit être lu. Il est pratique de le faire en examinant la forme originale du document, dans laquelle les blocs d'emprunt sont marqués, et immédiatement, au fur et à mesure que vous lisez, modifiez le rapport. Malheureusement, ce n'est pas une action logique de tous, beaucoup sont satisfaits du pourcentage d'originalité, sans même regarder le rapport.
Revenons un peu en arrière et découvrons ce qui entre dans l'index du module de recherche Internet créé par Anti-Plagiat.
Indexation Internet
L'anti-plagiat est principalement axé sur le travail étudiant, les publications scientifiques, les travaux de qualification finale, les dissertations, etc. Nous indexons Internet de manière directionnelle - nous recherchons de grands groupes de textes scientifiques, résumés, articles, dissertations, revues scientifiques, etc. L'indexation se produit comme ceci:
- Notre robot vient, se présente et, guidé par robots.txt (nous avons un bon robot), télécharge des documents avec une charge raisonnable sur chaque hôte (des centaines de sites fonctionnent en même temps, donc nous pouvons attendre un certain temps entre les chargements de page);
- Le robot passe le document et ses métadonnées à la file d'attente de traitement, le texte est extrait du document;
- Le texte est analysé pour la «qualité» - comme vous vous en souvenez de l'article sur la décharge, nous pouvons déterminer le genre du document, ajouter des heuristiques simples au volume ici et comprendre si un texte approprié nous est parvenu ou des déchets;
- Le texte qualitatif va plus loin et se transforme en hachage. Les hachages et les métadonnées sont envoyés à l'index Internet principal;
- Nous comparons le texte reçu avec les textes précédemment indexés par nos soins. Un débutant n'est ajouté que s'il est vraiment nouveau , c'est-à-dire 90% - . , url .
Ainsi, nous indexons des textes de haute qualité, et tous les textes indexés sont sensiblement différents pour nous. La croissance du volume indexé sur Internet est illustrée dans la figure ci-dessous. Maintenant, en moyenne, nous ajoutons à l'indice 15-20 millions de documents par mois.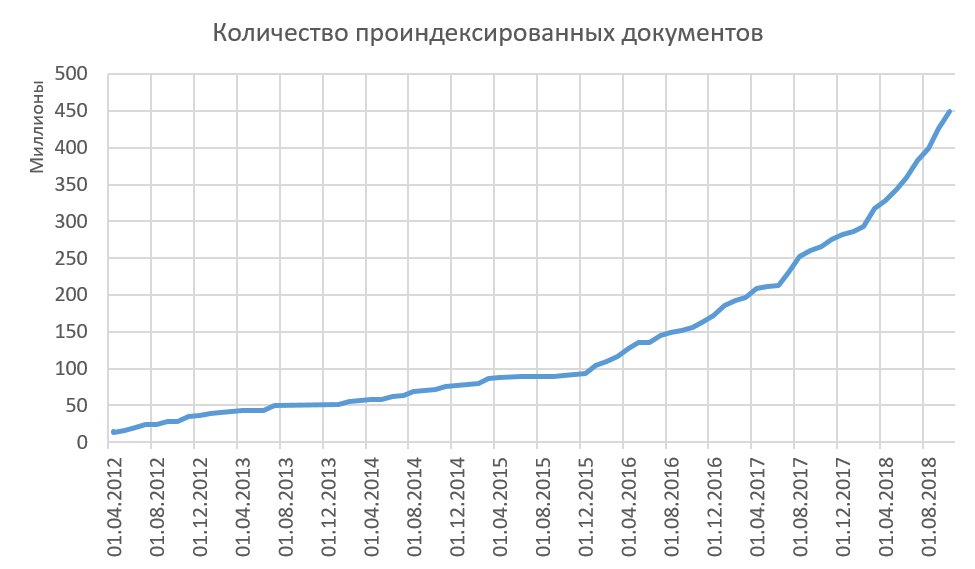 Vous avez remarqué que la procédure de suppression de l'index n'est décrite nulle part? Et elle ne l'est pas! Nous ne supprimons fondamentalement pas les documents de l'index. Nous pensons que si nous pouvions voir quelque chose sur Internet, alors d'autres personnes pourraient voir ce texte et l'utiliser d'une manière ou d'une autre. À cet égard, il existe une statistique intéressante de ce qui était autrefois sur Internet et qui n'est plus là. Oui, imaginez que l'expression «une fois sur Internet y restera pour toujours» n'est pas vraie! Quelque chose disparaît à jamais d'Internet. Souhaitez-vous en savoir plus sur nos statistiques à ce sujet?
Vous avez remarqué que la procédure de suppression de l'index n'est décrite nulle part? Et elle ne l'est pas! Nous ne supprimons fondamentalement pas les documents de l'index. Nous pensons que si nous pouvions voir quelque chose sur Internet, alors d'autres personnes pourraient voir ce texte et l'utiliser d'une manière ou d'une autre. À cet égard, il existe une statistique intéressante de ce qui était autrefois sur Internet et qui n'est plus là. Oui, imaginez que l'expression «une fois sur Internet y restera pour toujours» n'est pas vraie! Quelque chose disparaît à jamais d'Internet. Souhaitez-vous en savoir plus sur nos statistiques à ce sujet?Conclusion
Il est étonnant de constater que les solutions techniques adoptées il y a plus de 10 ans restent pertinentes. Nous nous préparons maintenant à publier la version 4 de l'index, il est plus rapide, plus avancé technologiquement et meilleur, cependant, il est basé sur toutes les mêmes solutions. De nouvelles directions de recherche sont apparues - emprunts transférables, paraphrase, mais notre index y est également utilisé, effectuant même une petite mais importante partie du travail.Chers lecteurs, que voudriez-vous savoir encore sur notre service?