
Au cœur des moteurs de recherche Meltwater et
Fairhair.ai se trouve Elasticsearch, une collection de clusters avec des milliards d'articles dans les médias et les réseaux sociaux.
Les fragments d'index dans les clusters varient considérablement dans la structure d'accès, la charge de travail et la taille, ce qui pose des problèmes très intéressants.
Dans cet article, nous décrirons comment nous avons utilisé la programmation linéaire (optimisation linéaire) pour répartir la charge de travail de recherche et d'indexation aussi uniformément que possible sur tous les nœuds des clusters. Cette solution réduit la probabilité qu'un nœud devienne un goulot d'étranglement dans le système. En conséquence, nous avons augmenté la vitesse de recherche et économisé sur l'infrastructure.
Contexte
Les moteurs de recherche de Fairhair.ai contiennent environ 40 milliards de publications provenant des médias sociaux et des éditoriaux, traitant quotidiennement des millions de requêtes. La plate-forme fournit aux clients des résultats de recherche, des graphiques, des analyses et des exportations de données pour une analyse plus avancée.
Ces ensembles de données massifs résident dans plusieurs clusters Elasticsearch à 750 nœuds avec des milliers d'index dans plus de 50 000 fragments.
Pour plus d'informations sur notre cluster, consultez les articles précédents sur
son architecture et l'
équilibreur de charge d'apprentissage automatique .
Répartition inégale de la charge de travail
Nos données et les requêtes des utilisateurs sont généralement liées à la date. La plupart des demandes tombent dans une certaine période de temps, par exemple, la semaine dernière, le mois dernier, le dernier trimestre ou une plage arbitraire. Pour simplifier l'indexation et les requêtes, nous utilisons l'
indexation temporelle , similaire à
la pile ELK .
Cette architecture d'index présente plusieurs avantages. Par exemple, vous pouvez effectuer une indexation de masse efficace, ainsi que supprimer des index entiers lorsque les données sont obsolètes. Cela signifie également que la charge de travail pour un index donné varie considérablement au fil du temps.
De manière exponentielle, davantage de requêtes sont envoyées aux derniers index, par rapport aux anciens.
 Fig. 1. Schéma d'accès aux indices de temps. L'axe vertical représente le nombre de requêtes terminées, l'axe horizontal représente l'âge de l'index. Les plateaux hebdomadaires, mensuels et annuels sont clairement visibles, suivis d'une longue queue de charge de travail plus faible sur les indices plus anciens
Fig. 1. Schéma d'accès aux indices de temps. L'axe vertical représente le nombre de requêtes terminées, l'axe horizontal représente l'âge de l'index. Les plateaux hebdomadaires, mensuels et annuels sont clairement visibles, suivis d'une longue queue de charge de travail plus faible sur les indices plus anciensLes motifs de la fig. 1 étaient assez prévisibles, car nos clients sont plus intéressés par de nouvelles informations et comparent régulièrement le mois en cours avec le passé et / ou cette année avec l'année écoulée. Le problème est qu'Elasticsearch ne connaît pas ce modèle et ne s'optimise pas automatiquement pour la charge de travail observée!
L'algorithme d'allocation de fragments Elasticsearch intégré ne prend en compte que deux facteurs:
- Le nombre de fragments sur chaque nœud. L'algorithme essaie d'équilibrer uniformément le nombre de fragments par nœud dans le cluster.
- Étiquette l'espace disque libre. Elasticsearch prend en compte l'espace disque disponible sur un nœud avant de décider d'allouer de nouvelles partitions à ce nœud ou de déplacer des segments de ce nœud vers d'autres. Avec 80% du disque utilisé, il est interdit de placer de nouveaux fragments sur un nœud, 90% du système commencera à transférer activement les fragments de ce nœud.
L'hypothèse fondamentale de l'algorithme est que chaque segment du cluster reçoit approximativement la même quantité de charge de travail et que tout le monde a la même taille. Dans notre cas, c'est très loin de la vérité.
L'équilibrage de charge standard conduit rapidement à des points chauds dans le cluster. Ils apparaissent et disparaissent de façon aléatoire, à mesure que la charge de travail évolue avec le temps.
Un point chaud est essentiellement un hôte fonctionnant près de sa limite d'une ou plusieurs ressources système, comme un processeur, des E / S de disque ou une bande passante réseau. Lorsque cela se produit, le nœud met d'abord les demandes en file d'attente pendant un certain temps, ce qui augmente le temps de réponse à la demande. Mais si la surcharge dure longtemps, les demandes sont finalement rejetées et les utilisateurs obtiennent des erreurs.
Une autre conséquence courante de la congestion est la pression instable des déchets JVM due aux requêtes et aux opérations d'indexation, ce qui conduit au phénomène de «l'enfer effrayant» du ramasse-miettes JVM. Dans une telle situation, la machine virtuelle Java ne peut pas obtenir la mémoire assez rapidement et tombe en panne de mémoire, ou se retrouve bloquée dans un cycle de collecte de déchets sans fin, se fige et cesse de répondre aux requêtes et aux pings du cluster.
Le problème a empiré lorsque nous avons
refactorisé notre architecture sous AWS . Auparavant, nous étions «sauvés» par le fait que nous avions exécuté jusqu'à quatre nœuds Elasticsearch sur nos propres serveurs puissants (24 cœurs) dans notre centre de données. Cela masquait l'influence de la distribution asymétrique des éclats: la charge était largement lissée par un nombre relativement important de noyaux sur la machine.
Après refactorisation, nous n'avons placé qu'un seul nœud à la fois sur des machines moins puissantes (8 cœurs) - et les premiers tests ont immédiatement révélé de gros problèmes avec les «points chauds».
Elasticsearch attribue des fragments dans un ordre aléatoire, et avec plus de 500 nœuds dans un cluster, la probabilité de trop de fragments "chauds" sur un seul nœud a considérablement augmenté - et ces nœuds ont rapidement débordé.
Pour les utilisateurs, cela signifierait une sérieuse détérioration du travail, car les nœuds encombrés répondent lentement et rejettent parfois complètement les demandes ou se bloquent. Si vous mettez un tel système en production, les utilisateurs verront fréquemment, semble-t-il, des ralentissements aléatoires de l'interface utilisateur et des délais d'attente aléatoires.
Dans le même temps, il reste un grand nombre de nœuds avec des fragments sans trop de charge, qui sont en fait inactifs. Cela conduit à une utilisation inefficace de nos ressources de cluster.
Ces deux problèmes pourraient être évités si Elasticsearch distribuait les fragments de manière plus intelligente, car l'utilisation moyenne des ressources système à tous les nœuds est à un niveau sain de 40%.
Changement continu de cluster
En travaillant plus de 500 nœuds, nous avons observé une dernière chose: un changement constant de l'état des nœuds. Les éclats se déplacent constamment d'avant en arrière dans les nœuds sous l'influence des facteurs suivants:
- De nouveaux index sont créés et les anciens sont supprimés.
- Les étiquettes de disque sont déclenchées en raison de l'indexation et d'autres modifications de partition.
- Elasticsearch décide au hasard qu'il y a trop peu ou trop de fragments sur le nœud par rapport à la valeur moyenne du cluster.
- Les pannes matérielles et les plantages au niveau du système d'exploitation entraînent le démarrage de nouvelles instances AWS et les joignent au cluster. Avec 500 nœuds, cela se produit en moyenne plusieurs fois par semaine.
- De nouveaux sites sont ajoutés presque chaque semaine en raison de la croissance normale des données.
Avec tout cela pris en compte, nous sommes arrivés à la conclusion qu'une solution complexe et continue de tous les problèmes nécessite un algorithme de réoptimisation continu et dynamique.
Solution: Shardonnay
Après une longue étude des options disponibles, nous sommes arrivés à la conclusion que nous voulons:
- Créez votre propre solution. Nous n'avons trouvé aucun bon article, code ou autres idées existantes qui fonctionneraient bien à notre échelle et pour nos tâches.
- Lancez le processus de rééquilibrage en dehors d'Elasticsearch et utilisez les API de redirection en cluster plutôt que d'essayer de créer un plugin . Nous voulions une boucle de rétroaction rapide, et le déploiement d'un plugin sur un cluster de cette envergure peut prendre plusieurs semaines.
- Utilisez la programmation linéaire pour calculer les mouvements optimaux des fragments à tout moment.
- Effectuez l'optimisation en continu afin que l'état du cluster atteigne progressivement l'optimum.
- Ne déplacez pas trop d'éclats à la fois.
Nous avons remarqué une chose intéressante: si vous déplacez trop d'éclats en même temps, il est très facile de déclencher une
tempête en cascade de mouvements d' éclats. Après le début d'une telle tempête, elle peut se poursuivre pendant des heures, lorsque les éclats se déplacent de façon incontrôlable d'avant en arrière, provoquant l'apparition de marques sur le niveau critique d'espace disque à divers endroits. À son tour, cela conduit à de nouveaux mouvements d'éclats et ainsi de suite.
Pour comprendre ce qui se passe, il est important de savoir que lorsque vous déplacez un segment indexé activement, il commence en fait à utiliser beaucoup plus d'espace sur le disque à partir duquel il se déplace. Cela est dû à la façon dont Elasticsearch stocke
les journaux de transactions . Nous avons vu des cas où lors du déplacement d'un nœud, l'indice a doublé. Cela signifie que le nœud qui a initié le mouvement des fragments en raison d'une utilisation élevée de l'espace disque utilisera
encore plus d'espace disque pendant un certain temps jusqu'à ce qu'il déplace suffisamment de fragments vers d'autres nœuds.
Pour résoudre ce problème, nous avons développé le service
Shardonnay en l'honneur du célèbre cépage Chardonnay.
Optimisation linéaire
L'optimisation linéaire (ou
programmation linéaire , LP) est une méthode permettant d'obtenir le meilleur résultat, tel qu'un profit maximum ou un coût le plus bas, dans un modèle mathématique dont les exigences sont représentées par des relations linéaires.
La méthode d'optimisation est basée sur un système de variables linéaires, certaines contraintes qui doivent être respectées et une fonction objective qui détermine à quoi ressemble une solution réussie. Le but de l'optimisation linéaire est de trouver les valeurs des variables qui minimisent la fonction objectif, sous réserve de restrictions.
La distribution des fragments comme problème d'optimisation linéaire
Shardonnay doit fonctionner en continu et à chaque itération, il exécute l'algorithme suivant:
- À l'aide de l'API, Elasticsearch récupère des informations sur les fragments, index et nœuds existants dans le cluster, ainsi que leur emplacement actuel.
- Modélise l'état d'un cluster comme un ensemble de variables LP binaires. Chaque combinaison (nœud, index, fragment, réplique) obtient sa propre variable. Dans le modèle LP, il existe un certain nombre d'heuristiques soigneusement conçues, des restrictions et une fonction objective, plus à ce sujet ci-dessous.
- Envoie le modèle LP à un solveur linéaire, ce qui donne une solution optimale en tenant compte des contraintes et de la fonction objectif. La solution consiste à réaffecter des fragments aux nœuds.
- Interprète la solution du LP et la convertit en une séquence de mouvements d'éclats.
- Demande à Elasticsearch de déplacer les fragments via l'API de redirection de cluster.
- Attend que le cluster déplace les fragments.
- Revient à l'étape 1.
L'essentiel est de développer les bonnes contraintes et la fonction objective. Le reste sera fait par Solver LP et Elasticsearch.
Sans surprise, la tâche a été très difficile pour un cluster de cette taille et de cette complexité!
Limitations
Nous basons certaines restrictions sur le modèle en fonction des règles dictées par Elasticsearch lui-même. Par exemple, respectez toujours les étiquettes de disque ou interdisez de placer une réplique sur le même nœud qu'une autre réplique du même fragment.
D'autres sont ajoutés sur la base de l'expérience acquise au cours des années de travail avec de grands clusters. Voici quelques exemples de nos propres limites:
- Ne déplacez pas les index d'aujourd'hui, car ils sont les plus chauds et obtiennent une charge presque constante en lecture et en écriture.
- Privilégiez le déplacement de fragments plus petits, car Elasticsearch les gère plus rapidement.
- Il est conseillé de créer et de placer les futurs fragments quelques jours avant qu'ils deviennent actifs, commencent à être indexés et subissent une lourde charge.
Fonction de coût
Notre fonction de coût pèse ensemble un certain nombre de facteurs différents. Par exemple, nous voulons:
- minimiser la variance des indexations et des requêtes de recherche afin de réduire le nombre de "points chauds";
- conserver la variance minimale d'utilisation du disque pour un fonctionnement stable du système;
- minimiser le nombre de mouvements d'éclats afin que les "tempêtes" avec une réaction en chaîne ne commencent pas, comme décrit ci-dessus.
Réduction des variables LP
À notre échelle, la taille de ces modèles LP devient un problème. Nous avons rapidement réalisé que les problèmes ne pouvaient pas être résolus dans un délai raisonnable avec plus de 60 millions de variables. Par conséquent, nous avons appliqué de nombreuses astuces d'optimisation et de modélisation pour réduire considérablement le nombre de variables. Parmi eux, l'échantillonnage biaisé, l'heuristique, la méthode diviser pour régner, la relaxation itérative et l'optimisation.
 Fig. 2. La carte thermique montre la charge déséquilibrée sur le cluster Elasticsearch. Cela se manifeste par une grande dispersion de l'utilisation des ressources sur le côté gauche du graphique. Grâce à une optimisation continue, la situation se stabilise progressivement
Fig. 2. La carte thermique montre la charge déséquilibrée sur le cluster Elasticsearch. Cela se manifeste par une grande dispersion de l'utilisation des ressources sur le côté gauche du graphique. Grâce à une optimisation continue, la situation se stabilise progressivement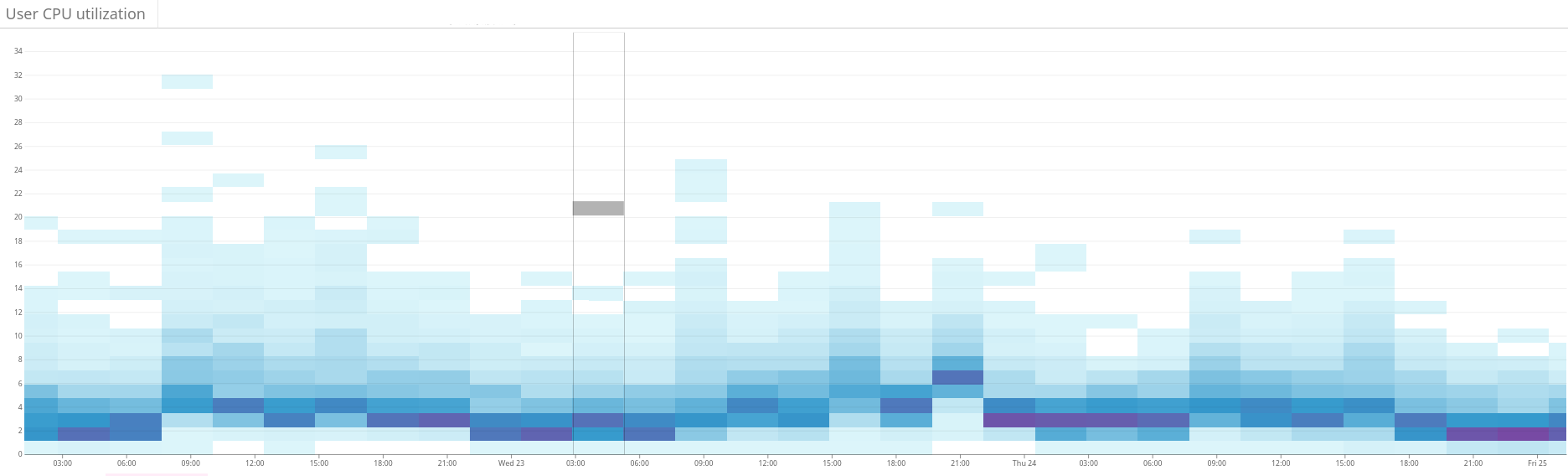 Fig. 3. La carte thermique montre l'utilisation du processeur sur tous les nœuds du cluster avant et après la configuration de la fonction de chaleur dans Shardonnay. Un changement significatif dans l'utilisation du processeur est observé avec une charge de travail constante.
Fig. 3. La carte thermique montre l'utilisation du processeur sur tous les nœuds du cluster avant et après la configuration de la fonction de chaleur dans Shardonnay. Un changement significatif dans l'utilisation du processeur est observé avec une charge de travail constante. Fig. 4. La carte thermique montre le débit de lecture des disques pendant la même période que sur la fig. 3. Les opérations de lecture sont également réparties plus uniformément sur le cluster.
Fig. 4. La carte thermique montre le débit de lecture des disques pendant la même période que sur la fig. 3. Les opérations de lecture sont également réparties plus uniformément sur le cluster.Résultats
En conséquence, notre solveur LP trouve de bonnes solutions en quelques minutes, même pour notre énorme cluster. Ainsi, le système améliore de manière itérative l'état du cluster dans le sens de l'optimalité.
Et la meilleure partie est que la dispersion de la charge de travail et de l'utilisation du disque converge comme prévu - et cet état presque optimal est maintenu après de nombreux changements intentionnels et inattendus dans l'état du cluster depuis!
Nous prenons désormais en charge une répartition saine de la charge de travail dans nos clusters Elasticsearch. Tout cela grâce à l'optimisation linéaire et à notre service, que nous aimons appeler
Chardonnay .