chapitres précédents
Courbes d'apprentissage
28 Diagnostic des biais et de la dispersion: apprentissage des courbes
Nous avons examiné plusieurs approches de la séparation des erreurs en biais et dispersion évitables. Nous l'avons fait en évaluant la proportion optimale d'erreurs, en calculant les erreurs sur l'échantillon d'apprentissage de l'algorithme et sur l'échantillon de validation. Discutons d'une approche plus informative: l'apprentissage des graphiques de courbe.
Les graphiques des courbes d'apprentissage sont les dépendances de la part de l'erreur sur le nombre d'exemples d'échantillons d'apprentissage.
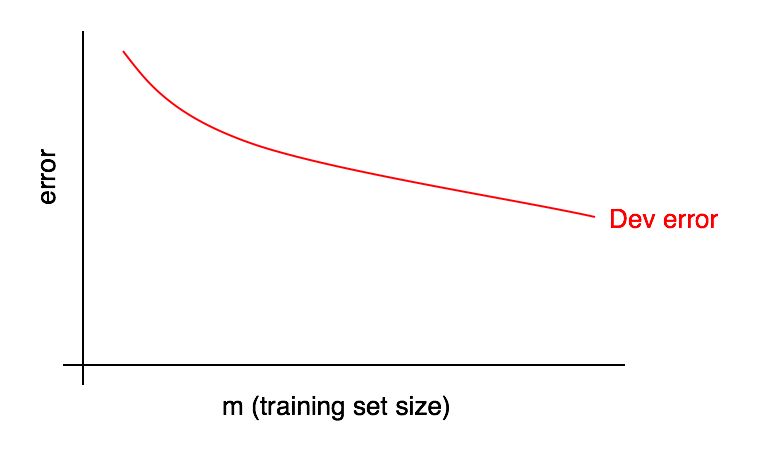
À mesure que la taille de l'échantillon d'apprentissage augmente, l'erreur dans l'échantillon de validation devrait diminuer.
Nous nous concentrerons souvent sur une «part d'erreurs souhaitée» qui, nous l'espérons, atteindra éventuellement notre algorithme. Par exemple:
- Si nous espérons atteindre un niveau de qualité accessible à l'homme, alors la part des erreurs humaines devrait devenir la «part d'erreurs souhaitée»
- Si l'algorithme d'apprentissage est utilisé dans certains produits (comme un fournisseur d'images de chats), nous pouvons avoir une idée du niveau de qualité que vous devez atteindre pour que les utilisateurs en tirent le meilleur parti.
- Si vous travaillez sur une application importante depuis longtemps, vous pouvez avoir une compréhension raisonnable des progrès que vous pouvez faire au cours du prochain trimestre / de l'année.
Ajoutez le niveau de qualité souhaité à notre courbe d'apprentissage:

Vous pouvez extrapoler visuellement la courbe d'erreur rouge dans l'échantillon de validation et supposer à quel point vous pourriez vous rapprocher du niveau de qualité souhaité en ajoutant plus de données. Dans l'exemple montré dans l'image, il semble probable que doubler la taille de l'échantillon d'apprentissage atteindra le niveau de qualité souhaité.
Cependant, si la courbe de la fraction de l'erreur de l'échantillon de validation a atteint un plateau (c'est-à-dire s'est transformée en une ligne parallèle à l'axe des abscisses), cela indique immédiatement que l'ajout de données supplémentaires n'aidera pas à atteindre l'objectif:
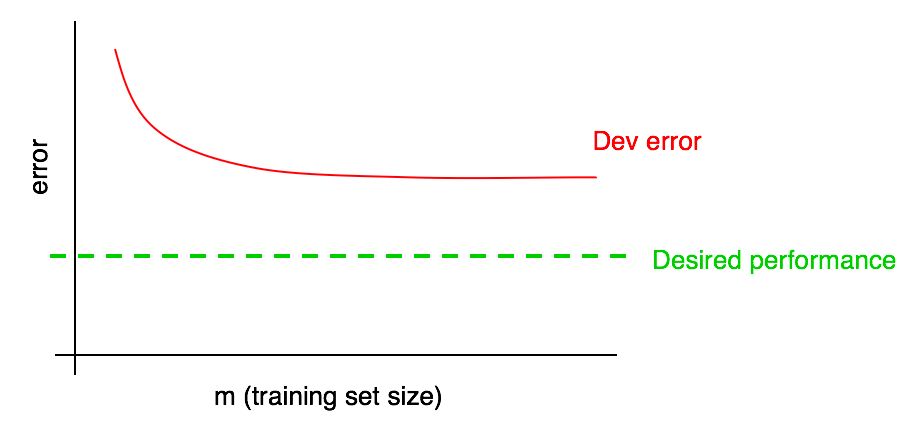
Un coup d'œil à la courbe d'apprentissage peut ainsi vous aider à éviter de passer des mois à collecter deux fois plus de données d'entraînement juste pour réaliser que les ajouter n'aide pas.
L'un des inconvénients de cette approche est que si vous ne regardez que la courbe d'erreur dans l'échantillon de validation, il peut être difficile d'extrapoler et de prédire avec précision le comportement de la courbe rouge si vous ajoutez plus de données. Par conséquent, il existe un autre graphique supplémentaire qui peut aider à évaluer l'impact de données de formation supplémentaires sur la proportion d'erreurs: une erreur d'apprentissage.
29 Calendrier des erreurs d'apprentissage
Les erreurs dans les échantillons de validation (et de test) devraient diminuer à mesure que l'échantillon d'apprentissage augmente. Mais dans l'exemple de formation, l'erreur lors de l'ajout de données augmente généralement.
Illustrons cet effet avec un exemple. Supposons que votre échantillon de formation se compose de seulement 2 exemples: une image avec des chats et une sans chats. Dans ce cas, l'algorithme d'apprentissage peut facilement mémoriser les deux exemples de l'échantillon d'apprentissage et afficher une erreur de 0% sur l'échantillon d'apprentissage. Même si les deux exemples de formation sont mal étiquetés, l'algorithme se souviendra facilement de leurs classes.
Imaginez maintenant que votre ensemble d'entraînement se compose de 100 exemples. Supposons qu'un certain nombre d'exemples soient classés incorrectement, ou qu'il soit impossible d'établir une classe dans certains exemples, par exemple, dans des images floues, quand même une personne ne peut pas déterminer si un chat est présent dans l'image ou non. Supposons que l'algorithme d'apprentissage "se souvienne" encore de la plupart des exemples d'exemples de formation, mais qu'il est désormais plus difficile d'obtenir une précision de 100%. En augmentant l'échantillon d'apprentissage de 2 à 100 exemples, vous constaterez que la précision de l'algorithme dans l'échantillon d'apprentissage diminuera progressivement.
En fin de compte, supposons que votre ensemble de formation se compose de 10 000 exemples. Dans ce cas, il devient de plus en plus difficile pour l'algorithme de classer idéalement tous les exemples, surtout si l'ensemble d'apprentissage contient des images floues et des erreurs de classification. Ainsi, votre algorithme fonctionnera moins bien sur un tel échantillon d'entraînement.
Ajoutons un graphique d'erreur d'apprentissage à nos précédents.
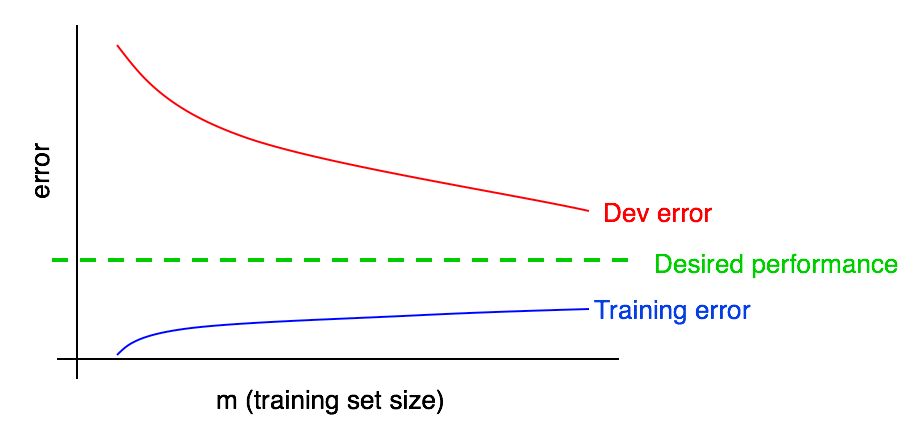
Vous pouvez voir que la courbe bleue «Erreurs d'apprentissage» augmente avec l'augmentation de l'échantillon d'apprentissage. De plus, un algorithme d'apprentissage montre généralement une meilleure qualité dans un échantillon d'apprentissage que dans un échantillon de validation; ainsi, la courbe d'erreur rouge dans l'échantillon de validation se situe strictement au-dessus de la courbe d'erreur bleue dans l'échantillon d'apprentissage.
Ensuite, voyons comment interpréter ces graphiques.
suite