Dans le dernier article, j'ai parlé de Kubernetes, comment ThoughtSpot l' utilise pour ses propres besoins de support de développement. Aujourd'hui, je voudrais poursuivre la conversation sur un court, mais à partir de cette histoire de débogage non moins intéressante, qui s'est produite récemment. L'article est basé sur le fait que la conteneurisation! = Virtualisation. De plus, il montre comment les processus conteneurisés sont en concurrence pour les ressources, même avec des restrictions optimales sur le groupe de contrôle et les performances élevées des machines.
Plus tôt, nous avons lancé une série d'opérations liées au développement de b CI / CD dans le cluster interne de Kubernetes. Tout irait bien, mais lorsque vous lancez une application "dockée", les performances chutent soudainement de façon spectaculaire. Nous n'avons pas lésiné: dans chacun des conteneurs, il y avait des limites sur la puissance de calcul et la mémoire (5 CPU / 30 Go de RAM) définies dans la configuration du Pod. Sur une machine virtuelle avec de tels paramètres, toutes nos demandes d'un petit ensemble de données (10 Ko) pour les tests volaient. Cependant, dans Docker & Kubernetes avec 72 CPU / 512 Go de RAM, nous avons réussi à lancer 3-4 copies du produit, puis les freins ont commencé. Les requêtes qui se terminaient en quelques millisecondes se sont maintenant bloquées pendant 1 à 2 secondes, ce qui a provoqué toutes sortes d'échecs dans le pipeline de tâches CI. J'ai dû gérer de près le débogage.
En règle générale, toutes sortes d'erreurs de configuration lors de l'empaquetage d'une application dans Docker sont suspectées. Cependant, nous n'avons rien trouvé qui pourrait causer au moins une sorte de ralentissement (par rapport aux installations sur du matériel nu ou des machines virtuelles). Tout semble aller bien. Ensuite, nous avons essayé toutes sortes de tests à partir du package Sysbench . Nous avons vérifié les performances du CPU, du disque, de la mémoire - tout était le même que sur du métal nu. Certains services de notre boutique de produits contiennent des informations détaillées sur toutes les actions: elles peuvent ensuite être utilisées dans le profilage des performances. En règle générale, en cas de pénurie de ressources (CPU, RAM, disque, réseau), dans certains appels, il y a une défaillance significative dans le temps - nous découvrons donc ce qui ralentit exactement et où. Cependant, rien ne s'est produit dans ce cas. Les proportions temporelles ne différaient pas de la configuration de travail - la seule différence étant que chaque appel était beaucoup plus lent que sur du métal nu. Rien n'indiquait la véritable source du problème. Nous étions prêts à abandonner quand nous avons soudain trouvé cela .
Dans cet article, l'auteur analyse un cas mystérieux similaire lorsque deux processus légers, en principe, se sont tués lors de l'exécution dans Docker sur la même machine, et que les limites de ressources ont été définies à des valeurs très modestes. Nous avons tiré deux conclusions importantes:
- La raison principale réside dans le noyau Linux lui-même. En raison de la structure des objets de cache dentry dans le noyau, le comportement d'un processus a considérablement inhibé l'appel au noyau
__d_lookup_loop , ce qui a directement affecté les performances d'un autre. - L'auteur a utilisé
perf pour détecter les bogues dans le noyau. Un excellent outil de débogage que nous n'avons jamais utilisé auparavant (ce qui est dommage!).
perf (parfois appelé perf_events ou perf tools; anciennement connu sous le nom de Performance Counters for Linux, PCL) est un outil d'analyse des performances Linux disponible à partir de la version 2.6.31 du noyau. L'utilitaire de gestion de l'espace utilisateur, perf, est disponible à partir de la ligne de commande et est une collection de sous-commandes.
Il effectue le profilage statistique de l'ensemble du système (noyau et espace utilisateur). Cet outil prend en charge les compteurs de performances des plates-formes matérielles et logicielles (par exemple, hrtimer), des points de trace et des échantillons dynamiques (par exemple, kprobes ou uprobes). En 2012, deux ingénieurs IBM ont reconnu la perf (avec OProfile) comme l'un des deux outils de profilage de compteur de performances les plus utilisés sur Linux.
Nous avons donc pensé: peut-être avons-nous la même chose? Nous avons commencé des centaines de processus différents dans des conteneurs, et tous avaient le même noyau. Nous avons senti que nous avions attaqué la piste! Armés de perf , nous avons répété le débogage, et à la fin nous attendions une découverte des plus intéressantes.
Vous trouverez ci-dessous les entrées de perf des 10 premières secondes de ThoughtSpot fonctionnant sur une machine saine (rapide) (à gauche) et à l'intérieur du conteneur (à droite).
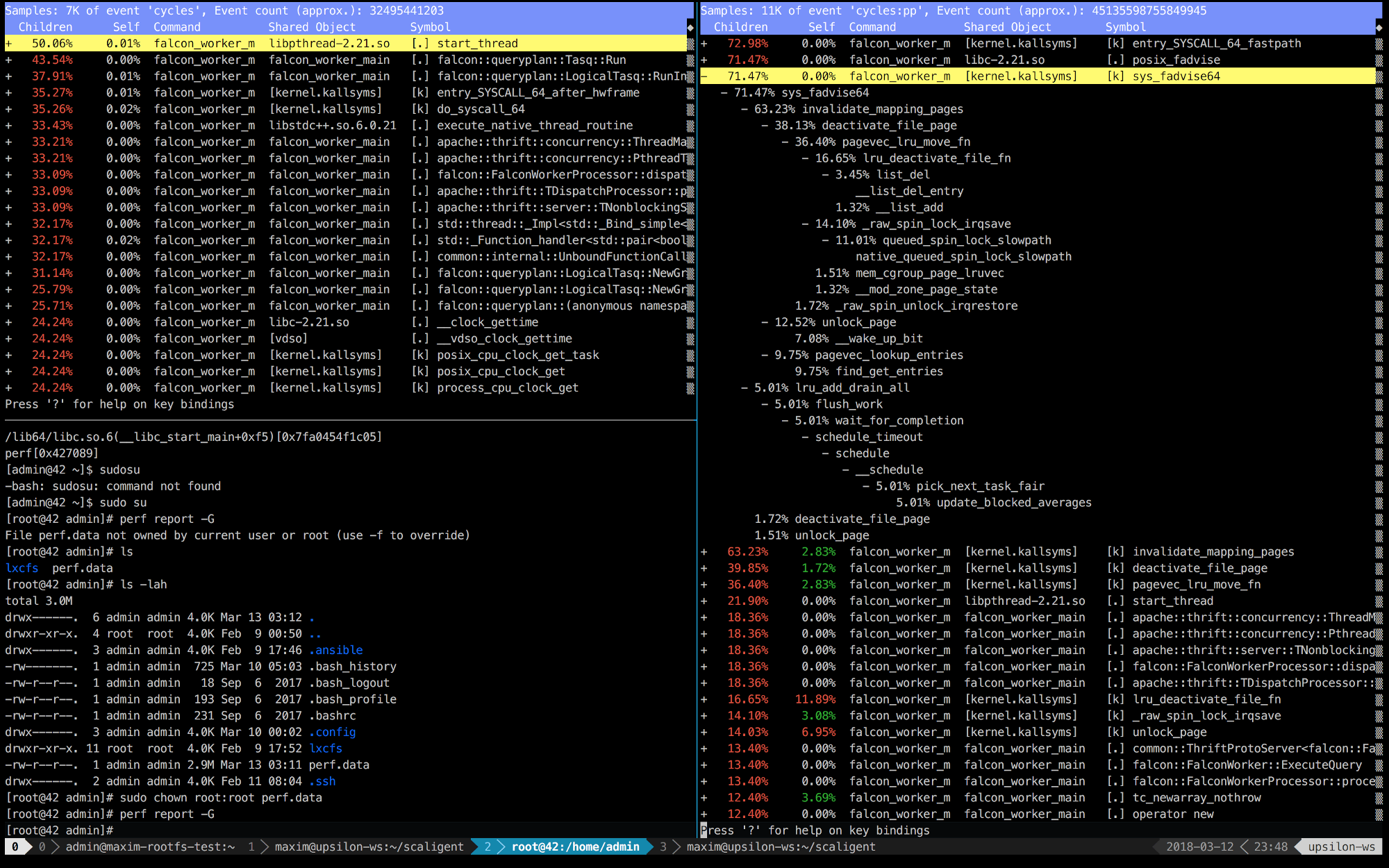
Il est immédiatement clair qu'à droite, les 5 premiers appels sont connectés au noyau. Le temps est principalement consacré à l'espace du noyau, tandis qu'à gauche - la plupart du temps est consacré à nos propres processus exécutés dans l'espace utilisateur. Mais la chose la plus intéressante est que l'appel posix_fadvise prend tout le temps.
Les programmes utilisent posix_fadvise (), déclarant leur intention d'accéder aux données du fichier selon un modèle spécifique à l'avenir. Cela donne au noyau la possibilité d'effectuer l'optimisation nécessaire.
L'appel est utilisé dans toutes les situations, par conséquent, il n'indique pas explicitement la source du problème. Cependant, en fouillant dans le code, je n'ai trouvé qu'un seul endroit qui, théoriquement, affectait tous les processus du système:
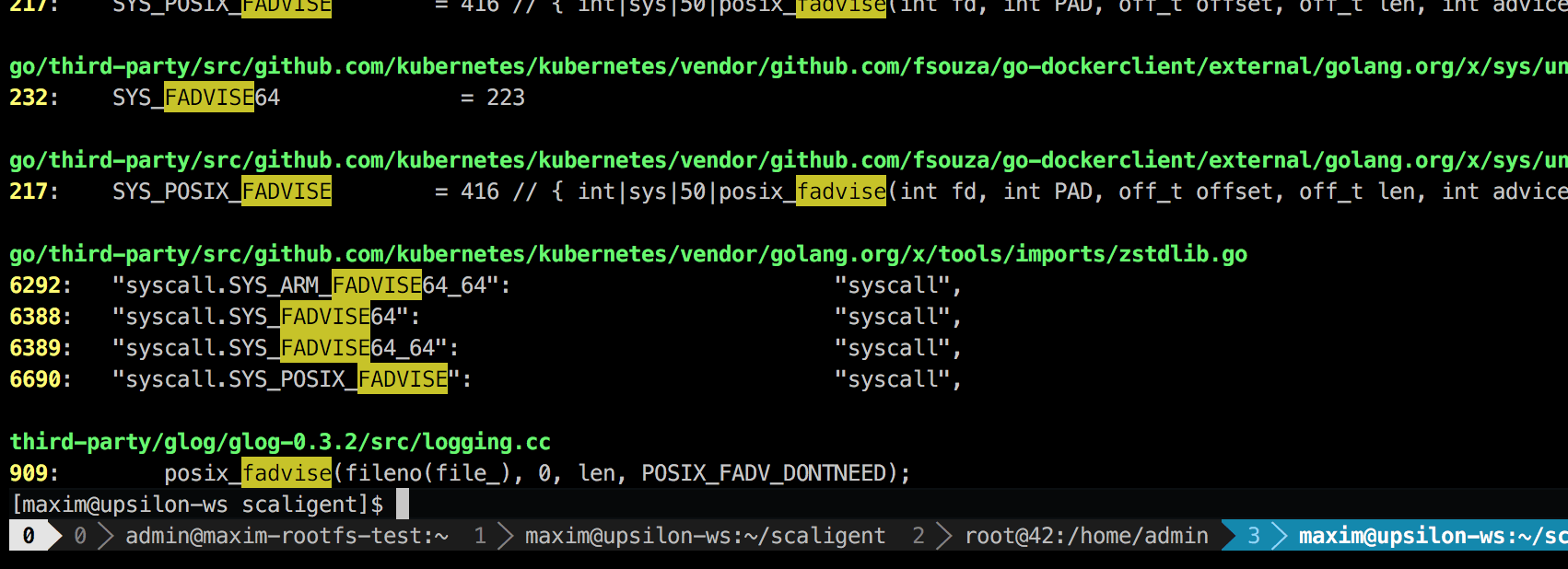
Il s'agit d'une bibliothèque de journalisation tierce appelée glog . Nous l'avons utilisé pour le projet. Plus précisément, cette ligne (dans LogFileObject::Write ) est probablement le chemin le plus critique de la bibliothèque entière. Il est appelé pour tous les événements «journal dans un fichier» (journal dans un fichier), et de nombreuses instances de notre journal de produit assez souvent. Un rapide coup d'œil au code source suggère que vous pouvez désactiver la partie fadvise en définissant le paramètre --drop_log_memory=false :
if (file_length_ >= logging::kPageSize) {
ce que nous avons fait, bien sûr, et ... dans la bulle!
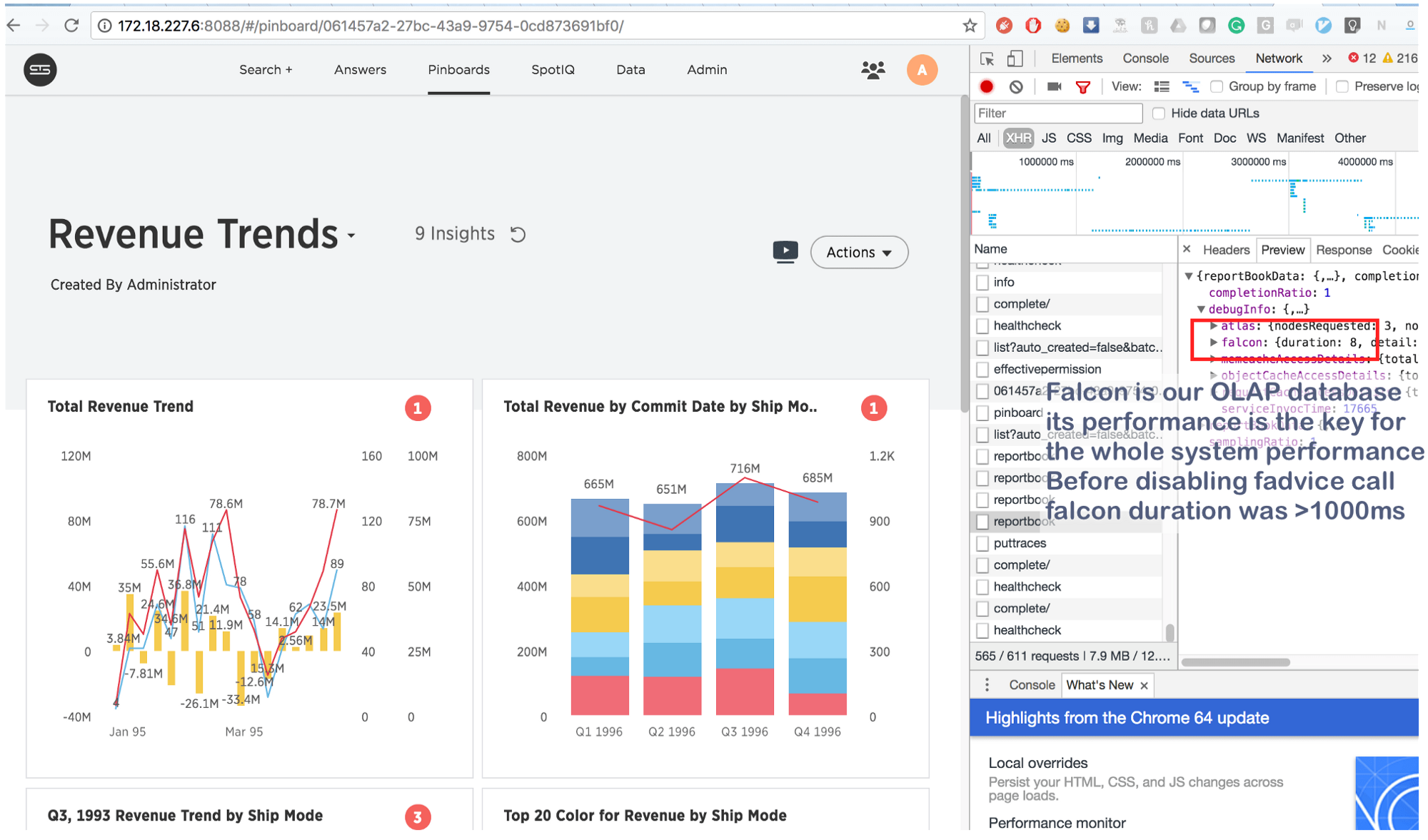
Ce qui prenait auparavant quelques secondes se fait maintenant en 8 (huit!) Millisecondes. Un peu sur Google, nous avons trouvé ceci: https://issues.apache.org/jira/browse/MESOS-920 et aussi ceci: https://github.com/google/glog/pull/145 , ce qui a encore une fois confirmé notre intuition sur la véritable cause de l'inhibition. Très probablement, la même chose s'est produite sur la machine virtuelle / bare metal, mais comme nous avions 1 copie du processus par machine / noyau, l'intensité des appels fadvise était beaucoup plus faible, ce qui expliquait le manque de consommation de ressources supplémentaires. En augmentant les processus de journalisation de 3 à 4 fois et en mettant en évidence un noyau commun pour eux, nous avons vu que cela bloquait vraiment les conseils.
Et en conclusion:
Ces informations ne sont pas nouvelles, mais pour une raison quelconque, beaucoup de gens oublient l'essentiel: dans les cas avec des conteneurs, les processus «isolés» rivalisent pour toutes les ressources de base , et pas seulement pour le CPU , la RAM , l'espace disque et le réseau . Et comme le noyau est une structure extrêmement complexe, des plantages peuvent se produire n'importe où (comme, par exemple, dans __d_lookup_loop de l' article Sysdig ). Cependant, cela ne signifie pas que les conteneurs sont pires ou meilleurs que la virtualisation traditionnelle. Ils sont un excellent outil qui résout leurs tâches. N'oubliez pas: le noyau est une ressource partagée et préparez-vous à déboguer les conflits inattendus dans l'espace du noyau. De plus, de tels conflits sont une excellente occasion pour les attaquants de briser l'isolement "aminci" et de créer des canaux cachés entre les conteneurs. Et enfin, il y a perf - un excellent outil qui montrera ce qui se passe dans le système et aidera à déboguer tout problème de performances. Si vous prévoyez d'exécuter des applications très chargées dans Docker, assurez-vous de prendre le temps d'apprendre la perf .